Comments 83
Колоссальная работа,
1. что значит «p_»?
2. В ByteArrayCompareWithSimplest зря закешировали длину массива, т.к. это немного ухудшает производительность
3. В каком режиме вы компилировали программу? Release или Debug? с оптимизацией или без?
1. что значит «p_»?
2. В ByteArrayCompareWithSimplest зря закешировали длину массива, т.к. это немного ухудшает производительность
3. В каком режиме вы компилировали программу? Release или Debug? с оптимизацией или без?
За счет чего кеширование длины ухудшает производительность?
Да, именно так, но только в случае с массивами.
1. Компилятор знает, что длина массива не изменяется при итерировании.
2. Если не кэшировать длину, то используется специальная IL-инструкция ldlen, если кэшировать, то используется переменная, а это медленнее.
Вот тут подробнее: habrahabr.ru/post/192130/
1. Компилятор знает, что длина массива не изменяется при итерировании.
2. Если не кэшировать длину, то используется специальная IL-инструкция ldlen, если кэшировать, то используется переменная, а это медленнее.
Вот тут подробнее: habrahabr.ru/post/192130/
> что значит «p_»?
Это у меня так параметры именуются. Их так проще отличить от полей и локальных переменных. Кстати, многие заблуждаются, но это не Венгерская нотация, а нечто иное, т.к. Венгенская нотация оговаривает префиксы в зависимости от типа (или размера) переменой. Чтобы понять отличие, достаточно взглянуть на имена параметров WinAPI'шных функций, там именно она. Например "LPCTSTR lpFileName".
Венгерская нотация затрудняет рефакторинг (при изменении типа приходится переименовывать все переменные), а мои префиксы — нет.
>… зря закешировали длину массива, т.к. это немного ухудшает производительность
Не ухудшает. Только что специально перепроверил (перекомпилил, посмотрел дизасм). Код у вас есть — проверьте сами.
>В каком режиме вы компилировали программу…
Релиз — дебаг в таких эксперимента не интересен.
Это у меня так параметры именуются. Их так проще отличить от полей и локальных переменных. Кстати, многие заблуждаются, но это не Венгерская нотация, а нечто иное, т.к. Венгенская нотация оговаривает префиксы в зависимости от типа (или размера) переменой. Чтобы понять отличие, достаточно взглянуть на имена параметров WinAPI'шных функций, там именно она. Например "LPCTSTR lpFileName".
Венгерская нотация затрудняет рефакторинг (при изменении типа приходится переименовывать все переменные), а мои префиксы — нет.
>… зря закешировали длину массива, т.к. это немного ухудшает производительность
Не ухудшает. Только что специально перепроверил (перекомпилил, посмотрел дизасм). Код у вас есть — проверьте сами.
>В каком режиме вы компилировали программу…
Релиз — дебаг в таких эксперимента не интересен.
Не могли бы вы выложить весь ваш исходный код в какой-нибудь открытый репозиторий, например, с помощью на GitHub?
Было бы интересно посмотреть и, чем черт не шутит, прогнать тесты у себя.
P.S.
Спасибо за статью, вы провели действительно большую работу!
Было бы интересно посмотреть и, чем черт не шутит, прогнать тесты у себя.
P.S.
Спасибо за статью, вы провели действительно большую работу!
Вот так пойдёт? files.rsdn.ru/67254/ConsoleApplication22014_03_20151019.zip
Там кода совсем чуть-чуть, и он практически весь приведён в статье, поэтому я изначально не стал его выкладывать никуда.
Там кода совсем чуть-чуть, и он практически весь приведён в статье, поэтому я изначально не стал его выкладывать никуда.
Спасибо, сойдет!
Я запустил вашу программу со значениями констатнт указанными вами в статье и получил следующее.
Мои результаты, почему-то очень сильно отличаются от ваших.
Что я использую:
Windows 7 x64 со всеми последними обновлениями для .Net 4.0 Client Profile и настройками Microsoft Visual Studio 2012 по-умолчанию, и только для конфигурации x86.
Я запустил вашу программу со значениями констатнт указанными вами в статье и получил следующее.
Результаты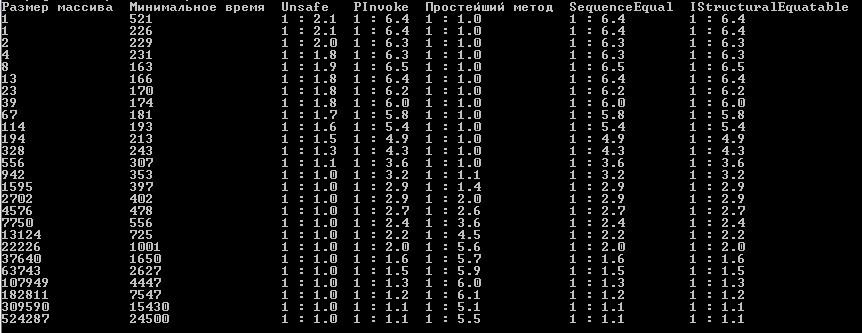

Мои результаты, почему-то очень сильно отличаются от ваших.
Что я использую:
Windows 7 x64 со всеми последними обновлениями для .Net 4.0 Client Profile и настройками Microsoft Visual Studio 2012 по-умолчанию, и только для конфигурации x86.
Windows 8.1 x64, VS 2013, все обновления.
.net 4 client
Размер массива Минимальное время Unsafe PInvoke Простейший метод SequenceEqual IStructuralEquatable
524288 11108 1 : 1.0 1 : 1.5 1 : 5.8 1 : 1.5 1 : 1.5
690001 13547 1 : 1.0 1 : 1.6 1 : 6.2 1 : 1.6 1 : 1.6
908093 18188 1 : 1.0 1 : 1.6 1 : 6.1 1 : 1.6 1 : 1.6
1195118 23089 1 : 1.0 1 : 1.7 1 : 6.3 1 : 1.7 1 : 1.7
1572863 29947 1 : 1.0 1 : 1.7 1 : 6.5 1 : 1.7 1 : 1.7
.net 4.5.1
Размер массива Минимальное время Unsafe PInvoke Простейший метод SequenceEqual IStructuralEquatable
524288 11048 1 : 1.0 1 : 1.6 1 : 5.9 1 : 1.6 1 : 1.6
690001 14056 1 : 1.0 1 : 1.6 1 : 6.1 1 : 1.6 1 : 1.6
908093 17823 1 : 1.0 1 : 1.6 1 : 6.3 1 : 1.6 1 : 1.6
1195118 23763 1 : 1.0 1 : 1.6 1 : 6.2 1 : 1.6 1 : 1.6
1572863 30210 1 : 1.0 1 : 1.7 1 : 6.3 1 : 1.7 1 : 1.7 Компиляция изначально 32-битного приложения в 64 бита умножает необходимую для него память и снижает его производительностьРади интереса прогнал ваш код на x86-64:
.net 4.5.1
Размер массива Минимальное время Unsafe PInvoke Простейший метод SequenceEqual IStructuralEquatable
524288 8392 1 : 1.5 1 : 1.0 1 : 8.9 1 : 1.0 1 : 1.0
690001 11161 1 : 1.5 1 : 1.0 1 : 8.8 1 : 1.0 1 : 1.0
908093 14559 1 : 1.5 1 : 1.0 1 : 9.0 1 : 1.0 1 : 1.0
1195118 18972 1 : 1.5 1 : 1.0 1 : 9.0 1 : 1.0 1 : 1.0
1572863 24114 1 : 1.6 1 : 1.0 1 : 9.3 1 : 1.0 1 : 1.0 Интересно, то, что у нас получились результаты, соврешенно отличные от авторских.
Причем, производительность IStructuralEquatable явно не сильно отстает от своих конкурентов(тем более на три порядка), а вашем втором примере она вообще показывает лучший результат, даже в абсолютном сравнении!
Причем, производительность IStructuralEquatable явно не сильно отстает от своих конкурентов(тем более на три порядка), а вашем втором примере она вообще показывает лучший результат, даже в абсолютном сравнении!
Автор явно что-то делал не так. Такие порядки различия (1:261 по минимальному времени и… 1:216954 (o_O) по времени
Вообще, мне интересно, почему PInvoke/
IStructuralEquatable) можно объяснить только серьёзным изъяном в тестировании. Это я не говорю о том, что методика изначально неправильная — ни квантилей, ни прогрева кэша, ни сборки мусора…Вообще, мне интересно, почему PInvoke/
SequenceEqual/IStructuralEquatable в варианте x86-64 стали показывать совершенно другие результаты. Сходу не могу это объяснить :)1. Ваша нотация еще хуже «венгерской», т.к. она мешает intelli-sense. Для того, чтобы отличать параметры от полей и локальных переменных нужно использовать нормальную IDE (VS + ReSharper + Color Identifiers, например)
2. Ухудшает, см тут: habrahabr.ru/post/192130/
3. Как раз интересен, потому что компилируется разный CIL, (не) используются разные оптимизации, по разному работает GC. От этого даже может измениться поведение кода.
2. Ухудшает, см тут: habrahabr.ru/post/192130/
3. Как раз интересен, потому что компилируется разный CIL, (не) используются разные оптимизации, по разному работает GC. От этого даже может измениться поведение кода.
>Релиз — дебаг в таких эксперимента не интересен.
stackoverflow.com/a/4045073/259946
* Array index checking elimination. An important optimization when working with arrays (all .NET collection classes use an array internally). When the JIT compiler can verify that a loop never indexes an array out of bounds then it will eliminate the index check. Big one.
* Loop unrolling. Short loops (up to 4) with small bodies are eliminated by repeating the code in the loop body. Avoids the branch misprediction penalty.
* Code hoisting. Code inside a loop that is not affected by the loop can be moved out of the loop.
Вы не находите, что это именно то, о чем вы возмущаетесь в статье, что JIT этого не делает?
stackoverflow.com/a/4045073/259946
* Array index checking elimination. An important optimization when working with arrays (all .NET collection classes use an array internally). When the JIT compiler can verify that a loop never indexes an array out of bounds then it will eliminate the index check. Big one.
* Loop unrolling. Short loops (up to 4) with small bodies are eliminated by repeating the code in the loop body. Avoids the branch misprediction penalty.
* Code hoisting. Code inside a loop that is not affected by the loop can be moved out of the loop.
Вы не находите, что это именно то, о чем вы возмущаетесь в статье, что JIT этого не делает?
Мне дебаг был неинтересен именно потому, что я хотел самолично взглянуть на оптимизации JIT'ера.
И соответственно, я в статье показал, что:
*Array index checking elimination…
этого нет
* Loop unrolling.…
Этого тоже нет. Что может быть проще цикла с тремя действиями ( 1)проверка индекса, 2)чтение, 3)сравнение)?! Но нет, не JIT'ер его не развернул, он скомпилировал именно так, как я написал.
* Code hoisting.
Насчёт этого — не знаю. В плюсах — есть, здесь не интересовался.
И соответственно, я в статье показал, что:
*Array index checking elimination…
этого нет
* Loop unrolling.…
Этого тоже нет. Что может быть проще цикла с тремя действиями ( 1)проверка индекса, 2)чтение, 3)сравнение)?! Но нет, не JIT'ер его не развернул, он скомпилировал именно так, как я написал.
* Code hoisting.
Насчёт этого — не знаю. В плюсах — есть, здесь не интересовался.
Еще раз спрошу: вы уверены, что вы делали тесты в Release режиме? Потому что я у себя вижу стабильные 1000 лишних тиков при кэшированой длине, и в 1.5 раза медленнее, если навесить на методы [MethodImpl(MethodImplOptions.NoOptimization)].
>Еще раз спрошу: вы уверены, что вы делали тесты в Release режиме?
Абсолютно.
Абсолютно.
У меня самый «долгий тест» ~34000 тиков.
Ещё нужно учесть, что если скомпилировать программу в Release, но запустить её с отладчиком, jit-оптимизации не отработают. Для того, чтобы посмотреть оптимизированный asm, нужно запустить программу без отладчика, прогнать тесты и только тогда (например, пока программа ждёт в
Console.ReadKey()) приаттачиться отладчиком к внешнему процессу.Loop unrolling делается, но не всегда. Выбор конкретной стратегии развёртки цикла зависит от:
— Архитектуры x86/x64
— Количество итераций цикла
— Размещение массива в памяти.
Можете взглянуть на мою заметку по этому поводу, там некоторые нюансы освещены. Для n=2^k под x64 развёртка делается практически всегда.
— Архитектуры x86/x64
— Количество итераций цикла
— Размещение массива в памяти.
Можете взглянуть на мою заметку по этому поводу, там некоторые нюансы освещены. Для n=2^k под x64 развёртка делается практически всегда.
Спасибо за статью! На самом деле это хорошая идея для продукта — написать свой nGen, который будет транслировать MSIL в понятный для Intel C++ Compiler формат. Есть ли что-то типа LLVM для Intel?
Статья великолепная, браво! Есть пара мыслей на ее счет:
1. В что если в способе «PInvoke, для CRT функции memcmp()» тоже использовать fixed + unsafe и уже передавать в memcmp непосредственно указатели? Думается, я меньше вашего разбираюсь в .NET'e, но это место выглядит подозрительным)
2. Мой опыт со студийным (MS VS) компилятором убедил меня в том, что в Release сборке он «божит», оптимизации порой фантастические. Можете поделиться пруфом, что интеловский круче?)
1. В что если в способе «PInvoke, для CRT функции memcmp()» тоже использовать fixed + unsafe и уже передавать в memcmp непосредственно указатели? Думается, я меньше вашего разбираюсь в .NET'e, но это место выглядит подозрительным)
2. Мой опыт со студийным (MS VS) компилятором убедил меня в том, что в Release сборке он «божит», оптимизации порой фантастические. Можете поделиться пруфом, что интеловский круче?)
1) 100 с лишним строк на асме — это мало, почти ничто, а основная масса кода, который выполняется по пути к неуправляемому — проверка всяких security, и её исключить вряд ли получится. Т.е. очень сомнительно, что там что-то можно оптимизировать. А т.к. подобное развлечение весьма утомительно, то я этим заниматься не буду. Если было бы необходимо выжать максимум из машины, то я бы попробовал взглянуть в сторону грязных хаков (напр. пропатчить какую-нибудь функцию, или делегат). Однако всё это путь в никуда: завтра где-нибудь в исходниках CLR подправят выравнивание, или поледобавят, или баг какой-нибудь исправят, и всё перестанет работать.
2) Ни разу не видел чтобы он глючил. Видел, что в дебажном и релизном коде финализаторы в другом порядке вызываются (и ещё что-то там про финализаторы было), но всё всегда работало корректно, по крайней мере CLR.
2) Ни разу не видел чтобы он глючил. Видел, что в дебажном и релизном коде финализаторы в другом порядке вызываются (и ещё что-то там про финализаторы было), но всё всегда работало корректно, по крайней мере CLR.
Выравнивание не подправят. Суровая объективная реальность современных процессоров. У всех компиляторов сейчас выравнивание по-умолчанию — минимум 32 бита. Так что в этом плане можно не бояться.
В что если в способе «PInvoke, для CRT функции memcmp()» тоже использовать fixed + unsafe и уже передавать в memcmp непосредственно указатели?Ничего особенного не случится. Для массива байт маршаллер и так фиксирует (pin) массив в памяти и передаёт в unmanaged-код обычный указатель.
Подробнее:
— Copying and Pinning (Formatted Blittable Classes)
— Blittable and Non-Blittable Types
Не хотите изучить еще и RtlCompareMemory?
Перед изучение функции протестировал, предварительно выставив атрибут SuppressUnmanagedCodeSecurity для функции
Функция оказалась на удивление маленькой, она вся здесь, под катом. В функции активно используются строковые операции сравнения c префиксом повторения (
Например, сравнение DWORD'ов выглядит так:
Почти так же можно представить побайтное сравнение.
То, что функция оказалась медленнее unsafe я могу обяснить только тем, что в unsafe за одну итерацию цикла читаются два соседних DWORD'а для каждого массива, а здесь только один (цикл не развёрнут).
memcmp() и RtlCompareMemory()Результаты
Размер массива Минимальное время Unsafe MemCMP RtlCompareMemory Простейший метод
1 279 1 : 001,7 1 : 003,2 1 : 008,8 1 : 001,0
1 278 1 : 001,8 1 : 003,2 1 : 008,9 1 : 001,0
2 325 1 : 001,3 1 : 002,9 1 : 006,1 1 : 001,0
4 374 1 : 001,1 1 : 002,6 1 : 009,0 1 : 001,0
7 422 1 : 001,0 1 : 002,5 1 : 007,0 1 : 001,1
12 426 1 : 001,0 1 : 002,5 1 : 006,9 1 : 001,7
19 490 1 : 001,0 1 : 002,2 1 : 006,0 1 : 001,9
32 560 1 : 001,0 1 : 002,0 1 : 005,3 1 : 002,7
54 622 1 : 001,0 1 : 002,0 1 : 005,4 1 : 003,8
89 802 1 : 001,0 1 : 001,7 1 : 004,3 1 : 004,7
147 1092 1 : 001,0 1 : 001,5 1 : 003,7 1 : 004,0
242 1571 1 : 001,0 1 : 001,4 1 : 003,0 1 : 004,2
398 2328 1 : 001,0 1 : 001,4 1 : 002,7 1 : 004,5
657 3664 1 : 001,0 1 : 001,2 1 : 002,2 1 : 004,6
1082 5519 1 : 001,0 1 : 001,2 1 : 002,1 1 : 005,0
1782 8554 1 : 001,0 1 : 001,2 1 : 002,1 1 : 005,3
2936 13520 1 : 001,0 1 : 001,2 1 : 002,0 1 : 005,5
4837 21771 1 : 001,0 1 : 001,2 1 : 002,0 1 : 005,6
7967 35464 1 : 001,0 1 : 001,2 1 : 001,9 1 : 005,7
13124 58073 1 : 001,0 1 : 001,2 1 : 001,9 1 : 005,7
21618 96457 1 : 001,0 1 : 001,2 1 : 001,9 1 : 005,7
35610 167952 1 : 001,0 1 : 001,1 1 : 001,8 1 : 005,4
58656 285282 1 : 001,0 1 : 001,1 1 : 001,8 1 : 005,3
96617 534712 1 : 001,0 1 : 001,1 1 : 001,6 1 : 004,7
159146 924569 1 : 001,0 1 : 001,1 1 : 001,6 1 : 004,5
262143 1520968 1 : 001,0 1 : 001,1 1 : 001,6 1 : 004,5
Окошки дебагера (смотрите версию библиотеки)

Функция оказалась на удивление маленькой, она вся здесь, под катом. В функции активно используются строковые операции сравнения c префиксом повторения (
cmps*). Например, сравнение DWORD'ов выглядит так:
while
(
( 0 != ecx )
& ( 0 == Compare( (DWORD) RAM[esi], (DWORD) RAM[edi] ) )
)
{
--ecx;
edi += 4;
esi += 4;
}
Почти так же можно представить побайтное сравнение.
То, что функция оказалась медленнее unsafe я могу обяснить только тем, что в unsafe за одну итерацию цикла читаются два соседних DWORD'а для каждого массива, а здесь только один (цикл не развёрнут).
Дизассемблер с комментариями
77A52780 /$ 56 push esi ; сохранить значения регистров в стеке
77A52781 |. 57 push edi
77A52782 |. FC cld ; DF <-- 0
77A52783 |. 8B7424 0C mov esi, [esp+0C] ; esi <-- Source1
77A52787 |. 8B7C24 10 mov edi, [esp+10] ; edi <-- Source2
77A5278B |. 8B4C24 14 mov ecx, [esp+14] ; ecx <-- SIZE_T
77A5278F |. C1E9 02 shr ecx, 2 ; ecx <-- (ecx >> 2) ( делим счётчик на 4)
77A52792 |.- 74 04 jz short smaller_4 ;
77A52794 |. F3:A7 repe cmpsd ; В цикле по ecx сравниваем DWORD'ы;
77A52796 |.- 75 16 jne short not_zero ; if ( !ZF ) goto not_zero;
smaller_4:
77A52798 |> 8B4C24 14 mov ecx, [esp+14] ; ecx <-- SIZE_T
77A5279C |. 83E1 03 and ecx, 00000003 ; ecx &= 3
77A5279F |.- 74 04 jz short return_SIZE_T ; if ( ZF ) goto return_SIZE_T;
77A527A1 |. F3:A6 repe cmpsb ; в цикле сравниваем байты
77A527A3 |.- 75 16 jne short found_difference
return_SIZE_T:
77A527A5 |> 8B4424 14 mov eax, [esp+14] ; eax <-- SIZE_T
77A527A9 |. 5F pop edi ; восстанавливаем значения регистров
77A527AA |. 5E pop esi
77A527AB |. C2 0C00 ret 0C ; return eax
not_zero:
77A527AE |> 83EE 04 sub esi, 4 ; esi -= 4
77A527B1 |. 83EF 04 sub edi, 4 ; edi -= 4
77A527B4 |. B9 04000000 mov ecx, 4 ; ecx -= 4
77A527B9 |. F3:A6 repe cmpsb ; в цикле сравниваем байты
found_difference:
77A527BB |> 4E dec esi ; --esi
77A527BC |. 2B7424 0C sub esi, [esp+0C] ; esi <-- (esi - Source1)
77A527C0 |. 8BC6 mov eax, esi ; eax <-- esi
77A527C2 |. 5F pop edi ; восстанавливаем значения регистров
77A527C3 |. 5E pop esi
77A527C4 \. C2 0C00 ret 0C ; return eax
Вот такое работает в полтора раза быстрее, чем SequentalEqual:
!a.Where((t, i) => t != b[i]).Any()
!a.Where((t, i) => t != b[i]).Any()
Спасибо за статью. Было бы интересно посмотреть на сравнение с x64.
И еще одна цитата на счет JIT, просто на заметку:
Мои опыты еще на .Net 2.0 показали, что буквально любым усложнением можно нарушить тонкую грань, после которой JIT и/или компилятор перестает оптимизировать что-либо. Показательный пример когда есть приватный метод, берущий на вход IList<byte> и пробегающий по элементам, но используется только с byte[], а затем добавляется где-то еще код с LinkedList<byte> с вызовом этого метода и все начинает работать медленнее — компилятор переделывает метод на итераторы и страдает производительность той части, которая не менялась.
The good news is that we do eliminate bounds checks for what we believe to be the most common form of array accesses: accesses that occur within a loop over all the indices of the loop. So, there is no dynamic range check for the array access in this program:
static void Test_SimpleAscend(int[] a) {
for (int i = 0; i < a.Length; i++)
a[i] = i; // We get this.
}
Unfortunately, we do not eliminate the range check for the descending version of this loop:
static void Test_SimpleDescend(int[] a) {
for (int i = a.Length — 1; i >= 0; i--)
a[i] = i; // We DO NOT get this.
}
Мои опыты еще на .Net 2.0 показали, что буквально любым усложнением можно нарушить тонкую грань, после которой JIT и/или компилятор перестает оптимизировать что-либо. Показательный пример когда есть приватный метод, берущий на вход IList<byte> и пробегающий по элементам, но используется только с byte[], а затем добавляется где-то еще код с LinkedList<byte> с вызовом этого метода и все начинает работать медленнее — компилятор переделывает метод на итераторы и страдает производительность той части, которая не менялась.
буквально любым усложнением можно нарушить тонкую грань
Косвенно в тему Вашему посту расскажу свою историю.
Однажды на работе зашел разговор на тему оптимизаций. Поведали историю о том, как один человек отстаивал свою точку зрения против отдела (~10 человек). Он утверждал, что любой код с заранее известными исходными данными компилятор студии в релизе свернет до mov eax, <результат>. И тогда он победил — писали циклы с тремя уровнями вложенности, хитрили, но не смогли побороть это поведение. Естественно, я тоже решил проверить, и с первой попытки написал for одного уровня вложенности, который компилятор не смог на стадии компиляции вычислить. У меня получилось эту тонкую грань перейти.
Вообще, оптимизации в компиляторах это крайне сложная часть computer science.
Вот такой unsafe код где-то в 1.5 раза быстрее вашего
if (x.Length != y.Length)
return false;
fixed (byte* xp = x, yp = y)
{
int* xip = (int*) xp, yip = (int*) yp;
int b = 0;
int s = sizeof (int*);
var il = x.Length/s;
for (int i = 0; i < il; i++, b += s)
{
if (xip[i] != yip[i])
return false;
}
for (; b < x.Length; b ++)
{
if (x[b] != y[b])
return false;
}
}
return true;
if (x.Length != y.Length)
return false;
fixed (byte* xp = x, yp = y)
{
int* xip = (int*) xp, yip = (int*) yp;
int b = 0;
int s = sizeof (int*);
var il = x.Length/s;
for (int i = 0; i < il; i++, b += s)
{
if (xip[i] != yip[i])
return false;
}
for (; b < x.Length; b ++)
{
if (x[b] != y[b])
return false;
}
}
return true;
Вы хотели сказать:
В строке int s = sizeof(int*); у вас была ошибка, надо было без *, это совпадение что для x86 sizeof(int) == sizeof(int*).
public static unsafe bool CompareByteArrays(byte[] x, byte[] y)
{
if (x.Length != y.Length)
return false;
fixed (byte* xp = x, yp = y)
{
int* xip = (int*)xp, yip = (int*)yp;
int b = 0;
int s = sizeof(int);
var il = x.Length / s;
for (int i = 0; i < il; i++, b += s)
{
if (xip[i] != yip[i])
return false;
}
for (; b < x.Length; b++)
{
if (x[b] != y[b])
return false;
}
}
return true;
}
В строке int s = sizeof(int*); у вас была ошибка, надо было без *, это совпадение что для x86 sizeof(int) == sizeof(int*).
во втором цикле начальное значение b всегда будет равно il * s, нет смысла из-за этого добавлять второй счетчик в основной цикл, ведь уже для размера 1025 байт мы выполним 256 лишних сложений.
-del
64 бита умножает необходимую для него память и снижает его производительность
Возможность сразу сравнить 8 байт вместо 4 ой как снижает производительность, особенно в вашей задаче.
В .NET нативный метод string.equal использует, как мне помнится, как раз таки unsafe сравнение кусков памяти. Не пробовали его в своих тестах?
UFO just landed and posted this here
1) В процессе экспериментов с большими массивами и отладчиком, я закомментировал некоторые вызовы в MeasurementsResults DoMeasurements().
2) Метод PrepareTestData(int p_ArraySize) поправьте на тот, что в статье. Он был исправлен с той же целью.
3) Константы тоже несколько отличаются, например private const int StartArraySize = 512 * 1024;
3) Метод CompareArraysWithPInvokeMethod() тоже был изменён, в исследовательских целях. Однако это не столь сильно должно сказаться на итоговых данных.
Посмотрите, поправьте, попробуйте.
Посыпаю голову пеплом. Надо было поле получения итоговой таблицы, зазиповать исходники.
2) Метод PrepareTestData(int p_ArraySize) поправьте на тот, что в статье. Он был исправлен с той же целью.
3) Константы тоже несколько отличаются, например private const int StartArraySize = 512 * 1024;
3) Метод CompareArraysWithPInvokeMethod() тоже был изменён, в исследовательских целях. Однако это не столь сильно должно сказаться на итоговых данных.
Посмотрите, поправьте, попробуйте.
Посыпаю голову пеплом. Надо было поле получения итоговой таблицы, зазиповать исходники.
О, ну здрасьте!
(Я извиняюсь, на большее чем 32К меня не хватило. Может быть, Saladin будет более усидчив :)
По поводу оптимизаций в
Как видите, clr.JIT_RngChkFail действительно присутствует. В данном случае это связано с тем, что
Итого:
1) В более простых случаях итерирования одного массива с помощью
2) Подумайте, почему 64-битный код и PInvoke оказываются быстрее (в лучшем случае — почти в 2 раза!), а unsafe код — медленнее ;)
result.SequenceEqualTime = result.IStructuralEquatableTime = result.PInvokeTime;(Я извиняюсь, на большее чем 32К меня не хватило. Может быть, Saladin будет более усидчив :)
.net 4.5.1 x86
Размер массива Минимальное время Unsafe PInvoke Простейший метод SequenceEqual IStructuralEquatable
32768 17168 1 : 1.0 1 : 1.8 1 : 7.5 1 : 128.2 1 : 2267.8 .net 4.5.1 x86-64
Размер массива Минимальное время Unsafe PInvoke Простейший метод SequenceEqual IStructuralEquatable
32768 10878 1 : 2.2 1 : 1.0 1 : 13.6 1 : 286.5 1 : 2732.5 По поводу оптимизаций в
Simplest:Осторожно! Ассемблер
if (p_BytesLeft.Length != p_BytesRight.Length)
00000000 push ebp
00000001 mov ebp,esp
00000003 push edi
00000004 push esi
00000005 push ebx
00000006 mov edi,edx
00000008 mov ebx,dword ptr [ecx+4]
0000000b cmp ebx,dword ptr [edi+4]
0000000e je 00000017
{
return false;
00000010 xor eax,eax
00000012 pop ebx
00000013 pop esi
00000014 pop edi
00000015 pop ebp
00000016 ret
}
for (int i = 0; i < p_BytesLeft.Length; ++i) //вот так, без всяких хитростей мы байты сравниваем
00000017 xor esi,esi
00000019 test ebx,ebx
0000001b jle 00000039
{
if (p_BytesLeft[i] != p_BytesRight[i])
0000001d movzx eax,byte ptr [ecx+esi+8]
00000022 cmp esi,dword ptr [edi+4]
00000025 jae 00000043
00000027 cmp al,byte ptr [edi+esi+8]
0000002b je 00000034
return false;
0000002d xor eax,eax
0000002f pop ebx
00000030 pop esi
00000031 pop edi
00000032 pop ebp
00000033 ret
for (int i = 0; i < p_BytesLeft.Length; ++i) //вот так, без всяких хитростей мы байты сравниваем
00000034 inc esi
00000035 cmp ebx,esi
00000037 jg 0000001D
}
return true;
00000039 mov eax,1
0000003e pop ebx
0000003f pop esi
00000040 pop edi
00000041 pop ebp
00000042 ret
00000043 call 73039937
00000048 int 3Как видите, clr.JIT_RngChkFail действительно присутствует. В данном случае это связано с тем, что
for ограничивает индекс границами p_BytesLeft, но этот же самый индекс используется для доступа к p_BytesRight. Таким образом, jit-компилятор не может убрать проверку. Да, мы выше проверяем длины массивов на равенство, но jit-компилятор сильно ограничен в возможностях оптимизации, поскольку его главная задача — быстро компилировать msil.Итого:
1) В более простых случаях итерирования одного массива с помощью
for, закэшировав длину массива, вы гарантированно ломаете оптимизации;2) Подумайте, почему 64-битный код и PInvoke оказываются быстрее (в лучшем случае — почти в 2 раза!), а unsafe код — медленнее ;)
Вот чёрт, а я только репозиторий создал и залил туда исправленные исходники. Ссылка.
Придется исправлять.
Придется исправлять.
Если ещё точнее, то одну из двух проверок на границы jit-компилятор всё-таки выкинул.
Так там ведь проверяются длины массивов на равенство. Было бы совсем печально, если бы он этого не сделал.
Так там ведь проверяются длины массивов на равенство.Это не помогает :) А вообще, вот, советую к прочтению: Array Bounds Check Elimination in the CLR.
Кроме того, в исходниках, которые вы запускали, в методе
Поправлю опечатки и исходники — обновлю статью, выложу корректные исходники.
Смотрите, проверяйте, перепроверяйте. Увы, у меня без таких обидных ляпов не получается…
DoMeasurements() присутствует строка: result.SequenceEqualTime = result.IStructuralEquatableTime = result.PInvokeTime;
Поправлю опечатки и исходники — обновлю статью, выложу корректные исходники.
Смотрите, проверяйте, перепроверяйте. Увы, у меня без таких обидных ляпов не получается…
Кстати, Эрик Липперт написал цикл замечательных статей о наиболее часто встречающихся ошибках при написании benchmark'ов. Рекомендую ознакомится: tech.pro/blog/1293/c-performance-benchmark-mistakes-part-one
UFO just landed and posted this here
Вы выходите за пределы массивов:
x1 += 2;
x2 += 2;x1, x2 — это int*, => вы передвинетесь на 8 байтов.UFO just landed and posted this here
UFO just landed and posted this here
В комментариях возникло много нареканий на чистоту эксперимента. Могу предложить вам воспользоваться моим решением для построения .NET-бенчмарков: BenchmarkDotNet. Автоматически выставится ProcessorAffinity, приоритеты для потоков, делается прогрев кеша, итоговые статистики считаются по некоторой выборке экспериментов и т.п.
Я воспользовался вашим советом и переписал тесты с использованием BenchmarkDotNet. Результат здесь.
Однако, видимо, я что-то сделал не так, потому что иногда ошибка(Err) достигает 1055,11%.
Не могли бы взглянуть, правильно ли использован класс BenchmarkCompetition?
P.S. не весь код из ваших примеров компилируется, не молги бы вы поправить его?
Однако, видимо, я что-то сделал не так, потому что иногда ошибка(Err) достигает 1055,11%.
Не могли бы взглянуть, правильно ли использован класс BenchmarkCompetition?
Результат запуска benchmark
E:\GitHub\Best-Way-to-Compare-Byte-Arrays-in-.Net\Benchmarks\bin\Release>Bench
rks.exe 1204000
BenchmarkCompetition: start
***** Simplest: start *****
WarmUp:
Ticks: 7706 ms: 2
Ticks: 4806 ms: 1
Ticks: 4700 ms: 1
Ticks: 4739 ms: 1
Stats: MedianTicks=4772, MedianMs=1, Error=63.96%
Result:
Ticks: 4726 ms: 1
Ticks: 4784 ms: 1
Ticks: 4775 ms: 1
Ticks: 4736 ms: 1
Ticks: 4749 ms: 1
Ticks: 4798 ms: 1
Ticks: 4865 ms: 1
Ticks: 4716 ms: 1
Ticks: 4785 ms: 1
Ticks: 4797 ms: 1
Stats: MedianTicks=4779, MedianMs=1, Error=03.16%
***** Simplest: end *****
***** SequenceEqual: start *****
WarmUp:
Ticks: 47214 ms: 15
Ticks: 41995 ms: 13
Ticks: 40726 ms: 13
Ticks: 41666 ms: 13
Stats: MedianTicks=41830, MedianMs=13, Error=15.93%
Result:
Ticks: 40865 ms: 13
Ticks: 40682 ms: 13
Ticks: 40700 ms: 13
Ticks: 41486 ms: 13
Ticks: 43097 ms: 14
Ticks: 41157 ms: 13
Ticks: 41609 ms: 13
Ticks: 43426 ms: 14
Ticks: 41876 ms: 13
Ticks: 40337 ms: 13
Stats: MedianTicks=41321, MedianMs=13, Error=07.66%
***** SequenceEqual: end *****
***** IStructuralEquatable: start *****
WarmUp:
Ticks: 700334 ms: 231
Ticks: 706967 ms: 234
Ticks: 703792 ms: 233
Stats: MedianTicks=703792, MedianMs=233, Error=00.95%
Result:
Ticks: 700858 ms: 232
Ticks: 706920 ms: 234
Ticks: 699373 ms: 231
Ticks: 698729 ms: 231
Ticks: 697655 ms: 230
Ticks: 699388 ms: 231
Ticks: 699028 ms: 231
Ticks: 696725 ms: 230
Ticks: 702334 ms: 232
Ticks: 695562 ms: 230
Stats: MedianTicks=699200, MedianMs=231, Error=01.63%
***** IStructuralEquatable: end *****
***** Unsafe: start *****
WarmUp:
Ticks: 5533 ms: 1
Ticks: 619 ms: 0
Ticks: 588 ms: 0
Ticks: 485 ms: 0
Ticks: 481 ms: 0
Ticks: 479 ms: 0
Stats: MedianTicks=536, MedianMs=0, Error=1055.11%
Result:
Ticks: 553 ms: 0
Ticks: 474 ms: 0
Ticks: 622 ms: 0
Ticks: 475 ms: 0
Ticks: 551 ms: 0
Ticks: 683 ms: 0
Ticks: 479 ms: 0
Ticks: 480 ms: 0
Ticks: 476 ms: 0
Ticks: 480 ms: 0
Stats: MedianTicks=480, MedianMs=0, Error=44.09%
***** Unsafe: end *****
***** PInvoke: start *****
WarmUp:
Ticks: 2076 ms: 0
Ticks: 619 ms: 0
Ticks: 568 ms: 0
Ticks: 557 ms: 0
Ticks: 564 ms: 0
Stats: MedianTicks=568, MedianMs=0, Error=272.71%
Result:
Ticks: 567 ms: 0
Ticks: 628 ms: 0
Ticks: 558 ms: 0
Ticks: 364 ms: 0
Ticks: 362 ms: 0
Ticks: 454 ms: 0
Ticks: 364 ms: 0
Ticks: 362 ms: 0
Ticks: 438 ms: 0
Ticks: 571 ms: 0
Stats: MedianTicks=446, MedianMs=0, Error=73.48%
***** PInvoke: end *****
BenchmarkCompetition: finish
Competition results:
Simplest : 1ms
SequenceEqual : 13ms
IStructuralEquatable : 231ms
Unsafe : 0ms
PInvoke : 0ms
P.S. не весь код из ваших примеров компилируется, не молги бы вы поправить его?
Ну там, где
А вот
Error=1055.11%, это warm up, можно в общем-то не обращать внимания.А вот
Error=73.48% PInvoke::Result (или 44.09% Unsafe::Result) — это звоночек.Сразу бросается в глаза большая ошибка: слишком малое время работы одного запуска бенчмарка. Увеличьте количество итераций. Время работы в районе 1–2ms не показывает вообще ничего, т.к. время работы бенчмарка сравнимо с временем накладных расходов (по запуску CLR, JIT-компиляции и т.п.) Нужно ЗНАЧИТЕЛЬНО увеличить время работы одного run-а. Да, в целом бенчмарк будет гоняться очень долго (особенно, с учётом нормального прогрева), вполне возможно что полный запуск всего займёт, скажем, час. Но зато у вас будут актуальные результаты на руках, которыми можно с чистой совестью делиться с общественностью.
Принято считать, что если Error>5%, то что-то пошло не так.
P.S. Ок, посмотрю что там за проблемы с компиляцией.
Принято считать, что если Error>5%, то что-то пошло не так.
P.S. Ок, посмотрю что там за проблемы с компиляцией.
Я немного непонял, насчет значительного времени увелечения одного прогона. Нужно увеличить время выполнения теста, то есть скажем пробовать сравнить очень большие массивы. Или всё-таки увеличить количество самих прогонов, например увеличив BenchmarkSettings.Instance.DefaultResultIterationCount скажем до 10 миллионов?
Я больше склоняюсь ко второму варианту.
Я больше склоняюсь ко второму варианту.
Тут нужно пробовать разные соотношения количества прогонов и размера массива. Нужно учитывать следующее:
1. Если массив будет слишком маленьким, то бенчмарк будет некорректен из-за того, что процессор мб сможет как-то хитро организовать кэширование данных. Возможно одни методы сравнения массивов более чувствительны к кешу, чем другие.
2. Если массив будет слишком большим, то бенчмарк будет некорректен из-за того, что на сцену могут выйти какие-нибудь memory issue (по типу использования файла подкачки или других реакций ОС не нехватку памяти).
Вообще, если проводить полноценное исследование, то нужно сравнивать методы в зависимости от размера массива, количества оперативки и процессорной архитектуры (размеры кешей и выбор x86/x64 имеют первостепенное значение). Но если задача состоит построить первое приближение к полноценному исследованию, то нужно постараться подобрать золотую середину — среднее значение величины массива, которое не вызовет сайд-эффектов. При этом нужно понимать, что вывод вида «один метод будет лучше другого в абстрактной ситуации» можно делать только при качественной разнице во времени работы. Разница в 5–10% может быть легко компенсирована сменой процессорной архитектуры.
Как только вы подберёте «оптимальный» размер массива, можно приступать к наращиванию количества прогонов. Один прогон должен выполняться хотя бы секунду, чтобы результаты были адекватны. Чем больше — тем лучше (тут всё зависит от того, насколько долго вы готовы ждать результатов).
1. Если массив будет слишком маленьким, то бенчмарк будет некорректен из-за того, что процессор мб сможет как-то хитро организовать кэширование данных. Возможно одни методы сравнения массивов более чувствительны к кешу, чем другие.
2. Если массив будет слишком большим, то бенчмарк будет некорректен из-за того, что на сцену могут выйти какие-нибудь memory issue (по типу использования файла подкачки или других реакций ОС не нехватку памяти).
Вообще, если проводить полноценное исследование, то нужно сравнивать методы в зависимости от размера массива, количества оперативки и процессорной архитектуры (размеры кешей и выбор x86/x64 имеют первостепенное значение). Но если задача состоит построить первое приближение к полноценному исследованию, то нужно постараться подобрать золотую середину — среднее значение величины массива, которое не вызовет сайд-эффектов. При этом нужно понимать, что вывод вида «один метод будет лучше другого в абстрактной ситуации» можно делать только при качественной разнице во времени работы. Разница в 5–10% может быть легко компенсирована сменой процессорной архитектуры.
Как только вы подберёте «оптимальный» размер массива, можно приступать к наращиванию количества прогонов. Один прогон должен выполняться хотя бы секунду, чтобы результаты были адекватны. Чем больше — тем лучше (тут всё зависит от того, насколько долго вы готовы ждать результатов).
P.S. не весь код из ваших примеров компилируется, не молги бы вы поправить его?
Мм. А какая у вас ошибка компиляции? У меня всё отлично собирается.
Код из этого примера github.com/AndreyAkinshin/BenchmarkDotNet/blob/master/BenchmarkDotNet.Samples/CustomSampleProgram.cs
Не компилируется, так как метод AddTask принимает два параметра вместо трёх.
Не компилируется, так как метод AddTask принимает два параметра вместо трёх.
Эмм. Вот сигнатура вызываемого метода:
Вот вызовы этого метода:
Метод должен принимать 4 параметра (точнее говоря, есть такая перегрузка этого метода). И при вызове ему как раз передаётся 4 параметра. Всё ещё не вижу проблемы.
public void AddTask(string name, Action initialize, Action action, Action clean)Вот вызовы этого метода:
competition.AddTask("For",
() => { array = new int[ArraySize]; },
() => For(),
() => { array = null; });
competition.AddTask("Linq",
() => { array = new int[ArraySize]; },
() => Linq(),
() => { array = null; });
Метод должен принимать 4 параметра (точнее говоря, есть такая перегрузка этого метода). И при вызове ему как раз передаётся 4 параметра. Всё ещё не вижу проблемы.
Ну смотрите, я выкачал NuGet пакет версии «0.5.1».
Этот пакет включает библиотеку «BenchmarkDotNet.dll» той же версии.
Эта библиотека содержит класс BenchmarkCompetition. Вот его определение:
Вполне возможно, что проблема в том, что опубликованный NuGet пакет не первой свежести, но это все что я нашел через NuGet поиск.
Этот пакет включает библиотеку «BenchmarkDotNet.dll» той же версии.
Эта библиотека содержит класс BenchmarkCompetition. Вот его определение:
// Type: BenchmarkDotNet.BenchmarkCompetition
// Assembly: BenchmarkDotNet, Version=0.5.1.0, Culture=neutral, PublicKeyToken=null
// MVID: A1FDCA59-3DB1-4AC6-9C3F-8307BAA3104A
// Assembly location: E:\GitHub\Best-Way-to-Compare-Byte-Arrays-in-.Net\packages\BenchmarkDotNet.0.5.1\lib\net35\BenchmarkDotNet.dll
using System;
namespace BenchmarkDotNet
{
public class BenchmarkCompetition
{
public void AddTask(string name, Action initialize, Action action);
public void AddTask(string name, Action action);
public void Run();
public void PrintResults();
}
}
Вполне возможно, что проблема в том, что опубликованный NuGet пакет не первой свежести, но это все что я нашел через NuGet поиск.
Да, всё верно, проблема в версии. После публикации версии 0.5.1 в NuGet было ещё несколько коммитов (в том числе коммит, включающий обсуждаемый Sample). Я сегодня/завтра доберусь до репозитория и выложу в NuGet свежую версию (она будет иметь номер 0.5.2). Вы можете либо подождать, либо скачать исходники с GitHub-а и ручками подключить в свой Solution проект со свежей версией (однако, если вы собираетесь обновлять свой бенчмарк на GitHub-е, то советую дождаться обновлённой версии, чтобы просто подцепить зависимость).
Обновил версию пакета в NuGet до 0.5.2. Теперь можете работать со свежими обновлениями: https://www.nuget.org/packages/BenchmarkDotNet/
И ещё один совет: в вашем примере разумно создавать массивы один раз в самом начале, нет нужны пересоздавать их на каждый Task. Конечно, профилактические вызовы GC делаются в нужных местах, но всё же в бенчмарках хорошо бы максимально сократить подобные операции.
Хм, а почему бы не попробовать сделать сравнение буферов в несколько потоков?
Пожалуйста, повторите измерение для PInvoke, применив атрибут SuppressUnmanagedCodeSecurity.
Описание говорит, что он ускоряет дело. Есть надежда получить результат близкий к наибыстрейшему даже на коротких массивах.
Описание говорит, что он ускоряет дело. Есть надежда получить результат близкий к наибыстрейшему даже на коротких массивах.
Не знал, большое спасибо и за подсказку и за внимательность!
Применение атрибута дало хороший эффект. Прогон от 1 байта до 12 Кб дал вот такие результаты:
Применение атрибута дало хороший эффект. Прогон от 1 байта до 12 Кб дал вот такие результаты:
Размер массива Минимальное время Unsafe PInvoke Простейший метод SequenceEqual IStructuralEquatable
1 273 1 : 001,8 1 : 003,5 1 : 001,0 1 : 010,5 1 : 055,3
1 271 1 : 001,8 1 : 003,5 1 : 001,0 1 : 010,3 1 : 055,6
2 325 1 : 002,4 1 : 003,0 1 : 001,0 1 : 010,9 1 : 092,2
3 326 1 : 002,4 1 : 003,0 1 : 001,0 1 : 010,7 1 : 092,3
4 377 1 : 001,1 1 : 002,7 1 : 001,0 1 : 011,4 1 : 118,7
6 425 1 : 001,0 1 : 002,7 1 : 001,0 1 : 011,6 1 : 138,8
9 426 1 : 001,0 1 : 002,6 1 : 001,2 1 : 013,5 1 : 174,0
13 426 1 : 001,0 1 : 002,7 1 : 001,6 1 : 016,7 1 : 241,4
20 490 1 : 001,0 1 : 002,4 1 : 002,1 1 : 020,5 1 : 330,4
29 490 1 : 001,0 1 : 002,5 1 : 002,7 1 : 026,5 1 : 448,2
43 560 1 : 001,0 1 : 002,2 1 : 003,4 1 : 032,3 1 : 572,4
63 638 1 : 001,0 1 : 002,1 1 : 004,2 1 : 039,8 1 : 731,8
91 806 1 : 001,0 1 : 001,8 1 : 004,7 1 : 044,2 1 : 832,3
133 1012 1 : 001,0 1 : 001,7 1 : 003,9 1 : 052,5 1 : 960,5
195 1335 1 : 001,0 1 : 001,5 1 : 004,1 1 : 057,2 1 : 1066,8
284 1769 1 : 001,0 1 : 001,4 1 : 004,4 1 : 061,7 1 : 1172,5
414 2414 1 : 001,0 1 : 001,3 1 : 004,5 1 : 064,8 1 : 1247,9
603 3380 1 : 001,0 1 : 001,2 1 : 004,6 1 : 066,9 1 : 1292,7
879 4750 1 : 001,0 1 : 001,2 1 : 004,7 1 : 068,6 1 : 1343,9
1282 6423 1 : 001,0 1 : 001,2 1 : 005,0 1 : 073,8 1 : 1449,2
1868 8893 1 : 001,0 1 : 001,2 1 : 005,2 1 : 077,5 1 : 1526,0
2723 12667 1 : 001,0 1 : 001,2 1 : 005,4 1 : 079,0 1 : 1560,1
3969 18042 1 : 001,0 1 : 001,2 1 : 005,4 1 : 080,9 1 : 1598,8
5785 25872 1 : 001,0 1 : 001,2 1 : 005,5 1 : 082,1 1 : 1640,5
8431 37341 1 : 001,0 1 : 001,2 1 : 005,6 1 : 083,2 1 : 1645,5
12288 54115 1 : 001,0 1 : 001,2 1 : 005,6 1 : 083,6 1 : 1653,2
Трэйс от управляемого кода к функции показал всего 50 команд.
main 00540F14 call 001DC2F4 ESP=001AEE14
main 001DC2F4 mov eax, 1D38D8 EAX=001D38D8
main 001DC2F9 mov ebp, ebp
main 001DC2FB jmp 00540F40
main 00540F40 push ebp ESP=001AEE10
main 00540F41 mov ebp, esp EBP=001AEE10
main 00540F43 push edi ESP=001AEE0C
main 00540F44 push esi ESP=001AEE08
main 00540F45 push ebx ESP=001AEE04
main 00540F46 sub esp, 28 ESP=001AEDDC
main 00540F49 mov [ebp-18], eax
main 00540F4C xor ebx, ebx EBX=00000000
main 00540F4E mov [ebp-10], ebx
main 00540F51 mov [ebp-14], ebx
main 00540F54 mov esi, fs:[0E38] ESI=002F2AE0
main 00540F5B mov dword ptr [ebp-30], 645CABC8
main 00540F62 mov dword ptr [ebp-34], C28DAB21
main 00540F69 mov eax, [esi+0C] EAX=001AF09C
main 00540F6C mov [ebp-2C], eax
main 00540F6F mov [ebp-1C], ebp
main 00540F72 mov dword ptr [ebp-20], 0
main 00540F79 lea eax, [ebp-30] EAX=001AEDE0
main 00540F7C mov [esi+0C], eax
main 00540F7F xor ebx, ebx
main 00540F81 test ecx, ecx
main 00540F83 je short 00540F8F
main 00540F85 mov [ebp-10], ecx
main 00540F88 mov eax, ecx EAX=023B42E4
main 00540F8A add eax, 8 EAX=023B42EC
main 00540F8D mov ebx, eax EBX=023B42EC
main 00540F8F xor edi, edi EDI=00000000
main 00540F91 test edx, edx
main 00540F93 je short 00540F9F
main 00540F95 mov [ebp-14], edx
main 00540F98 mov eax, edx EAX=023B42E4
main 00540F9A add eax, 8 EAX=023B42EC
main 00540F9D mov edi, eax EDI=023B42EC
main 00540F9F mov eax, [ebp-18] EAX=001D38D8
main 00540FA2 mov eax, [eax+14] EAX=001D397C
main 00540FA5 mov ecx, [eax] ECX=75A97975
main 00540FA7 push dword ptr [ebp+0C] ESP=001AEDD8
main 00540FAA push dword ptr [ebp+8] ESP=001AEDD4
main 00540FAD push edi ESP=001AEDD0
main 00540FAE push ebx ESP=001AEDCC
main 00540FAF mov dword ptr [ebp-28], 0
main 00540FB6 mov [ebp-24], esp
main 00540FB9 mov dword ptr [ebp-20], 540FC6
main 00540FC0 mov byte ptr [esi+8], 0
main 00540FC4 call ecx ESP=001AEDC8
Sign up to leave a comment.
5 способов сравнить два байтовых массива. Сравнительное тестирование