Comments 33
Идея похожа, но не совсем та.
HAML — это как HTML, только HAML. То есть просто шаблонизатор, который нужно парсить (можно кэшировать где-то, конечно, но зачем если можно не кэшировать), передавать значения, я о шаблонизаторах в целом писал в самом начале, но HAML один из самых интересных.
Тут же вы используете PHP, и, соответственно, при необходимости можете вызывать произвольные функции, использовать тернарный оператор, сразу же передать полученную строку куда-то. Взаимодействие получается проще.
HAML — это как HTML, только HAML. То есть просто шаблонизатор, который нужно парсить (можно кэшировать где-то, конечно, но зачем если можно не кэшировать), передавать значения, я о шаблонизаторах в целом писал в самом начале, но HAML один из самых интересных.
Тут же вы используете PHP, и, соответственно, при необходимости можете вызывать произвольные функции, использовать тернарный оператор, сразу же передать полученную строку куда-то. Взаимодействие получается проще.

Это отлично, но как быть при разделении бекенд и фронтенд на разных специалистов? Фронт может не быть силён в программировании и классическая вёрстка ему будет ближе. С другой стороны есть много шаблонизаторов (haml, jade) позволяющие создавать фрагменты вёрстки.
Мое стойкое убеждение в том, что HTML это не View, это структура для него.
Для View существуют веб-компоненты.
К примеру:
Вот таким подходом в текущем проекте генерируется блок пользователя (код схематичен). e_profile_account_details превращается в веб-компонент e-profile-account-details, а как он выглядит backend-у уже не интересно совсем, всё остальное делается на фронтенде с декларативными data-binding к созданным атрибутам, работает кеширование практически всего View на уровне браузера (прокси, CDN) и прочие радости.
В изменении внешнего вида backend не участвует, совсем.
Или вот ещё схематический пример:
Как элемент выглядит, что будет при клике на нём — всё это чистый frontend, а backend только генерирует структуру того, что будет передано в браузер.
Размер страницы получается минимальный, на backend нет кучи шаблонов, которые, возможно с модификациями, нужно тащить ещё и на frontend.
Для View существуют веб-компоненты.
К примеру:
h::e_profile_account_details([
'name' => $profile['name'],
'type_of_housing' => $profile['type_of_housing'] ?: 'Unknown',
'area' => $profile['area'],
'persons' => $profile['persons']
])
Вот таким подходом в текущем проекте генерируется блок пользователя (код схематичен). e_profile_account_details превращается в веб-компонент e-profile-account-details, а как он выглядит backend-у уже не интересно совсем, всё остальное делается на фронтенде с декларативными data-binding к созданным атрибутам, работает кеширование практически всего View на уровне браузера (прокси, CDN) и прочие радости.
В изменении внешнего вида backend не участвует, совсем.
Или вот ещё схематический пример:
h::{'e-profile-home-device'}([
'id' => '$i[id]',
'category' => '$i[category]',
'device_name' => '$i[name]',
'insert' => $active_devices
])
Как элемент выглядит, что будет при клике на нём — всё это чистый frontend, а backend только генерирует структуру того, что будет передано в браузер.
Размер страницы получается минимальный, на backend нет кучи шаблонов, которые, возможно с модификациями, нужно тащить ещё и на frontend.
Проблема в том, что чистый HTML писать слишком сложно? Я думал все уже давно пользуются snippet'ами для этого.
Присоединяюсь к вопросу. Тоже когда-то экспериментировала с генерацией HTML-кода, но вскоре стало понятно, что это кодинг ради кодинга и создание ненужных проблем. Сниппеты — лучшее решение.
Emmet он же бывший ZenCoding. Как познакомился с ним — проблем не знаю.
Огромное спасибо chikuyonok за этот продукт.
Огромное спасибо chikuyonok за этот продукт.
Посмотрел дему и немного ужаснулся. Очередной новый язык изобретен. Да, довольно удобно, но запомнить все эти новые теги параллельно с HTML мой мозг отказывается. У меня проще:
<td3TAB ->
td /td
td /td
td /td
classTAB ->
class=""
<td3TAB ->
td /td
td /td
td /td
classTAB ->
class=""
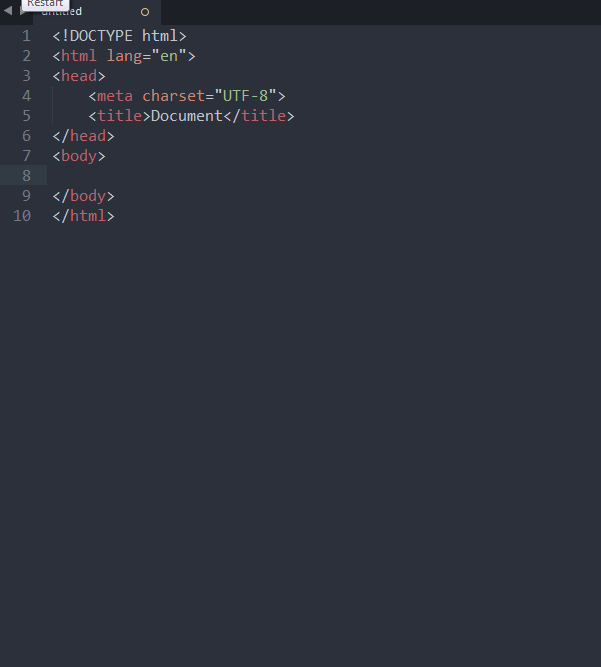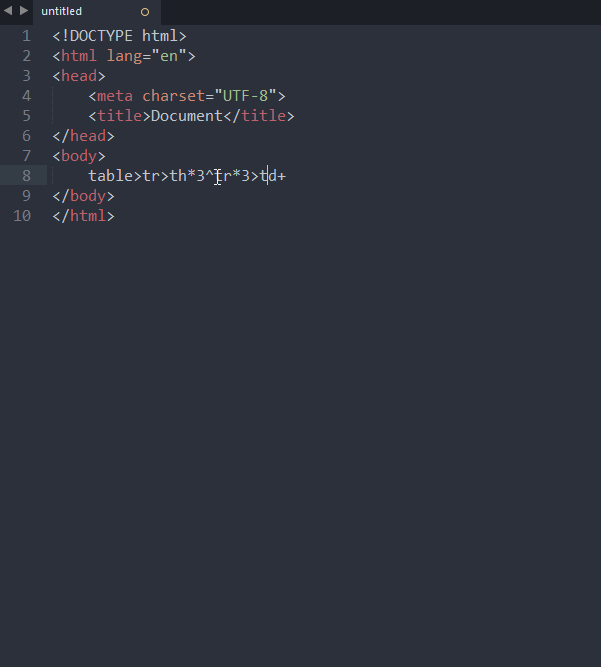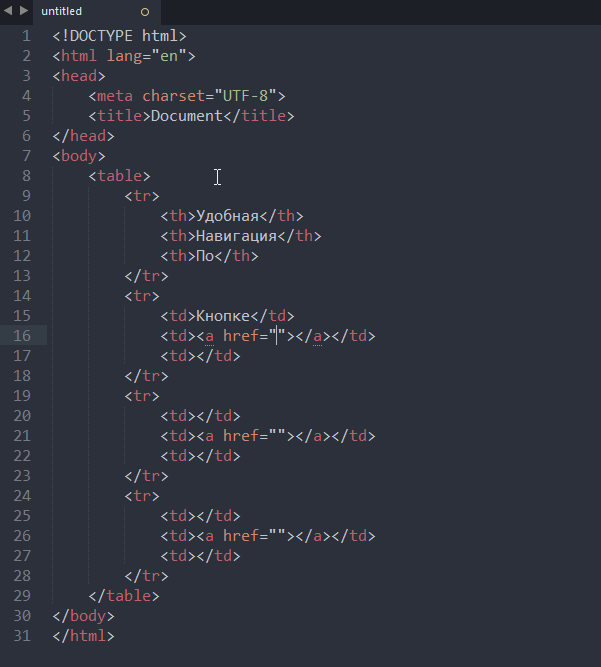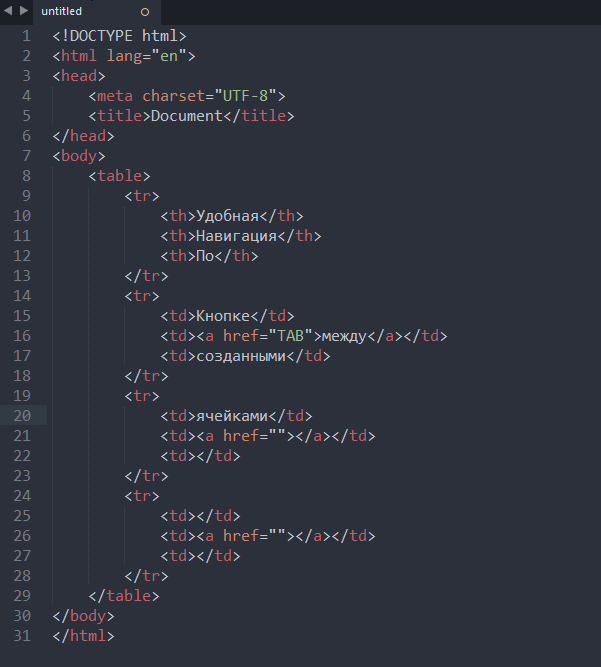
Вру. Установил плагин для Vim, понял что все довольно просто.
Используется стандартный биндинг клавиш режима ввода плюс какая-то непонятная запятая в конце требуется. Я привык завершать snippet через Tab, а тут мне нужно либо какую нибудь "<C-Z>," (обратите внимание на запятую в конце!), либо "," (та же запятая в конце), но при этом UltiSnips начинает подвисать (понятно почему). Перелапачивать плагин придется.
Используется стандартный биндинг клавиш режима ввода плюс какая-то непонятная запятая в конце требуется. Я привык завершать snippet через Tab, а тут мне нужно либо какую нибудь "<C-Z>," (обратите внимание на запятую в конце!), либо "," (та же запятая в конце), но при этом UltiSnips начинает подвисать (понятно почему). Перелапачивать плагин придется.
Ммм… После того как я изобретал свой шаблонизатор я очень негативно отношусь к парсингу строк для генерации кода. Много проблем может возникнуть + никаких подсказок от IDE.
Еще заметил что полностью генерировать весь html неудобно. Визуально много бесполезного шума получется. Остановился на варианте генерации html кода где нужно совмещать пхп-код с html-тегами. Так получается наиболее оптимально.
Мой велосипед менее функционален, но при этом более прост в использовании и не требует никакого знания спец-вставок и их парсинга.
Примеры:
1.
2.
В чем преимущества:
— никакого парсинга входных строк что сильно уменьшает количество возможных багов и ускоряет генерацию кода
— В примере 1 будут подсказки аттрибутов от IDE, что значительно ускоряет написание
— В content можно передавать другие теги
— Можно модифицировать аттрибуты и контент когда угодно и где угодно т.к. мы работаем с объектом (также есть методы append и prepend для контента, addClass для классов и некоторые другие помогалки)
— Можно легко делать компоненты унаследовав класс HtmlTag. Что я и сделал для form и input, textarea, select тэгов, получив весьма удобный генератор форм с минимальными запарами.
Недостатки:
— нет автоматизации для массивов данных (хотя, вероятно, я ее добавлю ибо очень уж полезная идея)
Еще заметил что полностью генерировать весь html неудобно. Визуально много бесполезного шума получется. Остановился на варианте генерации html кода где нужно совмещать пхп-код с html-тегами. Так получается наиболее оптимально.
Мой велосипед менее функционален, но при этом более прост в использовании и не требует никакого знания спец-вставок и их парсинга.
Примеры:
1.
HtmlTag::a('content')->href('/url')->class('abc');2.
HtmlTag::a(array('content' => 'text', 'href' => '/url', 'class' => 'abc'))В чем преимущества:
— никакого парсинга входных строк что сильно уменьшает количество возможных багов и ускоряет генерацию кода
— В примере 1 будут подсказки аттрибутов от IDE, что значительно ускоряет написание
— В content можно передавать другие теги
— Можно модифицировать аттрибуты и контент когда угодно и где угодно т.к. мы работаем с объектом (также есть методы append и prepend для контента, addClass для классов и некоторые другие помогалки)
— Можно легко делать компоненты унаследовав класс HtmlTag. Что я и сделал для form и input, textarea, select тэгов, получив весьма удобный генератор форм с минимальными запарами.
Недостатки:
— нет автоматизации для массивов данных (хотя, вероятно, я ее добавлю ибо очень уж полезная идея)
Если вызывать методы из символов что позволяет синтаксис PHP — парсинга строки можно сказать нет, и работает быстрее, спец вставки разного рода исключительно опциональны. По атрибутам подсказок не получите, но если унаследуете и допишите перед классом PhpDoc блоки с названиями методов как тегов, кторые вам нужны (то есть будут PhpDoc блоки, а реализации самих методов не будет) — получите подсказки. Просто тэгов много, атрибутов и подавно, а в последнее время я активно использую веб-компоненты, и в итоге добавить для всего подсказки для IDE просто невозможно.
И, к стати, оно у вас может и работает быстрее, но вероятнее всего памяти кушает больше.
Если у вас оно сходу преобразовывается в строку, то да, моё творение жрет больше. Зато позволяет себя модифицировать далее в коде (а это весьма полезно бывает).
К тому же если использовать
Разница в расходе памяти тут будет зависеть от реализации.
К тому же если использовать
echo HtmlTag::a(), то получится примерно одинаково т.к. объект сразу превратится в строку (методом __toString()) и на него не останется ссылок (т.е. сборщик мусора его грохнет).Разница в расходе памяти тут будет зависеть от реализации.
Реализовал аналогично, но для генерации платформонезависимого SQL. Работает вполне себе шустро, плюс ко всему, умеет генерировать объекты из строки.
Для SQL у меня тоже есть свой велосипед больше похожий на ORM, правда. Хотя 1 из компонентов — сборщик sql запросов
Фишка в том, что ORM должен вылетать с исключениями на каждый непонравившийся ему момент. Ну а любое исключение отправляется мне на email. Идея в том, чтобы предотвратить неадекватные или ошибочные действия с данными. Например, если в объект не загружено поле, но я к нему обращаюсь — получу исключение на почту. Ибо нефиг.
Платформонезависимостью не похвастаюсь, но она «условно» есть =) Просто я не проверял на других БД, кроме PostgreSQL
DbQuery::create(table, alias)->fields('*')->where(array())->run() и т.д. Ситуация была такая, что нужно было сделать максимально вредный ORM, который умел бы превращать ответы из БД в объекты и наоборот. Валидация, конвертация типов (для timestamp, например), максимально простое прикрепление файлов и получение путей к ним и т.п. Все поля, естественно, должны быть описаны в конфигахФишка в том, что ORM должен вылетать с исключениями на каждый непонравившийся ему момент. Ну а любое исключение отправляется мне на email. Идея в том, чтобы предотвратить неадекватные или ошибочные действия с данными. Например, если в объект не загружено поле, но я к нему обращаюсь — получу исключение на почту. Ибо нефиг.
Платформонезависимостью не похвастаюсь, но она «условно» есть =) Просто я не проверял на других БД, кроме PostgreSQL
Мой генератор SQL является частью ORM. Генерация SQL это все таки одна из задач любой ORM.
Согласен. Хотя обычно они не связаны слишком сильно. У меня же получилось так, что sql-генератор проверяет нет ли в запросе неизвестных полей (берет он их из конфигов модели) и назначены ли кастомным полям типа
COUNT(*) алиасы. Также умеет делать join'ы по названию модели беря данные о связи из конфига модели. Его теперь без напильника отдельно от всего ORM не поиспользуешь. Зато удобно =)Очень элегантная реализация получилась. Молодцы!
А теперь мы захотели разных скинов или сделать новое общее подменю…
Код удручает.
Весь модуль в виде единого god-сласса с навешанными на него всеми ответственностями, методы в сотни строк, с многоуровневыми вложенными условиями и циклами, «информативные» названия некоторых переменных: "$q", "$d" и методов: «template_1», возможность работы с модулем только статическими вызовами (как его передавать как сервис через иньекцию зависимостей ?).
Непонимание ряда моментов работы PHP в виде попыток оптимизации передачи массивов по ссылке (PHP сам передаёт массив фактически по ссылке и копирует его только при применении изменений к нему).
Нет, вы меня извините конечно, но лучше бы вы потратили это время на изучение паттернов проектирования, принципов SOLID, стандартов кодирования, и того, как не следует оптимизировать код за PHP, об этом целые статьи есть.
Весь модуль в виде единого god-сласса с навешанными на него всеми ответственностями, методы в сотни строк, с многоуровневыми вложенными условиями и циклами, «информативные» названия некоторых переменных: "$q", "$d" и методов: «template_1», возможность работы с модулем только статическими вызовами (как его передавать как сервис через иньекцию зависимостей ?).
Непонимание ряда моментов работы PHP в виде попыток оптимизации передачи массивов по ссылке (PHP сам передаёт массив фактически по ссылке и копирует его только при применении изменений к нему).
Нет, вы меня извините конечно, но лучше бы вы потратили это время на изучение паттернов проектирования, принципов SOLID, стандартов кодирования, и того, как не следует оптимизировать код за PHP, об этом целые статьи есть.
Ох, уж это компилирование php в html. Как закончите, вот вам ссылочки:
twig.sensiolabs.org/doc/tags/macro.html
docs.emmet.io/
twig.sensiolabs.org/doc/tags/macro.html
docs.emmet.io/
в Picolisp очень удобная генерация html. Плюс возможность смешивания высокоуровневых средств с низкоуровневыми на одной и той же странице
Вы пишите
И тут же этот самый причудливый синтаксис. Может вам он и кажется не таким, но поверьте, даже HAML или Jade очевиднее. А по поводу HAML это тот же HTML, только HAML, это смотря как использовать. Те же, наследования, инклуды и циклы из Jade очень помогают при сборке просто огромного количества шаблонов.
Вобщем или вы не донесли проблему и предложили свою гениальную идею неподготовленной публике, или велосипед.
Шаблонизаторы частично решают эту проблему, но их причудливый синтаксис нужно изучать
И тут же этот самый причудливый синтаксис. Может вам он и кажется не таким, но поверьте, даже HAML или Jade очевиднее. А по поводу HAML это тот же HTML, только HAML, это смотря как использовать. Те же, наследования, инклуды и циклы из Jade очень помогают при сборке просто огромного количества шаблонов.
Вобщем или вы не донесли проблему и предложили свою гениальную идею неподготовленной публике, или велосипед.
UFO just landed and posted this here
Sign up to leave a comment.
Генерация HTML: удобнее чем хелперы и чистый HTML