В процессе работы над диалоговой системой (http://habrahabr.ru/post/235763/) мы столкнулись с непреодолимой, на первый взгляд, проблемой – в реальных, боевых условиях работы, производительность системы ASR оказывалась значительно ниже ожидаемой. Одним из компонентов, сказывающимся на производительности, неизменно оказывался шум на заднем фоне, принимающий самые разнообразные формы. Особенно неприятными для ASR в наших экспериментах были трудно-нейтрализуемые шум городской улицы и шум массовых скоплений людей.
Стало ясно, что проблему придется решить, или реальной ценности от голосовой системы просто не будет.
Изначальный план был простым – найти аналитическое решение для этих двух конкретных типов шума и нейтрализовать именно их. Но в процессе экспериментов с несколькими алгоритмами выяснилось, что, во-первых, голос достаточно сильно искажался, во-вторых, в нашей обучающей выборке типов шума оказалось сильно больше. Плюс к этому мы не хотели, чтобы (относительно) чистая речь как-либо модифицировалась, так как это негативно сказывалось на word error rate при распознавании.
Нужна была адаптивная схема.
Глубокие нейронные сети являются отличным решением в случаях, когда аналитическое решение для функции тяжело или невозможно подобрать. А мы хотели именно такую функцию – для трансформации зашумленного речевого сигнала в незашумленный. И вот что у нас получилось:
Мы пошли еще немного дальше и имплементировали сеть на комплексных числах. Идея сводится к тому, чтобы восстанавливать не только амплитуду, но и фазу, которую в противном случае приходится брать из зашумленного сигнала. А фаза из зашумленного сигнала негативно сказывается на качестве восстановленного звука, если его хочется затем услышать. Поэтому скоро у нас появится опция «высокое качество», за счет примерно 2-х-кратного замедления скорости обработки. Для использования в ASR смысла в ней, конечно же, нет.
Ну и через непродолжительное время мы перейдем на нашу новую рекуррентную модель, которая сможет похвастаться местами радикальным улучшением качества восстановленного голоса за счет существенного расширения области видимости. Относительно небольшой размер окна в текущей модели приводит к небольшим артефактам на переходах между разными типами шума, или когда профиль сигнала шума частично совпадает с профилем речи (ребенок плачет на заднем фоне).
Для желающих побаловаться с моделью – добро пожаловать к нам на сайт (http://sapiensapi.com/#speechapidemo). Там можно загрузить свой файл, взять готовый, зашумить или убрать шум из файла. Интерфейс достаточно прост.
Любителям API мы предлагаем бесплатный тестовый API через Mashape (http://www.mashape.com/tridemax/speechapi).
Если у вас есть какие-то вопросы – пишите мне на tridemax@sapiensapi.com, ну или же добро пожаловать в комментарии.
Стало ясно, что проблему придется решить, или реальной ценности от голосовой системы просто не будет.
Изначальный план был простым – найти аналитическое решение для этих двух конкретных типов шума и нейтрализовать именно их. Но в процессе экспериментов с несколькими алгоритмами выяснилось, что, во-первых, голос достаточно сильно искажался, во-вторых, в нашей обучающей выборке типов шума оказалось сильно больше. Плюс к этому мы не хотели, чтобы (относительно) чистая речь как-либо модифицировалась, так как это негативно сказывалось на word error rate при распознавании.
Нужна была адаптивная схема.
Глубокие нейронные сети являются отличным решением в случаях, когда аналитическое решение для функции тяжело или невозможно подобрать. А мы хотели именно такую функцию – для трансформации зашумленного речевого сигнала в незашумленный. И вот что у нас получилось:
- Модель работает до фильтр-банка. Альтернативой было шумоподавление после фильтр-банка (например в MEL-space), которое к тому же работало бы быстрее. Но мы хотели построить модель, которая будет работать и для материала, который затем должен слышать человек или внешние ASR системы. Таким образом мы можем очищать от шума любые голосовые потоки.
- Модель адаптивна. Убирает любые типы шума на заднем фоне, включая музыку, крики, проехавший мимо грузовик или шум циркулярной пилы, чем выгодно отличается от других коммерчески доступных систем. Но если сигнал не зашумлен, он практически не претерпевает изменений. Т.е. это speech enhancement модель – восстанавливает чистый голос из плохого сигнала. Одним из интересных дальнейших экспериментов будет способность подобной модели восстанавливать голос студийного качества из 8KHz в 44KHz. Многого мы не ждем, но возможно она нас удивит.
- Эта конкретная модель работает только с 8Khz. Связано это с тем, что на момент начала обучения у нас было множество 8KHz материала. Сейчас у нас уже достаточно материала в 44KHz и мы можем собрать любую модель, будь в этом необходимость. Пока же наша область интересов лежит в телекоммуникационном поле.
- Время обучения (после всех наших оптимизаций) – около двух недель на 40 ядрах. Первая версия тренировалась почти 2 месяца на том же оборудовании. Причем модель продолжает улучшать уровень ошибки на тестовых данных, поэтому мы еще ее потренируем.
- Скорость обработки на относительно современном процессоре сейчас около 20х от реального времени на одном ядре. 20-ти ядерный сервер с hyper-threading’ом может обрабатывать примерно 700 голосовых потоков одновременно, почти 90 Мбит/с в сырых данных.
Мы пошли еще немного дальше и имплементировали сеть на комплексных числах. Идея сводится к тому, чтобы восстанавливать не только амплитуду, но и фазу, которую в противном случае приходится брать из зашумленного сигнала. А фаза из зашумленного сигнала негативно сказывается на качестве восстановленного звука, если его хочется затем услышать. Поэтому скоро у нас появится опция «высокое качество», за счет примерно 2-х-кратного замедления скорости обработки. Для использования в ASR смысла в ней, конечно же, нет.
Ну и через непродолжительное время мы перейдем на нашу новую рекуррентную модель, которая сможет похвастаться местами радикальным улучшением качества восстановленного голоса за счет существенного расширения области видимости. Относительно небольшой размер окна в текущей модели приводит к небольшим артефактам на переходах между разными типами шума, или когда профиль сигнала шума частично совпадает с профилем речи (ребенок плачет на заднем фоне).
Хотелось бы показать несколько интересных картинок
Вход  Выход
Выход 
Вход Выход
Выход 
Вход Выход
Выход 
Вход Выход
Выход 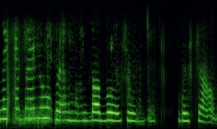
 Выход
Выход 
Вход
 Выход
Выход 
Вход
 Выход
Выход 
Вход
 Выход
Выход 
Для желающих побаловаться с моделью – добро пожаловать к нам на сайт (http://sapiensapi.com/#speechapidemo). Там можно загрузить свой файл, взять готовый, зашумить или убрать шум из файла. Интерфейс достаточно прост.
Любителям API мы предлагаем бесплатный тестовый API через Mashape (http://www.mashape.com/tridemax/speechapi).
Если у вас есть какие-то вопросы – пишите мне на tridemax@sapiensapi.com, ну или же добро пожаловать в комментарии.
