Задача поиска непрерывных последовательностей событий довольно легко решается с помощью SQL. Давайте уточним, что из себя представляют эти последовательности.
Для примера возьмём Stack Overflow. Он использует клёвую систему репутации с наградами за определенные достижения. Как и во многих социальных проектах, они поощряют пользователей ежедневно посещать ресурс. Обратим внимание на эти две награды:

Нетрудно понять, что они означают. Зайдите на сайт в первый день. Затем на второй день. Затем на третий (возможно несколько раз, это не имеет значения). Не зашли на четвёртый? Начинаем считать заново.
Для доступа к данным мы будем использовать Stack Exchange Data Explorer.
Обратите внимание, что мы не будем запрашивать даты посещений, так как эта информация не предоставляется. Вместо этого, давайте запросим даты размещённых пользователем сообщений.
В качестве базы данных используется SQL Server, следовательно мы можем использовать следующий запрос:
…который выдаст что-то подобное:
(можете сделать запрос самостоятельно, здесь)
Как можно заметить, есть несколько пропусков:
Человеку легко увидеть, сколько дней подряд идут даты без пропусков. Но как сделать это посредством SQL?
Чтобы упростить задачу, давайте «сохраним» индивидуальные запросы в обобщённых табличных выражениях. Предыдущий запрос мы назовём dates:
Теперь цель полученного запроса — поместить все последовательные даты в одну и ту же группу, чтобы мы могли объединить их. Вот как мы это сделаем:
Мы хотим объединить каждую группу «grp» и подсчитать количество дат в группе, а также найти минимум и максимум в каждой группе.
Давайте теперь посмотрим на результат запроса, и, чтобы было понятнее, мы пронумеруем строки независимо от пропусков в датах:
Как можно видеть, независимо от того, что существует разрыв между датами (две даты не являются последовательными), их номера строк по-прежнему будут последовательными. Мы можем сделать это с помощью функции ROW_NUMBER():
Теперь давайте посмотрим вот такой интересный запрос:
Приведённый выше запрос даёт нам следующий результат:
(можете сделать запрос самостоятельно, здесь)
Все, что мы сделали, это вычли номер строки из дня, чтобы получить новую дату «grp». Полученная таким образом дата не имеет смысла, это просто вспомогательное значение.
Однако, мы можем гарантировать, что для последовательных дат, значение «grp» будет одинаковое, потому что для всех последовательно идущих дат, следующие два уравнения верны:
Для непоследовательных дат, разница в номерах строк будет также 1, но разница в днях будет больше единицы. Группы теперь можно легко различить:
Таким образом, финальный запрос будет следующим:
И его результат:
(можете сделать запрос самостоятельно, здесь)
То, что мы использовали дни — это просто наш выбор. Мы взяли точное время и округлили его до дня с помощью функции CAST:
Если бы мы хотели узнать последовательность, например, из недель, мы могли бы округлять время до недель:
Этот запрос использует численное выражение года и недели и создаёт числа типа 201503 для третьей недели 2015 года. Остальная часть запроса остаётся без изменений:
И вот что мы получим:
(можете сделать запрос самостоятельно, здесь)
Неудивительно, что последовательные недели охватывают гораздо более длинные диапазоны, так как автор регулярно пишет на Stack Overflow.
Для примера возьмём Stack Overflow. Он использует клёвую систему репутации с наградами за определенные достижения. Как и во многих социальных проектах, они поощряют пользователей ежедневно посещать ресурс. Обратим внимание на эти две награды:
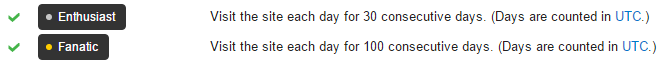
Нетрудно понять, что они означают. Зайдите на сайт в первый день. Затем на второй день. Затем на третий (возможно несколько раз, это не имеет значения). Не зашли на четвёртый? Начинаем считать заново.
Как отследить это с помощью SQL?
Для доступа к данным мы будем использовать Stack Exchange Data Explorer.
Обратите внимание, что мы не будем запрашивать даты посещений, так как эта информация не предоставляется. Вместо этого, давайте запросим даты размещённых пользователем сообщений.
В качестве базы данных используется SQL Server, следовательно мы можем использовать следующий запрос:
SELECT DISTINCT CAST(CreationDate AS DATE) AS date
FROM Posts
WHERE OwnerUserId = ##UserId##
ORDER BY 1
…который выдаст что-то подобное:
date
----------
2010-11-26
2010-11-27
2010-11-29
2010-11-30
2010-12-01
2010-12-02
2010-12-03
2010-12-05
2010-12-06
2010-12-07
2010-12-08
2010-12-09
2010-12-13
2010-12-14
...
(769 rows)
(можете сделать запрос самостоятельно, здесь)
Как можно заметить, есть несколько пропусков:
date
--------------------------------------
2010-11-26
2010-11-27 <---- Пропуск после 2 дней
2010-11-29
2010-11-30
2010-12-01
2010-12-02
2010-12-03 <---- Пропуск после 5 дней
2010-12-05
2010-12-06
2010-12-07
2010-12-08
2010-12-09 <---- Пропуск после 5 дней
2010-12-13
2010-12-14
...
Человеку легко увидеть, сколько дней подряд идут даты без пропусков. Но как сделать это посредством SQL?
Чтобы упростить задачу, давайте «сохраним» индивидуальные запросы в обобщённых табличных выражениях. Предыдущий запрос мы назовём dates:
WITH
-- This table contains all the distinct date
-- instances in the data set
dates(date) AS (
SELECT DISTINCT CAST(CreationDate AS DATE)
FROM Posts
WHERE OwnerUserId = ##UserId##
)
...
Теперь цель полученного запроса — поместить все последовательные даты в одну и ту же группу, чтобы мы могли объединить их. Вот как мы это сделаем:
SELECT
COUNT(*) AS consecutiveDates,
MIN(week) AS minDate,
MAX(week) AS maxDate
FROM groups
GROUP BY grp -- This "grp" value will be explained later
ORDER BY 1 DESC, 2 DESC
Мы хотим объединить каждую группу «grp» и подсчитать количество дат в группе, а также найти минимум и максимум в каждой группе.
Создание групп для последовательных дат
Давайте теперь посмотрим на результат запроса, и, чтобы было понятнее, мы пронумеруем строки независимо от пропусков в датах:
row number date
--------------------------------
1 2010-11-26
2 2010-11-27
3 2010-11-29 <-- пропуск перед этой строкой
4 2010-11-30
5 2010-12-01
6 2010-12-02
7 2010-12-03
8 2010-12-05 <-- пропуск перед этой строкой
Как можно видеть, независимо от того, что существует разрыв между датами (две даты не являются последовательными), их номера строк по-прежнему будут последовательными. Мы можем сделать это с помощью функции ROW_NUMBER():
SELECT
ROW_NUMBER() OVER (ORDER BY date) AS [row number],
date
FROM dates
Теперь давайте посмотрим вот такой интересный запрос:
WITH
-- This table contains all the distinct date
-- instances in the data set
dates(date) AS (
SELECT DISTINCT CAST(CreationDate AS DATE)
FROM Posts
WHERE OwnerUserId = ##UserId##
),
-- Generate "groups" of dates by subtracting the
-- date's row number (no gaps) from the date itself
-- (with potential gaps). Whenever there is a gap,
-- there will be a new group
groups AS (
SELECT
ROW_NUMBER() OVER (ORDER BY date) AS rn,
dateadd(day, -ROW_NUMBER() OVER (ORDER BY date), date) AS grp,
date
FROM dates
)
SELECT *
FROM groups
ORDER BY rn
Приведённый выше запрос даёт нам следующий результат:
rn grp date
--- ---------- ----------
1 2010-11-25 2010-11-26
2 2010-11-25 2010-11-27
3 2010-11-26 2010-11-29
4 2010-11-26 2010-11-30
5 2010-11-26 2010-12-01
6 2010-11-26 2010-12-02
7 2010-11-26 2010-12-03
8 2010-11-27 2010-12-05
9 2010-11-27 2010-12-06
10 2010-11-27 2010-12-07
11 2010-11-27 2010-12-08
12 2010-11-27 2010-12-09
13 2010-11-30 2010-12-13
14 2010-11-30 2010-12-14
(можете сделать запрос самостоятельно, здесь)
Все, что мы сделали, это вычли номер строки из дня, чтобы получить новую дату «grp». Полученная таким образом дата не имеет смысла, это просто вспомогательное значение.
Однако, мы можем гарантировать, что для последовательных дат, значение «grp» будет одинаковое, потому что для всех последовательно идущих дат, следующие два уравнения верны:
date2 - date1 = 1 // разница в днях между двумя датами
rn2 - rn1 = 1 // Разница в цифрах строк
Для непоследовательных дат, разница в номерах строк будет также 1, но разница в днях будет больше единицы. Группы теперь можно легко различить:
rn grp date
--- ---------- ----------
1 2010-11-25 2010-11-26
2 2010-11-25 2010-11-27
3 2010-11-26 2010-11-29
4 2010-11-26 2010-11-30
5 2010-11-26 2010-12-01
6 2010-11-26 2010-12-02
7 2010-11-26 2010-12-03
8 2010-11-27 2010-12-05
9 2010-11-27 2010-12-06
10 2010-11-27 2010-12-07
11 2010-11-27 2010-12-08
12 2010-11-27 2010-12-09
13 2010-11-30 2010-12-13
14 2010-11-30 2010-12-14
Таким образом, финальный запрос будет следующим:
WITH
-- This table contains all the distinct date
-- instances in the data set
dates(date) AS (
SELECT DISTINCT CAST(CreationDate AS DATE)
FROM Posts
WHERE OwnerUserId = ##UserId##
),
-- Generate "groups" of dates by subtracting the
-- date's row number (no gaps) from the date itself
-- (with potential gaps). Whenever there is a gap,
-- there will be a new group
groups AS (
SELECT
ROW_NUMBER() OVER (ORDER BY date) AS rn,
dateadd(day, -ROW_NUMBER() OVER (ORDER BY date), date) AS grp,
date
FROM dates
)
SELECT
COUNT(*) AS consecutiveDates,
MIN(week) AS minDate,
MAX(week) AS maxDate
FROM groups
GROUP BY grp
ORDER BY 1 DESC, 2 DESC
И его результат:
consecutiveDates minDate maxDate
---------------- ------------- -------------
14 2012-08-13 2012-08-26
14 2012-02-03 2012-02-16
10 2013-10-24 2013-11-02
10 2011-05-11 2011-05-20
9 2011-06-30 2011-07-08
7 2012-01-17 2012-01-23
7 2011-06-14 2011-06-20
6 2012-04-10 2012-04-15
6 2012-04-02 2012-04-07
6 2012-03-26 2012-03-31
6 2011-10-27 2011-11-01
6 2011-07-17 2011-07-22
6 2011-05-23 2011-05-28
...
(можете сделать запрос самостоятельно, здесь)
Бонус: найти последовательность недель
То, что мы использовали дни — это просто наш выбор. Мы взяли точное время и округлили его до дня с помощью функции CAST:
SELECT DISTINCT CAST(CreationDate AS DATE)
Если бы мы хотели узнать последовательность, например, из недель, мы могли бы округлять время до недель:
SELECT DISTINCT datepart(year, CreationDate) * 100
+ datepart(week, CreationDate)
Этот запрос использует численное выражение года и недели и создаёт числа типа 201503 для третьей недели 2015 года. Остальная часть запроса остаётся без изменений:
WITH
weeks(week) AS (
SELECT DISTINCT datepart(year, CreationDate) * 100
+ datepart(week, CreationDate)
FROM Posts
WHERE OwnerUserId = ##UserId##
),
groups AS (
SELECT
ROW_NUMBER() OVER (ORDER BY week) AS rn,
dateadd(day, -ROW_NUMBER() OVER (ORDER BY week), week) AS grp,
week
FROM weeks
)
SELECT
COUNT(*) AS consecutiveWeeks,
MIN(week) AS minWeek,
MAX(week) AS maxWeek
FROM groups
GROUP BY grp
ORDER BY 1 DESC, 2 DESC
И вот что мы получим:
consecutiveWeeks minWeek maxWeek
---------------- ------- -------
45 201401 201445
29 201225 201253
25 201114 201138
23 201201 201223
20 201333 201352
16 201529 201544
15 201305 201319
12 201514 201525
12 201142 201153
9 201502 201510
7 201447 201453
7 201321 201327
6 201048 201053
4 201106 201109
3 201329 201331
3 201102 201104
2 201301 201302
2 201111 201112
1 201512 201512
(можете сделать запрос самостоятельно, здесь)
Неудивительно, что последовательные недели охватывают гораздо более длинные диапазоны, так как автор регулярно пишет на Stack Overflow.
