Comments 41
так была изобретена технология снепшотирования COW. Отличие этой технологии заключается в основном в том, что все другие файловые системы, как правило, не обладали встроенным механизмом записи «в новое место»,
О каких именно файловых системах в контексте СХД идет речь? Обычно СХД в своей основе — блочные устройства, и снэпшоты делаются на уровне блоков.
Чем больше таких снепшотов тем больше дополнительных паразитических операций
Можете пояснить этот момент? Насколько я понимаю, при CoW делается копия блока, в который ведется запись, в количестве одной штуки, сколько бы там снэпшотов ни было. Какие дополнительные операции будут при большом числе снэпшотов (при условии, что работаем мы, как правило, все же с последней копией, а не со всем деревом)?
Ещё вопрос — на томе кончилось место, что будет происходить со снэпшотами в WAFL?
Что же касательно «когда закончиться место на WAFL», не понял вопроса. Если место закончилось со снепшотами ничего происходить не будет…
Поясняю. Допустим, у нас есть система с CoW. Мы сделали очередной снэпшот. Идет-идет запись, и тут место под снэпшот кончается. Последствия — дальше снэпшот не пишется, запись на основной LUN как шла, так и идет.
Теперь мы обнаруживаем ту же ситуацию, но при алгоритме «всегда в новое место» — «нового места» для записи нового блока нет. Что будет происходить?
Теперь мы обнаруживаем ту же ситуацию, но при алгоритме «всегда в новое место» — «нового места» для записи нового блока нет. Что будет происходить?
Если вы сравниваете ситуацию с «нового места» у вас нет, то сравнивайте её с тем, что его нет и для вашего LUN на CoW иначе это не корректное сравнение.
Здесь нужно разделить ситуацию на два момента: используется ли thing provisioning или не используется.
Если thing Provisioning не используется, то ситуация «со снепшотами у нетапа», будет аналогична — лун будет продолжать работать, а снепшоты не смогут сниматься.
Вопрос со снепшотами нетапа более комплексный на самом деле.
Так к примеру если включить на вольюме механизм Snapshot Autodelete, он будет удалять старые снепшоты, перед тем как снять новые если место закончилось.
Если thing Provisioning не используется, то ситуация «со снепшотами у нетапа», будет аналогична — лун будет продолжать работать, а снепшоты не смогут сниматься.
Вопрос со снепшотами нетапа более комплексный на самом деле.
Так к примеру если включить на вольюме механизм Snapshot Autodelete, он будет удалять старые снепшоты, перед тем как снять новые если место закончилось.
Стоит также отметить, что системы с CoW часто требуют специально выделенной области под снепшоты, жестко заданного размера.
Т.е. использует ваш снепшот этот резерв, не использует или использует не на полную — не важно — место зарезервировано.
В то время, как снепшоты нетапа вовсе не требуют наличия заранее заданного пространства. Если лун у нас толстый, а для снепшота не хватает пространства он не снимиться, запуститься механизм (если включён) автоудаления снепшотов (гибко настраивается). Это не задействованное пространство может быть использовано, к примеру под снепшоты от другого вольюма (которому это может быть «больше нужно»), это определённая гибкость и экономия.
Т.е. использует ваш снепшот этот резерв, не использует или использует не на полную — не важно — место зарезервировано.
В то время, как снепшоты нетапа вовсе не требуют наличия заранее заданного пространства. Если лун у нас толстый, а для снепшота не хватает пространства он не снимиться, запуститься механизм (если включён) автоудаления снепшотов (гибко настраивается). Это не задействованное пространство может быть использовано, к примеру под снепшоты от другого вольюма (которому это может быть «больше нужно»), это определённая гибкость и экономия.
COW это стратегия, которая может применяться как на блочных устройствах так и н файловых системах.
Момент заключается в том, что когда мы имеем один снепшот, то данные которые к нему относяться в первоначальный момент остаются на своих местах и ещё не перемещены в «резерв». Это отложенное действие которое будет выполнено только с теми данными, к оторым будет обрашение на перезапись и только в тот момент они начнут копироваться, когда это обращение произойдёт (иначе снепшот снимался бы слишком долго). Типа pay-as-you-go.
Вот теперь представьте у вас есть первый снепшот, идут операции перезаписи, которые время от времени попадают на старые блоки данных из снепшота, это генерирует дополнительные операции на перенос этих данных. Теперь представьте что таких снапшотов два, три и т.д, каждый такой снепшот — и всё по-новому. Чем интенсивнее перезапись данных (которые попадают на блоки в снепшотах, ещё не перенесённых в резерв), тем больше паразитических операций. Чем больше снепшотов, тем больше вероятность, что такие данные будут относиться к снепшоту и ещё не будут перенесены.
Каждая операция записи при попадании на блок из снепшота будет генерировать дополнительную операцию на чтение старого блока и записи старого блока в новое место (резерв). Таким образом вместо одной операции имеем три.
В высоконагруженных системах типа Баз Данных это будет носить наиболее выраженный неприятный эффект: блоки обычно маленькие 8KB разбросаны то там то тут, а средний показатель перезаписи 30-50%. На вращающихся жестких дисках операции поиска будут занимать много времени + дополнительные две операции (тоже мелкими блоками) и соответственно сразу будут увеличиваться латенси, что для высоконагруженных систем, как паравило, очень заметно.
Многие производители пытаются оптимизировать эти операции различными путями (заранее залаживая больше производительности, добавляя кеши, оптимизируя чтение и запись), но архитектура COW изначально была создана с изъяном и по-прежнему достаточно сильно влияют на производительность.
Момент заключается в том, что когда мы имеем один снепшот, то данные которые к нему относяться в первоначальный момент остаются на своих местах и ещё не перемещены в «резерв». Это отложенное действие которое будет выполнено только с теми данными, к оторым будет обрашение на перезапись и только в тот момент они начнут копироваться, когда это обращение произойдёт (иначе снепшот снимался бы слишком долго). Типа pay-as-you-go.
Вот теперь представьте у вас есть первый снепшот, идут операции перезаписи, которые время от времени попадают на старые блоки данных из снепшота, это генерирует дополнительные операции на перенос этих данных. Теперь представьте что таких снапшотов два, три и т.д, каждый такой снепшот — и всё по-новому. Чем интенсивнее перезапись данных (которые попадают на блоки в снепшотах, ещё не перенесённых в резерв), тем больше паразитических операций. Чем больше снепшотов, тем больше вероятность, что такие данные будут относиться к снепшоту и ещё не будут перенесены.
Каждая операция записи при попадании на блок из снепшота будет генерировать дополнительную операцию на чтение старого блока и записи старого блока в новое место (резерв). Таким образом вместо одной операции имеем три.
В высоконагруженных системах типа Баз Данных это будет носить наиболее выраженный неприятный эффект: блоки обычно маленькие 8KB разбросаны то там то тут, а средний показатель перезаписи 30-50%. На вращающихся жестких дисках операции поиска будут занимать много времени + дополнительные две операции (тоже мелкими блоками) и соответственно сразу будут увеличиваться латенси, что для высоконагруженных систем, как паравило, очень заметно.
Многие производители пытаются оптимизировать эти операции различными путями (заранее залаживая больше производительности, добавляя кеши, оптимизируя чтение и запись), но архитектура COW изначально была создана с изъяном и по-прежнему достаточно сильно влияют на производительность.
Статья несет в себе массу полезной информации. Но к сожалению создает впечатление, что только NetApp использует подход RoW (Redirect of Write), а все остальные производители живут все еще в XX веке и используют подход CoW (Copy on Write). Вернее мне кажется более правильной аббревиатура CoFW (Copy on First Write), так как она более точно отображает суть процесса.
На самом деле все давно не так. И реализация снапшотинга через механизм RoW встречается во многих решениях. Как софтовых (Н-р: снапшоты у VMWare или работа Windows Shadow Services у мелкомягких), так и в хардварных.
При этом тот же механизм снапшотинга RoW имеет также свое негативное влияние на системы в целом и на их производительность. Но размер этого влияния во много раз меньше, чем при использовании старого механизма CoW/CoFW. Нет ничего совершенного в этом мире.
На самом деле все давно не так. И реализация снапшотинга через механизм RoW встречается во многих решениях. Как софтовых (Н-р: снапшоты у VMWare или работа Windows Shadow Services у мелкомягких), так и в хардварных.
При этом тот же механизм снапшотинга RoW имеет также свое негативное влияние на системы в целом и на их производительность. Но размер этого влияния во много раз меньше, чем при использовании старого механизма CoW/CoFW. Нет ничего совершенного в этом мире.
Вы могли бы привести ссылки на счёт VMware. Был уверен, что VMWare испоьзует CoW. В любом случае, по-факту снепшоты VMWare тормозят виртуалки, это также сказано во всех документах онного — не использовать снепшоты на высоконагруженных системах и во многих других случаях.
На нетапе по-факту снепшоты не тормозят систему вообще. Это вам подтвердит любой владелец FAS системы.
На нетапе по-факту снепшоты не тормозят систему вообще. Это вам подтвердит любой владелец FAS системы.
Вы ошиблись на счёт VMWare.
В версии ESXi 5.5. используются именно CoW снепшоты.
В версии ESXi 5.5. используются именно CoW снепшоты.
Вчитайтесь еще раз в приведенный вами документ по VMWare. При снятии снапшота исходный «vmdk» файл «замораживается» для изменений. То есть операции записи на него больше не идут. Его блоки ни в какую отдельную резервную область не копируются перед изменением. Где тут CoW по вашему? Все новые записи и записи меняющие существующие блоки перенаправляются в новый созданный на том же DataStore файл «delta.vmdk». Ни чего не напоминает? Да детали реализации у разных производителей отличаются, но все же это механизм и идеология RoW.
За счет этого возврат к снапшоту — это так же просто отмена использования ссылок на блоки delta файла. Т.е. происходит «мгновенно». Естественно виртуалку для этого нужно предварительно выключить.
Проблемы с производительностью заснапшченных виртуалок на VMware есть — это верно. Но тут дело больше реализации механизмов работы самого vmkernel с уже созданными снапшотами (в том числе операция поиска наиболее актуальной версии блока для операций чтения), а не в механизме создания этих снапшотов. Я уже писал «Нет ничего совершенного в этом мире». ;)
Снапшоты у NetApp имеют свои минусы, насколько мне известно (дело не в производительности). Но устраивать холивары не вижу смысла.
За счет этого возврат к снапшоту — это так же просто отмена использования ссылок на блоки delta файла. Т.е. происходит «мгновенно». Естественно виртуалку для этого нужно предварительно выключить.
Проблемы с производительностью заснапшченных виртуалок на VMware есть — это верно. Но тут дело больше реализации механизмов работы самого vmkernel с уже созданными снапшотами (в том числе операция поиска наиболее актуальной версии блока для операций чтения), а не в механизме создания этих снапшотов. Я уже писал «Нет ничего совершенного в этом мире». ;)
Снапшоты у NetApp имеют свои минусы, насколько мне известно (дело не в производительности). Но устраивать холивары не вижу смысла.
По-моему вполне даже CoW: именно необходимость в поиске «актуальной версии» это и есть признак того что это CoW
Холивар устраивать не нужно, но конструктивно подискутировать я не против.
Это как раз то место, где о снепшотах можно дискутировать.
Что именно, по-вашему, относится к недостаткам снепшотов на нетапе? Лично мне об онных ничего не изветно.
Это как раз то место, где о снепшотах можно дискутировать.
Что именно, по-вашему, относится к недостаткам снепшотов на нетапе? Лично мне об онных ничего не изветно.
Ок, постараемся не уходить в холивар :). Сразу оговорюсь, что искренее считаю NetApp одним из технологических лидеров и инноваторов на рынке систем хранения данных. Но меня всегда улыбают попытки какого либо из вендоров сказать, что мы лучше всех и мы одни тут такие. Особенно когда это приобретает форму «Все п......., а я — д'Артаньян» :). На самом деле просто не принято говорить о минусах своих решений и это вполне объяснимо и даже наверно по человечески нормально.
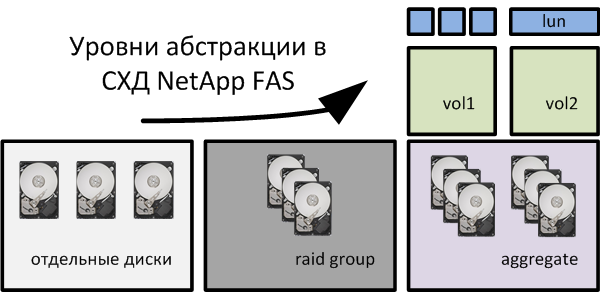
Теперь по существу. Я не являюсь человеком глубоко подкованным в технических особенностях СХД компании NetApp и могу ошибаться. Но насколько понимаю snapshots у NetApp делаются на уровне так называемых «flex volume». А луны при этом создаются «уровнем ниже». Т.е. пространство в flex volume разбивается на LUN-ы. Соответственно луны (блочные устройства) уже могут быть отданы различным серверам (потребителям).
twistedminds.ru/wp-content/uploads/2012/06/netapp.png
Соответственно при создании снапшота на flex volume начинают отслеживаться изменения по всем лунам на данном flex volume. А не потому единственному луну, где лежит например база MS SQL и который необходимо консистентно бэкапить. Получается перерасход диского пространства на хранение измененных блоков всех остальных лунов, для которых в данный конкретный момент снапшотинг не нужен. Если я не прав, давно все изменилось и работает совершенно не так, то поправьте меня пожалуйста.
Теперь по существу. Я не являюсь человеком глубоко подкованным в технических особенностях СХД компании NetApp и могу ошибаться. Но насколько понимаю snapshots у NetApp делаются на уровне так называемых «flex volume». А луны при этом создаются «уровнем ниже». Т.е. пространство в flex volume разбивается на LUN-ы. Соответственно луны (блочные устройства) уже могут быть отданы различным серверам (потребителям).
twistedminds.ru/wp-content/uploads/2012/06/netapp.png
{kind=link}
Соответственно при создании снапшота на flex volume начинают отслеживаться изменения по всем лунам на данном flex volume. А не потому единственному луну, где лежит например база MS SQL и который необходимо консистентно бэкапить. Получается перерасход диского пространства на хранение измененных блоков всех остальных лунов, для которых в данный конкретный момент снапшотинг не нужен. Если я не прав, давно все изменилось и работает совершенно не так, то поправьте меня пожалуйста.
Вы правы, именно из-за этого у нетапа есть рекомендация хранить один лун на одном вольюме.
При необходимости поддерживаются Snapshot Consistency Groups — снятие снепшота _одновременно_ на нескольких вольюмах, даже если они находятся на разных контроллерах. Так что с этим можно легко и не принуждённо жить.
Возможно эта ситуация как-то измениться с vVol, пока не знаю.
При необходимости поддерживаются Snapshot Consistency Groups — снятие снепшота _одновременно_ на нескольких вольюмах, даже если они находятся на разных контроллерах. Так что с этим можно легко и не принуждённо жить.
Возможно эта ситуация как-то измениться с vVol, пока не знаю.
Надо учитывать, что рекомендация «1vol — 1lun» так же снижает эффективность расхода места, ведь дедупликация действует веутри каждого тома отдельно.
Так что если решулярные изменения не перепахиют половину данных, я бы забил на потери на снапшоты (они-то дедуплицируются) и клал сходные виртуалки на один vol.
Тем более, что восстанавливать из снапшотов их можно по-отдельности.
Так что если решулярные изменения не перепахиют половину данных, я бы забил на потери на снапшоты (они-то дедуплицируются) и клал сходные виртуалки на один vol.
Тем более, что восстанавливать из снапшотов их можно по-отдельности.
Пшш, с мобилки грамотность -1.
Кстати, обычно снапшоты нужны сразу на все луны, так что проблема не частая.
Кстати, обычно снапшоты нужны сразу на все луны, так что проблема не частая.
Тут я бы не согласился. Зачем мне снапшоты сразу на всю ферму серверов с разными OS (условно лежащих на одном агрегате), если в конкретный момент времени мне нужно сделать только консистентный бэкап MS Exchange. Не забываем что снапшот «не равно» полная резервная копия.
Ну, совсем разные OS можно по разным вольюмам бить.
А чем консистентный снапшот отличается от бэкапа, кроме места хранения?
Кстати, на эту вот тему:
к одному серваку HyperV я не смог подключить два клона LUN-а одновременно.
Видимо потому, что у них совпадал Lun ID или что-нибудь в этом роде.
по очереди подключались без проблем.
А чем консистентный снапшот отличается от бэкапа, кроме места хранения?
Кстати, на эту вот тему:
к одному серваку HyperV я не смог подключить два клона LUN-а одновременно.
Видимо потому, что у них совпадал Lun ID или что-нибудь в этом роде.
по очереди подключались без проблем.
Тут нужно уже смотреть реализацию конкретного вендора и конкретной СХД. При нормальном подходе снапшоты и клоны томов должны подключаться даже к исходному серверу как отдельные логические тома имеющие собственный HostID, а соответственно и отличную от исходной букву диска или точку монтирования.
Снапшот и бэкап (резервная копия) — это вообще разные сущности.
Снапшот — это замороженное на конкретную точку во времени состояние системы.
Консистентный снапшот — это снапшот, гарантирующий целостность данных в данной точке во времени. В частности, для того что бы сделать консистентный снапшот FS, необходимо заставить операционную систему выполнить синхронизацию всех кэшированных в оперативной памяти данных на дисковое устройство (или LUN), затем приостановить ввод/вывод на это устройство и только после этого можно создать снапшот. А затем уже разморозить ввод/вывод на диск.
Если снапшот неконсистнтный, то мы получаем состояние системы в нем примерно такое же, как если бы у сервера выключили питание на входе. То есть операционка после восстановления с такого снапшота имеет шансы «не взлететь». А если на томе была база данных, то вообще есть вероятность с ней попрощаться.
Бэкап или резервная копия данных — это отдельная полная копия данных, с которой мы можем восстановиться в том числе и на другое железо. Очень удобно делать бэкап используя как источник консистентный снапшот данных. Это позволяет не беспокоиться о том, что в процессе, например двухчасового копирования данных, данные продолжают изменяться. Так как сервисы работают и продолжают что-то писать. То есть данные даже в процессе самого бэкапа могут изменяться и в итоге мы можем получить неконсистентую резервную копию.
Поэтому сннапшотинг и бэкап — это вещи, которые очень удачно могут дополнять друг друга. Но снапшоты — это ни в коем случае не бэкап, так они не защищают от потери исходных блоков данных. А копию бэкапов в идеале необходимо хранить на удаленной площадке.
Снапшот и бэкап (резервная копия) — это вообще разные сущности.
Снапшот — это замороженное на конкретную точку во времени состояние системы.
Консистентный снапшот — это снапшот, гарантирующий целостность данных в данной точке во времени. В частности, для того что бы сделать консистентный снапшот FS, необходимо заставить операционную систему выполнить синхронизацию всех кэшированных в оперативной памяти данных на дисковое устройство (или LUN), затем приостановить ввод/вывод на это устройство и только после этого можно создать снапшот. А затем уже разморозить ввод/вывод на диск.
Если снапшот неконсистнтный, то мы получаем состояние системы в нем примерно такое же, как если бы у сервера выключили питание на входе. То есть операционка после восстановления с такого снапшота имеет шансы «не взлететь». А если на томе была база данных, то вообще есть вероятность с ней попрощаться.
Бэкап или резервная копия данных — это отдельная полная копия данных, с которой мы можем восстановиться в том числе и на другое железо. Очень удобно делать бэкап используя как источник консистентный снапшот данных. Это позволяет не беспокоиться о том, что в процессе, например двухчасового копирования данных, данные продолжают изменяться. Так как сервисы работают и продолжают что-то писать. То есть данные даже в процессе самого бэкапа могут изменяться и в итоге мы можем получить неконсистентую резервную копию.
Поэтому сннапшотинг и бэкап — это вещи, которые очень удачно могут дополнять друг друга. Но снапшоты — это ни в коем случае не бэкап, так они не защищают от потери исходных блоков данных. А копию бэкапов в идеале необходимо хранить на удаленной площадке.
Ещё как бекап. Я вам целую статью наваял, а вы снова за своё.
Чтобы классический бекап снять, а потом мочь его восстановить, он тоже должен быть консистентный.
А вопрос «проблемы с другим железом», описан в моём предыдущем коментарии.
Реализация деталей у разных вендоров разная на всех уровнях: на уровне архитектуры самой СХД, на уровне ОС, на уровне фич и патентов, на уровне рейда и т.д. И у каждого вендора видение свое как что реализовать. Так у нетапа локальный снепшот это бекап не защищающий от физического повреждения (защиту обеспечивает сама СХД рейдом, HA и т.д.). А отреплицированный снепшот это полноценный бекап с как это себе «видит» нетап.
У нетапа многие вещи «не стандартно» реализованы, вы просто наверное, не работали с нетапом, так сказать в продакшн, вот тогда бы вы поняли, что детали реализации не важны — важен результат.
И миеть локальный бекап который может быть восстановлен за одну минуту, на продакшн, это очень удобно. Потому что бухгалтерша чаще допускает ошибки, нежели происходит потом или пожар.
Чтобы классический бекап снять, а потом мочь его восстановить, он тоже должен быть консистентный.
А вопрос «проблемы с другим железом», описан в моём предыдущем коментарии.
Реализация деталей у разных вендоров разная на всех уровнях: на уровне архитектуры самой СХД, на уровне ОС, на уровне фич и патентов, на уровне рейда и т.д. И у каждого вендора видение свое как что реализовать. Так у нетапа локальный снепшот это бекап не защищающий от физического повреждения (защиту обеспечивает сама СХД рейдом, HA и т.д.). А отреплицированный снепшот это полноценный бекап с как это себе «видит» нетап.
У нетапа многие вещи «не стандартно» реализованы, вы просто наверное, не работали с нетапом, так сказать в продакшн, вот тогда бы вы поняли, что детали реализации не важны — важен результат.
И миеть локальный бекап который может быть восстановлен за одну минуту, на продакшн, это очень удобно. Потому что бухгалтерша чаще допускает ошибки, нежели происходит потом или пожар.
Согласен в том плане, что копия всей виртуалки — это далеко не выгруженная база 1с-ки или бэкап SQL-я.
их можно восстановить не только на другое железо, но и, что важнее, на другую OS.
А из снапшота сперва надо выдрать базу.
их можно восстановить не только на другое железо, но и, что важнее, на другую OS.
А из снапшота сперва надо выдрать базу.
Удачный пример :).
Вопрос в «чем консистентный снапшот отличается от бэкапа, кроме места хранения?» я надеюсь у вас тоже отпал? :)
Вопрос в «чем консистентный снапшот отличается от бэкапа, кроме места хранения?» я надеюсь у вас тоже отпал? :)
В моём следующем, за этим, посте про Архитектуру резервного копирования NetApp рассказано как на основе SnapProtect получить всё тоже самое на основе консистентного снепшота.
Т.е. SnapProtect/SnapManager не просто сделает консистентный снепшот виртуалки, но и базы данных которая в ней живёт. А дальше при помощи, к примеру RMAN'а (точно также как если бы это был класический бекап), без каких-либо промежуточных «выдираний» базы данных из виртуального диска восстановить эти данные в новое место: на новое железо с новой ОС. Или при помощи мастера SnapProtect/SnapManager.
Т.е. SnapProtect/SnapManager не просто сделает консистентный снепшот виртуалки, но и базы данных которая в ней живёт. А дальше при помощи, к примеру RMAN'а (точно также как если бы это был класический бекап), без каких-либо промежуточных «выдираний» базы данных из виртуального диска восстановить эти данные в новое место: на новое железо с новой ОС. Или при помощи мастера SnapProtect/SnapManager.
По большому счёту локальные снепшоты это полноценные бекапы, которые не защищают от физического повреждения СХД.
Тем не мение они прекрастно справляются с восстановлением нечаянно изменённых/удалённых данных, к примеру пользователем или вирусом — т.е. от логической ошибки, логического повреждения.
А чтобы защититься, в том числе, и от физического повреждения, нужно эти снепшоты выносить на другую площадку. Так вот на удалённой площадке те же самые снепшоты уже самые полноценные бекапы.
Тем не мение они прекрастно справляются с восстановлением нечаянно изменённых/удалённых данных, к примеру пользователем или вирусом — т.е. от логической ошибки, логического повреждения.
А чтобы защититься, в том числе, и от физического повреждения, нужно эти снепшоты выносить на другую площадку. Так вот на удалённой площадке те же самые снепшоты уже самые полноценные бекапы.
Полноценные бэкапы — это все же отдельные физические копии данных, размещенные на другом устройстве хранения (в идеале на удаленной площадке), с которыми не работаю в онлайне никакие боевые сервисы и которые можно восстановить в том числе на другое железо. Другой сервер, диски, СХД и т.д.
Это у нас уже полемика пошла.
1) я же сказал, полноценные бекапы — это снепшоты на удалённой системе.
2) восстановить можно на третий, четвертый и т.д. сайт (с нетапом)
3) Если используется OSSV или SPOS можно восстанавливать данные «не на нетап».
4) у SnapProtect есть такая штука позволяющая энд юзеру бекапить и восстанавливать свои данные из ноутбука (т.е. данные живущие не на нетапе), называется Web Console.
А по поводу «отдельности бекапов», то в таком случае не вижу большой разницы между отдельной ленточной кассетой со сжатым бекапом и снепшотом.
Снепшот это полноценная полная файловая система на момент как она была зафиксирована. А если вы намекаете на то, что снепшоты могут как-то повредиться, то во-первых есть механизм проверки чексумм и восстановления при помощи RAID (чего нет у ленточных кассет), а во-вторых мне лично не известны такие случаи.
1) я же сказал, полноценные бекапы — это снепшоты на удалённой системе.
2) восстановить можно на третий, четвертый и т.д. сайт (с нетапом)
3) Если используется OSSV или SPOS можно восстанавливать данные «не на нетап».
4) у SnapProtect есть такая штука позволяющая энд юзеру бекапить и восстанавливать свои данные из ноутбука (т.е. данные живущие не на нетапе), называется Web Console.
А по поводу «отдельности бекапов», то в таком случае не вижу большой разницы между отдельной ленточной кассетой со сжатым бекапом и снепшотом.
Снепшот это полноценная полная файловая система на момент как она была зафиксирована. А если вы намекаете на то, что снепшоты могут как-то повредиться, то во-первых есть механизм проверки чексумм и восстановления при помощи RAID (чего нет у ленточных кассет), а во-вторых мне лично не известны такие случаи.
Да ладно вам полемика :).
Ленты я тоже не жалую :). Лучше отдельное дисковое устройство, можно не очень дорогое но с Raid6 :). Я уже писал: " не являюсь человеком глубоко подкованным в технических особенностях СХД компании NetApp и могу ошибаться" :).
Если рассматривать концепцию и идеологию снапшотинга в общем. То снапшот — это не бэкап. В том числе потому что поврежедение исходных данных приведет к порче всех сделанных в последствии снапшотов, безотносительно вендоров и конкретных реализаций процесса. А в данном случае декларируя, что в случае NetApp конечный пользователь может не делать бэкапов, а пользовать только снапшотинг, вы на мой взгляд несколько дезинформируете неокрепшие умы.
Я не спорю, что зареплицированные на удаленный сайт снапшоты могут считаться полноценным бэкапом. Особенно если есть инструментарий, позволяющий с этим удобно работать (объектное восстановление отдельных писем или файлов и т.д.). В общем все зависит от конкретной реализации. И в ваш случай с NetApp — это скорее частная реализация. Но в целом картины мира это не меняет. Еще раз снапшотинг — это не замена резервному копированию данных.
Ленты я тоже не жалую :). Лучше отдельное дисковое устройство, можно не очень дорогое но с Raid6 :). Я уже писал: " не являюсь человеком глубоко подкованным в технических особенностях СХД компании NetApp и могу ошибаться" :).
Если рассматривать концепцию и идеологию снапшотинга в общем. То снапшот — это не бэкап. В том числе потому что поврежедение исходных данных приведет к порче всех сделанных в последствии снапшотов, безотносительно вендоров и конкретных реализаций процесса. А в данном случае декларируя, что в случае NetApp конечный пользователь может не делать бэкапов, а пользовать только снапшотинг, вы на мой взгляд несколько дезинформируете неокрепшие умы.
Я не спорю, что зареплицированные на удаленный сайт снапшоты могут считаться полноценным бэкапом. Особенно если есть инструментарий, позволяющий с этим удобно работать (объектное восстановление отдельных писем или файлов и т.д.). В общем все зависит от конкретной реализации. И в ваш случай с NetApp — это скорее частная реализация. Но в целом картины мира это не меняет. Еще раз снапшотинг — это не замена резервному копированию данных.
Так вот дьявол кроется в деталях ;)
Нетап первый реализовал технологию снепшотинга и за 1993-2015=23 года развил и довел их до ума.
По поводу дезинформации, я нигде не писал «про снепшоты в общем», здесь конкретно речь про снепшоты NetApp и конкретно на системах FAS — посмотрите заглавие статьи.
Нетап первый реализовал технологию снепшотинга и за 1993-2015=23 года развил и довел их до ума.
По поводу дезинформации, я нигде не писал «про снепшоты в общем», здесь конкретно речь про снепшоты NetApp и конкретно на системах FAS — посмотрите заглавие статьи.
Когда я писал про дезу :) имелись в виду утверждения в комментариях.
В частности:
«По большому счёту локальные снепшоты это полноценные бекапы, которые не защищают от физического повреждения СХД.»
Вот тут дъявол и селиться :). Полноценные бэкапы — это резервные копии, защищенные от физического или логического повреждения исходных данных. И никак иначе.
В частности:
«По большому счёту локальные снепшоты это полноценные бекапы, которые не защищают от физического повреждения СХД.»
Вот тут дъявол и селиться :). Полноценные бэкапы — это резервные копии, защищенные от физического или логического повреждения исходных данных. И никак иначе.
Вы почему-то ошибочно подумали, что я пишу «про картину мира в целом», хотя я уже не в первый коммент пытаюсь вам донести, что не веду речи «за жизнь в целом», а конкретно только про NetApp FAS.
Ещё раз, всё ниже сказанное касается только NetApp FAS
Итак подрезюмировав:
Так вот эти две вещи прекрастно дополняют друг друга и сосуществуют вместе.
Ещё раз, всё ниже сказанное касается только NetApp FAS
- Снепшот вынесенный на удалённую площадку, с точки зрения нетапа — полноценный бекап.
- Локальный снепшот это тот же бекап, не защищающий от выхода из строя оборудования — защита выполнена на уровне отказоустойчивости и дублирования компонент СХД, RAID. Такой локальный снепшот это тот же бекап защищающий от логической ошибки но при этом с возможностью моментального восстановления с точки зрения NetApp.
Итак подрезюмировав:
- Отреплицированный бекап будет восстанавливаться дольше, но он защищён от катастроф.
- Локальный бекап не защищён от катастроф, защищет от выхода из строя некоторых компонент СХД (не всей СХД в целом), но может быть моментально восстановлен.
Так вот эти две вещи прекрастно дополняют друг друга и сосуществуют вместе.
В принципе да, можно было бы получить и большую степень дедубликации если всё ложить в один вольюм. Хотя даже в рамках одного луна может быть много повторяющейся информации. Но здесь я бы предлажыл рассмотреть не «ситуацию в общем», а с конкретикой.
В каких случаях нужно ложить один лун на один вольюм? Самый частый случай это базы данных. Сами по себе базы данных практически не дедублицируемы. Так что вопрос сам собой отпадает.
А когда всё можно ложить в одну корзину? К примеру в случае с виртуализацией иметь кучу виртуалок на одном датасторе который живёт на одном луне. Процесс восстановления отдельной виртуалки можно выполнить через медиа-агент примапив к нему снепшот нетапа. А вот если иметь датастор на NFS шаре, то медиа агент совсем не нужен, так как поддерживается пофайловое восстановление из снепшота при помощи SnapRestore. И здесь опять вопрос с дедубликацией снимается сам по себе.
В каких случаях нужно ложить один лун на один вольюм? Самый частый случай это базы данных. Сами по себе базы данных практически не дедублицируемы. Так что вопрос сам собой отпадает.
А когда всё можно ложить в одну корзину? К примеру в случае с виртуализацией иметь кучу виртуалок на одном датасторе который живёт на одном луне. Процесс восстановления отдельной виртуалки можно выполнить через медиа-агент примапив к нему снепшот нетапа. А вот если иметь датастор на NFS шаре, то медиа агент совсем не нужен, так как поддерживается пофайловое восстановление из снепшота при помощи SnapRestore. И здесь опять вопрос с дедубликацией снимается сам по себе.
Я предпочёл каждую виртуалку хранить на своём луне, но все луны на одном вольюме.
Так проще откатывать виртуалки по-отдельности.
Жалко, что дедупликацию нельзя включить на агрегат.
Она же всё равно блочная а не файловая!
Так проще откатывать виртуалки по-отдельности.
Жалко, что дедупликацию нельзя включить на агрегат.
Она же всё равно блочная а не файловая!
А бд, например, эксченджа не дедуплицируется?
Там же куча одинаковой инфы в письмах…
Или там сжатие встроенное…
Там же куча одинаковой инфы в письмах…
Или там сжатие встроенное…
Sign up to leave a comment.
Парадигма резервного копирования NetApp