 Это вторая статья в цикле про создание и использование скриптов для веб-скрейпинга на Node.js.
Это вторая статья в цикле про создание и использование скриптов для веб-скрейпинга на Node.js.
- Web scraping при помощи Node.js
- Web scraping на Node.js и проблемные сайты
- Web scraping на Node.js и защита от ботов
- Web scraping обновляющихся данных при помощи Node.js
В первой статье разбиралась простейшая задача из мира веб-скрейпинга. Именно такие задачи достаются веб-скрейперам в подавляющем большинстве случаев – получение данных с незащищённых HTML-страниц стабильно работающего сайта. Быстрый анализ сайта, HTTP-запросы при помощи needle (организованные при помощи tress), рекурсивный проход по ссылкам, DOM-парсинг при помощи cheerio – вот это вот всё.
В этой статье разбирается более сложный случай. Не из тех, когда приходится отказываться от взятого с боем заказа, но из тех, которые начинающему скрейперу могут сорвать дедлайн. К слову, эта задача содержалась в реальном заказе на одной международной бирже фриланса, и первый исполнитель её провалил.
Цель этой статьи (как и прошлой) – показать весь процесс создания и использования скрипта от постановки задачи и до получения конечного результата, однако темы, уже раскрытые в первой статье, освещаются здесь довольно кратко, так что начать я рекомендую с первой статьи. Тут акцент будет на анализ сайта с точки зрения веб-скрейпинга, выявление подводных камней и способы их обхода.
Постановка задачи
 Заказчик хочет скрипт, который будет получать данные с маркеров на карте в одном из разделов некого сайта 'LIS Map' (ссылка на раздел прилагается: 'http://www.puntolis.it/storelocator/defaultsearch.aspx?idcustomer=111'). В смысл данных вникать не нужно (всё равно там всё по-итальянски). Достаточно если скрипт сможет взять строчки с маркеров и сохранить их в электронную таблицу в столбцы '
Заказчик хочет скрипт, который будет получать данные с маркеров на карте в одном из разделов некого сайта 'LIS Map' (ссылка на раздел прилагается: 'http://www.puntolis.it/storelocator/defaultsearch.aspx?idcustomer=111'). В смысл данных вникать не нужно (всё равно там всё по-итальянски). Достаточно если скрипт сможет взять строчки с маркеров и сохранить их в электронную таблицу в столбцы 'Title', 'Address' и 'Place'.
Маркеров на сайте много, так что они организованы порциями по регионам и выбираются из выпадающих списков в два или три уровня. Маркеры нужны все. Порядок не важен.
Очень похоже, что удобного API у сайта нет. По крайней мере заказчик о нём не знает и на сайте его не заметно. Значит придётся скрейпить.
Анализ сайта
Первая плохая новость – весь выбор и отображение данных на сайте происходит динамически на одной и той же странице. Выглядит это так: при обновлении показывается выпадающий список, после выбора пункта – ещё выпадающий список (а иногда после него и ещё один), а потом появляется карта выбранного региона.
Поиск слов из маркеров по исходному тексту страницы ничего не даёт. Поиск слов из выпадающих списков – тоже. Уже на этом этапе может показаться, что сайт можно скрейпить только инструментами типа PhantomJS или Selenium WD, но отчаиваться рано. Скорее всего данные либо содержатся в одном из подключённых скриптов, либо подгружаются динамически. В любом случае их можно найти на вкладке Network в Chrome DevTools или в аналогичном инструменте в другом браузере.
С самого начала вместе с HTML нашей целевой страницы подгружается статика (картинки, CSS, пара скриптов), а также выполняется несколько запросов через XMLHttpRequest. Почти все запросы подгружают дополнительные скрипты и только один – что-то ещё. Его адрес вот такой:
http://www.puntolis.it/storelocator/buildMenuProv.ashx?CodSer=111Вот так это выглядит в браузере (скриншот кликабельный):
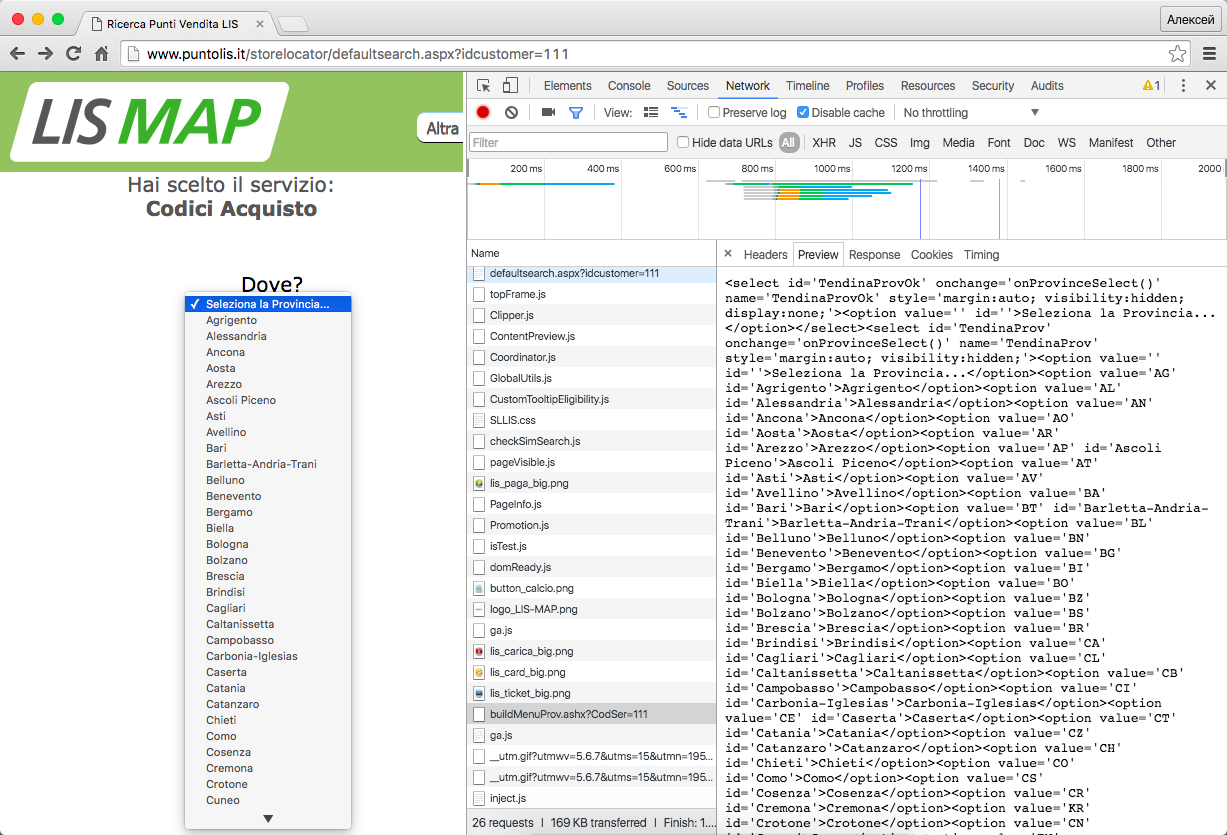
Заглядываем в него и видим данные для первого выпадающего списка в виде фрагмента HTML. Каждый пункт списка (судя по всему это называется 'Provincia') представлен фрагментом такого вида:
<option value='AG' id='Agrigento'>Agrigento</option>Очищаем вкладку Network и выбираем один из пунктов списка. Происходит ещё один XHR-запрос на вот такой адрес:
http://www.puntolis.it/storelocator/buildMenuLoc.ashx?CodSer=111&ProvSel=AGВот так это выглядит в браузере (скриншот кликабельный):
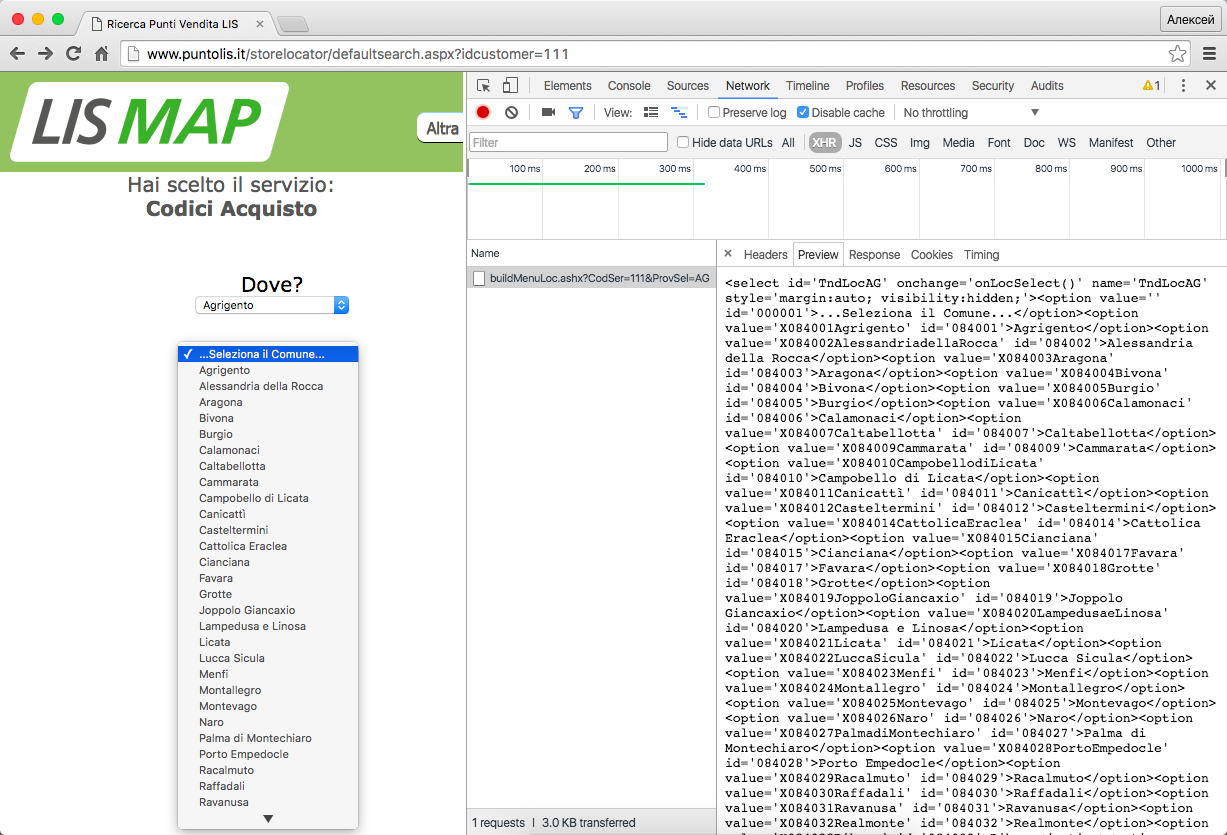
Буквы AG в конце адреса – это код провинции Agrigento из предыдущего списка. На всякий случай можно попробовать с другими провинциями и убедиться, что так оно и работает. В ответ на запрос приходит фрагмент HTML с содержимым второго выпадающего списка (похоже это называется 'Comune'). Каждый пункт представлен вот таким фрагментом:
<option value='X084001Agrigento' id='084001'>Agrigento</option>Выбираем пункт из второго списка и на странице появляется карта с маркерами, данные которых приходят в виде XML в ответ на очередной XHR-запрос вот по такому адресу:
http://www.puntolis.it/storelocator/Result.aspx?provincia=AG&localita=084001&cap=XXXXX&Servizio=111Вот так это выглядит в браузере (скриншот кликабельный):
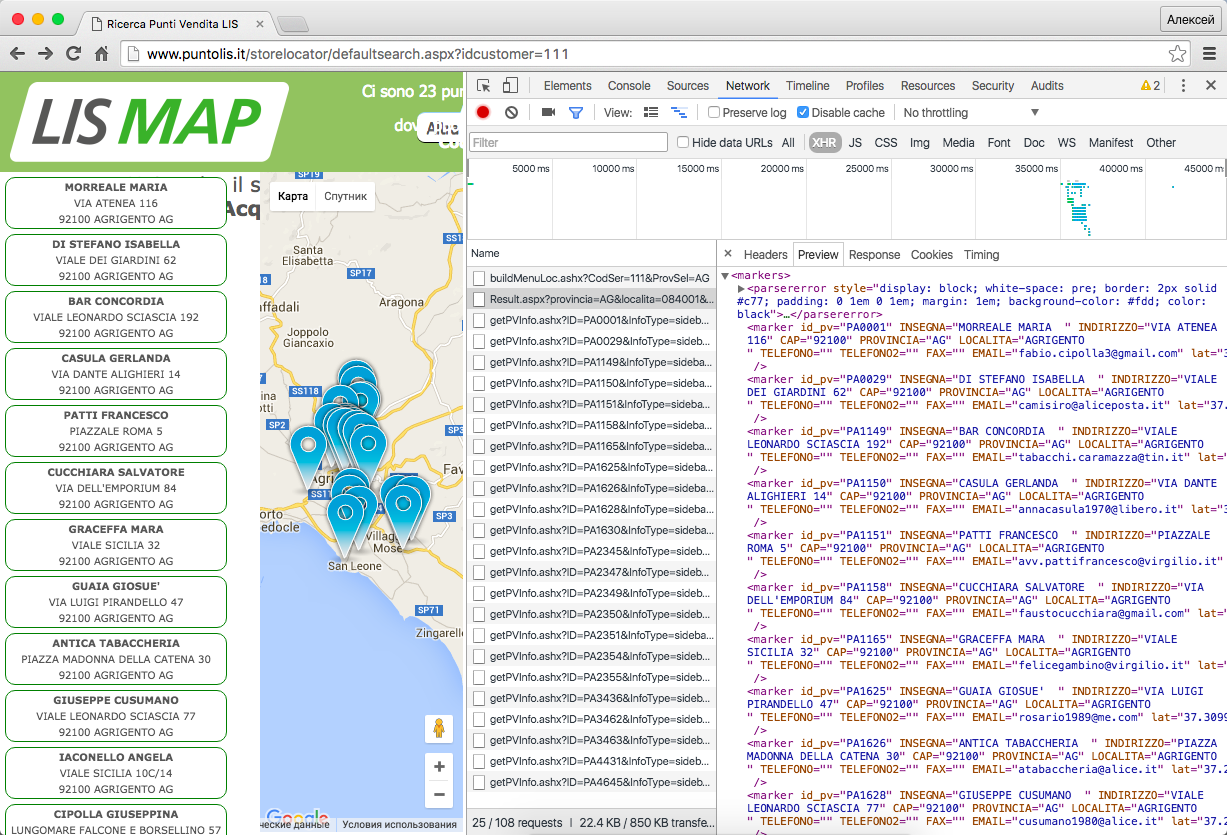
Приглядевшись к этому адресу легко заметить в нём буквенный код провинции Agrigento (AG) и цифровой идентификатор коммуны Agrigento (084001). Теперь у нас есть все шаблоны адресов, чтобы получить список маркеров, каждый из которых будет представлен вот таким фрагментом:
<marker id_pv="PA1150" INSEGNA="CASULA GERLANDA " INDIRIZZO="VIA DANTE ALIGHIERI 14" CAP="92100" PROVINCIA="AG" LOCALITA="AGRIGENTO " TELEFONO="" TELEFONO2="" FAX="" EMAIL="annacasula1970@libero.it" lat="37.3088220" lon="13.5788890" CODSER="101,102,103,104,105,106,107,109,110,111,112,113,114,201,202,203,204,210,220,240,250,260,261,270,290,301,302,303,306,401,402" />Нужные нам поля есть в данных маркера, хоть и по кусочкам.
(Стоит упомянуть, что на некоторых сайтах данные могут быть зашифрованы, и тогда обнаружить их простым поиском характерных слов практически нереально. К счастью, такое случается совсем редко. На нашем сайте всё проще.)
Теперь вспоминаем, что для некоторых провинций на сайте выдаётся не два, а три уровня выпадающих списков. В запрос данных после второго списка подставляется не цифровой идентификатор коммуны, а её название, адрес немного другой, а в ответ приходит не список маркеров, а пункты третьего списка.
Вот так это выглядит в браузере (скриншот кликабельный):
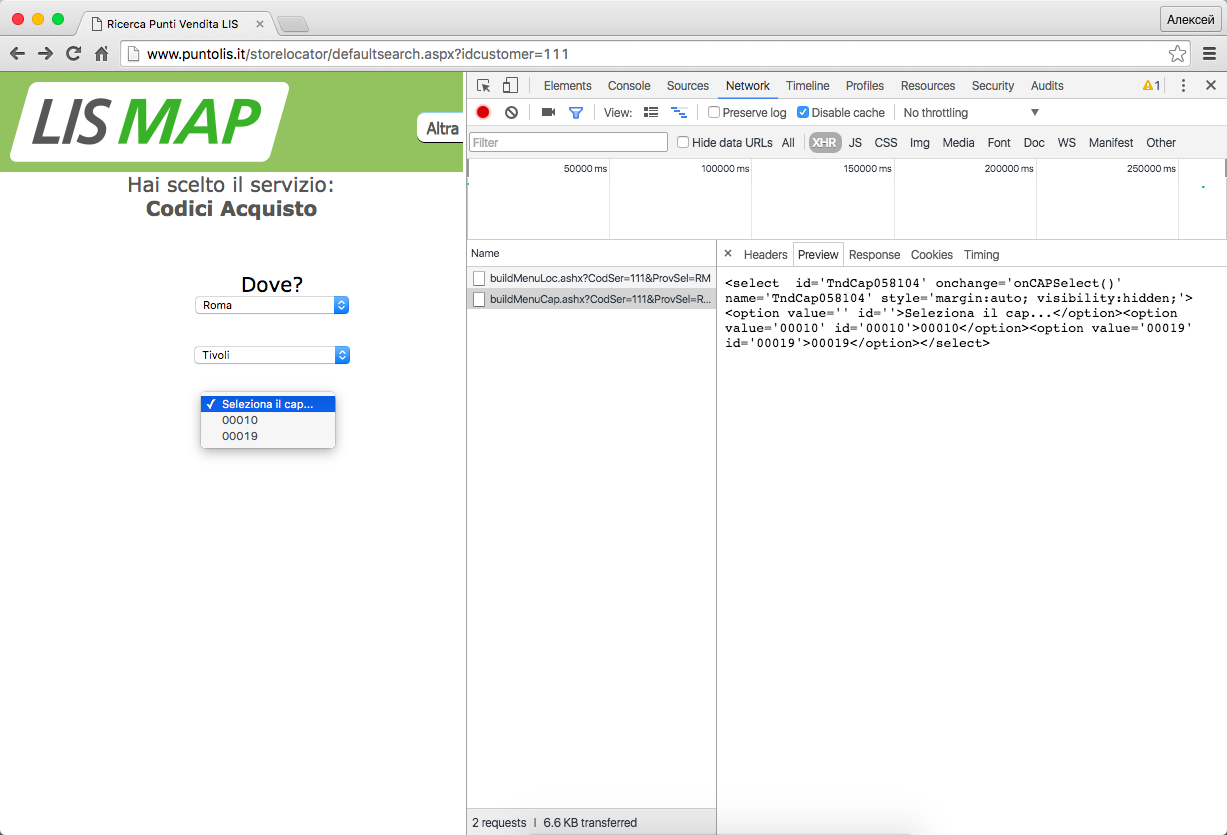
Может показаться, что нам придётся по-разному обрабатывать разные провинции, но прежде чем расстраиваться стоит всё проверить. Если мы руками подставим нужные данные в шаблон, то получим список всех маркеров, например, для коммуны Tivoli в провинции Roma:
http://www.puntolis.it/storelocator/Result.aspx?provincia=RM&localita=058104&cap=XXXXX&Servizio=111Таким образом можно забыть про третий уровень. Видимо веб-мастер нашего сайта тоже поленился по-разному обрабатывать запросы для разных провинций и просто прикрутил третий уровень поверх изначального двухуровневого интерфейса. Такие костыли встречаются часто и если их проверять, то можно сэкономить время и здорово упростить скрипт.
Получение страниц
Использование http-клиента в скрипте довольно подробно разбиралось в первой статье. Здесь стоит остановиться только на одном моменте.
Найденные нами адреса можно открыть в браузере и увидеть их содержимое (HTML или XML соответственно), но только если в браузере уже установлены куки с основной страницы раздела (ссылка из задания). В случае с curl и с http-клиентом в скрипте ситуация такая же. Это самая примитивная защита от ботов, но её придётся учесть. Это – вторая плохая новость. В самом начале надо выполнить запрос к основной странице, сохранить полученные куки и передавать их вместе с каждым последующим запросом.
Краулинг
У нас есть четыре типа URL, с которыми нам предстоит работать:
- Основная страница (нужен только чтобы получить куки)
- Список провинций (с него будем начинать)
- Шаблон списка коммун
- Шаблон списка маркеров
Адреса, построенные на основе списков, мы будем добавлять в очередь, а данные из маркеров – сохранять в массив. Весь краулинг будет выглядеть примерно вот так:
var tress = require('tress');
var needle = require('needle');
var fs = require('fs');
// Главная страница (только ради куков):
var sCookie = 'http://www.puntolis.it/storelocator/defaultsearch.aspx?idcustomer=111';
// Стартовый URL. Список провинций:
var sProv = 'http://www.puntolis.it/storelocator/buildMenuProv.ashx?CodSer=111';
// Шаблон списка коммун для заданной провинции (подставить код провинции вместо %s):
var sLoc = 'http://www.puntolis.it/storelocator/buildMenuLoc.ashx?CodSer=111&ProvSel=%s';
// Шаблон списка маркеров (подставить коды провинции и коммунны вместо %s):
var sMarker = 'http://www.puntolis.it/storelocator/Result.aspx?provincia=%s&localita=%s&cap=XXXXX&Servizio=111';
var httpOptions = {};
var results = [];
// Настраиваем очередь задач
var q = tress(crawl);
q.drain = function(){
fs.writeFileSync('./data.json', JSON.stringify(results, null, 4));
}
// Инициализация
needle.get(sCookie, function(err, res){
if (err || res.statusCode !== 200)
throw err || res.statusCode;
// устанавливаем куки
httpOptions.cookies = res.cookies;
// Запускаем краулинг
q.push(sProv);
});
function crawl(url, callback){
needle.get(url, httpOptions, function(err, res){
if (err || res.statusCode !== 200)
throw err || res.statusCode;
// Тут будет парсинг
callback();
});
}По сути всё похоже на краулинг из предыдущей статьи, только добавлена установка куков отдельным запросом, обработчик задач вынесен в отдельную функцию, а в обработке ошибок проверяется код ответа.
Обычно, если заказчик просит сохранение данных в Excel, ему будет достаточно CSV. Иногда вообще удаётся договориться на JSON (благо бесплатных онлайновых конвертеров существует достаточно). Но если заказчику принципиально нужен файл xlsx – можно воспользоваться, например, модулем excelize или другой подобной обёрткой. Например так:
q.drain = function(){
require('excelize')(results, './', 'ADDR.xlsx', 'sheet', function(err){
if (err) throw err;
console.log(results.length + ' adresses saved.');
});
}Парсинг
Парсить хорошо организованные куски HTML/XML намного проще, чем захламлённые страницы, так что всем, кто разобрался с парсингом в прошлой статье, в этой всё должно быть очевидно без объяснений. Блок кода парсинга будет выглядеть так:
var $ = cheerio.load(res.body);
$('#TendinaProv option').slice(1).each(function() {
q.push(sLoc.replace('%s', $(this).attr('value')));
});
$('select[onchange="onLocSelect()"] option').slice(1).each(function() {
q.push(sMarker.replace('%s', url.slice(-2)).replace('%s', $(this).attr('id')));
});
$('marker').each(function() {
results.push({
Title: $(this).attr('insegna').trim(),
Address: $(this).attr('indirizzo').trim(),
Place: [
$(this).attr('cap').trim(),
$(this).attr('localita').trim(),
$(this).attr('provincia').trim()
].join(' ')
});
});Особенно стоит обратить внимание на метод slice из cheerio. Он работает точно также, как одноимённый метод у массивов. Конкретно здесь он используется перед each для удаления из выборок пунктов списка первого пункта, который не несёт полезной информации. Но это не то, из-за чего метод slice стоит знать каждому скрейперу, использующему cheerio. Главное, что при тестировании скрейпинга сайтов с большими выборками можно перед вызовом метода each вызывать, например slice(0,5) (ну, или slice(1,5) в нашем случае), чтобы уменьшить выборку до приемлемых размеров. Скрейпинг будет работать полностью в боевом режиме, но не так долго.
(Важное примечание: если будете пробовать скрейпить LIS Map – обязательно используйте slice. Хабраэффект убивает.)
Индикация
Есть как минимум две причины, чтобы тут не пренебрегать индикацией, как это было сделано в прошлый раз.
Во-первых, сайт LIS Map значительно менее стабильный, чем Ferra.ru, так что на этапе боевых запусков скрипта будет здорово видеть, что именно происходит.
Во-вторых, на этот раз заказчик хочет не готовые данные, а работоспособный скрипт, который он сможет сам запускать вручную по мере необходимости. Вряд ли заказчику понравится раз за разом скучать, глядя на замерший курсор в окне терминала и пытаться угадать сколько времени прошло, сколько работы за это время выполнилось и всё ли с этой работой нормально. Но копаться в длинных файлах логов он тоже не захочет, так что навороченные логгеры, такие как bunyan или winston, тут будут избыточным решением. Ему понадобится нечто более простое и наглядное: консольный индикатор прогресса, совмещённый с предельно лаконичным консольным же логгером, сообщающим о самых основных событиях.
Поскольку при веб-скрейпинге практически никогда не известен конечный объём работ (ибо рекурсивный проход по ссылкам и всё такое), стандартный индикатор прогресса в виде заполняющейся полоски тут не подойдёт. Лучше сделать счётчик выполненных задач (строчку с “бегущими” циферками). Также понадобится вывод в терминал различных видов сообщений, который не будет затирать счётчик. Сообщения хорошо бы сопровождать автоматическими метками времени.
Именно под такие задачи создан модуль cllc (Command line logger and counter). С его помощью можно отображать строку со счётчиками, и выводить сообщения.
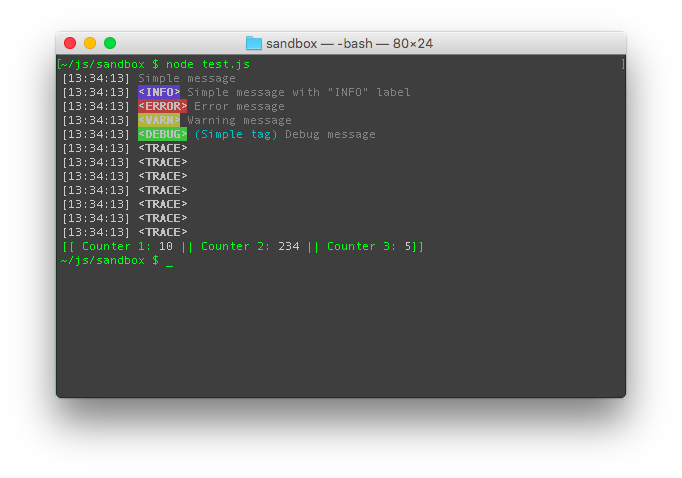
Нам понадобятся следующие возможности модуля cllc:
var log = require('cllc')();
log('Message'); // Вывести обычное сообщение
log.e('Error message'); // Вывести сообщение об ошибке с ярлыком <ERROR>
// Создать индикатор с тремя счётчиками:
log.start('Найдено провинций %s, Найдено коммун %s, Найдено маркеров %s.');
log.step(); // Увеличить первый счётчик на 1. (То же, что и log.step(1))
log.step(0, 1); // Увеличить второй счётчик на 1.
log.step(0, 0, 1); // Увеличить третий счётчик на 1.
log.finish(); // Остановить индикатор.Между вызовами log.start и log.finish все сообщения будут выводиться над индикатором ничего не затирая. Все сообщения сопровождаются временными метками.
var log = require('cllc')();
var tress = require('tress');
var needle = require('needle');
var cheerio = require('cheerio');
var fs = require('fs');
var sCookie = 'http://www.puntolis.it/storelocator/defaultsearch.aspx?idcustomer=111';
var sProv = 'http://www.puntolis.it/storelocator/buildMenuProv.ashx?CodSer=111';
var sLoc = 'http://www.puntolis.it/storelocator/buildMenuLoc.ashx?CodSer=111&ProvSel=%s';
var sMarker = 'http://www.puntolis.it/storelocator/Result.aspx?provincia=%s&localita=%s&cap=XXXXX&Servizio=111';
var httpOptions = {};
var results = [];
var q = tress(crawl);
q.drain = function(){
fs.writeFileSync('./data.json', JSON.stringify(results, null, 4));
log.finish();
log('Работа закончена');
}
needle.get(sCookie, function(err, res){
if (err || res.statusCode !== 200)
throw err || res.statusCode;
httpOptions.cookies = res.cookies;
log('Начало работы');
log.start('Найдено провинций %s, Найдено коммун %s, Найдено маркеров %s.');
q.push(sProv);
});
function crawl(url, callback){
needle.get(url, httpOptions, function(err, res){
if (err || res.statusCode !== 200) {
log.e((err || res.statusCode) + ' - ' + url);
log.finish();
process.exit();
}
var $ = cheerio.load(res.body);
$('#TendinaProv option').slice(1).each(function() {
q.push(sLoc.replace('%s', $(this).attr('value')));
log.step();
});
$('select[onchange="onLocSelect()"] option').slice(1).each(function() {
q.push(sMarker.replace('%s', url.slice(-2)).replace('%s', $(this).attr('id')));
log.step(0, 1);
});
$('marker').each(function() {
results.push({
Title: $(this).attr('insegna').trim(),
Address: $(this).attr('indirizzo').trim(),
Place: [
$(this).attr('cap').trim(),
$(this).attr('localita').trim(),
$(this).attr('provincia').trim()
].join(' ')
});
log.step(0, 0, 1);
});
callback();
});
}Запускаем скрипт и видим на индикаторе, что всё работает. Скрипт находит 110 провинций и 5116 коммун, а затем начинает собирать маркеры. Но очень быстро валится с ошибкой socket hang up. При перезапуске ошибка вылезает сразу, ещё на стадии инициализации. В браузере в это время выдаётся страница ошибки с кодом 500.
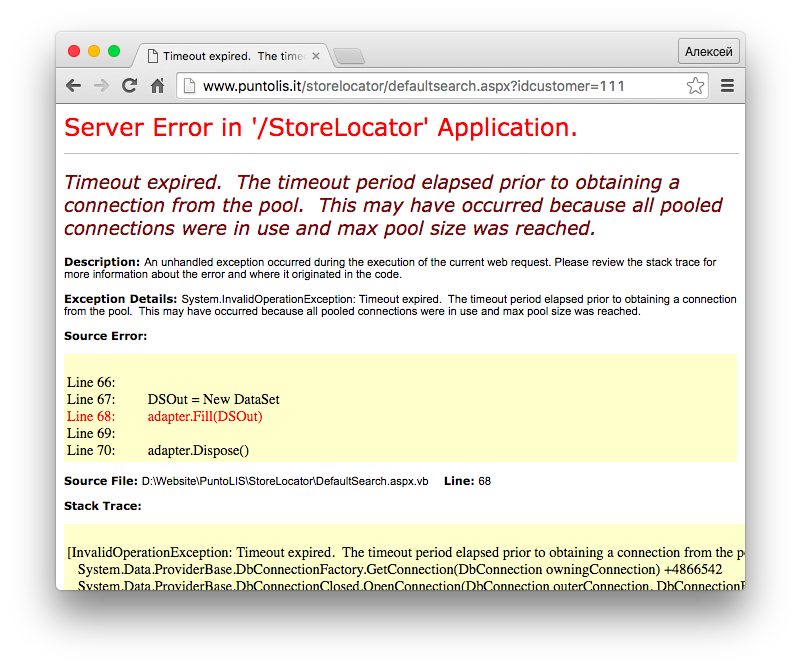
На странице ошибки говорится, что возможная причина – превышение допустимого количества подключений. Имеются в виду подключения к базе данных, а не по http. Проще говоря, установка connection: 'Keep-Alive' в needle нам не поможет. Такая же страница выдаётся в другом браузере и по другому IP (то есть это не блокировка и прокси не помогут). Таким образом сайт лежит в течении примерно 20-30 минут, как повезёт. Потом ситуация повторяется. Как вы наверняка догадались, это – третья плохая новость.
Обработка ошибок
Хуже всего с такими сайтами то, что их скрейпинг трудно тестировать. Стоит запустить скрипт не с тем параметром – и придётся ждать более 20 минут, чтобы повторить попытку. Без индикации было бы совсем грустно, а так мы всего за несколько запусков можем определить, что сайт каждый раз падает после трёх с небольшим сохранённых маркеров. Немного поигравшись со счётчиками можно установить, что речь идёт примерно о полутора сотнях коммун. Это означает, что если наш скрипт не будет завершаться после ошибки, а будет ждать пока сайт поднимется и продолжать, то он остановится более 30 раз. То есть работа скрипта займёт 10-15 часов.
Не факт, что заказчика такой вариант устроит. Возможно он предпочтёт закрыть заказ оплатив уже потраченное время. Однако прежде чем огорчать заказчика стоит проверить ещё один вариант.
Вполне возможно, что мы слишком часто бомбим сайт запросами. Стоит попробовать установить между запросами задержку и посмотреть что получится. Технически это сделать очень легко, нам даже ничего не придётся писать. У модуля tress есть свойство concurrency, хорошо знакомое пользователям async.queue. Это свойство задаётся при создании очереди вторым параметром (по умолчанию concurrency равно 1) и указывает во сколько параллельных потоков будут обрабатываться задачи. Вот только у tress свойство concurrency может иметь и отрицательные значения, означающие, что между задачами в единственном потоке должна быть задержка. Например, если установить concurrency в -1000, то это будет означать задержку в 1000 миллисекунд. Очевидность интерфейса тут принесена в жертву совместимости с async.queue, но если знать – всё просто.
Осталось решить, какой должна быть задержка. Простые расчёты показывают, что при задержке в 10 секунд наши 5227 запросов (1 список провинций, 110 списков коммун и 5116 списков маркеров) будут выполняться более 14 часов. То есть даже если за это время сайт не упадёт – по времени мы ничего не выиграем. С другой стороны, даже 100 миллисекунд в мире http – это вполне заметная задержка. Для начала попробуем поставить задержку в 1 секунду.
var q = tress(crawl, -1000);Ничего не изменилось, сайт всё так же падает после трёх с небольшим найденных маркеров. Для очистки совести попробуем задержку в 3 секунды.
var q = tress(crawl, -3000);Сайт падает после первых семи сотен маркеров. Можно было бы продолжать экспериментировать с задержками побольше, но во-первых по времени кардинального выигрыша уже не будет, а во-вторых, мы не сможем гарантировать, что сайт точно не упадёт. Таким образом у нас остаётся только один рабочий вариант – в случае ошибки возвращать задачу в очередь, ставить всю очередь на паузу, после чего возобновлять скрейпинг до следующей ошибки, и так – 10-20 часов.
Вот на этом этапе можно интересоваться у заказчика, устроит ли его настолько медленный скрипт, учитывая, что заметно быстрее ему не сделает никто. Тут мы будем исходить из предположения, что заказчик согласился.
Итак, нам надо сделать, чтобы если http-запрос завершается ошибкой, то соответствующий адрес возвращается в очередь, а сама очередь ставится на паузу на указанное время. Всё это отлично реализуется стандартными возможностями модуля tress, выгодно отличающими его от async.queue.
В очереди tress любая задача находится в одном из четырёх состояний:
- Ожидает выполнения
- Выполняется
- Успешно выполнена
- Признана невыполнимой
Разработчику все эти задачи представлены в виде четырёх массивов, доступных по свойствам q.waiting, q.active, q.finished и q.failed. Во время всяких отладочных экспериментов содержимое этих массивов даже можно менять по живому, но в рабочих скриптах так делать не стоит. Да и надобности в таком хакерстве нет, ведь всё происходит автоматически. Когда задача передаётся обработчику, она переносится из массива waiting в массив active, где и остаётся пока не будет вызван колбэк. После вызова колбэка задача переносится из active в один из трёх оставшихся массивов. В какой – зависит от параметров колбэка:
- Если колбэк вызван без параметров или если первый параметр null – задача признаётся выполненной и помещается в массив finished.
- Если первый параметр колбэка имеет тип boolean, то задача возвращается на повторную обработку и ставится в начало очереди (начало массива waiting), если параметр равен true, или в конец очереди (конец массива waiting), если параметр равен false.
- Если первый параметр колбэка – объект ошибки (instanceof Error), то задача перемещается в массив failed.
- При любых других значениях первого параметра колбэка поведение модуля не определено и может меняться в последующих версиях (так что лучше не надо).
После перемещения задачи из active в другой массив tress вызывает один из трёх обработчиков: q.success, q.retry или q.error соответственно. Важно, что в однопоточном режиме (concurrency <= 1) выполнение обработчика завершается до того, как стартует следующая задача. Это позволяет нам сделать следующее:
Обработку ошибки запроса сделаем так:
function crawl(url, callback){
needle.get(url, httpOptions, function(err, res){
if (err || res.statusCode !== 200) {
log.e((err || res.statusCode) + ' - ' + url);
return callback(true); // возвращаем url в начало очереди
}
// парсинг
callback();
});
}И добавим, например, такой обработчик q.retry:
var q = tress(crawl);
q.retry = function(){
q.pause();
// в this лежит возвращённая в очередь задача.
log.i('Paused on:', this);
setTimeout(function(){
q.resume();
log.i('Resumed');
}, 300000); // 5 минут
}Такой скрипт успешно завершает скрейпинг за 14 с небольшим часов, как и ожидалось.
Задержку я поставил на 5 минут. Если сайт ещё не проснулся – просто ещё раз вывалится ошибка, а если проснулся – не придётся ждать зря. Меньше всего потери времени будут, если паузу вообще не включать, но тогда скрипт будет бессмысленно бомбить сайт запросами и мусорить в лог одинаковыми сообщениями об ошибке.
Ещё один способ – в случае ошибки понижать скорость (ставить отрицательную concurrency). Например вот так:
var q = tress(crawl);
q.success = function(){
q.concurrency = 1;
}
q.retry = function(){
q.concurrency = -300000; // 5 минут
}Заключение
В таком виде скрипт можно отдавать заказчику (для желающих код последнего варианта на gist). В реальной жизни в комплект поставки могут добавиться разные мелочи, такие как инструкция по инсталляции и запуску node-скрипта на Windows, но технически одного скрипта достаточно.
Стоит отметить, что при падениях сайтов часто слетают сессии, так что приходится перед снятием очереди с паузы (см. выше первый вариант) пробовать провести инициализацию. В нашем случае этого не происходит, но так бывает далеко не всегда. При проектировании собственной универсальной библиотеки для веб-скрейпинга вообще стоит предусмотреть возможность передавать в неё отдельную асинхронную функцию для инициализации, внутри которой можно выполнять любые http-запросы или что-то ещё.
Ещё стоит отметить, что в таких долгоиграющих скриптах стоит предусмотреть возможность прервать работу скрипта (например, по Ctrl-C, или по выключению компьютера), а потом возобновить её с того же места без потери данных. Скрипты для веб-скрейпинга довольно часто запускаются не на надёжных удалённых серверах, а на персональных компьютерах заказчиков, а 14 часов – это далеко не предел, так что прерывание скрипта с сохранением данных – это важно. Даже если заказчик этого не просит – потом он пожалеет, что не попросил. Я планирую остановиться поподробнее на этой теме в другой статье.
