Kernel is the root of all evil ⊙.☉
Сейчас вряд ли кого-то удивить использованием epoll()/kqueue() в поллерах событий. Для решения проблемы C10K cуществует довольно много разнообразных решений (libevent/libev/libuv), с разной производительностью и довольно высокими накладными расходами. В статье рассматривается использование DPDK для решения задачи обработки 10 миллионов соединений (С10M), и достижение максимального прироста производительности при обработке сетевых запросов в распространённых прикладных решениях. Главной особенностью подобной задачи является делегирование ответственности обработки трафика с ядра ОС в пользовательское пространство (userspace), точный контроль обработки прерываний и каналов DMA, использование VFIO, и много других не очень понятных слов. В качестве целевого прикладного окружения было выбрано Java Netty с использованием Disruptor паттерна и offheap кэширования.

Если кратко — это очень эффективный способ обработки трафика, по производительности близкий к существующим аппаратным решениям. Накладные расходы от использования средств предоставленных самим ядром ОС — слишком велики, и для подобных задач оно является источником большинства проблем. Сложность заключается в поддержке со стороны драйверов целевых сетевых интерфейсов, и архитектурных особенностях приложений в целом.
В статье очень детально рассмотрены вопросы установки, настройки, использования, отладки, профилирования и разворачивания DPDK для построения высокопроизводительных решений.
Почему DPDK ?
Существуют ещё Netmap, OpenOnload и pf_ring.
netmap
Основной задачей при разработке netmap являлась разработка простого в использовании решения, по этому предоставляется наиболее распространённый синхронный интерфейс select(), что позволяет значительно упростить портирование существующих решений. С точки зрения гибкости и абстрагирования железа netmap'у явно не хватает функционала. Тем не менее это наиболее доступное и распространённое решение (даже под
pf_ring
pf_ring появился как средство «разгона» pcap'a, и так уж исторически сложилось что на момент разработки не было готовых к использованию, стабильных решений. Явных преимуществ перед тем же netmap'ом у него не много, но есть поддержка IOMMU в проприетарной ZC версии. Сам по себе продукт издавна не отличался высокой производительностью или качеством, является не более чем средством сбора и анализа pcap дампов и не предназначался для обработки трафика в пользовательских приложениях. Главной особенностью pf_ring'a ZC является полная независимость от существующих драйверов сетевых интерфейсов.
OpenOnload
OpenOnload узкоспециализированный высокопроизводительный,
Другие
Есть ещё решения Napatech, но, на сколько мне известно, у них там просто библиотека со своим API, без вундервафель как у SolarFlare, по этому их решения менее распространены.
Естественно я рассмотрел не все существующие решения — я просто не мог со всем столкнуться, но я не думаю что они могут сильно отличаться от того что описано выше.
DPDK
Исторически так сложилось, что наиболее распространёнными адаптерами для работы c 10/40GbE являются адаптеры Intel обслуживаемые e1000 igb ixgbe i40e драйверами. По этому они являются частыми целевыми адаптерами для высокопроизводительных средств обработки трафика. Так было с Netmap и pf_ring, разработчики которых являются
DPDK это OpenSource проект Intel'a, на основе которого были построены целые конторы (6WIND) и для которого производители изредка предоставляют драйвера, например Mellanox. Естественно, коммерческая поддержка решений на его основе просто замечательная, её предоставляет довольно большое количество вендоров (6WIND, Aricent, ALTEN Calsoft Labs, Advantech, Brocade, Radisys,Tieto, Wind River, Lanner, Mobica)
DPDK имеет наиболее широкий функционал, и лучше всего абстрагирует существующее железо.
Он не создан удобным — он создан достаточно гибким для достижения высокой, возможно максимальной, производительности.
Список поддерживаемых драйверов и карт
- Chelsio cxgbe (Terminator 5)
- Cisco enic (вся серия Virtual Interface Card)
- Emulex oce (OneConnect OCe14000 family)
- Mellanox mlx4 (ConnectX-3, ConnectX-3 Pro)
- QLogic/Broadcom bnx2x (NetXtreme II)
Intel все существующие в ядре linux'a драйвера
- e1000 (82540, 82545, 82546)
- e1000e (82571..82574, 82583, ICH8..ICH10, PCH..PCH2)
- igb (82575..82576, 82580, I210, I211, I350, I354, DH89xx)
- ixgbe (82598..82599, X540, X550)
- i40e (X710, XL710)
- fm10k
Все они портированы в виде Poll Mode драйверов для выполнения в пользовательском пространстве (usermode).
Что-то ещё ?
Вообще-то да, ещё есть поддержка
- виртуализации на основе QEMU, Xen, VMware ESXi
- паравиртуализируемых сетевых интерфейсов на основе копирования буферов
хоть это и зло - AF_PACKET сокетов и PCAP дампов для тестирования
- сетевых адаптеров с кольцевыми буферами
Архитектура DPDK
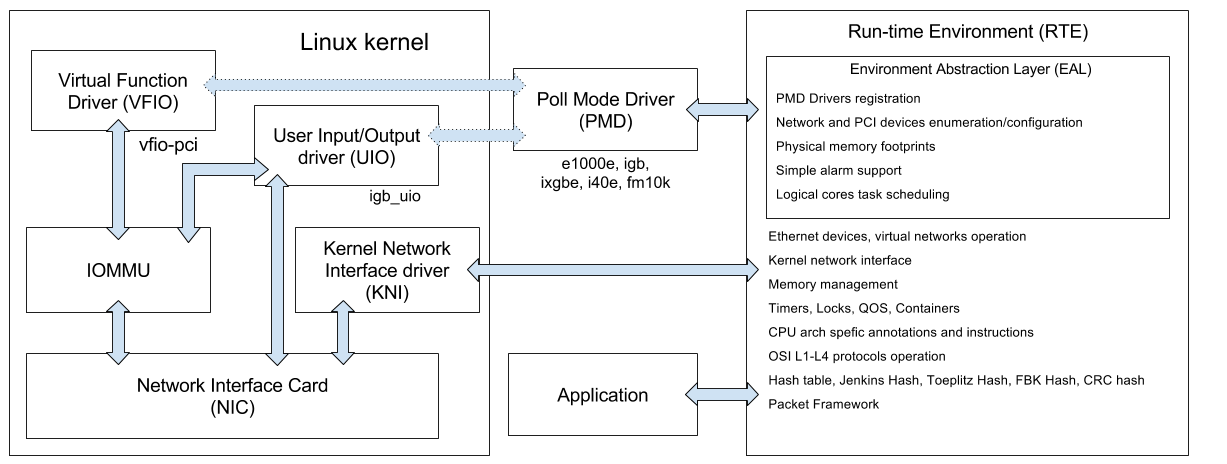
* это он у меня в голове так фунциклирует, реальность может чуть отличаться
Сам DPDK состоит из набора библиотек (содержимое папочки lib):
- librte_acl — списки контроля доступа
КЭПдля VLAN'ов - librte_compat — совместимость экспортируемых бинарных интерфейсов (ABI)
- librte_ether — управление ethernet адаптером, работа с ethernet фреймами
- librte_ivshmem — совместное использование (sharing) буферов с помощью ivshmem
- librte_kvargs — парсинг аргументов ключ-значение
- librte_mbuf — менеджмент буферов сообщений (message buffer — mbuf)
- librte_net — кусочек BSD'шного IP стека c ARP/IPv4/IPv6/TCP/UDP/SCTP
- librte_power — управление энергопотреблением и частотами (cpufreq)
- librte_sched — QOS иерархический планировщик
- librte_vhost — виртуальные сетевые адаптеры
- librte_cfgfile — парсинг конфигурационных файлов
- librte_distributor — средство распредления пакетов между существующими задачами
- librte_hash — хэш-функции
- librte_jobstats — измерение времени выполнения задач
- librte_lpm — Longest Prefix Match функции, используются для поиска по таблицам форвардинга
- librte_mempool — менеджер пулов объектов в памяти
- librte_pipeline — конвеер пакетного фреймворка
- librte_reorder — сортировка пакетов в буфере сообщений
- librte_table — реализация таблиц поиска (lookup table)
- librte_cmdline — парсинг аргументов командой строки
- librte_eal — платформо-зависимое окружение
- librte_ip_frag — фрагментация IP пакетов
- librte_kni — API для взаимодействием с KNI
- librte_malloc — нетрудно догадаться
- librte_meter — QOS метрика
- librte_port — реализация портов для сетевых пакетов
- librte_ring — кольцевые lock-free FIFO очереди
- librte_timer — таймеры и счётчики
UIO драйверов (lib/librte_eal/linuxapp) сетевых интерфейсов под linux:
- uio_igb — ethernet сетевой адаптер
- xen_dom0 — понятно из названия
и BSD
- nic_uio
И вышеупомянутых Poll Mode драйверов (PMD), которые выполняются в пользовательском пространстве (userspace): e1000, e1000e, igb, ixgbe, i40e, fm10k и других.
Kernel Network Interface (KNI) — это специализированный драйвер который позволяет взаимодействовать с сетевым API ядра, выполнять ioctl вызовы к портам интерфейсов которые работают с DPDK, использовать распространённые утилиты (ethtool, ifconfig, tcpdump) для управления ими.
Как видите, у DPDK, по сравнению с другими решениями
Требования и тонкая настройка целевой системы
Переведены и дополнены основные рекомендации официальной документации.
Не затронут вопрос настройки гипервизоров XEN и VMware для работы с DPDK.
Общие
Если вы ставите ваш DPDK под Intel Communications Chipset 89xx, то вам сюда.
Для сборки нужен coreutils, gcc, заголовки ядра, заголовки glibc.
Вроде поддерживается clang, и есть поддержка Intel'овского icc.
Для запуска вспомогательных скриптов — Python 2.6/2.7
Ядро Linux должно быть собрано с поддержкой UIO и мониторингом адресных пространств процессов, это параметры ядра:
CONFIG_UIO
CONFIG_UIO_PDRV
CONFIG_UIO_PDRV_GENIRQ
CONFIG_UIO_PCI_GENERIC
и
CONFIG_PROC_PAGE_MONITOR
Хочу обратить внимание на то что в grsecurity параметр PROC_PAGE_MONITOR считается слишком уж информативным — помогает в эксплуатировании уязвимостей ядра и в обходе ASLR.
HPET
Для организации периодических прерываний высокой точности нужен HPET таймер.
Можно глянуть наличие
grep hpet /proc/timer_list
Advanced -> PCH-IO Configuration -> High Precision TimerИ собрать ядро с включенным CONFIG_HPET и CONFIG_HPET_MMAP.
По умолчанию поддержка HPET выключена в самом DPDK, по этому нужно её включить выставив флаг CONFIG_RTE_LIBEAL_USE_HPET вручную в файле config/common_linuxapp.
В некоторых случаях целесообразно использовать HPET, в других — TSC.
Для реализации высокопроизводительного решения нужно использовать оба, так как у них разное предназначение и они компенсируют недостатки друг друга. Обычно, по умолчанию используется TSC. Инициализация и проверка доступности HPET таймера осуществляется вызовом rte_eal_hpet_init(int make_default) <rte_cycles.h>. Странно что в документации API его упускают.
Изоляция ядер
Для разгрузки системного планировщика довольно распространённой практикой является изоляция логических ядер процессора сугубо для нужд высокопроизводительных приложений. Особенно это актуально для двух-процессорных систем.
Если ваше приложение выполняется на чётных ядрах 2, 4, 6, 8, 10 — можете добавить параметр ядра в ваш любимый загрузчик
isolcpus=2,4,6,8,10Для широкораспространённого grub'a это параметр GRUB_CMDLINE_LINUX_DEFAULT в конфиге /etc/default/grub.
Hugepages
Большие страницы необходимы для выделения памяти под сетевые буферы. Выделение больших страниц позитивно влияет на производительность так как необходимо меньше вызовов для трансляции виртуальных адресов памяти в TLB. Правда выделяться они должны в процессе загрузки ядра во избежание фрагментации.
Для этого нужно добавить параметр ядра:
hugepages=1024Это выделит 1024 страницы по 2МБайт'a.
Для выделения четырёх страниц по гигабайту:
default_hugepagesz=1G hugepagesz=1G hugepages=4Но нужна соответствующая поддеркжа — флаг процессора pdpe1gb в /proc/cpuinfo.
grep pdpe1gb /proc/cpuinfo | uniq
Для 64-разрядных приложений использование 1ГБайт'ных страниц является предпочтительным.
Для получения информации о распределении страниц между ядрами в NUMA системе, можно использовать следующую команду
cat /sys/devices/system/node/node*/meminfo | fgrep Huge
Более подробно об управлением политикой выделения и освобождения больших страниц в NUMA системах можно почитать в официальной документации.
Для поддержки больших страниц нужно собрать ядро с параметром CONFIG_HUGETLBFS
Управления выделенными областями памяти для больших страниц осуществлеятся механизмом Transparent Hugepage, который выполняет дефрагментацию в отдельном потоке ядра khugepaged. Для его поддержки нужно собирать с параметром CONFIG_TRANSPARENT_HUGEPAGE и политик CONFIG_TRANSPARENT_HUGEPAGE_ALWAYS либо CONFIG_TRANSPARENT_HUGEPAGE_MADVISE.
Этот механизм остаётся актуальным даже в случае выделения больших страниц во время загрузки ОС, так как тем не менее остаётся вероятность отсутствия возможности выделения непрерывных областей памяти для страниц в 2МБайт'а, по различным причинам.
Есть блокбастер о NUMA и памяти от адептов Intel'a.
Есть небольшая статья о использовании больших страниц от Rad Hat.
После настройки и выделения страниц нужно примонтировать их, для этого нужно добавить в /etc/fstab соответствующую точку монтирования
nodev /mnt/huge hugetlbfs defaults 0 0
Для 1Гбайт'овых страниц размер страницы нужно указать дополнительным параметром
nodev /mnt/huge hugetlbfs pagesize=1GB 0 0
По моим личным наблюдениям больше всего проблем при настройке и эксплуатации DPDK возникает именно с большими страницами. Стоит уделить особенное внимание средствам администрирования больших страниц.
Кстати, в Power8 размер больших страниц составляет 16МБайт и 16ГБайт что, как по мне, немного перебор.
Менеджмент энергопотребления
В DPDK уже есть средства по управлению частотами процессора, так что бы стандартные политики «не совали палки в колёса».
Для их использования нужно включить SpeedStep и C3 С6.
У вас в BIOS путь к настройкам мог бы выглядеть вот так
Аdvanced->Processor Configuration->Enhanced Intel SpeedStep TechВ приложении l3fwd-power представлен пример L3 свитча с использованием функций управления энергопотреблением.
Advanced->Processor Configuration->Processor C3 Advanced->Processor Configuration-> Processor C6
Права доступа
Понятное дело что выполнять приложение с root'овыми правами доступа очень небезопасно.
Целесообразно использовать ACL для создания прав доступа отдельной пользовательской группы
setfacl -s u::rwx,g::rwx,o:---,g:dpdk:rw- /dev/hpet
setfacl -s u::rwx,g::rwx,o:---,g:dpdk:rwx /mnt/huge
setfacl -s u::rwx,g::rwx,o:---,g:dpdk:rw- /dev/uio0
setfacl -s u::rwx,g::rwx,o:---,g:dpdk:rw- /sys/class/uio/uio0/device/config
setfacl -s u::rwx,g::rwx,o:---,g:dpdk:rwx /sys/class/uio/uio0/device/resource*
Что добавит полный доступ для группы пользователей dpdk для используемых ресурсов и устройства uio0.
Прошивка
Для 40GbE cетевых адаптеров обработка мелких пакетов является довольно сложной задачей, и от прошивки до прошивки Intel внедряет дополнительные оптимизации. Поддержка прошивок серии FLV3E реализована в DPDK 2.2-rc2, но пока наиболее оптимальной является версия 4.2.6. Вы можете обратиться в поддержку вендоров или напрямую к Intel'у для обновления, либо обновить самостоятельно.
Расширенные метки, размер запроса и дескрипторов чтения в PCIe устройствах
Параметры PCIe шины extended_tag и max_read_request_size значительно влияют на скорость обработки мелких пакетов — порядка 100Байт 40GbE адаптерами. В некоторых версиях BIOS их можно установить вручную — 125 Байт и «1» соответственно, для 100 Байтных пакетов.
Значения можно выставить в конфиге config/common_linuxapp при сборке DPDK, с помощью следующих параметров:
CONFIG_RTE_PCI_CONFIGЛибо с помощью setpci lspci команд.
CONFIG_RTE_PCI_EXTENDED_TAG
CONFIG_RTE_PCI_MAX_READ_REQUEST_SIZE
Вот в чём разница между MAX_REQUEST и MAX_PAYLOAD параметрами для PCIe устройств, но в конфигах есть только MAX_REQUEST.
Для i40e драйвера имеет смысл уменьшить размер дескрипторов чтения до 16 Байт, выполнить это можно установкой следующего параметра: CONFIG_RTE_LIBRTE_I40E_16BYTE_RX_DESC в config/common_linuxapp или в config/common_bsdapp соответственно.
Также можно указать минимальный интервал между обработкой прерываний записи CONFIG_RTE_LIBRTE_I40E_ITR_INTERVAL в зависимости от существующих приоритетов: максимальной пропускной способности или попакетным задержкам.
Также подобные параметры есть для драйвера Mellanox mlx4.
CONFIG_RTE_LIBRTE_MLX4_SGE_WR_NКоторые наверняка как-то влияют на производительность.
CONFIG_RTE_LIBRTE_MLX4_MAX_INLINE
CONFIG_RTE_LIBRTE_MLX4_TX_MP_CACHE
CONFIG_RTE_LIBRTE_MLX4_SOFT_COUNTERS
Все остальные параметры сетевых адаптеров связаны с отладочными режимами, которые позволяют очень тонко профилировать и отлаживать целевое приложение, но об этом далее.
IOMMU для работы с Intel VT-d
Нужно собрать ядро с параметрами
CONFIG_IOMMU_SUPPORT
CONFIG_IOMMU_API
CONFIG_INTEL_IOMMU
Для igb_uio драйвера должен быть установлен параметр загрузки
iommu=ptЧто приводит к корректной трансляции адресов DMA (DMA remapping). Поддержка IOMMU для целевого сетевого адаптера в гипервизоре выключается. Сам по себе IOMMU довольно расточителен для высокопроизводительных сетевых интерфейсов. В DPDK реализован маппинг «один к одному», по этому полная поддержка IOMMU не требуется, хоть это и ещё одна брешь в безопасности.
Если при сборке ядра установлен флаг INTEL_IOMMU_DEFAULT_ON то должен использоваться параметр загрузки
intel_iommu=onЧто гарантирует корректную инициализацию Intel IOMMU.
Хочу обратить внимание что использование UIO (uio_pci_generic, igb_uio) является опциональным для ядер поддерживающих VFIO (vfio-pci), с помощью которых реализованы функции взаимодействия с целевыми сетевыми интерфейсами.
igb_uio нужен в случае отсутствия поддержки некоторых прерываний и/или виртуальных функций целевыми сетевыми адаптерами, иначе можно спокойно использовать uio_pci_generic.
Не смотря на то что iommu=pt параметр является обязательным для igb_uio драйвера, vfio-pci драйвер корректно функционирует как с параметром iommu=pt так и с iommu=on.
Сам по себе VFIO функциклирует довольно
Если ваше устройство находится за PCI-to-PCI мостом, то драйвер моста будет входить в ту же IOMMU группу что и целевой адаптер, по этому драйвер моста нужно выгрузить — что бы VFIO могло подхватить устройства за мостом.
Проверить расположение существующих устройств и используемые драйвера можно скриптом:
./tools/dpdk_nic_bind.py --status
Также можно явно привязать драйвера к конкретным сетевым устройствам
./tools/dpdk_nic_bind.py --bind=uio_pci_generic 04:00.1
./tools/dpdk_nic_bind.py --bind=uio_pci_generic eth1
Удобненько однако.
Установка
Берём исходники и собираем так как описано далее.
Сам DPDK поставляется с набором приложений-примеров, на которых можно обкатать корректность настройки системы.
Настройка DPDK, как уже было сказано выше, производится посредством установки параметров в файлах config/common_linuxapp и config/common_bsdapp. Стандартные значения платформозависимых параметров хранятся в файлах config/defconfig_*.
Сначала производится применение шаблона конфигурации, создаётся папка build со всей живностью и таргетами:
make config T=x86_64-native-linuxapp-gcc
В DPDK 2.2 доступны следующие целевые окружения (у меня)
arm-armv7a-linuxapp-gcc
arm64-armv8a-linuxapp-gcc
arm64-thunderx-linuxapp-gcc
arm64-xgene1-linuxapp-gcc
i686-native-linuxapp-gcc
i686-native-linuxapp-icc
ppc_64-power8-linuxapp-gcc
tile-tilegx-linuxapp-gcc
x86_64-ivshmem-linuxapp-gcc
x86_64-ivshmem-linuxapp-icc
x86_64-native-bsdapp-clang
x86_64-native-bsdapp-gcc
x86_64-native-linuxapp-clang
x86_64-native-linuxapp-gcc
x86_64-native-linuxapp-icc
x86_x32-native-linuxapp-gcc
ivshmem — это механизм QEMU который вроде как позволяет делиться областью памяти между несколькими гостевыми виртуальными машинами без копирования, посредством общего специализированного устройства. Хотя копировать в разделяемую (shared) память нужно в случае коммуникации между гостевыми ОС, правда это не случай DPDK. Сам по себе ivshmem реализован довольно просто.
Предназначение остальных шаблонов конфигурации должно быть очевидным, иначе зачем вы вообще это читаете?
Кроме шаблона конфигурации есть другие опциональные параметры
EXTRA_CPPFLAGS - флаги препроцессора
EXTRA_CFLAGS - флаги компилятора
EXTRA_LDFLAGS - флаги линковщика
EXTRA_LDLIBS - библиотеки линковщика
RTE_KERNELDIR - путь к заголовочным файлам ядра
CROSS - префикс тулчейна
V=1 - детализировать отладочную информацию процесса сборки
D=1 - внедрить отладочные зависимости
O - расположение папки `build`
DESTDIR - путь установки целей `/usr/local`
Далее просто старый-добрый
make
Список целей для make довольно банален
all build clean
install uninstall
examples examples_clean
Для работы нужно загрузить UIO модули
sudo modprobe uio_pci_generic
sudo modprobe uio
sudo insmod kmod/igb_uio.ko
Если используется VFIO
sudo modprobe vfio-pci
Если используется KNI
insmod kmod/rte_kni.ko
Сборка и запуск примеров
DPDK использует 2 переменные окружения для сборки примеров:
- RTE_SDK — путь к папке где установлен DPDK
- RTE_TARGET — название шаблона конфигурации используемого для сборки
Они используются в соответствующих Makefile'ах.
EAL уже предоставляет некоторые параметры командной строки для настройки приложения:
- -c <маска> — шестнадцатеричная маска логических ядер на которых будет выполнятся приложение
- -n <количество> каналов памяти на процессор
- -b <домен: шина: идентификатор.функция>,… — чёрный список PCI устройств
- --use-device <домен: шина: идентификатор.функция>,… — белый список PCI устройств, не может использоваться одновременно с чёрным
- --socket-mem MB — количество выделяемой памяти больших страниц на один процессорный сокет
- -m MB — количество выделяемой памяти больших страниц, игнорируется физическое расположение процессора
- -r <количество> слотов памяти
- -v — версия
- --huge-dir — папка к которой примонтированы большие страницы
- --file-prefix — префикс файлов которые хранятся в файловой системе больших страниц
- --proc-type — экземпляр процесса, используется вместе с --file-prefix для запуска приложения в нескольких процессах
- --xen-dom0 — выполнение в Xen domain0 без поддержки больших страниц
- --vmware-tsc-map — использование TSC счетчика предоставляемого VMWare, вместо RDTSC
- --base-virtaddr — базовый виртуальный адресс
- --vfio-intr — тип прерываний исспользуемых VFIO
Для проверки номерации ядер в системе можно использовать команду lstopo из пакета hwloc.
Рекомендуется использовать всю выделенную в виде больших страниц память, это поведение по умолчанию если не используются параметры -m и --socket-mem. Выделение непрерывных областей памяти меньше чем доступно в больших страницах может привести к ошибкам инициализации EAL, и иногда к неопределённому поведению.
Для выделения 1ГБайт'a памяти
- на нулевом сокете () нужно указать --socket-mem=1024
- на первом --socket-mem=0,1024
- на нулевом и втором --socket-mem=1024,0,1024
Для сборки и запуска Hello World
export RTE_SDK=~/src/dpdk
cd ${RTE_SDK}/examples/helloworld
make
./build/helloworld -c f -n 2
Таким образом приложение выполнится на четырех ядрах, c учётом что установлено 2 планки памяти.
И получим мы 5 hello world'ов с разных ядер.
Проблема курицы, яйца и птеродактиля
Я выбрал Java как целевую платформу из-за относительно высокой производительности виртуальной машины и возможности внедрения дополнительных механизмов менеджмента памяти. Вопрос как распределить ответственность: где выделять память, где управлять потоками, как выполнять планировку задач и что особенного в механизмах DPDK — довольно сложен и двузначен. Пришлось незаурядно поколупаться в исходниках DPDK, Netty и самого OpenJDK. В итоге были разработаны специализированные версии компонентов netty с очень глубокой интеграцией DPDK.
Продолжение следует.
