Добрый день.
Примерно 2 недели назад наш мониторинг тул (NewRelic) начал детектить большое количество падений сайта продолжительностью не более 1 минуты, но с очень большой частотой. Помимо этого визуально было заметно, что общая производительность веб-приложения (Umbraco 6.1.6, .net 4.0) упала.
Красные полосы на картинке — это и есть наши падения.
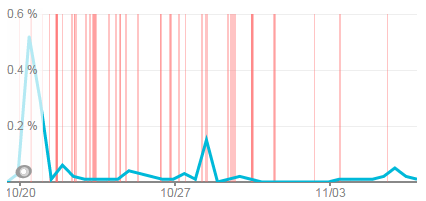
Да, оговорюсь. Перед тем, как мы это все заметили, новый модуль для блога был установлен и соответственно блог компании был мигрирован из Worldpress в Umbraco.
В итоге у нас есть следующие входные данные: приложение стало хранить больше данных (намного больше) + был установлен сторонний модуль = High CPU.
Перед тем, как начать исследование, было решено проверить Googe Analytics, чтобы убедиться, что количество пользователей не изменилось (итог — все было как и прежде) + было решено произвести нагрузочное тестирование — определить пропускную способность.
Тут нас ожидало полное разочарование, наше приложение умирало при 30 одновременных сессий. Сайт через браузер не открывался вообще. И это был продакшен.
1. Устанавливаем его на продакшен сервер.
2. Запускаем, создаем новое правило с типом «Performance».
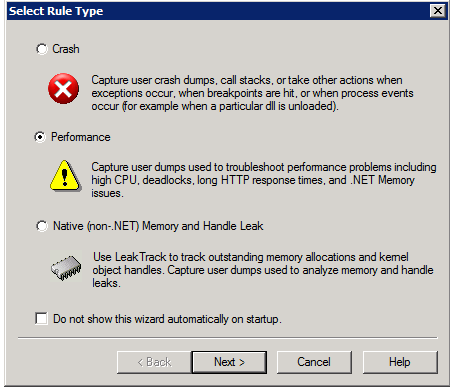
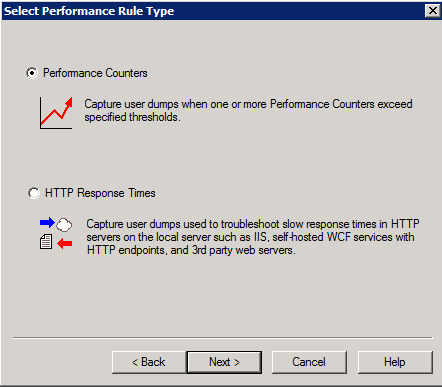
3. Указываем, что дампы должны собираться используя Performance Counters.
4. В нашем случае выбираем % Processor Time, порог — 80%, продолжительностью — 15 секунд.
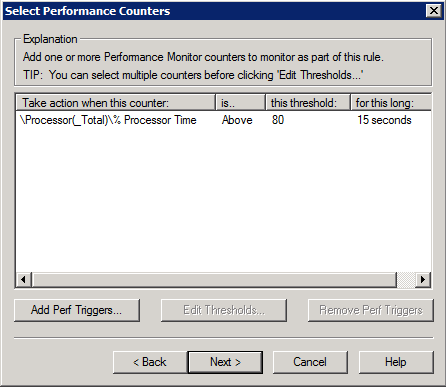
Это означает что, дампы будут собираться, если CPU загружен более чем на 80% в течение 15 секунд.
5. Изучаем результаты
То, на что нужно обратить внимание, выделено красными прямоугольниками.
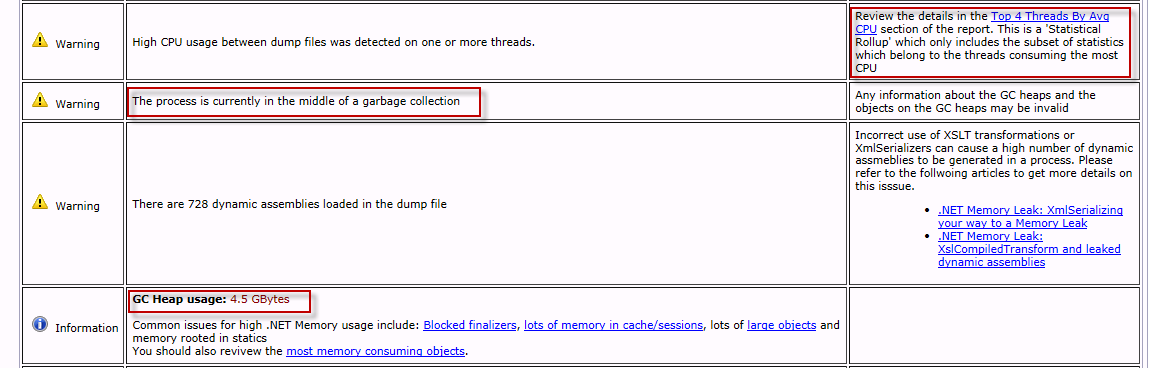

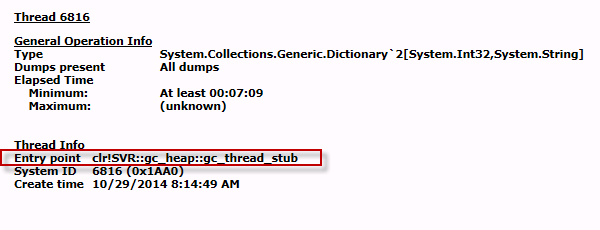
А именно:
Тут я хотел бы обратить внимание на то, что сама проблема кроется не в GC, а в том, что неправильное выделение памяти заставляет его работать таким образом.
В GC, наиболее трудоемкой является сборка мусора поколения Gen 2 (что вызывает, соответственно, сборку Gen 1 и Gen 0). Так же у каждого поколения есть свой порог, превысив который сборка мусора будет автоматически запускаться. А это означает, чем чаще превышается порог, тем чаще сборка мусора будет запускаться.
Небольшой пример:
Допустим порог поколения Gen 2: 300 MB
За одну секунду GC может очистить: 100 MB (Gen 2)
Каждый новый пользователь в секунду приводит к выделению: 10 MB (в Gen 2)
Если у нас 10 пользователей, то 10 * 10 = 100 MB, следовательно проблем нету.
Если у нас 40 пользователей, то ежесекундно выделяется 400 MB, что вызывает сборку сумора (порог превышен), и так по нарастающей.
То есть, чем больше пользователей, тем больше памяти выделяется (по нарастающей), тем чаще вызывается сборка мусора с большим интервалом времени на сборку.
В .net 4.0, когда запускается сборка мусора, всем потокам GC присваивается максимальный приоритет. Это означает, что все ресурсы сервера будут направлены на сборку мусора и, помимо этого, все остальные потоки (обрабатывающие входящие запросы) будут временно приостановлены до момента, пока сборка мусора не закончится. Это и есть причина, почему cервер никак не отвечал на запросы даже при неполной загрузке.
Для этого я использовал dotMemory в качестве профайлера памяти.
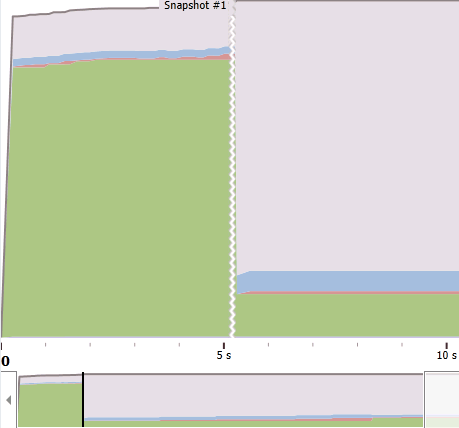
Запускаем под нагрузкой dotMemory и пытаемся сделать снимок памяти, когда её обьем начинает сильно расти. (Зеленая зона на изображении ниже — Gen 2.)
Далее приступаем к анализу снимка.
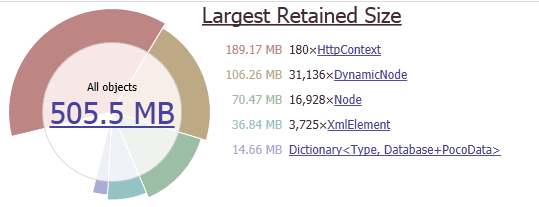
Наибольший обьем в памяти занимают HttpContext, DynanicNode, Node.
HttpContext исключаем, так как в нем хранятся ссылки на объекты DynanicNode и Node.
Далее проведем группировку по поколениям, так как нам нужны объекты только поколения Gen 2.
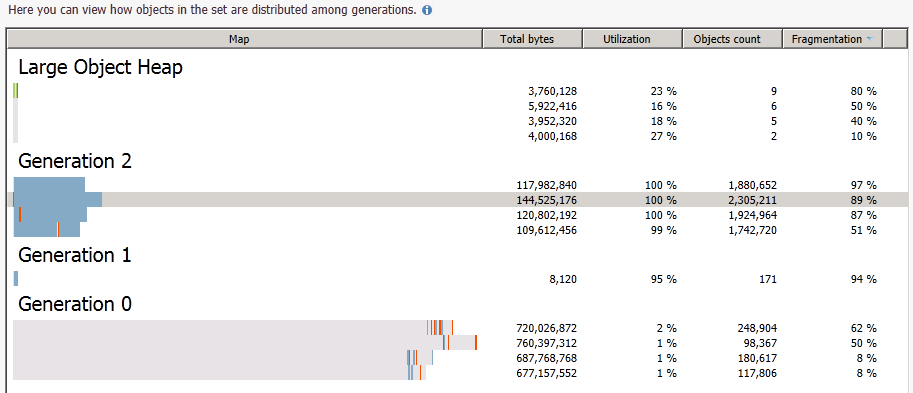
В поколении Gen 2 опять производим группировку по домминаторам.

Это позволяет 100 % найти нужные объекты, которые занимают наибольшее количество памяти. После нужно поработать с конкретным экземплярам объекта, чтобы определить, что это за объект (id, свойства и т.д.)
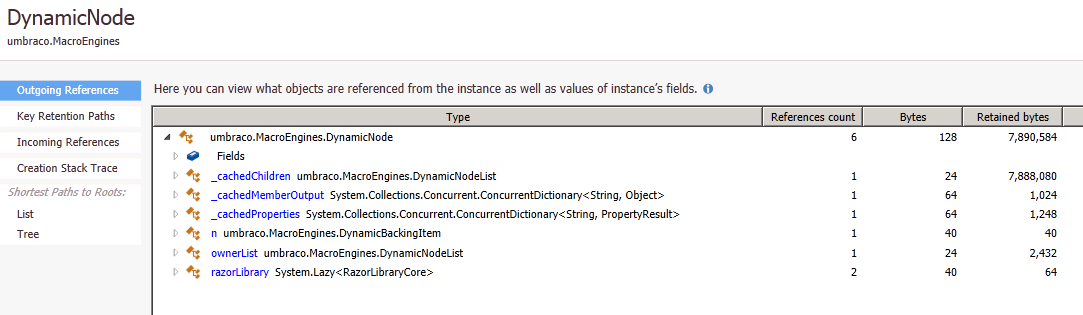
В этот момент стало понятно, какие данные являются источником проблемы, осталось только найти место, где они создаются и пофиксить.
Следовательно, сам фикс проблемы заключался в замене метода isAncestor на нашу собственную реализацию + применение OutputCache к нашему контролу.
— High CPU — это не только рекурсия или большая нагрузка, но и GC;
— Создание объектов должно быть обдуманным и соответствовать архитектуре приложения;
— Output cache — всегда и везде;
— Все, что не видно при обычном тестировании, проявится при нагрузочном!
И на заметку:
На момент написания статьи NewRelic не помог мне выловить источник High CPU, зато performance counter % Time in GC без труда указал на источник проблемы.
Если на графике пики CPU растут в соответствии с пиками графика % Time in GC и значение % Time in GC выше линии 20%, => High CPU из-за сборщика мусора.
Спасибо за внимание. Надеюсь было интересно.
Примерно 2 недели назад наш мониторинг тул (NewRelic) начал детектить большое количество падений сайта продолжительностью не более 1 минуты, но с очень большой частотой. Помимо этого визуально было заметно, что общая производительность веб-приложения (Umbraco 6.1.6, .net 4.0) упала.
Красные полосы на картинке — это и есть наши падения.

Да, оговорюсь. Перед тем, как мы это все заметили, новый модуль для блога был установлен и соответственно блог компании был мигрирован из Worldpress в Umbraco.
В итоге у нас есть следующие входные данные: приложение стало хранить больше данных (намного больше) + был установлен сторонний модуль = High CPU.
В путь
Перед тем, как начать исследование, было решено проверить Googe Analytics, чтобы убедиться, что количество пользователей не изменилось (итог — все было как и прежде) + было решено произвести нагрузочное тестирование — определить пропускную способность.
Тут нас ожидало полное разочарование, наше приложение умирало при 30 одновременных сессий. Сайт через браузер не открывался вообще. И это был продакшен.
Шаг 1 — собрать дампы производительности под нагрузкой, используя Debug Diagnostics tools
1. Устанавливаем его на продакшен сервер.
2. Запускаем, создаем новое правило с типом «Performance».

3. Указываем, что дампы должны собираться используя Performance Counters.

4. В нашем случае выбираем % Processor Time, порог — 80%, продолжительностью — 15 секунд.

Это означает что, дампы будут собираться, если CPU загружен более чем на 80% в течение 15 секунд.
5. Изучаем результаты
То, на что нужно обратить внимание, выделено красными прямоугольниками.



А именно:
- На момент сборки дампов Garbage Collector был запущен (поначалу я не придал этому внимания);
- Очень большой размер кучи;
- Все 4 потока принадлежат Garbage Collector и съедают 100% CPU.
Тут я хотел бы обратить внимание на то, что сама проблема кроется не в GC, а в том, что неправильное выделение памяти заставляет его работать таким образом.
Немного теории
В GC, наиболее трудоемкой является сборка мусора поколения Gen 2 (что вызывает, соответственно, сборку Gen 1 и Gen 0). Так же у каждого поколения есть свой порог, превысив который сборка мусора будет автоматически запускаться. А это означает, чем чаще превышается порог, тем чаще сборка мусора будет запускаться.
Небольшой пример:
Допустим порог поколения Gen 2: 300 MB
За одну секунду GC может очистить: 100 MB (Gen 2)
Каждый новый пользователь в секунду приводит к выделению: 10 MB (в Gen 2)
Если у нас 10 пользователей, то 10 * 10 = 100 MB, следовательно проблем нету.
Если у нас 40 пользователей, то ежесекундно выделяется 400 MB, что вызывает сборку сумора (порог превышен), и так по нарастающей.
То есть, чем больше пользователей, тем больше памяти выделяется (по нарастающей), тем чаще вызывается сборка мусора с большим интервалом времени на сборку.
В .net 4.0, когда запускается сборка мусора, всем потокам GC присваивается максимальный приоритет. Это означает, что все ресурсы сервера будут направлены на сборку мусора и, помимо этого, все остальные потоки (обрабатывающие входящие запросы) будут временно приостановлены до момента, пока сборка мусора не закончится. Это и есть причина, почему cервер никак не отвечал на запросы даже при неполной загрузке.
Следовательно, можно сделать вывод: причиной является некорректное выделение большого объёма памяти за короткие промежутки времени. Чтобы решить проблему, необходимо найти, где у нас в коде так называемые memory leaks.
Шаг 2 — поиск объектов. которые занимают больше всего памяти (Memory Profiling)
Для этого я использовал dotMemory в качестве профайлера памяти.
Запускаем под нагрузкой dotMemory и пытаемся сделать снимок памяти, когда её обьем начинает сильно расти. (Зеленая зона на изображении ниже — Gen 2.)

Далее приступаем к анализу снимка.

Наибольший обьем в памяти занимают HttpContext, DynanicNode, Node.
HttpContext исключаем, так как в нем хранятся ссылки на объекты DynanicNode и Node.
Далее проведем группировку по поколениям, так как нам нужны объекты только поколения Gen 2.

В поколении Gen 2 опять производим группировку по домминаторам.

Это позволяет 100 % найти нужные объекты, которые занимают наибольшее количество памяти. После нужно поработать с конкретным экземплярам объекта, чтобы определить, что это за объект (id, свойства и т.д.)

В этот момент стало понятно, какие данные являются источником проблемы, осталось только найти место, где они создаются и пофиксить.
Шаг 3 — Фикс проблемы
В моем конкретном случае проблема крылась к контроле, который генерировал главную навигацию сайта. Этот контрол не был в кеше, то есть отрабатывал при каждом запросе страниц. А конкретный 'memory leek' был связан с вызовом нативного метода Umbraco DynamicNode.isAncestor(). Как оказалось, для того чтобы определить парента, метод поднимал все дерево сайта в память. Это подтверждало тот факт, что проблема начала проявляться только с ростом данных, а конкретно — с импортом блога.
Следовательно, сам фикс проблемы заключался в замене метода isAncestor на нашу собственную реализацию + применение OutputCache к нашему контролу.
Выводы
— High CPU — это не только рекурсия или большая нагрузка, но и GC;
— Создание объектов должно быть обдуманным и соответствовать архитектуре приложения;
— Output cache — всегда и везде;
— Все, что не видно при обычном тестировании, проявится при нагрузочном!
И на заметку:
На момент написания статьи NewRelic не помог мне выловить источник High CPU, зато performance counter % Time in GC без труда указал на источник проблемы.
Если на графике пики CPU растут в соответствии с пиками графика % Time in GC и значение % Time in GC выше линии 20%, => High CPU из-за сборщика мусора.
Спасибо за внимание. Надеюсь было интересно.
