DDMS (Dalvik Debug Monitor Server) — безумно полезный инструмент для отладки приложений, который идет в комплекте с Android SDK, о котором почему-то особо и не сказано на хабре, впрочем как и в примерах google он представлен в очень скромном виде. Я бы хотел раскрыть его возможности и показать на что он способен. Вкратце:
Об этих вещах будет рассказано в рамках данной статьи. И для справки, менее интересное, что довольно тривиально и о чем НЕ будет рассказано в рамках данной статьи:
DDMS содержит инструмент, который позволяет нам анализировать информацию по каждому процессу и его потокам. Достаточно выделить необходимый процесс нашего приложения и нажать «update threads».

Справа вы можете увидеть вкладку «Threads» и работающие потоки выбранного процесса. По каждому потоку доступна следующая информация:
Таким образом, мы можем понять, какой поток больше всего расходует процессорного времени. Тут следует сказать несколько слов о некоторых потоках.
GC – как все думаю догадались, это поток сборщика мусора. До Android 3 он недоступен для просмотра в потоках.
JDWP (Java Debug Wire Protocol) – протокол взаимодействия между дебагером и виртуальной машиной.
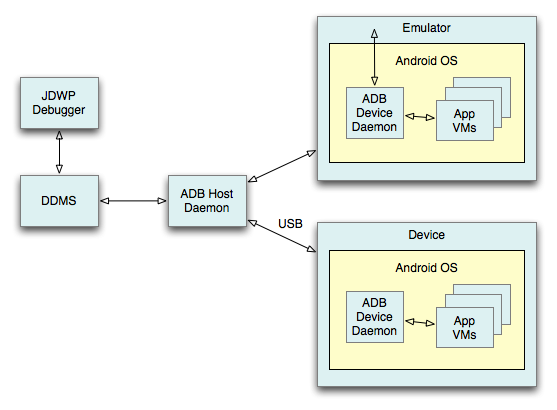
Это собственно его поток. Не стоит беспокоиться его появлению, он создается только при отладке приложения.
Вы также можете наблюдать за вашими действующими потоками и выявить утечку памяти, если какой-то из ваших потоков присутствует в списке в двух экземплярах (естественно, если так не задумано). Допустим, вы повернули экран, но при этом забыли грамотно обработать закрытие потока, после чего создали его копию. В списке вы увидите оба таких потока. Я запустил обычный поток в onCreate() и повернул экран, не останавливая прошлый, и получил такую картину.

Пожалуй, по вкладке с потоками всё. Но эта информация тесно связана с продолжением статьи.
Нам доступен инструмент для отладки кучи. Для этого также следует выбрать необходимый процесс и выбрать «update heap».

Теперь нам доступна информация о распределении динамической памяти в нашем процессе. Запускаем сборку мусора (Cause GC) и смотрим что осталось.
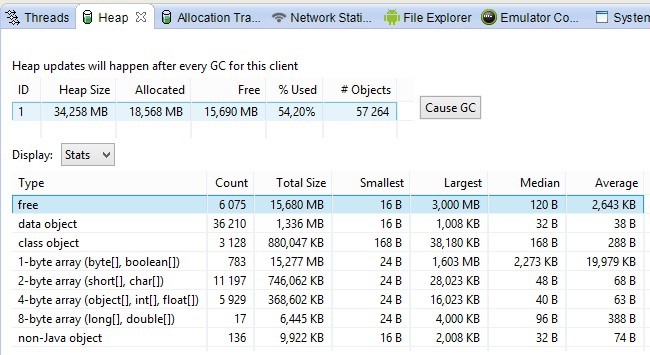
Тут все довольно просто:
В нижней части скриншота, показано распределение объектов по размеру и типу.
Heap Size может быть увеличен по необходимости самой виртуальной машиной. Порой достаточно нескольких минут слежения за ним, чтобы понять, что у вас утечка памяти.
Приведу пример. В одном из проектов я использую слушатель Broadcast сообщений. Я закомментировал unregisterReceiver в onPause
Сам BroadcastReceiver зарегистрирован через LocalBroadcastManager
Он позволяет бросать сообщения только в рамках одного процесса. Это приведет к удержанию Activity, что определенно отразится на куче. Так как я работаю в своем проекте с картографическим сервисом, то это приведет к удержанию карты и всех тайлов, которые закешированы, поэтому результат быстро будет заметен.
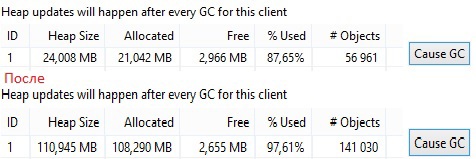
В верхней части рисунка показан первый старт приложения. Далее я 11 раз поворачивал экран, после чего heap довольно сильно увеличился. На 12 раз приложение перестало отвечать. Увеличивающийся heap — это палка о двух концах. С одной стороны хорошо, что он может так неслабо увеличиваться (зависит свободной памяти), с другой стороны, приложение может долго не падать и будет медленно работать, раздражая пользователя. Конечно же анализ кучи не покажет где у вас утечка, но даст понять что она всё же есть, а это уже неплохо.
Куда больше информации нам может дать Allocation tracker. Он позволяет отследить, какие объекты были созданы у выбранного процесса за выбранный промежуток времени, где можно посмотреть какие объекты создавались чаще, их размер, поток который их создавал и стек вызова.

Выбираем «Start track», после чего производим действия с приложением, которые хотим проанализировать, далее жмем «Get Allocations». Снизу появится список объектов, которые были созданы за этот период времени.
На данном скриншоте объекты отсортированы по порядку их инициализации или по времени создания, не знаю как лучше выразиться. Вы можете отсортировать ваши объекты любым удобным способом, просто нажав на название столбца. Доступная информация:
Мы можем выбрать любой объект и посмотреть весь его стек вызова. Таким образом, можно получить информацию о том, где создаются объекты, как часто, их размер и принять соответствующие меры, ведь многим известно, что создание объекта – это дорогостоящая операция и её следует избегать.
Наконец-то я добрался до своего любимого инструмента для анализа кода, «Method Profiling». Данный инструмент позволяет анализировать время, которое было затрачено методами на свою работу. Тем самым, мы можем понять узкие места в нашем коде и оптимизировать их.
Покажу простенький пример. В одном из наших проектов, приходилось иметь дело с NMEA протоколом. Это морской протокол, который предоставляет так сказать “сырые” данные о GPS. Я производил парсинг этих данных. Так выглядит одна из нужных мне строк.
Split по запятой и все прекрасно. Или нет? Выбираем необходимый процесс и запускаем Method Profiling.

Спустя 1-2 минуты (вы сами выбираете время, которое считаете нужным), останавливаем Method Profiling, после чего получаем trace наших методов, как показано на рисунке ниже.

В верхней части показан временной график работы потоков. Тут можно найти id потока, его имя и графическое представление времени его работы. Куда более интересна нижняя часть трейса. Слева, сверху вниз, показаны методы, которые потребляют максимальное кол-во процессорного времени;
В данной таблице заметно, мой метод тратит 23.5% общего времени. По нажатию на него, я получил такую картину

Очевидно, что всему виной метод split, который тратит 72% времени от общего времени метода, в котором он вызывался. Обычный переход на substring позволил оптимизировать данный метод в 2 раза.
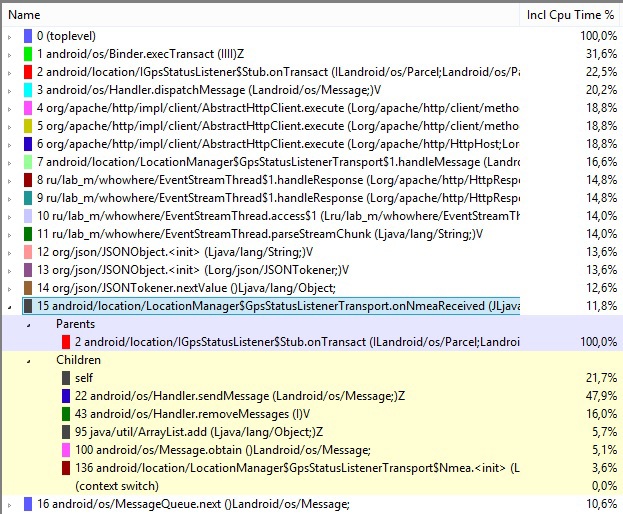
Наш метод опустился по загруженности на 15 позицию, а наверх поднялись другие, у которых также можно глянуть информацию, на что тратится время, посмотреть стек вызовов и придумать, как можно его оптимизировать. Также здесь присутствует и неявная оптимизация. Так как split плодит массив со строками, то теперь нагрузка на GC стала меньшей, следовательно и количество вызовов сборщика по определению будет меньшим, что благоприятно отразится как на скорости, так и на отзывчивости приложения. GC также можно найти в данном трейсе, если он запускался системой за время анализа кода.
Вы можете сортировать методы, также как и с allocation tracker, просто нажмите на название столбца.
Существует возможность анализировать только определенные участки кода в приложении. Для этого Android предоставляет нам два метода:
После завершения работы stopMethodTracing, trace будет доступен в /sdcard/trace_name.trace. Это бывает очень полезно, если мы хотим оптимизировать определенные участки кода, либо к примеру улучшить скорость старта приложения.
Пожалуй, на этом пока что всё. За сценой остался анализ дампа кучи (Dump HPROF File). Если вам будет интересно, то я постараюсь написать статью в таком же духе о таком замечательном инструменте, как MAT, который позволяет анализировать дамп кучи на предмет утечки и прочего. Он как раз и покажет все экземпляры моей активности, которые удерживались в куче при повороте экрана.
Я также обошел стороной инструмент Hierarchy Viewer, о котором на хабре уже есть статья. Надеюсь, статья вышла полезной и поможет вам оптимизировать ваши приложения.
Happy debugging!
- изучать информацию о работающих потоках;
- анализировать heap на количество свободной и занятой памяти;
- анализировать какие объекты чаще создаются, их размер и другое (Allocation tracker);
- находить проблемные участки кода, которые долго работают и требуют оптимизации (Method profiling). Это я советую знать всем.
Об этих вещах будет рассказано в рамках данной статьи. И для справки, менее интересное, что довольно тривиально и о чем НЕ будет рассказано в рамках данной статьи:
- работать с файловой системой эмулятора или устройства;
- находить информацию об ошибках (привет LogCat);
- эмулировать звонки/смс/местоположение;
- использовать инструмент Network Statistics.
Threads
DDMS содержит инструмент, который позволяет нам анализировать информацию по каждому процессу и его потокам. Достаточно выделить необходимый процесс нашего приложения и нажать «update threads».
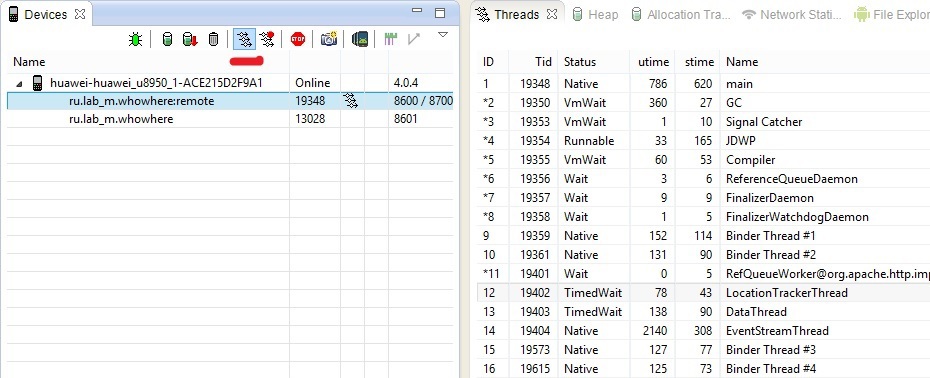
Справа вы можете увидеть вкладку «Threads» и работающие потоки выбранного процесса. По каждому потоку доступна следующая информация:
- Id – уникальный идентификатор потока, назначенный виртуальной машиной. Если рядом символ звездочки, то это демон-поток;
- Tid – id потока в Linux. Главный поток процесса будет содержать id процесса;
- Status – статус потока на данный момент;
- Utime – общее время, которое поток потратил на выполнение пользовательского кода. Единицы измерения jiffies, длительность которой определяется системой и обычно составляет 10ms;
- Stime – время, потраченное на выполнение системного кода. Единицы измерения также jiffies;
- Name – имя потока. Не забывайте давать осмысленные имена при создании потока.
Таким образом, мы можем понять, какой поток больше всего расходует процессорного времени. Тут следует сказать несколько слов о некоторых потоках.
GC – как все думаю догадались, это поток сборщика мусора. До Android 3 он недоступен для просмотра в потоках.
JDWP (Java Debug Wire Protocol) – протокол взаимодействия между дебагером и виртуальной машиной.
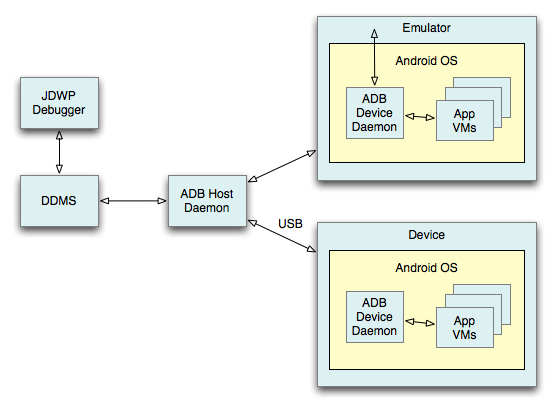
Это собственно его поток. Не стоит беспокоиться его появлению, он создается только при отладке приложения.
Вы также можете наблюдать за вашими действующими потоками и выявить утечку памяти, если какой-то из ваших потоков присутствует в списке в двух экземплярах (естественно, если так не задумано). Допустим, вы повернули экран, но при этом забыли грамотно обработать закрытие потока, после чего создали его копию. В списке вы увидите оба таких потока. Я запустил обычный поток в onCreate() и повернул экран, не останавливая прошлый, и получил такую картину.
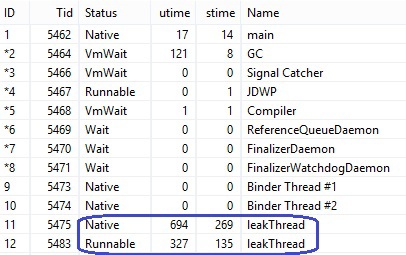
Пожалуй, по вкладке с потоками всё. Но эта информация тесно связана с продолжением статьи.
Heap
Нам доступен инструмент для отладки кучи. Для этого также следует выбрать необходимый процесс и выбрать «update heap».
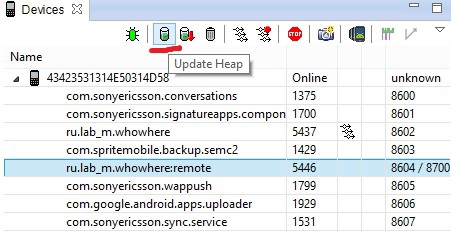
Теперь нам доступна информация о распределении динамической памяти в нашем процессе. Запускаем сборку мусора (Cause GC) и смотрим что осталось.
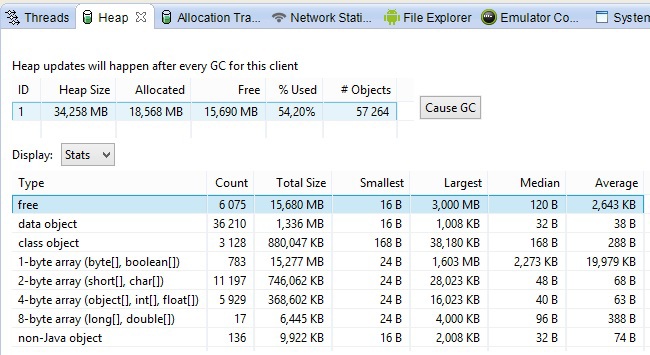
Тут все довольно просто:
- Heap size – это общий размер кучи, который выделил Android под данный процесс;
- Allocated – используемая память;
- Free – свободная память;
- Used – используемая в процентах память;
- Objects – общее кол-во объектов, которые составляют allocated размер.
В нижней части скриншота, показано распределение объектов по размеру и типу.
Heap Size может быть увеличен по необходимости самой виртуальной машиной. Порой достаточно нескольких минут слежения за ним, чтобы понять, что у вас утечка памяти.
Приведу пример. В одном из проектов я использую слушатель Broadcast сообщений. Я закомментировал unregisterReceiver в onPause
// LocalBroadcastManager.getInstance(this).unregisterReceiver(receiver);
Сам BroadcastReceiver зарегистрирован через LocalBroadcastManager
LocalBroadcastManager.getInstance(this).registerReceiver(receiver, intentFilter);
Он позволяет бросать сообщения только в рамках одного процесса. Это приведет к удержанию Activity, что определенно отразится на куче. Так как я работаю в своем проекте с картографическим сервисом, то это приведет к удержанию карты и всех тайлов, которые закешированы, поэтому результат быстро будет заметен.
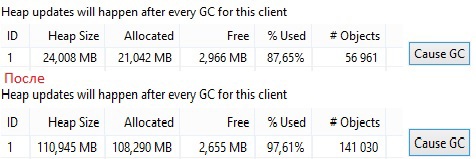
В верхней части рисунка показан первый старт приложения. Далее я 11 раз поворачивал экран, после чего heap довольно сильно увеличился. На 12 раз приложение перестало отвечать. Увеличивающийся heap — это палка о двух концах. С одной стороны хорошо, что он может так неслабо увеличиваться (зависит свободной памяти), с другой стороны, приложение может долго не падать и будет медленно работать, раздражая пользователя. Конечно же анализ кучи не покажет где у вас утечка, но даст понять что она всё же есть, а это уже неплохо.
Allocation tracker
Куда больше информации нам может дать Allocation tracker. Он позволяет отследить, какие объекты были созданы у выбранного процесса за выбранный промежуток времени, где можно посмотреть какие объекты создавались чаще, их размер, поток который их создавал и стек вызова.
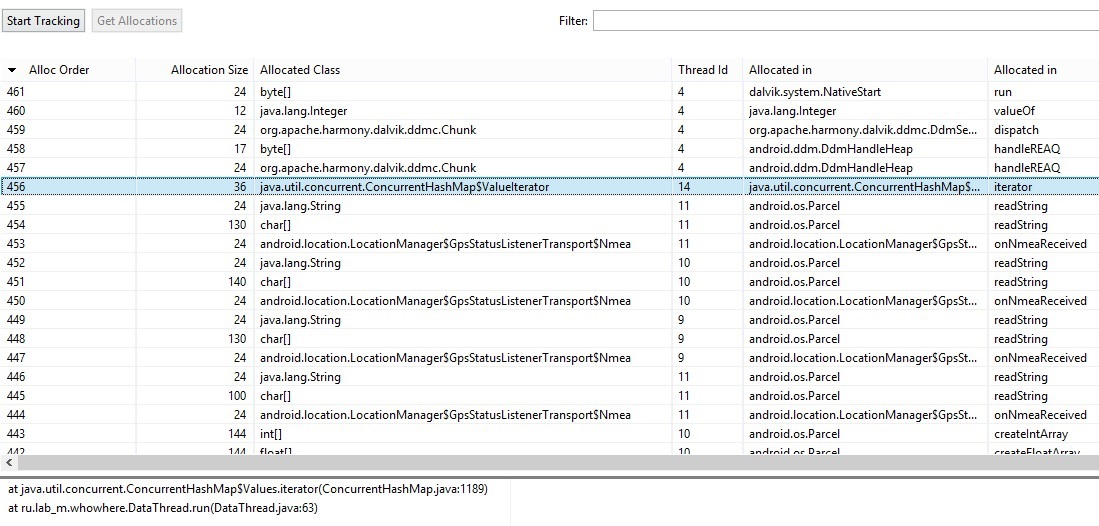
Выбираем «Start track», после чего производим действия с приложением, которые хотим проанализировать, далее жмем «Get Allocations». Снизу появится список объектов, которые были созданы за этот период времени.
На данном скриншоте объекты отсортированы по порядку их инициализации или по времени создания, не знаю как лучше выразиться. Вы можете отсортировать ваши объекты любым удобным способом, просто нажав на название столбца. Доступная информация:
- Alloc order – номер созданного объекта;
- Allocation Size – размер объекта;
- Allocated Class – тип объекта;
- Thread Id – id потока, назначенный виртуальной машиной (не путать с Tid);
- Allocated Id – класс и метод, в котором был создан объект.
Мы можем выбрать любой объект и посмотреть весь его стек вызова. Таким образом, можно получить информацию о том, где создаются объекты, как часто, их размер и принять соответствующие меры, ведь многим известно, что создание объекта – это дорогостоящая операция и её следует избегать.
Method profiling
Наконец-то я добрался до своего любимого инструмента для анализа кода, «Method Profiling». Данный инструмент позволяет анализировать время, которое было затрачено методами на свою работу. Тем самым, мы можем понять узкие места в нашем коде и оптимизировать их.
Покажу простенький пример. В одном из наших проектов, приходилось иметь дело с NMEA протоколом. Это морской протокол, который предоставляет так сказать “сырые” данные о GPS. Я производил парсинг этих данных. Так выглядит одна из нужных мне строк.
$GPGGA,123519,4807.038,N,01131.000,E,1,08,0.9,545.4,M,46.9,M,,*47
Split по запятой и все прекрасно. Или нет? Выбираем необходимый процесс и запускаем Method Profiling.
Спустя 1-2 минуты (вы сами выбираете время, которое считаете нужным), останавливаем Method Profiling, после чего получаем trace наших методов, как показано на рисунке ниже.
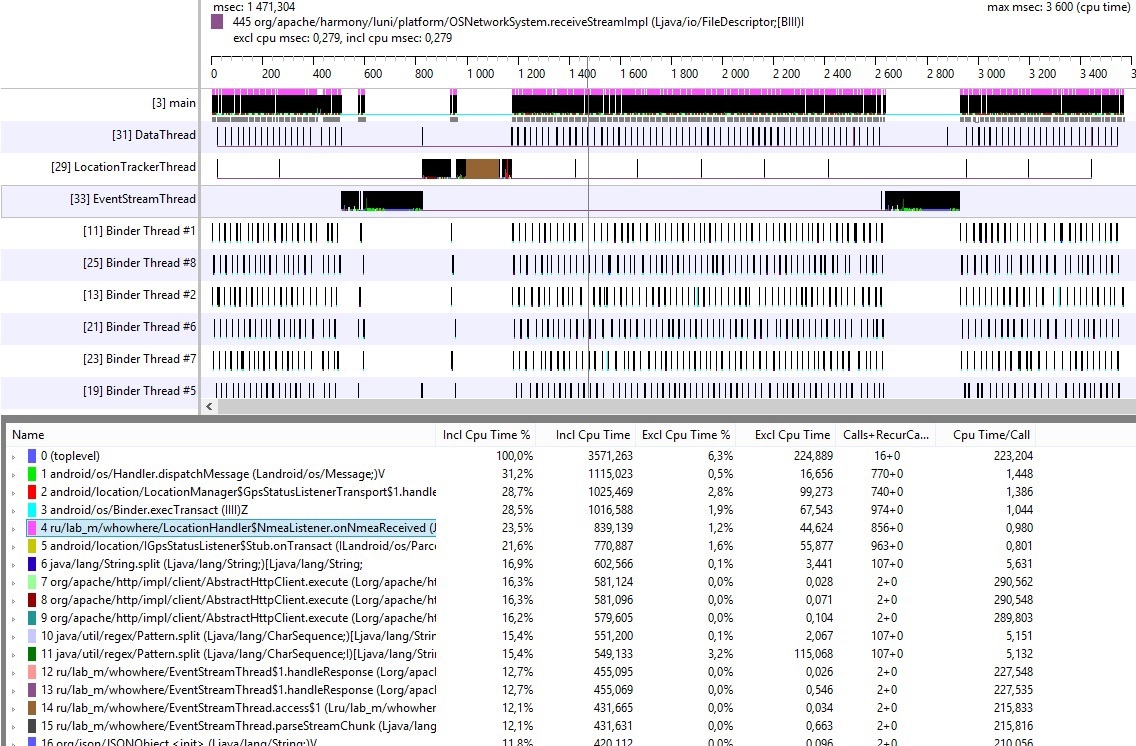
В верхней части показан временной график работы потоков. Тут можно найти id потока, его имя и графическое представление времени его работы. Куда более интересна нижняя часть трейса. Слева, сверху вниз, показаны методы, которые потребляют максимальное кол-во процессорного времени;
- Incl Cpu Time % — время, которое тратится на выполнение собственного кода в методе, плюс время, которое тратится на выполнение других методов в данном методе (%);
- Excl Cpu Time % — время, которое тратится на выполнение собственного кода в методе (%);
- Incl Cpu Time и Excl Cpu Time – тоже самое, только единицы измерения миллисекунды;
- Calls+Recur Calls/Total – количество вызовов и их повторов;
- Time/Call – общее затраченное время (ms).
В данной таблице заметно, мой метод тратит 23.5% общего времени. По нажатию на него, я получил такую картину
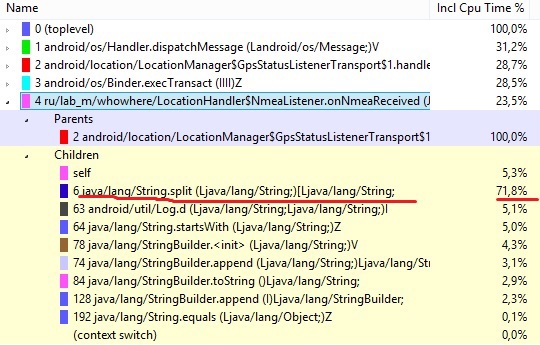
Очевидно, что всему виной метод split, который тратит 72% времени от общего времени метода, в котором он вызывался. Обычный переход на substring позволил оптимизировать данный метод в 2 раза.
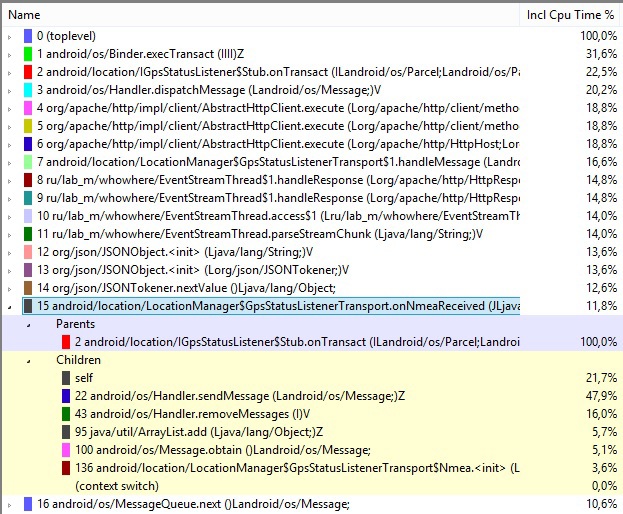
Наш метод опустился по загруженности на 15 позицию, а наверх поднялись другие, у которых также можно глянуть информацию, на что тратится время, посмотреть стек вызовов и придумать, как можно его оптимизировать. Также здесь присутствует и неявная оптимизация. Так как split плодит массив со строками, то теперь нагрузка на GC стала меньшей, следовательно и количество вызовов сборщика по определению будет меньшим, что благоприятно отразится как на скорости, так и на отзывчивости приложения. GC также можно найти в данном трейсе, если он запускался системой за время анализа кода.
Вы можете сортировать методы, также как и с allocation tracker, просто нажмите на название столбца.
Существует возможность анализировать только определенные участки кода в приложении. Для этого Android предоставляет нам два метода:
android.os.Debug.startMethodTracing(“trace_name”);
и
android.os.Debug.stopMethodTracing();
После завершения работы stopMethodTracing, trace будет доступен в /sdcard/trace_name.trace. Это бывает очень полезно, если мы хотим оптимизировать определенные участки кода, либо к примеру улучшить скорость старта приложения.
Пожалуй, на этом пока что всё. За сценой остался анализ дампа кучи (Dump HPROF File). Если вам будет интересно, то я постараюсь написать статью в таком же духе о таком замечательном инструменте, как MAT, который позволяет анализировать дамп кучи на предмет утечки и прочего. Он как раз и покажет все экземпляры моей активности, которые удерживались в куче при повороте экрана.
Я также обошел стороной инструмент Hierarchy Viewer, о котором на хабре уже есть статья. Надеюсь, статья вышла полезной и поможет вам оптимизировать ваши приложения.
Happy debugging!
