Здравствуйте, уважаемые хабровчане.
Многие из вас, уверен, не раз сталкивались с проблемой, когда сайт, полностью работающий на JS, например, связка Angular.js + UI-router, для роботов извне (индексатор Google'а, краулеры Facebook'a или Twitter'a) доступен в самом что ни на есть неподобающем виде.
В нескольких статьях я постараюсь вам рассказать, как с помощью нехитрых приемов можно все-таки отбросить «non-SEO-friendly» как причину не разрабатывать с учетом тенденций в мире веб-разработки.
В этой части я постараюсь описать как я боролся с краулерами Facebook'a и Twitter'a, чтобы мои ссылки в постах в этих соцсетях выглядели привлекательно и люди заходили.
Если эта тема вам интересна, прошу под кат.
Конечно же Вы видели в своей ленте в Facebook большие и привлекающие внимание сообщения и очень себе такое хотели. Вроде таких:
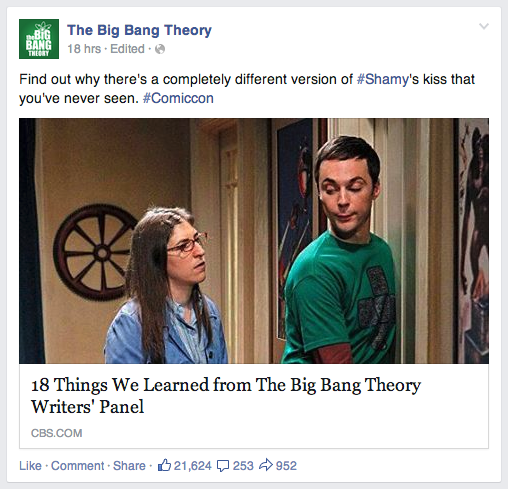
Недружелюбность SEO к JavaScript'у, зачастую, отталкивает разработчиков от разработки сайта, использующего полную силу JavaScript'a в том виде, в котором он сейчас есть. Использование HTML5 History API, переходы по ссылкам без перезагрузки страницы и прочее, и прочее остается лишь для веб-приложений.
Очень жаль, но прослеживается такая тенденция, что сайты завязанные на JavaScript'e не пригодны для ресурсов, которые зависят от SEO довольно сильно, как то: интернет-магазины, новостные, информационные ресурсы и так далее.
Почему так происходит?
Потому что роботы не исполняют JavaScript.
То есть, скормив ссылку на страницу на нашем сайте краулеру Facebook'a, мы получим результат аналогичный как и для самого index.html, который лежит в корне.
Допустим, Вы, как и я решили создать на Angular.js с использованием ui-router что-то похожее на блог. Допустим, в добавок мы хотим, чтобы только браузер знал, что переходы по Вашему сайту осуществляются с помощью AJAX'a и включим так называемый HTML5 Mode для
Для работы с HTML5 History API нужно во время конфигурации модуля основного приложения указать это:
Приступаем.
Для дебага мы можем использовать готовые инструменты:
Пытаемся скормить какую-либо страницу Facebook debugger'у и понимаем, что все-таки да, JS не выполняется.
Как быть?
Первое, что приходит в голову — редирект. Краулеры соцсетей имеют свои User-Agent'ы, которые мы сможем использовать для перенаправления на уже _готовую_ страницу. Т.е. нам нужно рендерить страницу не у клиента, а на сервере, причем не все, а только те, что являются для нас важными, в случае с блогом — это посты. В данном случае нам поможет PHP.
Для этого мы напишем своеобразный прокси, назовем его
В теле тега
Open Graph — это протокол, набор правил, по которому социальная сеть может построить социальный граф, определить, кто автор статьи и так далее. Подробнее можно прочитать на сайте самого Open Graph'a.
Итак, в моем случае веб-сервером выступает Apache, поэтому можем просто перечислить User-Agent'ы и отправить вместе с ID поста на наш прокси, который вернет нам «сухую» страничку.
В конфигурацию прописываем следующее:
Итак, после этого снова пробуем нашу ссылку с постом отправить в Facebook debugger.
Вы можете увидеть какие-либо предупреждения и исправить их, либо, если все прошло как по маслу — увидеть как будет выглядеть ваша ссылка в постах на Facebook'е.
В случае с Twitter'ом просто необходимо дополнительные мета-теги описать. Их список можно найти на странице самого валидатора: Twitter Card validator.
Если тема окажется интересной — в следующей части я расскажу про индексацию сайта, написанного на JavaScript'е.
Многие из вас, уверен, не раз сталкивались с проблемой, когда сайт, полностью работающий на JS, например, связка Angular.js + UI-router, для роботов извне (индексатор Google'а, краулеры Facebook'a или Twitter'a) доступен в самом что ни на есть неподобающем виде.
В нескольких статьях я постараюсь вам рассказать, как с помощью нехитрых приемов можно все-таки отбросить «non-SEO-friendly» как причину не разрабатывать с учетом тенденций в мире веб-разработки.
В этой части я постараюсь описать как я боролся с краулерами Facebook'a и Twitter'a, чтобы мои ссылки в постах в этих соцсетях выглядели привлекательно и люди заходили.
Если эта тема вам интересна, прошу под кат.
Конечно же Вы видели в своей ленте в Facebook большие и привлекающие внимание сообщения и очень себе такое хотели. Вроде таких:

Недружелюбность SEO к JavaScript'у, зачастую, отталкивает разработчиков от разработки сайта, использующего полную силу JavaScript'a в том виде, в котором он сейчас есть. Использование HTML5 History API, переходы по ссылкам без перезагрузки страницы и прочее, и прочее остается лишь для веб-приложений.
Очень жаль, но прослеживается такая тенденция, что сайты завязанные на JavaScript'e не пригодны для ресурсов, которые зависят от SEO довольно сильно, как то: интернет-магазины, новостные, информационные ресурсы и так далее.
Почему так происходит?
Потому что роботы не исполняют JavaScript.
То есть, скормив ссылку на страницу на нашем сайте краулеру Facebook'a, мы получим результат аналогичный как и для самого index.html, который лежит в корне.
Допустим, Вы, как и я решили создать на Angular.js с использованием ui-router что-то похожее на блог. Допустим, в добавок мы хотим, чтобы только браузер знал, что переходы по Вашему сайту осуществляются с помощью AJAX'a и включим так называемый HTML5 Mode для
ui-router. Как в таком случае будет выглядеть index.html? Да примерно так:<!doctype html>
<html class="no-js">
<head>
<meta charset="utf-8">
<base href="/">
<title></title>
<!-- Перечень стилей -->
</head>
<body ng-app="app">
<div ui-view=""></div>
<!-- И тут простыня из подключаемых javascript файлов -->
</body>
</html>
Для работы с HTML5 History API нужно во время конфигурации модуля основного приложения указать это:
angular.module('app', [
...
'ui.router',
...
])
.config(function($locationProvider) {
...
$locationProvider.html5Mode(true);
...
})
Приступаем.
Для дебага мы можем использовать готовые инструменты:
Пытаемся скормить какую-либо страницу Facebook debugger'у и понимаем, что все-таки да, JS не выполняется.
Как быть?
Первое, что приходит в голову — редирект. Краулеры соцсетей имеют свои User-Agent'ы, которые мы сможем использовать для перенаправления на уже _готовую_ страницу. Т.е. нам нужно рендерить страницу не у клиента, а на сервере, причем не все, а только те, что являются для нас важными, в случае с блогом — это посты. В данном случае нам поможет PHP.
Для этого мы напишем своеобразный прокси, назовем его
crawler_proxy.php<?php
$SITE_ROOT = "http://example.com/";
$jsonData = getData($SITE_ROOT);
makePage($jsonData, $SITE_ROOT);
function getData($siteRoot) {
$id = ctype_digit($_GET['id']) ? $_GET['id'] : 1;
$rawData = file_get_contents($siteRoot.'blog/api/get_post/?id='.$id);
return json_decode($rawData);
}
function makePage($data, $siteRoot) {
?>
<!DOCTYPE html>
<html>
<head>
<meta property="og:title" content="<?php echo $data->post->title; ?>" />
<meta property="og:description" content="<?php echo strip_tags($data->post->excerpt); ?>" />
<meta property="og:image" content="<?php echo $data->post->attachments[0]->images->full->url; ?>" />
<meta property="og:site_name" content="My Blog"/>
<meta property="og:url" content="http://example.com/posts/<?php echo $data->post->id ?>" />
<meta property="og:type" content="article"/>
<!-- etc. -->
</head>
<body>
<h1><?php echo $data->post->title; ?></h1>
<p><?php echo $data->post->content; ?></p>
<img src="">
</body>
</html>
<?php
}
?>
В теле тега
head прописываются мета-теги с указанием свойства Open Graph'a.Open Graph — это протокол, набор правил, по которому социальная сеть может построить социальный граф, определить, кто автор статьи и так далее. Подробнее можно прочитать на сайте самого Open Graph'a.
Итак, в моем случае веб-сервером выступает Apache, поэтому можем просто перечислить User-Agent'ы и отправить вместе с ID поста на наш прокси, который вернет нам «сухую» страничку.
В конфигурацию прописываем следующее:
# ------------------------------------------------------------------------------
# | Redirect crawlers to PHP proxy |
# ------------------------------------------------------------------------------
<IfModule mod_rewrite.c>
RewriteEngine On
# redirect crawlers
RewriteCond %{HTTP_USER_AGENT} (Facebot|Google.*snippet|Twitterbot|facebookexternalhit/*)
RewriteRule posts/(\d+)$ /crawler_proxy.php?id=$1 [L]
</IfModule>
Итак, после этого снова пробуем нашу ссылку с постом отправить в Facebook debugger.
Вы можете увидеть какие-либо предупреждения и исправить их, либо, если все прошло как по маслу — увидеть как будет выглядеть ваша ссылка в постах на Facebook'е.
В случае с Twitter'ом просто необходимо дополнительные мета-теги описать. Их список можно найти на странице самого валидатора: Twitter Card validator.
Если тема окажется интересной — в следующей части я расскажу про индексацию сайта, написанного на JavaScript'е.
