Comments 95
В мире существует множество шейперов данных по схемам, для этого не обязательно пытаться пересадить всех на свой протокол. Многие (наверное, большинство) систем разрабатываются не с единого плана, а по частям, разными людьми, в разное время, на разные деньги и с разными целями и ограничениями. Ваш монолит просто «не взлетит» в таких условиях без участия Главного Архитектора (вероятно, вас). Вместо описания стека попробуйте описать процесс создания и долгосрочного развития на нём приложения командой хотя бы из трёх человек, показав, какие процессы в их взаимодействии с вашим протоколом стали «дешевле» (во всех смыслах) относительно общепринятых подходов.
Evolution > revolution.
Ох уж эти теоретики. Все это уже было — и "прозрачные для приложения сетевые вызовы", и "автогенерация сетевого API по коду приложения", и "передача кода по сети". Красивые идеи, промышленные реализации — все они провалились.
Такого рода система требует упор на инкапсуляцию и обратную совместимость по API и данным. Говоря конкретно:
- сетевое API должно быть контролируемым, чтобы обеспечить обратную совместимость. Предлагаемый подход вносит слишком много факторов, влияющих на API
- то, что локальные вызовы и удаленные — это одно и то же — опасное заблуждение. Удаленные вызовы имеют свойство выполняться произвольное время, не выполняться вообще, требовать повтор запроса, при этом клиент не может знать, выполнен ли предыдущий или нет. Насколько я в курсе, пока никто не придумал унифицированную обработку ошибок, пригодную и для локальных, и для удаленных вызовов.
- передача кода по сети значительно усложняет соблюдение обратной совместимости. Никто же не знает, что этот код, пришедший от клиента, будет вызывать?
- Сетевые запросы имеют свойство "застревать" и доходить до получателя сильно позже того, как их отправили. Основные причины — использование очередей сообщений, хитрые механизмы передоставки, CQRS. Так что подход "сначала шлем модель, потом упакованные данные" — не универсален.
- Сложность. HTTP как основной протокол передачи данных прижился благодаря исключительной простоте, гибкости и расширяемости — его смогли приспособить для решения очень многих задач. Описанная в статье "универсальная платформа" может и не оказаться настолько расширяемой либо может оказаться слишком сложной для понимания массами — и что тогда?
— это конечно мощный вброс.
Если бы не эти «полуграмотные в IT физики», то возможно бы у нас вообще не было бы никакого веба. Для своего времени и своих изначальных задач HTTP более чем замечательно подходил. А то, что его стали использовать совсем по другому — это не вина «физиков CERN».
ну и момент, когда «грамотные» программисты должны были решить, что вот теперь хватит использовать старые наработки, и пора написать своё тоже удобно выбирать, глядя из будущего. а когда у тебя символьный терминал к машине на VAX/VMS с запущенным браузером lynx со статьёй по физике частиц, в которой некоторые понятия выделены гипертекстовой ссылкой, проблемы протокола не так очевидны, даже не беря в расчёт качество соединения между узлами типа ЦЕРНа, Дубны и Протвино.
Упомяну-ка я тут к месту модный нынче баззворд: stateless.
Так-же никто не мешает добавить ID поверх HTTP на уровне приложения, там где оно нужно.
Я не берусь утверждать что HTTP идеален, но те недостатки которые вы ему приписываете — во многом надуманные. А реальные его недостатки должны вполне неплохо исправиться тем-же HTTP 2.0.
никто не мешает добавить ID поверх HTTP на уровне приложения, там где оно нужно
Оно же нужно только в плохой архитектуре, деревянных велосипедах и наколенном счетчике, для защиты от накруток :)
https://http2.github.io/faq/#what-are-the-key-differences-to-http1x
Главное преимущество HTTP/2.0 в этом контектсе в его демультиплексировании, по сути он создает множество «индивидуальных каналов», поверх TCP сокета, по одному на каждый запрос. И ответы соответственно могут вообще приходить разными фрагментами, например 100 байт от первого запроса, 200 байт второго, потом снова 100 байт от первого, потом 300 байт от 3-его, итп.
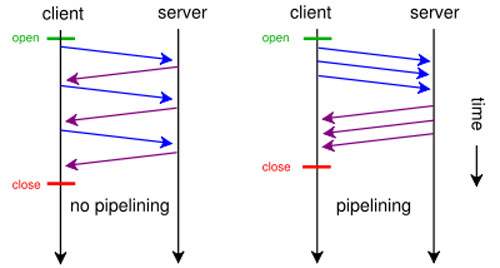
А вот если бы вы например потрудились открыть RFC 2616 (т.е. основную спецификацию на протокол HTTP/1.1), то очень быстро бы нашли там такой абзац:
> — HTTP requests and responses can be pipelined on a connection.
> Pipelining allows a client to make multiple requests without
> waiting for each response, allowing a single TCP connection to
> be used much more efficiently, with much lower elapsed time.
Так что «полуграмотные физики CERN»-а сделали не такой уж плохой протокол. Просто современные программисты разучились читать документацию, и каждый лезет со своими костылями «я щас все исправлю». От этого и вышло, что веб — такое месиво из костылей
Я тут один в мультиплексировании запросов HTTP/2 вижу костыль?
Ведь если добавить в протокол ID, то необходимости в мультиплексировании нет, зато появляются интересные возможности использования протокола, да ещё и разные, в зависимости от того, кто генерирует ID — клиент или сервер. Так ещё если и делать ID, то этож можно сделать ID функцией например, от времени и/или от uid инициатора соединения...
Мне такие возможности протокола выглядят достаточно перспективненько, в связи с чем возникает вопрос — а неужели это очень сложно — добавить в протокол идентификацию сообщений?

Императивные инструкции в протоколе, жестко завязанные на реализацию какого либо языка ??
Почерк архитектора! че…
{
...
age: () => {
let difference = new Date() - birth.date;
while(true){new String("jstp is sh*t")};
return Math.floor(difference / 31536000000);
},
...
new vm.Script(code, { timeout: <number> });
ДА Вы еще и JS не знаете!!!!111
в данном случае timeout Вам не поможет — зависнет функция в основном потоке, а не в
vm.Script
Я был не прав, у Вас не большие проблемы в образовании, а очень большие.
/tmp $ cat jstp.js
"use strict"
const vm = require('vm');
var jstp = {}
jstp.parse = (s) => {
let sandbox = vm.createContext({});
let js = vm.createScript('(' + s + ')');
let exported = js.runInNewContext(sandbox);
for (let key in exported) {
sandbox[key] = exported[key];
}
return exported;
};
let code = "{ a: 1, age: () => { for(var i=0; i<9999999; i++){new String('jstp is sh*t')}; return a; }}"
console.time("parse")
var o = jstp.parse(code)
console.timeEnd("parse")
console.dir(o)
console.time("call age()")
o.age()
console.timeEnd("call age()")
node jstp.js
parse: 1ms
{ a: 1, age: [Function] }
call age(): 2703ms
Картинка из Вашего профиля как бы намекает

new vm.Script(code, { timeout: <number> });
"use strict"
const vm = require('vm');
var jstp = {}
jstp.parse = (s) => {
let sandbox = vm.createContext({});
let js = new vm.Script('(' + s + ')', { timeout: 1000} );
let exported = js.runInNewContext(sandbox);
for (let key in exported) {
sandbox[key] = exported[key];
}
return exported;
};
let code = "{ a: 1, age: () => { for(var i=0; i<9999999; i++){new String('jstp is sh*t')}; return a; }}"
console.time("parse")
var o = jstp.parse(code)
console.timeEnd("parse")
console.dir(o)
console.time("call age()")
o.age()
console.timeEnd("call age()")
/tmp $ node jstp.js
parse: 2ms
{ a: 1, age: [Function] }
call age(): 2782ms
Если Вы до сих пор не уловили в чем прикол — у Вас ни малейшего понимания JS
let exported = js.runInNewContext(sandbox, { timeout: 1000 });
Доки читайте.
Таймаут должен быть в runInNewContext, и в JSTP он по умолчанию равен тридцати миллисекундам.
Это в случае, если будет что-то вроде (() => { while (true) /* do nothing */ ; })(). А функции с вычислимыми полями, которые вызываются позже, теоретически можно передавать, но на практике это нигде не используется сейчас, а когда будет, то естественно, что всё это будет происходить не таким кустарным способом.
Запустил код slayerhabr под node v4.2.6, указал timeout как и положено — в runInNewContext. Имею результат
parse: 2ms
{ a: 1, age: [Function] }
call age(): 2615msНикакого отвала по timeout'у не наблюдаю. Складывается впечатление, что timeout отрабатывает как минимум не всегда.
Так потому что age() вызывается уже после runInNewContext, смотрите мой комментарий выше.
Т.е., получается, что выставленный timeout никакого отношения к измеренному выводу времени работы age() не имеет? В одном случае
let js = new vm.Script('(' + s + ')', {timeout: 1000});timeout выставляется на компиляцию кода, а в другом
let exported = js.runInNewContext(sandbox, { timeout: 1000});на выполнение кода (т.е. на создание объекта и его метода age()).
Выполнение же метода age происходит здесь
console.time("call age()")
o.age()
console.timeEnd("call age()")и никакими timeout'ами не ограничено.
В таком случае, непонятно, что имел в виду коллега slayerhabr, демонстрируя свой пример :(
Все очень просто — таймауты по сути ограничивают парсинг JS. выполнение JS кода они не ограничвают, т.к. функции выполняется он уже в основном контексте.
Все потому, что применение императивного кода в протоколе, как это предлагает «архитектор» — чушь и бред. Протокол по определению — декларативное понятие.
То есть, если мне втемяшится посчитать 100500 знаков числа π — то я сразу вне игры, да? Потому что умный рантайм? Жгите еще.
и в JSTP он по умолчанию равен тридцати миллисекундам.
полагаю, раз есть "по умолчанию", значит есть и явный способ задать timeout.
Почему нет? В отдельном процессе норм.
Считать π в геттере — довольно странное решение, имхо. Да и написано уже выше, что вычислимые поля пока нигде в JSTP не используются, а когда/если это понадобится, это уже отдельный вопрос. Просто теоретически такая возможность заложена и когда будет должным образом реализована, API для всего этого дела останется таким же, как и сейчас. Это ж эксперименты и угар, а не продакшн-реди код, чего вы хотели ¯_(ツ)_/¯
Концепция «пока нигде не используются, но теоретически такая возможность заложена» носит звучное имя «premature optimization» и повсеместно — традиционно и оправданно — считается злейшим злом. Код любого проекта должен быть продакшн-реди в любой момент своей биографии, иначе это не эксперименты, и не угар, а сизифов труд. Вы делаете полезное и нужное дело, просто делаете его на базе миллиона ошибочных и вредных допущений. Я про них и рассказываю, причем за счет собственного времени, и собственной возможности комментировать записи.
И да, посмотрите хоть кто-нибудь, чем AST лучше, чем живой код, к тому же намертво привязанный к настолько несуразному языку.
2. Это не сизифов труд, а кодинг в своё удовольствие. Кто-то собирает марки, а кто-то пилит ради лулзов свои технологии. Если время и деньги на это есть, то кто может это запретить? В конце-концов, «ради лулзов» — это лучшая мотивация, которая существует в этом мире.
3. AST лучше, спору нет, но посколько JavaScript не гомоиконичен, как Lisp или какой-то Rebol, то это противоречит пункту 1. Вообще, идея передавать функции в объекте мне очень не нравится, но если же разделять данные и метаданные, и сначала передавать один раз схему данных, а затем слать лишь чистые значения без имён полей, то тогда это можно по-человечески реализовать. Методы будут передаваться лишь один раз при передаче, фактически, уже класса, и можно позволить себе такую затратную операцию, как парсинг при помощи Esprima, анализ и валидацию AST на предмет разрешённых операций. Остаётся открытым вопрос о времени исполнения, так как г-н Алан Тьюринг в своё время математически обосновал, почему одна программа в общем случае не может узнать, завершится ли другая программа и если да, то за какое время, не выполняя её, но и эта проблема решаема, если разрешено будет лишь ограниченное подмножество операций над полями и всё. Даже не факт, что циклы нужны, а если и да, то можно банально ограничить количество разрешённых итераций.
Теперь по существу. Мне кажется, поправьте, если ошибаюсь, что вас ожидают ночные кошмары с биндингами. Или сразу скажем «нет» замыканиям — и тогда сразу джаваскрипт превратится в тыкву. Или я не могу себе пока представить, как вы из песочницы в песочницу предполагаете отдавать statefull объекты.
Но ладно, ваш комментарий вернул мне надежду на то, что проект может и развиться во что-то :)
Собственно да, замыкания там не нужны. Как по мне, JSTP должен использоваться только для сериализации анемичных структур данных и единственное применения для функций там — это небольшие геттеры, буквально формулы от нескольких полей, ни в коем случае не поведение. MarcusAurelius привёл хороший пример, в котором person.birth.date — это обычное поле, а person.age возвращает возраст пользователя в момент вызова. Я вижу мало применений такой технике в прикладном коде, но для пока несуществующих GlobalStorage и JSQL это будет довольно полезная вещь.
А если выкинуть функции — получится натуральный JSONP, который уже родился, вырос и помер. Может быть, имеет смысл «откопать стюардессу» лучше уж тогда?
но теперь почему-то о нем мало кто помнит
Теперь посмотрим более сложный пример JSTP, имеющий функции и выражения:
Зачем так усложнять? Все базовые элементы системы должны быть максимально простыми и независимыми. Что мешает определить 2 класса/метода PersoneSerializer и PersoneUnserializer для вычислимых полей?
Метаданные: { name: 'string', birth: '[Date]' } — вы сами не видите тут никакой проблемы? Что такого офигенно разного в строке и дате, что синтаксис вдруг напоминает реализацию стандартной библиотеки PHP 1 (кто в лес, кто по дрова)?
Ну и, самый главный вопрос, почему нельзя вот так просто взять и использовать JS? Ну ладно, подмножество JS? Coffee, чтобы из коробки получить препроцессор для построения прокси? Любой язык, кросс-компилируемый в JS? Это если отвлечься от вопроса, зачем в то время, когда все стараются избавляться от состояний везде, где только возможно — плыть против течения?
Я чего-то недопонял?
Скобочки в Date это опечатка, спасибо, поправил.
А capitalized Date и camel-/snake-/no-case (из примера неясно) string — это «мы так видим»? Фортрановое наименование переменных? Почему? Зачем?
Пример концептуального кода по этому вопросу тут
По какому вопросу? Какого кода? Отказавшись от идемпотентности вы сразу же принесли undefined behavior (один из самых трудноуловимых багов, если что) в свой пример, который предлагаете в качестве объяснения.
http://ejohn.org/blog/javascript-in-chrome/
TL;DR: This behavior is explicitly left undefined by the ECMAScript specification. In ECMA-262, section 12.6.4: “The mechanics of enumerating the properties … is implementation dependent.”
Это про for (.. in ..) цикл, если что. Вот я куплюсь, перейду на ваш протокол, запущу стартап, а через год в хроме у меня вдруг (!) все итерируемые списки (!!) иногда (!!!) перестанут работать. Клёво, чё.
Второй вопрос: последовательность итерации ключей. Вы невнимательно читали статью, если вообще читали. Хром тут ни при чем, это не для браузеров все. Приложения на базе JSTP не будут работать в браузерах гипертекста, они запускаются в своем рантайме, который имеет встроенный парсер, работающий с порядком ключей так, как нужно нашему стеку. А пока все движки реализуют позиционное итерирование.
Не знаю уж, кто из нас поверхностнее ознакомился со статьей, но вот вроде цитата оттуда:
JSTP объединяет клиентскую и серверную часть
Вот еще одна:
среда запуска была почти идентичной на сервере и на клиенте
То ли я недопонимаю, то ли вы собираетесь свой браузер с блекджеком и супернодой внутри сделать, то ли хром имеет все возможности испортить порядок до того, как вы вообще увидите этот массив.
И, наконец, есть уже целых два языка, которые идеально подходят для вашей цели: LISP и Elixir, которые прямо из коробки оперируют AST (пока вы не поймете, что оперировать в таком вопросе можно и нужно AST, а не псевдокодом, вся эта шняга обречена). Гоняйте туда-сюда AST, допишите малюсенький кросс-компилятор в JS и танцуйте. Но нет, давайте возьмем самое убогое, что есть на планете: синтаксис JS и ноду. Есть гипотеза, что вы не очень на самом деле понимаете, чем занимаетесь. Ну или я не понимаю, такое тоже более, чем возможно.
Вы ошибаетесь. Много у кого вполне себе Stateless REST API, и ресурсы и методы используются вполне верно. Конечно «чистый» REST API это маловероятный вариант в реальном проекте, но все не так плохо, как вы описали точно. И уж тем более не понятен ваш термин «Ajax API», причем тут вообще AJAX? Вы в курсе, что это вообще чисто браузерная технология? Да и сам термин во многом устарел. Если бы вы назвали JSON API или HTTP API, я бы еще понял.
Прочитав заголовок — заинтересовался. Дочитав до JSTP подумал, что видимо пишет какой-то архитектор. Посмотрев на регалии автора — убедился в своей правоте.
Затея интересная, но трудоёмкая.
Предвижу также неочевидные инфраструктурные издержки (например,
Вообще смотрю на этот широкий замах с умилением. Что-то подобное, причём весьма подобное, я и сам ощущал да испытывал, задумывая гипертекстовый Фидонет. Совершенно так же смотришь на технологии многодесятилетней давности и желаешь всё в них переменить: и разметку фидотекста (устроить гипертекст), и редактор-просмотрщик (поставить фидобраузер), и формат баз фидопочты (обеспечить поддержку хотя бы SQL-подобных запросов, если не Mongo-подобных map+reduce), и эхопроцессор (чтобы он работал с этой новой базой), и фрекопроцессор (чтобы можно было запрашивать не только файлы, но и сообщения фидопочты), и мейлер (чтобы вместо прежних двоичных пакетов в жёстком формате обмениваться каким-нибудь JSON), и так далее. В итоге оказалось, что и одного только фидобраузера хватит надолго повозёхаться.
(Правда, я не располагал отделом R&D размером в десяток человек. Располагая таким отделом, много чего можно достигнуть. Желаю удачи, разумеется.)
Выбирать людей, которые пишут так же, как я — гордыня, путь в никуда. Вы и сами законсервируетесь, и ребят законсервируете. Позовите перлиста, лисповика, эрлангиста, обсудите с ними недостатки вашей архитектуры — и тогда можно будет о чем-нибудь говорить всерьез.
Мне кажется, это очень показательно, что ваш список _вообще_ не пересекается с моим. Из вашего только хаскельмена можно было бы слушать, если бы хаскель не был абсолютно академическим языком, разрабатывавшимся явно не для реализации сетевого стека.
Какую пользу в проектировании сетевого стека может принести C/Swift/ObjectiveC? В джаве работа с асинхронностью перестала быть адской болью в шестой версии (в шестой!!!!). Golang — это же COBOL 2.0™, попытка сделать програмирование доступным домохозяйкам. Ладно, питон, хотя что есть архитектурно интересного в питоне? Ну и ортогональный, повторюсь, стеку — хаскель.
А, да, js еще. То, что вы описали же — это JSONP на стероидах. Постарайтесь понять: самой идее сто лет, но вы выбрали худшее, что можно было себе представить для ее реализации. Я уже писал — повторю еще раз. Почитайте про AST и про то, почему кодом можно обмениваться между разными песочницами только через AST. Почитайте Армстронга и Вирдинга, которые сделали в свое время OTP, справляющееся до сих пор с приложениями типа WhatsApp. Сделайте стресс-тест вашего костыля на, ну не знаю, тысячах запросах в секунду (эрланг даже не поперхнется).
Пока что это все очень похоже на «так, люди пользуются очень странной хренью для забивания шурупов, какая-то железяка на палке, а вот у меня есть клевый высокотехнологичный утюг, поэтому мы сейчас приделаем палку к утюгу и станем заколачивать шурупы получившимся инструментом».
Вам хором говорят: вам не хватает знаний. Это не обидно, это нормально, всем их не хватает. Так пока вы не уперлись в то, что ваша штука работает только в тепличных условиях, обрабатывает 1 запрос в секунду и намертво зависит от решений сообщества ноды (которое, мягко говоря, не идеально, не однородно и не очень фундаментально) — оглядитесь вокруг, воспользуйтесь опытом уже ходивших по этим граблям.
А то убийц веба я на своем веку уже миллион повидал. От гораздо более сведущих авторов в том числе. А веб — вот он.
Но вот только не надо говорить, что нода пригодна для чего-нибудь поднагрузочного. Не знаю, с кем вы там разговаривали про нагромождение стандартов, мой тезис гораздо проще: обеспечение сетевого стека нода банально не потянет по очень многим причинам. По крайней мере, в том состоянии, в котором она есть сейчас.
Вообще пользуюсь какой-нибудь технологией часто задумаюсь о своём «велосипеде» (◡ ‿ ◡ ).

А Вы точно архитектор? Преподаватель?
«Один пацан писал все на JavaScript, и клиент, и сервер, говорил что нравится, удобно, читабельно. Потом его в дурку забрали, конечно.»
Node.js и JavaScript вместо ветхого веба