Хранение документов в Postgres немного проще, теперь у нас есть серьезные процедуры сохранения, возможность запускать полнотекстовый поиск, и некоторые простые процедуры поиска и фильтрации.
Это только половина истории, конечно же. Рудиментарные поиски могут служить нуждам приложения, но они никогда не будут работать в долгой перспективе, когда нам надо будет задавать более глубокие вопросы.
Хранение документов является очень большой темой. То, как хранить документ (и что хранить), для меня, разделяется на три области:
Я очень тяготею к последнему. Я информационный накопитель и когда что-то случается, я хочу знать что/почему/где до любых пределов.
Вот что я раньше делал, чтобы сохранять информацию о людях, покупающих что-нибудь в Tekpub. Это формат документа, который я собирался пустить в дело, но так и не дошел до этого (из-за распродажи на Plularsight).
Это большой документ. Я люблю большие документы! Этот документ — точный результат всех движений информации в процессе оформления заказа:
Я хочу, чтобы этот документ был автономным, самодостаточным объектом, которому не нужны никакие другие документы, чтобы быть завершенным. Другими словами, я хотел бы быть способным:
Этот документ является завершенным сам по себе и это прекрасно!
ОК, достаточно, давайте напишем некоторые отчеты.
Поводя аналитику важно помнить две вещи:
Выполнение огромных запросов по объединенным таблицам занимает вечность, и это ни к чему не приводит в конечном счете. Вам следует строить отчеты на исторических данных, которые не меняются (или меняются совсем мало) со временем. Денормализация помогает со скоростью, и скорость — ваш друг при построении отчетов.
Учитывая это, мы должны использовать доброту PostgreSQL чтобы сформировать наши данные в таблицу фактов продаж. «Фактическая» таблица — это просто денормализованный набор данных, который представляет событие в вашей системе — самый маленький объем усваиваемой информации о факте.
Для нас этот факт — продажа, и мы хотим чтобы это событие выглядело так:
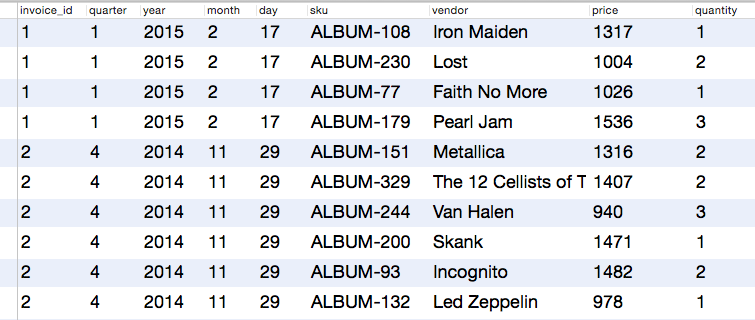
Я использую образец базы Chinook с некоторыми случайными данными о продажах, созданными при помощи Faker.
Каждая из этих записей — это единичное событие, которые я хочу накапливать, и вся информация о размерности, с которой я хочу их объединять (время, поставщик) — уже включены. Я могу добавить больше (категорию и т.д.), но пока хватит и этого.
Эти данные в находятся табличной форме, это означает что мы должны их добывать из документа, показанного выше. Задача не из легких, но намного проще, поскольку мы используем PostgreSQL:
Это набор обобщенных табличных выражений (ОТВ), объединенных вместе функциональным образом (об этом ниже). Если вы никогда не использовали ОТВ — они могут выглядеть немного непривычно… пока вы не приглядитесь и не поймете, что вы просто объединяете вещи вместе именами.
В первом запросе выше, я вытягиваю id продажи и называю его invoice_id, и после этого вытягиваю timestamp и конвертирую его в timestampz, Несложные действия по своей сути.
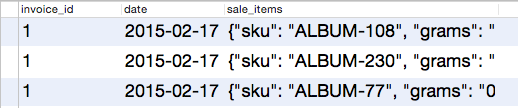
Что становится интереснее здесь — это jsonb_array_elements, который вытягивает массив объектов из документа и создает запись для каждого из них. То есть, если бы мы имели в базе единственный документ, с тремя объектами и запустили бы следующий запрос:
Вместо одной записи, представляющей продажу, мы получили бы 3:
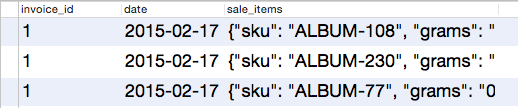
Теперь, когда мы выделили объекты, нам необходимо разделить их по отдельным колонкам. Вот тут и появляется следующая хитрость с jsonb_to_record. Мы можем сразу использовать эту функцию, описывая значения типов на лету:
В этом простом примере я конвертирую jsonb в таблицу — мне всего лишь достаточно сказать PostgreSQL как это сделать. Это именно то, что мы и делаем во втором ОТВ («событие») выше. Также, мы используем date_part чтобы конвертировать даты.
Это дает нам таблицу событий, которую мы можем сохранить в представление, если мы:
Вы можете подумать, что этот запрос ужасно медленный. На самом же деле, он достаточно быстрый. Это не является какой-то отметкой уровня, или чем-то вроде того — просто относительный результат, чтобы показать вам, что этот запрос, на самом деле, быстрый. У меня имеется 1000 тестовых документов в базе, выполнение этого запроса на всех документах возвращается приблизительно за десятую долю секунды:

PostgreSQL. Классная вещь.
Теперь мы готовы к некоторым накоплениям!
Дальше все проще. Вы просто объединяете данные, которые хотите, и если вы про что-то забыли — просто добавляете это к своему представлению и не надо заботиться ни о каких объединениях таблиц. Просто преобразование данных, которое действительно происходит быстро.
Давайте посмотрим пятерку лучших продавцов:
Этот запрос возвращает данные за 0.12 секунды. Достаточно быстро для 1000 записей.
Одна из вещей, которая мне действительно нравится в RethinkDB это ее собственный язык запросов, ReQL. Он вдохновлен Haskell (в соответствии с командой) и весь заключается в композиции (особенно для меня):
Как можно видеть выше, мы можем аппроксимировать это, используя ОТВ, объединенные вместе, каждое из которых преобразует данные специфическим путем.
Есть еще много всего, что я мог бы написать, но давайте просто подытожим это все тем, что вы можете делать все, что умеют делать другие документо-ориентированные системы и даже больше.Возможности запросов в Postgres очень велики — есть очень малый список вещей, которые вы не сможете сделать и, как вы видели, возможность преобразовывать Ваш документ в в табличную структуру очень помогает.
И это конец этой маленькой серии статей.
Это только половина истории, конечно же. Рудиментарные поиски могут служить нуждам приложения, но они никогда не будут работать в долгой перспективе, когда нам надо будет задавать более глубокие вопросы.
Исходный документ
Хранение документов является очень большой темой. То, как хранить документ (и что хранить), для меня, разделяется на три области:
- Модель документа/домена. Взгляд на все это со стороны разработчика, но если вы поклонник DDD(Domain Driven Design), то это играет роль.
- Реальный мир. Счета, покупки, заказы — бизнес работает на этих вещах — давайте задумаемся над этим.
- Транзакции, результаты процесса, источники событий. На самом деле, когда «что-то происходит» с приложением, вы отслеживаете все, что происходило при этом и храните это.
Я очень тяготею к последнему. Я информационный накопитель и когда что-то случается, я хочу знать что/почему/где до любых пределов.
Вот что я раньше делал, чтобы сохранять информацию о людях, покупающих что-нибудь в Tekpub. Это формат документа, который я собирался пустить в дело, но так и не дошел до этого (из-за распродажи на Plularsight).
{
"id": 1,
"items": [
{
"sku": "ALBUM-108",
"grams": "0",
"price": 1317,
"taxes": [],
"vendor": "Iron Maiden",
"taxable": true,
"quantity": 1,
"discounts": [],
"gift_card": false,
"fulfillment": "download",
"requires_shipping": false
}
],
"notes": [],
"source": "Web",
"status": "complete",
"payment": {
//...
},
"customer": {
//...
},
"referral": {
//...
},
"discounts": [],
"started_at": "2015-02-18T03:07:33.037Z",
"completed_at": "2015-02-18T03:07:33.037Z",
"billing_address": {
//...
},
"shipping_address": {
//...
},
"processor_response": {
//...
}
}
Это большой документ. Я люблю большие документы! Этот документ — точный результат всех движений информации в процессе оформления заказа:
- Адреса клиента (для выставления счета, для доставки)
- Платежная информация и что было куплено
- Как они сюда попали и краткая информация о том, что произошло на их пути (в виде заметок)
- Точный ответ от процессора (который сам по себе является большим документом)
Я хочу, чтобы этот документ был автономным, самодостаточным объектом, которому не нужны никакие другие документы, чтобы быть завершенным. Другими словами, я хотел бы быть способным:
- Осуществлять заказ
- Запускать некоторые отчеты
- Оповещать клиента об изменениях, выполнении и т.д.
- Принимать дальнейшие меры, если потребуется (списание, отмена)
Этот документ является завершенным сам по себе и это прекрасно!
ОК, достаточно, давайте напишем некоторые отчеты.
Формирование данных. Фактическая таблица
Поводя аналитику важно помнить две вещи:
- Никогда не проводите ее на работающей системе
- Денормализация — это норма
Выполнение огромных запросов по объединенным таблицам занимает вечность, и это ни к чему не приводит в конечном счете. Вам следует строить отчеты на исторических данных, которые не меняются (или меняются совсем мало) со временем. Денормализация помогает со скоростью, и скорость — ваш друг при построении отчетов.
Учитывая это, мы должны использовать доброту PostgreSQL чтобы сформировать наши данные в таблицу фактов продаж. «Фактическая» таблица — это просто денормализованный набор данных, который представляет событие в вашей системе — самый маленький объем усваиваемой информации о факте.
Для нас этот факт — продажа, и мы хотим чтобы это событие выглядело так:

Я использую образец базы Chinook с некоторыми случайными данными о продажах, созданными при помощи Faker.
Каждая из этих записей — это единичное событие, которые я хочу накапливать, и вся информация о размерности, с которой я хочу их объединять (время, поставщик) — уже включены. Я могу добавить больше (категорию и т.д.), но пока хватит и этого.
Эти данные в находятся табличной форме, это означает что мы должны их добывать из документа, показанного выше. Задача не из легких, но намного проще, поскольку мы используем PostgreSQL:
with items as (
select body -> 'id' as invoice_id,
(body ->> 'completed_at')::timestamptz as date,
jsonb_array_elements(body -> 'items') as sale_items
from sales
), fact as (
select invoice_id,
date_part('quarter', date) as quarter,
date_part('year', date) as year,
date_part('month', date) as month,
date_part('day', date) as day,
x.*
from items, jsonb_to_record(sale_items) as x(
sku varchar(50),
vendor varchar(255),
price int,
quantity int
)
)
select * from fact;
Это набор обобщенных табличных выражений (ОТВ), объединенных вместе функциональным образом (об этом ниже). Если вы никогда не использовали ОТВ — они могут выглядеть немного непривычно… пока вы не приглядитесь и не поймете, что вы просто объединяете вещи вместе именами.
В первом запросе выше, я вытягиваю id продажи и называю его invoice_id, и после этого вытягиваю timestamp и конвертирую его в timestampz, Несложные действия по своей сути.
Что становится интереснее здесь — это jsonb_array_elements, который вытягивает массив объектов из документа и создает запись для каждого из них. То есть, если бы мы имели в базе единственный документ, с тремя объектами и запустили бы следующий запрос:
select body -> 'id' as invoice_id,
(body ->> 'completed_at')::timestamptz as date,
jsonb_array_elements(body -> 'items') as sale_items
from sales
Вместо одной записи, представляющей продажу, мы получили бы 3:
Теперь, когда мы выделили объекты, нам необходимо разделить их по отдельным колонкам. Вот тут и появляется следующая хитрость с jsonb_to_record. Мы можем сразу использовать эту функцию, описывая значения типов на лету:
select * from jsonb_to_record(
'{"name" : "Rob", "occupation": "Hazard"}'
) as (
name varchar(50),
occupation varchar(255)
)
В этом простом примере я конвертирую jsonb в таблицу — мне всего лишь достаточно сказать PostgreSQL как это сделать. Это именно то, что мы и делаем во втором ОТВ («событие») выше. Также, мы используем date_part чтобы конвертировать даты.
Это дает нам таблицу событий, которую мы можем сохранить в представление, если мы:
create view sales_fact as
-- the query above
Вы можете подумать, что этот запрос ужасно медленный. На самом же деле, он достаточно быстрый. Это не является какой-то отметкой уровня, или чем-то вроде того — просто относительный результат, чтобы показать вам, что этот запрос, на самом деле, быстрый. У меня имеется 1000 тестовых документов в базе, выполнение этого запроса на всех документах возвращается приблизительно за десятую долю секунды:

PostgreSQL. Классная вещь.
Теперь мы готовы к некоторым накоплениям!
Отчет о продажах
Дальше все проще. Вы просто объединяете данные, которые хотите, и если вы про что-то забыли — просто добавляете это к своему представлению и не надо заботиться ни о каких объединениях таблиц. Просто преобразование данных, которое действительно происходит быстро.
Давайте посмотрим пятерку лучших продавцов:
select sku,
sum(quantity) as sales_count,
sum((price * quantity)/100)::money as sales_total
from sales_fact
group by sku
order by salesCount desc
limit 5
Этот запрос возвращает данные за 0.12 секунды. Достаточно быстро для 1000 записей.
ОТВ и функциональные запросы
Одна из вещей, которая мне действительно нравится в RethinkDB это ее собственный язык запросов, ReQL. Он вдохновлен Haskell (в соответствии с командой) и весь заключается в композиции (особенно для меня):
Чтобы понять ReQL, он помогает понять функциональное программирование. Функциональное программирование входит в декларативную парадигму, в которой программист стремится описать значение, которое он хочет посчитать, нежели описывать шаги, необходимые для подсчета этого значения. Языки запросов баз данных, как правило, стремится к декларативному идеалу, что при этом дает обработчику запросов наибольшую свободу в выборе оптимального плана выполнения. Но пока SQL добивается этого используя специальные ключевые слова и специфический декларативный синтаксис, ReQL имеет возможность выразить сколь угодно сложные операции через функциональную композицию.
Как можно видеть выше, мы можем аппроксимировать это, используя ОТВ, объединенные вместе, каждое из которых преобразует данные специфическим путем.
Заключение
Есть еще много всего, что я мог бы написать, но давайте просто подытожим это все тем, что вы можете делать все, что умеют делать другие документо-ориентированные системы и даже больше.Возможности запросов в Postgres очень велики — есть очень малый список вещей, которые вы не сможете сделать и, как вы видели, возможность преобразовывать Ваш документ в в табличную структуру очень помогает.
И это конец этой маленькой серии статей.
