Comments 104
Давно хотел увидеть такую статью. Спасибо!
Пруфы привести не могу (но гуглить все умеют), но читал, что адепты таких систем, как Inferno OS и Plan9 считают, что если код написан хорошо, то подсветка не нужна и только мешает. Даже доводы какие-то приводили. Хотя я их не понимаю и согласен со статьей.
Очень хотелось бы увидеть пример хорошего кода, который портит подсветка ;)
[sarcasm]
Что-то вроде этого
[/sarcasm] double _[]={-2
,1,-1.3 ,1.3, 0, 0,0,0
,0 ,0,50, 80, 0,0,0 ,255
, 8,0}; int main (
int j) {if (j== 1 ){ if(
_[12] >_[10] )_[17]=1 ;} if
(_[13] >_[11 ] ||_[17]==1) return
;_[6] = _ [13] / _[11]*(_[1]-_[ 0])
+_[ 0]; _ [7]=_[12]/_[10]*(_[3]-_[2] )+_
[2];_[8]=_[9]=_[14]=0;l2:_[4]=_[8] * _ [8]
;_[ 5]= _ [9]*_[9];_[9]=2*_[8]*_[9]+ _[7
];_[8 ] = _ [ 4 ]-_[5]+_[6];_[14 ]++
;if((_ [14]< _ [15])&&(_[4]+ _[ 5]
<_[16 ])) goto l2; putchar(
" #@*+ "[( int) _[14]%
5 ]);_ [13 ] ++ ; main (
0) ;_[12]++; _[13] =0
;if(_ [17] !=1) putchar
(0xa); main(1);}
Не скажу за IDE для Python, выскажусь за Visual Studio ( где на большую часть подсветки даже внимания не обращал до прочтения статьи).
В контексте «качества» стоит выделить три типа кода:
1. Свой+недавний код. Понятный, забыть еще не успел. При разработке прототипов частенько мелькают // TODO, или throw new NotImplementedException();, так что подсветка помогает. Как минимум не мешает подсветка строк, уходящее ныне выделение цветом {0} в String.Format. Я молчу проогромную помощь R# — не уверен, можно ли рассматривать подсветку R# в том же смысле, что и авторы исследования. Короче, подсветка как минимум не вредит.
2. Чужой хороший или свой+давний+хороший код. Разделение цветом классов и интерфейсов, базовых и составных типов не мешает. Пожалуй, читать код проще: легче выделяются конструкторы и исключения.
3. Чужой или свой+давний не очень хороший код. Полагаю, чем хуже код в смысле выравнивания, тем меньше польза подсветки. При этом подсветка помогает читать код с плохой системой именования.
Резюмируя: подсветке в её VS-проявлении быть. Скромная, незаметная, простые правила цвета.
P.S. Если есть желание поставить свой эксперимент — покодируйте скрипты на T4 в той же студии. Ценность подсветки осознается моментально.
В контексте «качества» стоит выделить три типа кода:
1. Свой+недавний код. Понятный, забыть еще не успел. При разработке прототипов частенько мелькают // TODO, или throw new NotImplementedException();, так что подсветка помогает. Как минимум не мешает подсветка строк, уходящее ныне выделение цветом {0} в String.Format. Я молчу про
2. Чужой хороший или свой+давний+хороший код. Разделение цветом классов и интерфейсов, базовых и составных типов не мешает. Пожалуй, читать код проще: легче выделяются конструкторы и исключения.
3. Чужой или свой+давний не очень хороший код. Полагаю, чем хуже код в смысле выравнивания, тем меньше польза подсветки. При этом подсветка помогает читать код с плохой системой именования.
Резюмируя: подсветке в её VS-проявлении быть. Скромная, незаметная, простые правила цвета.
P.S. Если есть желание поставить свой эксперимент — покодируйте скрипты на T4 в той же студии. Ценность подсветки осознается моментально.
результаты статьи этот аспект никак не затрагивают, т.к. define «код написан хорошо» = ??? и дискуссия покидает пространство аргументов…
Если обратить внимание на вот это предложение:
Технически это означает, что для начинающих программистов подсветка кода важна в большей степени, чем для опытных.то можно сказать почему так происходит — для опытных программистов, пишущих операционные системы подсветка синтаксиса менее полезна. Но это не значит, что она вредна, или бесполезна для остальных.
Эксперимент конечно хорошо, но и без него ясно что с подсветкой проще. )
Он хорош тем, что дает точные цифры: 8.4 секунды и 2.5 минут (150 секунд) экономится.
Интересно было бы поставить другой эксперимент: 100 студентов, анализируют задачи. Подсвечивать задачу или нет для каждой пары «студент\задача» — определяется случайно. Хотя переключения внимания так не проанализируешь.
Интересно было бы поставить другой эксперимент: 100 студентов, анализируют задачи. Подсвечивать задачу или нет для каждой пары «студент\задача» — определяется случайно. Хотя переключения внимания так не проанализируешь.
Эксперимент с десятью участниками — это несерьёзно для HCI. Маленький размер группы даёт статистическую значимость на грани фола (p~0.045). Поэтому к «точным цифрам» результатов нужно относиться очень осторожно.
Думаю, более подробных экспериментов не будет. В первоисточнике указаны ранние исследования той же проблемы, везде прирост производительности относительно небольшой. Эксперимент-прототип проверил, что ситуация не изменилась, и более серьезные эксперименты не нужны.
Ага, я сейчас как раз заворачиваю статью на Eye Tracking Research & Applications на подобную тему и схожими проблемами: 15 участников, при этом дизайн эксперимента — between-subject. Там 7 студентов исправляли ошибки в Java коде (30 строк) без инструкций, а 8 — с инструкцией сначала прочитать техзадание (коротенькое), а уж потом искать ошибки (это так профи делали). Получили типа инструкции помогают быстрее находить ошибки «до 17% быстрее». Ну а после ревью все 4 рецензентов отправили работу на доработку, в том числе и по про причине количества участников.
Так что некачественные статьи не пройдут, спите спокойно, дорогие разработчики :)
Так что некачественные статьи не пройдут, спите спокойно, дорогие разработчики :)
Следующая статься должна быть «Пользуйтесь редакторами кода» (Имеется в виду такие инструменты, как Go To Definition, Find All References, Code Completion, подсвечивание ошибок без компиляции, рефакторинг и т.д.)
подсветка кода помогает быстрее в нем разбираться
Rob Pike категорически не согласен.
У Роба Пайка (да, это имя можно написать по-русски) есть какие-то аргументы?
Очень коротко: подсветка бесполезна и только отвлекает. Хотя я его мнение не разделяю.
Syntax highlighting is juvenile. When I was a child, I was taught arithmetic using colored rods (http://en.wikipedia.org/wiki/Cuisenaire_rods). I grew up and today I use monochromatic numerals.
-rob
Доводные скудные доводы можно найти в Acme FAQ
Q: Is there syntax highlighting?
A: No. The creator of main users of Acme find syntax highlighting unhelpful and distracting.
When I was a child, I was taught arithmetic using colored rodsТравма на всю жизнь, не иначе.
Все равно это довольно мягкая форма, я однажды услышал от коллеги (в контексте разговора про Visual Assist X) что-то вроде:
Но он еще под ZX Spectrum программировал, что ему скажешь :)
Подсветка кода? Зачем? Ты что, гей?
Но он еще под ZX Spectrum программировал, что ему скажешь :)
Кстати, есть довольно известная статья на эту тему, содержащая аргументы: A case against syntax highlighting.
Статья содержательная, спасибо.
Позже попробую соотнести рассуждения с переведенным исследованием более внимательно.
С первого взгляда видно одно интересное различие в выводах:
— в исследовании есть ограничение, которое я сформулировал как "[подсветка] работает только в том случае, если вы знаете что каким цветом подсвечивается" (оно опирается на статью Green, B. F., & Anderson, L. K. (1956). Color coding in a visual search task из Journal of Experimental Psychology). Вывод из этого такой: это знание позволяет сосредоточиться на содержании, уделив меньше внимания «знакомым по цвету» рабочим конструкциям.
— в статье из тех же предпосылок (в абзаце Semantics are more important than syntax — т.е. что содержательная часть кода важнее общего синтаксиса) делает обратный вывод: что нет смысла выделять «неважные» части кода.
Видимо, наш мозг умнее нас (о_О) и ему достаточно самого факта того, что информация рассортирована заранее: даже если for и include подсвечены веселыми цветами, а код — унылым серым… на коде все равно становится легче сосредоточиться))
Позже попробую соотнести рассуждения с переведенным исследованием более внимательно.
С первого взгляда видно одно интересное различие в выводах:
— в исследовании есть ограничение, которое я сформулировал как "[подсветка] работает только в том случае, если вы знаете что каким цветом подсвечивается" (оно опирается на статью Green, B. F., & Anderson, L. K. (1956). Color coding in a visual search task из Journal of Experimental Psychology). Вывод из этого такой: это знание позволяет сосредоточиться на содержании, уделив меньше внимания «знакомым по цвету» рабочим конструкциям.
— в статье из тех же предпосылок (в абзаце Semantics are more important than syntax — т.е. что содержательная часть кода важнее общего синтаксиса) делает обратный вывод: что нет смысла выделять «неважные» части кода.
Видимо, наш мозг умнее нас (о_О) и ему достаточно самого факта того, что информация рассортирована заранее: даже если for и include подсвечены веселыми цветами, а код — унылым серым… на коде все равно становится легче сосредоточиться))
Статья абсолютно бессодержательна. Она пытается сравнивать несравнимое: художественную литературу и программы. Художественную литературу читают. От корки до корки. В программах что-то ищут, никто их не читает от корки до корки.
Возьмите любой словарь (то есть книгу, которую не читают от корки до корки, а в которую бегло заглядывают чтобы что-то нужное для себя «выцепить») и вы увидите всю вашу «неправильную» синтаксическую подсветку в изобилии (с поправкой на ограничения печатного процесса: обычно словари всё-таки чёрно-белые, но бывают и цветные).
Возьмите любой словарь (то есть книгу, которую не читают от корки до корки, а в которую бегло заглядывают чтобы что-то нужное для себя «выцепить») и вы увидите всю вашу «неправильную» синтаксическую подсветку в изобилии (с поправкой на ограничения печатного процесса: обычно словари всё-таки чёрно-белые, но бывают и цветные).
Судя по всему, люди сейчас вообще редко читают, и только бегло посматривают. И вдумываются редко. Ваш ответ на пост о статье, который Вы разместили на 12 часов позже, неоднократно заплюсовали. Мой по сути о том-же самом, но не такой безапелляционный, ещё и заминусовали. Выводы?
1. Нужно громко кричать, что-бы тебя услышали (ну или что-бы заглушить речь окружающих).
2. Своё мнение нужно уверенно навязывать, и спорить с окружающими, даже если мнения совпадают, иначе аудитория не воспримет.
Человеческий мозг и то как он экономит на обработке информации, в угоду упрощению, — невероятно увлекательный механизм для изучения.
И Вы всётаки заблуждаетесь в том, что делают с программами. В них не просто ищут, — их анализируют. Это разные вещи.
Однако, мне всё интереснее и интереснее проверить, — использует-ли мозг те-же самые регионы для ориентации в коде, что и в пространстве. Нужно «закраудфандидь»…
1. Нужно громко кричать, что-бы тебя услышали (ну или что-бы заглушить речь окружающих).
2. Своё мнение нужно уверенно навязывать, и спорить с окружающими, даже если мнения совпадают, иначе аудитория не воспримет.
Человеческий мозг и то как он экономит на обработке информации, в угоду упрощению, — невероятно увлекательный механизм для изучения.
И Вы всётаки заблуждаетесь в том, что делают с программами. В них не просто ищут, — их анализируют. Это разные вещи.
Однако, мне всё интереснее и интереснее проверить, — использует-ли мозг те-же самые регионы для ориентации в коде, что и в пространстве. Нужно «закраудфандидь»…
Нужно не громко кричать, а аргументировать. Но да, понимать как люди читают комментраии тоже нужно. Клиповое мышление, да. Но не только.
Вы высказали странное и, по большому счёту, неверное, утверждение о том, что исходный текст программ и «текст «печатного издания»» неэквивалентны. После чего высказали пару других утверждений из которых ничего, ровным счётом ничего, не следует. Ну да, в тексте программ есть паттерны, а в художественной литературе нет… а зато вот в стихах есть — но в них никто рифму не подсвечивает! Почему из выших высказываний должно следовать что статья неверна? Непонятно.
Я же показал очень простой, наглядный и, главное, позитивный контрпример: словари сущесвуют столетиями, аналоги «подсветки» в них используются тоже столетиями — и из этого сразу видно что «базовые правила типографии» далеко не всегда требуют использовать один-единственный шрифт!
Ваше же утверждение про неэквивалентность «текста «печатного издания»» и «исходного кода программ»… скажите: вот это вот — это печатное издание? А вот это?.. или это? Где вы проводите границу?
Что касается программ — то с ними делают много разных вещей и в зависимости от того что конкретно с ними делают подсветка может помогать или вредить. Когда люди в них что-то ищут — она очень помогает, когда их просто читают — она действительно не так важна.
Вы высказали странное и, по большому счёту, неверное, утверждение о том, что исходный текст программ и «текст «печатного издания»» неэквивалентны. После чего высказали пару других утверждений из которых ничего, ровным счётом ничего, не следует. Ну да, в тексте программ есть паттерны, а в художественной литературе нет… а зато вот в стихах есть — но в них никто рифму не подсвечивает! Почему из выших высказываний должно следовать что статья неверна? Непонятно.
Я же показал очень простой, наглядный и, главное, позитивный контрпример: словари сущесвуют столетиями, аналоги «подсветки» в них используются тоже столетиями — и из этого сразу видно что «базовые правила типографии» далеко не всегда требуют использовать один-единственный шрифт!
Ваше же утверждение про неэквивалентность «текста «печатного издания»» и «исходного кода программ»… скажите: вот это вот — это печатное издание? А вот это?.. или это? Где вы проводите границу?
Что касается программ — то с ними делают много разных вещей и в зависимости от того что конкретно с ними делают подсветка может помогать или вредить. Когда люди в них что-то ищут — она очень помогает, когда их просто читают — она действительно не так важна.
Вы опять спорите не о том, и аргументов как таковых, от Вас не следовало. О «художественной литературе», в статье кроме разноцветной «Алисы» ничего нет.
И самое главное, всё упирается в один абзац: «Well, no. One of the basic rules of thumb in typography is that, when writing a piece of text, you should choose one typeface and stick to it. Likewise, a splash of colour may grab the reader's attention, but it will inevitably decrease the legibility of the text. The natural flow of the text is broken, and it takes more brain effort to piece together the individual letters into words and semantics. Cognitively, the reading process becomes slightly less automatic and slightly more conscious; leaving less room in the conscious part of the mind for actually understanding the text.»
Именно с этим абзацем, я и не согласен, т.к он ставит в однозначноее соответствие код и некий абстрактный текст.
Сравнивать их нельзя по одной простой причине, — совершеннo разная категория текстов. Я не согласен с приравниванием кода, к неким абстрактным текстам.
У Вас плохо с английским. А также у меня вызывает когнитивный диссонанс, выворачивание Вами смысла буквально записанных фраз.
«Базовые правила типографии», в Вашей интерпретации, в оригинальном тексте «правило большого пальца». Эта идиома означает, что так делать принято. И никаких столетий исследований типографов за этим не стоит.
Еслли смотреть глубже. То это правило соблюдается и для словарей и для периодики, и для справочников! Форматирование словаря, имеет чёткую структуру, и не имеет подсветки, несмотря на то, что может использовать шрифт разной толщины и наклона.
Авторы-же статьи против «разноцветья» в одном абзаце. Они сравнивают некую целостную семантическую структуру исходного кода (например функцию), и абзац текста. Я несогласен с этим сравнением. Именно в силу неэквивалентности кода программы и абзаца «печатного издания» (книг, периодической литературы, журнала)
Фактически, смысл всей статьи сводится примерно, к: «Внутри тела функции (как и абзаца в „печатном издании“), должен использоваться один и тотже шрифт, а также никакой подсветки быть не должно.»
Однако словарь многократно ближе к исходному коду, чем газета. Но и в газете, — буквы не подсвечиваются! И даже если заголовок статьи напечатан одним шрифтом (и даже другим цветом), то весь текст статьи совершенно другим, и очень редко, именно для привлечения внимания используется курсив.
«Печатные издания», действительно разнообразны. Например газеты и журналы используют цветные, кричащие заголовки. Если 200 лет назад, этого просто не было, то сейчас цветные [ЗАГОЛОВКИ] в периодикe используется на всю катушку.
Pазнообразие шрифтов в газетах разных лет, хоть и не велико, и выдержано в едином стиле, всё равно присутствует.
Однако, — ЭТО НИКАК НЕ ПРОТИВОРЕЧИТ УТВЕРЖДЕНИЯМ АВТОРОВ СТАТьИ, О «правиле большого пальца в типографии»!
Это никак не может считаться подсветкой синтаксиса. Вот выделять знаки припенания другим цветом, — это подсветка синтаксиса.
Вы высказали тоже самое другими словами и 12ью часами поже:
Как Вы это объясните ?! У меня опять когнитивный диссонанс от Ваших высказываний, которые противоречат друг-другу.
Надеюсь, я разместил предостаточно ловушек, привлекающих внимание и удерживающих его, для того что-бы общий смысл написанного не был утерян.
И я так подозреваю, меня минусовать продолжат, т.к. видимо я слишком много пишу. «Многабукф», — беда современности.
И самое главное, всё упирается в один абзац: «Well, no. One of the basic rules of thumb in typography is that, when writing a piece of text, you should choose one typeface and stick to it. Likewise, a splash of colour may grab the reader's attention, but it will inevitably decrease the legibility of the text. The natural flow of the text is broken, and it takes more brain effort to piece together the individual letters into words and semantics. Cognitively, the reading process becomes slightly less automatic and slightly more conscious; leaving less room in the conscious part of the mind for actually understanding the text.»
Именно с этим абзацем, я и не согласен, т.к он ставит в однозначноее соответствие код и некий абстрактный текст.
Сравнивать их нельзя по одной простой причине, — совершеннo разная категория текстов. Я не согласен с приравниванием кода, к неким абстрактным текстам.
У Вас плохо с английским. А также у меня вызывает когнитивный диссонанс, выворачивание Вами смысла буквально записанных фраз.
«Базовые правила типографии», в Вашей интерпретации, в оригинальном тексте «правило большого пальца». Эта идиома означает, что так делать принято. И никаких столетий исследований типографов за этим не стоит.
Я же показал очень простой, наглядный и, главное, позитивный контрпример: словари сущесвуют столетиями, аналоги «подсветки» в них используются тоже столетиями — и из этого сразу видно что «базовые правила типографии» далеко не всегда требуют использовать один-единственный шрифт!
Еслли смотреть глубже. То это правило соблюдается и для словарей и для периодики, и для справочников! Форматирование словаря, имеет чёткую структуру, и не имеет подсветки, несмотря на то, что может использовать шрифт разной толщины и наклона.
Авторы-же статьи против «разноцветья» в одном абзаце. Они сравнивают некую целостную семантическую структуру исходного кода (например функцию), и абзац текста. Я несогласен с этим сравнением. Именно в силу неэквивалентности кода программы и абзаца «печатного издания» (книг, периодической литературы, журнала)
Фактически, смысл всей статьи сводится примерно, к: «Внутри тела функции (как и абзаца в „печатном издании“), должен использоваться один и тотже шрифт, а также никакой подсветки быть не должно.»
Однако словарь многократно ближе к исходному коду, чем газета. Но и в газете, — буквы не подсвечиваются! И даже если заголовок статьи напечатан одним шрифтом (и даже другим цветом), то весь текст статьи совершенно другим, и очень редко, именно для привлечения внимания используется курсив.
«Печатные издания», действительно разнообразны. Например газеты и журналы используют цветные, кричащие заголовки. Если 200 лет назад, этого просто не было, то сейчас цветные [ЗАГОЛОВКИ] в периодикe используется на всю катушку.
Pазнообразие шрифтов в газетах разных лет, хоть и не велико, и выдержано в едином стиле, всё равно присутствует.
Однако, — ЭТО НИКАК НЕ ПРОТИВОРЕЧИТ УТВЕРЖДЕНИЯМ АВТОРОВ СТАТьИ, О «правиле большого пальца в типографии»!
Это никак не может считаться подсветкой синтаксиса. Вот выделять знаки припенания другим цветом, — это подсветка синтаксиса.
Вы высказали странное и, по большому счёту, неверное, утверждение о том, что исходный текст программ и «текст «печатного издания»» неэквивалентны
Вы высказали тоже самое другими словами и 12ью часами поже:
Она пытается сравнивать несравнимое: художественную литературу и программы.
Как Вы это объясните ?! У меня опять когнитивный диссонанс от Ваших высказываний, которые противоречат друг-другу.
Надеюсь, я разместил предостаточно ловушек, привлекающих внимание и удерживающих его, для того что-бы общий смысл написанного не был утерян.
И я так подозреваю, меня минусовать продолжат, т.к. видимо я слишком много пишу. «Многабукф», — беда современности.
И я так подозреваю, меня минусовать продолжат, т.к. видимо я слишком много пишу.Минусовать продолжат пока вы не научитесь выражать свои мысли. Неужели вы до сих пор верите в то, что «весь мир шагает не в ногу» и только вы — «в ногу»? Остановитесь, подумайте над тем, что вы пишите…
«Базовые правила типографии», в Вашей интерпретации, в оригинальном тексте «правило большого пальца». Эта идиома означает, что так делать принято.Честное слово: хоть бы не позорились. Или в словарь заглянули. «Rules of thumb» — это a rough, practical method of procedure. В русском языке такие вещи принято называть правилами (не путать с законами! из правил могут быть исключения, а законы действуют всегда!).
Форматирование словаря, имеет чёткую структуру, и не имеет подсветки, несмотря на то, что может использовать шрифт разной толщины и наклона.Что значит «не имеет подсветки»? Вы про то, что там неоновых огней нету? Ну дык это ограничение типографское. Разные шрифты и цвета (в словарях, изданных в цвете) — присутствуют. Посмотрите же сами, чёрт побери, на Amazon'е кнопка «Look inside» есть.
Неоновые огни и мигание в редакторах кода редко используется, впрочем, хотя техническая возможность имеется.
Вот выделять знаки припенания другим цветом, — это подсветка синтаксиса.Вы либо издеватесь, либо придуряетесь. Да, бывают, наверное, такие редакторы, которые выделяют только знаки препинания. Но их, в общем-то, не так много (я ни одного не знаю). Как правило выделяются ключевые слова, языковые конструкции (то есть не правая скобка рисуется одним цветом, а левая — другим, а конструкция [...] выделяется одним способом, а (...) — другим, /*...*/ — третьим). Но ведь то же самое происходит и в словарях! Буквально то же самое! На компьютерные, понятно, ссылаться не совсем корректно, но зато просто. Посмотрите сюда:
[test] выделено одним способом, (драгоценного металла) — другим, брит. и амер. — третьим. И в бумажных словарях — то же самое! С поправкой на ограничения технологии!Вы высказали тоже самое другими словами и 12ью часами поже:Ещё раз: вы действительно не понимаете или придуряетесь? Разница между моим утверждением и вашим в том, что вы использовали широкое понятие, которое в результате привело к тому, что ваше утверждение как минимум неочевидно, а как максимум — неверно (в зависимости от того как интерпретировать понятие «печатного издания»), я использовал узкое понятие, которое, разумеется проще понять и с которым особо-то и не поспоришь… но главное даже не в этом, как я уже сказал. Главное: у вас эта мысль «провисла в воздухе» и «потонула в многословии», я же свою «подкрепил» другим, весьма наглядным, примером, показавшим что утвеждлаемое в статье правило может и не исполняться!
Она пытается сравнивать несравнимое: художественную литературу и программы.
Надеюсь, я разместил предостаточно ловушек, привлекающих внимание и удерживающих его, для того что-бы общий смысл написанного не был утерян.И опять вы ничего не поняли. В дискуссиях «ловушки» попросту неуместны, это не детектив. Старайтесь быть проще, чтобы люди к вам потянулись.
Воспринимать текст с экрана и без того сложно, а вы тут ещё «ловушек» понарасставляли — неудивительно, что люди вас минусоют!
Честное слово: хоть бы не позорились. Или в словарь заглянули. «Rules of thumb» — это a rough, practical method of procedure. В русском языке такие вещи принято называть правилами (не путать с законами! из правил могут быть исключения, а законы действуют всегда!).
Не упорствуйте в своей глупости. Учите английский A rule of thumb is a principle with broad application that is not intended to be strictly accurate or reliable for every situation
Перевод: «Правило большого пальца, — широко применяемый принцип, не предназначенный гарантировать точность или быть применимым в любых ситуациях.»
С Вами, я точно не шагаю в ногу.
С теми кто, не в состоянии оценить противоречия в собственных высказываниях, и упорствуют в своём невежестве, мне никогда не будет по пути.
Rule of thumb это правило правой руки. Оно же правило буравчика.
А перевод такой:
Правило правой руки — принцип с широкой областью применения который не должен быть строго точным или надёжным в любой ситуации.
А перевод такой:
Правило правой руки — принцип с широкой областью применения который не должен быть строго точным или надёжным в любой ситуации.
Правильно. Но это один из вариантов перевода одного из смыслов. Одна из больших проблем английского — его многозначность. Почти все слова имеют много смыслов, куча таких чудных вещей, как авто-антонимы и прочее. Брать один вариант из словаря и упорно игнорировать все остальные, при этом ещё и обвинять всех вокруг в незнании английского — это один из способов заработать много минусов. Не самый лучший, впрочем: есть много других, гораздо более простых способов хабрасуицида…
Какое правило правой руки? Перевод у вас тоже верный, но как Вы смогли прийти к выводу, что это «ПРАВИЛО ПРАВОЙ РУКИ»? Мне цепочка Ваших рассуждений интересна :)
Ну в самом названии же говорится «Правило большого пальца». По русски это означает «на глазок». Ну прочтите Bы статью в педивикии хотя-бы.
The earliest known citation comes from J. Durham’s Heaven upon Earth, 1685, ii. 217: «Many profest Christians are like to foolish builders, who build by guess, and by rule of thumb.»[1]
"… как строители дураки, которые строят наугад и руководствуясь правилом большого пальца".
Ну в самом названии же говорится «Правило большого пальца». По русски это означает «на глазок». Ну прочтите Bы статью в педивикии хотя-бы.
The earliest known citation comes from J. Durham’s Heaven upon Earth, 1685, ii. 217: «Many profest Christians are like to foolish builders, who build by guess, and by rule of thumb.»[1]
"… как строители дураки, которые строят наугад и руководствуясь правилом большого пальца".
Да, точно, почитайте википедию. Посмотрите варианты перевода этого словосочетания на другие языки. Там больших пальцев негусто.
А ещё почитайте вот этот абзатц:
То, что описано в нём по-русски называется правилом правой руки. Такое выражение в русском языке есть, а вот выражения правило большого пальца в русском языке нет.
Перевести Rule of thumb как правило большого пальца это ошибка того же рода, что перевести We did it как мы сделали это.
Перевод один в один действительно существует не всегда. Отрывок про христиан переводится примерно вот так:
"… как глупые строители, которые строят наугад и из общих соображений"
А ещё почитайте вот этот абзатц:
Oersted's rule: Hold right hand with the fingertips in the direction of current. The line shall be between the magnet and the palm. Magnet north pole will then turn to the thumb side. Named for Hans Christian Ørsted (often rendered Oersted in English; 14 August 1777 – 9 March 1851), a Danish physicist and chemist who discovered that electric currents create magnetic fields, an important aspect of electromagnetism.
То, что описано в нём по-русски называется правилом правой руки. Такое выражение в русском языке есть, а вот выражения правило большого пальца в русском языке нет.
Перевести Rule of thumb как правило большого пальца это ошибка того же рода, что перевести We did it как мы сделали это.
Перевод один в один действительно существует не всегда. Отрывок про христиан переводится примерно вот так:
"… как глупые строители, которые строят наугад и из общих соображений"
Почти. «Не из общих соображений», а «на глазок», — было-бы гораздо точнее. Но да, так лучше: «глупые строители, которые строят наугад и на глазок».
Всё это напрямую относится к имперской системе мер, а именно дюйм и большой палец, невероятно тесно связаны:
In many other European languages, the word for «inch» is the same as or derived from the word for «thumb», as a man's thumb is about an inch wide (and this was even sometimes used to define the inch);
Но я уже понял, что объяснять, что-либо здесь, — бесполезно.
Всё это напрямую относится к имперской системе мер, а именно дюйм и большой палец, невероятно тесно связаны:
In many other European languages, the word for «inch» is the same as or derived from the word for «thumb», as a man's thumb is about an inch wide (and this was even sometimes used to define the inch);
Но я уже понял, что объяснять, что-либо здесь, — бесполезно.
Объяснять полезно прежде всего тому, кто это делает. Таким образом он улучшает собственное понимание предмета.
Так вот. Перевод идиомы rule of the thumb идиомой на глазок крайне неточен. Делать что-то на глазок не означает руководствоваться какими-то правилами общего характера. Делать что-то на глазок означает не проводить точных измерений. А делать что-то по правилам общего характера по русски звучит как из общих соображений. Возможно есть словосочетание, лучше передающее смысл, но вы его не предложили.
Так вот. Перевод идиомы rule of the thumb идиомой на глазок крайне неточен. Делать что-то на глазок не означает руководствоваться какими-то правилами общего характера. Делать что-то на глазок означает не проводить точных измерений. А делать что-то по правилам общего характера по русски звучит как из общих соображений. Возможно есть словосочетание, лучше передающее смысл, но вы его не предложили.
Вас видимо удивило, что разные словосочетания в одном языке могу означать одно и то же явление. Это случается нередко, привыкайте.
Если вы ознакомитесь с содержимым по предоставленной вами ссылке, то вы обнаружите, что один из вариантов правила правой руки предложен Флемингом. В тексте, описывающем это правило, вы найдёте ссылку на уже упомянутого мной Ганса Христиана Орстеда.
Значения терминов Right hand rule и Rule of the thumb перекрываются не полностью, но в русском языке идиомы передающей смысл лучше, чем правило правой руки просто нет. И уж тем более в русском языке нет правила большого пальца.
P. S. И обратите внимание, громогласные заявления делаете в основном вы. Восклицательные знаки в основном ваши.
Если вы ознакомитесь с содержимым по предоставленной вами ссылке, то вы обнаружите, что один из вариантов правила правой руки предложен Флемингом. В тексте, описывающем это правило, вы найдёте ссылку на уже упомянутого мной Ганса Христиана Орстеда.
Значения терминов Right hand rule и Rule of the thumb перекрываются не полностью, но в русском языке идиомы передающей смысл лучше, чем правило правой руки просто нет. И уж тем более в русском языке нет правила большого пальца.
P. S. И обратите внимание, громогласные заявления делаете в основном вы. Восклицательные знаки в основном ваши.
Данная статья, без всяких на то доказательств, заявляет об эквивалентности текста «печатного издания» и исходного кода программ.
Я с этим утверждением согласиться не могу, по следующим причинам:
1. Словарный запас газеты или книги, не ограничен ничем, кроме словарного запаса автора и редактора.
2. В печатном издании отсутствуют повторяющиеся и легко распознаваемые мозгом паттерны, которые в исходном коде являются ключевыми для понимания и осмысления того, что-же делает этот код.
Предложу несколько гипотез (возможно не связанных между собой):
а) При анализе информации, мозг пытается её упростить (абстрагировать), для того что-бы тратить меньше энергии на обработку этой информации. Т.к. любой исходный код содержит не случайный набор букв, расположенных на случайном расстоянии друг от друга, а синтаксически и семантичски значимые паттерны, то подсветка кода должна облегчить (повысить скорость?): 1. распознавания паттерна; 2. оценку, анализ и упрощене паттерна; 3. оценку и анализ связи между паттернами в разных участках файла исходног текста.
б) Подсветка синтаксиса в коде, помогает ориентироваться в нём, точно так-же как это делает карта местности. То есть я предполагаю, что для чтения и осмысления кода используются механизмы схожие с механизмами ориентации в пространстве.
Кто-бы ещё занялся исследованием этих гипотез? :)
Я с этим утверждением согласиться не могу, по следующим причинам:
1. Словарный запас газеты или книги, не ограничен ничем, кроме словарного запаса автора и редактора.
2. В печатном издании отсутствуют повторяющиеся и легко распознаваемые мозгом паттерны, которые в исходном коде являются ключевыми для понимания и осмысления того, что-же делает этот код.
Предложу несколько гипотез (возможно не связанных между собой):
а) При анализе информации, мозг пытается её упростить (абстрагировать), для того что-бы тратить меньше энергии на обработку этой информации. Т.к. любой исходный код содержит не случайный набор букв, расположенных на случайном расстоянии друг от друга, а синтаксически и семантичски значимые паттерны, то подсветка кода должна облегчить (повысить скорость?): 1. распознавания паттерна; 2. оценку, анализ и упрощене паттерна; 3. оценку и анализ связи между паттернами в разных участках файла исходног текста.
б) Подсветка синтаксиса в коде, помогает ориентироваться в нём, точно так-же как это делает карта местности. То есть я предполагаю, что для чтения и осмысления кода используются механизмы схожие с механизмами ориентации в пространстве.
Кто-бы ещё занялся исследованием этих гипотез? :)
Вы вообще не туда полезли. Статья начинается с правильных предпосылок, а потом переходит к идиотским выводам.
Посылка: типогрофы за столетия всё выверили и нужно делать как и они. Возьмите первую попавшуюся книгу и всё сразу поймёте.
Ну я решил проверить, встал с кресла, дошёл до шкафа, взял первую попавшуюся книгу, открыл и обнаружил, что вау-вау-вау: все понятия помечены шрифтом, изменяемые части слов — другим, и т.д. и т.п. Едва ли не десяток шрифтов в одном абзаце!
И как же это соотносится с «самоочевидным» самодовольным заявлением автором про то, что типогрфы говорят, что так делать не нужно?
Да никак: типографы, конечно, правы — но мне первой в руки попался англо-русский словарь Мюллера, а не детектив.
Намёк понятен? Если вы хотите прочитать книгу (или код) «от корки до корки» — то подсветка скорее вредна, это абсолютная правда. Если же вы хотите в куске кода что-то быстро найти — то тут она в самый раз как те самые столетия изысканий типографов подтверждают.
А теперь, внимание вопрос: как часто вы читаете код и как часто вы его бегло просматриваете чтобы в нём что-то найти?
Посылка: типогрофы за столетия всё выверили и нужно делать как и они. Возьмите первую попавшуюся книгу и всё сразу поймёте.
Ну я решил проверить, встал с кресла, дошёл до шкафа, взял первую попавшуюся книгу, открыл и обнаружил, что вау-вау-вау: все понятия помечены шрифтом, изменяемые части слов — другим, и т.д. и т.п. Едва ли не десяток шрифтов в одном абзаце!
И как же это соотносится с «самоочевидным» самодовольным заявлением автором про то, что типогрфы говорят, что так делать не нужно?
Да никак: типографы, конечно, правы — но мне первой в руки попался англо-русский словарь Мюллера, а не детектив.
Намёк понятен? Если вы хотите прочитать книгу (или код) «от корки до корки» — то подсветка скорее вредна, это абсолютная правда. Если же вы хотите в куске кода что-то быстро найти — то тут она в самый раз как те самые столетия изысканий типографов подтверждают.
А теперь, внимание вопрос: как часто вы читаете код и как часто вы его бегло просматриваете чтобы в нём что-то найти?
1. Вы без всяких доказательств делаете утверждения вида «вредно/не вредно». При любой статистической выборке есть стандартное отклонение. Тоесть кому-то удобно(менее энергозатратно), а кому-то нет. Где статистические выкладки?
1.1 В технической литературе, есть такое понятие «типографские соглашения». Они никак не мешают читать книги от корки до корки. И я тому подтверждение. У меня есть привычка читать книги от корки до корки, если они мне нужны, или интересны. Одна из самых захватывающих серий книг, прочитанных мной, — комплект документации по информиксу в 1995-м году. 7 книг Informix Online Dynamic Server 7.1. Самые разнообразные кегли, рамочки и прочее, никак не мешали усвоению материала, и увлекательности чтения.
2. Вот этим пассажем: «Если же вы хотите в куске кода что-то быстро найти — то тут она в самый ...», Вы сказали почти тоже самое, что и я. Только я предположил, и выразил гипотезу, которую можно исследовать и или опровергнуть или подтвердить, Вы-же бездоказательно утверждаете.
3. Пассаж: "Столетия изыскания типографов", очень забавляет. Tempora mutantur et nos mutamur in illis. Хочу статистики. Свежей. Из этого десятилетия. И всё таки предположу, что мозг приспосабливается к форме представленной информации, с течением времени (эту фразу я мог-бы сделать утверждением, если-бы не было лень искать ссылки на исследования, которые Вы без труда найдёте сами).
1.1 В технической литературе, есть такое понятие «типографские соглашения». Они никак не мешают читать книги от корки до корки. И я тому подтверждение. У меня есть привычка читать книги от корки до корки, если они мне нужны, или интересны. Одна из самых захватывающих серий книг, прочитанных мной, — комплект документации по информиксу в 1995-м году. 7 книг Informix Online Dynamic Server 7.1. Самые разнообразные кегли, рамочки и прочее, никак не мешали усвоению материала, и увлекательности чтения.
2. Вот этим пассажем: «Если же вы хотите в куске кода что-то быстро найти — то тут она в самый ...», Вы сказали почти тоже самое, что и я. Только я предположил, и выразил гипотезу, которую можно исследовать и или опровергнуть или подтвердить, Вы-же бездоказательно утверждаете.
3. Пассаж: "Столетия изыскания типографов", очень забавляет. Tempora mutantur et nos mutamur in illis. Хочу статистики. Свежей. Из этого десятилетия. И всё таки предположу, что мозг приспосабливается к форме представленной информации, с течением времени (эту фразу я мог-бы сделать утверждением, если-бы не было лень искать ссылки на исследования, которые Вы без труда найдёте сами).
Нифига ж себе «вы сказали почти тоже самое, что и я»…
Я беру посыл из статьи (текст программ ничем радикально от других текстов не отличается) и применяю его к тому, что вижу в реальном мире. Вижу не совсем то, чего хотелось бы видеть авторам. Вижу что в книгах, которые предназначены не для чтения «от корки до корки», а для поиска (всевозможные справочники, словари и прочее) синтаксическая разметка очень даже применяется. В стихах — нет, в романах — нет, а в словарях — очень даже да.
Вы же утверждаете совсем иное: что исходный посыл статьи вообще в корне неверен и нужны дополнительные исследования, которые покажут, что печатный текст и программа — это совсем разные вещи.
Ну проведёте исследования — расскажете. Интересно будет почитать. Мне же никаких исследований не нужно, так как я исхожу из тех же посылок, что и авторы статьи, просто указываю на то, что они не совсем правильно их применили.
Я беру посыл из статьи (текст программ ничем радикально от других текстов не отличается) и применяю его к тому, что вижу в реальном мире. Вижу не совсем то, чего хотелось бы видеть авторам. Вижу что в книгах, которые предназначены не для чтения «от корки до корки», а для поиска (всевозможные справочники, словари и прочее) синтаксическая разметка очень даже применяется. В стихах — нет, в романах — нет, а в словарях — очень даже да.
Вы же утверждаете совсем иное: что исходный посыл статьи вообще в корне неверен и нужны дополнительные исследования, которые покажут, что печатный текст и программа — это совсем разные вещи.
Ну проведёте исследования — расскажете. Интересно будет почитать. Мне же никаких исследований не нужно, так как я исхожу из тех же посылок, что и авторы статьи, просто указываю на то, что они не совсем правильно их применили.
Я вижу множество расхождений в Ваших утверждениях.
1. Вот это: "которые покажут, что печатный текст и программа — это совсем разные вещи", — называется извращение трактовки.
Я не утверждал, что они покажут. Я выдвинул две конкретные гипотезы, результаты исследования которых были-бы мне интересны.
Одновременно, утверждаю, что именно для меня, код и «печатный текст», — это действительно разные вещи. Словари и код ближе друг к другу, чем к «печатному тексту». Тоесть словари, как и код имеют структуру, те самые паттерны о которых я и говорил.
Далее, опять цитирую Вас: «Я беру посыл из статьи (текст программ ничем радикально от других текстов не отличается) и применяю его к тому, что вижу в реальном мире. Вижу не совсем то, чего хотелось бы видеть авторам.»
Уточните пожалуйста, Вы поддерживате гипотезу о не эквивалентности кода и «печатного текста» или нет? Хочется чёткого понимания, что мы говорим на одном языке.
Далее: «Вижу что в книгах, которые предназначены не для чтения «от корки до корки», а для поиска (всевозможные справочники, словари и прочее) синтаксическая разметка очень даже применяется. В стихах — нет, в романах — нет, а в словарях — очень даже да.»
а) в словарях нет синтактической разметки, — есть семантическая
б) в стихах есть «значимое», форматирование (Маяковский, Рождественский)
в) в романах также есть разметка: диалоги, выделения курсивом, оглавления
В любом случае, если я на этом месте, не перестал Вас понимать, то Вы не считаете код и «печатный текст» эквивалентами.
Тогда, расхождение здесь: «Нифига ж себе «вы сказали почти тоже самое, что и я»…»
1. Вот это: "которые покажут, что печатный текст и программа — это совсем разные вещи", — называется извращение трактовки.
Я не утверждал, что они покажут. Я выдвинул две конкретные гипотезы, результаты исследования которых были-бы мне интересны.
Одновременно, утверждаю, что именно для меня, код и «печатный текст», — это действительно разные вещи. Словари и код ближе друг к другу, чем к «печатному тексту». Тоесть словари, как и код имеют структуру, те самые паттерны о которых я и говорил.
Далее, опять цитирую Вас: «Я беру посыл из статьи (текст программ ничем радикально от других текстов не отличается) и применяю его к тому, что вижу в реальном мире. Вижу не совсем то, чего хотелось бы видеть авторам.»
Уточните пожалуйста, Вы поддерживате гипотезу о не эквивалентности кода и «печатного текста» или нет? Хочется чёткого понимания, что мы говорим на одном языке.
Далее: «Вижу что в книгах, которые предназначены не для чтения «от корки до корки», а для поиска (всевозможные справочники, словари и прочее) синтаксическая разметка очень даже применяется. В стихах — нет, в романах — нет, а в словарях — очень даже да.»
а) в словарях нет синтактической разметки, — есть семантическая
б) в стихах есть «значимое», форматирование (Маяковский, Рождественский)
в) в романах также есть разметка: диалоги, выделения курсивом, оглавления
В любом случае, если я на этом месте, не перестал Вас понимать, то Вы не считаете код и «печатный текст» эквивалентами.
Тогда, расхождение здесь: «Нифига ж себе «вы сказали почти тоже самое, что и я»…»
UFO just landed and posted this here
UFO just landed and posted this here
Интересно, насколько эффективнее будет давать функциям хорошие имена?
Мне кажется, подсветка особенно полезна при просмотре кода, содержащего многострочные строковые литералы и многострочные комментарии.
Мне кажется, подсветка особенно полезна при просмотре кода, содержащего многострочные строковые литералы и многострочные комментарии.
Посветка подсветке рознь. Иногда бывает так:
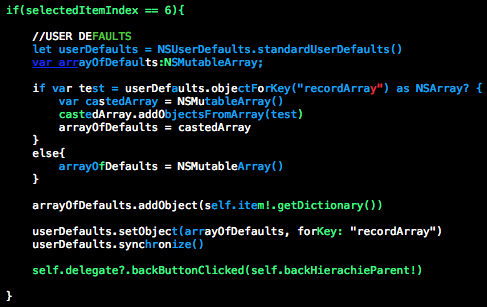
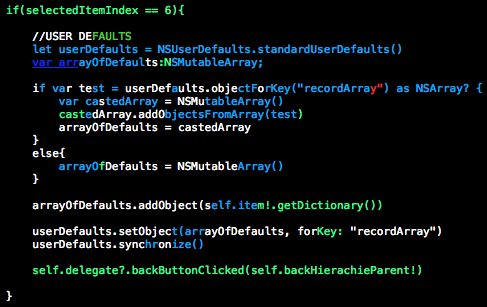
сразу вспоминается из одной книжки
int a = 5
int b = 10
c = a/*b
С подсветкой сразу понимаешь где косяк.
int a = 5
int b = 10
c = a/*b
С подсветкой сразу понимаешь где косяк.
Оно и так понятно. Скажу холиварную вещь, конечно, но проблема в Си. Знаков на клавиатуре много, но создатели решили использовать одни и те же для разных операций. Вот откуда и косяки.
Ага, давайте использовать Emoji!
Как то так

Но ведь отличный план же!
Даёшь APL. И специальную клавиатуру, да.
проблема в Си. Знаков на клавиатуре много, но создатели решили использовать одни и те же для разных операций
А точно много? Предложите ваш вариант.
Знак доллара или тильда например?
Тильда в Си уже занята под бинарное отрицание.
Знак доллара — валидная часть идентификатора (иными словами, $b — это корректный идентификатор).
Заодно напомню, что в Си некоторые символы уже используются несколько раз, так что одного свободного знака доллара вам все равно не хватит.
Знак доллара — валидная часть идентификатора (иными словами, $b — это корректный идентификатор).
Заодно напомню, что в Си некоторые символы уже используются несколько раз, так что одного свободного знака доллара вам все равно не хватит.
Значит в некоторых случаях можно их было заменить словами, как это сделали в Паскале в своё время. and, or, xor и not очень даже легко воспринимаются человеком и понятно что делают. Это там освободило пару символов и позволило не использовать один и тот же символ для разных операций. Ровно как и присваивание очень сильно отличается от равно. Спутать и совершить ошибку просто нельзя.
Но, как я уже сказал изначально — тема холиварная, а я холиварить не хочу, честное слово.
Но, как я уже сказал изначально — тема холиварная, а я холиварить не хочу, честное слово.
Значит в некоторых случаях можно их было заменить словами, как это сделали в Паскале в своё время. and, or, xor и not очень даже легко воспринимаются человеком и понятно что делают.
А изначально вы написали «знаков на клавиатуре много». Понятно, что если писать словами, то слов на всех хватит, но будет ли это так же выразительно?
А почему бы и нет? Мы с Вами же словами общаемся и очень даже выразительно. Скажем в C# есть же слова out, ref, var. Аналогичные паскалевским out, const и var. В плюсах, насколько я знаю, это всё решается всяческими значками (привет звёздочки).
Код мы пишем не для компьютера, а для человека. Для человека, который будет его поддерживать и модифицировать, читать. Компьютеру всё-равно какую ахинею читать, хоть бреинфак. А вот человеку нет.
Код мы пишем не для компьютера, а для человека. Для человека, который будет его поддерживать и модифицировать, читать. Компьютеру всё-равно какую ахинею читать, хоть бреинфак. А вот человеку нет.
А почему бы и нет? Мы с Вами же словами общаемся и очень даже выразительно.
Потому что выразительность нашего с вами общения и компьютерного кода отличаются.
Скажем в C# есть же слова out, ref, var. [...] В плюсах, насколько я знаю, это всё решается всяческими значками (привет звёздочки).
Э нет.
var в C# — это (возможно, с оговорками) auto в C++. ref/out же выписан отдельно по двум причинам: во-первых, предполагается, что его будут использовать существенно реже, во-вторых, что важнее, в C# есть «настоящие указатели» (*ptr), и их семантика отличается от семантики ref/out.Код мы пишем не для компьютера, а для человека. Для человека, который будет его поддерживать и модифицировать, читать. Компьютеру всё-равно какую ахинею читать, хоть бреинфак. А вот человеку нет.
А почему вы считаете что verbose-запись — лучше, чем terse? Как тогда объяснить тот факт, что математики в записи чаще используют символьные нотации, нежели слова?
А у математиков есть двусмысленность в каждом значке? У математиков есть знак равенства = и неравенства, есть знак больше, есть меньше, а есть больше или равно, меньше или равно. На клавиатуре они есть? Нет. Они есть в шрифтах, но набирать их жуть как не удобно.
У математиков для каждой операции свой символ, да и глупо сравнивать математику и программирование. Программирование основано на языке программирования, а математика на формулах. Давайте ещё сравним программирование с химией может?
У математиков для каждой операции свой символ, да и глупо сравнивать математику и программирование. Программирование основано на языке программирования, а математика на формулах. Давайте ещё сравним программирование с химией может?
А у математиков есть двусмысленность в каждом значке?
Не в каждом, но есть.
У математиков есть знак равенства = и неравенства
И как вы отличите равенство от присвоения? (в математике есть и то, и другое)
да и глупо сравнивать математику и программирование
Учитывая, что одно выросло из другого — совсем не глупо.
Программирование основано на языке программирования, а математика на формулах.
Программирование основано на алгоритмах. Язык программирования — всего лишь способ записи.
Что за знак присвоения в математике, простите мне моё невежество. Всегда считал, что в математике нет присвоения, есть только равенство.
«Пусть А — это...»
Значит знак присвоения это тире? Есть какие-то печатные материалы по этому поводу почитать?
Нет, знак присвоения — это знак присвоения. Устоявшегося символа нет.
math.stackexchange.com/a/63857
А тире как раз используется в обычной письменной речи.
math.stackexchange.com/a/63857
А тире как раз используется в обычной письменной речи.
Это не присвоение, это чисто школьный квантор, который используется чтобы упростить школьникам жизнь и не вводить кванторы существования(∃) и всеобщности(∀). В «настоящей» математике его нету, как и общепринятого символа для него.
Наиболее близкое к присвоению, это т. н. «определение», которое записывается, внезапно, как ":=" (да, как в Паскале).
Наиболее близкое к присвоению, это т. н. «определение», которое записывается, внезапно, как ":=" (да, как в Паскале).
Скажем так, я это видел больше одного раза в совсем не школьных лекциях. Другое дело, что да, соседний лектор в этом же месте использовал
:=, а более соседний ←. Было весело.Это нормально.
Просто любое «Пусть X — блаблабла. Тогда для него выполняется такая-то теорема» на самом деле в более «правильной» декларативной записи превращается в «Для всех X, принадлежащих такому-то множеству, выполняется такой-то предикат» или «Существует такое X, принадлежащее такому-то множеству, что для него выполняется такой-то предикат».
Просто любое «Пусть X — блаблабла. Тогда для него выполняется такая-то теорема» на самом деле в более «правильной» декларативной записи превращается в «Для всех X, принадлежащих такому-то множеству, выполняется такой-то предикат» или «Существует такое X, принадлежащее такому-то множеству, что для него выполняется такой-то предикат».
Там был другой кейс. Я, к сожалению, не могу сейчас вспомнить.
(но вообще да, императивное присвоение в математике хрен найдешь, чаще используется «определение», с символикой которого и случаются пляски)
(но вообще да, императивное присвоение в математике хрен найдешь, чаще используется «определение», с символикой которого и случаются пляски)
О чем я и говорил. Нет понятия присвоения в математике. Только равенство.
Не «нет», а «очень редко используется», и не «только равенство», а «еще есть определение».
Но не суть,
Но не суть,
= — не единственный многозначный символ. Тильде не повезло намного больше.Нету. Потому что в математике переменная — не «ящичек куда можно положить значение», а короткий идентификатор для множества значений. А множеству значений мы ничего не присваиваем, мы его определяем набором условий.
UPD. Кроме равенства, неравенства, определения, соответственно есть еще всякие принадлежности и непринадлежности к множествам, у которых более базовая семантика чем у равенства.
UPD. Кроме равенства, неравенства, определения, соответственно есть еще всякие принадлежности и непринадлежности к множествам, у которых более базовая семантика чем у равенства.
Не, ты не прав. «Для всех X, принадлежащих такому-то множеству, выполняется такой-то предикат» — это утверждение (теоремы, леммы и т.п.).
А в доказательстве используется «Пусть x — любое значение из множества… тогда...» или «Возьмем x — любое значение из множества… тогда...»
И это, в принципе, присвоение. Мы после этого проводим логическую цепочку основываясь на том что значение из множества…
А в доказательстве используется «Пусть x — любое значение из множества… тогда...» или «Возьмем x — любое значение из множества… тогда...»
И это, в принципе, присвоение. Мы после этого проводим логическую цепочку основываясь на том что значение из множества…
А вообще: вот. Очень любопытное чтение.
А у математиков есть двусмысленность в каждом значке?
Да, математики обозначают совершенно разные вещи одинаковыми закорючками. Разные разделы математики могут использовать одинаковую нотацию для обозначения совершенно не связанных объектов и связей.
Точно, про тильду протупил.
Очевидно что все неиспользуемые символы — валидные части идентификатора (например, если! не использовался, то !b тоже был бы корректным). Так что про доллар не аргумент. Нижнее подчёркивание и собака есть еще.
Очевидно что все неиспользуемые символы — валидные части идентификатора (например, если! не использовался, то !b тоже был бы корректным). Так что про доллар не аргумент. Нижнее подчёркивание и собака есть еще.
Так что про доллар не аргумент. Нижнее подчёркивание и собака есть еще.
Все равно не хватит символов, чтобы покрыть все операции. Единственный вариант — это замена части операторов на обычные слова (как ссылаются выше на примере Паскаля), но это уже другая выразительность.
Ну, C++ идёт своим путём, как обычно. Для справки:
and и or в C++ — это ключевые слова. И да, используются они именно так, как вы подумали :-)Эксперимент не полный. :)
Осталось выяснить, какая подсветка эффективнее, синтаксическая или семантическая.
Осталось выяснить, какая подсветка эффективнее, синтаксическая или семантическая.
Это просто будет другой эксперимент. Причем в итоге надо будет сравнивать три вариантна: без подсветки, с синтанкической и семантической (потому что вдруг она… мешает?)
Ну слава б-гу, думал KDevelop никто не упомянет :)
Про себя могу сказать, что семантическая подсветка повышает производительность в разы. Не говоря уже о том, что практически не бывает такого, что отправляешь на компиляцию код с синтаксическими ошибками. Система большая, сборка медленная. Семантика здорово позволяет экономить время на мелочах. Не говоря уже о том, что ловятся ситуаций с копипастой и случайным использованием не той переменной в выражении.
Про себя могу сказать, что семантическая подсветка повышает производительность в разы. Не говоря уже о том, что практически не бывает такого, что отправляешь на компиляцию код с синтаксическими ошибками. Система большая, сборка медленная. Семантика здорово позволяет экономить время на мелочах. Не говоря уже о том, что ловятся ситуаций с копипастой и случайным использованием не той переменной в выражении.
Уважаемый Чебурашка, а где эта статья была опубликована, в каком рецензируемом журнале? Я только ссылки на реддит пока нахожу, и ещё блог «Lambda the Ultimate». Там есть хоть какое-то рецензирование? Я это к тому, что вроде как статья подтверждает очевидное, но всё же будет лучше если она ещё будет и признана качественной по исследовательским меркам.
Статья опубликована на семинаре/симпозиуме (как правильно переводится workshop?) местного значения PPIG 2015. То есть строгость рецензирования минимальная из существующих. Во-вторых, опубликована молодым аспирантом без соавторов, что для серьёзной группы нетипично. В третьих, маленький размер выборки делает результаты недостоверными, то есть бесполезными.
Поэтому по исследовательским меркам статья серьёзного обсуждения пока не заслуживает.
Поэтому по исследовательским меркам статья серьёзного обсуждения пока не заслуживает.
Уважаемый anmipo уже ответил. И да, как серьезное исследование ее рассматривать просто нельзя.
И результаты на такой выборке и с такими параметрами на самой грани того, что вообще можно считать «статистикой»)
Плюс к этому, меня заинтересовала тема и непосредственность, с которой авторы подошли к исследованию — это само по себе может служить хорошим примером «гибкого научного» (как минимум рационального) подхода к окружающим нас системам.
И результаты на такой выборке и с такими параметрами на самой грани того, что вообще можно считать «статистикой»)
Плюс к этому, меня заинтересовала тема и непосредственность, с которой авторы подошли к исследованию — это само по себе может служить хорошим примером «гибкого научного» (как минимум рационального) подхода к окружающим нас системам.
UFO just landed and posted this here
UFO just landed and posted this here
А я заметил, что разноцветные буквы и цифры в коде меня отвлекают/раздражают. В итоге, я пришел к компромиссу: использование различных начертаний вместо цветов для выделения слов (жирный для ключевых слов, подчеркнутый — для полей класса и т. д.). Цвета используются в основном для строк.

На самом деле это дико интересная тема, я год целенаправлено жил без подсветки синтаксиса.
Выключил я её сознательно именно для того, чтобы улучшить качество кода, после встречи с замечательным человеком и прочтения вот этой статьи: www.unicog.org/publications/ReadingDegradedWordsDorsalVentral_Neuroimage2008.pdf
Если в двух словах: у человека есть две «системы чтения», одна из них работает, когда читать трудно, вторая используется для «нормального чтения». Есть основания полагать, что когда читать трудно, качество чтения выше, допускается меньше ошибок и всё такое.
Через некоторое время, правда, мозг прекрасно учится читать код без подсветки и эффект улетучивается. Так что сейчас я уже не заморачиваюсь: есть подсветка — пусть будет, нет её — не стану включать.
Эксперимент был очень полезным.
Что касается этого вот исследования: очень маленькая выборка, я думал намного больше будет. По такой выборке делать выводы нельзя, это очевидно. Вдобавок, большинство людей программируют с подсветкой синтаксиса, а значит их мозг уже натренирован на восприятие «подсвеченного текста». Само собой им проще будет с подсветкой, чем без неё.
В выводах, опять же, фигурирует слово «скорость», а вот о серьёзном контроле качества понимания прочитанного кода на такой выборке и таких примерах говорить рано.
Пока получается как на этой картинке:

Выключил я её сознательно именно для того, чтобы улучшить качество кода, после встречи с замечательным человеком и прочтения вот этой статьи: www.unicog.org/publications/ReadingDegradedWordsDorsalVentral_Neuroimage2008.pdf
Если в двух словах: у человека есть две «системы чтения», одна из них работает, когда читать трудно, вторая используется для «нормального чтения». Есть основания полагать, что когда читать трудно, качество чтения выше, допускается меньше ошибок и всё такое.
Через некоторое время, правда, мозг прекрасно учится читать код без подсветки и эффект улетучивается. Так что сейчас я уже не заморачиваюсь: есть подсветка — пусть будет, нет её — не стану включать.
Эксперимент был очень полезным.
Что касается этого вот исследования: очень маленькая выборка, я думал намного больше будет. По такой выборке делать выводы нельзя, это очевидно. Вдобавок, большинство людей программируют с подсветкой синтаксиса, а значит их мозг уже натренирован на восприятие «подсвеченного текста». Само собой им проще будет с подсветкой, чем без неё.
В выводах, опять же, фигурирует слово «скорость», а вот о серьёзном контроле качества понимания прочитанного кода на такой выборке и таких примерах говорить рано.
Пока получается как на этой картинке:

Sign up to leave a comment.
Пользуйтесь подсветкой кода