
В декабре 2013 года вышла новая, седьмая версия HP Vertica. В продолжении традиции большого строительства «не маленьких данных», версия получила название «Кран» (шестая версия называлась «Бульдозер»). В этой статье я опишу, что же изменилось в новой версии.
Работа с неструктурированными данными — Flex Zone
Самым главным шагом вверх по лестнице работы с большими данными в новой версии HP Vertica можно назвать появление поддержки прямой работы с неструктурированными данными CSV и JSON форматов. В шестой версии поддерживалась загрузка данных из CSV файлов и выполнение запросов к ним, как к внешним глобальным таблицам. Если данные файлов имели заранее неизвестную, плавающую структуру, то единственным способом загрузки и работы с такими данными в Vertica являлась их предварительная обработка во внешних приложениях, таких, как ETL инструменты.
Теперь Vertica умеет работать с неструктурированными данными так же просто, как и со структурированными. Выглядит это так:
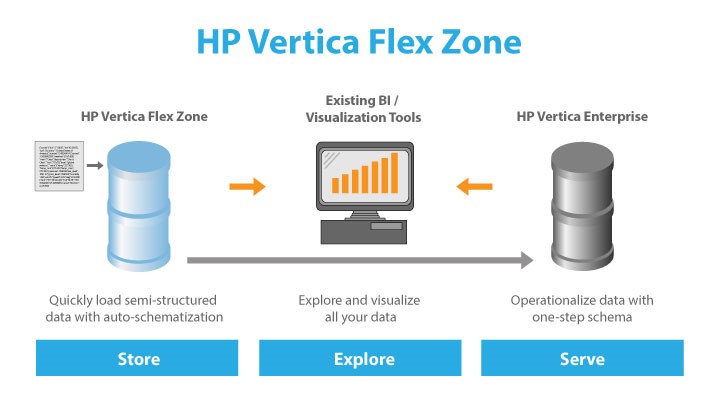
HP Vertica Flex Zone — это специальная область хранения и обработки неструктурированных данных. В БД Vertica можно создавать flex таблицы, загружать в них данные из файлов с CSV и JSON форматами и выполнять к ним запросы, соединяя эти данные в запросах с реляционными таблицами Vertica. Загруженные данные в flex таблицах хранятся на нодах кластера сервера в специальном формате, но по тем же принципам, что и реляционные данные БД. Для них так же поддерживается сжатие, зеркалирование и сегментирование данных (распределение между нодами кластера). При таком хранении, неструктурированные данные при обработке используют все преимущества MPP архитектуры Vertica, работают в отказоустойчивой масштабируемой архитектуре и участвуют в резервном копировании.
Огромным преимуществом Flex Zone можно назвать то, что это не внешнее решение, интегрированное с Vertica (как HDFS/Hadoop коннекторы), а собственная реализованная нативная поддержка неструктурированных данных. Это дает гибкость и отсутствие зависимости от ошибок и смены версий внешнего продукта. Так же это дает гарантию скорости работы при гибридной обработке в запросах с использованием таблиц структурированных и неструктурированных данных.
Где полезна Flex зона? Простой пример: требуется загружать файлы с динамической (плавающей) структурой. Причем заранее не известно, какие данные будут в дальнейшем востребованы при анализе, а какие нет. Вариантами решений такой задачи на шестой версии Vertica было бы:
- Создать в БД таблицу со всеми возможными полями, которые могут присутствовать в файлах. Отслеживать появление новых колонок в файлах и добавлять их в таблицу. Для JSON форматов написать и поддерживать дополнительный загрузчик данных, который разбирает формат и записывает данные в таблицу. Решение производительное, но дорогое в разработке и сопровождении.
- Создать в Hadoop задачу разбора и записи обрабатываемых файлов в CSV формат, а результат обработки хранить в HDFS. Подключить с HDFS получаемые файлы в качестве внешних таблиц к Vertica, указав требуемые для обработки поля. По мере появления новых полей пересоздавать подключение внешних таблиц с измененной структурой. Решение быстрое в разработке, но дорогое в сопровождении и не производительное.
Для седьмой версии Vertica данная задача по обработке, хранению и работе с файлами будет сводиться всего к двум SQL операторам:
- Определить flex таблицы (create table)
- Загрузить данные в flex таблицу (copy)
Vertica позволяет для flex таблиц описать сразу материализованные столбцы (create/alter table). Такие столбцы сразу же при загрузке заполняются значениями и хранятся как стандартные столбцы таблиц Vertica в колоночной структуре. К остальным столбцам можно обращаться динамически посредством созданного представления, которое можно перестраивать путем специализированных функций. Такой подход позволяет материализовать значимые и ключевые в запросах поля, получая прочие из хранимых неструктурированных данных в ходе обработки запроса. Такой гибридный подход позволяет удержать высокую скорость выполнения запросов даже для неструктурированных данных.
В итоге я хотел бы резюмировать: Flex зона позволяет легко и надежно хранить неструктурированные данные, извлекая из них информацию по требованию. Это экономит на трудоемкости разработки и сопровождении решения работы с такими данными и дает отличные возможности в области анализа разных данных.
Так как Flex зона работает на серверах кластера Vertica, хранится и обрабатывается там же, то и лицензируется так же, как и структурированные данные, то есть по объему исходных данных. Здесь я хотел бы заметить один большой недостаток при таком лицензировании: в отличие от структурированных данных, flex таблицы загружают для хранения в БД весь объем данных файлов, а значит лицензироваться будет все загруженное. В случае, если из неструктурированного файла используется только половина полей, хранение таких данных выходит дороговато с точки зрения лицензий. Для таких случаев все-таки получается удобнее использовать в качестве хранилища неструктурированных файлов HDFS и обрабатывать их в Hadoop, поставляя результаты обработки в Vertica. Однако схема лицензирования слишком туманно описана в документации, я буду уточнять ее положения и в дальнейшем отпишусь по этому вопросу.
Работа с файлами HDFS с помощью HCatalog
В шестой версии Vertica была возможность загружать плоские файлы с HDFS. Так же было можно подключать такие файлы для анализа в запросах в качестве внешних таблиц. Основным недостатком здесь можно назвать требование точного описания структуры загружаемого с HDFS файла. В новой версии Vertica поддержка работы с плоскими файлами HDFS расширена до поддержки метаданных описания плоских таблиц через коннектор к интерфейсу HCatalog, который обслуживает хранение описания структуры плоских файлов (метаданных) для Apache Hive. Выглядит это вот так:

При загрузке данных с файлов HDFS или выполнении к ним запроса в качестве подключенных внешних таблиц, Vertica получает с сервера HCatalog метаданные для файлов. Затем сервер загружает сами данные файлов с кластера HDFS и обрабатывает их. Возможности обработки Hadoop/Hive при этом не используются. В документации Vertica сказано, что за счет эффективных решений сервера в области анализа данных, выгоднее забирать данные и далее обрабатывать их на стороне Vertica, чем это делать на стороне Hadoop. Дополнительным преимуществом такого подхода можно назвать затраты на разработку и сопровождение. К слову сказать, в той же документации дописано, что в случае массивной и тяжелой обработки данных рекомендуется это производить на Hadoop, здесь Vertica будет менее эффективна. Так что можно сказать, что Vertica в определенном смысле не просто интегрируется с Hadoop, но и пытается его заменить в области аналитической обработки данных, предоставляя как собственные алгоритмы обработки неструктурированных данных, так и свое хранение данных в Flex зоне.
Управление большим кластером
У любого MPP всегда рано или поздно настает час X: количество серверов кластера достигает критического значения, когда затраты передачи сообщений и координации по сети начинают быть самым узким местом системы. Судя по всему, сервер HP Vertica дорос до компаний, в которых сотни и тысячи серверов являются не чудом, а рабочим моментом. Поэтому, в седьмой версии значительно расширили возможности сетевого взаимодействия серверов кластера. Теперь, помимо обычного broadcast режима работы Vertica, можно включить режим «Large Cluster Arrangement», позволяющий оптимизировать работу Vertica для кластеров с большим количеством серверов. Документация Vertica рекомендует использовать его как при количестве от 120 серверов в кластере, так и при меньшем количестве серверов, если между ними идет высоконагруженная сетевая активность. Принцип режима большого кластера заключается в том, что его ноды объединяются по группам в которых назначаются координаторы сетевого взаимодействия. Внутри каждой группы ноды общаются между собой, а между группами за сетевое общение отвечают координаторы групп.
Есть и еще одна проблема MPP, критичная для больших кластеров: это отказоустойчивость группы серверов (стоек). Как известно, Vertica зеркалирует данные между соседними нодами. До седьмой версии это происходило автоматически и не было возможности указать порядок зеркалирования. Это ставило под угрозу работу кластера в целом, если у него были множество стоек серверов и одна из стоек отключалась. Получалось, что у кластера исчезали соседние ноды и он был вынужден останавливать свою работу. В седьмой версии эта проблема была решена с помощью «Fault Groups». Теперь для базы данных есть возможность расписать группы серверов по стойкам и расписать по ним работающие ноды кластера:
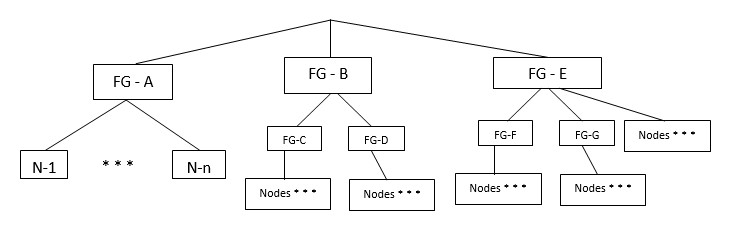
Сервер Vertica при сегментировании данных будет гарантировать, что зеркало данных серверов будут хранится в разных отказоустойчивых группах. Таким образом, выключение одной группы серверов (стойки) не приведет к остановке кластера, так как у другой группы будет зеркало, которое они смогут подключить для работы кластера.
JDBC API Key-Value
Изначально HP Vertica проектировался, как аналитический сервер данных, позволяющий быстро проводить анализ над большими объемами данных. Постепенно возможности сервера росли и теперь Vertica уже можно назвать полноценным BigData сервером, позволяющим обрабатывать как структурированные, так и неструктурированные данные. Любой BigData сервер должен в том числе уметь не только быстро анализировать данные, но и искать значения по ключу, то есть поддерживать быстрый доступ к данным, выступая в роли Key-Value сервера. Команда Vertica серьезно решила покрыть все требования BigData в своем продукте и реализовала эту возможность посредством расширения для JDBC драйверов Vertica. Изначально поиск информации по ключу в Vertica выглядел как обычный SELECT запрос в БД с фильтром в WHERE по ключу, в результате которого запрос распределялся между серверами кластера, где все начинали работу, пока одна из нод кластера не находила нужный результат и возвращала его вызвавшей клиентской сессии. Выглядит это так:

Теперь, с помощью интерфейса Key-Value можно запросить данные следующим образом:
VGet get = conn.prepareGet("public", "users");
get.addPredicate("id", 5);
ResultSet rs = get.execute();
При выполнении этого кода, интерфейс JDBC сразу определит, на каком сервере кластера находится требуемая запись и получит ее:

Достигается работа с Key-Value за счет определенных правил сегментации записей и наличия PK/UK ключа в обрабатываемой таблице. Без наличия этих правил на обрабатываемой таблице, данный способ работать не будет.
Резюмируя можно сказать, что Key-Value интерфейс позволяет организовать высокоэффективный способ быстрого поиска и получения данных по заданному ключу для множества сессий, без лишних нагрузок на сервера кластера по процессорному времени, дисковой и сетевой активности. Я думаю, это в первую очередь оценят компании, связанные с вебом, для которых всегда важна скорость поиска информации по ключу.
Клиентские драйвера
В драйвер JDBC Vertica была добавлена поддержка стандарта JDBC 4. В первую очередь это полезно для решений, использующих JNDI. Так же расширена поддержка получения метаданных базы через драйвера и улучшена работа пула соединений.
Для всех драйверов введена поддержка «connection failover» и «connection load balancing». Можно указать список хостов, по которым можно соединятся по очереди, если предыдущий в списке оказался не доступным. Так же, для соединения можно указать опцию балансировки подключения. Тогда при подключении к первому доступному по списку хосту, подключенный сервер может перенаправить подключение клиента на другой, менее загруженный доступный хост. Эти возможности фактически убирают необходимость использования стороннего балансировщика нагрузки, выполняя его функции.
Для идентификации пользователя так же в клиентских драйверах доступен протокол Kerberos 5 версии.
В драйверах была оптимизирована работа пакетной вставка записей (batch inserts). По заявлениям вендора, теперь скорость вставки значительно выше и требуется меньшие затраты ресурсов на стороне клиентской части.
Производительность и отказоустойчивость
Оптимизирована работа кластера в случае выхода из строя серверов. Это достигается за счет равномерного перераспределения нагрузок вычислений между другими нодами кластера. Раньше за отказавшую ноду приходилось работать соседке, содержащей ее зеркало, что приводило к общему снижению производительности кластера из-за ожидания рабочих нод, пока работающая за двоих нода отработает вычисления как за себя, так и за упавшую соседку.
Для ускорения обработки расчета количества уникальных значений полей в таблицах с большим количеством записей добавлены функции примерного подсчета количества с погрешностью. Это позволяет значительно ускорить выполнение запросов, если погрешность допускается.
Оптимизатор теперь поддерживает новый алгоритм частичной сортировки группировок, использующий гибрид алгоритмов GROUPBY PIPELINED и GROUPBY HASH. Это позволяет более эффективно выполнять запросы агрегации данных с использованием части отсортированных столбцов, что уменьшает потребление памяти и свопа на диске для хеширования.
Ускорена работа оператора MERGE для таблиц, которые имеют PK/UK ключи, по которым идет объединение данных и набор колонок и значений для вставки и изменений совпадает. Если же эти условия не соблюдаются, то объединение таблиц осуществляется по алгоритму предыдущих версий без оптимизации.
Усовершенствована работа загрузчика данных COPY, где теперь более эффективно происходит разбор и парсинг загружаемого файла путем его разбивки на несколько частей и параллельной обработки между ядрами ноды.
Расширение SDK
В предыдущих версиях Vertica можно было на языке C расширять функциональность сервера путем написания собственных скалярных (простых) функций, функций трансформации данных (olap) и функций обработки загружаемых данных операторами COPY и CREATE EXTERNAL TABLE. Теперь это доступно так же на Java платформе. Специально для этого в новую версию HP Vertica включен Java SDK.
Остальные расширения
Значительно расширена функциональность веб консоли (Management Console). Все больше этот инструмент превращается из средства мониторинга работы системы в средство полноценного администрирования кластеров. Теперь консоль поддерживает просмотр планов и профилей выполнения запросов и запуск дизайнера для оптимизации и создании новых проекций. Даже добавлена поддержка скинов консоли, хотя мне не понятно, зачем это нужно.
Значительно улучшен сам Database Designer. Переработаны алгоритмы определения лучших кандидатов сегментации и упаковки столбцов. Добавлена возможность анализа корреляции столбцов (тесной связи между ними), то есть фактически используется профилирование данных при анализе. Добавлены функции, позволяющие программным путем создать область дизайна для указанных таблиц и запросов, проанализировать их и добавить новые проекции или изменить существующие, с более оптимальной структурой. Это позволяет автоматизировать работу по тюнингу выполнения запросов данных. Например, можно самостоятельно разработать и запланировать сбор тяжелых запросов в указанное время, провести их анализ и получить рекомендации по оптимизации структур данных, применив их автоматически на базе данных или сохранив в виде скрипта для ручного выполнения в дальнейшем. Дополнительно ведено понятие групп запросов, позволяющее выявить дизайнеру типовые запросы и производить оптимизацию с учетом веса частоты их использования. Это например, позволяет не строить лишние проекции на тяжелые ночные запросы, если они выполняются раз в сутки.
Усовершенствована система инсталляции сервера. Теперь Vertica самостоятельно проверяет большее количество настроек OS и пытается их исправить. В случае невозможности, рекомендации по ручной настройке выдаются в ходе инсталляции.
Так же были расширены функциональность языка SQL, функций, служебных таблиц, параметров конфигурации и т.д. Все это можно более подробно почитать в документации HP Vertica.
Резюмируя статью
HP Vertica действительно выросла из роли низкого мощного бульдозера до высокого сильного крана. Строительство BigData идет полным ходом. Объем изменений с учетом того, что продолжали исправно выходить паки для шестой версии с расширением функциональности, действительно впечатляет.
Автор Константинов Алексей
Архитектор хранилищ данных
Компания EasyData
Пожалуйста при использовании информации статьи ссылайтесь на автора.
