Comments 254
После первого листинга кода читать дальше как-то не захотелось. Но чувак звучал очень умно, и я попытался дать ему шанс. Но после формулы
data’ = A (data) я все-таки сдался. Он ведь пытается сделать очередный основанный на FRP подход/фреймворк, так?Пытается быть «не такой как все».
Мне нравятся решения фейсбука уже за то, что они придумывают им новые названия, а не выбирают «MVC», или другой избитый TLA (https://en.wikipedia.org/wiki/Three-letter_acronym).
TLA+ от майкрософт это гениально :)
TLA+ от майкрософт это гениально :)
По поводу
Он ученый и ему свойственна академичность. Возможно и несколько избыточная.
По поводу
Лично мне статья показалась скорее попыткой под другим углом взглянуть на MVC.
Да, приведенный код весьма далек от идеала. Но те проблемы, которые он обозначил в начале статьи, от этого ведь никуда не пропадают. Как направление для развития своих мыслей при проектировании, имхо, статья стоит внимания. Как конечное непререкаемое решение — тут соглашусь с вами, не стоит.
чувак звучал очень умно
Он ученый и ему свойственна академичность. Возможно и несколько избыточная.
По поводу
пытается сделать очередный основанный на FRP подход/фреймворк
Лично мне статья показалась скорее попыткой под другим углом взглянуть на MVC.
Да, приведенный код весьма далек от идеала. Но те проблемы, которые он обозначил в начале статьи, от этого ведь никуда не пропадают. Как направление для развития своих мыслей при проектировании, имхо, статья стоит внимания. Как конечное непререкаемое решение — тут соглашусь с вами, не стоит.
Я, честно говоря, не очень понял, в чем у него проблема, но, кажется, дело вот в чем:
Потом, видимо, к нему приходит Dev2 и просит {x, y, w}. И он, вместо того чтобы сделать 4 отдельных API и сказать Dev и Dev2, что нужные данные доступны по таким-то REST-эндпойнтам, делает ему новое отдельное API, и они, естественно, растут в геометрической прогрессии, и автор фрустрирует.
Ну так проблема не в MVC, не в React.js и не в 500 сущностях в Angular2.
Dev — итак, на этом экране нужны данные x, y и z. Не мог бы ты сделать API, которое вернет данные в формате {x:, y:, z: }
Потом, видимо, к нему приходит Dev2 и просит {x, y, w}. И он, вместо того чтобы сделать 4 отдельных API и сказать Dev и Dev2, что нужные данные доступны по таким-то REST-эндпойнтам, делает ему новое отдельное API, и они, естественно, растут в геометрической прогрессии, и автор фрустрирует.
Ну так проблема не в MVC, не в React.js и не в 500 сущностях в Angular2.
Если раскидать данные по 4-м отдельным REST-эндпойнтам, то это не сильно помогает, если на front-end нужен целый граф объектов. Да, будет меньше эндпоинтов, но будет больше запросов за данными, чтобы собрать нужный граф объектов на клиенте.
Дополнительные проблемы возникают от того, что на front end зависимости объектов друг от друга со временем рискуют стать неуправляемыми.
Вообще про это гораздо лучше меня рассказывал Samer Buna в своем выступлении.
Ну и как раз из-за этих проблем Facebook изначально и разработал React, Flux и GraphQL, поскольку MVC не масштабируется под их потребности
Автору же решение Facebook в виде React и GraphQL кажется недоработанным, о чем он и говорит в статье.
Дополнительные проблемы возникают от того, что на front end зависимости объектов друг от друга со временем рискуют стать неуправляемыми.
Вообще про это гораздо лучше меня рассказывал Samer Buna в своем выступлении.
Ну и как раз из-за этих проблем Facebook изначально и разработал React, Flux и GraphQL, поскольку MVC не масштабируется под их потребности
Автору же решение Facebook в виде React и GraphQL кажется недоработанным, о чем он и говорит в статье.
Просто FB не умеет в MVC, судя по этой картинке:
Например, почему от вьюх идут стрелки к моделям, хотя должны идти к контроллерам? Ну и вообще, почему на второй картинке остался только 1 View? Будь их там побольше, оно выглядело бы так же запутанно.
В итоге они взяли всё тот же MVC (одну из вариаций), только назвали его по-другому.
Может я что-то не понимаю, но в чём отличие от флакса от классического MVC? Там модель содержит всю логику и оповещает подписавшиеся на неё вьюхи о изменениях в своих данных. Там почти такой же однонаправленный поток данных: от модели ко вьюхам. Никакого двунаправленного связывания, от которого многие не в восторге. А действия пользователя всё так же идут от вью через контроллеры к моделям (или другим контроллерам).
Да и автор, по-сути, опять пересказал старый добрый MVC.
Ну и второй коммент в этой статье доставляет)
wtf?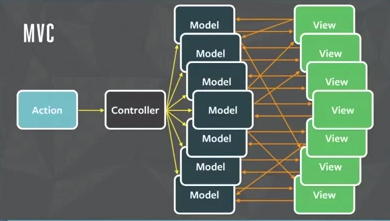

Например, почему от вьюх идут стрелки к моделям, хотя должны идти к контроллерам? Ну и вообще, почему на второй картинке остался только 1 View? Будь их там побольше, оно выглядело бы так же запутанно.
В итоге они взяли всё тот же MVC (одну из вариаций), только назвали его по-другому.
Может я что-то не понимаю, но в чём отличие от флакса от классического MVC? Там модель содержит всю логику и оповещает подписавшиеся на неё вьюхи о изменениях в своих данных. Там почти такой же однонаправленный поток данных: от модели ко вьюхам. Никакого двунаправленного связывания, от которого многие не в восторге. А действия пользователя всё так же идут от вью через контроллеры к моделям (или другим контроллерам).
Да и автор, по-сути, опять пересказал старый добрый MVC.
Ну и второй коммент в этой статье доставляет)
Ну и не забываем, что это все от парней, которые не осилили написать френд-ленту и сказали, что HTML5 сосет по производительности.
Ещё вспомнился давний пост на хабре, где FB превозмогал ограничения андроида на количество классов. Вот только они в своё приложение хотели запихнуть почти всё (помню оно ужасно тормозило и выжирало кучу памяти, так что я его снёс и больше не трогал). При этом, приложение ВК с почти аналогичным функционалом работало отлично.
Опять сами создали себе проблему и опять героически боролись с ней. Ну хоть делом заняты…
Опять сами создали себе проблему и опять героически боролись с ней. Ну хоть делом заняты…
По поводу мотивации Facebook в создании React/Flux/GraphQL согласен — мотивация о немасштабируемости MVC мне кажется слабоватой, чтобы переходить на GraphQL, с которым вопросов куда больше чем ответов.
По поводу данной конкретной статьи — в том и прелесть идеи автора, что без существенного слома можно получить плюшки.
Возможно тут дело просто в личной боли каждого. У меня за душой есть здоровенный пожилой проект, который еще не смертельно, но уже страдает от сложности. Изучая, к примеру, грядущие Angular 2 и Aurelia, я не смог увидеть, в чем они мороку с этим приложением помогут уменьшить. А пока читал оригинал этой статьи — несколько решений в голову сами собой пришли. И это без всяких переходов на новые фреймворки.
По поводу данной конкретной статьи — в том и прелесть идеи автора, что без существенного слома можно получить плюшки.
Возможно тут дело просто в личной боли каждого. У меня за душой есть здоровенный пожилой проект, который еще не смертельно, но уже страдает от сложности. Изучая, к примеру, грядущие Angular 2 и Aurelia, я не смог увидеть, в чем они мороку с этим приложением помогут уменьшить. А пока читал оригинал этой статьи — несколько решений в голову сами собой пришли. И это без всяких переходов на новые фреймворки.
Почитайте стандарт jsonapi.org, они в принципе весьма красиво решили проблемы «графов» и связанных ресурсов.
По поводу FLUX, что вы ответите на такое: FLUX это ничто иное как православный MVC (79-ого года, когда контроллер ничего не знал о view толком) + Event Sourcing? А так как Event Sourcing это деталь реализации модели — то это просто старый добрый MVC. И мотивация в введении понятия Flux как по мне — устранение разночтений. Интерпритаций и видоизменений MVC уже как грязи, и большая часть похоже на вот эту картинку «неправильного MVC». Потому лучше просто описать «правильное» и переименовать. И вот эту мысль я поддерживаю. А введение event sourcing — это более чем логично когда отслеживание состояния приложения это проблема. Нет состояния — нет проблем.
По поводу FLUX, что вы ответите на такое: FLUX это ничто иное как православный MVC (79-ого года, когда контроллер ничего не знал о view толком) + Event Sourcing? А так как Event Sourcing это деталь реализации модели — то это просто старый добрый MVC. И мотивация в введении понятия Flux как по мне — устранение разночтений. Интерпритаций и видоизменений MVC уже как грязи, и большая часть похоже на вот эту картинку «неправильного MVC». Потому лучше просто описать «правильное» и переименовать. И вот эту мысль я поддерживаю. А введение event sourcing — это более чем логично когда отслеживание состояния приложения это проблема. Нет состояния — нет проблем.
Я больше не использую Wordpress — я могу получить лучшее от технологий HTML5 и CSS3 с тем же уровнем затрат (или меньшим).
На этом месте словил очередной WTF.
Неоднозначные ощущения от прочтения, вроде бы кое-где и мысли правильные озвучиваются и в то же самое время множество моментов с которыми если нельзя согласиться, то вообще непонятно зачем.
Лично мне статья показалась скорее попыткой под другим углом взглянуть на MVC.
Рекомендую еще немного повернуть угл и посмотреть на развитие идей вокруг MVC на протяжении времени. Вообще разбираться в чем-то проще, если знать как шла мысль.
<perfection_mode>Даже оригинал применил не-букву ударения ( ’, ´, не апостроф), поэтому формально замечание верно, в JS не работает, а с таким символом не было бы формального замечания:
И тогда в JS это работает как переменная.
Вообще, штрих — это из численных методов математики, там это обозначает следующую итерацию переменной. Ну а JS не обязан соблюдать синтаксис формул численных методов, хотя может, если поискать букву-штрих среди юникодов.
</perfection_mode>
data̕ = 5; // символ "запятая сверху справа" - ̕
И тогда в JS это работает как переменная.
Вообще, штрих — это из численных методов математики, там это обозначает следующую итерацию переменной. Ну а JS не обязан соблюдать синтаксис формул численных методов, хотя может, если поискать букву-штрих среди юникодов.
</perfection_mode>
Транслейшен с English ужасен. Тут какбе следует understand, что те, кто знает English, лучше прочитают статью на English; а те, кто не знает, будут посылать икательные рефлексы переводчику, every time натыкаясь на English вордс.
Да. Согласен, что далеко не идеал )
Изначально пытался писать как можно больше на русском, но мешанина из «действий», «представлений» и «представлений состояний» получалась такой, что я сам с трудом читал написанное.
Если писать «экшен», «вью» и т.д., то те, кто не знает английский вряд ли будут сильно счастливее.
Поэтому решил все-таки устоявшиеся термины писать на английском.
Изначально пытался писать как можно больше на русском, но мешанина из «действий», «представлений» и «представлений состояний» получалась такой, что я сам с трудом читал написанное.
Если писать «экшен», «вью» и т.д., то те, кто не знает английский вряд ли будут сильно счастливее.
Поэтому решил все-таки устоявшиеся термины писать на английском.
А мне понравился перевод, ничего не смутило.
почему тогда в тексте остались conserns, side effects?
Сoncern при переводе на русский язык плохо отделяется от responsibility. Мне неизвестны устоявшиеся русские переводы этих слов в среде разработчиков, которые бы четко отделяли одно от другого. То же самое касается, к примеру, cohesion и coupling.
По поводу side effect — никогда не слышал чтобы разработчики употребляли термин «побочный эффект» или «сторонний эффект».
Ну и оба термина часто используются разработчиками в речи без перевода.
По поводу side effect — никогда не слышал чтобы разработчики употребляли термин «побочный эффект» или «сторонний эффект».
Ну и оба термина часто используются разработчиками в речи без перевода.
к примеру, cohesion и coupling.
Зацепление и связанность, или внутренняя и внешнаяя связаность, если уж по смыслу подбирать. В нашем случае можно было бы перевести concerns как область ответственности, а responsibility — ответственность. Мы же не гугл транслейт, нам главное просто смысл передать а не дословно переводить.
разработчики употребляли термин «побочный эффект» или «сторонний эффект».
У вас выборка не репрезентативна. Эти слова очень даже хорошо переводятся и при этом смысл не теряется.
Разработчики говорят сайд-эффекты, но все поймут если написать «побочный эффект». Вам же не приходит в голову писать дошь (или dosh :), вместо дождь, из за того что большинство так говорит в разговорной речи.
Расскажите автору про Object.assign() или какой-нибудь другой способ слияния объектов. А то трудно серьёзно воспринимать человека, который ещё пишет как на рисунке 1.
{kind=link}
Кстати, функция, которую написал автор, еще и не является чистой…
Почему?
var s = { };
theme.slider(s);
console.log(s); // wat?!
¯ \ _ (ツ) _ / ¯
Я не знаю джаваскрипта, предполагал что там аргументы по значению передаются.
Я не знаю джаваскрипта, предполагал что там аргументы по значению передаются.
Так и есть, они передаются по значению. Но они — объекты. Внутренности объекта не копируются, а разделяются между разными ссылками на него.
что переводится как «объекты передаются по ссылке всегда».
Нет, не по ссылке:
Если бы объекты передавались по ссылке — в консоли бы оказалось 10.
function foo (x) {
x = { a: 10 };
}
var s = { a: 5 };
foo(s);
console.log(s.a); // 5
Если бы объекты передавались по ссылке — в консоли бы оказалось 10.
Объекты передаются как раз по ссылке. А вот ссылка на объект передается по значению.
UFO just landed and posted this here
Переменная в динамическом языке является не лексической ссылкой (нет отдельного этапа компиляции, преобразовывающей имена в адреса, это происходит в рантайме), а именно переменной, которая занимает определённое количество памяти и хранит в себе значение (даже если это значение — undefined). Присвоение объекта переменной в JS — это рантаймная операция, в переменную попадёт ссылка на присвоенный объект, а не просто «возникнет имя у объекта». Вероятно, вы говорили о C++, а не JS.
Я тут имел в виду не только JS. В некоторых языках можно ссылку передавать по ссылке, например в C# с использованием ref.
Да, ваш пример показывает огромную пропасть в понимании определения «ссылка».
Но ведь вы в функции делаете переприсвоение x = { a: 10 }, следовательно создается новая ссылка. Если же делать так:
то в s.a будет 10
function foo (x) {
x.a = 10;
}
то в s.a будет 10
function foo(x) {
x.a = 10
}
var s = { a: 5 }
foo(s)
console.log(s.a)
Днище
Вот развёрнутый ответ на ваш вопрос http://dmitrysoshnikov.com/ecmascript/ru-chapter-8-evaluation-strategy/ — Тонкости ECMA-262-3. Часть 8. Стратегия передачи параметров в функцию.
<perfection_mode>Опять же, формально придирка верная, и обычно здесь пишут var arg1 = obj.arg1 ||
Но почему написано так — очевидно, эта конструкция подменяет es6-конструкцию «default args» и аргумент у вызова этой функции — всегда натуральный именованный список, не переменная (т.е. типа f({arg1:'val1', arg2:'val2'}).
Если вообще отойти от es5 и удариться в es6-запись (потому что альтернатива Object.assign() — из той же оперы), то определяли бы функкцию в виде
а если считать, что необходимость именованного списка в es3-5 была как раз вызвана отсутствием значений аргументов по умолчанию — то вообще
"arg1_default";Но почему написано так — очевидно, эта конструкция подменяет es6-конструкцию «default args» и аргумент у вызова этой функции — всегда натуральный именованный список, не переменная (т.е. типа f({arg1:'val1', arg2:'val2'}).
Если вообще отойти от es5 и удариться в es6-запись (потому что альтернатива Object.assign() — из той же оперы), то определяли бы функкцию в виде
function f(obj = {arg1:'default_val1', arg2:'default_val2'}){...}
а если считать, что необходимость именованного списка в es3-5 была как раз вызвана отсутствием значений аргументов по умолчанию — то вообще
function f(arg1='default_val1', arg2='default_val2', ...){...}
Всю статью можно ужать в одно предложение: «Наши девелоперы за… ли меня, и я решил, что так больше продолжаться не может».
Как уже было сказано ранее, проблемы в MVC нет, есть проблема в девелоперах.
Как уже было сказано ранее, проблемы в MVC нет, есть проблема в девелоперах.
Как уже писал выше, если бы не было проблем с MVC, то Facebook не изобретал бы Flux и GraphQL.
Речь же не о том, что MVC безоговорочно фигня и все — не используем. До какого-то предела сложности он отлично работает. Начиная с какого-то предела уже приходится искать альтернативы. Каждому гвоздю свой молоток.
Речь же не о том, что MVC безоговорочно фигня и все — не используем. До какого-то предела сложности он отлично работает. Начиная с какого-то предела уже приходится искать альтернативы. Каждому гвоздю свой молоток.
У фейсбука проблемы с MVC, потому что они делают с ним что-то не то, судя по иллюстрациям в этой статье.
Предлагаю гипотезу. У Фейсбука осложнения потому, что их главные архитекторы очень сильно подсели на PHP (или на страх о переходе с него на что-то другое). Они даже компилятор PHP написали, боясь потерять свой код. И реактивная концепция, согласно этой гипотезе, к ним пришла не из FP, а именно из PHP. Чистая функция render в JSX — это квинтэссенция подхода PHP («отрисовать страницу и умереть, не заботясь о менеджменте ресурсов»), а не принцип из FP. И именно потому, как мне думается, Redux (который кажется естественным продолжением «Реакта как FP-концепции») родился не в Фейсбуке.
Предлагаю вам другую гипотизу. Проекты масштабов Facebook могут позволить себе любое безумие, лишь бы быть экономически эффективными и продолжать быстро впиливать новые фичи. Помимо PHP, HHVM (между прочим они почти все на Hack пишут, что несколько не то же самое). И имея то же количество кода, что у ребят из фэйсбука, я думаю вы бы тоже передумали «переписывать» что-то.
Ммм, а в чем принципиальная разница? Чистая функция, извините, остается жить после того как вернула результат?
Чистая функция render в JSX — это квинтэссенция подхода PHP («отрисовать страницу и умереть, не заботясь о менеджменте ресурсов»)
Ммм, а в чем принципиальная разница? Чистая функция, извините, остается жить после того как вернула результат?
> вы бы тоже передумали «переписывать» что-то
Я же не говорил, что они поступают нецелесообразно. Страх перед уходом от PHP вполне может быть следствием финансового планирования. Или вы решили, что я PHP не люблю?
> а в чем принципиальная разница?
Никакой принципиальной разницы. В этом, вроде бы, мой тезис и заключался.
Я же не говорил, что они поступают нецелесообразно. Страх перед уходом от PHP вполне может быть следствием финансового планирования. Или вы решили, что я PHP не люблю?
> а в чем принципиальная разница?
Никакой принципиальной разницы. В этом, вроде бы, мой тезис и заключался.
тяжело сказать, хорошую ли идею двигает автор, так как с первого прочтения въехал не до конца, буду перечитывать.
но по тому, во что въехал
1) главный императив — борьба со сложностью, пока мне кажется решение излишне сложным
2) ок, что делать с сайд эффектами? во фронтенде их уйма, да и к тому же многое асинхронно
но по тому, во что въехал
1) главный императив — борьба со сложностью, пока мне кажется решение излишне сложным
2) ок, что делать с сайд эффектами? во фронтенде их уйма, да и к тому же многое асинхронно
Нет никаких «состояний».
Как только кто-то говорит «статус», моя рука тянется к пистолету. Любой статус — это просто функция от полной истории!
Как только кто-то говорит «статус», моя рука тянется к пистолету. Любой статус — это просто функция от полной истории!
Почему было бы просто и понятно не изложить в чем суть проблемы? Девелоперы приходят — это конечно серьезная проблема, но не очень внятная. Отсюда и решение проблемы такое же не внятное. Хотя, если честно, то объяснения в статье я тоже понял не до конца. Кто-нибудь может сказать в двух словах, чем то, что описывает автор, отличается от mvc?
Когда уже допилят webasm и весь это зоопарк отправится в компостную яму?
Awww, вы думаете, что с приходом WASM количество говнякеров во фронтенде уменьшиться? Раньше порог входа в JS (небольшой, но все же) хоть как-то ограничивал число желающих, а теперь фронтенд-фреймворки будут писать еще и на всем остальном.
с приходом webasm зоопарк только быстрее начнет размножаться. И это хорошо, потому как пока мы не достигли того уровня энтропии, когда разработчики наконец перестаную велосипеды делать и начнут наконец делом заниматься.
в целом же webasm позволит нам просто портировать узкие части системы написанные на языках типа Си для выполнения оных в браузере. Самый пожалуй показательный пример — pdf.js, или же многочисленные библиотеки для работы с DSP и т.д.
в целом же webasm позволит нам просто портировать узкие части системы написанные на языках типа Си для выполнения оных в браузере. Самый пожалуй показательный пример — pdf.js, или же многочисленные библиотеки для работы с DSP и т.д.
Не дочитал статью, остановился на том, как вместа синтаксиса вьюхи он придумал оборачивать вьюху в «чистый js» или что-то вроде. Ну да неважно, я другого понять не могу:
Он пишет, что проблема в том, что каждый хмырь требует от сервера отдавать данные в своем формате. Одному так, другому эдак, третьему по-другому поле назови в ответном json'e. Ну так надо собрать всех разрабов — фронта и мобил — и договориться, в каком виде отдавать данные. А кто после начинает придумывать «а давай тут поле переименуем» — по рукам давать.
Проблема решена. При чем тут mvc? Куда-то его непонятно куда унесло в своих рассуждениях, стоит дочитывать статью?
Он пишет, что проблема в том, что каждый хмырь требует от сервера отдавать данные в своем формате. Одному так, другому эдак, третьему по-другому поле назови в ответном json'e. Ну так надо собрать всех разрабов — фронта и мобил — и договориться, в каком виде отдавать данные. А кто после начинает придумывать «а давай тут поле переименуем» — по рукам давать.
Проблема решена. При чем тут mvc? Куда-то его непонятно куда унесло в своих рассуждениях, стоит дочитывать статью?
Те же мысли вышли и у меня. Автор пытался «решить» проблему взаимодействия членов команды (по другому это не назвать) обвиняя инструменты, которые используют разработчики. Вот как-то у меня не возникает таких проблем, и я обычно пишу апишки не привязываясь к UI. Если кто-то начинает говорить мол «так удобнее одним запросом выбрать», я объясняю что лучше сделать 3 паралельных запроса. Однако у других разработчиков встречал такое — просто не могут отстаивать свое мнение, что по итогу приводит к очень странным апишкам, потому что ее проектирует фронтэндер исходя именно из UI.
Пишу бэкэнд для фронтэндщиков и мобильщиков 5 лет, требую апишки от бэкэндщиков 3 года.
p.s. Поясню на всякий случай почему сделать 3 паралельных запроса эффективнее чем сделать один. Дело в том, что в linux системах (а наши сервера на нем крутятся), имеют буфер отправленных пакетов на каждое соединение. То есть мы можем послать до 10-ти пакетов (зависит от настроек ядра, но по умолчанию 10) не дожидаясь подтверждения о доставке. Как правило размер пакета ограничен MTU, который обычно равен 1500 байт. Итого, не дожидаясь подтверждения от клиента мы можем отправить аж 15Кб. Если контент ответа с сервера не умещается в 15 килобайт, то тогда следующую пачку данных мы сможем отправить только когда нам придет подтверждение о доставке наших пакетов. А это, в зависимости от лэтенси, довольно много времени.
Итого, 3 ответа по 15 килобайт, придут, в большинстве случаев, быстрее, чем 1 ответ в 45 килобайт.
Пишу бэкэнд для фронтэндщиков и мобильщиков 5 лет, требую апишки от бэкэндщиков 3 года.
p.s. Поясню на всякий случай почему сделать 3 паралельных запроса эффективнее чем сделать один. Дело в том, что в linux системах (а наши сервера на нем крутятся), имеют буфер отправленных пакетов на каждое соединение. То есть мы можем послать до 10-ти пакетов (зависит от настроек ядра, но по умолчанию 10) не дожидаясь подтверждения о доставке. Как правило размер пакета ограничен MTU, который обычно равен 1500 байт. Итого, не дожидаясь подтверждения от клиента мы можем отправить аж 15Кб. Если контент ответа с сервера не умещается в 15 килобайт, то тогда следующую пачку данных мы сможем отправить только когда нам придет подтверждение о доставке наших пакетов. А это, в зависимости от лэтенси, довольно много времени.
Итого, 3 ответа по 15 килобайт, придут, в большинстве случаев, быстрее, чем 1 ответ в 45 килобайт.
Это все работает пока у нас не больше 3х клиентов, одновременно беспокоящих сервер :)
Но для ненагруженных серверов так и есть, причем не только в Линуксе.
Но для ненагруженных серверов так и есть, причем не только в Линуксе.
Всё зависит от того, как принимаются решения. Если есть архитектор, то решения принимаются быстро, хоть и не всегда оптимально. Если у вас скрамный скрам с "равноправием", то обсуждение какой-нибудь мелочи может затянуться на несколько дней, что контрпродуктивно.
История из жизни. На одном проекте, где я разрабатывал апи, было очень сложно убедить мобильщиков чуть поднапрячься и реализовать полноценные модели, абстрагирующие от протокола. Ведь это так просто — дёрнуть по ресту ручку и получить все необходимые данные в виде готовых вложенных структур. Используемый ими фреймворк очень поощрял такой подход. Аргументы про экспоненциальный рост дублирования в выдаче, затирание изменений при конкурентной записи, отметались простыми "никто так не делает" и "зачем ты так всё усложняешь?". В итоге, мне всё же удалось отстоять несколько ключевых моментов (плоская выдача вместо иерархической, апдейты диффами), но не потому, что убедил, а потому что они сдались и затаили обиду. Было бы у меня чуть меньше авторитета, пришлось бы сдаваться уже мне, и пилить "традиционный апи" с традиционными же детскими болезнями, а потом через год всё равно перепиливать.
История из жизни. На одном проекте, где я разрабатывал апи, было очень сложно убедить мобильщиков чуть поднапрячься и реализовать полноценные модели, абстрагирующие от протокола. Ведь это так просто — дёрнуть по ресту ручку и получить все необходимые данные в виде готовых вложенных структур. Используемый ими фреймворк очень поощрял такой подход. Аргументы про экспоненциальный рост дублирования в выдаче, затирание изменений при конкурентной записи, отметались простыми "никто так не делает" и "зачем ты так всё усложняешь?". В итоге, мне всё же удалось отстоять несколько ключевых моментов (плоская выдача вместо иерархической, апдейты диффами), но не потому, что убедил, а потому что они сдались и затаили обиду. Было бы у меня чуть меньше авторитета, пришлось бы сдаваться уже мне, и пилить "традиционный апи" с традиционными же детскими болезнями, а потом через год всё равно перепиливать.
Если есть архитектор, то решения принимаются быстро
Я категорически против позиции "архитектор" в компании, ибо это абсолютно непродуктивный способ делать дела. Оно оправдано в очень небольшом проценте случаев.
Если у вас скрамный скрам с «равноправием»
Скрамный скрам, канбаны и прочая "гибкая" фигня говорит нам лишь о том, что команда сама себя сорганизует. То есть то что демократия не отменяет того, что у кого-то авторитетность мнения будет выше, и кто-то станет на проекте лидом. И если этот лид адекватный, все будет весьма и весьма продуктивно. Опять же в случае спорных моментов, просто можно сдлеать оценку двух вариантов, оценить риски и вперед эксперементировать с наиболее оптимальным вариантом.
плоская выдача вместо иерархической, апдейты диффами
А можете накидать аргументов за плоскую выдачу? А то я что-то как-то сдался в этом плане, ибо не смог придумать минусов достойных. Ну мол, мне и самому удобнее в некоторых случаях делать вложенность, особенно если ресурс весьма жирный (у меня был случай с каталогом где у ресурса выходило бы 400 свойств, и в итоге я раздробил это на отдельные объекты, что бы было удобнее работать).
Мне не очень нравится динамическая структура ответов (например как в jsonapi) ибо вызывает проблемы. в частности на android, но...
что до патчей… справедливости ради, это сильно усложняет реализацию на клиенте, во всяком случае сказывается отсутствие адекватных решений (хотя не надо верить мне наслово, ресерчил где-то года полтора назад, надо будет повторить). В подавляющем большинстве случаев хватает PUT + ETag и т.д. В моей практике было не так много проектов, где приходилось быть писсемистом, и лепить полноценные diff-ы. В одном из таких случаев мы и на бэкэнде использовали event sourcing, невилировать вероятность потери данных.
Оно конечно правильнее так, через Patch с коллекцией действий, или хотя бы diff ресурса, но подобное усложнение надо применять исходя из требований к проекту.
Все люди разные, с разным опытом, разным взглядом на идеальную архитектуру. Договориться порой очень сложно. И приведение казалось бы железных аргументов не всегда помогает. Всё скатывается в голосование большинством. Да, можно избрать архитектора, но и архитектором станет лишь тот, кто не противоречит мнению большинства. А будешь сильно возражать — большинство скажет, что не хочет с тобой работать, так как "ты всё время споришь, тормозя работу". Демократия не помогает достичь лучшего решения, только посредственного. Поэтому и нужен человек с опытом и рациональным мышлением для принятия окончательного решения. Как найти/выявить такого человека — вопрос отдельный. Но точно не голосованием.
Касательно плоской выдачи, приведу пример из жизни. На одном проекте было дерево тэгов и выводилось оно наиболее естественным способом — json со вложенными структурами. Всё было хорошо, пока клиенты не стали жаловаться, что у них всё тормозит. Стали разбираться. Оказалось, что у некоторых клиентов при сравнительно небольших деревьях, выдача получалась просто огромной. А всё потому, что один тэг мог быть сразу в двух других и соответствующие поддеревья выдавались в двух местах. Таким образом, у активно пользующихся тэгами клиентов, выдача дерева тэгов росла экспоненциально. Чтобы сформировать эту выдачу серверу приходилось тратить кучу времени и памяти, чтобы транслировать плоский список моделей в json-дерево. Да и на клиенте работать с голым json не особо удобно, поэтому первое, что делал клиент — рекурсивно пробегался по json и собирал дерево объектов с перекрёстными ссылками. Отказ от иерархической выдачи позволил заменить на клиенте рекурсивный обход итерированием по массиву; на сервере позволил заменить сложный алгоритм формирования дерева тривиальной выдачей списка; ну и в целом всё стало работать куда быстрее и кушать меньше трафика.
Диффы разные бывают. В частности, мы остановились на диффах такого плана:
Это означает, что в список favorite перед "alice" необходимо добавить "mary". Но можно и полностью затирать свойство, просто не указывая его в "prev":
Фактически мы пол дня спорили о том, чтобы мобильщики писали
Касательно плоской выдачи, приведу пример из жизни. На одном проекте было дерево тэгов и выводилось оно наиболее естественным способом — json со вложенными структурами. Всё было хорошо, пока клиенты не стали жаловаться, что у них всё тормозит. Стали разбираться. Оказалось, что у некоторых клиентов при сравнительно небольших деревьях, выдача получалась просто огромной. А всё потому, что один тэг мог быть сразу в двух других и соответствующие поддеревья выдавались в двух местах. Таким образом, у активно пользующихся тэгами клиентов, выдача дерева тэгов росла экспоненциально. Чтобы сформировать эту выдачу серверу приходилось тратить кучу времени и памяти, чтобы транслировать плоский список моделей в json-дерево. Да и на клиенте работать с голым json не особо удобно, поэтому первое, что делал клиент — рекурсивно пробегался по json и собирал дерево объектов с перекрёстными ссылками. Отказ от иерархической выдачи позволил заменить на клиенте рекурсивный обход итерированием по массиву; на сервере позволил заменить сложный алгоритм формирования дерева тривиальной выдачей списка; ну и в целом всё стало работать куда быстрее и кушать меньше трафика.
Диффы разные бывают. В частности, мы остановились на диффах такого плана:
{
"next" : { favorite : [ "mary" , "alice" ] },
"prev" : { favorite : [ "alice" ] }
}Это означает, что в список favorite перед "alice" необходимо добавить "mary". Но можно и полностью затирать свойство, просто не указывая его в "prev":
{
"next" : { favorite : [ "mary" , "alice" ] },
"prev" : {}
}Фактически мы пол дня спорили о том, чтобы мобильщики писали
{ "next" : {...} } вместо {...}, чтобы потом можно было легко прикрутить диффы, не ломая апи. :-DЕщё есть классный паттерн — uri в качестве идентификатора. Но его отстоять тогда не удалось, к сожалению.
// GET /search=MVC/proj=habr?fetch=name,found(name,tag,prof(name))
{
"search=MVC/proj=habr" : {
"name" : "MVC",
"found" : [ "post=277113" , "user=lair" ]
},
"post=277113" : {
"name" : "Почему я больше не использую MVC-фреймворки",
"tag" : [ "tag=web-разработка", "tag=angularjs", "tag=javascript", "tag=patterns" ]
},
"user=lair" : {
"name" : "Сергей Роговцев",
"prof" : [ "prof=architect" ]
}
"prof=architect" : {
"name" : "Архитектор"
}
}uri в качестве идентификатора
URI — Uniform Resource Identifier. Ну то есть это как бы, даже не паттерн, это просто использование URI по назначению.
Есть такая штука как HATEOAS, то что вы привели выше сильно смахивает на эту штуку, но в слегка извращенной форме.
Именно так. Тогда получается гибкий и самоописывающийся формат. А не так, что нужно взять идентификатор, сформировать из него URL по шаблону и только тогда можно запросить ресурс.
HATEOAS — несколько неудобная реализация той же идеи.
HATEOAS — несколько неудобная реализация той же идеи.
в слегка извращенной форме
Я бы сказал даже не слегка.
Не развернёте свою мысль?
В приведенном примере нет ни настоящих адресов, ни настоящих ссылок (если есть, то они неопознаваемы). Даже если оставить за скобками собственно состояние, ради которого HATEOAS придумывается, как пользоваться этими недоссылками, если это вообще ссылки — непонятно. Честный же гиперлинкинг предполагает в минимальной своей форме — ссылку, которую можно использовать напрямую, просто вставив ее в запрос, на следующем этапе появляются отношения, описываемые ссылками (и как раз в этот момент начинается самое интересное), на следующем этапе все это описывается формально (к сожалению, ни одного реального стандарта до сих пор нет, есть k конкурирующих).
(Ну и да, URI — это идентификатор ресурса в сети, использовать его внутри документа — отдельное неочевидное развлечение)
(Ну и да, URI — это идентификатор ресурса в сети, использовать его внутри документа — отдельное неочевидное развлечение)
В данном случае используется relative-uri (да, слэша вначале идентификаторов не хватает), чтобы не раздувать объём выдачи и не хардкодить конкретное имя сервера.
Это URL — идентификатор ресурса в сети, а URI — абстрактный идентификатор, который не всегда имеет к сети отношение.
Это URL — идентификатор ресурса в сети, а URI — абстрактный идентификатор, который не всегда имеет к сети отношение.
В данном случае используется relative-uri
Угу. Осталось понять, как об этом догадаться, и какая у него семантика.
Именно. Читать не хотят, а сами догадаться не могут. Вот и получается, что кругозор вырождается в точку зрения.
https://tools.ietf.org/html/rfc3986#section-4.2
https://tools.ietf.org/html/rfc3986#section-4.2
А толку-то с этого RFC? Он ничего о семантике и положении URI внутри вашего документа не скажет.
Что вы понимаете под "семантикой" и "положением URI внутри документа"?
Под семантикой я понимаю, как ни странно, семантику — то, какой смысл вкладывается в элемент. В приведенном вами примере есть набор строковых ключей, за каждым из которых лежит какой-то объект. Все эти ключи — равноправны, и понять, чем они друг от друга отличаются, из самого документа — нельзя.
Далее, если посмотреть на пример прищурившись, то можно увидеть, что часть этих ключей используется в других местах (например, в блоке
А уж догадаться, глядя на пример, что эти же идентификаторы можно впихнуть в запрос просто как часть пути — это отдельный челлендж. И я, кстати, до сих пор не уверен, что то, как они преобразуются из относительных в абсолютные, — это то, что вы задумывали.
Сравните с тем, как устроен, например, HAL.
Далее, если посмотреть на пример прищурившись, то можно увидеть, что часть этих ключей используется в других местах (например, в блоке
found), и наверное имеется в виду, что это — внутренние связи через идентификаторы. (Но есть и аналогичные по виду ключи — теги — которые нигде в документе больше не используются. А что с ними делать?) Но машина-то не умеет смотреть прищурившись, ей все надо объяснять. И поэтому, чтобы работать с вашим форматом, нужен специально написанный прикладной API, который будет знать, что в блоке found лежат идентификаторы, по которым надо забрать блоки с уровня выше, а потом в каких-то из них повторить аналогичные процедуры.А уж догадаться, глядя на пример, что эти же идентификаторы можно впихнуть в запрос просто как часть пути — это отдельный челлендж. И я, кстати, до сих пор не уверен, что то, как они преобразуются из относительных в абсолютные, — это то, что вы задумывали.
Сравните с тем, как устроен, например, HAL.
Под семантикой я понимаю, как ни странно, семантику — то, какой смысл вкладывается в элемент. В приведенном вами примере есть набор строковых ключей, за каждым из которых лежит какой-то объект. Все эти ключи — равноправны, и понять, чем они друг от друга отличаются, из самого документа — нельзя.
А как понять, что
"status": "shipped" — это одно из значений перечисления [ "shipped", "processing", "cancelled" ], а не произвольная строка? Для передачи семантики, необходима расширенная система типов (именованное перечисление, значение в заданной валюте, ссылка на сущность определённого типа и тд). В то же время JSON имеет ограниченную систему типов (строка, число, словарь, список, флаг, пустота). HAL же вводит лишь один единственный дополнительный тип "список ссылок на другие сущности". То есть не решает проблему систематично, а не понятно зачем вставляет частичный костыль. В результате, вместо того, чтобы писать просто:{
"status" : "processing",
"items": [ "box=123" , "letter=321" ]
}Или ещё проще и гибче:
status processing
items
box=123
letter=321Приходится писать сложно:
{
"_links": {
"items": [{
"href": "box=123"
},{
"href": "letter=321"
}]
}
"status" : "processing",
}И всё равно где-то в коде держать логику по преобразованию
status из строкового типа в элемент перечисления и обратно.Но есть и аналогичные по виду ключи — теги — которые нигде в документе больше не используются. А что с ними делать?
Их свойства не зафетчили — вот их и нет в выдаче.Давайте зафетчим и их:
// GET /search=MVC.proj=habr.type=post?fetch=name,found(name,tag(name,rating))
{
"search=MVC.proj=habr.type=post" : {
"name" : "MVC",
"found" : [ "post=277113" ]
},
"post=277113" : {
"name" : "Почему я больше не использую MVC-фреймворки",
"tag" : [ "tag=javascript", "tag=patterns" ]
},
"tag=javascript" : {
"name" : "javascript",
"rating" : 4
},
"tag=patterns" : {
"name" : "patterns",
"rating" : 5
},
}чтобы работать с вашим форматом, нужен специально написанный прикладной API, который будет знать, что в блоке found лежат идентификаторы, по которым надо забрать блоки с уровня выше, а потом в каких-то из них повторить аналогичные процедуры.
Это касается любого формата, будь то хоть HAL, хоть OData, хоть JSONAPI, — требуется адаптер, предоставляющий API для работы с протоколом.
А уж догадаться, глядя на пример, что эти же идентификаторы можно впихнуть в запрос просто как часть пути — это отдельный челлендж.
Давайте не будем играть в дурачка. Даже если вы принципиально не читаете документацию на то, чем пользуетесь, догадаться тут не сложно, что подстрока в ссылке соответствует подстроке в теле документа.
И я, кстати, до сих пор не уверен, что то, как они преобразуются из относительных в абсолютные, — это то, что вы задумывали.
Я вроде бы прямо сказал, что так и задумано. В соответствии со спецификацией.
А как понять, что «status»: «shipped» — это одно из значений перечисления [ «shipped», «processing», «cancelled» ], а не произвольная строка?
Никак. Но это и не семантика, внезапно. Семантика значения shipped — это status.
Для передачи семантики, необходима расширенная система типов
Вы путаете семантику с типизацией.
HAL же вводит лишь один единственный дополнительный тип «список ссылок на другие сущности». То есть не решает проблему систематично, а не понятно зачем вставляет частичный костыль.
HAL решает конкретную проблему — представления гипермедиа. Зачем ему решать все остальные?
Это касается любого формата, будь то хоть HAL, хоть OData, хоть JSONAPI, — требуется адаптер, предоставляющий API для работы с протоколом.
Вот только все эти форматы — они не прикладные, поэтому для них можно написать обобщенный обработчик, чем и ценно. И чем формализованнее правила, тем легче жить.
Я вроде бы прямо сказал, что так и задумано. В соответствии со спецификацией.
Ну то есть задумано, что когда я пойду по первому идентификатору (
search=MVC/proj=habr), не покидая контекст документа (/search=MVC/proj=habr), я попаду в /search=MVC/search=MVC/proj=habr, и так до бесконечности?Не вижу принципиальной разницы между "типизацией" и "семантикой" в данном контексте.
В том и проблема, что HAL — это костыль для частного случая. Но проблему в общем случае он не решает. А общее решение типа того, что я привёл, помогает и в этом частном случае.
Вы видимо не заметили моё замечание "да, слэша вначале идентификаторов не хватает". Как вариант — вместо слеша использовать, например, точки.
В том и проблема, что HAL — это костыль для частного случая. Но проблему в общем случае он не решает. А общее решение типа того, что я привёл, помогает и в этом частном случае.
Вы видимо не заметили моё замечание "да, слэша вначале идентификаторов не хватает". Как вариант — вместо слеша использовать, например, точки.
Не вижу принципиальной разницы между «типизацией» и «семантикой» в данном контексте.
А зря.
В том и проблема, что HAL — это костыль для частного случая.
Для HATEOAS — с которого начался разговор — это как раз не частный случай, а фундаментально необходимая информация.
А может это вы видите то, чего нет?
Это частный случай понимания смысла. Решается выдачей схемы. Как $metadata в OData.
Это частный случай понимания смысла. Решается выдачей схемы. Как $metadata в OData.
А может это вы видите то, чего нет?
Вряд ли. У
price и discount один и тот же тип (до тех пор, пока у вас не type-driven development, по крайней мере), но разная семантика.Решается выдачей схемы.
… и теперь нам надо придумывать парсер и интерпретатор для схемы вместо того, чтобы использовать зафиксированную в медиа-типе конвенцию. Избыточно.
Есть разные уровни семантики. И на разных уровнях они могут иметь как разный смысл, так и одинаковый. А типы просто гарантируют, что смысл не будет перепутан.
Не избыточно, а расширяемо. Вы как обычно переусложняете :-)
Не избыточно, а расширяемо. Вы как обычно переусложняете :-)
А типы просто гарантируют, что смысл не будет перепутан.
И как в приведенном примере типы гарантируют, что смысл не будет перепутан?
Не избыточно, а расширяемо. Вы как обычно переусложняете
Как раз наоборот: расширяемость без необходимости — это и есть переусложнение.
Если мы не вводим отдельные типы для price и discount то, очевидно, никак. В JSON с типами всё плохо, но мы уже об этом спорили в обсуждении формата Tree. JSON позволяет поднять уровень лишь через костыли в духе
Необходимость-то есть. А вот понимания этой необходимости зачастую нет, да. Это я вам как фронтенд разработчик заявляю — у нас есть острая необходимость знать схему запроса/ответа, причём здесь и сейчас, а не где-то там, в сторонке, на другом сервере, для другой версии, с корявым описанием.
{ _links": { "items": [{ "href": "box=123" }] } } — тут мы фактически вводим тип "ссылка", правда не конкретизируем ссылка это на какой тип. Просто динамическая ссылка на произвольную сущность.Необходимость-то есть. А вот понимания этой необходимости зачастую нет, да. Это я вам как фронтенд разработчик заявляю — у нас есть острая необходимость знать схему запроса/ответа, причём здесь и сейчас, а не где-то там, в сторонке, на другом сервере, для другой версии, с корявым описанием.
Если мы не вводим отдельные типы для price и discount то, очевидно, никак.
Вот поэтому типизация и отличается от семантики.
тут мы фактически вводим тип «ссылка», правда не конкретизируем ссылка это на какой тип
Это ссылка не на тип, а на ресурс. Там вообще могут быть не объекты.
Это я вам как фронтенд разработчик заявляю — у нас есть острая необходимость знать схему запроса/ответа,
О, уже необходимость схемы, а не необходимость расширяемости. А я вам отвечу: мне, как разработчику клиентской или серверной части при сервисном взаимодействии необходимо знать, что запрос/ответ совпадают с заранее определенной схемой, и схема самого запроса/ответа мне в этом контексте нужна слабо.
Тип — это формализованная семантика.
Ресурс какого-то типа. Давайте заканчивать этот очередной бессмысленный терминологический спор.
Расширяемой разработчиком схемы, а не выбитой в граните спецификации как HAL. Хорошо, наверно, жить в мире, где схемы никогда не меняются. ;-)
Ресурс какого-то типа. Давайте заканчивать этот очередной бессмысленный терминологический спор.
Расширяемой разработчиком схемы, а не выбитой в граните спецификации как HAL. Хорошо, наверно, жить в мире, где схемы никогда не меняются. ;-)
Тип — это формализованная семантика.
Далеко не во всех языках. В JS, например, точно не так.
Ресурс какого-то типа
А вот тип ресурса в HAL прекрасно указывается: пара атрибутов
type/profile.Расширяемой разработчиком схемы, а не выбитой в граните спецификации как HAL.
HAL специфицирует конкретную часть JSON-документа. Все прочие части вы вольны расширять как угодно. Вам не нравится HAL-овская трактовка ссылок? Окей, ваше дело. Предложите другую, семантически совпадающую с HATEOAS. Не нравится HATEOAS? Снова ваше дело, только что ж вы тогда удивляетесь, что о вашей реализации говорят, что она не HATEOAS?
Это от разработчика зависит а не языка.
Да, но это приходится указывать в каждой ссылке, вместо того, чтобы вынести это в схему.
Вот, что я говорю: "HATEOAS — несколько неудобная реализация той же идеи.". Я не считаю необходимым ссылки на другие ресурсы выделять как-то особо, относительно остальных типов.
Да, но это приходится указывать в каждой ссылке, вместо того, чтобы вынести это в схему.
Вот, что я говорю: "HATEOAS — несколько неудобная реализация той же идеи.". Я не считаю необходимым ссылки на другие ресурсы выделять как-то особо, относительно остальных типов.
Это от разработчика зависит а не языка.
Если в языке нет типов, то разработчик может упрыгаться, но ему ничего не поможет.
Да, но это приходится указывать в каждой ссылке, вместо того, чтобы вынести это в схему.
Зато каждая ссылка самодостаточна.
HATEOAS — несколько неудобная реализация той же идеи.
Какой "той же"?
Пользовательские типы есть везде. И в JS в том числе.
Чтобы она была полностью самодостаточна, можно тут же приложить ещё и содержимое ресурса, на который она ссылается. ;-)
Я и не утверждал, что у меня HATEOAS. Идея hypermedia.
Чтобы она была полностью самодостаточна, можно тут же приложить ещё и содержимое ресурса, на который она ссылается. ;-)
Я и не утверждал, что у меня HATEOAS. Идея hypermedia.
Пользовательские типы есть везде. И в JS в том числе.
Угу. Пожалуйста, выразите с помощью типов на JS следующее: у типа "заказ" есть два свойства: цена и скидка, каждое своего типа (т.е. значение цены нельзя присвоить в скидку, значение скидки нельзя присвоить в цену).
Чтобы она была полностью самодостаточна, можно тут же приложить ещё и содержимое ресурса, на который она ссылается.
Тогда она перестанет быть ссылкой и станет включенным ресурсом. Которые, что характерно, в HAL есть.
Я и не утверждал, что у меня HATEOAS.
Но зачем-то попросили объяснить, почему я тоже считаю, что у вас его нет.
class Scalar
{
constructor( value )
{
this.value = value
}
static ensure( value )
{
if( value instanceof this ) return value
throw new Error( 'Wrong type' )
}
}
class Price extends Scalar {}
class Discount extends Scalar {}
class Order()
{
_price = null
get price()
{
return this._price
}
set price( value )
{
this._price = Price.ensure( value )
}
_discount = null
get discount()
{
return this._discount
}
set discount( value )
{
this._discount = Discount.ensure( value )
}
}
var order = new Order
order.price = new Price
order.discount = order.priceОбъявления свойств можно упростить до:
class Order()
{
@Price.prop()
_price = null
@Discount.prop()
_discount = null
}Не стоит приписывать мне то, что я не говорил.
(а) Это JavaScript? Или все-таки ES6?
(б) вы не выразили нужное ограничение с помощью типов, вы были вынуждены написать в каждом свойстве проверку на совпадение (с равным успехом можно использовать тегированные структуры)
(б) вы не выразили нужное ограничение с помощью типов, вы были вынуждены написать в каждом свойстве проверку на совпадение (с равным успехом можно использовать тегированные структуры)
1) Версия языка не имеет значения, в рантайме они полностью совместимы.
2) Вам шашечки или ехать? Можете записать так, если очень хочется, чтобы было похоже на какой-нибудь C#:
2) Вам шашечки или ехать? Можете записать так, если очень хочется, чтобы было похоже на какой-нибудь C#:
class Order
{
@Price price = null
@Discount discount = null
}Вот, что я говорю: «HATEOAS — несколько неудобная реализация той же идеи.». Я не считаю необходимым ссылки на другие ресурсы выделять как-то особо, относительно остальных типов.
Anyway, мне не очень интересно, что вы думаете о HATEOAS, я комментировал тот факт, что у вас — не он.
чтобы не раздувать объём выдачи
gzip сверху и не нужно об этом париться.
По поводу "извращенности" — я могу понять обиды пользователей вашего API, поскольку нельзя просто взять и использовать API. Я не вижу профита конкретно в такой реализации, против обычных урлов. В случае урлов сервер полностью отвечает за то, где искать ресурсы. А тут выходит что клиент тоже должен что-то знать об этом.
Ну то есть сама идея более чем правильная, а вот реализация — заставляет писать велосипеды. А мне что-то как-то уже надоело велосипеды писать. Вот есть например jsonapi — вполне себе годный формат. Единственное что под android неудобно использовать, во всяком случае имеющаяся реализация под Java так себе.
Тут дело больше в удобстве отладки. Копипаста имени сервера только лишь создаёт визуальный шум.
Я же написал, что эту фичу не удалось протолкнуть. Так что в реальности было всё ещё хуже — клиенты брали идентификаторы сущностей вида "12345" и подставляли в шаблон вида
Вычисление абсолютной ссылки на основе относительной и базовой есть в любой библиотеке для работы со ссылками. Это базовая операция, которая должна применяться ко всем ссылкам из документа. Так устроен веб.
Я же написал, что эту фичу не удалось протолкнуть. Так что в реальности было всё ещё хуже — клиенты брали идентификаторы сущностей вида "12345" и подставляли в шаблон вида
https://example.com/person={personId}?fetch={fetchPlan}. Вычисление абсолютной ссылки на основе относительной и базовой есть в любой библиотеке для работы со ссылками. Это базовая операция, которая должна применяться ко всем ссылкам из документа. Так устроен веб.
Я тут запилил пример того, то я имею ввиду, правда с XML выдачей, но формат легко меняется на любой другой: http://nin-jin.github.io/harp=1/
UFO just landed and posted this here
Он не масштабируется под реальные приложения как Дэн любит утверждать. Давайте рассмотрим простой пример, объясняющий почему.
А кто ни будь понял почему? Я никаких объяснений не увидел. Поток сознания какой то.
Читая статью я сделал вывод что главное отличие в этом:
И выведенном далее отдельном state representation.
На всякий случай написал еще автору оригинальной статьи и попросил его сформулировать, в чем проблема масштабируемости. Как только он ответит — репостну сюда.
Другими словами, машины состояния не должны быть кортежами, соединяющими два состояния (S1, A, S2) каковыми они обычно являются. Они являются, скорее, кортежами форм (Sk, Ak1, Ak2,...) которые определяют все разрешенные Actions для состояния Sk с результирующим состоянием вычисляемым после того, как Action был применен к системе и Model обработал изменения.
И выведенном далее отдельном state representation.
На всякий случай написал еще автору оригинальной статьи и попросил его сформулировать, в чем проблема масштабируемости. Как только он ответит — репостну сюда.
UFO just landed and posted this here
Да, речь именно про finite state machine.
Комбинация с MVC и предлагается автором, то есть он предлагает оценить нашу систему с точки зрения состояний (выделить их в отдельный конструктив) и на их основе вычислять next-action predicate.
По поводу дерева каталогов и бесконечного количества состояний не совсем понял. Можете более развернуто описать? Я могу представить состояния к примеру, «редактируемый-нередактируемый», или «актуальный каталог-каталог в архиве», но бесконечного количества состояний я не могу представить.
Комбинация с MVC и предлагается автором, то есть он предлагает оценить нашу систему с точки зрения состояний (выделить их в отдельный конструктив) и на их основе вычислять next-action predicate.
По поводу дерева каталогов и бесконечного количества состояний не совсем понял. Можете более развернуто описать? Я могу представить состояния к примеру, «редактируемый-нередактируемый», или «актуальный каталог-каталог в архиве», но бесконечного количества состояний я не могу представить.
Автор ответил на вопрос по поводу масштабируемости:
Оригинал
There are a couple of reasons why Redux «does not scale to real-world applications» (which is an expression that Dan Abramov is using all the time to explain that Redux is so much better).
First, Redux cannot implement the simple rocket example because it does not have a «next-action-predicate», so when the counter is decremented and something has to decide what to do next, Redux, is powerless, some ugly code will show up in the reducer.
Second, Redux is coupling action/model inside the reducer. Let's say you trigger an action that increments a counter, all I suggest in SAM is that you factor the code in two steps:
a) an action (a pure function) hat given a dataset computes the proposed changes to the model
b) a method that mutates the model
The Redux reducer looks like this:
All I am saying, you need to write an action increment:
and then present the new value to the model which will choose to accept the proposed values:
In SAM the actions and the model updates are strictly decoupled, unlike Redux which encourages people to create a big ball of mud, for no particular reason, other than Dan using a naive interpretation of state machine semantics.
With SAM, actions are external to the model and as such can be reused across models and even implemented by third parties. In Redux, actions are merely intents. The implementation of the action is in the model (reducer). That is wrong.
First, Redux cannot implement the simple rocket example because it does not have a «next-action-predicate», so when the counter is decremented and something has to decide what to do next, Redux, is powerless, some ugly code will show up in the reducer.
Second, Redux is coupling action/model inside the reducer. Let's say you trigger an action that increments a counter, all I suggest in SAM is that you factor the code in two steps:
a) an action (a pure function) hat given a dataset computes the proposed changes to the model
b) a method that mutates the model
The Redux reducer looks like this:
case INCREMENT:
return state + 1;
All I am saying, you need to write an action increment:
function increment(data) {
data.counter = data.counter || 0 ;
data.counter += 1 ;
return data ;
}
and then present the new value to the model which will choose to accept the proposed values:
model.present = function(data) {
if (data.counter !== undefined) {
// can have some validation rules that decides whether
// that value is acceptable or not
model.counter = data.counter ;
}
}
In SAM the actions and the model updates are strictly decoupled, unlike Redux which encourages people to create a big ball of mud, for no particular reason, other than Dan using a naive interpretation of state machine semantics.
With SAM, actions are external to the model and as such can be reused across models and even implemented by third parties. In Redux, actions are merely intents. The implementation of the action is in the model (reducer). That is wrong.
Перевод
Есть несколько причин почему Redux “не масштабируется под реальные приложения” (это выражение, которое Дэн Абрамов постоянно использует чтобы объяснить, что Redux гораздо лучше)
Во-первых, Redux не в состоянии реализовать простой пример с ракетой, потому что он не имеет “next action predicate”. То есть когда счетчик уменьшается и нужно принять решение, что делать дальше, то Redux бессилен и в reducer появится какой-либо уродливый код.
Во-вторых, Redux связывает действия и модели внутри reducer. Предположим, вы вызываете действие которое увеличивает счетчик, все, что я предложил в SAM это что разделить код на два шага:
а) действие (чистая функция)
b) метод, который изменяет модель
Reducer в Redux выглядит следующим образом:
Все, что я утверждаю, это что вам необходимо написать действие инкрементации:
И после этого предоставить новой значение в Model, который решит, принять ли предлагаемое значение:
В SAM действия и обновления модели строго разделены, в отличие от Redux, который поощряет людей в создании big ball of mud (полагаю, автор про антипаттерн) без особых на то оснований, помимо этого Дэн использует наивную интерпретацию семантики машин состояний.
В SAM, действия являются внешними по отношению к Model и, как таковые, могут быть переиспользованы с другими Model-ами и даже быть реализованными третьей стороной. В Redux, действия это всего лишь намерения. Реализация действий находится в модели (reducer). Это неправильно.
Во-первых, Redux не в состоянии реализовать простой пример с ракетой, потому что он не имеет “next action predicate”. То есть когда счетчик уменьшается и нужно принять решение, что делать дальше, то Redux бессилен и в reducer появится какой-либо уродливый код.
Во-вторых, Redux связывает действия и модели внутри reducer. Предположим, вы вызываете действие которое увеличивает счетчик, все, что я предложил в SAM это что разделить код на два шага:
а) действие (чистая функция)
b) метод, который изменяет модель
Reducer в Redux выглядит следующим образом:
case INCREMENT:
return state + 1;
Все, что я утверждаю, это что вам необходимо написать действие инкрементации:
function increment(data) {
data.counter = data.counter || 0 ;
data.counter += 1 ;
return data ;
}
И после этого предоставить новой значение в Model, который решит, принять ли предлагаемое значение:
model.present = function(data) {
if (data.counter !== undefined) {
// can have some validation rules that decides whether
// that value is acceptable or not
model.counter = data.counter ;
}
}
В SAM действия и обновления модели строго разделены, в отличие от Redux, который поощряет людей в создании big ball of mud (полагаю, автор про антипаттерн) без особых на то оснований, помимо этого Дэн использует наивную интерпретацию семантики машин состояний.
В SAM, действия являются внешними по отношению к Model и, как таковые, могут быть переиспользованы с другими Model-ами и даже быть реализованными третьей стороной. В Redux, действия это всего лишь намерения. Реализация действий находится в модели (reducer). Это неправильно.
it does not have a «next-action-predicate», so when the counter is decremented and something has to decide what to do next, Redux, is powerless, some ugly code will show up in the reducer.
И что с того? Redux реализует концепцию event sourcing, нас интересует только цепочка действий а не конкретное состояние системы, его можно всегда вычислить. А это означает что наши редьюсеры можно переписать и полностью поменять модель, описывающую состояния системы в целом, при этом мы не теряем данные.
Redux is coupling action/model inside the reducer
Опять же, по сути redux это именно редьюсеры и ничего более. «экшены» — это команды, юзкейсы. Конечно же мы должны знать о них. По сути и редьюсеры и экшены это часть модели, детали ее реализации. Подробнее можно у Грэга Янга почитать/посмотреть лекции.
All I am saying, you need to write an action increment:
Это прямое нарушение идеи, заложенной в Redux, мы тут мутируем состояние, и теперь зависим от последовательности действий и от времени. Экшены ни в коем случае не должны мутировать состояния (как и контроллеры в MVC). Они должны «просить» модель сделать что-то, в нашем случае — экшены нужны что бы запомнить «что мы хотели сделать», а редьюсеры уже смогут вычислить состояния не основе цепочки действий. Декремент в этом случае это будет просто какая-то операция, но значения мы не будем сохранять, так как мы не знаем какое оно было изначально.
Это полностью устраняет любые проблемы асинхронных операций, так как все сводится к линейной коллекции действий над данными, и мы можем «проигрывать» их когда захотим, с возможностью восстанавливать предыдущее состояния и т.д.
Именно в этом смысл, если у нас нет прямых мутаций состояний (как в FSM) а только история переходов — то нет никаких проблем.
В MVC такая логика будет реализована в Controller, и, вероятно, вызываться по таймеру из View.
Что?! Таймер во View? Это в MVC? Это косяк перевода или там так и написано?
In MVC, that kind of logic would be implemented in the controller, perhaps triggered by a timer in the view.
Ну тут на самом деле вопрос. Если это чисто UI штука (т.е. через 10 секунд мы отправляем команду), то может быть и так.
Но если эти 10 секунд есть в предметной области (т.е. там «протяжка, предварительная, ключ на старт»), то таймер должен быть строго внутри модели.
Впрочем, я испорчен M-V-VM.
Всегда считал что что MVC в вебе — как на корове седло. Нет ничего естественнее компонентного подхода. Никаких API, никакой асинхронки (и уж тем более яваскриптового безумия в виде клиентских фреймворков), никаких проблем с сохранением состояния страницы после перезагрузки. И уж тем более нет необходимости изобретать мудреные конструкции аналогичные приведенным в статье.
никаких проблем с сохранением состояния страницы после перезагрузки.
Правда?
Разумеется нет — просто хотел всех обмануть.
Ну вот то-то и оно. Хранение состояния в вебе — одна из самых сложных задач (понятное дело, после инвалидации кэшей и именования).
это был сарказм. Не вижу ни малейших проблем с сохранением состояния (разумеется не в случае MVC). Но не собираюсь обсуждать с вами это по десятому кругу — у вас спорить на любую тему — это просто хобби.
Не вижу ни малейших проблем с сохранением состояния
Не видите? А как вы собираетесь хранить состояние в случае веб-фермы?
Если на вашей платформе что-то сложно реализуется, это говорит о проблеме в вашей архитектуре
вариантов масса — у .NET WebForms один способ, а например у Java Wicket другой — не вижу тут великой проблеммы
Не возьмусь утверждать за Wicket, а у WebForms с этим состоянием достаточное количество проблем, чтобы приходилось постоянно искать пути их решения.
именно с состоянием проблем нет.
Главная проблема WebForms — это как ни странно визуальный редактор. Изза него разрабу очень неудобно управлять стилями и элементами.
Поэтому в .net MVC никакого визуального построителя нет. Все что майкам надо было сделать — выкинуть редактор и оставить компонентную модель.
Главная проблема WebForms — это как ни странно визуальный редактор. Изза него разрабу очень неудобно управлять стилями и элементами.
Поэтому в .net MVC никакого визуального построителя нет. Все что майкам надо было сделать — выкинуть редактор и оставить компонентную модель.
разумеется не в случае MVC
За состояние в MVC полностью отвечает модель. Этот же слой инкапсулирует в себе всю логику по изменению состояния. C и V — только UI, через него мы только взаимодействуем с приложением, но они какак не должно влиять на состояние приложения (менять напрямую).
А если у нас за сохранение состояние отвечает отдельный объект (который на самом деле не один, за ним может быть целый слой, и может даже не один, но инкапсуляция же, контроллер этого не зает), то MVC на этот вопрос вообще не должно влиять.
А если у вас не вызывает проблем сохранение состояния, то вообще плевать какую мы архитектуру для UI используем.
речь о состоянии страницы в браузере — то есть о персистентности ее элементов после перезагрузки.
Именно эта проблема вынудила разрабов использовать клинтские фрейморки, асинхронные вызовы и прочую ересь что многократно усложнило разработку.
А на архитектуру не плевать. Если я выставил чекбокс (не связаный с персистентными данными модели а например в форме регистрации)на странице то в MVC я вынужден писать код по восстановлению его состояния на случай перезагрузки этой же страницы, например для вывода ошибки. А к примеру в WebForms такой необходимости нет — чекер никуда не сбросится.
Именно эта проблема вынудила разрабов использовать клинтские фрейморки, асинхронные вызовы и прочую ересь что многократно усложнило разработку.
А на архитектуру не плевать. Если я выставил чекбокс (не связаный с персистентными данными модели а например в форме регистрации)на странице то в MVC я вынужден писать код по восстановлению его состояния на случай перезагрузки этой же страницы, например для вывода ошибки. А к примеру в WebForms такой необходимости нет — чекер никуда не сбросится.
Именно эта проблема вынудила разрабов использовать клинтские фрейморки, асинхронные вызовы и прочую ересь что многократно усложнило разработку.
Нет, не эта — а желание ускорить отклик интерфейса на действия пользователя.
А к примеру в WebForms такой необходимости нет — чекер никуда не сбросится.
Никогда не задумывались, какой ценой?
Нет, не эта — а желание ускорить отклик интерфейса на действия пользователя.
а какие проблемы с откликом? Что интернет медленее работает если webforms или база данных? Или браузер медленнее рисует?
И как MVC ускоряет отклик?
Никогда не задумывались, какой ценой?
нет никакой цены и нет никаких проблем кроме связаных с разметкой которую вынуждены формировать под работу визуального редактора
а какие проблемы с откликом?
Ну так, раундтрип до сервера — это всегда дольше, чем локально обработать. Три, четыре, пять порядков.
Что интернет медленее работает если webforms или база данных?
Страница быстрее работает, если интернет не задействовать, как ни странно.
И как MVC ускоряет отклик?
Речь шла не об MVC, а о клиентских фреймворках и асинхронии.
(Но вообще конкретно между asp.net MVC и asp.net WebForms — MVC «в среднем» быстрее, потому что нет накладных расходов на избыточное состояние. Понятно, что можно WebForms заточить, но это требует больше усилий.)
нет никакой цены
Правда? Вы никогда не смотрели на размер передаваемого viewstate? На то, как выглядит клиентский HTML? На то, сколько событий вызывается при разборе и актуализации состояния?
а какие проблемы с откликом?А вы попробуйте использовать синхронные HTTP вызовы. Удивитесь.
как разработчик пробую и те и другие. разницы практически никакой.
вы удивитесь но на диалапе сейчас никто не сидит.
А вот если не просто асинхронка а еще и модные нынче клиентские фреймворки с сотнями евентов и биндингов то отклик однозначно больше, особенно на мобильных браузерах.
вы удивитесь но на диалапе сейчас никто не сидит.
А вот если не просто асинхронка а еще и модные нынче клиентские фреймворки с сотнями евентов и биндингов то отклик однозначно больше, особенно на мобильных браузерах.
А вот если не просто асинхронка а еще и модные нынче клиентские фреймворки с сотнями евентов и биндингов то отклик однозначно больше, особенно на мобильных браузерах.
У меня создается впечатление что вы просто не знаете о чем говорите. Что до "нет разницы между синхронными и асинхронными запросами" — попробуйте сделать синхронный ajax запрос и запустить анимацию одновременно. А если вам так не нравятся промисы/колбэки, так есть async/await.
try {
response = await myService.myAsyncCall()
} catch (e) {
// handle exception
}вообще то речь шла о клиенте.
если речь о сервере то в большинстве случаев ощутимого выиграша тоже нет.
данная конструкция исправляет кривую архитектуру IIS не более того.
но с учетом скорости передачи данных и рендеринга в браузере это не имеет значения для конечного пользователя. Разве что на очень высоко нагруженых проектах но такие проекты составляют слишком незначительную долю всех сайтов чтобы говорить о каких то типовых решениях .
если речь о сервере то в большинстве случаев ощутимого выиграша тоже нет.
данная конструкция исправляет кривую архитектуру IIS не более того.
но с учетом скорости передачи данных и рендеринга в браузере это не имеет значения для конечного пользователя. Разве что на очень высоко нагруженых проектах но такие проекты составляют слишком незначительную долю всех сайтов чтобы говорить о каких то типовых решениях .
вообще то речь шла о клиенте.
А я вам о чем?
если речь о сервере то в большинстве случаев ощутимого выиграша тоже нет.
Предлагаю вам эксперемент. Запустить ab на ваше node.js приложение которое делает "синхронные" вызовы. И посмотрите какое количество запросов просто отвалится.
данная конструкция исправляет кривую архитектуру IIS не более того.
Причем тут IIS?
Резюмирую — вы не знаете о чем говорите, раз не знаете что в JS уже можно пользоваться штуками вроде async/await.
так вот об ощутимом "выиграша", благодаря ему как раз становится возможной полноценная асинхронная работа с IO операциями в аспнете. Я специалист не сильно широкого круга, можете привести пожалуйста примеры асинхронных платформ для веба кроме ноджс?
вообще то смысл ноды изначально как раз однопоточная работа 0 асинзронное обращение с клиента не меняет сути дела нода там или нет
хотя строго говоря ajax это тоже не асинхронные вызовы — технически правильно — паралельные вызовы в фоновом режиме или как то так
а в яве проблем с асинхронкой не было никогда — любой сервлет работает в отдельном потоке в ява машине
то что происходит в аспнете это исправление работы iis который изначально работал как нода -в одном потоке.
точнее он работая щас в одном потоке может распаралеливать длинные операции. ну другие системы вообще не имели этих проблем
Не вижу тут великого достижения.
хотя строго говоря ajax это тоже не асинхронные вызовы — технически правильно — паралельные вызовы в фоновом режиме или как то так
а в яве проблем с асинхронкой не было никогда — любой сервлет работает в отдельном потоке в ява машине
то что происходит в аспнете это исправление работы iis который изначально работал как нода -в одном потоке.
точнее он работая щас в одном потоке может распаралеливать длинные операции. ну другие системы вообще не имели этих проблем
Не вижу тут великого достижения.
вообще то смысл ноды изначально как раз однопоточная работа
Нет, суть ноды была в том что бы запустить однопоточный event loop и организовать эффективную работу с I/O. А эффективная работа с I/O заключается в максимальной утилизации CPU, что возможно только в рамках одного потока и с использованием неблокирующих вызовов.
любой сервлет работает в отдельном потоке в ява машине
Погуглите про "переключение контекста". Именно по этой причине nginx работает на event loop, а не на потоках, несколько процессов-воркеров с event loop.
Но асинхронные сервлеты были ещё до ноды, как и NIO. И нода и NIO используют epoll (на линуксе), так что особо разницы нет.
А производительность, тем не менее, у java всё равно обычно выше даже при использовании обычных сервлетов без NIO.
А производительность, тем не менее, у java всё равно обычно выше даже при использовании обычных сервлетов без NIO.
как разработчик пробую и те и другие. разницы практически никакой.Практически?! Я как пользователь ненавижу таких разработчиков как вы.
вы удивитесь но на диалапе сейчас никто не сидит.У меня сейчас не самый худший интернет. Если посмотреть на загрузки на данной странице хабра, то одним из самых быстрых запросов окажется, например, ваша аватарка. 1.3кб за 45мс (403 ответ).
Конечно рядовой пользователь скорее всего и не заметит, что приложение не отвечает 45 миллисекунд после нажатия какой-либо кнопки. Но ощущения от приложения точно поменяются.
И при этом это самый маленький, требующий минимум серверной логики, запрос.
Конечно рядовой пользователь скорее всего и не заметит, что приложение не отвечает 45 миллисекунд после нажатия какой-либо кнопки. Но ощущения от приложения точно поменяются.
каким образом они поменяются если он не заметит?
и как асинхронка ускорила бы загрузку страницы хабра?
можно конено сделать чтобы коменты подтягивались как в фейсбуке но это резко усложнит разработку за что надо кому то платить, при том что как рядовой пользователь я не вижу никаких проблем с хабром. а вот если у меня на мобиле будет дико тупить браузер потому что на сайт навесили какой то ангуляр — уж точно буду матерится.
Отзывчивость интерфейса имеет большое значение.
С хабром нет никаких проблем. И, к слову, тут все запросы работают асинхронно.
Про комментарии в FB мне не понятно. Т.к. не пользуюсь этим медленным и неудобным сайтом.
В клиентском вебе всё асинхронное. Кому тут что платить за какую-то сложность? Признайтесь, вы просто очень далеки от данной темы.
Про ангуляр согласен. Он годится только для простых сайтов. Как только вам нужно сделать что-то посложнее тут же начинаются пляски с бубном.
С хабром нет никаких проблем. И, к слову, тут все запросы работают асинхронно.
Про комментарии в FB мне не понятно. Т.к. не пользуюсь этим медленным и неудобным сайтом.
В клиентском вебе всё асинхронное. Кому тут что платить за какую-то сложность? Признайтесь, вы просто очень далеки от данной темы.
Про ангуляр согласен. Он годится только для простых сайтов. Как только вам нужно сделать что-то посложнее тут же начинаются пляски с бубном.
и как асинхронка ускорила бы загрузку страницы хабра?
Очень просто: запросы не будут блокировать работу со страницей.
то есть о персистентности ее элементов после перезагрузки.
Какой перезагрузки? В том то и дело, что сейчас если мы хотим сделать юзер френдли сайт, то нам в первую очередь надо беспокоиться о его отзывчивости. Можете обвинять в этом мобильные приложения.
что многократно усложнило разработку.
На самом деле лишь уравновесило. Сейчас для процентов так 80% проектов апишку можно просто сгенерить. А для случаев посложнее, «отчищение» бэкэнда от обязанностей формирования представления для человека только упрощает дело (отдать json-структурку проще чем замэпить ее на HTML, учитывать всякие ajax и работать с формами). Чистая клиент-серверная архитектура.
Более того, это позволяет нам ускорить разработку, так как у двоих членов команды примерно одинаковый объем работ, и это означает что мы можем более гибко паралелить работу.
А на архитектуру не плевать.
Архитектура — это весьма емкое слово. Конкретно MVC мне больше нравится воспринимать как «прием» для отделения UI от приложения (если они отдельно друг от друга — у нас больше пространства для моневра опять же).
в MVC я вынужден писать код по восстановлению его состояния на случай перезагрузки этой же страницы, например для вывода ошибки.
Ммм… у меня закралось подозрение маленькое… Можете все же описать мне что такое это ваше MVC что оно так отличается от моего?
Парень наверное на state-less контроллеры намекает ;)
Заголовок спойлера
Который раз смотрю ваши коментарии и убеждаюсь, что тред с вашим коментом скатится в обсуждение какого-то древнего легаси с которым вы вынуждены работать. Что ж вы делаете то там???
Который раз смотрю ваши коментарии и убеждаюсь, что тред с вашим коментом скатится в обсуждение какого-то древнего легаси с которым вы вынуждены работать. Что ж вы делаете то там?
Вы меня ни с кем не путаете?
Всегда считал что что MVC в вебе — как на корове седло
Вы о каком именно MVC? Много их разных. Да и поскольку вариантов UI много (HTTP, MQ, CLI) отделить UI от самого приложения не кажется такой уж глупой идеей.
Нет ничего естественнее компонентного подход
Не вижу никаких противоречий с MVC. У каждого компонента своя модель, свое view и свой контроллер. С точки зрения этого компонента конечно. Если мы поднимимся на уровень выше, у нас будет много компонентов со своими вью и контроллерами, но они могут работать с одной и той же моделью (что не очень удобно) или же с отдельными объектами, которые находятся на границе между логикой приложения и UI.
Оригинальная идея MVC описывала сам принцип, как разделить view и model за счет дополнительного посредника. Дальнейшие штуки (HMVC, MVVM, MVP) — это все просто уточнения и развитие мыслей но суть сохраняется такой же.
Никаких API, никакой асинхронки
Я думаю вам не понравилось бы, если бы клик на кнопку вызывал блокирование всего UI вашего приложения.
И уж тем более нет необходимости изобретать мудреные конструкции аналогичные приведенным в статье.
Конструкции на самом деле намного проще, просто тут они излишне усложнены.
речь не о общей идее MVC как принципа отделения мух от котлет а об конкретных имплементациях MVC для веб в исполнении Zend и иже с ним
в исполнении Zend и иже с ним
фреймворки типа Symfony, Laravel, Spring и т.д. — это MVA фреймворки. То есть вместо контроллера у нас там цепочка адаптеров. У этой цепочки могут быть разные названия (фронт контроллер, мидлвэры, экшены), но суть у этой концепции одна и та же. Это просто адаптер UI к приложению.
То есть в случае WEB бэкэнда UI это HTTP. Причем запрос — это асинхронное действие над UI, которое мы в адаптере конвертируем в обычный вызов метода «модели» (обычно какой-то сервис). Затем мы просим «модель» дать нам кусок состояния (в идеале — DTO) и формируем из него HTTP ответ (уже UI часть).
Так что все очень даже там хорошо.
Похоже на то, что автор обнаружил в MVC фатальный недостаток.
Знаете сколько уже людей нашли фатальный недостаток в MVC за 40 лет то? Причем исходя из моих наблюдений, основная проблема в том, что все объясняют что значат эти буквы в отдельности, но мало кто понимает как они взаимодействуют друг с другом. А отсюду появляется много чуши.
потому что MVC — абстрактная идея — а когда приходится писать код требуется конкретика. и тут начинается веселье.
Если речь о десктопе — тут еще более менее ясно — потому как MVC под него и придуман. Когда это попытались надвинуть на вэб — тут уже кто в лес кто по дрова. К примеру десятки файлов в папке model стандартного фреймворка на самом деле не модели а DTO потому как модель в класическом MVC одна — например база данных.
К примеру Word — класический MVC. В древней пятой визуал студии даже шаблон такой был — файл документа — модель, меню приложения — контроллер, отображение документа — вид.
Если речь о десктопе — тут еще более менее ясно — потому как MVC под него и придуман. Когда это попытались надвинуть на вэб — тут уже кто в лес кто по дрова. К примеру десятки файлов в папке model стандартного фреймворка на самом деле не модели а DTO потому как модель в класическом MVC одна — например база данных.
К примеру Word — класический MVC. В древней пятой визуал студии даже шаблон такой был — файл документа — модель, меню приложения — контроллер, отображение документа — вид.
К примеру десятки файлов в папке model стандартного фреймворка на самом деле не модели а DTO
Нет. DTO не имеет поведения, а модели — имеют.
модель в класическом MVC одна — например база данных. К примеру Word — класический MVC.
И где в ворде база данных?
Нет. DTO не имеет поведения, а модели — имеют.
не теоретизируйте — просто посмотрите реализацию этих «моделей» в любом фреймворке.
в большинстве случаев там ПО ФАКТУ именно DTO..Модель в принципе одна а не десятки.
И где в ворде база данных?
я написал «НАПРИМЕР база данных»
В ворде — модель — это документ doc.
в большинстве случаев там ПО ФАКТУ именно DTO
Ну да, большинство разработчиков используют анемичную модель и транзакционные скрипты. Причем часто последние в контроллер вытекают. Тут спорить не буду.
Но это не у «фреймворков» а у разработчиков. Ту же active record люди сегодня используют в большинстве своем как старый добрый row data gateway.
не теоретизируйте — просто посмотрите реализацию этих «моделей» в любом фреймворке.
Я не теоретизирую, я говорю из собственного опыта разработки под asp.net MVC.
Модель в принципе одна а не десятки.
Нет такого «принципа». Ничто в исходном описании паттерна об этом не говорит.
модель в класическом MVC одна — например база данных.
Модель это модель. Это может быть как один объект, так и целый граф объектов связанных между собой (в доке 79-ого года, описывающую эту абстрактную концепуию, так и описывается). По сути своей модель — это все приложение. Модель предметной области, которая хранит и обрабатывает данные (ну то есть не тупо хранилище но еще и поведение).
Представим себе HTTP API приложения, как стену, состоящую из маленьких блоков, у каждого блока есть вход и выход (как трубы). Это отдельные экшены нашего API а вся стена представляет собой интерфейс нашего приложения. Мы можем отправлять сообщения внутрь и получать его из приложения через наши трубы.
Каждый отдельный блок — это контроллер, или лучше сказать адаптер. Снаружи мы только знаем, что если мы пошлем в него сообщение, мы получим какой-то ответ. Как формируется ответ — мы не знаем. Внутри же адаптер берет наше сообщение, переводит его для нижестоящего слоя и отправляет на выполнение. Все, на этом его зона ответственности заканчивается. Он так же может попросить нижестоящий слой выдать ему текущее состояние данных, что бы дать ответ на запрос.
Теперь представим, что за нашим слоем адаптеров скрывается еще один слой — слой приложения. Он так же состоит из отдельных блоков, все они между собой как-то связаны трубами (или не связаны, тут уже применяются правила GRASP), по которым кидают друг дружке сообщения. Часть этих блоков соединина трубами со слоем адаптеров. Это наша граница между слоями. Слой приложения ничего не подозревает о том что есть какие-то адаптеры и т.д.
Для адаптеров моделью будут служить именно эти объекты, которые связаны с ними. То что те в свою очередь представляют только вершину графа — это детали реализации модели, все скрыто инкапсуляцией. База данных в этом случае так же деталь реализации этого слоя. Ее к слову может и не быть вовсе.
У нас много адаптеров, есть целый жирный слой «модели», но это не один объект, а целый граф. Каждый адаптер общается со своей вершиной этого графа и у каждого адаптера модель одна, но если посмотреть на всю совокупность адаптеров, то не обязательно одна и та же вершина будет являться моделью для оного.
Слегка может упорото, но как по мне это самый наглядный способ визуализации этого дела. С картинкой было бы лучше но мне лень. Если захотите — могу нарисовать.
на самом деле не модели а DTO
Stateless сервисы это DTO? с какой это стати? Или вы о «моделях» в контексте active record? или еще каких моделях? Вся проблема в том что само слово «модель» определяет некую абстракцию. «Модель автомобиля» включает в себя модели отдельных ее компонентов.
In traditional MVC, the action (controller) would call an update method on the model and upon success (or error) decide how to update the view. As he points out, it does not have to be that way, there is another equally valid, Reactive, path if you consider that actions should merely pass values to the model, regardless of the outcome, rather than deciding how the model should be updated.
Чушь, в классическом MVC вид подписывается на события в модели. data’ = A (data) — здесь он вообще по сути описывает Flux.
Он взял MVC, разбил методы контроллера на отдельные классы Action, а то что оставалось в контроллере ещё поместил в State, я правильно понял?
Уважаемые хабравчане.
Поскольку дискуссия вокруг статьи идет весьма активно, Жан-Жак Дюбре (он читает комментарии) решил организовать чаты в gitter.
Вы можете пообщаться с ним лично в следующих чатах:
https://gitter.im/jdubray/sam
https://gitter.im/jdubray/sam-examples
https://gitter.im/jdubray/sam-architecture
Также автор статьи разместил примеры кода здесь: https://bitbucket.org/snippets/jdubray/
По поводу кода он оставил следующий комментарий:
Поскольку дискуссия вокруг статьи идет весьма активно, Жан-Жак Дюбре (он читает комментарии) решил организовать чаты в gitter.
Вы можете пообщаться с ним лично в следующих чатах:
https://gitter.im/jdubray/sam
https://gitter.im/jdubray/sam-examples
https://gitter.im/jdubray/sam-architecture
Также автор статьи разместил примеры кода здесь: https://bitbucket.org/snippets/jdubray/
По поводу кода он оставил следующий комментарий:
I don't code for a living, so I am not the best developer, but people can get a sense of how the pattern works and that you can do the exact same thing as React + Redux + Relay with plain JavaScript functions, no need for all these bloated library (and of course you don't need GraphQL).
UFO just landed and posted this here
Вы путаете слои (presentation, domain) с компонентами паттерна (model, view...). Все компоненты MVC (MVVP, MVP...) находятся в одном слое.
UFO just landed and posted this here
Мне начинает казаться, что вы под Model, View и Controller понимаете совсем не то, что под этим понимают в MVC. Давайте начнем с простого вопроса: о каком типе приложений вы говорите — десктопном, мобильном или веб? Если веб — то у вас паттерн на стороне сервера или клиента?
UFO just landed and posted this here
(Я, вроде бы, конкретный вопрос задал...)
Понимаете ли, в чем дело, если у вас "другой" MVC, то ваше мнение о нем слабо применимо к "оригинальному". Так что нет, это не "всё, что вам надо знать про MVC, MVVM и еже с ними", это то, что вы поняли об MVC и MVVM, и, похоже, поняли неправильно.
Понимаете ли, в чем дело, если у вас "другой" MVC, то ваше мнение о нем слабо применимо к "оригинальному". Так что нет, это не "всё, что вам надо знать про MVC, MVVM и еже с ними", это то, что вы поняли об MVC и MVVM, и, похоже, поняли неправильно.
UFO just landed and posted this here
А я вроде бы конкретно пояснил что я делаю, еще в самом начале
"Вроде бы". На мой простой вопрос вы так и не ответили, а от него, заметим, очень многое зависит. Ладно, другой простой вопрос: как именно view получает данные, которые нужно отобразить (ну или кто их передает), в каком виде эти данные существуют?
я очевидно указал, что эволюция в статье от MVC к M-Action-State-V — не более чем иллюзия и самообман.
Srsly? Переход от ООП-модели с меняющимся состоянием к чистым функциям — это иллюзия?
(я никак не хочу обсуждать конкретные достоинства и недостатки одного и другого подходов, это другой вопрос совершенно)
А все, что действительно надо знать о, описано в статье Фаулера про Separated Presentation.
UFO just landed and posted this here
Мой коммент первого уровня в этом треде содержит строку описвающую мою модель:
Я спрашивал про конкретный контекст, i.e., приложение в котором вы используете свой подход.
Этого не достаточно?
Мне непонятно тогда, почему если вы используете не MVC, вы продолжаете использовать терминологию MVC и рассуждать об MVC. Вы "никогда не использовали прямой доступ" — прекрасно, вы и MVC никогда не использовали, поздравляю вас.
Понимаете ли, термины и шаблоны используются именно для того, чтобы упростить понимание того, о чем идет речь. А вы, напротив, запутываете его.
Где вы увидели «поломанную ООП»?
А я где-то ее увидел?
С каких пор композиция/декомпозиция самих объектов, перестала быть ООП?
А где в чистых функциях, предлагаемых Дюбре, композиция/декомпозиция объектов? Вся эта красота перестала быть ООП в тот момент, когда мы отказались от мутабельного состояния.
UFO just landed and posted this here
Т.е. вы отрицаете, что Dependency injection...
А какое отношение это имеет к вопросу?
очевидно что код Controller'a общается изолированно с View и Model — и отвечает на внешние запросы.
Мне не очевидно. Еще более мне не очевидно, откуда, все-таки, во View берутся данные, которые надо отобразить.
Тривиальный пример: в домене есть сущность "пользователь", у пользователя есть фамилия, имя и отчество (три отдельных свойства), в интерфейсе надо вывести одно текстовое поле, содержащее фамилию, имя и отчество, сконкатенированные через пробел. Откуда в этом поле берутся данные?
UFO just landed and posted this here
… а теперь давайте переложим это в "нормальные" термины.
… то есть получает снаружи input model.
… обращается к domain layer. Не к модели, это важно.
… те данные, которые вы передаете во View — вот это назвается Model.
… и к этому моменту View уже отработало.
Если смотреть на происходящее в таких терминах, выясняется, что у вас никогда нет движения ни View -> Controller -> Model (потому что вызовы к контроллеру осуществляет не View, а внешняя среда), ни Model -> Controller -> View (потому что модель возникает внутри контроллера).
В реальности же, модель — это и есть "интерфейс" между контроллером и представлением. Контроллер создает модель, представление потребляет модель. Контроллер знает, какое представление активировать, ни модель, ни представление ничего не знают о контроллерах (представление может знать, но в терминах "куда передать запрос дальше", а не "кто меня активировал").
И удивительным образом, все три этих компонента находятся в одном слое. В другом слое находится только домен.
Контроллер принимает входящие данные из вне + окружение.
Сопоставляет парамтеры окружения и вводные со своей картой (Action Map, url_routing — суть есть задачи Контроллера).
… то есть получает снаружи input model.
В соответствии с этим он делает запрос к соответсвующим методом объекта Model.
Получает данные (может принять какое-то промежуточное решение, например Модель сказала что данных пока нет)
… обращается к domain layer. Не к модели, это важно.
Вызывает метод/методы объекта View с передачей ему данных в аргументы методов — который уже генерит их уже в ответе
… те данные, которые вы передаете во View — вот это назвается Model.
Получает в ответе какое-то blob/text/html-тело ответа в виде уже отрендеренного шаблона и отправляет ответ во внешний мир
… и к этому моменту View уже отработало.
Если смотреть на происходящее в таких терминах, выясняется, что у вас никогда нет движения ни View -> Controller -> Model (потому что вызовы к контроллеру осуществляет не View, а внешняя среда), ни Model -> Controller -> View (потому что модель возникает внутри контроллера).
В реальности же, модель — это и есть "интерфейс" между контроллером и представлением. Контроллер создает модель, представление потребляет модель. Контроллер знает, какое представление активировать, ни модель, ни представление ничего не знают о контроллерах (представление может знать, но в терминах "куда передать запрос дальше", а не "кто меня активировал").
И удивительным образом, все три этих компонента находятся в одном слое. В другом слое находится только домен.
UFO just landed and posted this here
Я вам привел пример с web-реализацией, продиктованной особенностью HTTP.
Поэтому в серверном MVC на самом деле не "оригинальный" MVC, а Model2.
для чистоты можно отдать отдельные данные окружения сразу View,
Нельзя. View в Model2 — это, фактически, шаблон, он не умеет работать с "окружением".
В моей вариации Controller
Повторюсь, нет никакой "вашей вариации". То, что вы описываете — это самый обычный Model2, в котором вы неправильно именуете компоненты.
Т.к. шаг влево, шаг вправо — все на всё похоже.
Вот из-за этого "все на все похоже" и возникает путаница. Хотя, казалось бы, шаблоны описаны и понятны.
под Model как-бы везде понимается Структура-Данных (БД + базовые функции ПО (API))
Кем "понимается"? Я даже не буду говорить, что вы сейчас взяли и смешали два разных слоя, хотя так ратовали за абстракцию и отсутствие протечек.
B все-таки под Model как-бы везде понимается Структура-Данных (БД + базовые функции ПО (API))
Да, а сервисный слой — это что?
Модель — это иерархия, я тут уже приводил свою аналогию. На низком уровне это сущности, описывающие отдельные модельки отдельных компонентов. Чуть выше есть сервисы, которые реализуют бизнес правила, ограничения либо они занимаются оркестрацией. "модель" в контексте MVC это то, что "соприкасается" с контроллером, и обычно это сервисы, но в целом это "все что угодно что отвечает за обработку данных". Фактически модель это и есть само приложение.
UFO just landed and posted this here
UFO just landed and posted this here
Точнее View и есть «ответ» на внешний запрос
Серьезно?
Я, пожалуй, спрошу еще раз: зачем вы используете термины, закрепленные за вполне конкретным шаблоном (окей, будем честными, двумя разными шаблонами), совершенно иначе, нежели они в этом шаблоне используются? Более того, делаете это аккурат в посте, где обсуждается этот шаблон.
UFO just landed and posted this here
И почему я не могу дать свою вариацию?
Потому что ваша "вариация" — это обычный Model 2 с неправильно названными частями.
UFO just landed and posted this here
Ну нет. Dependency Injection совершенно ортогональна MVC в любой его реинкарнации.
UFO just landed and posted this here
В вашем псевдокоде как раз MVC.
UFO just landed and posted this here
Больше похоже на MVA, Mediating Controller MVC…
в MVC каноническом View напрямую связано с моделью обревабл отношениями и само обновляло себя по ивентам от модели. На бэкэнде это не нужно. Контроллер же обрабатывал действия пользователей и слал модели сообщения (дергал методы), что бы модель уже принимала решение менять ей состояние или нет.
в MVC каноническом View напрямую связано с моделью обревабл отношениями и само обновляло себя по ивентам от модели. На бэкэнде это не нужно. Контроллер же обрабатывал действия пользователей и слал модели сообщения (дергал методы), что бы модель уже принимала решение менять ей состояние или нет.
Это не я вас запутал, а вы сам себя запутали, когда стали использовать термины не по назначению.
Вот ваш исходный код, чуть-чуть поправленный по привычке:
А теперь просто переименуем в соответствии с нормальной практикой:
Вот, нормальный такой Model 2, контроллер получает модель и передает ее представлению.
Говорю же, не надо путать model из MVC с доменной моделью.
Вот ваш исходный код, чуть-чуть поправленный по привычке:
public ActionResult Render(args)
{
ActionMap(args);
var some_data = this.CModel.get_data(args);
var some_view = this.CView.Template(some_data);//я все-таки исхожу из того, что данные вам для чего-то нужны
return some_view;
}А теперь просто переименуем в соответствии с нормальной практикой:
public ActionResult Render(args)
{
ActionMap(args);
var model = this.Domain.get_data(args);
var result = this.View.Template(model);
return result;
}Вот, нормальный такой Model 2, контроллер получает модель и передает ее представлению.
Говорю же, не надо путать model из MVC с доменной моделью.
UFO just landed and posted this here
Да, но вы упускаете момент, я не просто так "..." троеточия поставил.
А что в них происходит, если они важны для шаблона?
Уточним, все же данные из объекта класса Модель, а потом отдает эти данные нужному методу Представления, который рендерит на основе их ответ. Представление ничего не знает о Модели в принципе. Я намеренно так обозвал переменные, чтобы заострить на этом момент.
… но нет. От того, что вы переназвали переменные, суть не меняется. В Model 2 модель — это то, что view получило на вход. Другое дело, что вы путаетесь именно потому, что называете компоненты "не так".
Сначала — тот факт, что MVC все в одном слое и общаются между собой
Я говорил, что они все в одном слое. Что все они общаются между собой — я не говорил.
а у меня не MVC
Это предположение я сделал исходя из вашего описания.
Потом, по приведенному псевдокоду — вы вынесли вердикт, что это классический такой MVC для Web, потом вот опять Model2...
Классический MVC "для веб" (для серверной стороны) — это и есть Model 2.
Так что пока ни одного противоречия.
В общем, на самом деле держать за «идею MVC» как какую-то особую идею — ровно нет никакого смысла.
А в ней и нет ничего "особого", просто это работающий и потому распространенный паттерн. Другое дело
я делал все примерн тоже самое
Иногда "примерно" играет существенную роль.
UFO just landed and posted this here
Пожалуй, лучшее MVC выглядит примерно так
Вот только это не MVC. Ни одно, ни другое. MVC — это вполне определенный паттерн.
И нет, нельзя сказать, что State + Action = Controller, потому что в "клиентском" (классическом) MVC состояние инкапсулировано в модели, а в серверном (Model 2) — его, по факту, нет (и вокруг него прыгают, чтобы его имитировать тем или иным способом).
Собственно, ключевое отличие (и смысл) SAM в том, чтобы явно разделить входящий и исходящий поток, получив чисто реактивное (чисто функциональное, если хотите) представление происходящего.
И нет, SAM нельзя свести к вашей картинке, потому что в SAM представление (где бы оно ни было) все равно знает о модели, потому что оно строится по модели (посмотрите на все картинки с кодом, все представления имеют модель входным параметром).
UFO just landed and posted this here
UFO just landed and posted this here
В целом соглашусь, но предоставлю чуть другие картинки, по которым разница все же есть. И да, разнциа в названиях — это мелочи, а вот разница во взаимодействии — вот это действительно важно.

А так "леса не видят" потому что не знаю зачем нужен принцип Separation of concerns и т.д.


А так "леса не видят" потому что не знаю зачем нужен принцип Separation of concerns и т.д.
то, что нарисовал это на самом деле обычный MVVM
И снова нет. MVVM не применим на сервере.
Замените ViewModel на Controller — ни сути ни определения это не поменяет.
Поменяет. В MVVM между view и viewmodel — двусторонний биндинг. У вас же его нет.
M <-> C <-> V = всё и точка — едем дальше.
Все, все серверные фреймворки, в которых Model 2, и поэтому все не так, как вы нарисовали — выкидываем?
Странно, что VM и M соединены двумя стрелками (Request + Response?), а V и VM — одной (Two Way Data Binding?)

сплошные стрелки — направление потока данных, или направления сообщений.
стрелки с пунктиром — observable отношения.
Контроллер не обязательно должен отслеживать события именно этого view, а у модель может быть больше одной вьюшки.
UFO just landed and posted this here
C --> VА где хранить статусы, например номер текущей страницы пагинатора, в модели? или MVC для этого не подходит?
Ещё Вопрос: кто должен отвечать за подготовку данных, например если перед выводом нужно отсортировать, или задекорировать/перевести язык значения?
Вот вы правильные вопросы задаете. Именно по этому со временем люди превратили контроллер в "адаптер" между view и model, который полностью их отделял друг от друга. Например MVP. А потом комуто стало лень делать подписку на события и придумали биндинги (MVVM) ну и т.д.
За это полностью отвечает view. Это не "шаблон", это полноценный компонент который может хранить свое состояние.
По этой схемке view и отвечает за это, он забирает состояние модели и формирует view.
А где хранить статусы, например номер текущей страницы пагинатора, в модели? или MVC для этого не подходит?
За это полностью отвечает view. Это не "шаблон", это полноценный компонент который может хранить свое состояние.
Ещё Вопрос: кто должен отвечать за подготовку данных, например если перед выводом нужно отсортировать, или задекорировать/перевести язык значения?
По этой схемке view и отвечает за это, он забирает состояние модели и формирует view.
Согласен, все эти MV* — очередной способ изолировать данные от представления (иногда и от логики, если она есть). А все остальное — удобства поверх. Если данные отделены от представления и соблюден принцип единственной ответственности, то уже пофиг, как это называется, разумный человек всегда разберется.
Тут так же как и со всеми паттернами, названия нужны просто для того, что бы сказав три буквы люди понимали как у вас что организовано. Но с MVC тут проблемка, потому как то, что называли MVC 30 лет назад сейчас совсем другая штука (например то что описал BjornValor это больше смахивает на MVP или MVA).
В целом же, как мне кажется, намного более важно уяснить что такое smartui и чем это плохо.
В целом же, как мне кажется, намного более важно уяснить что такое smartui и чем это плохо.
UFO just landed and posted this here
Изоляция бывает не обязательно вертикальная.
Какая же это изоляция?
Нормальная такая изоляция. Вы правда не знаете других способов изоляции кроме слоев?
Нет, они не находятся в одном слое. VC — в одном слое, M — граница другого слоя.
UFO just landed and posted this here
MV — в другом (и они не общаются напрямую).
Если они не общаются напрямую то они априори не могут быть в одном слое. Они же не знают ничего друг о друге.
Канонический MVC 79-ого года не имеет слоев в принципе. Это три отдельных компонента, и они описывают взаимодействие в небольших масштабах. То что там модель является сервисом слоя приложения, это детали о которых "контроллер" знать ничего не должен, и view ничего знать не должно. На сервере "модель" с которой общается view (или то что контроллер экспоузит) это по большому счету DTO. Вот и все.
Если они не общаются напрямую то они априори не могут быть в одном слое.
Это почему? В одном слое может быть много компонентов, которые напрямую друг с другом не общаются.
ну пожалуй соглашусь. Но тут мы говорим о чем-то из problem space и чем-то из связанным с UI, а MVC придумывалось что бы разделить это на два отдельных слоя.
Вот снова: не слоя, а компонента. MVC весь живет в слое представления (presentation layer). То, что его модель может, в самом простом случае, быть идентичной с моделью домена, никуда его не двигает.
Блин, сам же писал чуть выше про то что в MVC нет слоев, и сам же начал про слови, ввожу в заблуждение. Но там же я говорил что компоненты эти принадлежат разным слоям, или разным зонам ответственности, если вам так больше нравится.
Вы бы хотя бы где-нибудь на что-нибудь сослались, чтобы понять, почему Вы считаете, что Ваша интерпретация — единственно верная.
4.1.1 Model
The model is a non-visual object containing all the data and behaviour other than that
used for its presentation to the user (Fowler 2003). Model represents the data and
state (Freeman et al. 2004) of an application and the domain logic that manipulates it
(Buschmann et al. 1996).
4.3.1 Separated Presentation or Model-View
The most fundamental principle in the Smalltalk MVC and all the others that followed,
is to separate the elements seen on the screen i.e. presentation or user interface, and
the set of classes that are concerned with the core of the application, i.e. the domain
objects or data management (Potel 1996; Fowler 2003). Fowler (2006b) refers to this
as Separated Presentation, while Sanderson (2010) names it Model-View (figure 4-
2).
Another strict rule is visibility: the presentation can call the domain objects, but not
vice-versa. The domain objects should be completely self contained and unaware of
any presentations. This is in fact a form of a layered architecture. The visibility rule can
even be validated with build-time tools. (Fowler 2006b)
На самом деле, я не считаю, что моя интерпретация — единственно верная; я скорее считаю ее наименее усложненной. Другое дело, что это стремление к простоте и привело меня к ошибке.
На самом деле, Fesor выше был прав, говоря, что model — граница другого слоя. Такая ситуация (даже не столько интерпретация паттерна, сколько его реализация) тоже возможна: модель может (и долгое время это и было единственным вариантом) представлять собой домен, и, как следствие, принадлежать к domain layer. При этом (а) чтобы это было эффективным, она не может быть в другом tier (как раз отсюда и мое некорректное "все в одном слое") и (б) поскольку и контроллер, и представление знают о модели, они оба живут в одном слое (иначе будет нарушено правило непересечения слоев).
На самом деле, Fesor выше был прав, говоря, что model — граница другого слоя. Такая ситуация (даже не столько интерпретация паттерна, сколько его реализация) тоже возможна: модель может (и долгое время это и было единственным вариантом) представлять собой домен, и, как следствие, принадлежать к domain layer. При этом (а) чтобы это было эффективным, она не может быть в другом tier (как раз отсюда и мое некорректное "все в одном слое") и (б) поскольку и контроллер, и представление знают о модели, они оба живут в одном слое (иначе будет нарушено правило непересечения слоев).
(б) поскольку и контроллер, и представление знают о модели, они оба живут в одном слое (иначе будет нарушено правило непересечения слоев)
Я вот это не очень понял. Тут вот это подразумевалось?
поскольку и Controller, и View знают о Model, они оба (Controller и View?) живут в одном tier(?) (иначе будет нарушено правило непересечения tier(?))
Нет именно layer в данном случае. Есть же простое правило "слоеной" (layered) архитектуры: слои лежат один на другом, обращаться можно только к слою ниже, пересекать слои нельзя. Соответственно, когда два компонента обращаются к одному и тому же компоненту, они могут быть с ним либо в одном слое, либо в слое на один выше.
(c tier то же самое, понятное дело, но на одном tier может быть несколько layer)
(c tier то же самое, понятное дело, но на одном tier может быть несколько layer)
Я почему-то под "непересечением слоев" понял непересечение границы, т.к. Model Вы и Fesor зачем-то на границу поместили.
А на границу вы его, судя по всему, поместили, чтобы для варианта в 5-1 проиллюстрировать, что вот в отдельном слое лежит Domain Model, а Application Model в другом и вроде как вместе с Controller и View, но при этом же надо как-то обозначить, что View и Controller не должны лезть к Domain Model.
Вот если руководствоваться правилом непересечения слоев, то надо было просто в три слоя их разложить, а не в два. Но чтобы остаться в рамках картинки, где слоя всего два нарисовано приходится придумывать вот это про границу.
Или что вы под этим размещением на границе подразумевали?
Вот если руководствоваться правилом непересечения слоев, то надо было просто в три слоя их разложить, а не в два. Но чтобы остаться в рамках картинки, где слоя всего два нарисовано приходится придумывать вот это про границу.
Или что вы под этим размещением на границе подразумевали?
На границу его поместил Fesor.
С моей точки зрения, когда используется application model, то верно как раз мое первое утверждение (все компоненты паттерна живут в одном layer) — для паттерна больше не существует domain model, она скрыта, а application model принадлежит к presentation layer.
В том же случае, когда используется сразу domain model, V и C находятся в presentation layer, а M — в domain layer.
С моей точки зрения, когда используется application model, то верно как раз мое первое утверждение (все компоненты паттерна живут в одном layer) — для паттерна больше не существует domain model, она скрыта, а application model принадлежит к presentation layer.
В том же случае, когда используется сразу domain model, V и C находятся в presentation layer, а M — в domain layer.
Application layer разделяет presentation layer и domain layer. Это слой оркестрации, который оперирует бизнес логикой и реализует юзкейсы.
В этом случае в рамках MVC "моделью" является та часть application layer, которая соприкосается с presentation layer, то есть граница приложения. Вот даже схемку когда-то рисовал.
В этом случае в рамках MVC "моделью" является та часть application layer, которая соприкосается с presentation layer, то есть граница приложения. Вот даже схемку когда-то рисовал.
{kind=link}
Историю я помню, но, насколько я понял, Вы с этим согласились: "На самом деле, Fesor выше был прав".
Что значит "скрыто"? Просто в другом слое, причем всего лишь на один уровень ниже. Почему Model может туда обращаться, а находящиеся там же (где и Model) View и Controller — нет?
Вы сами ввели в разговор правило непересечения слоев. Вот следуя ему, View и Controller могут обратиться к Domain Model. Если же Вы запретите пересекать границу (какое-то другое правило), то к Domain Model не сможет обратиться Application Model.
Итого: разложив все в три слоя и пользуясь правилом непересечения слоев — картина получается непротиворечивая. Ваше последнее описание мне пока кажется противоречивым. Возможно, Вы используете какой-то другой способ изоляции, но в явном виде пока его не описали, причем еще раз обращу Ваше внимание, что изоляцию через правило непересечения слоев Вы ввели в обсуждение сами.
Что значит "скрыто"? Просто в другом слое, причем всего лишь на один уровень ниже. Почему Model может туда обращаться, а находящиеся там же (где и Model) View и Controller — нет?
Вы сами ввели в разговор правило непересечения слоев. Вот следуя ему, View и Controller могут обратиться к Domain Model. Если же Вы запретите пересекать границу (какое-то другое правило), то к Domain Model не сможет обратиться Application Model.
Итого: разложив все в три слоя и пользуясь правилом непересечения слоев — картина получается непротиворечивая. Ваше последнее описание мне пока кажется противоречивым. Возможно, Вы используете какой-то другой способ изоляции, но в явном виде пока его не описали, причем еще раз обращу Ваше внимание, что изоляцию через правило непересечения слоев Вы ввели в обсуждение сами.
могут обратиться к Domain Model
Почему вы смешиваете понятие "модель" и "модель предметной области"? Это же совсем разные вещи (обычно).
Обратиться к Domain Model ни вью ни контроллер не могут, если между ними еще один слой. Если это не так, у нас нет никакого смысла в этих слоях, раз они не скрывают детали своей реализации.
Итого: разложив все в три слоя и пользуясь правилом непересечения слоев — картина получается непротиворечивая.
Не дочитал ваш комментарий. Тогда все ок)
Почему Model может туда обращаться, а находящиеся там же (где и Model) View и Controller — нет?
Потому что это нарушает паттерн. View и Controller общаются с одной моделью. С чем общается она, их не очень волнует.
Вот следуя ему, View и Controller могут обратиться к Domain Model.
Да, это правило не запрещает им обращаться в домен. Но это будет нарушением паттерна.
Итого: разложив все в три слоя и пользуясь правилом непересечения слоев — картина получается непротиворечивая.
… но избыточная. Мы придумываем дополнительный слой там, где без него можно обойтись. Опять-таки, иногда application-слой настолько объемен, что его выделение осмысленно — но чаще конкретная модель обслуживает конкретный UC, и отрывать ее особого смысла нет.
И сразу в дополнение вот отсюда (предыдущее оттуда же было):
Если посмотреть сначала на первую, потому на вторую, то, на мой взгляд, получается, что есть разные интерпретации. И не очень понятно, почему Вы свою интерпретацию про слои и компоненты считаете единственно верной.
Figure 4-1. Building blocks of the Model-View-Controller architectural pattern. Solid
lines represent direct connections, dashed lines represent indirect connections
Figure 5-1. The VisualWorks version of MVC, which separated the concepts of domain
model and application model. (Bower & McGlashan 2000)
Если посмотреть сначала на первую, потому на вторую, то, на мой взгляд, получается, что есть разные интерпретации. И не очень понятно, почему Вы свою интерпретацию про слои и компоненты считаете единственно верной.
Прочитав статью и комментарии можно увидеть эффект Даннинга — Крюгера в действии
Удивительно, но факт: эффект Даннинга — Крюгера может проявляться даже на людях, знающих о существовании эффекта Даннинга — Крюгера. (И даже на тех, кто знает о данном удивительном факте, да.)
не поделитесь подробностями своих наблюдений? Я серьезно.
Люди фокусируются на неважных вещах, которые даже для автора неважны, и комментируют их, вместо того, что посмотреть в корень и подискутировать с автором о фундаментальных концепциях, которые он продвигает или на которые он ссылается. Прокомментировать аргументы, которые автор приводит. Найти контр-аргументы и т.п.
Кстати, текст стоит обновить ссылкой на вторую часть статьи автора — http://www.ebpml.org/blog15/2015/12/why-i-no-longer-use-mvc-frameworks-part-2/
Sign up to leave a comment.
Почему я больше не использую MVC-фреймворки