Привет, Хабр!
Мы запустили Data Mining Hub и хотим рассказать, что это такое и для чего он может вам пригодиться.
Data Mining Hub (DMH) — это платформа для разработки алгоритмов для интеллектуального анализа данных (Data Mining) и машинного обучения (Machine Learning), в основе которой лежит итеративный подход, a также это инструмент для бизнеса, помогающий анализировать большой объём данных и извлекающий из этих данных полезную и необходимую информацию.
Отличие DMH от подобных ресурсов, таких как kaggle и алгомост:
В DMH существует две стороны. Первая – это заказчик, который описывает задачу, и вторая – это ученый, который пытается эту задачу решить.
Ученым DMH предоставляет возможность принять участие в решении интересных задач, посоревноваться с другими участниками и, конечно, получить оплату, если их алгоритм был выбран Заказчиком. Если же он не был выбран на этой итерации, то он всегда может быть выбран на следующей. DMH автоматически перенесет результаты с прошлой итерации в новую, если не изменились исходные данные. Но также есть возможность улучшить свой алгоритм и получить оплату за счет улучшенного алгоритма в следующей итерации.
Для заказчика DMH — это единая точка интеграции с большим количеством ученых и простой способ использовать разные алгоритмы на одних и тех же данных.
Кратко принцип работы DMH можно описать следующим образом:
Все желающие могут перейти по ссылке www.datamininghub.com/invite/me и попросить DMH пригласить их, просто указав email.
Рассмотрим, что нужно сделать ученому, чтобы принять участие в решении поставленной задачи. В принципе, все достаточно просто. Ему необходимо выбрать задачу, создать под нее алгоритм, опробовать его на исходных данных. Если получен удовлетворительный результат, то дальше уже можно указать стоимость использования алгоритма.
После аутентификации на datamininghub.com откроется страница, где будут перечислены все задачи, требующие решения. Необходимо выбрать понравившуюся задачу и скачать исходные данные в секции Data Set
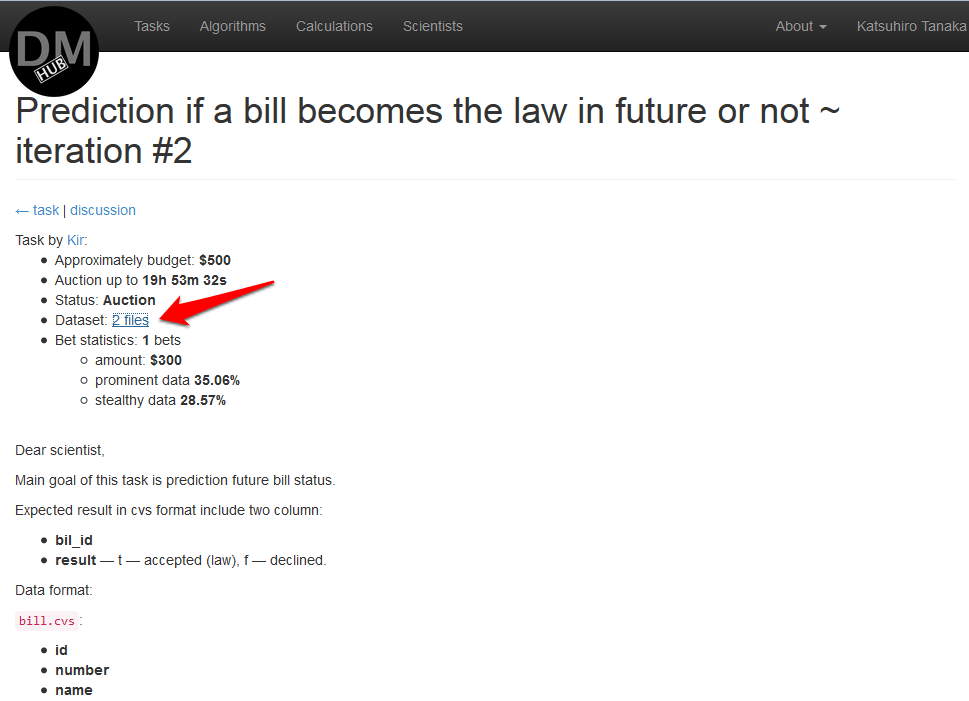
Далее необходимо разработать алгоритм с использованием любых средств разработки. Главное, чтобы алгоритм был jar файлом (или несколько таковых), который можно было бы запустить как job на hadoop.
Небольшой пример алгоритма на Scala доступен по ссылке: github.com/datamininghub/example-algorithm
Реальный пример решения существующей задачи доступной по адресу www.datamininghub.com/task/1 или на той же Scala доступен тут: github.com/datamininghub/example-bill-status-prediction
Для того чтобы загрузить свой алгоритм необходимо:
Существует возможность проверить работоспособность алгоритма на любых данных до выставления стоимости пользования данным алгоритмом, нажав на try it на панели навигации на странице Algorithm details. Появится страница edit calculations, в секции Mappings которой необходимо будет загрузить данные для вычислений и нажать на calculate на панели навигации.
p.s. — отдельное спасибо Евгении за неоценимый вклад в этот текст!
Мы запустили Data Mining Hub и хотим рассказать, что это такое и для чего он может вам пригодиться.
Data Mining Hub (DMH) — это платформа для разработки алгоритмов для интеллектуального анализа данных (Data Mining) и машинного обучения (Machine Learning), в основе которой лежит итеративный подход, a также это инструмент для бизнеса, помогающий анализировать большой объём данных и извлекающий из этих данных полезную и необходимую информацию.
Отличие DMH от подобных ресурсов, таких как kaggle и алгомост:
- задача делится на итерации;
- код алгоритма остается у автора, Заказчик берет его только в аренду;
- вычислениями, оценкой и манипуляциями с деньгами управляет DMH;
- для участия не требуется верификация и подтверждение квалификации.
В DMH существует две стороны. Первая – это заказчик, который описывает задачу, и вторая – это ученый, который пытается эту задачу решить.
Ученым DMH предоставляет возможность принять участие в решении интересных задач, посоревноваться с другими участниками и, конечно, получить оплату, если их алгоритм был выбран Заказчиком. Если же он не был выбран на этой итерации, то он всегда может быть выбран на следующей. DMH автоматически перенесет результаты с прошлой итерации в новую, если не изменились исходные данные. Но также есть возможность улучшить свой алгоритм и получить оплату за счет улучшенного алгоритма в следующей итерации.
Для заказчика DMH — это единая точка интеграции с большим количеством ученых и простой способ использовать разные алгоритмы на одних и тех же данных.
Кратко принцип работы DMH можно описать следующим образом:
- Заказчик создает задание, приводит описание, определяет примерный бюджет, продолжительность и период принятия решения для каждой итерации.
- Заказчик загружает данные, с которыми потом будут работать ученые.
- Заказчик подтверждает задание, после чего ученым становятся доступны данные.
- На основе данных ученые создают свои алгоритмы, загружают их в DMH и указывает стоимость использования алгоритма.
- Заказчик выбирает понравившейся ему алгоритм, и после этого перечисляется оплату Ученому.
Все желающие могут перейти по ссылке www.datamininghub.com/invite/me и попросить DMH пригласить их, просто указав email.
Рассмотрим, что нужно сделать ученому, чтобы принять участие в решении поставленной задачи. В принципе, все достаточно просто. Ему необходимо выбрать задачу, создать под нее алгоритм, опробовать его на исходных данных. Если получен удовлетворительный результат, то дальше уже можно указать стоимость использования алгоритма.
Рассмотрим все более подробно
После аутентификации на datamininghub.com откроется страница, где будут перечислены все задачи, требующие решения. Необходимо выбрать понравившуюся задачу и скачать исходные данные в секции Data Set
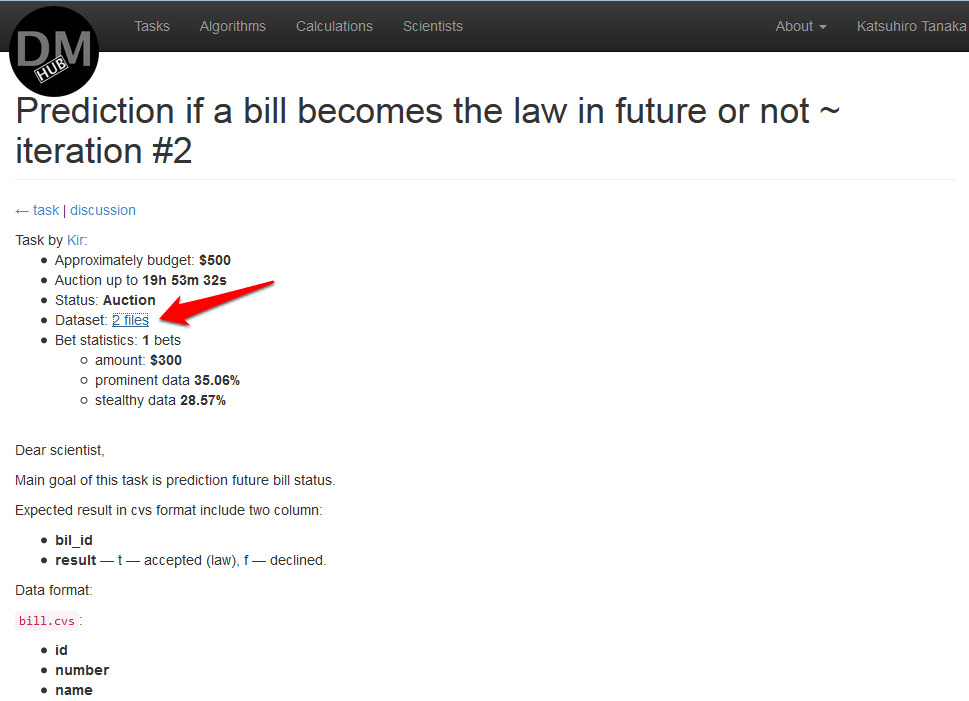
Далее необходимо разработать алгоритм с использованием любых средств разработки. Главное, чтобы алгоритм был jar файлом (или несколько таковых), который можно было бы запустить как job на hadoop.
Небольшой пример алгоритма на Scala доступен по ссылке: github.com/datamininghub/example-algorithm
Реальный пример решения существующей задачи доступной по адресу www.datamininghub.com/task/1 или на той же Scala доступен тут: github.com/datamininghub/example-bill-status-prediction
Для того чтобы загрузить свой алгоритм необходимо:
- Зайти на DMH.
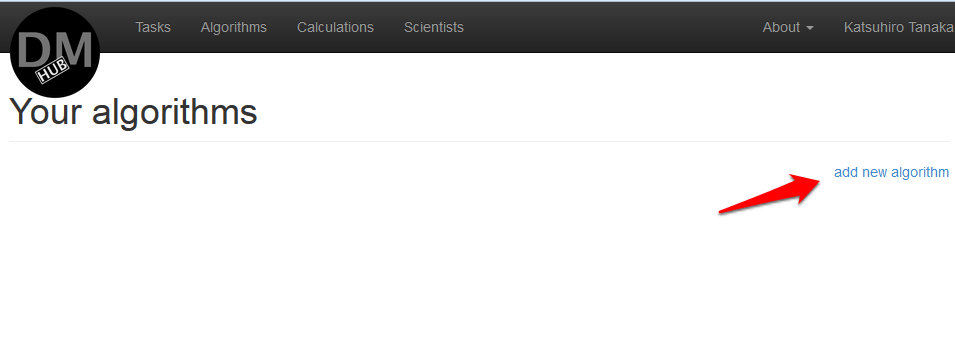
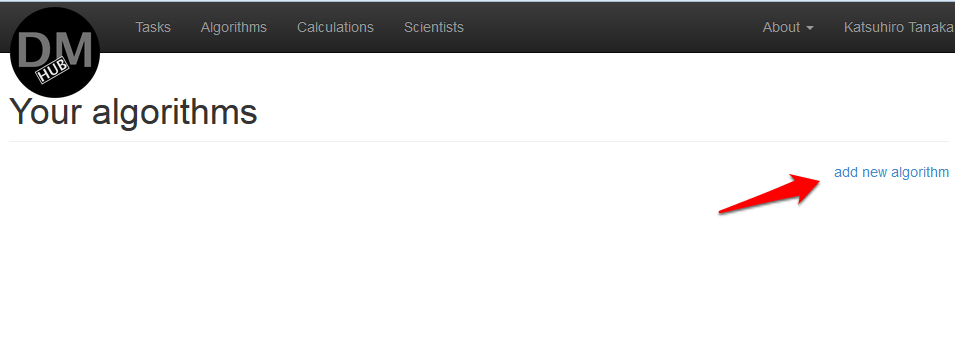
- В меню выбрать Algorithms, после чего откроется страница, где будут перечислены все созданные алгоритмы данного пользователя.
- Нажать на add new algorithm
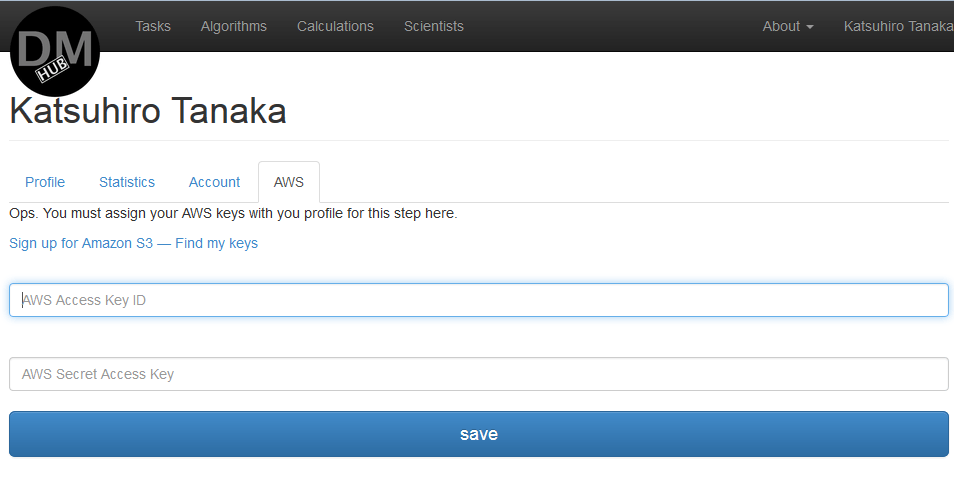
- Если ранее к профилю пользователя не был привязан AWS аккаунт, то системы попросит сделать это на данном этапе:
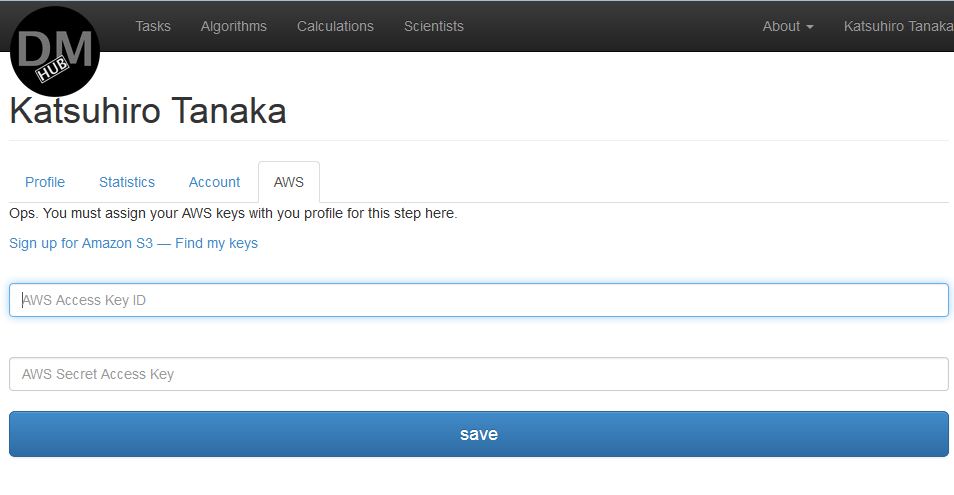
Если AWS аккаунт отсутствует, то необходимо будет его зарегистрировать.
Перейдя по ссылке http://aws.amazon.com/free/ возможно зарегистрировать новый аккаунт и использовать бесплатные лимиты в течение года.
После этого вам нужно будет пройти по ссылке Sign up for Amazon S3 — Find my keys и создать ключи, которые необходимо дальше ввести в DMH.
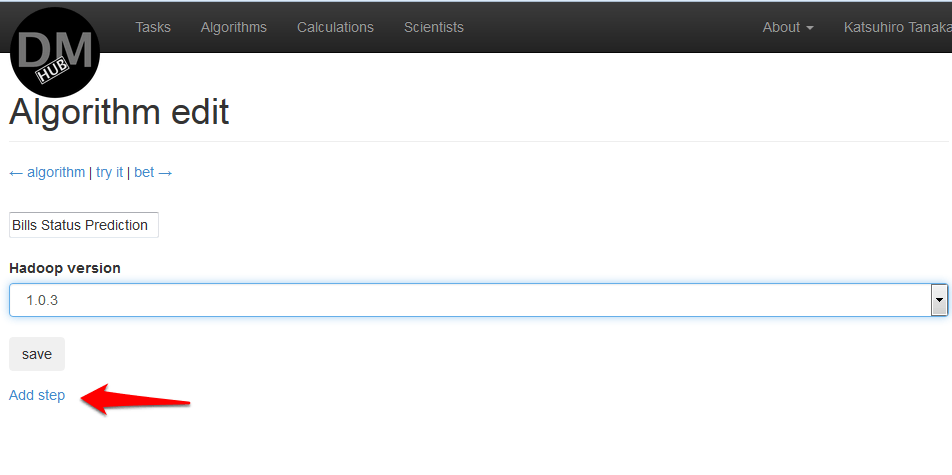
- После того как будет осуществлена привязка AWS аккаунта, появится страница Algorithm details, на которой будет отражено дефолтное имя алгоритма DataMiningHub algorithm N for Hadoop 1.0.3 и где необходимо будет нажать на Edit:

- На появившейся странице Algorithm edit возможно изменить название алгоритма на какое либо другое, изменить версию используемого Hadoop. Затем необходимо нажать на Add step, чтобы добавить шаг, представляющий из себя добавление jar файл, содержащего код алгоритма, и определить аргументы, с которыми этот файл будет запускаться:

- На появившейся странице Add file необходимо выбрать jar файл для загрузки и нажать кнопку Upload или указать S3 ссылку на этот файл.

Для примера взят файл с именем bill-status-prediction.jar
Примечание: загрузка файла может занять некоторые время!
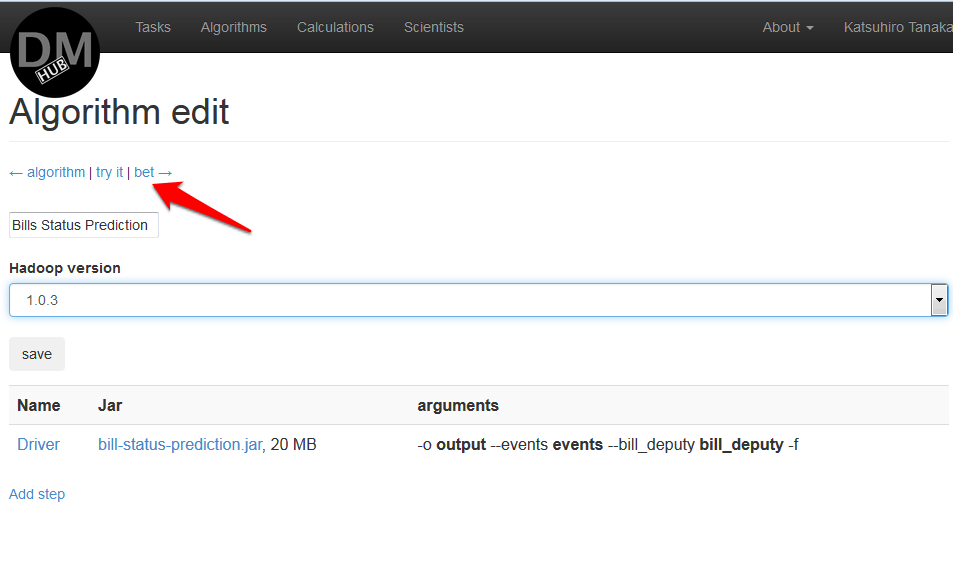
- Теперь необходимо задать аргументы на странице Step algorithm edit, с которыми данный jar файл будет запускаться, и нажать кнопку Save:

Для примера используются следующие аргументы:-o {output} --events {events} --bill_deputy {bill_deputy} -f
- После того, как были заданы аргументы, снова появится страница Algorithm edit, но уже с информацией об уже введенном шаге. При необходимости можно загрузить другие jar файлы, так же нажав Add step и повторив пункты с 6 по 8.
- Теперь на странице Algorithm details необходимо нажать bet на панели навигации, чтобы определить стоимость пользования алгоритма и выполнить вычисления:

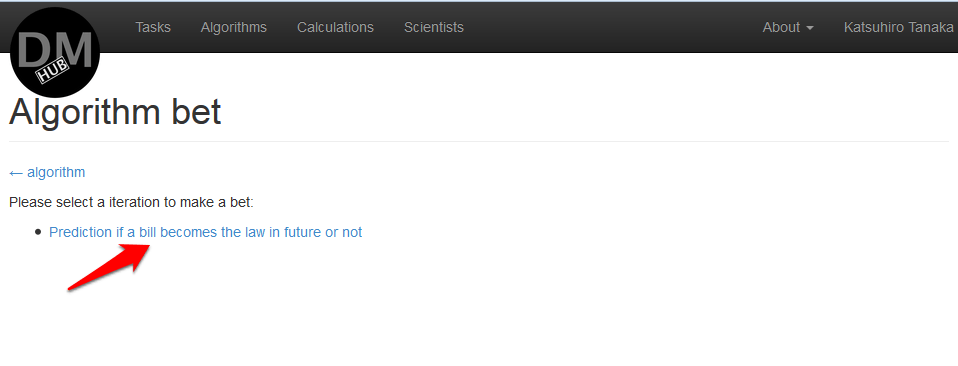
- На странице Algorithm bet необходимо выбрать задачу, в которой будет использоваться алгоритм:
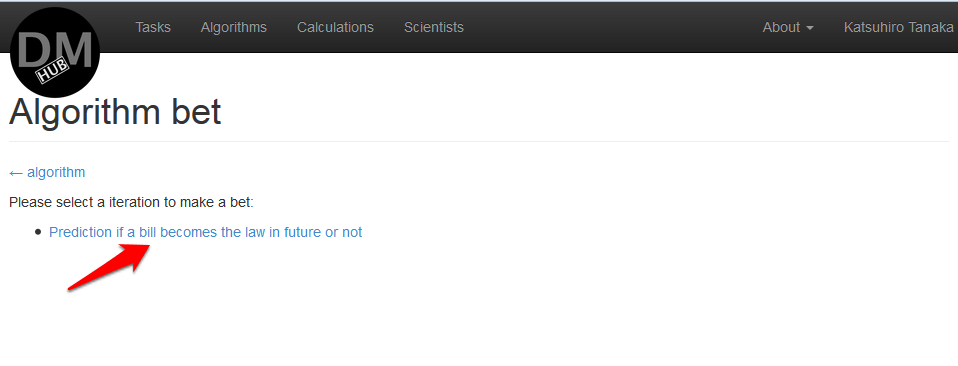
В данном примере доступна только одна итерация Prediction if a bill becomes the law in future or not.
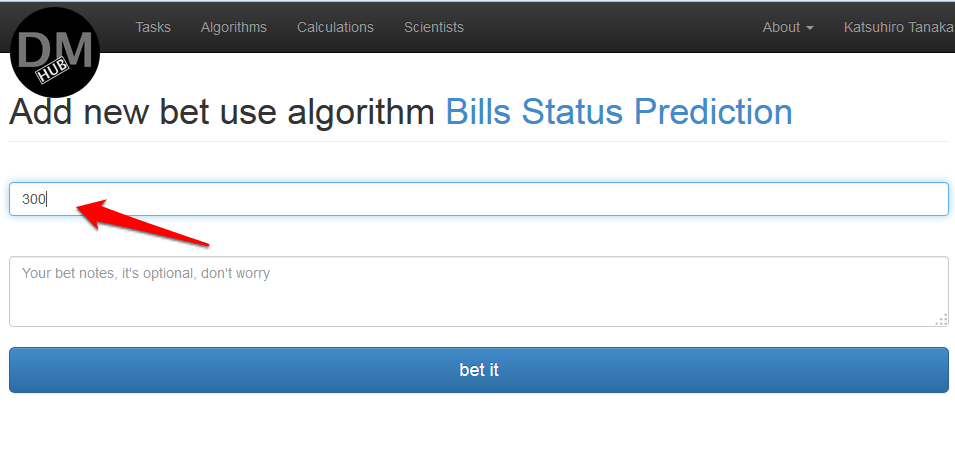
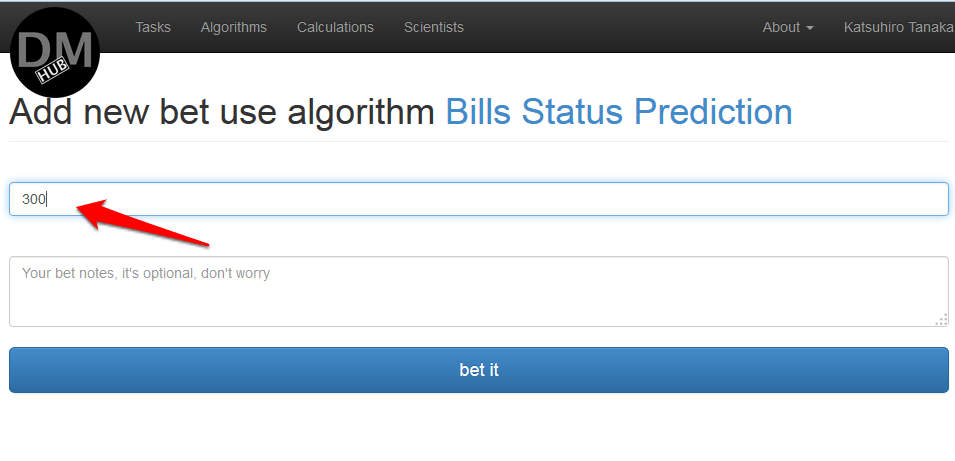
- На появившейся странице Add new bet use algorithm %algorithm_name% необходимо определить стоимость пользования алгоритмом и нажать кнопку bet it:
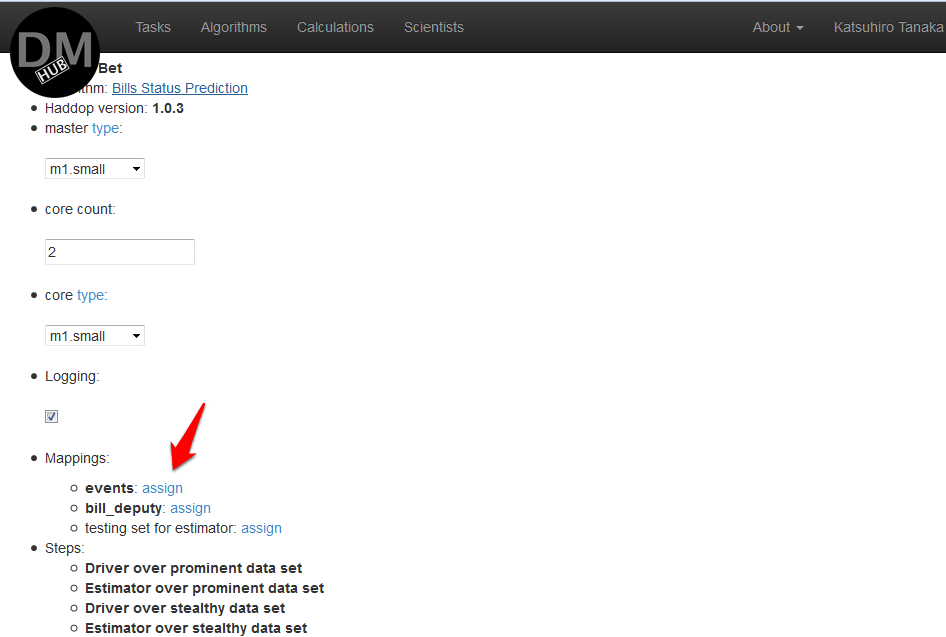
- На появившейся странице Edit calculation необходимо в секции Mappings сделать маппинг имен всех аргументов из всех шагов (steps) c исходными данными, нажав на assign напротив каждого имени аргумента и выбрав необходимый источник данных, и нажать calculate:
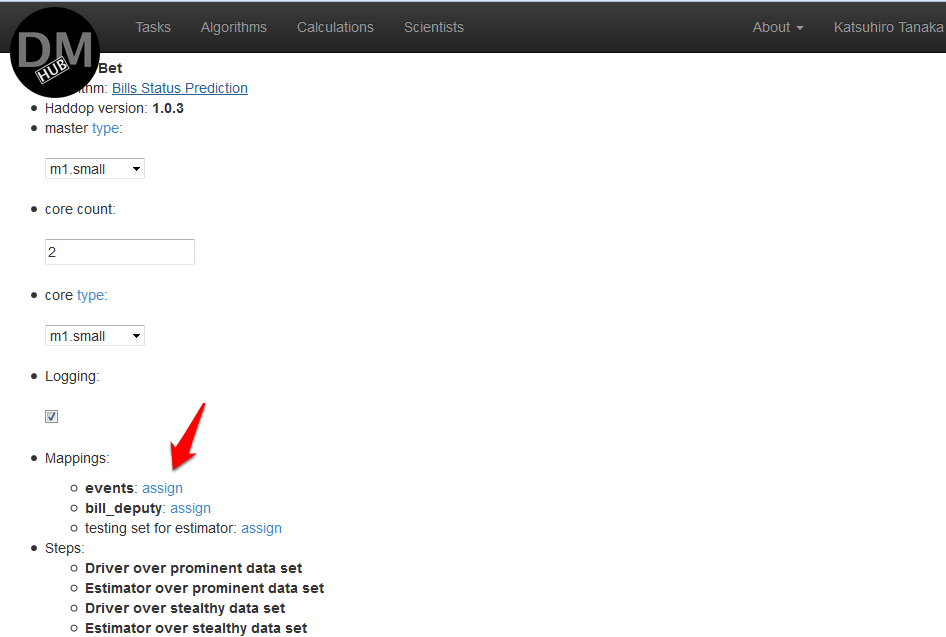
При необходимости можно сохранить данное вычисление, нажав кнопку Save.
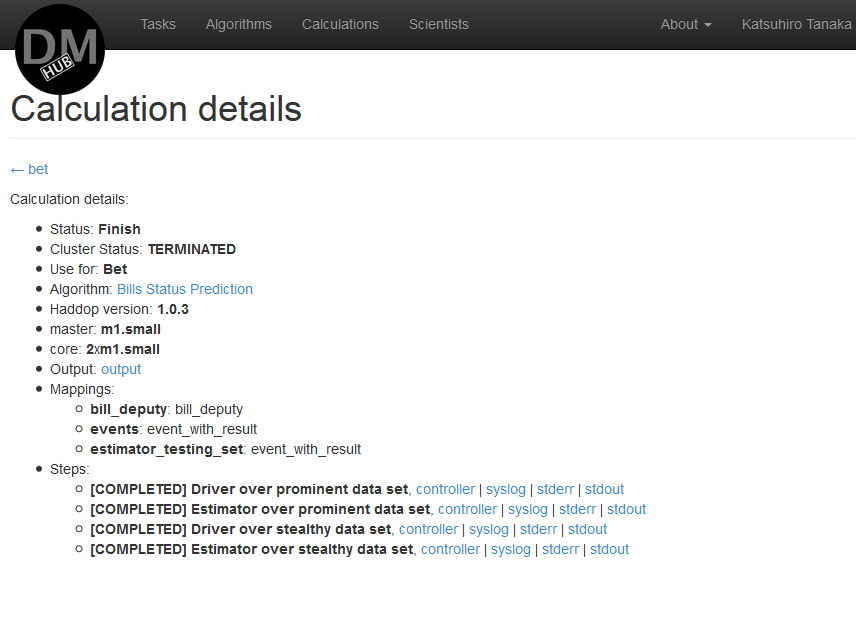
- После всех манипуляций появится страница Сalculation details, на которой выведется состояние данного вычисления. После того, как вычисление закончится, его результат будет выслан на почтовый адрес, привязанный к данному профилю.
Пример вычисления в процессе обработки:

Пример законченного вычисления:
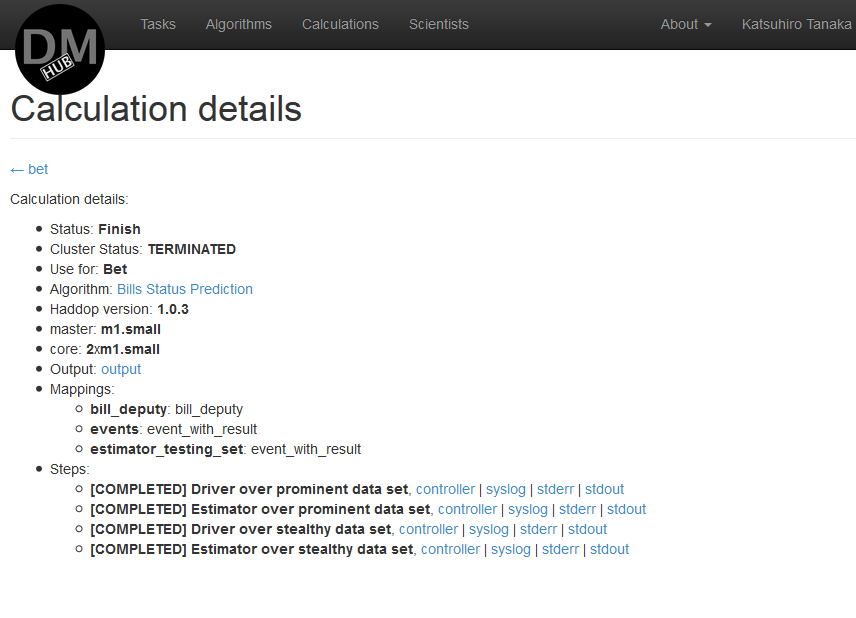
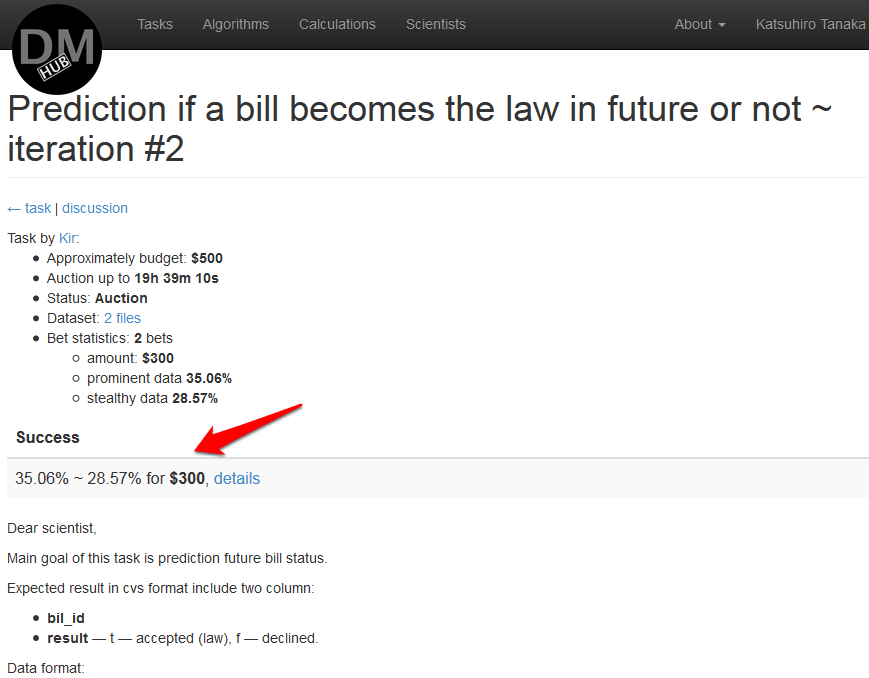
- Когда вычисление будет закончено, его результат появится в описании задачи, также как и стоимость пользования алгоритмом, и Заказчик сможет выбрать данный алгоритм в качестве решения поставленной задачи:





Существует возможность проверить работоспособность алгоритма на любых данных до выставления стоимости пользования данным алгоритмом, нажав на try it на панели навигации на странице Algorithm details. Появится страница edit calculations, в секции Mappings которой необходимо будет загрузить данные для вычислений и нажать на calculate на панели навигации.
p.s. — отдельное спасибо Евгении за неоценимый вклад в этот текст!
