Несколько лет назад я попробовал сделать сайт на такой системе как MODx и мне понравилось, не смотря на опыт работы с другими CMS, а может и благодаря этому. Понравилась именно логика построения работы с ней, принципы структуры данных и многое другое, но в первую очередь, то, что фрилансеру нужно особенно часто – простота и скорость запуска проекта при высокой гибкости. Но, хотя MODx мне до сих пор по нраву, пост не совсем о ней и даже скорее совсем о другом.
На самом деле я рассматриваю эту cms только как пример, того что присутствует во многих и опенсурс, и коммерческих системах. Просто мне как фрилансеру до недавних пор приходилось работать почти всегда с разработкой сайтов по дешевле и побыстрее – может у других фрилансеров много «жирных» клиентов, я не знаю, у меня не было. Так вот такая ситуация привела к не плохому опыту работы на модыксе. Но открытие собственной компании и дальнейшее подтягивание клиентов с индивидуальными запросами, потребовало вспоминать и улучшать свой лвл в настоящем программировании и построении баз данных. И вот тут я и почувствовал какой-то дискомфорт, что ли, ну как минимум смущение при воспоминании структуры как MODx, так и некоторых других открытых систем. Далее поясняю подробнее, что именно показалось странным, но интересным.
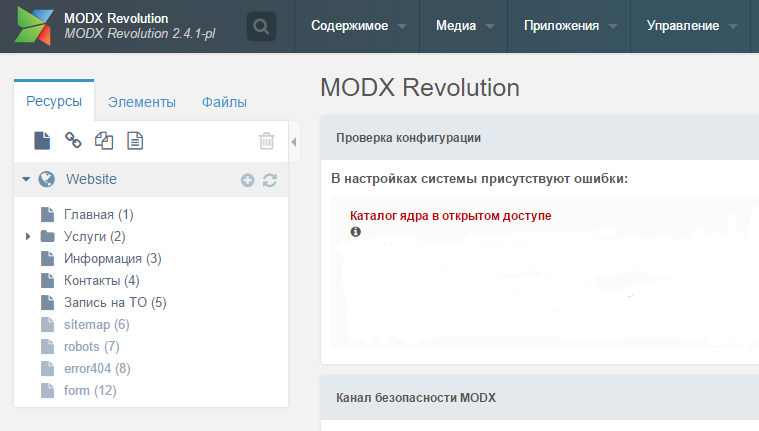
Дело в том, что в MODx Revo основным понятием для построения структуры сайта являются ресурсы. Вот именно, там нет такого как, например, в том же Вордпрессе отдельно страницы сайта, отдельно записи блога. Все страницы и записи, и даже много чего еще реализуется через модель ресурсов сайта. На самом деле это удобно, особенно учитывая тот факт, что это cmf/cms, то есть система рассчитана на разработку совершенно разных сайтов и тематически и технически. Таким образом, за всей структурой сайта удобно следить в одной панели управления ресурсами. В общем, система ресурсов позволяет создавать и управлять следующими сущностями сайта (хотел было написать объектами, но в ООП это слово уже занято, так что пусть будет «сущности»):
• Обычные html-страницы;
• Разного рода категории и разделы блога или каталога;
• Товары и их категории;
• XML-документы, например, sitemap.xml для поисковых роботов;
• Текстовые документы, к примеру, robots.txt правильно сделать ресурсом, а не просто залить файлом;
• Json-страницы, которые лично я использую для того же аякс;
• Создать собственный формат текстового файла.
Вот такое объединение множества различных «сущностей» сайта в объекте одной модели Resources и вызвало мой интерес. Разум философа зашевелился и начал выдавать множество предположений и вопросов.
Во-первых, я обратил внимание на пользователей, потому что они сделаны совершенно отдельно от ресурсов. Как бы на первый взгляд это логично, но с другой стороны, если начали такую пляску с объединением кучи всего, почему бы не сделать все до конца. Да-да, максимализм в деле. Тем более, что сделать пользователей как один из видов ресурсов не представляет большой проблемы. В случае с modx это по большей части реализуется с помощью плейсхолдеров, позволяющих расширить количество атрибутов ресурса, и «контекстов», дающих возможность выделять часть ресурсов по их назначению. Реализация же чего-то подобного на фреймворке (я имею ввиду php-фреймворки) или голой связке скриптов и реляционной базы данных совсем дело не сложное.
Во-вторых, совершенно отдельными моделями реализуются шаблоны и вся система представления и настройки сайта. Почему бы их тоже не объединить в одну модель, хотя бы чисто ради эксперимента. Чувствую летящие в меня помидоры.
По сути, это продолжение работы натурфилософов, только перенесенное в плоскость хранения данных: «Что есть единое» и стоит ли идти путем обобщения при проектировании базы данных? Под обобщением, или переходом от частного к общему, я подразумеваю как раз то слияние нескольких моделей на уровне MVC проекта и соответственно таблиц на уровне базы данных, которое и заметил в modx. Хотя в ситуации с БД все же объединяются не таблицы, а именно ключевые атрибуты (т.н. первичный ключ), что приводит к объединению и таблиц. Но это не означает, что подобную структуру нельзя приводить к нормальной форме.
Давайте разберем чисто гипотетический пример. При проектировании базы данных нам понадобилось хранить и предоставлять доступ к нескольким «сущностям» веб-приложения: администраторы сайта, с разными ролями и правами; клиенты; страницы сайта; тэги; товары; категории. Существует несколько способов построить базу данных. И я говорю не о нормализации БД, которую нужно делать, приводя по хорошему к третьему виду. Я имею ввиду количество или, можно сказать, разнообразие первичных ключей.
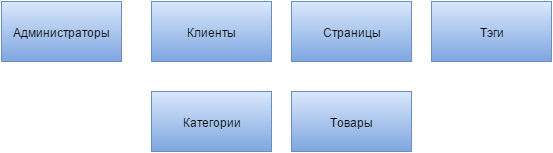
Самым естественным и распространенным решением будет делать все «как сказали», то есть для каждой «сущности» свой первичный ключ и набор не ключевых атрибутов, которые при нормализации могут быть выделены в отдельные таблицы (см. Рис.выше). Но при таком решении поднимается несколько вопросов и проблем. И если на вопросы типа «Почему бы администраторов и клиентов не объединить в юзеров с разным уровнем доступа?» можно просто забить. То с проблемами придется разбираться. В плане администраторов нужно решить, как определять их роли и права доступа. Как вариант это создание еще одной «сущности» или даже двух отдельных для прав и для ролей. К тому же появляется важный атрибут определения роли, который и будет решаться этими «сущностями», либо, если они не созданы на уровне БД и определяются в php (кто пишет сайты и приложения на другом языке представьте, что я его тут упомянул, а не php), тогда этот атрибут должен создаваться отдельным полем.
Есть другой вариант решения, который заключается как раз в повышении уровня обобщения базы данных. Можно объединить всех пользователей в один ключевой атрибут, таким образом, получится, что и все администраторы, и все клиенты это пользователи. Но нам нужно их как то отличать, для этого придется вводить не ключевой атрибут ролей, который, в общем-то, у нас был и при первом способе, но не распространялся на клиентов. Таким же образом мы можем объединить страницы сайта, категории, товары и тэги в объект «ресурсы». И тут нам тоже понадобится дополнительный не ключевой атрибут, позволяющий определить какую «сущность» представляет собой тот или иной ресурс. И опять это все можно привести к нормальному виду.
Из таких рассуждений рождается желание понять, как же высоко может подняться уровень обобщения данных. Вполне можно предположить, что пользователи это всего на всего один из видов ресурсов. Если вспомнить опыт modx, который и привел меня к таким размышлениям, то в базу кроме описанных выше «сущностей» нужно добавить роли пользователей, права доступа, шаблоны и некоторые другие, так сказать, сопутствующие данные, типа настроек системы. И даже их можно все объединить в общий уровень обобщения – «объекты». В него отлично вписываются и «ресурсы». Теперь нам просто нужно у каждого элемента уровня объекта иметь атрибут, определяющий к какой «сущности» он относится.
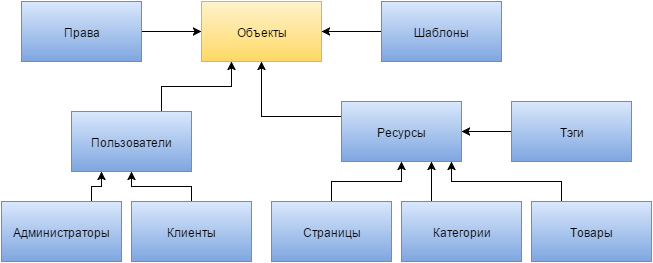
Вот что же мы можем видеть при продвижении вверх по уровням обобщения. Во-первых, для реализации нужен, как теперь оказывается, тоже ключевой атрибут, определяющий положение «сущности» при более низких уровнях – «атрибут обобщения». Он должен отражать значение при самом низком уровне, который мог бы быть. К примеру, у одного из администраторов сайта он может иметь значение «контент менеджер», у других это будет «программист» и тд. Во-вторых, поднимаясь вверх мы в конце приходим к выводу, что все данные в базе делятся на объекты и атрибуты. По сути объекты это такие же поля таблиц, но ключевые и отражающие значение атрибута обобщения.
В-третьих, все уровни обобщения, кроме возможно самого верхнего, позволяют приводить базу к нормальному виду, хотя и могут казаться просто безумнейшим решением. Более того они таковыми и могут оказаться. Давайте представим, что у нас по тысяче страниц, тэгов и клиентов, администраторов и настроек пусть всех в сумме тоже тысяча. У нас получается что при уровне объекта все они будут храниться в одной таблице, даже если мы сделали нормализацию и вынесли атрибуты в другие таблицы. А если объектов в десятки раз больше?
Мы определились, конечно, от части, с повышением уровня. И хотя это имеет свои плюсы, как то высокий уровень абстракции, даже заоблачный, но минусов все же больше. На мой взгляд их слишком много, особенно если вы делаете highload. Предлагаю посмотреть как низко мы можем опустить уровень обобщения и какие плюсы и минусы это может нести в сравнении с «обычным» уровнем. На самом деле, определить на сколько низкий уровень обобщения возможен получится только с конкретной задачей и результат будет определенно только для нее.
Давайте посмотрим что мы можем сделать с нашим примером. Клиентов, конечно же, мы не будем приписывать к пользователям. Далее раздробим администраторов на нужные нам роли, тем самым избавившись от них, и оставив только права, как атрибуты для каждого из них. Думаю это будет как то так: контент менеджеры, seo админы (скорее всего он будет один), программисты. Так же разделим ресурсы на отдельные части, чем избавимся от необходимости указывать какой «сущностью» является каждый из них. Как мы видим, атрибут обобщения теперь не нужен, получается, что сами данные выполняют его роль. А это позволяет избавится не только от атрибута, но и таблицы и возможно не одной, учитывая что количество атрибутов у ресурсов и пользователей может быть не мало.
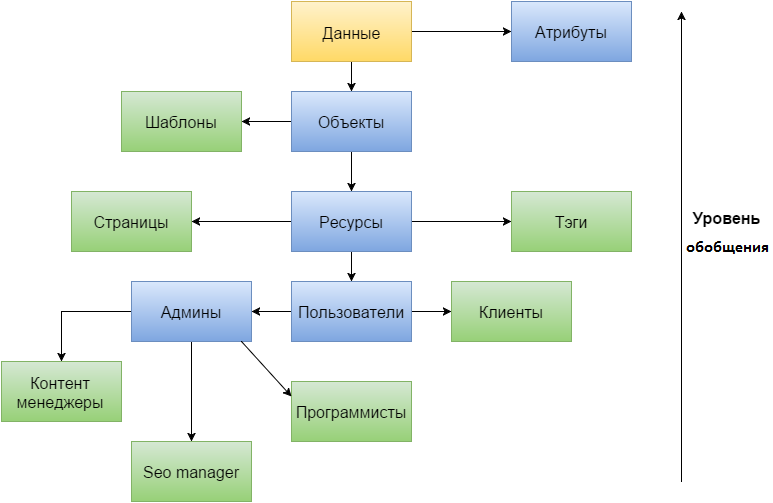
Разбивая всех и вся на части мы получаем большее количество таблиц. Теперь пользователи занимают не одну таблицу, кроме всяких там таблиц с дополнительными атрибутами, а четыре в нашем примере. Тоже происходит и с ресурсами, которые были одной таблицей. И с одной стороны количество таблиц увеличивается, но с другой стоит отметить, что мы тут не учитываем как изменится база после ее нормализации. А так же заметим еще два положительных эффекта, особенно приятных при разработке нагруженных приложений. Количество строк в каждой из таблиц становится меньше, да именно тут наблюдается прямая зависимость между уровнем обобщения и загруженностью таблиц. А вот при нормализации такой зависимости нет, более того может быть обратная. И еще один плюс, конечно если им правильно воспользоваться, конкретная цель использования каждой таблицы. Не возникает двусмысленности как при высоких уровнях обобщения базы данных. И хотя большее количество таблиц, на первый взгляд, усложняют проект, при правильном именовании таблиц, сопровождении моделей (если они используются) пояснениями в комментариях – это может служить большей прозрачности работы с базой данных.
С другой стороны, уровень абстракции реализации базы данных падает и это может послужить плохую службу. Так к примеру, если появляется новый тип администраторов, то при высоком уровне нам достаточно внести одно дополнительное значение в атрибут обобщения. Далее можно создавать новых пользователей с присваиванием им этого значения. С минимальной абстракцией обобщения такая красота не прокатит, придется создавать новую основную таблицу для этого типа администраторов, а так же различные дополнительные, либо делать связь с существующими. И встает вопрос «Что если добавится не новый тип пользователя, а новый уровень вниз?», например, программисты вдруг разделятся на бекэнд и фронтэнд.
Здесь представлены только теоретические рассуждения мои на тему «А что если...», почти ни каких практических применений не приводится. Самое добротное и полезное на эту тему, из того что я нашел, это статья Джона и Дианы Смит «Database Abstractions: Aggregation and General ization». Они профессионально описали, то что я тут пытался передать. Хочу попробовать нагрузочное тестирование разных уровней обобщения. Всем peace&love.
Введение
На самом деле я рассматриваю эту cms только как пример, того что присутствует во многих и опенсурс, и коммерческих системах. Просто мне как фрилансеру до недавних пор приходилось работать почти всегда с разработкой сайтов по дешевле и побыстрее – может у других фрилансеров много «жирных» клиентов, я не знаю, у меня не было. Так вот такая ситуация привела к не плохому опыту работы на модыксе. Но открытие собственной компании и дальнейшее подтягивание клиентов с индивидуальными запросами, потребовало вспоминать и улучшать свой лвл в настоящем программировании и построении баз данных. И вот тут я и почувствовал какой-то дискомфорт, что ли, ну как минимум смущение при воспоминании структуры как MODx, так и некоторых других открытых систем. Далее поясняю подробнее, что именно показалось странным, но интересным.
Дело в том, что в MODx Revo основным понятием для построения структуры сайта являются ресурсы. Вот именно, там нет такого как, например, в том же Вордпрессе отдельно страницы сайта, отдельно записи блога. Все страницы и записи, и даже много чего еще реализуется через модель ресурсов сайта. На самом деле это удобно, особенно учитывая тот факт, что это cmf/cms, то есть система рассчитана на разработку совершенно разных сайтов и тематически и технически. Таким образом, за всей структурой сайта удобно следить в одной панели управления ресурсами. В общем, система ресурсов позволяет создавать и управлять следующими сущностями сайта (хотел было написать объектами, но в ООП это слово уже занято, так что пусть будет «сущности»):
• Обычные html-страницы;
• Разного рода категории и разделы блога или каталога;
• Товары и их категории;
• XML-документы, например, sitemap.xml для поисковых роботов;
• Текстовые документы, к примеру, robots.txt правильно сделать ресурсом, а не просто залить файлом;
• Json-страницы, которые лично я использую для того же аякс;
• Создать собственный формат текстового файла.
Постановка проблемы
Вот такое объединение множества различных «сущностей» сайта в объекте одной модели Resources и вызвало мой интерес. Разум философа зашевелился и начал выдавать множество предположений и вопросов.
Во-первых, я обратил внимание на пользователей, потому что они сделаны совершенно отдельно от ресурсов. Как бы на первый взгляд это логично, но с другой стороны, если начали такую пляску с объединением кучи всего, почему бы не сделать все до конца. Да-да, максимализм в деле. Тем более, что сделать пользователей как один из видов ресурсов не представляет большой проблемы. В случае с modx это по большей части реализуется с помощью плейсхолдеров, позволяющих расширить количество атрибутов ресурса, и «контекстов», дающих возможность выделять часть ресурсов по их назначению. Реализация же чего-то подобного на фреймворке (я имею ввиду php-фреймворки) или голой связке скриптов и реляционной базы данных совсем дело не сложное.
Во-вторых, совершенно отдельными моделями реализуются шаблоны и вся система представления и настройки сайта. Почему бы их тоже не объединить в одну модель, хотя бы чисто ради эксперимента. Чувствую летящие в меня помидоры.
От частного к общему
Обобщение – это абстракция, которая позволяет обобщенно представлять себе некоторый класс индивидуальных объектов как единый именованный объект.
Джон М. Смит, Диана К. Смит
По сути, это продолжение работы натурфилософов, только перенесенное в плоскость хранения данных: «Что есть единое» и стоит ли идти путем обобщения при проектировании базы данных? Под обобщением, или переходом от частного к общему, я подразумеваю как раз то слияние нескольких моделей на уровне MVC проекта и соответственно таблиц на уровне базы данных, которое и заметил в modx. Хотя в ситуации с БД все же объединяются не таблицы, а именно ключевые атрибуты (т.н. первичный ключ), что приводит к объединению и таблиц. Но это не означает, что подобную структуру нельзя приводить к нормальной форме.
Давайте разберем чисто гипотетический пример. При проектировании базы данных нам понадобилось хранить и предоставлять доступ к нескольким «сущностям» веб-приложения: администраторы сайта, с разными ролями и правами; клиенты; страницы сайта; тэги; товары; категории. Существует несколько способов построить базу данных. И я говорю не о нормализации БД, которую нужно делать, приводя по хорошему к третьему виду. Я имею ввиду количество или, можно сказать, разнообразие первичных ключей.
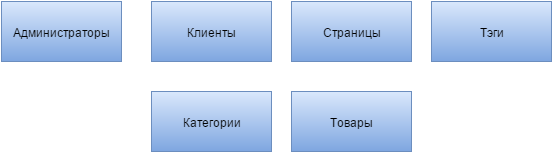
Самым естественным и распространенным решением будет делать все «как сказали», то есть для каждой «сущности» свой первичный ключ и набор не ключевых атрибутов, которые при нормализации могут быть выделены в отдельные таблицы (см. Рис.выше). Но при таком решении поднимается несколько вопросов и проблем. И если на вопросы типа «Почему бы администраторов и клиентов не объединить в юзеров с разным уровнем доступа?» можно просто забить. То с проблемами придется разбираться. В плане администраторов нужно решить, как определять их роли и права доступа. Как вариант это создание еще одной «сущности» или даже двух отдельных для прав и для ролей. К тому же появляется важный атрибут определения роли, который и будет решаться этими «сущностями», либо, если они не созданы на уровне БД и определяются в php (кто пишет сайты и приложения на другом языке представьте, что я его тут упомянул, а не php), тогда этот атрибут должен создаваться отдельным полем.
Есть другой вариант решения, который заключается как раз в повышении уровня обобщения базы данных. Можно объединить всех пользователей в один ключевой атрибут, таким образом, получится, что и все администраторы, и все клиенты это пользователи. Но нам нужно их как то отличать, для этого придется вводить не ключевой атрибут ролей, который, в общем-то, у нас был и при первом способе, но не распространялся на клиентов. Таким же образом мы можем объединить страницы сайта, категории, товары и тэги в объект «ресурсы». И тут нам тоже понадобится дополнительный не ключевой атрибут, позволяющий определить какую «сущность» представляет собой тот или иной ресурс. И опять это все можно привести к нормальному виду.
Из таких рассуждений рождается желание понять, как же высоко может подняться уровень обобщения данных. Вполне можно предположить, что пользователи это всего на всего один из видов ресурсов. Если вспомнить опыт modx, который и привел меня к таким размышлениям, то в базу кроме описанных выше «сущностей» нужно добавить роли пользователей, права доступа, шаблоны и некоторые другие, так сказать, сопутствующие данные, типа настроек системы. И даже их можно все объединить в общий уровень обобщения – «объекты». В него отлично вписываются и «ресурсы». Теперь нам просто нужно у каждого элемента уровня объекта иметь атрибут, определяющий к какой «сущности» он относится.
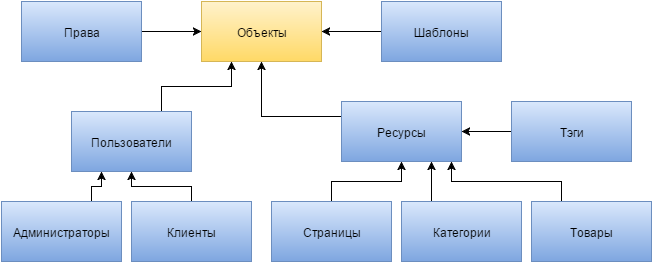
Вот что же мы можем видеть при продвижении вверх по уровням обобщения. Во-первых, для реализации нужен, как теперь оказывается, тоже ключевой атрибут, определяющий положение «сущности» при более низких уровнях – «атрибут обобщения». Он должен отражать значение при самом низком уровне, который мог бы быть. К примеру, у одного из администраторов сайта он может иметь значение «контент менеджер», у других это будет «программист» и тд. Во-вторых, поднимаясь вверх мы в конце приходим к выводу, что все данные в базе делятся на объекты и атрибуты. По сути объекты это такие же поля таблиц, но ключевые и отражающие значение атрибута обобщения.
В-третьих, все уровни обобщения, кроме возможно самого верхнего, позволяют приводить базу к нормальному виду, хотя и могут казаться просто безумнейшим решением. Более того они таковыми и могут оказаться. Давайте представим, что у нас по тысяче страниц, тэгов и клиентов, администраторов и настроек пусть всех в сумме тоже тысяча. У нас получается что при уровне объекта все они будут храниться в одной таблице, даже если мы сделали нормализацию и вынесли атрибуты в другие таблицы. А если объектов в десятки раз больше?
Минимальное обобщение
Мы определились, конечно, от части, с повышением уровня. И хотя это имеет свои плюсы, как то высокий уровень абстракции, даже заоблачный, но минусов все же больше. На мой взгляд их слишком много, особенно если вы делаете highload. Предлагаю посмотреть как низко мы можем опустить уровень обобщения и какие плюсы и минусы это может нести в сравнении с «обычным» уровнем. На самом деле, определить на сколько низкий уровень обобщения возможен получится только с конкретной задачей и результат будет определенно только для нее.
Давайте посмотрим что мы можем сделать с нашим примером. Клиентов, конечно же, мы не будем приписывать к пользователям. Далее раздробим администраторов на нужные нам роли, тем самым избавившись от них, и оставив только права, как атрибуты для каждого из них. Думаю это будет как то так: контент менеджеры, seo админы (скорее всего он будет один), программисты. Так же разделим ресурсы на отдельные части, чем избавимся от необходимости указывать какой «сущностью» является каждый из них. Как мы видим, атрибут обобщения теперь не нужен, получается, что сами данные выполняют его роль. А это позволяет избавится не только от атрибута, но и таблицы и возможно не одной, учитывая что количество атрибутов у ресурсов и пользователей может быть не мало.
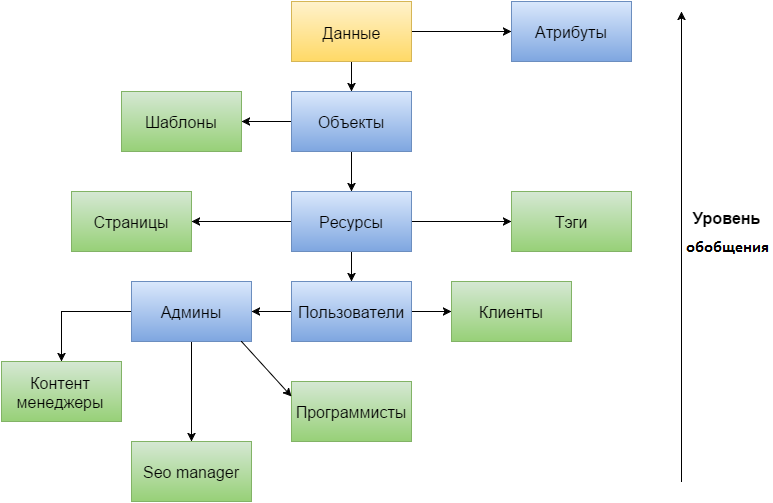
Разбивая всех и вся на части мы получаем большее количество таблиц. Теперь пользователи занимают не одну таблицу, кроме всяких там таблиц с дополнительными атрибутами, а четыре в нашем примере. Тоже происходит и с ресурсами, которые были одной таблицей. И с одной стороны количество таблиц увеличивается, но с другой стоит отметить, что мы тут не учитываем как изменится база после ее нормализации. А так же заметим еще два положительных эффекта, особенно приятных при разработке нагруженных приложений. Количество строк в каждой из таблиц становится меньше, да именно тут наблюдается прямая зависимость между уровнем обобщения и загруженностью таблиц. А вот при нормализации такой зависимости нет, более того может быть обратная. И еще один плюс, конечно если им правильно воспользоваться, конкретная цель использования каждой таблицы. Не возникает двусмысленности как при высоких уровнях обобщения базы данных. И хотя большее количество таблиц, на первый взгляд, усложняют проект, при правильном именовании таблиц, сопровождении моделей (если они используются) пояснениями в комментариях – это может служить большей прозрачности работы с базой данных.
С другой стороны, уровень абстракции реализации базы данных падает и это может послужить плохую службу. Так к примеру, если появляется новый тип администраторов, то при высоком уровне нам достаточно внести одно дополнительное значение в атрибут обобщения. Далее можно создавать новых пользователей с присваиванием им этого значения. С минимальной абстракцией обобщения такая красота не прокатит, придется создавать новую основную таблицу для этого типа администраторов, а так же различные дополнительные, либо делать связь с существующими. И встает вопрос «Что если добавится не новый тип пользователя, а новый уровень вниз?», например, программисты вдруг разделятся на бекэнд и фронтэнд.
Заключение
Здесь представлены только теоретические рассуждения мои на тему «А что если...», почти ни каких практических применений не приводится. Самое добротное и полезное на эту тему, из того что я нашел, это статья Джона и Дианы Смит «Database Abstractions: Aggregation and General ization». Они профессионально описали, то что я тут пытался передать. Хочу попробовать нагрузочное тестирование разных уровней обобщения. Всем peace&love.
