Comments 143
Хм, интересно, почему я решил ту виртуалку с нодой погасить да так и не запустил обратно? Надо ещё раз ноду поставить.
На картинке с поиском навального, одна страница на lurkmore.to находится в выдаче дважды.
С релевантностью у него не очень. По запросу google на первых 10-ти позициях его нет
Конкретно на главную сайта он очень редко выдает ссылки, а вот по содержанию страницы — отлично ищет
На картинках в статье с яндексом, насколько вижу, та же история
А вы попробуйте habrastorage в гугле поищите, например. Еще очень радует «ssh-add»
Это не показатель релевантности, зачем вам искать главную страницу гугла? О_о Попробйте на реальных запросах.
Дело не в главной гугл. Google это же ведь компания, согласны? :)
Факт остаётся фактом поиск так себе, и дело тут даже не в релевантности, а скорее в некотором внутреннем интеллекте алгоритма, и стабильности выдачи результатов по запросу.
p.s: поставил у себя ежемесячное сканирование русских вики ресурсов, сейчас уже досканировались, по идее должно было полегчать, но не полегчало, стало быть у YaCy действительно проблемы.
p.p.s: по запросу «Компания Google» тоже ничего :( в общем печаль, как она есть.
Факт остаётся фактом поиск так себе, и дело тут даже не в релевантности, а скорее в некотором внутреннем интеллекте алгоритма, и стабильности выдачи результатов по запросу.
p.s: поставил у себя ежемесячное сканирование русских вики ресурсов, сейчас уже досканировались, по идее должно было полегчать, но не полегчало, стало быть у YaCy действительно проблемы.
p.p.s: по запросу «Компания Google» тоже ничего :( в общем печаль, как она есть.
Ссылка на комментарий к версии 1.0, с релевантностью 3 года назад была такая же беда, видимо надо самим присоединяться к проекту и что то делать, ибо проект полезный и интересный, но, к сожалению, для глобального поиска абсолютно не приспособленный.
UFO just landed and posted this here
Он не может оценить поведение посетителей для определения релевантности, таким образом он использует контекстный метод поиска из-за этого ссылки на главную могут отсутствовать попробуйте поискать что-то кроме сайтов т.е информацию как в примерах.
Согласен что так быть не должно, но надо придумать алгоритм как поисковик будет распознавать какой сайт показывать как основной на основе url
Согласен что так быть не должно, но надо придумать алгоритм как поисковик будет распознавать какой сайт показывать как основной на основе url
Алгоритм давно известен. Именно он сделал гугл популярным — page rank. Хотя этим часто злоупотребляют сеошники, это да
Несовсем, в большинстве случаев учитывается поведение пользователей при поиске для улучшения дальнейшего поиска
Если я не залогинен, гугл ищет так же хорошо.
Это вы думаете, что не залогинены ;)
Да, но каким образом ваша залогиненность влияет на поведение других пользователей?
У гугла PageRank уже далеко на основной способ ранжирования.
а что основной?
Денежки.
Думаю верным ответом будет «никто не знает» т.к. официальной информации на эту тему нет, а все остальное — гадание на кофейной гуще. Возможно, впрочем, что я ошибаюсь т.к. к счастью уже давно не приходилось заниматься сео.
С другой стороны насчет page rank — да, напрямую на ранжирование он не влияет, зависимость какая-то определенно есть, но не более.
С другой стороны насчет page rank — да, напрямую на ранжирование он не влияет, зависимость какая-то определенно есть, но не более.
В перспективе все сводится к так называемому «поведенческому фактору». Лайки, шары, репосты, ретвиты, ну и, конечно, посещения. Кто, откуда, по каким запросам, как быстро ушел. Давненько не интересовался, насколько далеко Гугл в этом зашел, но примерно так выглядит ближайшее будущее (или уже настоящее) поиска.
Анализ содержимого сайта с точки зрения удобства пользователя.
en.wikipedia.org/wiki/Google_Panda
en.wikipedia.org/wiki/Google_Panda
У него очень маленькая база по русским сайтам. Я натравил когда-то на Хабр, Луркмор и свой сайт, и этот индекс распространился по сети — на этом фактически всё закончилось. На текущий момент ситуация всё ещё такая: хотите найти полезную информацию — сами добавляйте сайты, где она есть.
Ну так а в чем проблема? Автор в статье написал же про режим индексирования посещаемых страниц.
Это отдельные страницы, а я больше про то, что никто не пользуется добавлением сайтов. Индекс рунета почти не растёт.
Ну тут я с вами соглашусь. Но вообще, решил начать, как говорится, с себя: закроулил сайты по электронике, смолтоку и линуксам.
Спустя сутки, качество выдачи стало улучшаться прямо на глазах :) Я думаю, если народ пойдет в тему, очень скоро мы получим заметный результат.
Спустя сутки, качество выдачи стало улучшаться прямо на глазах :) Я думаю, если народ пойдет в тему, очень скоро мы получим заметный результат.
Ну вот у меня висит в FF виджет от Blippex, отправляет на свой сервер адреса тех сайтов, где я бываю.
Запилить такой же для Yacy и ставить всем подряд ))
Запилить такой же для Yacy и ставить всем подряд ))
Так вроде Yacy умеет работать в таком режиме. Augmented что ли. То есть вы используете его как прокси, а он еще потом кроулит страницы, что вы посещали.
Верно, умеет
Ненене, одно дело поставить маленький аддон в браузер, который ни на что не влияет, а другое — пускать интернет через доппрослойку, которая может создать проблемы.
На своём компе — да, не вопрос. Но я имел в виду способ охватить и все соседские и не только компы, чтобы быстрее набралась база сайтов.
То есть добавить ещё функционал в Yacy, чтобы парсил не только свои сайты, но и те, адреса которых ему присылают «тонкие клиенты», которые не могут сами кроулить.
На своём компе — да, не вопрос. Но я имел в виду способ охватить и все соседские и не только компы, чтобы быстрее набралась база сайтов.
То есть добавить ещё функционал в Yacy, чтобы парсил не только свои сайты, но и те, адреса которых ему присылают «тонкие клиенты», которые не могут сами кроулить.
я использую скрипт для greasemonkey/tampermonkey простейший вида
(по мотивам veclabs.posterous.com/ — добавлена явная проверка что не посылать)
недостаток — забивается слегка лог
с режимом proxy-индексации у меня было несколько проблем:
— страница должна запрашиваться без кук (или он не будет индексироваться, возможно я что-то путаю) а куча сайтов куки ставит даже когда юзер не залогинен
— если нет возможности YaCy как прокси прописать потому что уже прописано что-то другое и надо воротить сложные цепочки (допустим надо часть трафика направлять через прокси в европе, часть-директом, часть (*.i2p) вообще на I2P-ноду отдавать )
(по мотивам veclabs.posterous.com/ — добавлена явная проверка что не посылать)
// ==UserScript==
// @name YaCyIndexer
// @namespace https://yacy.domain.com
// @description Indexes visited pages with YaCy.
// @version 0.1
// @match *://*/*
// @grant GM_xmlhttpRequest
// @grant GM_log
// ==/UserScript==
// User parameters:
var paramYaCyLocation = 'http://yacy.domain.com';//адресВашегоСервера
var paramEnableQueryString = true; // Index pages with query strings (possible privacy leak).
var paramDepth = 1; // 0 = only the visited page; 1 = all links on visted page; higher values will index deeper but use exponentially more bandwidth.
var paramAgeNum = 7; // pages already indexed since this time won't be re-indexed.
var paramAgeUnit = 'day'; // units for above
// YaCy Arguments -- Don't change these unless you've read the YaCy API docs.
var crawlingstart = '';
var crawlingMode = 'url';
var crawlingURL = paramEnableQueryString ? window.location.href : [location.protocol, '//', location.host, location.pathname].join('');
var bookmarkTitle = '';
var crawlingDepth = paramDepth;
var directDocByURL = 'off';
var crawlingDepthExtension = '';
var range = 'wide';
var mustmatch = '.*';
var mustnotmatch = '';
var ipMustmatch = '.*';
var ipMustnotmatch = '';
var indexmustmatch = '.*';
var indexmustnotmatch = '';
var deleteold = 'off';
var recrawl = 'reload';
var reloadIfOlderNumber = paramAgeNum;
var reloadIfOlderUnit = paramAgeUnit;
var countryMustMatchSwitch = 'false';
var crawlingDomMaxCheck = 'off';
var crawlingQ = paramEnableQueryString ? 'on' : 'off';
var storeHTCache = 'off';
var cachePolicy = 'iffresh';
var indexText = 'on';
var indexMedia = 'on';
var crawlOrder = 'off';
var collection = 'user';
var yacy_url = paramYaCyLocation + '/Crawler_p.html?crawlingstart=' + encodeURIComponent(crawlingstart) + '&crawlingMode=' + encodeURIComponent(crawlingMode) + '&crawlingURL=' + encodeURIComponent(crawlingURL) + '&bookmarkTitle=' + encodeURIComponent(bookmarkTitle) + '&crawlingDepth=' + encodeURIComponent(crawlingDepth) + '&directDocByURL=' + encodeURIComponent(directDocByURL) + '&crawlingDepthExtension=' + encodeURIComponent(crawlingDepthExtension) + '&range=' + encodeURIComponent(range) + '&mustmatch=' + encodeURIComponent(mustmatch) + '&mustnotmatch=' + encodeURIComponent(mustnotmatch) + '&ipMustmatch=' + encodeURIComponent(ipMustmatch) + '&ipMustnotmatch=' + encodeURIComponent(ipMustnotmatch) + '&indexmustmatch=' + encodeURIComponent(indexmustmatch) + '&indexmustnotmatch=' + encodeURIComponent(indexmustnotmatch) + '&deleteold=' + encodeURIComponent(deleteold) + '&recrawl=' + encodeURIComponent(recrawl) + '&reloadIfOlderNumber=' + encodeURIComponent(reloadIfOlderNumber) + '&reloadIfOlderUnit=' + encodeURIComponent(reloadIfOlderUnit) + '&countryMustMatchSwitch=' + encodeURIComponent(countryMustMatchSwitch) + '&crawlingDomMaxCheck=' + encodeURIComponent(crawlingDomMaxCheck) + '&crawlingQ=' + encodeURIComponent(crawlingQ) + '&storeHTCache=' + encodeURIComponent(storeHTCache) + '&cachePolicy=' + encodeURIComponent(cachePolicy) + '&indexText=' + encodeURIComponent(indexText) + '&indexMedia=' + encodeURIComponent(indexMedia) + '&crawlOrder=' + encodeURIComponent(crawlOrder) + '&collection=' + encodeURIComponent(collection);
// проверяем не запрещено ли нам вообще этого host'а касатся
if ( (location.host!="accounts.google.com") && (location.host!="apis.google.com") && (location.host!="mail.google.com") && (location.host!="s-static.ak.facebook.com"))
{
GM_xmlhttpRequest({
method: "GET",
url: yacy_url,
onload: function(response) {
// GM_log("YaCy indexing should commence.");
}
});
}
else
{
// GM_log("Will NOT process host:"+location.host);
}
недостаток — забивается слегка лог
с режимом proxy-индексации у меня было несколько проблем:
— страница должна запрашиваться без кук (или он не будет индексироваться, возможно я что-то путаю) а куча сайтов куки ставит даже когда юзер не залогинен
— если нет возможности YaCy как прокси прописать потому что уже прописано что-то другое и надо воротить сложные цепочки (допустим надо часть трафика направлять через прокси в европе, часть-директом, часть (*.i2p) вообще на I2P-ноду отдавать )
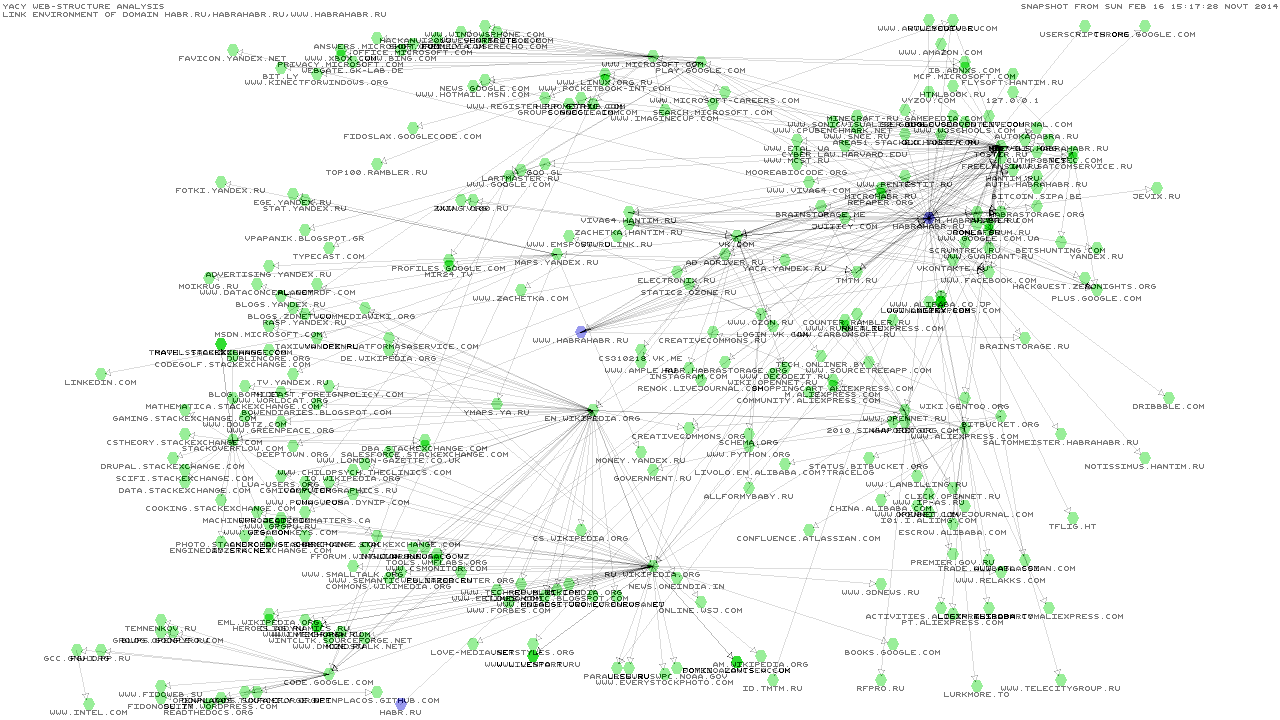
А что вы понимаете под базой сайтов? Если говорить про список доменов, то он набирается автоматически даже от одного единственного кроулера. Ниже представлен результат нескольких часов кроулинга хабра с моей ноды (кликабельно).
Поскольку кроулер шагает по ссылкам, предоставляемым пользователями, тут получается гораздо меньше сеошного шлака. В то же время, ссылки как правило ведут на осмысленные страницы. Другое дело, что релевантность будет определяться исключительно точностью запроса. Так что, на запрос «google» поисковик разумно возразит «ну а что гугл? есть такое слово» и в общем-то будет прав.
А вот граф для русской Википедии:
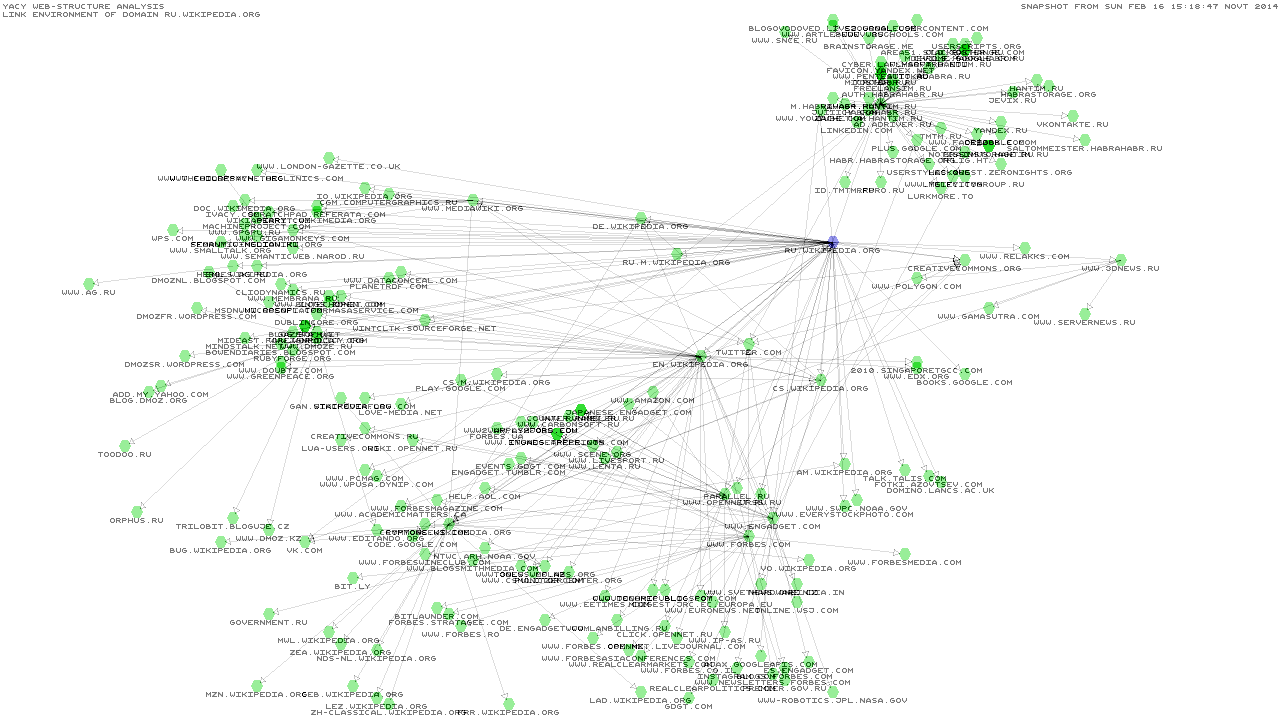
Поскольку кроулер шагает по ссылкам, предоставляемым пользователями, тут получается гораздо меньше сеошного шлака. В то же время, ссылки как правило ведут на осмысленные страницы. Другое дело, что релевантность будет определяться исключительно точностью запроса. Так что, на запрос «google» поисковик разумно возразит «ну а что гугл? есть такое слово» и в общем-то будет прав.

А вот граф для русской Википедии:

[offtop] Ссылки на картинки чучуть поломатые. Но после правки работают. [/offtop]
Ну насчёт списка доменов согласен, не был в курсе про такой функционал. Чтобы не было шлака, можно отдавать не домен, а прямо адрес страницы (вырезая POST-запросы и прочие персональные данные). Шпионство? Если отправлять анонимно и только один раз (опираясь на историю браузера), то это допустимое шпионство.
Опять же, Вы добавите хабр, а другой, кому Вы поставите такой виджет или юзерскрипт, добавит свои сайты. Так, глядишь, и теневой интернет выплывет ))
В данный момент стоит задача набрать критическую базу пользователей и данных для них, чтобы горстка энтузиастов не тянула всё на себе. А насколько это будет жизнеспособным и востребованным — покажет время.
Ну насчёт списка доменов согласен, не был в курсе про такой функционал. Чтобы не было шлака, можно отдавать не домен, а прямо адрес страницы (вырезая POST-запросы и прочие персональные данные). Шпионство? Если отправлять анонимно и только один раз (опираясь на историю браузера), то это допустимое шпионство.
Опять же, Вы добавите хабр, а другой, кому Вы поставите такой виджет или юзерскрипт, добавит свои сайты. Так, глядишь, и теневой интернет выплывет ))
В данный момент стоит задача набрать критическую базу пользователей и данных для них, чтобы горстка энтузиастов не тянула всё на себе. А насколько это будет жизнеспособным и востребованным — покажет время.
Кто-нибудь объясните, пожалуйста, хотя бы в двух словах, как работает p2p поисковик?.. У меня более или менее укладывается в голове p2p файлообменник, торрент, но поисковик как-то не очень)
Каждый узел в сети имеет часть индекса, и он объявляет об этом, когда вы ищите Морковь то по DHT вам отвечают что на таких-то узлах есть информация по вашему поисковому запросу, ваш узел идет туда и собирает её, затем уже ранжирует
а может ли узел подделать свою часть индекса?
теоритически — да, но в Yacy есть механизмы защиты, которые тянут на отдельную статью
Хотеть такую статью :)
Теоретически, если я пир я вижу айпи того кто забирает у меня какую-то информацию?
И если да, то какая же это анонимность? Выложил зловредный контент, записал всех кто с тебя тянет его, наругал всех кого записал.
И если да, то какая же это анонимность? Выложил зловредный контент, записал всех кто с тебя тянет его, наругал всех кого записал.
Распределение информации в сети происходит хаотично и вы не трогаете и не храните контент, вы храните где этот контент найти
Ну где-то он ведь хранится? Допустим у меня и хранится. Я выкладываю порнуху детскую, все видят что она у меня есть, и сообщают это тем кто ее ищет. У меня ведь ее будут тянуть? И если да, то буду ли я видеть их айпи?:)
Те кто к вам заходят? очевидно да они же по IPv4 будут заходить хотя они могут использовать прокси или Tor т.е как в обычном интернете.
Если же вы имеете ввиду будите ли вы видеть IP адреса людей котяре ищут её без захода к вам — то не факт, ты индекс о том, что у вас это есть хранится не только у вас + ваш индекс может быть переслан через несколько пиров (аналог луковой маршрутизации)
Если же вы имеете ввиду будите ли вы видеть IP адреса людей котяре ищут её без захода к вам — то не факт, ты индекс о том, что у вас это есть хранится не только у вас + ваш индекс может быть переслан через несколько пиров (аналог луковой маршрутизации)
Что представляют из себя узлы? Устройства волонтеров/добровольцев? Или по сереверам разбросано?
А шифрование там есть?
Отличный проект. Сам когда-то о таком задумывался. Похоже сделали так как хотел )
Для себя делал прокси с Solr для поиска.
Для себя делал прокси с Solr для поиска.
Ура!!! Наконец-то мы сможем найти Навального!!! Вопреки свирепствующей цензуре!!!
UFO just landed and posted this here
С опросами вообще всё плохо. Все варианты жутко категоричны.
А что бы следовало добавить?
«Хочу пользоваться несмотря на ...» и дальше четыре положения из «не хочу», аналогично поступить с пунктами «хочу». Если развивать мысль дальше, то «надо», «буду» и «хочу» — очень разные люди.
Все эти восемь пунктов хочу/не хочу, это восемь независимых опросов, с различными степенями детализации ответов. В идеале, каждому опросу должна соответствовать хорошая статья о том, что это вообще такое, как это реализовывается и какова цена вопроса — имхо, наш социум, даже его «техническая элита» с этого сайта, скажем так, на грани необходимости проведения ликбеза по каждому из пунктов.
Все эти восемь пунктов хочу/не хочу, это восемь независимых опросов, с различными степенями детализации ответов. В идеале, каждому опросу должна соответствовать хорошая статья о том, что это вообще такое, как это реализовывается и какова цена вопроса — имхо, наш социум, даже его «техническая элита» с этого сайта, скажем так, на грани необходимости проведения ликбеза по каждому из пунктов.
если хабар пользователям будет интересна тема децентрализованных поисковых систем, я готов сделать обзор всего функционала Yacy и рассмотреть подробно как она работает
Мне был бы очень интересен подробный разбор работы их DHT. В сети ничего — за исключением исходного кода — не нашел, как ни старался.
Я думаю, что общая идея такая же, как в Kademlia (Как работает поиск в Kad Network). Вообще тоже бы хотелось увидеть подробное описание их протокола.
Подняли бы ссылочку на ресурс на самый верх статьи, или продублировали…
Интересно, и как туда добавить свой ресурс?
Проиндексировав его с вашей машины и подождать пока индекс разбежиться по DHT
Как обстоят дела с индексацией? Правильно ли я понимаю что yacy просто попытается спарсить сайт и вполне может получить бан?
Она ведет себя полностью как поисковой бот и многими системами так и определяется например в форуме PHPBB она умеет читать robots файл умеет ждать между запросами, я пробовал индексировать сайты и они не банят yacy habr/wiki — точно
Yacy — это обычный поисковый бот, он не скрывает это и подчиняется правилам из robots.txt. Скорость парсинга легко настраивается заранее или во время парсинга, а также можно поставить запрос на remote crawl — парсинг всей сетью.
И тем не менее его работа у меня вызывает больше вопросов чем ответов.
Для habrahabr crawl-delay задан равным 10, что даёт 6 запросов в минуту. Yacy показывает Crawler PPM равным 6. Это логично.
anidb.net вообще запрещает индексацию сайта. yacy наплевал на robots.txt и добился бана по ip
Можно пояснить этот момент?
Насколько я вижу, можно задать только Speed / PPM, что является общим лимитом для всех индексаций.
Помимо этого можно заставить yacy игнорировать robots.txt и долбить сайт одному или с друзьями?
Для habrahabr crawl-delay задан равным 10, что даёт 6 запросов в минуту. Yacy показывает Crawler PPM равным 6. Это логично.
habrahabr.ru/robots.txt
User-agent: Yandex Crawl-delay: 2 Disallow: /search/ Disallow: /js/ Disallow: /css/ Disallow: /ajax/ Disallow: /login/ Disallow: /register/ Host: habrahabr.ru User-agent: Googlebot Crawl-delay: 2 Disallow: /search/ Disallow: /js/ Disallow: /css/ Disallow: /ajax/ Disallow: /login/ Disallow: /register/ User-agent: Slurp Crawl-delay: 8 Disallow: /search/ Disallow: /js/ Disallow: /css/ Disallow: /ajax/ Disallow: /login/ Disallow: /register/ User-agent: * Crawl-delay: 10 Disallow: /search/ Disallow: /js/ Disallow: /css/ Disallow: /ajax/ Disallow: /login/ Disallow: /register/
anidb.net вообще запрещает индексацию сайта. yacy наплевал на robots.txt и добился бана по ip
anidb.net/robots.txt
User-agent: * Disallow: / User-agent: Spinn3r Disallow: / User-agent: Tailrank Disallow: / User-agent: Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.2.1; aggregator:Spinn3r (Spinn3r 3.0); http://spinn3r.com/robot) Gecko/20021130 Disallow: /
Скорость парсинга легко настраивается заранее или во время парсинга, а также можно поставить запрос на remote crawl — парсинг всей сетью.
Можно пояснить этот момент?
Насколько я вижу, можно задать только Speed / PPM, что является общим лимитом для всех индексаций.
Помимо этого можно заставить yacy игнорировать robots.txt и долбить сайт одному или с друзьями?
объясните пожалуйста, запрос «camomile dreams», почему у меня в результате полный список дистфайлов и образов генты? Что это за красноглазые намеки?
Сдается мне что оснавная часть индекса набивается во время посещений сайтой, поэтому индекс напрямую зависит от интересов аудитории. Выходит что популярный контент становится еще популярнее, а непопулярный вообще не попадет в систему и не может быть найден. Так? Ведь кто даст принудительны запрос индексирования сайта которого не знает? Особенно это касается старых, брошенных сайтов, на которых бывает весьма полезная и уникальная информация.
Сдается мне что оснавная часть индекса набивается во время посещений сайтой, поэтому индекс напрямую зависит от интересов аудитории. Выходит что популярный контент становится еще популярнее, а непопулярный вообще не попадет в систему и не может быть найден. Так? Ведь кто даст принудительны запрос индексирования сайта которого не знает? Особенно это касается старых, брошенных сайтов, на которых бывает весьма полезная и уникальная информация.
Бот в фоновом режиме обходит все сайты на которые есть ссылки, учтите что сеть индекса не такая как у гугла а значит и время требуется для набора информации.
В скриншотах я привел пример пары запросов которые обрабатываются достаточно точно + по идее, если данная технология будет популярна — сайты сами у себя будут ставить yacy для быстрого появления новой информации
В скриншотах я привел пример пары запросов которые обрабатываются достаточно точно + по идее, если данная технология будет популярна — сайты сами у себя будут ставить yacy для быстрого появления новой информации
Индекс напрямую зависит от тех сайтов, которые были добавлены в этот индекс самими пользователями. Кто-то добавил сайт с дистрами генты, а, например, на ЖЖ поисковик ещё никто не натравливал (что даже понятно по скриншотам). Самые преданные пользователи YaCy разговаривают на немецком, и на русские сайты они не заходят.
а portable версия есть?
А где сырцы?
Ссылка на главной не считается?
shifttstas в заголовке «Три годя спустя»
Когда я, активный пользователь интернета, потребитель нелегального копирайтного контента и интересующийся политикой с разных точек зрения человек слышу о поиске без цензуры — мне почему-то только кавказ-центр и детское порно на ум приходит, как вещи которые кто-то мешает искать в обычном гугле. Ни о какой другой цензуре, мешающей искать варез, порно, политику я не слышал, точнее слышал, но не сталкивался лично.
Цензура в данном случае может выглядеть не так как ожидается.
Например поисковый гигант — монополист, может легко и незаметно уничтожить любую компанию, просто сместив выдачу результатов на нее в конец списка.
Это очень плохо, когда обычный пользователь считает поисковую систему — интернетом, именно поэтому за настройку поиска 'по умолчанию' google к примеру платит mozilla башенные деньги, а mail.ru/yandex/etc… платят разработчикам бесплатных утилит, чтобы те вставляли в инсталяторы приложений mail.ru guard/yandex bar/… которые перелопачивают пользовательскую систему и его настройки так что любой адекватный администратор за голову хватается и начинает плеваться.
К сожалению, на текущий момент не существует доступных технологий, которые способны бросить вызов уже сложившейся практике использования поисковых систем, но это нужно менять, дальше будет только хуже.
Например поисковый гигант — монополист, может легко и незаметно уничтожить любую компанию, просто сместив выдачу результатов на нее в конец списка.
Это очень плохо, когда обычный пользователь считает поисковую систему — интернетом, именно поэтому за настройку поиска 'по умолчанию' google к примеру платит mozilla башенные деньги, а mail.ru/yandex/etc… платят разработчикам бесплатных утилит, чтобы те вставляли в инсталяторы приложений mail.ru guard/yandex bar/… которые перелопачивают пользовательскую систему и его настройки так что любой адекватный администратор за голову хватается и начинает плеваться.
К сожалению, на текущий момент не существует доступных технологий, которые способны бросить вызов уже сложившейся практике использования поисковых систем, но это нужно менять, дальше будет только хуже.
Например поисковый гигант — монополист, может легко и незаметно уничтожить любую компанию, просто сместив выдачу результатов на нее в конец списка.
Есть прецеденты? Я пока не сталкивался с нерелевантным поиском.
К сожалению, на текущий момент не существует доступных технологий, которые способны бросить вызов уже сложившейся практике использования поисковых систем, но это нужно менять, дальше будет только хуже.
А при пользовании бесконтрольным децентрализованным поиском — кто отвечает за релевантность выдачи? Кто будет наказывать «сео-оптимизаторов»?
Алгоритмы очевидно же. А когда мы говорим о цензуре мы говорим о том, что из поисковой выдачи могут быть выпилины не угодные власти/режиму новости
А при пользовании бесконтрольным децентрализованным поиском — кто отвечает за релевантность выдачи? Кто будет наказывать «сео-оптимизаторов»?я это и имевю в виду, когда говорю что не существует адекватных технологий.
Ближайшее развитие будет идти в сторону развития 'контент провайдеров', мнение которых будет определять поток информации, фильтруемый для пользователя, который в свою очередь делает выбор между этими контент провайдерами, которых должно быть много.
сео-оптимизаторов наказывают алгоритмами, никаких людских сил не хватит модерировать поисковый индекс всего интернета вручную.
а я разве говорил про ручную обработку?
Отличным примером контент-провайдера с функцией поисковой системы на текущий момент можно предложить например google или yandex.
Отличным примером контент-провайдера с функцией поисковой системы на текущий момент можно предложить например google или yandex.
Я отвечал тому, кому отвечали вы, но промахнулся. KarasikovSergey говорил про контроль поисковой выдачи, чтобы в нее не попадал поисковый спам, однако, централизованные поисковики тоже не фильтруют выдачу руками, а полагаются целиком на алгоритмы, т.е. этим же самым может заниматься и децентрализованный клиент.
Есть прецеденты? Я пока не сталкивался с нерелевантным поиском.roem.ru/2014/02/18/europagoogle92730/
Вы конечно тролльски категоричны, но всё же минусуют зря.
Цензура — это не детское порно и не кавказ центр. Всё это фигня на фоне маразма творящегося с торрентами, войной за первые позиции и т.п.
Попробуйте в гугле поискать Яндекс — гугл ничтоже сумняшеся заменит слово «Яндекс» на «Google» и скажет, что я именно это и искал. По многим запросам гугл пихает на первое место википедию, даже если статья там на уровне «заготовка».
Война с сеошниками, имхо, проиграна — я могу долго и упорно листать страница за страницей в поисках контента, который «на ура» находился раньше, но теперь вместо него, я буду находить бредовую сеошную статью ни о чём, перепечатанную на тысячах сайтов, созданных исключительно для заработка на «прохожих». Это тоже можно рассматривать как форму цензуры, хотя это уже вопрос релевантности.
Всё это можно списать на то, что тратятся миллионные бюджеты на продвижение ссылками, статьями и т.п. Тот же Яндекс, например, уже декларировал отказ от ссылок как ранжирующего фактора. Но остаётся ещё «миллион» факторов, по которым поисковая система за меня решает, что тот или иной контент мне нужно видеть или не нужно. И независимо от того, ручное это вмешательство в алгоритм с целью устранить конкурента, неугодную действующей власти идеологию или настроенный автомат, (заметим, не без ошибок) реализующий желание мне максимально «угодить» — всё это цензура в той или иной форме. И да, я могу в 95% случаев быть согласным на такую цензуру, она может быть в рамках моих интересов, я могу заниматься самоцензурой. Но я оцениваю как не менее 5% собственную потребность получения полного спектра источников, а не «рекомендованного» и нахожу, что поисковые системы злоупотребляют моим доверием. Экономические же факторы ранжирования (пресловутая коррупция) — всегда остаются существенным риском.
Здесь выше в комментариях было высказано мнение, что поисковая выдача коррелирует с вложенными в рекламу средствами. Это мнение возникло не на пустом месте и я вполне могу объяснить, почему так происходит: вкладывая средства в рекламу в конкретной поисковой системе, руководство сайта обучает пользователей системы, которые в дальнейшем дают этому сайту некоторое предпочтение и он поднимается за счёт поведенческих факторов. Всё легально, все формальности соблюдены, но цель достигнута — за места нужно платить, посетителей можно покупать и делать это нужно именно в поисковой системе.
Цензура — это не детское порно и не кавказ центр. Всё это фигня на фоне маразма творящегося с торрентами, войной за первые позиции и т.п.
Попробуйте в гугле поискать Яндекс — гугл ничтоже сумняшеся заменит слово «Яндекс» на «Google» и скажет, что я именно это и искал. По многим запросам гугл пихает на первое место википедию, даже если статья там на уровне «заготовка».
Война с сеошниками, имхо, проиграна — я могу долго и упорно листать страница за страницей в поисках контента, который «на ура» находился раньше, но теперь вместо него, я буду находить бредовую сеошную статью ни о чём, перепечатанную на тысячах сайтов, созданных исключительно для заработка на «прохожих». Это тоже можно рассматривать как форму цензуры, хотя это уже вопрос релевантности.
Всё это можно списать на то, что тратятся миллионные бюджеты на продвижение ссылками, статьями и т.п. Тот же Яндекс, например, уже декларировал отказ от ссылок как ранжирующего фактора. Но остаётся ещё «миллион» факторов, по которым поисковая система за меня решает, что тот или иной контент мне нужно видеть или не нужно. И независимо от того, ручное это вмешательство в алгоритм с целью устранить конкурента, неугодную действующей власти идеологию или настроенный автомат, (заметим, не без ошибок) реализующий желание мне максимально «угодить» — всё это цензура в той или иной форме. И да, я могу в 95% случаев быть согласным на такую цензуру, она может быть в рамках моих интересов, я могу заниматься самоцензурой. Но я оцениваю как не менее 5% собственную потребность получения полного спектра источников, а не «рекомендованного» и нахожу, что поисковые системы злоупотребляют моим доверием. Экономические же факторы ранжирования (пресловутая коррупция) — всегда остаются существенным риском.
Здесь выше в комментариях было высказано мнение, что поисковая выдача коррелирует с вложенными в рекламу средствами. Это мнение возникло не на пустом месте и я вполне могу объяснить, почему так происходит: вкладывая средства в рекламу в конкретной поисковой системе, руководство сайта обучает пользователей системы, которые в дальнейшем дают этому сайту некоторое предпочтение и он поднимается за счёт поведенческих факторов. Всё легально, все формальности соблюдены, но цель достигнута — за места нужно платить, посетителей можно покупать и делать это нужно именно в поисковой системе.
> Попробуйте в гугле поискать Яндекс — гугл ничтоже сумняшеся заменит слово «Яндекс» на «Google» и скажет, что я именно это и искал.
У меня на запрос «яндекс» находит (внезапно!) Яндекс. У нас разный Google?
У меня на запрос «яндекс» находит (внезапно!) Яндекс. У нас разный Google?
Значит «разный». Таки они отказались от этой практики и сейчас (внезапно!) гугл действительно показывает Яндекс, да ещё и со страницей профиля. Ну ок, одной претензией к гуглу меньше, но это не отменяет того, что так было. Жаль, не могу предоставить скриншота, в данный момент — это только моё слово.
Просим больше статей.
Индексирование сайтов i2p/tor будет работать как ожидается?
Индексирование сайтов i2p/tor будет работать как ожидается?
bugs.yacy.net/view.php?id=330
> «Remote Proxy» function is missing not reimplemented
Т.е. он пока не может работать в цепочке прокси. Соответственно, как минимум, с tor ничего не выйдет.
> «Remote Proxy» function is missing not reimplemented
Т.е. он пока не может работать в цепочке прокси. Соответственно, как минимум, с tor ничего не выйдет.
Дополню unxed: с I2P тоже ничего не получится, ибо клиент предоставляет только прокси в качестве интерфейса.
Однако можно извратиться, и сделать виртуальный интерфейс, к примеру на BadVPN. Ну а далее просто указать этот интерфейс, правда я пока лишь рассуждаю на эту тему и практических изысканий не проводил, так что не могу гарантировать что это будет работать ибо i2p не предоставляет какого либо сервиса (интерфейса), заменяющего DNS, а о подробностях работы TOR мне вообще мало известно.
Помимо этого в UNIX системах возможно настроить прозрачное проксирование I2P и TOR, и таким образом предоставить доступ YaCy в эти сети.
Однако можно извратиться, и сделать виртуальный интерфейс, к примеру на BadVPN. Ну а далее просто указать этот интерфейс, правда я пока лишь рассуждаю на эту тему и практических изысканий не проводил, так что не могу гарантировать что это будет работать ибо i2p не предоставляет какого либо сервиса (интерфейса), заменяющего DNS, а о подробностях работы TOR мне вообще мало известно.
Помимо этого в UNIX системах возможно настроить прозрачное проксирование I2P и TOR, и таким образом предоставить доступ YaCy в эти сети.
Поисковик к сожалению имеет очень маленькую базу индексированных страниц.
По запросу «таракан» выдало всего 18 результатов, 12 из которых принадлежат лурке.
А часть запросов выдает «1-1 of -UNRESOLVED_PATTERN- „
Я думаю у проекта большие перспективы, в случае ужесточения цензуры, пока же ему далеко до идеала.
По запросу «таракан» выдало всего 18 результатов, 12 из которых принадлежат лурке.
А часть запросов выдает «1-1 of -UNRESOLVED_PATTERN- „
Я думаю у проекта большие перспективы, в случае ужесточения цензуры, пока же ему далеко до идеала.
База индекса это, к счастью, вообще не особая проблема, ибо достаточно просто сделать побольше индексирующих нод. Уже сейчас данная статья дала значительный рост русскоязычных нод, и результат на лицо:
На запрос «таракан» 1-10 из 3 103; (2 946 локально, 4 078 remote), 158 из 39 удаленных узлов YaCy :)
У меня выдало много интересного, в т.ч. и таракана на викисловаре. Так что всё уже хорошо :)
p.s: посмотрел на общедоступном поисковике там результаты ещё более интересный, а с локальной ноды, выдалось в первую очередь то, что есть в локальном индексе.
На запрос «таракан» 1-10 из 3 103; (2 946 локально, 4 078 remote), 158 из 39 удаленных узлов YaCy :)
У меня выдало много интересного, в т.ч. и таракана на викисловаре. Так что всё уже хорошо :)
p.s: посмотрел на общедоступном поисковике там результаты ещё более интересный, а с локальной ноды, выдалось в первую очередь то, что есть в локальном индексе.
Linux Mint 16, ставил из репозитория с оф.сайта.
При попытке настроить браузер на использования yacy в качестве proxy, на всех сайтах вижу proxy use not allowed.
Поискав в интернете причины, узнал, что нужно на http://127.0.0.1:8090/Settings_p.html?page=ProxyAccess снять галку «Nutze Proxy Accounts». Снял. Ничего не изменилось.
ЧЯДНТ?
При попытке настроить браузер на использования yacy в качестве proxy, на всех сайтах вижу proxy use not allowed.
Поискав в интернете причины, узнал, что нужно на http://127.0.0.1:8090/Settings_p.html?page=ProxyAccess снять галку «Nutze Proxy Accounts». Снял. Ничего не изменилось.
ЧЯДНТ?
Так, с этим разобрались. Нужно зайти на http://127.0.0.1:8090/Settings_p.html?page=http и включить «Transparenter Proxy».
При этом в качестве https-прокси он выступать не может (логично с точки зрения приватности).
При этом в качестве https-прокси он выступать не может (логично с точки зрения приватности).
Там есть еще одна интересная особенность, каждому пользователю выдается имя X.yacy к которому как-то можно получить доступ, документов пока не нашел насчет этого
Теперь новая проблема: как заставить Google Chrome гонять http-запросы через proxy, а https — напрямую в инет?
плагином
Через PAC-файл?
PAC Файл хрому можно скормить тоже только через EXTENSION API.
Он разве не использует настройки IE?
Скрытый текст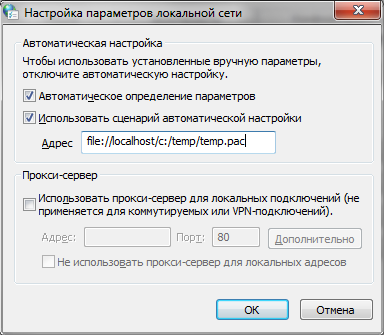
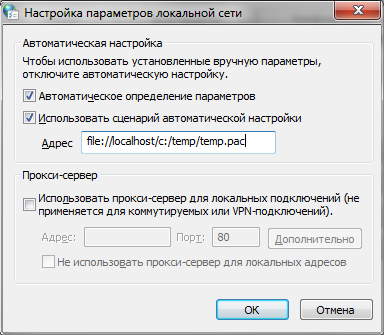
Нет.
Для Linux:
chrome/chromium может получить данные о proxy из настроек среды (если используется DE).
В случае если используется WM настройки можно задать разными способами.
1. Стандартные переменные окружения для proxy (
2.
3. Через флаги
Например для использования PAC файла:
4. Вроде был ещё способ через политики
Посмотреть текущие настройки можно тут: chrome://net-internals/#proxy
Для Win/Mac должно быть примерно так же.
Для Linux:
chrome/chromium может получить данные о proxy из настроек среды (если используется DE).
В случае если используется WM настройки можно задать разными способами.
1. Стандартные переменные окружения для proxy (
http_proxy и прочие)2.
CHROMIUM_USER_FLAGS и флаги3. Через флаги
Заголовок
--proxy-server=host:port
Specify the HTTP/SOCKS4/SOCKS5 proxy server to use for requests. This overrides any environment variables or settings picked via the options dialog. An individual proxy server
is specified using the format:
[<proxy-scheme>://]<proxy-host>[:<proxy-port>]
Where <proxy-scheme> is the protocol of the proxy server, and is one of:
«http», «socks», «socks4», «socks5».
If the <proxy-scheme> is omitted, it defaults to «http». Also note that «socks» is equivalent to «socks5».
Examples:
--proxy-server=«foopy:99»
Use the HTTP proxy «foopy:99» to load all URLs.
--proxy-server=«socks://foobar:1080»
Use the SOCKS v5 proxy «foobar:1080» to load all URLs.
--proxy-server=«socks4://foobar:1080»
Use the SOCKS v4 proxy «foobar:1080» to load all URLs.
--proxy-server=«socks5://foobar:66»
Use the SOCKS v5 proxy «foobar:66» to load all URLs.
It is also possible to specify a separate proxy server for different URL types, by prefixing the proxy server specifier with a URL specifier:
Example:
--proxy-server=«https=proxy1:80;http=socks4://baz:1080»
Load https://* URLs using the HTTP proxy «proxy1:80». And load http://*
URLs using the SOCKS v4 proxy «baz:1080».
--no-proxy-server
Disables the proxy server. Overrides any environment variables or settings picked via the options dialog.
--proxy-auto-detect
Autodetect proxy configuration. Overrides any environment variables or settings picked via the options dialog.
--proxy-pac-url=URL
Specify proxy autoconfiguration URL. Overrides any environment variables or settings picked via the options dialog.
Например для использования PAC файла:
--proxy-pac-url=http://localhost/proxy.pac4. Вроде был ещё способ через политики
Посмотреть текущие настройки можно тут: chrome://net-internals/#proxy
Для Win/Mac должно быть примерно так же.
Свой уютный поиск по stackoverflow и докам к postgresql.
Навальный, не нужен дорогой.
Навальный, не нужен дорогой.
Как один из вариантов :) вы можете проиндексировать эти сайты для всех, думаю будет полезно
Попробуйте ещё devdocs.io. О нём недавно была статья на хабре. Для документации получше будет.
А как выпилить картинки из индекса и ограничить общий объем на диске доступный под индекс?
Занимательно, а могу я его на Windows без последствий поставить не в профиль юзеру а в папку Program Files? По умолчанию папка С:\Users\X\YaCy
p.s: да, с документацией полнопопие, как рядовой пользователь сможет это использовать — не представляю :(
Понятно, даже не смотря на выключенный на сервере UAC авто обновление не работает. Печально. Хотя я наверно зря обо всём этом тут пишу.
Авто обновление чего? Оно долго происходит.
Проект как не странно активно развивается каждый день есть новые коммиты.
Но я надеюсь, что в конечном итоге это будет не java
Проект как не странно активно развивается каждый день есть новые коммиты.
Но я надеюсь, что в конечном итоге это будет не java
Авто обновление установленного софта :) При установке в PF, вне зависимости от состояния UAC обновляться само оно не не будет.
Эх, нет, не задалась у меня дружба с этой штукой, оно ставит зависимостями старую 64х битную версию Java, в итоге консоль управления Java перекрывается 64х битной версией (это критично, ибо даже настройки исключений для сайтов не настроить), а без этой 64х битной дурости YaCy просто не работает. В общем подождёмс пока научится работать с тем, что есть, I2P до такого уже доросли. А пока под снос, к сожалению. Пихать одно единственное приложение в виртуалку желания нет.
Брр, всё таки не понимаю, что происходит, попытался удалить явно остановленное приложение — инсталлятор ругнул, что оно работает, при этом службу я точно останавливал. Убил вручную процесс жабы, стала нормально запускаться служба. Видимо все проблемы из-за жабы, вспомнил, что с I2P тоже косячки подобные происходили, но как то сами поправились. В общем бррр — жаба редкостное, непредсказуемое зло.
Можно, вероятно это дурацкий вопрос, но всё же. Вот я добавляю сейчас индексы в коллекцию user (по умолчанию стояло), они хоть публично доступны, будут ли эти индексы расползаться автоматически? :)
UFO just landed and posted this here
Занимательно конечно индексатор у YaCy работает. Накидал мну ему заданий, он поработал несколько часов, а потом стал автоматически вставать на паузу, хотя этого делать его никто не просил :( Сколько бы раз я не пытался его с паузы снять, он всё равно встаёт обратно. Вряд ли это корректное поведение, не подскажите где что подкрутить, что бы убрать данное поведение, ибо у меня идей нет.
Всё, с этим кажись разобрался оказывается лимита памяти в 2000 МБ (максимального для 32х битной жабы) ему не хватало, пришлось удалить из системы всю жабу, и на чистую установить только 64х битную версию, после этого переустановил сервис YaCy (I2P пришлось устанавливать заново, без этого сервис упорно не стартовал). После переустановки жабы и сервиса установил в настройках YacY максимальный объём памяти в 10000 МБ и в тоге сервис отожрав ~8 ГБ наконец то начал индексировать всё то, что я ему скормил :)
p.s: пишу сюда из соображений того, что такие проблемы могут ещё у кого то быть, и лучше опишу особенности использования тут.
p.s: пишу сюда из соображений того, что такие проблемы могут ещё у кого то быть, и лучше опишу особенности использования тут.
Всё, кончились мои эксперименты. YacY просто перестал стартовать нормально, и теперь он просто вешается на старте (проработав 20-30 секунд, и отожрав примерно гиг оперативы). В логах при этом ничего криминального, т.е. нормальная работа а потом тишина. К сожалению более желания возиться с приложением нет.
Что-то не смог запустить как локальный прокси, если прописываю 127.0.0.1:8090 как прокси в браузере, то на любой адрес http://* вместо содержимого сайта просто открывается поисковая страница yaci аналогичная если открывать 127.0.0.1:8090
Sign up to leave a comment.
Yacy — распределённый не цензурируемый поисковик: три года спустя