Во многих задачах возникает необходимость использования генератора псевдослучайных чисел. Вот и у нас возникла такая необходимость. В общем и целом задача заключалась в создании вычислительной платформы на базе блока RB8V7, которая должна была быть использована как ускоритель расчетов конкретной научной задачи.
Скажу пару слов об этой научной задаче: необходимо было произвести расчет динамики биологических микротрубочек на временах порядка минуты. Расчеты представляли собой вычисления с использованием молекулярно-механической модели микротрубочки, разработанной в научной группе. Планировалось, что на основе полученных результатов вычислений можно будет сделать вывод о механизмах динамической нестабильности микротрубочек. Необходимость в использовании ускорителя была обусловлена тем фактом, что минута эквивалента достаточно большому количеству расчетных шагов (~ 10 ^ 12) и, как следствие, большому количеству времени, затрачиваемому на вычисления.
Итак, возвращаясь к теме статьи, в нашем случае генераторы псевдослучайных чисел нужны были для учета теплового движения молекул упомянутых микротрубочек.
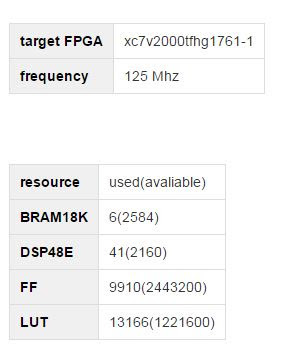
В качестве базовой архитектуры проекта был использована архитектура с поддержкой DMA передач. Как компонент этого вычислительной платформы необходимо было реализовать IP ядро, которое способно было бы генерировать новое псевдослучайное нормально распределенное число типа float каждый такт и занимало бы как можно меньше ресурсов на ПЛИС.
Хочу заметить, что, в итоге, у нас все получилось, однако путь к решению данной задачи был не лишен неверных шагов и ошибок, о которых я также хочу написать ниже. Надеюсь, данная статья окажется полезной.
Для решения данной задачи мы применили транслятор языка высокого уровня в RTL код. Для реализации сложной вычислительной задачи данный подход позволяет получить результат гораздо быстрее (и часто лучше), чем использование голого RTL. Нами была использована программа Vivado HLS версии 2014.4, которая транслирует C/C++ код с использованием специальных директив в RTL код. Примеры директив можно посмотреть тут.
С учетом упомянутых требований к разрабатываемому решению и того факта, что генератор должен включать несколько этапов вычислений, наиболее подходящей архитектурой является конвейер. О реализации конвейера на ПЛИС можно подробнее почитать здесь. Хочу заметить, что главными характеристиками вычислительного конвейера является интервал инициализации и латентность. Интервал инициализации — это количество тактов, затрачиваемое на выполнение ступени конвейера (максимум среди всех ступеней).
Латентность — это количество тактов, прошедшее с момента поступления данных на вход конвейера до момента выдачи конвейером результата. В данном случае латентность нас не очень интересует, так как она ничтожно мала по сравнению с предполагаемым общим временем работы конвейера, а вот к интервалу инициализации следует отнестись очень внимательно, так как он фактически характеризует, как часто конвейер способен принимать на вход данные и, соответственно, как часто он способен выдавать новый результат.
Первоначально было решено использовать следующий подход:
Из плюсов данного подхода стоит отметить, что данный генератор нормальных чисел реализуется в конечную схему весьма просто и действительно занимает не очень много. Главным минусом такого подхода является то, что он в нашем случае неправильный. =) Действительно, последовательные значения, которые выдает генератор, являются скоррелированными. Это можно наглядно продемонстрировать, построив автокорреляционную функцию (см. рис.), или построив зависимость x[i+k] от x[i], где k = 1,2,3…
Эта ошибка вылилась в интересные эффекты в динамике микротрубочек, движение которых было промоделировано с использованием данного генератора.

Итак, алгоритм генерации равномерно распределенных целых чисел необходимо было менять. Выбор пал на Вихрь Мерсенна. В том, что у этого алгоритма значения сгенерированных чисел не скоррелированны между собой, можно убедиться, посмотрев на автокорреляционную функцию получаемой последовательности чисел. Однако реализация данного алгоритма требует больше ресурсов, так как работает с полем чисел размера 612, а не с одним числом как в предыдущем случае (см. код в свободном доступе).
Сразу оговорюсь, что я понимаю под словами «процедура занимает n тактов (шагов)». Это значит, что данная процедура при трансляции в RTL будет выполняться за n тактовых импульсов. Например, если на очередном шаге конвейера нам надо прочитать из однопортовой RAM памяти два слова, то эта операция будет выполнена за два такта, так как порт только один, то есть память может обеспечить за такт выполнение только одного запроса на запись или на чтение.
Для оптимальной трансляции данного алгоритма в RTL код необходимо было переработать. Во-первых, в начальной реализации внутри генератора происходит следующее: при запросе нового случайного числа на выход подается либо очередной элемент матрицы, либо по достижении конца матрицы происходит процедура обновления элементов матрицы. Процедура обновления заключается в различных побитовых операциях с использованием элементов массива. Процедура занимает как минимум 612 шагов, так как обновляется значение каждого элемента. Затем на выход подается нулевой элемент матрицы. Таким образом, процедура будет занимать разное количество шагов для разных обращений к данной функции. Такая функцию нельзя конвейеризовать.
Поменяем эту процедуру: теперь за одно обращение к функции происходит обновление предыдущего элемента массива и выдача текущего элемента. Теперь данная процедура всегда занимаем одно и то же количество тактов. При этом результат одинаков в обоих реализациях: при завершении обхода матрицы она уже будет заполнена обновленными значениями и можно будет просто вернуться к нулевому элементу массива. Теперь эту процедуру реально конвейеризовать.
Теперь зададимся вопросом, как часто такой конвейер будет способен выдавать новое случайное число? Для этого нам нужно внести некоторую дополнительную ясность. С помощью каких ресурсов реализовывать используемый массив (mt)? Его можно реализовать либо с помощью регистров, либо с помощью памяти. Реализация с помощью регистров является наиболее простой с точки зрения конечной оптимизации кода для достижения единичного интервала инициализации. В отличие от ячеек памяти, к каждому регистру можно обратиться независимо.
Однако в случае использования большого количества регистров велика вероятность появления временных задержек на путях между регистрами, что приводит к необходимости понижения рабочей частоты для генерируемого IP ядра. В случае использования памяти существует ограничение на количество одновременных запросов к блоку памяти, причина которого заключается в ограниченном количестве портов блока. Однако при этом проблем с временными задержками, как правило, не возникает. Вследствие ограничений на ресурсы в нашем случае было бы предпочтительнее реализовать массив с помощью памяти. Рассмотрим, имеются ли у нас конфликты обращения к памяти и возможно ли их разрешить.
Итак, сколько одновременных с точки зрения ПЛИС запросов элементов массива происходит у нас за такт? Во первых заметим, что на каждом такте мы работаем с четырьмя ячейками массива. То есть в первом приближении нам необходимо обеспечить четыре одновременных запроса в память: три чтения и одну запись. Причем одно чтение и одна запись происходят в одну и ту же ячейку.
Первая проблема, которую необходимо решить, это убрать конфликт чтения и записи в одну и ту же ячейку. Это можно сделать, заметив, что в результате последовательных вызов функции как раз происходит чтение из одной и той же ячейки, таким образом, за предыдущий вызов достаточно прочитать значение и сохранить прочитанное в регистр, а на следующем просто взять необходимое число из регистра. Теперь необходимо обеспечить три одновременных запроса в память: два чтения и одну запись (в разные ячейки памяти).
Для решения конфликтов запросов в память в Vivado HLS существует несколько приемов: во-первых, добавить директиву, которая указывает транслятору реализовать массив через двухпортовую RAM память, таким образом, можно позволить себе два одновременных запроса в блок памяти, при условии, что они не обращаются к одной и той же ячейке.
Во-вторых, существует директива, которая указывает транслятору реализовать массив не через один блок памяти, а через несколько. Этим можно увеличить суммарное количество портов, и, таким образом, увеличить максимально возможное количество одновременных запросов. Можно, например, сделать так, чтобы элементы массива с индексами 0...N/2 лежали в одном блоке памяти, а элементы с индексами N/2+1...N-1 лежали во втором блоке памяти. Или, например, элементы с индексами 2*k лежали в одном блоке, а элементы с индексами 2*k+1 лежали в другом блоке. Замечу, что количество блоков может быть >2. Это также позволяет в некоторых случаях увеличить количество возможных одновременных запросов к массиву.
К сожалению, последний подход в нашем случае оказался не применим в чистом виде, так как разбивать наш массив пришлось на несколько блоков неравного размера, чего директива делать не умеет. Если внимательно посмотреть, к каким элементам в массиве происходит обращение в течение прохода по всем индексам, можно заметить, что массив можно разбить на три части таким образом, чтобы к каждой части было не более двух одновременных запросов.

На самом деле эта стадия заняла наибольшее количество времени, так как Vivado HLS транслятор упорно не хотел понимать, что мы от него хотим и конечный интервал инициализации был больше 1. Помогло то, что мы просто представили и нарисовали конечную схему и в соответствии с ней написали код. Заработало!
Таким образом, мы реализовали наш массив через 3 блока двухпортовой RAM памяти, что позволило конвейеризовать нашу функцию и обеспечить единичный интервал инициализации. То есть, теперь у нас есть рабочий генератор равномерно распределенных псевдослучайных чисел. Теперь необходимо получить из этих чисел нормально распределенные псевдослучайные числа. Можно было бы воспользоваться предыдущим подходом с использованием центральной предельной теоремы. Однако напомню, что теперь генератор равномерно распределенных случайных чисел занимает гораздо больше ресурсов, а для центральной предельной теоремы необходимо было бы реализовать 12 таких генераторов.
Наш выбор пал на преобразование Бокса-Мюллера, которое позволяет получить два нормально распределенных случайных числа из двух равномерно распределенных случайных величин на отрезке (0,1]. Причем в отличие от подхода с ЦПТ, где 12 это на самом деле не очень большое число, в случае преобразования мы получаем числа, для которых распределение аналитически точно будет гауссовским. Чуть более подробно об этом можно почитать тут. Хочу только заметить, что данное преобразование существует в двух вариантах: одно использует меньше вычислений, но при этом результат выдается не при каждом вызове генератора, второй подход использует больше вычислений, однако результат гарантирован при каждом вызове.
Так как результат нам нужен каждый такт, был использован второй поход. Плюс ко всему к каждой вычислительной операции была применена директива, которая указывает транслятору НЕ реализовывать данную операцию с использованием DSP блоков. По умолчанию Vivado HLS имплементирует вычислительные операции с помощью максимального количества DSP блоков. Дело в том, что с учетом конвейеризации количество необходимых DSP блоков было бы достаточно большим по сравнению с общим количеством доступных DSP блоков. С учетом их расположения на кристалле получались бы большие временных задержки.
В результате мы получили ядро, использующее следующий поход:
Привожу также визуализацию динамики микротрубочки с использованием данного генератора.

P.S.: На самом деле уже после оказалось, что использование подхода «вихрь Мерсенна» + преобразование Бокса-Мюллера действительно является рабочим подходом для получения нормально распределенных случайных чисел [1].
Проект доступен на github.
I welcome any questions or comments.
[1] High-Performance Computing Using FPGAs Editors: Vanderbauwhede, Wim, Benkrid, Khaled (Eds.) 2013 pp. 20-30
Скажу пару слов об этой научной задаче: необходимо было произвести расчет динамики биологических микротрубочек на временах порядка минуты. Расчеты представляли собой вычисления с использованием молекулярно-механической модели микротрубочки, разработанной в научной группе. Планировалось, что на основе полученных результатов вычислений можно будет сделать вывод о механизмах динамической нестабильности микротрубочек. Необходимость в использовании ускорителя была обусловлена тем фактом, что минута эквивалента достаточно большому количеству расчетных шагов (~ 10 ^ 12) и, как следствие, большому количеству времени, затрачиваемому на вычисления.
Итак, возвращаясь к теме статьи, в нашем случае генераторы псевдослучайных чисел нужны были для учета теплового движения молекул упомянутых микротрубочек.
В качестве базовой архитектуры проекта был использована архитектура с поддержкой DMA передач. Как компонент этого вычислительной платформы необходимо было реализовать IP ядро, которое способно было бы генерировать новое псевдослучайное нормально распределенное число типа float каждый такт и занимало бы как можно меньше ресурсов на ПЛИС.
Подробнее
Последнее требование было обусловлено тем, что, во-первых, кроме данного IP ядра, на ПЛИС должны были присутствовать и другие вычислительные модули + интерфейсная часть, во-вторых, вычисления в задаче производились над числами с плавающей точкой типа float, которые в случае с ПЛИС занимают довольно много ресурсов, и, в третьих, что ядер на ПЛИС предполагалось несколько. Требование генерировать случайное число каждый такт было обусловлено архитектурой конечного вычислительного модуля, который, собственно, и использовал данные случайные числа. Архитектура представляла собой конвейер и, соответственно, требовало новых случайных чисел каждый такт.
Хочу заметить, что, в итоге, у нас все получилось, однако путь к решению данной задачи был не лишен неверных шагов и ошибок, о которых я также хочу написать ниже. Надеюсь, данная статья окажется полезной.
Для решения данной задачи мы применили транслятор языка высокого уровня в RTL код. Для реализации сложной вычислительной задачи данный подход позволяет получить результат гораздо быстрее (и часто лучше), чем использование голого RTL. Нами была использована программа Vivado HLS версии 2014.4, которая транслирует C/C++ код с использованием специальных директив в RTL код. Примеры директив можно посмотреть тут.
С учетом упомянутых требований к разрабатываемому решению и того факта, что генератор должен включать несколько этапов вычислений, наиболее подходящей архитектурой является конвейер. О реализации конвейера на ПЛИС можно подробнее почитать здесь. Хочу заметить, что главными характеристиками вычислительного конвейера является интервал инициализации и латентность. Интервал инициализации — это количество тактов, затрачиваемое на выполнение ступени конвейера (максимум среди всех ступеней).
Латентность — это количество тактов, прошедшее с момента поступления данных на вход конвейера до момента выдачи конвейером результата. В данном случае латентность нас не очень интересует, так как она ничтожно мала по сравнению с предполагаемым общим временем работы конвейера, а вот к интервалу инициализации следует отнестись очень внимательно, так как он фактически характеризует, как часто конвейер способен принимать на вход данные и, соответственно, как часто он способен выдавать новый результат.
Первоначально было решено использовать следующий подход:
- регистры сдвига с линейной обратной связью для получения независимых целых равномерно распределенных случайных чисел. В начале каждый из них инициируется с помощью своего «затравочного» числа, т.н. seed.
- центральная предельная теорема, которая позволяет утверждать, что сумма большого количества независимых случайных величин имеет распределение близкое к нормальному. В нашем случае суммируются 12 чисел.
Код
#pragma HLS PIPELINE
unsigned lsb = lfsr & 1;
lfsr >>= 1;
if (lsb == 1)
lfsr ^= 0x80400002;
return lfsr;
Из плюсов данного подхода стоит отметить, что данный генератор нормальных чисел реализуется в конечную схему весьма просто и действительно занимает не очень много. Главным минусом такого подхода является то, что он в нашем случае неправильный. =) Действительно, последовательные значения, которые выдает генератор, являются скоррелированными. Это можно наглядно продемонстрировать, построив автокорреляционную функцию (см. рис.), или построив зависимость x[i+k] от x[i], где k = 1,2,3…
Автокорреляционная функция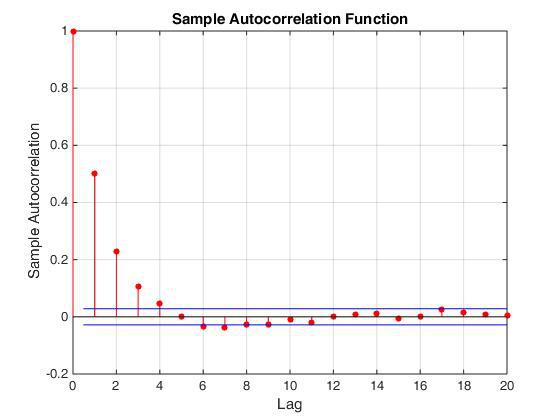

Эта ошибка вылилась в интересные эффекты в динамике микротрубочек, движение которых было промоделировано с использованием данного генератора.
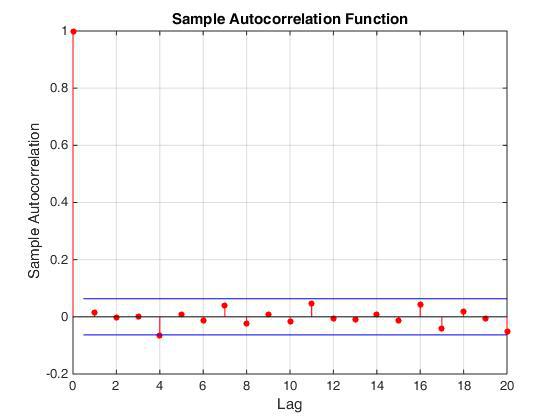
Итак, алгоритм генерации равномерно распределенных целых чисел необходимо было менять. Выбор пал на Вихрь Мерсенна. В том, что у этого алгоритма значения сгенерированных чисел не скоррелированны между собой, можно убедиться, посмотрев на автокорреляционную функцию получаемой последовательности чисел. Однако реализация данного алгоритма требует больше ресурсов, так как работает с полем чисел размера 612, а не с одним числом как в предыдущем случае (см. код в свободном доступе).
автокорреляционная функция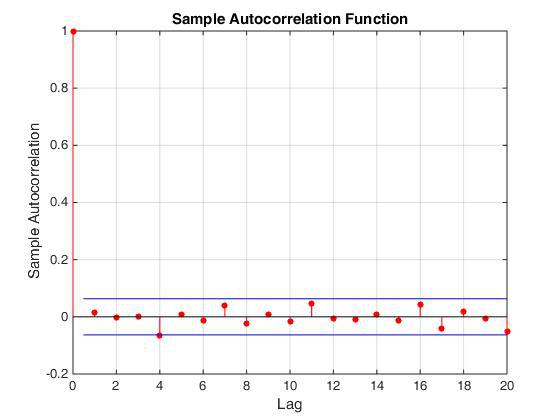
Сразу оговорюсь, что я понимаю под словами «процедура занимает n тактов (шагов)». Это значит, что данная процедура при трансляции в RTL будет выполняться за n тактовых импульсов. Например, если на очередном шаге конвейера нам надо прочитать из однопортовой RAM памяти два слова, то эта операция будет выполнена за два такта, так как порт только один, то есть память может обеспечить за такт выполнение только одного запроса на запись или на чтение.
Для оптимальной трансляции данного алгоритма в RTL код необходимо было переработать. Во-первых, в начальной реализации внутри генератора происходит следующее: при запросе нового случайного числа на выход подается либо очередной элемент матрицы, либо по достижении конца матрицы происходит процедура обновления элементов матрицы. Процедура обновления заключается в различных побитовых операциях с использованием элементов массива. Процедура занимает как минимум 612 шагов, так как обновляется значение каждого элемента. Затем на выход подается нулевой элемент матрицы. Таким образом, процедура будет занимать разное количество шагов для разных обращений к данной функции. Такая функцию нельзя конвейеризовать.
Вариант 0
unsigned long y;
if (mti >= N) { /* generate N words at one time */
int kk;
if (mti == N+1) /* if sgenrand() has not been called, */
sgenrand(4357); /* a default initial seed is used */
for (kk=0;kk<N-M;kk++) {
y = (mt[kk]&UPPER_MASK)|(mt[kk+1]&LOWER_MASK);
mt[kk] = mt[kk+M] ^ (y >> 1) ^ mag01[y & 0x1];
}
for (;kk<N-1;kk++) {
y = (mt[kk]&UPPER_MASK)|(mt[kk+1]&LOWER_MASK);
mt[kk] = mt[kk+(M-N)] ^ (y >> 1) ^ mag01[y & 0x1];
}
y = (mt[N-1]&UPPER_MASK)|(mt[0]&LOWER_MASK);
mt[N-1] = mt[M-1] ^ (y >> 1) ^ mag01[y & 0x1];
mti = 0;
}
y = mt[mti++];
y ^= (y >> 11);
y ^= (y << 7) & 0x9d2c5680UL;
y ^= (y << 15) & 0xefc60000UL;
y ^= (y >> 18);
return ( (double)y * 2.3283064370807974e-10 ); /* reals */
/* return y; */ /* for integer generation */
Поменяем эту процедуру: теперь за одно обращение к функции происходит обновление предыдущего элемента массива и выдача текущего элемента. Теперь данная процедура всегда занимаем одно и то же количество тактов. При этом результат одинаков в обоих реализациях: при завершении обхода матрицы она уже будет заполнена обновленными значениями и можно будет просто вернуться к нулевому элементу массива. Теперь эту процедуру реально конвейеризовать.
Вариант 1
#pragma HLS PIPELINE
#pragma HLS INLINE
float y;
unsigned long mt_temp,reg1;
unsigned long temper, temper1;
if (mti<N_period-M_period) {
mt_temp = (mt[mti]&UPPER_MASK)|(mt[mti+1]&LOWER_MASK);
mt[mti] = mt[mti+M_period] ^ (mt_temp >> 1) ^ mag01[mt_temp & 0x1UL];
}else{
if (mti<N_period-1) {
mt_temp = (mt[mti]&UPPER_MASK)|(mt[mti+1]&LOWER_MASK);
mt[mti] = mt[mti+(M_period-N_period)] ^ (mt_temp >> 1) ^ mag01[mt_temp & 0x1UL];
}else{
mt_temp = (mt[N_period-1]&UPPER_MASK)|(mt[0]&LOWER_MASK);
mt[N_period-1] = mt[M_period-1] ^ (mt_temp >> 1) ^ mag01[mt_temp & 0x1UL];
}
}
reg1 = mt[mti];
if (mti == (N_period - 1)) mti = 0;
else mti=mti+1;
temper=tempering(reg1);
temper1 = (temper==0) ? 1 : temper;
y=(float) temper1/4294967296.0;
return y;
Теперь зададимся вопросом, как часто такой конвейер будет способен выдавать новое случайное число? Для этого нам нужно внести некоторую дополнительную ясность. С помощью каких ресурсов реализовывать используемый массив (mt)? Его можно реализовать либо с помощью регистров, либо с помощью памяти. Реализация с помощью регистров является наиболее простой с точки зрения конечной оптимизации кода для достижения единичного интервала инициализации. В отличие от ячеек памяти, к каждому регистру можно обратиться независимо.
Однако в случае использования большого количества регистров велика вероятность появления временных задержек на путях между регистрами, что приводит к необходимости понижения рабочей частоты для генерируемого IP ядра. В случае использования памяти существует ограничение на количество одновременных запросов к блоку памяти, причина которого заключается в ограниченном количестве портов блока. Однако при этом проблем с временными задержками, как правило, не возникает. Вследствие ограничений на ресурсы в нашем случае было бы предпочтительнее реализовать массив с помощью памяти. Рассмотрим, имеются ли у нас конфликты обращения к памяти и возможно ли их разрешить.
Итак, сколько одновременных с точки зрения ПЛИС запросов элементов массива происходит у нас за такт? Во первых заметим, что на каждом такте мы работаем с четырьмя ячейками массива. То есть в первом приближении нам необходимо обеспечить четыре одновременных запроса в память: три чтения и одну запись. Причем одно чтение и одна запись происходят в одну и ту же ячейку.
Вариант 2
#pragma HLS PIPELINE
#pragma HLS INLINE
float y;
unsigned long mt_temp,reg1,reg2,reg3,result;
unsigned long temper, temper1;
if (mti<N_period-M_period) {
reg2=mt[mti+1]; // read 0
reg3=mt[mti+M_period]; // read 1
}else{
if (mti<N_period-1) {
reg2=mt[mti+1]; //read 0
reg3=mt[mti+(M_period-N_period)]; //read 1
}else{
reg2=mt[0]; //read 0
reg3=mt[M_period-1]; //read 1
}
}
reg1 = mt[mti]; //read 2
mt_temp = (reg1&UPPER_MASK)|(reg2&LOWER_MASK);
result = reg3 ^ (mt_temp >> 1) ^ mag01[mt_temp & 0x1UL];
mt[mti]=result; //write
if (mti == (N_period - 1)) mti = 0;
else mti=mti+1;
temper=tempering(result);
temper1 = (temper==0) ? 1 : temper;
y=(float) temper1/4294967296.0;
return y;
Первая проблема, которую необходимо решить, это убрать конфликт чтения и записи в одну и ту же ячейку. Это можно сделать, заметив, что в результате последовательных вызов функции как раз происходит чтение из одной и той же ячейки, таким образом, за предыдущий вызов достаточно прочитать значение и сохранить прочитанное в регистр, а на следующем просто взять необходимое число из регистра. Теперь необходимо обеспечить три одновременных запроса в память: два чтения и одну запись (в разные ячейки памяти).
Вариант 3
#pragma HLS PIPELINE
#pragma HLS INLINE
float y;
unsigned long mt_temp,reg1,reg2,reg3,result;
unsigned long temper, temper1;
if (mti<N_period-M_period) {
reg2=mt[mti+1]; //read 0
reg3=mt[mti+M_period]; //read1
}else{
if (mti<N_period-1) {
reg2=mt[mti+1]; //read 0
reg3=mt[mti+(M_period-N_period)]; //read 1
}else{
reg2=mt[0]; //read 0
reg3=mt[M_period-1]; //read 1
}
}
reg1 = prev_val;
mt_temp = (reg1&UPPER_MASK)|(reg2&LOWER_MASK);
result = reg3 ^ (mt_temp >> 1) ^ mag01[mt_temp & 0x1UL];
mt[mti]=result; //write
prev_val=reg2;
if (mti == (N_period - 1)) mti = 0;
else mti=mti+1;
temper=tempering(result);
temper1 = (temper==0) ? 1 : temper;
y=(float) temper1/4294967296.0;
return y;
Для решения конфликтов запросов в память в Vivado HLS существует несколько приемов: во-первых, добавить директиву, которая указывает транслятору реализовать массив через двухпортовую RAM память, таким образом, можно позволить себе два одновременных запроса в блок памяти, при условии, что они не обращаются к одной и той же ячейке.
#pragma HLS RESOURCE variable=mt1 core=RAM_2P_BRAM
Во-вторых, существует директива, которая указывает транслятору реализовать массив не через один блок памяти, а через несколько. Этим можно увеличить суммарное количество портов, и, таким образом, увеличить максимально возможное количество одновременных запросов. Можно, например, сделать так, чтобы элементы массива с индексами 0...N/2 лежали в одном блоке памяти, а элементы с индексами N/2+1...N-1 лежали во втором блоке памяти. Или, например, элементы с индексами 2*k лежали в одном блоке, а элементы с индексами 2*k+1 лежали в другом блоке. Замечу, что количество блоков может быть >2. Это также позволяет в некоторых случаях увеличить количество возможных одновременных запросов к массиву.
#pragma HLS array_partition variable=AB block factor=4
К сожалению, последний подход в нашем случае оказался не применим в чистом виде, так как разбивать наш массив пришлось на несколько блоков неравного размера, чего директива делать не умеет. Если внимательно посмотреть, к каким элементам в массиве происходит обращение в течение прохода по всем индексам, можно заметить, что массив можно разбить на три части таким образом, чтобы к каждой части было не более двух одновременных запросов.

На самом деле эта стадия заняла наибольшее количество времени, так как Vivado HLS транслятор упорно не хотел понимать, что мы от него хотим и конечный интервал инициализации был больше 1. Помогло то, что мы просто представили и нарисовали конечную схему и в соответствии с ней написали код. Заработало!
Схема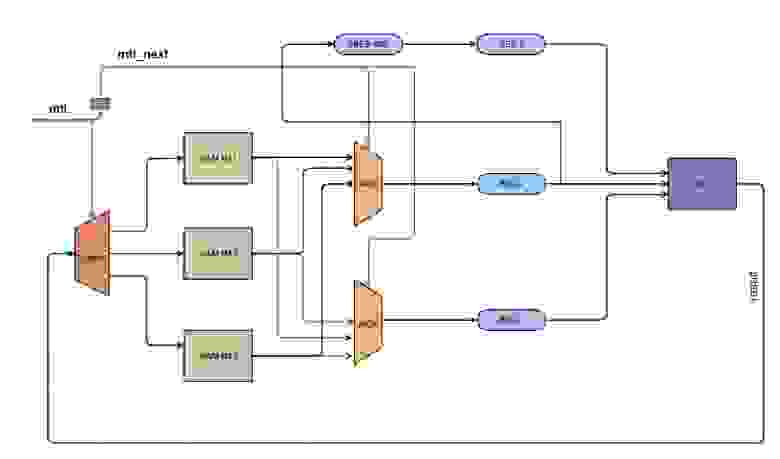
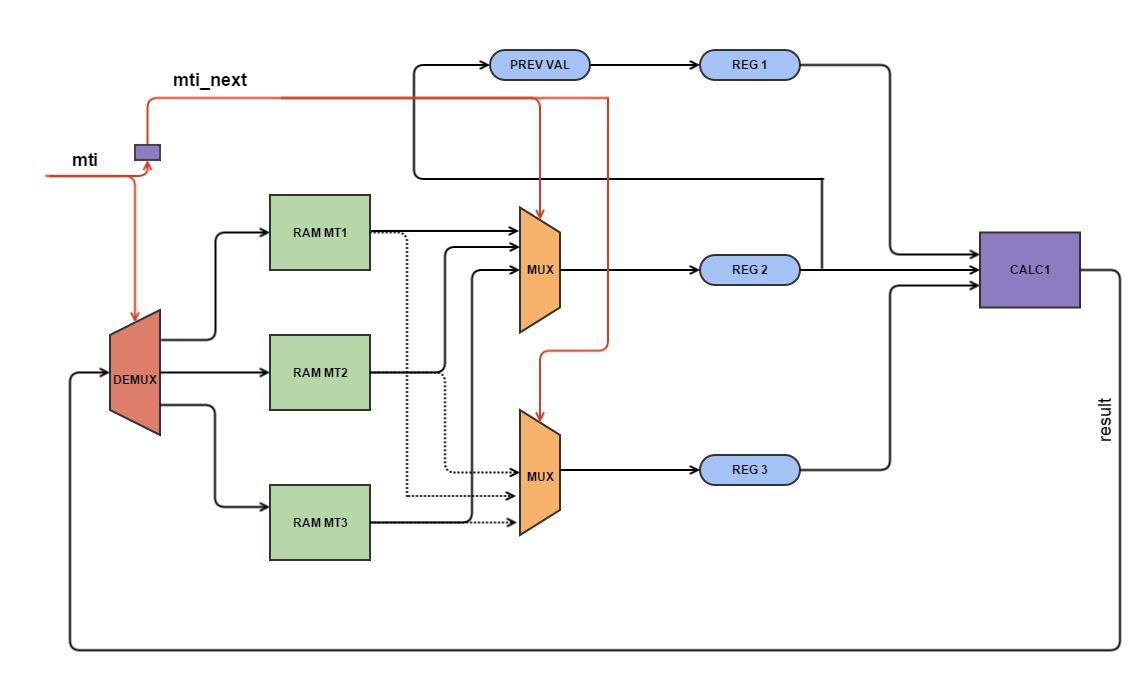
Конечный вариант
#pragma HLS PIPELINE
#pragma HLS RESOURCE variable=mt1 core=RAM_2P_BRAM
#pragma HLS RESOURCE variable=mt2 core=RAM_2P_BRAM
#pragma HLS RESOURCE variable=mt3 core=RAM_2P_BRAM
#pragma HLS INLINE
float y;
unsigned long mt_temp,reg1,reg2,reg3,result, m1_temp,m2_temp, m3_temp;
unsigned long temper, temper1;
unsigned int a1,a2, a3,s2,s3;
int mti_next=0;
if (mti == (N_period - 1)) mti_next = 0;
else mti_next=mti+1;
if (mti_next==0) {
s2=1; s3=2;
a1=mti_next; a2=2*M_period-N_period-1; a3=0;
}
else if (mti_next < (N_period - M_period)) {
s2 = 1; s3 = 3;
a1 = mti_next; a2 = 0; a3 = mti_next-1;
}else if (mti_next== (N_period - M_period)){
s2 = 2; s3 = 3;
a2 = 0; a1 = 0; a3 = N_period-M_period-1;
}
else if (mti_next < M_period) {
s2 = 2; s3 = 1;
a1 = mti_next - (N_period - M_period)-1; a2 = mti_next - (N_period - M_period); a3 = 0;
} else if (mti_next < (2*(N_period-M_period)+1)) {
s2 = 3; s3 = 1;
a1 = mti_next - (N_period - M_period)-1; a2 = 0; a3 = mti_next - M_period;
} else {
s2 = 3; s3 = 2;
a1 = 0; a2 = mti_next - (2*(N_period-M_period)+1); a3 = mti_next - M_period;
}
// read data from bram
m1_temp = mt1[a1];
m2_temp = mt2[a2];
m3_temp = mt3[a3];
if (s2 == 1) reg2 = m1_temp;
else if (s2 == 2) reg2 = m2_temp;
else reg2 = m3_temp;
if (s3 == 1) reg3 = m1_temp;
else if (s3 == 2) reg3 = m2_temp;
else reg3 = m3_temp;
reg1 = prev_val;
mt_temp = (reg1&UPPER_MASK)|(reg2&LOWER_MASK);
result = reg3 ^ (mt_temp >> 1) ^ mag01[mt_temp & 0x1UL];
// write process
if (mti < (N_period - M_period))
mt1[mti] = result;
else if (mti < M_period)
mt2[mti-(N_period-M_period)] = result;
else
mt3[mti-M_period] = result;
//save into reg
prev_val=reg2;
mti=mti_next;
temper=tempering(result);
temper1 = (temper==0) ? 1 : temper;
y=(float) temper1/4294967296.0;
return y;
Таким образом, мы реализовали наш массив через 3 блока двухпортовой RAM памяти, что позволило конвейеризовать нашу функцию и обеспечить единичный интервал инициализации. То есть, теперь у нас есть рабочий генератор равномерно распределенных псевдослучайных чисел. Теперь необходимо получить из этих чисел нормально распределенные псевдослучайные числа. Можно было бы воспользоваться предыдущим подходом с использованием центральной предельной теоремы. Однако напомню, что теперь генератор равномерно распределенных случайных чисел занимает гораздо больше ресурсов, а для центральной предельной теоремы необходимо было бы реализовать 12 таких генераторов.
Наш выбор пал на преобразование Бокса-Мюллера, которое позволяет получить два нормально распределенных случайных числа из двух равномерно распределенных случайных величин на отрезке (0,1]. Причем в отличие от подхода с ЦПТ, где 12 это на самом деле не очень большое число, в случае преобразования мы получаем числа, для которых распределение аналитически точно будет гауссовским. Чуть более подробно об этом можно почитать тут. Хочу только заметить, что данное преобразование существует в двух вариантах: одно использует меньше вычислений, но при этом результат выдается не при каждом вызове генератора, второй подход использует больше вычислений, однако результат гарантирован при каждом вызове.
Так как результат нам нужен каждый такт, был использован второй поход. Плюс ко всему к каждой вычислительной операции была применена директива, которая указывает транслятору НЕ реализовывать данную операцию с использованием DSP блоков. По умолчанию Vivado HLS имплементирует вычислительные операции с помощью максимального количества DSP блоков. Дело в том, что с учетом конвейеризации количество необходимых DSP блоков было бы достаточно большим по сравнению с общим количеством доступных DSP блоков. С учетом их расположения на кристалле получались бы большие временных задержки.
#pragma HLS RESOURCE variable=d0 core=FMul_nodsp
В результате мы получили ядро, использующее следующий поход:
- два генератора равномерно распределенных случайных чисел, использующих алгоритм «вихрь Мерсенна»
- преобразование Бокса-Мюллера, которое из двух равномерно распределенных на отрезке (0,1] случайных величин получает два нормально распределенных случайных числа
Привожу также визуализацию динамики микротрубочки с использованием данного генератора.
P.S.: На самом деле уже после оказалось, что использование подхода «вихрь Мерсенна» + преобразование Бокса-Мюллера действительно является рабочим подходом для получения нормально распределенных случайных чисел [1].
Проект доступен на github.
I welcome any questions or comments.
[1] High-Performance Computing Using FPGAs Editors: Vanderbauwhede, Wim, Benkrid, Khaled (Eds.) 2013 pp. 20-30
