Comments 28
Это правильное направление развития, но когда 5 лет назад я работал с FPGA на VHDL, у меня не было ощущения, что язык ограничивает мою производительность (но проекты, конечно, маленькие, так что не показатель). А вот что постоянно было занозой в заднице, так это крайне сложное тестирование и отладка, особенно в железе (не в симуляторе). Как обстоит дело с отладкой OpenCL кода?
Кстати, в то время OpenCL на GPU отлаживать тоже было грустно.
Кстати, в то время OpenCL на GPU отлаживать тоже было грустно.
Есть симуляторы типа oglgrind, которые большую часть ошибок отловят. Есть обычное юнит-тестирование. Пишем же не под железо, а под спецификацию.
Да, теперь предполагается, что вам не надо отлаживаться как обычному FPGA-разработчику используя Modelsim'e/SignalTap'e.
Насколько это реально, я не знаю — серьезных проектов на OpenCL под FPGA я не делал.
Буду признателен, если кто-то поделится реальным опытом применения Altera SDK for OpenCL в комментариях (или может в отдельной статье?), насколько всё радужно, как это рисуют маркетинговые буклетики)
Насколько это реально, я не знаю — серьезных проектов на OpenCL под FPGA я не делал.
Буду признателен, если кто-то поделится реальным опытом применения Altera SDK for OpenCL в комментариях (или может в отдельной статье?), насколько всё радужно, как это рисуют маркетинговые буклетики)
Ощущение, что всё же какое-то уж слишком топорное решение. Сам я сторонюсь FPGA, но вокруг достаточно много людей на них что-то делают. И первое, что мне всегда бросается в глаза — сложность делать многие, даже самые элементарные вещи. Например то же деление — очень много ест. Часто проблемы с памятью.
Как это решать, когда внешняя оболочка OpenCL даже не предусматривает таких заморочек?
Дальше. Стоимость. FPGA — не дешевое решение. Особенно те платы, где пойдёт OpenCL.
Но уже есть поколение встраиваемых компьютеров по 200 у.е. (Jetson TK1), на которых стоит видеокарта с очень неплохой мощность и на которой идёт CUDA. Я плохо разбираюсь в ценах на FPGA, но мне кажется, что в большинстве случаев они дороже даже для самых младших моделей?
Если критично высокоуровневое программирование, то ведь такое решение будет приятнее?
Хотя, конечно, нужно смотреть на скорости решения аналогичных задач и скорости их разработки.
Как это решать, когда внешняя оболочка OpenCL даже не предусматривает таких заморочек?
Дальше. Стоимость. FPGA — не дешевое решение. Особенно те платы, где пойдёт OpenCL.
Но уже есть поколение встраиваемых компьютеров по 200 у.е. (Jetson TK1), на которых стоит видеокарта с очень неплохой мощность и на которой идёт CUDA. Я плохо разбираюсь в ценах на FPGA, но мне кажется, что в большинстве случаев они дороже даже для самых младших моделей?
Если критично высокоуровневое программирование, то ведь такое решение будет приятнее?
Хотя, конечно, нужно смотреть на скорости решения аналогичных задач и скорости их разработки.
«Сложность делать» вылезает из-за управления низким уровнем) Это как на 8-битном контроллере писать перемножение float чисел на ассемблере. Да, сложно, но можно попытаться в интернете готовые примеры найти и пр.
Не очень понял вопроса: почему внешняя оболочка не предусматривает?
Да, чипы FPGA дороже своих конкурентов, и если основное различие будет только в энергоэффективности, то, мне кажется, съэкономленные деньги на электроэнергию не отобьют разницу в чипах. Может быть только в тех странах, где дорогая электроэнергия?
Как это решать, когда внешняя оболочка OpenCL даже не предусматривает таких заморочек?
Не очень понял вопроса: почему внешняя оболочка не предусматривает?
Да, чипы FPGA дороже своих конкурентов, и если основное различие будет только в энергоэффективности, то, мне кажется, съэкономленные деньги на электроэнергию не отобьют разницу в чипах. Может быть только в тех странах, где дорогая электроэнергия?
А вообще, не надо забывать, что Интел купил Альтеру, и собирается выпустить серверные процессоры Xeon со встроенной FPGA. Если они это сделают, и цена будет на 100$ больше, чем на процессор без FPGA, а количество ресурсов будет большим, то такой вариант станет очень привлекательным.
Кто знает, может они их чтобы похоронить купили: Stratix 10 сделать не смогли, в то время как Xilinx уже Ultrascale+ сэмплит.
Ну, Stratix 10 выйдет после Arria 10, а Arria еще находится на стадии инженерных образцов. Посмотрим, что будет
Ultrascale+ Kintex? Уже коммерческие образцы? Какая цена? :)
Ultrascale+ Kintex? Уже коммерческие образцы? Какая цена? :)
На Ultrascale+ нет ещё цен, объявили только что отправили избранным кастомерам. www.prnewswire.com/news-releases/xilinx-ships-industrys-first-16nm-all-programmable-mpsoc-ahead-of-schedule-300151415.html. Ultrascale (20nm TSMC) коллеги уже во всю используют.
Arria 10 выпускается на TSMC 20nm, в то время как Stratix 10 должен быть на Intel 14nm. При этом 14nm чипы Intel выпускает с осени прошлого года (Core M). Видимо у них какие-то серьезные задержки с продуктом, т.к. FPGA обычно одними из первых выходят на новых техпроцессах. Можно было бы подумать что им не хватает каких-то важных элементов вроде трансиверов, но судя по www.altera.com/products/fpga/stratix-series/stratix-10/features.tablet.html#heterogeneous3dintegration всё сложное I/O они выселили на отдельные чипы. Т.е. на Intel'овском чипе остаются только логика и SRAM'ы (с чем проблем быть не должно). Может быть не расчитали сил с новой архитектурой (HyperFlex).
Так что получается они уже целый год потеряли в пользу Xilinx. Отсюда и опосения за судьбу Altera.
Arria 10 выпускается на TSMC 20nm, в то время как Stratix 10 должен быть на Intel 14nm. При этом 14nm чипы Intel выпускает с осени прошлого года (Core M). Видимо у них какие-то серьезные задержки с продуктом, т.к. FPGA обычно одними из первых выходят на новых техпроцессах. Можно было бы подумать что им не хватает каких-то важных элементов вроде трансиверов, но судя по www.altera.com/products/fpga/stratix-series/stratix-10/features.tablet.html#heterogeneous3dintegration всё сложное I/O они выселили на отдельные чипы. Т.е. на Intel'овском чипе остаются только логика и SRAM'ы (с чем проблем быть не должно). Может быть не расчитали сил с новой архитектурой (HyperFlex).
Так что получается они уже целый год потеряли в пользу Xilinx. Отсюда и опосения за судьбу Altera.
Я вот так так и не понял а могу я в FPGA совместить ту часть HDL которая сгенерирована под OpenCL и какойто свой дизайн?
В статье я дал ссылку на гитхаб, где лежит квартусовский проект с Verilog IP.
Сгенерированые файлы открыты и вы можете как-то совместить с другим кодом или даже модифицировать.
Но придется поработать ручками, т.к. из коробки это пока не предполагается (механизма я не нашел).
Сгенерированые файлы открыты и вы можете как-то совместить с другим кодом или даже модифицировать.
Но придется поработать ручками, т.к. из коробки это пока не предполагается (механизма я не нашел).
Спасибо. Проеты ещё не смотрел, по друками никакого дев кита нет чтобы в живую пощупать.
Там вообще интересная ситуация получается: код получается открытым, и его можно портировать на другие чипы (хоть Xilinx), правда придется настройку кернелов и пр. писать самому.
Хотя, наверно, никому это не надо: у Xilinx есть своя тулза (SDAccel) для OpenCL.
Хотя, наверно, никому это не надо: у Xilinx есть своя тулза (SDAccel) для OpenCL.
Не очень понятная статья получилась, т.к. по сути никаких бенчмарков FPGA vs GPU на разных приложениях не приведено, хорошо хотя бы SPEC Accel погонять.
Непонятно какую архитектуру использует получившийся акселератор. Если это простой параллельный массив FSMD, тогда известно что на сложных kernel'aх он будет проигрывать как GPUшным шейдерам, так и всяким программируемым ASIP ядрам, т.к. весь timing будет сжираться на мультиплексорах.
Непонятно какую архитектуру использует получившийся акселератор. Если это простой параллельный массив FSMD, тогда известно что на сложных kernel'aх он будет проигрывать как GPUшным шейдерам, так и всяким программируемым ASIP ядрам, т.к. весь timing будет сжираться на мультиплексорах.
Я и сам бы хотел увидеть такие бенчмарки :)
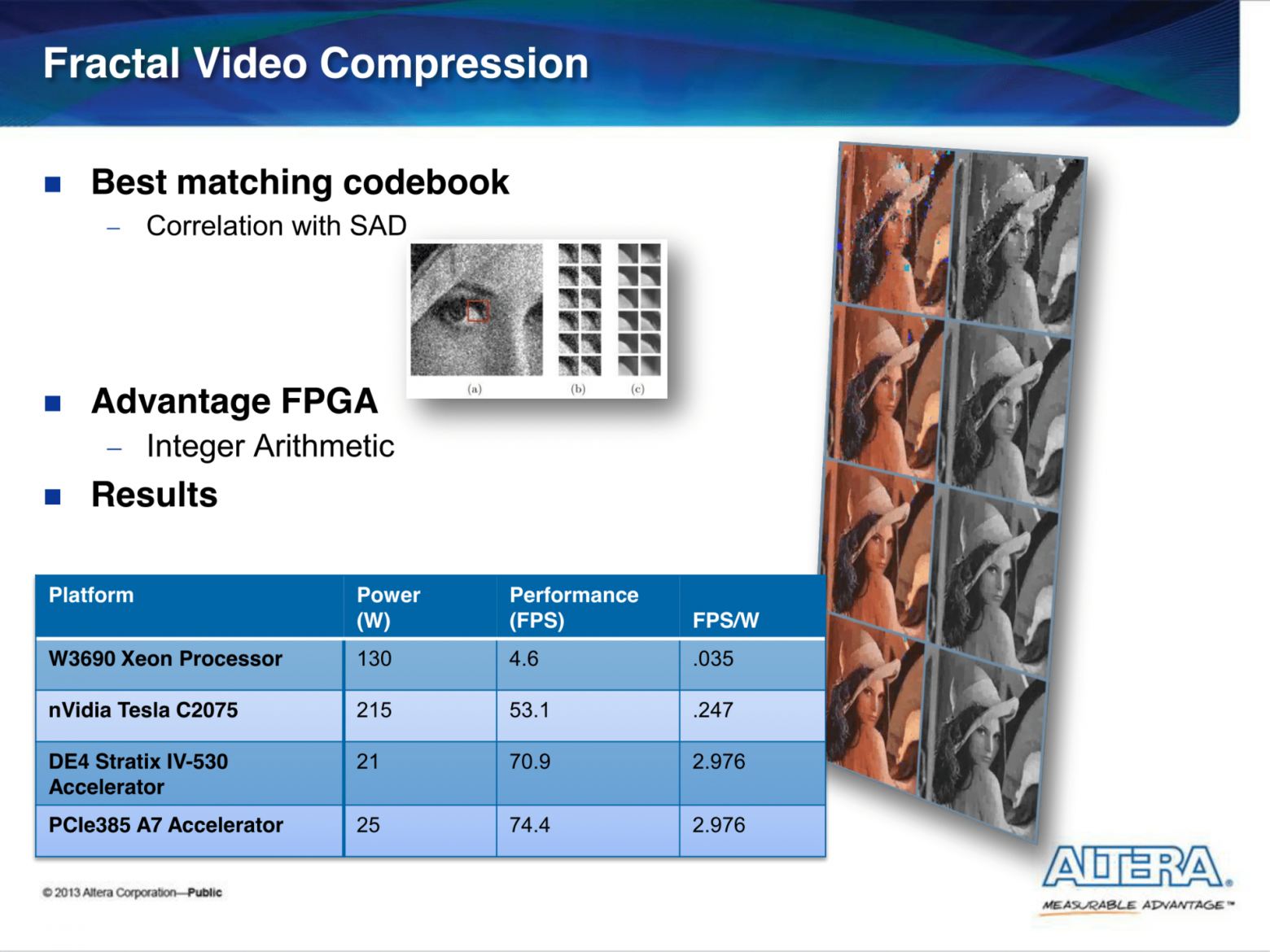
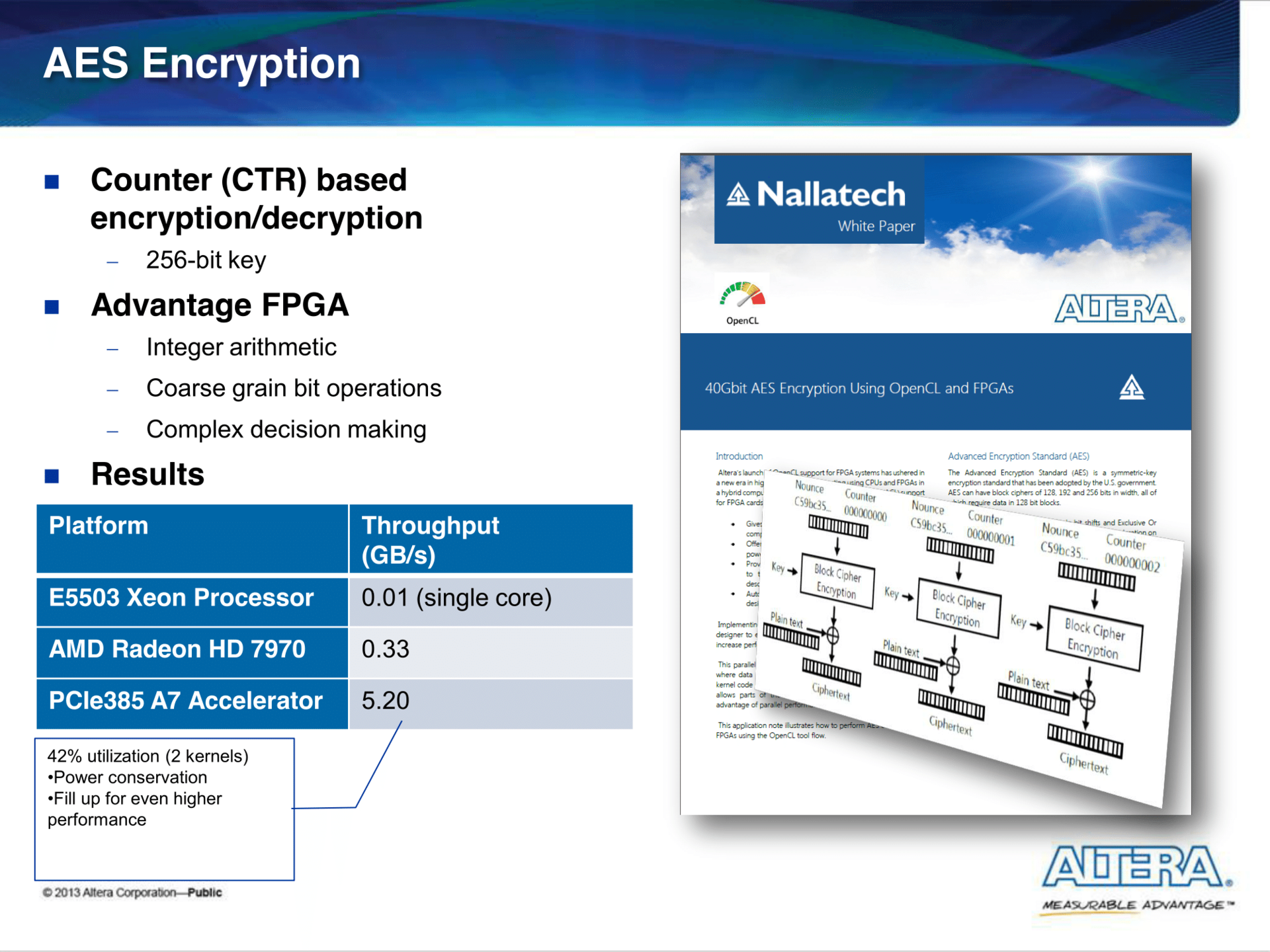
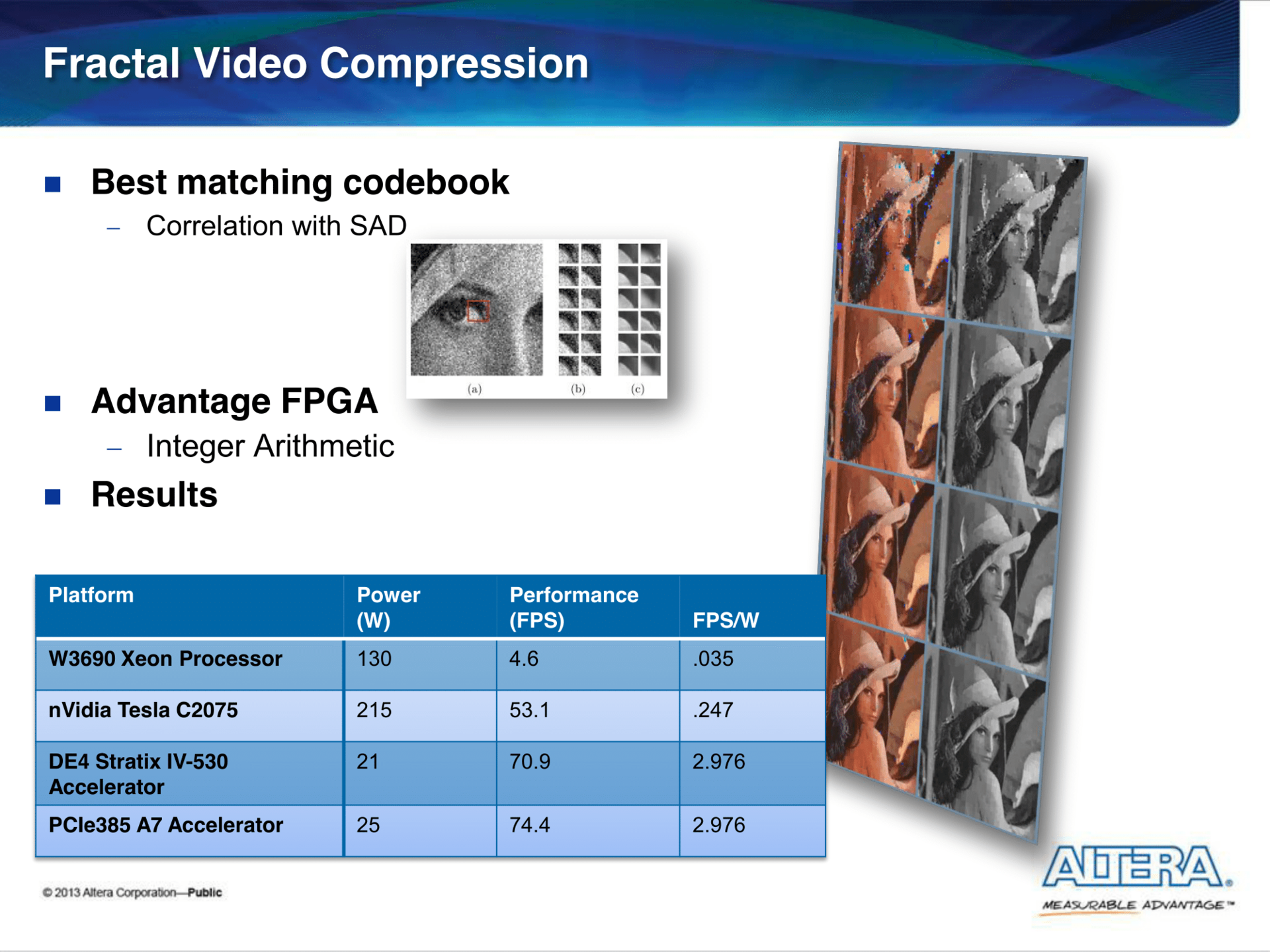
В презентации Harnessing the Power of FPGAs using Altera’s OpenCL Compiler приведены несколько бенчмарков (сравнение с Xeon'ом и Tesl'ой) на реальных задачах.
Слайды из презентации под спойлером:
В презентации Harnessing the Power of FPGAs using Altera’s OpenCL Compiler приведены несколько бенчмарков (сравнение с Xeon'ом и Tesl'ой) на реальных задачах.
Слайды из презентации под спойлером:
Скрытый текст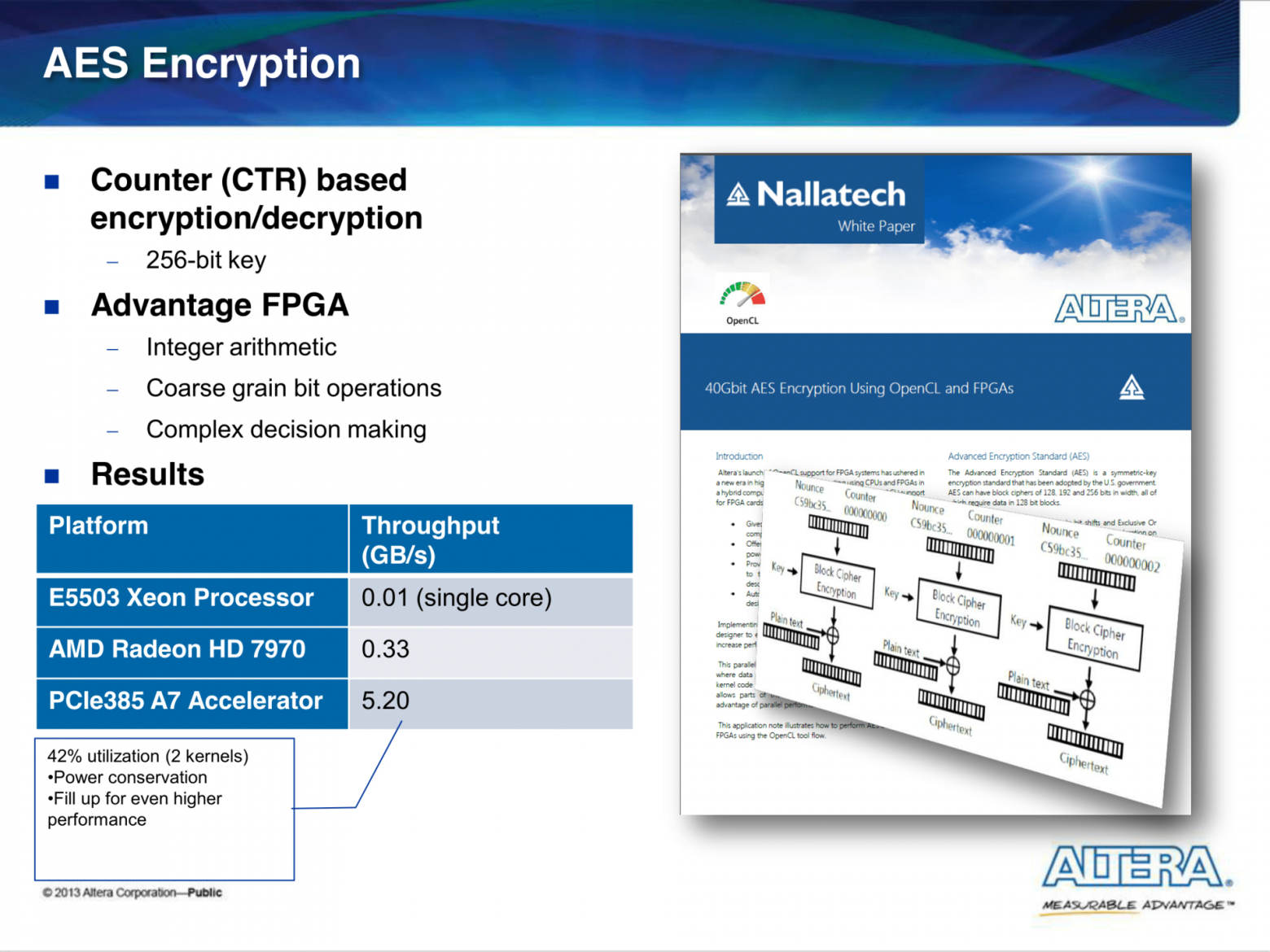




В общем понятно что какие-то kernel'ы будут лучше ложиться на GPU, какие-то на FPGA. Остается фундаментальная проблема с продуктивностью разработки под FPGA:
Думаю из-за этих сложностей FPGA долго будут оставаться достаточно нишевыми продуктами. Хотя PC-платформу от Intel/Altera с FPGA было бы приколько попробовать, с fpga-программами в userspace, без всякой удаленной отладки на плате :)
- цикл написал-просинтезил-попробовал исправил занимает кучу времени (очень раздражает по сравнению скажем с разработкой на Python, где даже компилировать не требуется)
- Отладка алгоритмического кода с помощью signal tap? Страшно даже думать об этом.
- Симулятор работает слишком медленно, какой-нибудь видео-поток в HD уже не прогнать. Плюс куча времени потребуется только чтобы написать тестовое окружение
Думаю из-за этих сложностей FPGA долго будут оставаться достаточно нишевыми продуктами. Хотя PC-платформу от Intel/Altera с FPGA было бы приколько попробовать, с fpga-программами в userspace, без всякой удаленной отладки на плате :)
Идеалогия предполагает, что программисты не будут брать в руки FPGA-шные инструменты (SignalTap и пр.):
см. полный workflow:
Полная сборка (на несколько часов) рекомендуется тогда, когда кернел на эмуляторе прошел тесты.
Правда, если будет расхождение в поведении между эмулятором на x86 и исполнением на FPGA, то это будет очень невесело дебажить :)
Про симуляцию с потоком HD-видео ничего сказать не могу — никогда с этим не работал, но на создание очень простого тестового окружения для симуляции (в ModelSim'e) кернела vector_add ушло полчаса.
- есть возможность собрать ядро, которое можно запустить под эмулятором (x86)
- оценить архитектуру и увидеть проблемные места по производительности получаемого решения можно БЕЗ компиляции квартусом
см. полный workflow:
Скрытый текст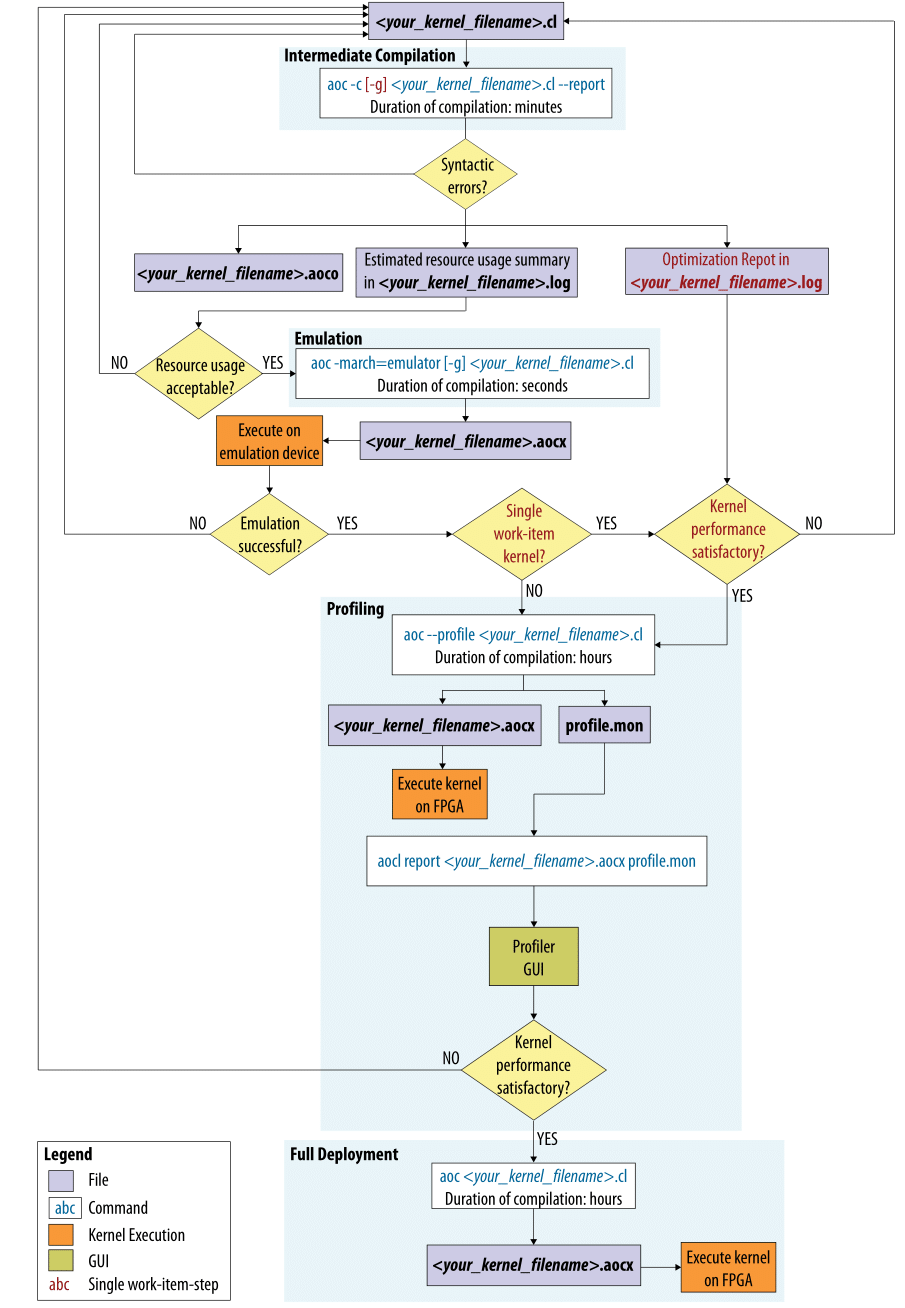
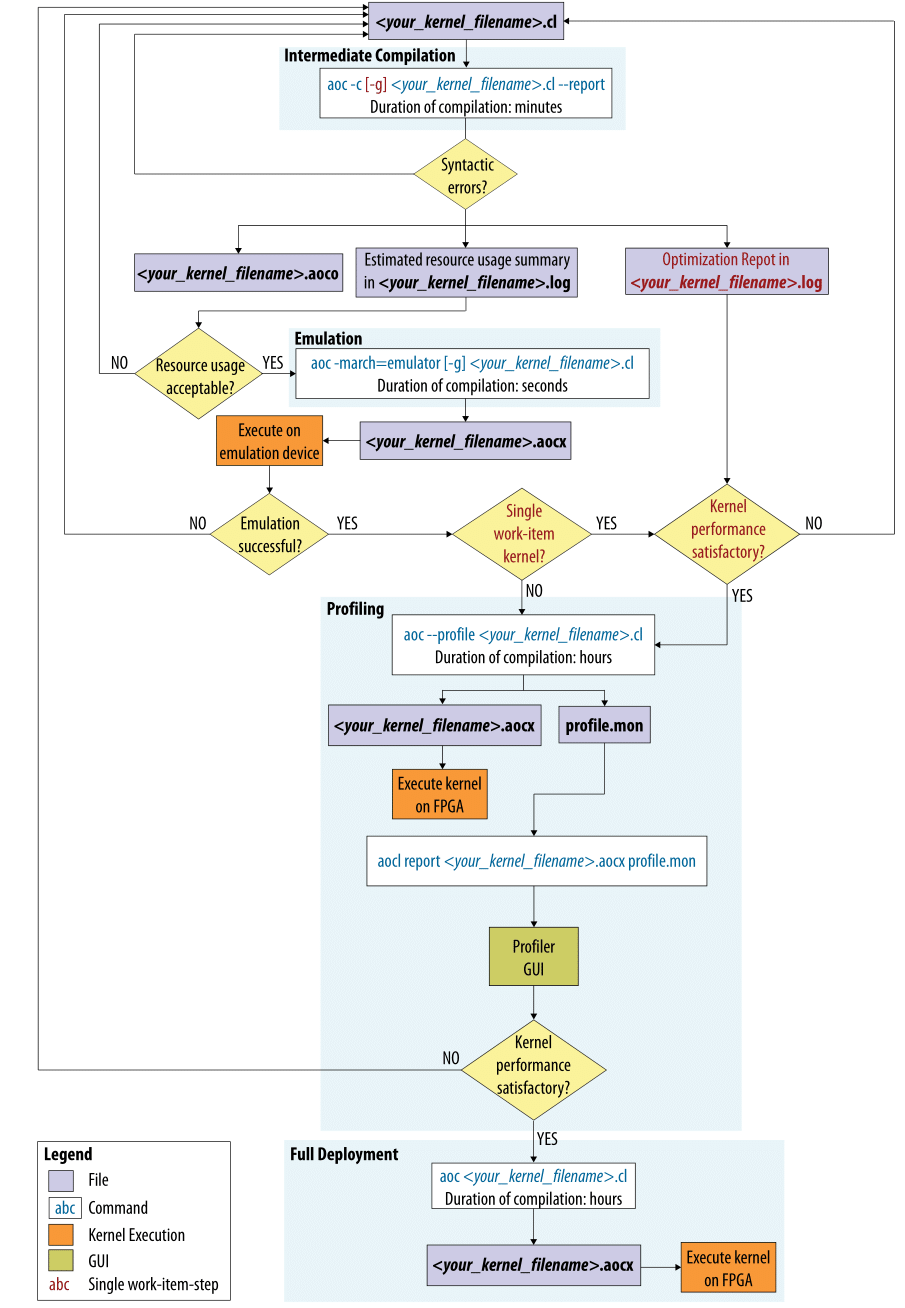
Полная сборка (на несколько часов) рекомендуется тогда, когда кернел на эмуляторе прошел тесты.
Правда, если будет расхождение в поведении между эмулятором на x86 и исполнением на FPGA, то это будет очень невесело дебажить :)
Про симуляцию с потоком HD-видео ничего сказать не могу — никогда с этим не работал, но на создание очень простого тестового окружения для симуляции (в ModelSim'e) кернела vector_add ушло полчаса.
Интересно, нужно будет самому попробовать.
Описал архитектуру ядра и как он работает тут.
www.altera.com/content/dam/altera-www/global/en_US/pdfs/literature/hb/opencl-sdk/aocl_getting_started.pdf
The development system has at least 85 gigabytes (GB) of free disk space for software installation.
The development system has at least 24 GB of RAM
Оно запускается в принципе на меньшем количестве ОЗУ? Например 16 Гб.
The development system has at least 85 gigabytes (GB) of free disk space for software installation.
The development system has at least 24 GB of RAM
Оно запускается в принципе на меньшем количестве ОЗУ? Например 16 Гб.
У меня дома 16 GB ОЗУ. Запустилось без проблем, но если будете компилировать под большие чипы (Stratix V, Arria 10) большие проекты, то оперативки может не хватить: на работе на сборочную машину мы докупали ОЗУ из-за этого.
Ок. Минимальный чип для запуска cyclone v? На stratix iv собрать получится?
Я чуть выше описал на каких платах гарантированно работает из коробки OpenCL, а так же что делать если плата не входит в этот список :)
В принципе, это обычный квартусовский проект (я ссылочку на гитхаб дал в статье), и под Stratix IV собрать можно, только придется поработать руками — изменить чип на нужный в проекте, возможно сделать виртуальные интерфейсы и т.п.
В принципе, это обычный квартусовский проект (я ссылочку на гитхаб дал в статье), и под Stratix IV собрать можно, только придется поработать руками — изменить чип на нужный в проекте, возможно сделать виртуальные интерфейсы и т.п.
Дает ли OpenCL компилятор информацию о том, сколько тактов будет работать kernel? Если нет, то интересно почему?
Sign up to leave a comment.
Altera + OpenCL: программируем под FPGA без знания VHDL/Verilog