Comments 119
gulp-rigger — это просто киллер фича. Плагин позволяет импортировать один файл в другой простой конструкцией
круто, надо поробовать
В jade эту роль играет оператор include.
А лучше сразу начать использовать gulp-preprocess (grunt-preprocess).
блин, ведь это правда офигенно, например sass не умеет импортировать обычный css, приходилось делать concat и в gulpfile.js прописывать вендорские css руками
Оставлю тут плагин, который для себя делал, может пригодится
И в итоге получились rails assets pipeline :)
Rails assets pipeline который не привязан к Rails :)
Мам, смотри, Спрокетс для Ноды!
var gulp = require('gulp'),
watch = require('gulp-watch'),
prefixer = require('gulp-autoprefixer'),
uglify = require('gulp-uglify'),
cssmin = require('gulp-cssmin'),
sass = require('gulp-sass'),
sourcemaps = require('gulp-sourcemaps'),
rigger = require('gulp-rigger'),
imagemin = require('gulp-imagemin'),
pngquant = require('imagemin-pngquant'),
rimraf = require('rimraf'),
connect = require('gulp-connect'),
opn = require('opn');
Ещё рекомендую gulp-load-plugins. Тогда весь код выше заменяется строчкой:
var plugins = require('gulp-load-plugins')();
Соответственно плагины будут доступны как plugins.autoprefixer, plugins.sass и т.д.
В статье есть про это
+ новым разработчикам все таки проще с такой записью знакомиться. Конечно кода получается больше, но зато его понятность выше. Но это исключительно мое имхо, поэтому и отметил в статье про альтернативу
Конечно не обязательно делать это именно так. Существует плагин gulp-load-plugins который позволяет не писать всю эту лапшу из require. Но мне нравится когда я четко вижу что и где подключается, и при желании могу это отключить. По этому пишу по старинке.
+ новым разработчикам все таки проще с такой записью знакомиться. Конечно кода получается больше, но зато его понятность выше. Но это исключительно мое имхо, поэтому и отметил в статье про альтернативу
В этих строчках заключена ошибка:
<title>Я собираю проекты как рок звезда</title>
Недавно занимался настройкой окружения под себя и в итоге оформил это как npm-модуль с возможностью развернуть новый проект: fmp.
Разница с описанными вами процессами небольшая, только прикрутил возможность при создании нового поректа указать используемый css-препроцессор, мне приходится работать с разными, ну и еще по-мелочи. В ближайших планах — добавить вменяемый HTML-шаблонизатор с возможностью определять переменные на любом уровне и устанавливать их значение в подключающих файлах (смотрю в сторону Handlebars и Jade), минификацию файлов и еще мелочевок.
Разница с описанными вами процессами небольшая, только прикрутил возможность при создании нового поректа указать используемый css-препроцессор, мне приходится работать с разными, ну и еще по-мелочи. В ближайших планах — добавить вменяемый HTML-шаблонизатор с возможностью определять переменные на любом уровне и устанавливать их значение в подключающих файлах (смотрю в сторону Handlebars и Jade), минификацию файлов и еще мелочевок.
Вы не слышали про yeoman?
>…я и делаю это именно так, вместо того что бы попросить gulp найти все *.js файлы и склеить их.
Заметил, что gulp склеивает их (у меня) в алфавитном порядке. И пользуюсь этим.
>…при поиске места ошибки я по очереди выключаю какие то файлы из сборки…
Добавил правило — исключать из сборки файлы с префиксами "-" и "_". Соответственно, что бы исключить файл из сборки достаточно его переименовать.
Заметил, что gulp склеивает их (у меня) в алфавитном порядке. И пользуюсь этим.
>…при поиске места ошибки я по очереди выключаю какие то файлы из сборки…
Добавил правило — исключать из сборки файлы с префиксами "-" и "_". Соответственно, что бы исключить файл из сборки достаточно его переименовать.
1) Все верно, он склеивает в алфавитном порядке. Но это же не удобно. Хочется сохранить для себя свободу в именовании файлов.
2) Закоментировать строчку в rigger'e будет быстрей, чем переименовывать файл. Зачем лишние действия?
2) Закоментировать строчку в rigger'e будет быстрей, чем переименовывать файл. Зачем лишние действия?
>Но это же не удобно.
Наверное, тут скорее вопрос привычки/предпочтений.
Можно много чего придумать. Как вариант — делать обязательный префикс с нумерацией, с определённым шагом.
Файл же всё-равно копируется или сохраняется — на этих этапах и можно добавить префикс, после которого уже можно написать нечто осмысленное.
>Закоментировать строчку в rigger'e будет быстрей, чем переименовывать файл.
Мне кажется, что это от IDE больше зависит.
Для изменения порядка сборки вам приходится менять местами куски кода, тогда как в моём случае — опять же достаточно переименования.
Впрочем, я и не утверждаю, что мой способ всегда лучше. Он всего лишь удобнее для меня — не нужно прописывать каждый файл вручную, а порядок подключения виден в любом подобии файлового менеджера, где поддерживается сортировка по имени.
Наверное, тут скорее вопрос привычки/предпочтений.
Можно много чего придумать. Как вариант — делать обязательный префикс с нумерацией, с определённым шагом.
Файл же всё-равно копируется или сохраняется — на этих этапах и можно добавить префикс, после которого уже можно написать нечто осмысленное.
>Закоментировать строчку в rigger'e будет быстрей, чем переименовывать файл.
Мне кажется, что это от IDE больше зависит.
Для изменения порядка сборки вам приходится менять местами куски кода, тогда как в моём случае — опять же достаточно переименования.
Впрочем, я и не утверждаю, что мой способ всегда лучше. Он всего лишь удобнее для меня — не нужно прописывать каждый файл вручную, а порядок подключения виден в любом подобии файлового менеджера, где поддерживается сортировка по имени.
Вопрос — а почему для сборки в альтернативах вы не рассмотрели npm? Есть неплохая статья, сравнивающая gulp, grunt & npm. Я вот остановился на npm и остался просто в восторге от него.
Я думаю, что использовать специальный пакет — просто логичнее. Например gulp использует системы стримов, и файл пишется на диск только в самом конце, пройдя, зачастую, через несколько пайпов. В случае использования чистого npm придется все же что-то придумывать самому, так просто не получится.
Логично, да, но npm такой же специальный пакет, только нативный :)
Насчет стримов — смотрите, если вам нужны программные стримы, такие, как в gulp — можно пойти путем gulp, создать файл для сборки
Но на самом деле это все достаточно сложно для повседневных задач, и практически всегда можно обойтись тасками в
Чем это классно? У вас нет лишнего файла
Насчет стримов — смотрите, если вам нужны программные стримы, такие, как в gulp — можно пойти путем gulp, создать файл для сборки
build.js, где делать все, что угодно и как угодно, не ограничиваясь плагинами gulp, которые по сути обертки над пакетами npm. В том числе вы можете использовать и стримы, и gulp, и что угодно, без каких-либо ограничений.Но на самом деле это все достаточно сложно для повседневных задач, и практически всегда можно обойтись тасками в
"scripts" с нативными пайпами вместо стримов.Чем это классно? У вас нет лишнего файла
gulpfile.js в проекте; вы используете декларативную нотацию тасков, что весьма читабельно; новый пользователь может узнать все возможные операции для проекта прямо из package.json, в одном месте, что удобно; наконец, вы используете нативный инструмент, который гарантированно будет существовать долго и всегда включает все возможные пакеты, в отличие от систем сборки, где их может недоставать.Я с некоторых пор переехал на npm scripts и абсолютно с вами согласен — package.json это отличная точка входа, чтобы узнать о проекте всё, что нужно.
На самом деле используя gulp — вы можете все также использовать что угодно. Например browserify, или del. Этим он и отличается от grunt.
Пожалуйста расскажите мне, как вы с помощью scripts напишите следующий gulpfile:
И это только кусок для сборки less.
Пожалуйста расскажите мне, как вы с помощью scripts напишите следующий gulpfile:
var gulp = require('gulp');
var _if = require('gulp-if');
// опущу подключение остальных плагинов
var production = process.env.NODE_ENV === 'production';
gulp.task('less', function () {
gulp.src('src/less/**/*.less')
.pipe(plumber()) // не даем ошибкам всплывать
.pipe(_if(!production, sourcemaps.init())) // для сорсмепов в дев-режиме
.pipe(less()) // компилируем less
.pipe(autoprefixer()) // расставляем префиксы для браузеров
.pipe(_if(production, csso())) // в продакшене жмем
.pipe(_if(!production, sourcemaps.write())) // пишем сормепы в дев-режиме
.pipe(gulp.dest('public/css')) // пишем на диск
.pipe(_if(production, gzip())) // если продакшен - жмем gzip
.pipe(_if(production, gulp.dest('public/css'))) // и тоже записываем на диск
});
gulp.task('default', ['less'], function () {
gulp.watch('src/less/**/*.less', ['less']);
});
И это только кусок для сборки less.
Проще простого:
Хаха! :)
А если серьезно — вы правы, c globules это не так просто сделать, особенно на windows (я пытался, не получилось, на windows много ограничений в shell — нет xargs, нет подстановки комманд, нет globules, нет
Если же вам известны точки входа less, то все гораздо проще:
В принципе, в небольших проектах точки входа всегда известны. Если же проект гигантский, то тут уж ничего не поделаешь — надо писать скрипт сборки. Но это уже дело предпочтения — писать сборку через gulp или через простые стримы с прямыми зависимостями.
"scripts": {
"build": "node build.js",
"watch": "watch 'npm run build' ./src/**/*"
}
Хаха! :)
А если серьезно — вы правы, c globules это не так просто сделать, особенно на windows (я пытался, не получилось, на windows много ограничений в shell — нет xargs, нет подстановки комманд, нет globules, нет
find *.less -exec cat {} и тд и тп). В то же время на виндах и в gulp с globules не все гладко.Если же вам известны точки входа less, то все гораздо проще:
"scripts": {
"build-dev": "npm run lessc-dev && npm run build-js && cat public/css/*.css | gzip-size | pretty-bytes",
"lessc-dev": "lessc src/less/main.less --source-map | autoprefixer > public/css/main.css",
"lessc-production": "lessc src/less/main.less | autoprefixer | csso > public/css/main.css ",
"build-js": "browserify src/js/index.js | ccjs - > public/js/index.js",
"watch": "watch 'npm run lessc-dev' less/*.less"
...
}
В принципе, в небольших проектах точки входа всегда известны. Если же проект гигантский, то тут уж ничего не поделаешь — надо писать скрипт сборки. Но это уже дело предпочтения — писать сборку через gulp или через простые стримы с прямыми зависимостями.
с grunt нельзя? правда?
Скажите, зачем вам лишние проверки на енвайронмент, если они только усложняют логику сборки? Не проще ли сконфигурировать для каждого свой запуск если енвайронменты отличаются?
Скажите, зачем вам лишние проверки на енвайронмент, если они только усложняют логику сборки? Не проще ли сконфигурировать для каждого свой запуск если енвайронменты отличаются?
Нет, нельзя. В grunt вы пишите конфиг, а он отрабатывает. То есть шаг в лево-право — новый плагин. Тк gulp основан на нативных потоках, вы можете очень легко встроить свой обработчик посреди обработки любого файла.
Нет, не проще. Если я что-то могу сделать без дублирования кода — я стараюсь это сделать именно так.
Ну и грант с его устаревшей системой при каждом изменении файла запишет это изменение на диск. Круто!
Нет, не проще. Если я что-то могу сделать без дублирования кода — я стараюсь это сделать именно так.
Ну и грант с его устаревшей системой при каждом изменении файла запишет это изменение на диск. Круто!
jmreidy/grunt-browserify это вам к примеру. Не дублировать код — это прелестно, но писать почти в каждой строчке if'ы — гораздо хуже.
Кстати, насчет дублирования. Есть так называемое правило третьего, где рекомендуется фолдить клоны именно на третьем повторении. Почему не на втором — потому что два похожих куска еще не обязательно клоны, есть риск сфолдить преждевременно, потратив время впустую.
В вашем случае, для того, чтобы изменить девелоперский пайплайн — надо глазами пройтись по всему обобщенному пайплайну, на каждом условии вычислять, к
Я к тому, что у вас скорее не про дублирование, а про разделение ответственности.
В вашем случае, для того, чтобы изменить девелоперский пайплайн — надо глазами пройтись по всему обобщенному пайплайну, на каждом условии вычислять, к
dev или к production оно относится. А если появятся переменная ci? Я к тому, что у вас скорее не про дублирование, а про разделение ответственности.
Вместо gulp-connect удобнее пользоваться browsersync.
Оказывается, у Gulp есть чёрный список плагинов, и в нём, например, значатся gulp-connect и gulp-cssmin
Такой вопрос — стоит ли добавлять сборку (директория build/ в статье) под .gitignore?
Ведь при инициализации в любом случае сборка происходит заново.
Ведь при инициализации в любом случае сборка происходит заново.
Хочется вспомнить этот боянистый твит:
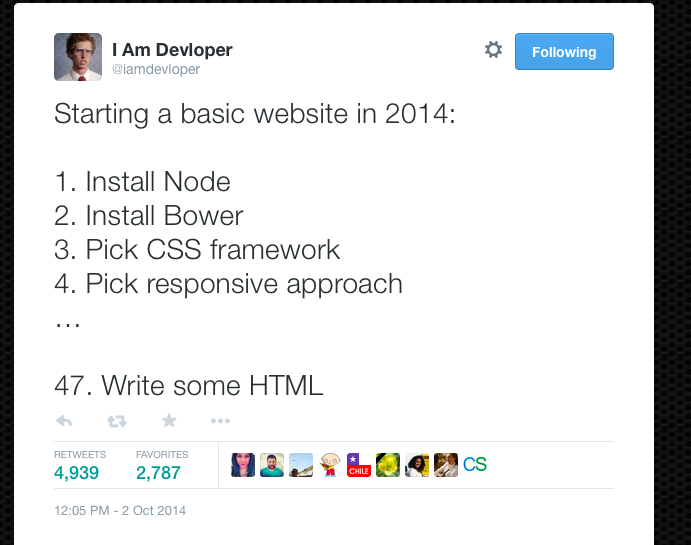
Но если честно сам пользуюсь и gulp, и grunt (разные проекты), вот только мне bower не зашел совсем — попытался, но это уже для меня перебор. Устанавливать JQuery через npm — перебор.
Может кто-нибудь кто пользуется разъяснит — в чем реальный смысл от него? Не хипстерства ради, а реальное применение, которое что-то облегчает.

Но если честно сам пользуюсь и gulp, и grunt (разные проекты), вот только мне bower не зашел совсем — попытался, но это уже для меня перебор. Устанавливать JQuery через npm — перебор.
Может кто-нибудь кто пользуется разъяснит — в чем реальный смысл от него? Не хипстерства ради, а реальное применение, которое что-то облегчает.
Пристрастился к bower после прочтения Bower: зачем фронтенду нужен менеджер пакетов.
Чем лезть на сайт и искать последнюю версию библиотеки, проще написать
Плюс, имея исходник в bower или npm, можно сделать свою сборку, взяв только нужные модули.
И более того, даже если не исключать ненужное, можно добиться меньшего размера при сборке.
Например, webpack рекомендует собирать reactjs из npm.
bower update jqueryПлюс, имея исходник в bower или npm, можно сделать свою сборку, взяв только нужные модули.
И более того, даже если не исключать ненужное, можно добиться меньшего размера при сборке.
Например, webpack рекомендует собирать reactjs из npm.
Собственно, управление зависимостями. Вы можете в bower.json указать конкретные версии библиотек от которых зависит ваше приложение. Можете даже указать конкретный коммит в GIT-репозитории (иногда бывает нужно и такое, когда, например, в какой-то из веток/пулл-реквестов есть фикс, но автор либы не спешит выпускать новую версию).
Указали — и всё, теперь одной командой можно выгрузить все зависимости. И скачаются именно те версии, с которыми ваше приложение точно работает.
В проект приходит новый разработчик — bower install и у него есть всё.
Собираем версию на продакшен — bower install, получили сборку с нужными зависимостям.
И да, если нужный вам пакет (bootstrap, например) зависит от другого (jquery в случае с бутстрапом), то Bower автоматически скачает зависимости.
Да, всё это будет не нужно, если вы будете ходить по сайтам, качать нужные версии и хранить их в репозитории. Но и обновление версий, и разрешение зависимостей — всё надо делать вручную. А это, в общем-то, довольно примитивная и нудная задача с которой лучше всего справляются машины.
Указали — и всё, теперь одной командой можно выгрузить все зависимости. И скачаются именно те версии, с которыми ваше приложение точно работает.
В проект приходит новый разработчик — bower install и у него есть всё.
Собираем версию на продакшен — bower install, получили сборку с нужными зависимостям.
И да, если нужный вам пакет (bootstrap, например) зависит от другого (jquery в случае с бутстрапом), то Bower автоматически скачает зависимости.
Да, всё это будет не нужно, если вы будете ходить по сайтам, качать нужные версии и хранить их в репозитории. Но и обновление версий, и разрешение зависимостей — всё надо делать вручную. А это, в общем-то, довольно примитивная и нудная задача с которой лучше всего справляются машины.
А если нету никаких зависимостей? Я пользуюсь как правило только Dojo и без особого труда контролирую её версию (и тащу её с CDN или кладу в git). Пока не очень понимаю необходимость такого нагромождения технологий для frontend. Frontend бывает разный и для разных нужд.
Очень напоминает бум батареек для Django или RoR, что в итоге ИМХО ни к чему хорошему не привело.
Очень напоминает бум батареек для Django или RoR, что в итоге ИМХО ни к чему хорошему не привело.
Если вы испольузуете модульность в JS с помощью browserify, например, то еще как имеет.
и потом
npm install jquery
и потом
var $ = require('jquery');
Не пойму, как собирать зависимости при помощи gulp-bower? Ведь просто вытаскивать по маске все js файлы не вариант, в пакетах обычно уже идут и минифицированные версии и исходники. Структура опять же везде разная.
Я использую такой скрипт:
где $ — ссылка на gulp-load-plugins, а manifestFilter — проверка для ускорения билда, что не добавились новые зависимости.
gulp.src('app/bower-manifest.html')
.pipe($.filter(manifestFilter))
.pipe(wiredep(wiredepConfig))
.pipe($.usemin({
js: [$.sourcemaps.init(), $.uglify(), $.rev(), $.sourcemaps.write('.')]
}))
где $ — ссылка на gulp-load-plugins, а manifestFilter — проверка для ускорения билда, что не добавились новые зависимости.
Спасибо за ответ, а за
В итоге накидал вот такой скрипт.
gulp-bower нужен для установки зависимостей. А для обработки зависимостей нужен (gulp-bower-files) main-bower-files
где $ — ссылка на gulp-load-pluginsотдельное спасибо.
В итоге накидал вот такой скрипт.
'use strict';
var gulp = require('gulp');
var plugins = require('gulp-load-plugins')({
pattern: ['gulp-*', 'main-*'] //это необходимо для плагина main-bower-files
});
var path = {
build: {
js: 'dist/js'
}
};
//установка зависимостей
gulp.task('bower', function() {
return plugins.bower();
});
//сборка зависимостей
gulp.task("bower-files", function(){
gulp.src(plugins.mainBowerFiles())
.pipe(plugins.uglify())
.pipe(plugins.concat('all.js'))
.pipe(gulp.dest(path.build.js))
});
gulp-bower нужен для установки зависимостей. А для обработки зависимостей нужен (
Пока не понял только, как бы последовательно запустить эти две задачи)
Еще раз отвечу сам себе, авось кому сгодится — www.npmjs.com/package/run-sequence
У вас нет сортировки зависимости, например, поставить jquery или angularjs первым.
Вот накидал свой велосипед на эту тему:
gist.github.com/dshster/2535b4317e495d070bcb
Вот накидал свой велосипед на эту тему:
gist.github.com/dshster/2535b4317e495d070bcb
Я правильно понял, в данном примере $.order(['angular/*.js'… ставит на первое место соответственно angular, затем все остальные в случайном порядке?
Как-то это все не то :) Вот и получается, что самый просто выход, это как автор, прописывать очередность в main.js
Как-то это все не то :) Вот и получается, что самый просто выход, это как автор, прописывать очередность в main.js
Попробуйте wiredep. Он должен сам правильно разруливать зависимости
в нем есть одна проблема — wiredep будет генерировать новые теги script и link для всех библиотек. На деве это конечно не страшно, но на прод так пускать нельзя. В итоге придется для прода все равно собирать все в один файл, и скорее всего — это придется делать похожим способом, как в статье. Так что проще один раз прописать это дело и забыть как страшный сон :)
Варианты? Во-первых не нужно прописывать все модули, нужно прописать только те, которые строго должны идти в первую очередь. Я не смог добиться, чтобы main-bower-files выводил в том порядке в котором прописаны в bower.json.
Даже если в консоли выполнить команду bower list -p, то порядок вывода модулей будет другой.
Даже если в консоли выполнить команду bower list -p, то порядок вывода модулей будет другой.
main-bower-files выдает файлы из пакетов, уже отсортированных согласно дереву зависимостей («dependencies» в bower.json пакета).
Но еще один просто огромный плюс main-bower-files это то, что он может использовать секцию «overrides» в bower.json, чтобы переопределить описание установленного пакета.
Вот пример:
Предположим, что пакет some-another-package использует jquery, но в зависимостях у него он не прописан.
Тогда при обработке main-bower-files его файлы могут выпасть перед файлами jquery и будет у нас красная консоль.
Мы принудительно указываем ему зависимость от jquery и также можем указать разные файлы пакета для разных версий сборки (версию сборки можно указать при вызове mainBowerFiles() в скрипте.
И исходя из всего вышенаписанного открывается еще одна невиданная доселе возможность: указать в качестве зависимости любой файл из git-репозитория, впоследстии описав его зависимости, после чего он будет обработан mainBowerFiles() и включен в проект в правильном месте. Вот «живой» пример:
Само собой, это грязный трюк — завтра реп могут благополучно грохнуть, но иногда он выручает просто безмерно.
Но еще один просто огромный плюс main-bower-files это то, что он может использовать секцию «overrides» в bower.json, чтобы переопределить описание установленного пакета.
Вот пример:
"dependencies": {
"angular": "1.3.13",
"jquery":"1.2.2",
"some-another-package": "0.0.1"
},
"overrides": {
"some-another-package": {
"dependencies": {
"jquery": "*"
},
"main": {
"development": ["some-another-package.js"],
"production": ["some-another-package.min.js"],
}
}
}
Предположим, что пакет some-another-package использует jquery, но в зависимостях у него он не прописан.
Тогда при обработке main-bower-files его файлы могут выпасть перед файлами jquery и будет у нас красная консоль.
Мы принудительно указываем ему зависимость от jquery и также можем указать разные файлы пакета для разных версий сборки (версию сборки можно указать при вызове mainBowerFiles() в скрипте.
И исходя из всего вышенаписанного открывается еще одна невиданная доселе возможность: указать в качестве зависимости любой файл из git-репозитория, впоследстии описав его зависимости, после чего он будет обработан mainBowerFiles() и включен в проект в правильном месте. Вот «живой» пример:
"dependencies": {
...
"flot-splines": "https://raw.githubusercontent.com/AMKohn/flot/master/jquery.flot.spline.js",
...
},
...
"overrides": {
"flot-splines": {
"main": [
"index.js"
],
"dependencies": {
"flot": "*"
}
}
}
Само собой, это грязный трюк — завтра реп могут благополучно грохнуть, но иногда он выручает просто безмерно.
Странно, что не используется ничего для AMD модулей.
Ну и спорный вопрос насчет необходимости Bower. Достаточно долго живем только c npm проблем нет пока, у нас часть кода шарится между клиентом и сервером. При использовании Bower это бы только добавило проблем.
Ну и спорный вопрос насчет необходимости Bower. Достаточно долго живем только c npm проблем нет пока, у нас часть кода шарится между клиентом и сервером. При использовании Bower это бы только добавило проблем.
AMD модули уже не вымирании.
с чего это вдруг?
С чего это вдруг что?
С чего это вдруг сейчас или вопрос о фундаментальных причинах вымирания AMD?
С чего это вдруг сейчас или вопрос о фундаментальных причинах вымирания AMD?
Давайте перейдем сразу к фундаментальным причинам.
Человек стремится делать проще и красивее.
Ну и на замену amd приходит System, это факт. А на замену common, возможно, es-modules.
// amd
define(['./foo', './bar'], (foo, bar) => {
console.log({foo, bar});
});
// common
var foo = require('./foo');
var bar = require('./bar');
console.log({foo, bar});
Ну и на замену amd приходит System, это факт. А на замену common, возможно, es-modules.
Модули решают проблему модульности. Все 3 стандарта (ES6H, CJS, AMD) по сути себя дублируют.
Разработчики обращаются к модулям для реализации более сложных задач. Для этого они в своем арсенале используют сборщики, препроцессоры, автоматические тесты и т.д.
И вопрос, к примеру, AMD vs CJS это уже просто выбор сахара. А сахар CJS слаще.
А любой транспайлер/сборщик сделает модули удобные для платформы.
Тем более сборщикам и остальным инструментам проще работать с CJS.
К примеру webpack. Он может «подключать» .less в файл .stylus обычным require.
«everything is a module»
CJS стал де факто стандартом nodejs. ES6H станет стандартом для нода и веба. И AMD тут места нет.
Он просто стал не нужен как стандарт. Как техника экспорта/компиляции/транспайлинга ок. Но не стандарт.
Разработчики обращаются к модулям для реализации более сложных задач. Для этого они в своем арсенале используют сборщики, препроцессоры, автоматические тесты и т.д.
И вопрос, к примеру, AMD vs CJS это уже просто выбор сахара. А сахар CJS слаще.
А любой транспайлер/сборщик сделает модули удобные для платформы.
Тем более сборщикам и остальным инструментам проще работать с CJS.
К примеру webpack. Он может «подключать» .less в файл .stylus обычным require.
«everything is a module»
CJS стал де факто стандартом nodejs. ES6H станет стандартом для нода и веба. И AMD тут места нет.
Он просто стал не нужен как стандарт. Как техника экспорта/компиляции/транспайлинга ок. Но не стандарт.
Я ошибался. Думал, что AMD это общее описание принципа модульной загрузки скриптов (особенно, если учесть что requirejs поддерживает и commonjs формат). Поэтому оригинальный вопрос стоит читать как «Странно, что не используется ничего для JS-модулей»
Да, в такой формулировке +100500.
Вам может быть интересно видео:
OSCON 2014: How Instagram.com Works; Pete Hunt
Смотреть с 25 минуты
Вам может быть интересно видео:
OSCON 2014: How Instagram.com Works; Pete Hunt
Смотреть с 25 минуты
Есть разница в подключении зависимостей Bower и NPM, последний для каждого модуля создаёт свою копию зависимостей, Bower — использует общие зависимости. Это сделано для того, чтобы не было ситуации с подключением одновременно разных версий jquery, например.
Половину хлама можно выбросить если использовать webpack для зависимостей.
А что потом происходит с этой папкой build, как она попадает на продакшен? Ее прямо в git/whatever коммитят, или же на продакшене запускается тот же самый скрипт сборки после обновления исходников?
В списке не хватает плагина для создания спрайтов.
UFO just landed and posted this here
Мода это конечно круто, но можно узнать, в чем выигрыш кодирования в dataurl? Сборка спрайтов у меня происходит автоматически через spritesmith, на выходе less файл с переменными названий спрайтов. Сам графический файл со спрайтами кешируется.
Не заметил этой моды. В основном встречаю спрайты или svg. При использовании плагинов для генерации спрайтов, удобство от использования dataURI совсем сомнительно, к тому же отдельная css с dataURI весит в полтора раза больше, чем спрайт.
к тому же отдельная css с dataURI весит в полтора раза больше, чем спрайт
Может это потому что в png применяется сжатие по умолчанию, а для css оно применится только при передаче по сети?
Что-то я очень сомневаюсь что закодированный в Base64 сжатый PNG еще сожмётся при передаче, иначе был бы нехилый профит.
Провел эксперимент, с картинкой png (этой: xkcd.com/1445/)
Размер: 11 597 байт,
В архиве: 11 613 байт
В виде строки base64
Размер: 15 464 байт
В архиве: 11 694 байт
Разница после gzip менее процента.
Попробовал поменять архиватор, тенденция сохранилась.
PS: на всякий случай прогнал картинку через punypng: No savings
Размер: 11 597 байт,
В архиве: 11 613 байт
В виде строки base64
Размер: 15 464 байт
В архиве: 11 694 байт
Разница после gzip менее процента.
Попробовал поменять архиватор, тенденция сохранилась.
PS: на всякий случай прогнал картинку через punypng: No savings
Другими словами смысла в экономии трафика никакого. В оптимизации автоматизации тоже выигрыша нет, осталось выяснить скорость рендеринга тысячи спрайтов в виде одной картинки или в виде отдельных dataurl.
В плане удобства — каждому свое.
Мне, например, нравится base64, тем что:
* его можно использовать в виде повторяющегося фона
* не нужен отдельный элемент для иконки
* base64 делается нажатием одной кнопки и без настроек — можно обойтись без сборки вообще, используя онлайн-декодер
* удаление иконки происходит так же просто как удаление класса из css
* добавление одной иконки никак не повлияет на другие. Со спрайтом вполне может произойти так, что неопытный специалист добавит что-то свое, пережмет из png-24 в png-8, и не заметит что стало хуже.
В общем, по мне baseurl проще. А значит, при прочих равных — лучше.
Мне, например, нравится base64, тем что:
* его можно использовать в виде повторяющегося фона
* не нужен отдельный элемент для иконки
<i class="icon"></i>* base64 делается нажатием одной кнопки и без настроек — можно обойтись без сборки вообще, используя онлайн-декодер
* удаление иконки происходит так же просто как удаление класса из css
* добавление одной иконки никак не повлияет на другие. Со спрайтом вполне может произойти так, что неопытный специалист добавит что-то свое, пережмет из png-24 в png-8, и не заметит что стало хуже.
В общем, по мне baseurl проще. А значит, при прочих равных — лучше.
Использую spritesmish
> не нужен отдельный элемент для иконки
Всё уже давно делают через псевдоклассы
> base64 делается нажатием одной кнопки и без настроек — можно обойтись без сборки вообще, используя онлайн-декодер
> удаление иконки происходит так же просто как удаление класса из css
Я кидаю иконку в папку иконок и вообще ничего не делаю дальше (bower сам подхватывает и перекодирует), в вашем же случае нужно искать css файл, искать класс нужный, менять его даже с автоматическим кодированием или удалять, а если файл довольно объёмный, то и редактор будет неспешно работать
Последний пункт вообще не актуальный. Единственный минус это первый пункт с повторяющимся фоном, но на практике уже давно не сталкивался когда мне нужно положить на фон графическую текстуру — градиенты и тени делаются через css, а большие изображения в спрайты не вношу.
В общем на мой взгляд надуманные проблемы, которые уже давно нормально решены.
> не нужен отдельный элемент для иконки
Всё уже давно делают через псевдоклассы
> base64 делается нажатием одной кнопки и без настроек — можно обойтись без сборки вообще, используя онлайн-декодер
> удаление иконки происходит так же просто как удаление класса из css
Я кидаю иконку в папку иконок и вообще ничего не делаю дальше (bower сам подхватывает и перекодирует), в вашем же случае нужно искать css файл, искать класс нужный, менять его даже с автоматическим кодированием или удалять, а если файл довольно объёмный, то и редактор будет неспешно работать
Последний пункт вообще не актуальный. Единственный минус это первый пункт с повторяющимся фоном, но на практике уже давно не сталкивался когда мне нужно положить на фон графическую текстуру — градиенты и тени делаются через css, а большие изображения в спрайты не вношу.
В общем на мой взгляд надуманные проблемы, которые уже давно нормально решены.
Система сборки это не преимущество спрайтов, для base64 все так же настраивается.
Что есть такого у спрайтов, чтобы их до сих пор использовать?
PS: забыл упомянуть — встраивать через data:url можно и jpeg и анимированный gif.
Что есть такого у спрайтов, чтобы их до сих пор использовать?
PS: забыл упомянуть — встраивать через data:url можно и jpeg и анимированный gif.
UFO just landed and posted this here
В теории (сейчас лень проверять) data-uri сделает из изображения base64.
Следовательно размер увеличится на 1/3 с копейками.
С другой стороны, если картинка не очень оптимизированна, то gzip должен выдать меньший результат.
Однако моя интуиция не верна:
davidbcalhoun.com/2011/when-to-base64-encode-images-and-when-not-to/
TL;DR. gzip+base64 дает тот же размер что и бинарка
Выводы очевидны
Следовательно размер увеличится на 1/3 с копейками.
С другой стороны, если картинка не очень оптимизированна, то gzip должен выдать меньший результат.
Однако моя интуиция не верна:
davidbcalhoun.com/2011/when-to-base64-encode-images-and-when-not-to/
TL;DR. gzip+base64 дает тот же размер что и бинарка
Выводы очевидны
«gulp-rigger» — насколько это тормозит сборку, файлы все-таки должны парсится?
LibSass всем хорош, только больно уж отстаёт от основной ветки. В итоге часть самых вкусностей не работает.
Нашёл для себя в качестве альтернативы Stylus, который:
а) нативный,
б) довольно быстрый,
в) более гибкий.
Рекомендую.
Нашёл для себя в качестве альтернативы Stylus, который:
а) нативный,
б) довольно быстрый,
в) более гибкий.
Рекомендую.
Недавно делал нечто подобное, но без bower (мне не нравится, что bower тянет за собой содержимое всего репозитория вместо одного js-файла) и с шаблонизатором Handlebars (ведь даже на фронте часто проще заполнять пространство в цикле, например, а не писать голый html). Так же livereload работает веселее — он не перегружает всю страницу, если изменены стили, а только перегружает сами стили. Ну и я использовал grunt, хотя можно попробовать и на gulp перейти.
Ну и вообще у меня как-то попроще получилось, хотя вроде все примерно то же самое)
Вот, если кому интересно — github.com/mrTimofey/boilerplate
Ну и вообще у меня как-то попроще получилось, хотя вроде все примерно то же самое)
Вот, если кому интересно — github.com/mrTimofey/boilerplate
Очень странный довод в пользу отказа от Bower — выше уже всё обсудили много раз. Вообще не важно в каком виде тянутся bower-модули, из них вы собираете общий js/css файл, а всё остальное можно поместить в .gitignore. Зато при каждом разворачивании проекта у вас нужный набор всех зависимостей. Вместо Handlebars я предпочитаю Jade.
Если у вас есть общий шаблон, на этом шаблоне построена куча сайтов и в какой-то библиотеке шаблона найдена уязвимость, то вам придётся ручками обновлять библиотеку на каждом сайте. Если сайтов 10, 20, 50 и они на разных хостингах, представьте сколько времени вам понадобиться чтобы обновить библиотеку? В общем тут только поможет опыт коллективной разработки сайтов чуть серьёзнее домашней странички.
Если у вас есть общий шаблон, на этом шаблоне построена куча сайтов и в какой-то библиотеке шаблона найдена уязвимость, то вам придётся ручками обновлять библиотеку на каждом сайте. Если сайтов 10, 20, 50 и они на разных хостингах, представьте сколько времени вам понадобиться чтобы обновить библиотеку? В общем тут только поможет опыт коллективной разработки сайтов чуть серьёзнее домашней странички.
Насчет Bower согласен. Стоит его добавить. Но жалко, конечно, что нельзя только нужный файл тянуть… Точнее, я читал, что как-то можно, но это будет не универсально, так как структура файлов проектов не у всех одинаковая.
Jade — да, я его тоже пробовал на этом же boilerplate. Очень удобно, но его можно легко поставить вместо HB добавлением зависимости в package и небольшой правкой кода в engine.js (собственно, для этого я и вынес код для шаблонизатора в отдельный файл). Нужно будет поправить документацию с учетом возможности ставить свой шаблонизатор.
Jade — да, я его тоже пробовал на этом же boilerplate. Очень удобно, но его можно легко поставить вместо HB добавлением зависимости в package и небольшой правкой кода в engine.js (собственно, для этого я и вынес код для шаблонизатора в отдельный файл). Нужно будет поправить документацию с учетом возможности ставить свой шаблонизатор.
Если хотите устанавливать через bower только самые нужные файлы, можно использовать bower-installer: github.com/blittle/bower-installer
Чтобы что, просто интересно? «ignore» в конфиге со стандартными настройками вполне хватает, мне кажется.
Я лишь предложил решение проблемы, описанной mr_T. Так-то, мне тоже вполне достаточно «ignore» в конфиге)
Вдруг кому-то еще для быстрого старта и ознакомления пригодится мой конфиг Gulp-а с комментариями на русском для каждой задачи.
В прошлом году познакомил с Gulp-ом коллег и некоторые уже активно используют, да и мне легче передавать проект.
В прошлом году познакомил с Gulp-ом коллег и некоторые уже активно используют, да и мне легче передавать проект.
здорово по моему
Обратил внимание, что генерируемый gulp-sourcemaps файл просто огромен (x10 от размера минифицированного файла). В опциях плагина ничего про сжатие карты не нашел, как победить такую ситуацию? И может быть, можно как-то ограничить пользователей от загрузки .map файла, он ведь им по факту не нужен?
Может простой вопрос, но всё же:
почему пути src и watch отличаются?
При том, что watch в итоге запускает билд по src.
почему пути src и watch отличаются?
При том, что watch в итоге запускает билд по src.
у вас никогда не возникало проблем с количеством файлов?
использовал ваш код, но с .pipe(reload({stream: true})); картинок копировалось только 48 штук (проверено много раз, и на файлах шрифтов, html файлы не проверял)
пришлось заменить на .on('end', browserSync.reload);, стали копироваться все
использовал ваш код, но с .pipe(reload({stream: true})); картинок копировалось только 48 штук (проверено много раз, и на файлах шрифтов, html файлы не проверял)
пришлось заменить на .on('end', browserSync.reload);, стали копироваться все

По умолчанию файлы собираются и минифицируются. А как добавлять не минифицированные файлы?
Sign up to leave a comment.
Приятная сборка frontend проекта