Comments 129
Я не знаток английского, но children множественное от child, то есть поэтому не может быть getChildrensAll(), должно быть getChildrenAll().
P.S. Или вру?
P.S. Или вру?
Да все верно, нужно изменить, чтобы не вводить в заблуждение. На раннем этапе я исходил из того, что методы с буквой s на конце возвращают множественное значение и намеренно сделал эту ошибку.
Чтобы не было лишних раздумий, лучше просто использовать то, что правильно звучит: getAllChildren(). Ну и, конечно, избегать наличия классов, в которых необходимо группировать методы по некоему префиксу (getChildren, getChildrenAll, getChildrenBy). Это можно достичь с помощью отдельных классов, например, ClassMetadata\Children, ClassMetadata\Parent.
В таком случае будете иметь, например, ClassMetadata\Children::getAll() и ClassMetadata\Parents::getAll(), соответственно, необходимость иметь разные имена для разных методов пропадёт: $meta->getChildren()->getAll(), $meta->getParents()->getAll().
В последнее время наличие некоего длинного имени метода своём классе всегда расцениваю как звонок к тому, что пора декомпозировать класс.
В таком случае будете иметь, например, ClassMetadata\Children::getAll() и ClassMetadata\Parents::getAll(), соответственно, необходимость иметь разные имена для разных методов пропадёт: $meta->getChildren()->getAll(), $meta->getParents()->getAll().
В последнее время наличие некоего длинного имени метода своём классе всегда расцениваю как звонок к тому, что пора декомпозировать класс.
Не врёте.
Можно просто
getChildren().С точки зрения понятности наименования, просто getChildren() может возвращать несколько наследников (наверное по какому-то критерию, чтобы убедиться — надо лезть в документацию), а вот getChildrenAll() вернет всех наследников, тут и в документацию лезть не надо.
Есть уже метод без All, он возвращает всех детей только первого уровня, а с All возвращает абсолютно всех.
«class is not found» туда же…
ну сразу что бросилось в глаза new и подобных экшенов не видать
простите, но ничего нестандартного я тут и не увидел. А по поводу хранения классов в разнобойных файлах, по-моему плохая практика — при увеличении количества классов просто замучаешься их сам искать
Вы всё ещё не используете нормальную IDE?
иде-идеёй, но расположение то лучше знать интуитивно…
Вы предлагаете на любой говнокод любую непродуманную архитектуру, лапшу и прочее — отвечать: «Вы всё ещё не используете нормальную IDE?».
Эм, а каким образом архитектура проекта заключается в сортировке классов по файлам?
Я не считаю что именно способ расположения классов является неудачным решением.
На мой взгляд, подобная свобода (которая является на самом деле ограничением), заставит разработчика использовать IDE и поиск класса по названию, что в результате повысит его скорость нахождения нужного участка кода.
А текущая практика раскидывания файлов по неймспейсам содинаковым наименованиям файлов, меня так вообще удручает.
Привет вам от 20 файлов Data.php в проекте и поиску по названию файла.
Что-то с этим делать надо в PHP, но что?
Я не считаю что именно способ расположения классов является неудачным решением.
На мой взгляд, подобная свобода (которая является на самом деле ограничением), заставит разработчика использовать IDE и поиск класса по названию, что в результате повысит его скорость нахождения нужного участка кода.
А текущая практика раскидывания файлов по неймспейсам содинаковым наименованиям файлов, меня так вообще удручает.
Привет вам от 20 файлов Data.php в проекте и поиску по названию файла.
Что-то с этим делать надо в PHP, но что?
Дело не в IDE, а в структуре классов. Не стоит хранить вилку в платяном шкафу, даже если у вас есть специальный человек, который всегда знает, где она лежит.
PHP не поддерживает классы внутри классов. Иногда это было бы полезно. Фреймворк позволяет объявлять несколько классов в одном файле, однако частично соблюдается стандарт PSR-0 (проверку анализатором можно отключить) — название первого класса в файле должно совпадать с названием файла.
не вижу практической ценности, те же «псевдо-внутренние» классы можно и в тот же файл с основным классом засунуть, и очевидно погрузка так и так будет
Regenix позволяет так делать, т.к. Class Scanner основывается не на названиях классов.
честно говоря все равно не вижу смысла, у меня на <5.3 был сканер классов (как часть автолоадера), не скажу, что он был быстрый
Возможно сама операция сканирования нагрузочная, но не более 1 сек при большом наборе файлов, а обычно 50-100 млсек, но когда данные берутся из кеша, то на это тратится около 0.3 млсекунды, если не меньше.
PSR-0 как-бы не позволяет нескольких классов в одном файле.
Очень вредно делать «иногда так, а иногда так».
Хранение классов в разнобойных файлах может понадобиться при использовании различных сторонних библиотек. Но при наличии в проекте composer'а непонятно, зачем это дополнительно поддерживать средствами фреймворка.
Ещё один php-mvc-framework…
Вот есть там метод такой loadDeps() который делает такие операции:
Метод вызывается внутри _registerDependencies(), который вызывается в register(), который в свою очередь содержит ещё пачку file_exists, который вызывается из _registerCurrentApp(), который вызывается в init(), который в initWeb($rootDir), который вызывается в index.php. Если я правильно все понял, куча файловых операций, включая чтение текстового файла и парсинг json, будет выполняться каждый запрос. Почему бы не подключать конфиг в виде нормально кешируемого байткод-кешерами php-файла с php-массивом?
Вообще, код выглядит перемудрёным и переусложненным. Смысл делать java из php — сомнительная затея вообще, на мой взгляд, на php можно писать намного проще, сохраняя при этом гибкость и скорость работы и разработки.
Вот есть там метод такой loadDeps() который делает такие операции:
$file = $this->getPath() . 'conf/deps.json';
if (is_file($file))
$this->deps = json_decode(file_get_contents($file), true);
Метод вызывается внутри _registerDependencies(), который вызывается в register(), который в свою очередь содержит ещё пачку file_exists, который вызывается из _registerCurrentApp(), который вызывается в init(), который в initWeb($rootDir), который вызывается в index.php. Если я правильно все понял, куча файловых операций, включая чтение текстового файла и парсинг json, будет выполняться каждый запрос. Почему бы не подключать конфиг в виде нормально кешируемого байткод-кешерами php-файла с php-массивом?
Вообще, код выглядит перемудрёным и переусложненным. Смысл делать java из php — сомнительная затея вообще, на мой взгляд, на php можно писать намного проще, сохраняя при этом гибкость и скорость работы и разработки.
Чтение JSON не происходит каждый заново, конкретно deps.json и остальные файлы конфигурации кешируются в APC или XCache и перезагружаются только при изменении этих файлов. В фреймворке я старался снизить количество операций по чтению файлов. На счет хранения конфигураций в PHP файлах, исходил из того, что PHP файлы не для конфигураций и при желании новичок может засунуть туда какую-нибудь логику.
P.S. Я не отрицаю что фреймворк мудренный внутри, но код приложений достаточно простой и понятный.
P.S. Я не отрицаю что фреймворк мудренный внутри, но код приложений достаточно простой и понятный.
Хорошо, значит я не докопал до места, где оно керишуется. А парсинг json и сборка конфигурации — происходит каждый запрос?
Есть два режима работы приложения DEV и PROD, в первом режиме (который включен по-умолчанию) почти ничего не кешируется таким образом. В режиме продакшена парсинг кешируется, вызываются лишь функции проверяющие время модифицирования файла, парсинг JSON и других конфигураций при каждом запросе не происходит если вы в продакшен режиме.
Ага, увидел, значит этой болезни там нет — это хорошо. Ещё по поводу самого кода — я бы все-таки разнёс все классы (включая статические, включая описанные в include.php, в разные файлы с именами классов (и директориями неймспейсов). Так гораздо удобнее с ними работать. И ещё, правила в .htaccess это конечно замечательно, но мне гораздо спокойнее когда в проекте вся публичная часть лежит в отдельном каталоге public (или htdocs).
Да я это понимаю (вначале так и было), сделал ради оптимизации. Возможно в будущем просто напишу утилиту, которая будет собирать из исходников один файл.
htaccess прописан так, что прямого доступа к файлам нет, только к статичным. Фреймворк можно держать в отдельной папке, он подключается откуда угодно, главное подключить файл include. Но пока я над этим сильно не работал.
htaccess прописан так, что прямого доступа к файлам нет, только к статичным. Фреймворк можно держать в отдельной папке, он подключается откуда угодно, главное подключить файл include. Но пока я над этим сильно не работал.
Сомнительная оптимизация, так как при использовании кэша байткода все файлы лежат в памяти и доступ к ним практически мгновенный. Я пришел к такому выводу, когда я оптимизировал через xhprof разные вещи. В итоге, при полном избавлении от файловых операций (включая file_exists) и после перехода на php array конфиги, самые большие затраты цпу пришлись на… вызовы microtime(), который вызывался в начале и конце каждого скрипта.
Все же я иду больше от того, что PHP array это файлы исходного кода, а не файлы конфигурации. Пусть даже это и приводит к небольшому ухудшению производительности.
На счет кеша байткода, я так и предполагал, однако например APC мне не давал в этом смысле какого-то выигрыша. Возможно Zend Opcache ведет себя по-другому.
На счет кеша байткода, я так и предполагал, однако например APC мне не давал в этом смысле какого-то выигрыша. Возможно Zend Opcache ведет себя по-другому.
Во «взрослых» фреймворках уже давно реализованы конфигураторы, компилирующие на продакшне различные форматы конфига в php-файлы.
Можно узнать, о каких взрослых фреймворках вы говорите?
Symfony компилирует, вроде, yaml в php.
Заранее извиняюсь, что рассматриваю Symfony в совокупности с Doctrine, но иначе не представляю зачем рассматривать отдельно их. Это как смотреть на абстрактного коня в вакууме. Да, можно поставить не Doctrine, но она идет как коробочное решение, так что не обессудьте.
Итак, используется Symfony 2 с Doctrine все конфиги в Yaml. Конфиги Doctrine после первого запуска кешируются в array(по умолчанию) Слева как есть, справа с изменением YamlParser на нативное расширение для PHP:
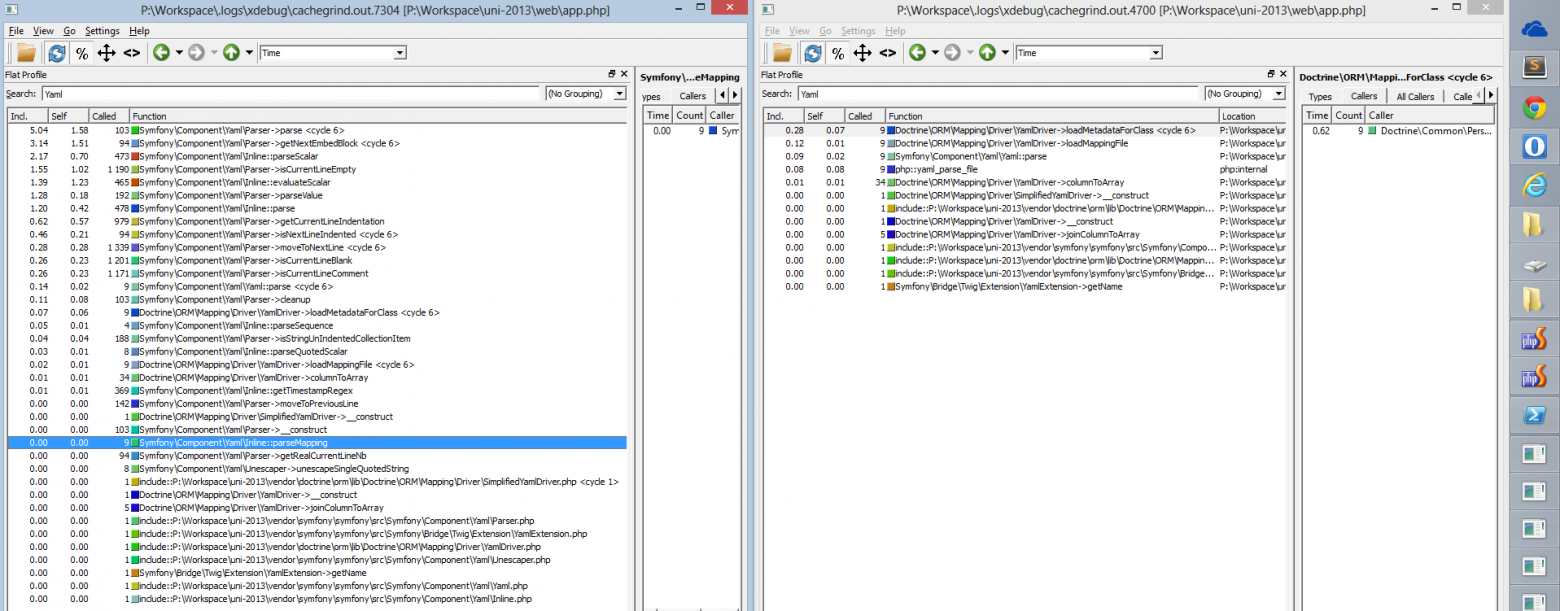
Это трейс небольшого проекта. В большом, доля парсинга Yaml у нас достигает 50% всего времени. Исследование профайлера показывает, что всё это хозяйство дёргается из bootstrap.php.cache
Так что у меня пока язык не повернется сказать, что:
p.s.
не отрицаю, что возможно это можно пофикить, но пока не до этого было.
Итак, используется Symfony 2 с Doctrine все конфиги в Yaml. Конфиги Doctrine после первого запуска кешируются в array(по умолчанию) Слева как есть, справа с изменением YamlParser на нативное расширение для PHP:

Это трейс небольшого проекта. В большом, доля парсинга Yaml у нас достигает 50% всего времени. Исследование профайлера показывает, что всё это хозяйство дёргается из bootstrap.php.cache
Так что у меня пока язык не повернется сказать, что:
Во «взрослых» фреймворках уже давно реализованы конфигураторы, компилирующие на продакшне различные форматы конфига в php-файлы.
p.s.
не отрицаю, что возможно это можно пофикить, но пока не до этого было.
Можно компилировать отдельной тулзой и юзать уже как php-конфиги (не знаю, есть ли там готовое). Я предпочитаю не париться и юзать php.
Всё это было бы разумно, если бы в yml конфигах использовались особенности yaml, типа якорей и алиасов, а так никаких преимуществ в сравнении с php конфигами нет. зато имеется дополнительный парсинг, который нужно кешировать, возможные проблемы из-за форматирования (лет пять назад из-за этого выбросил yml из фреймворка).
Понятно ещё, когда используют xml, его можно валидировать через схемы, можно трансформировать через xlst, делать удобные выборки через xpath. А yml и ini — бессмысленные дополнительные преобразования.
Понятно ещё, когда используют xml, его можно валидировать через схемы, можно трансформировать через xlst, делать удобные выборки через xpath. А yml и ini — бессмысленные дополнительные преобразования.
Мы так же перешли на php конфиги с тех пор как обнаружили данную фишку :)
Конфиги не кешируются в Array(). Они компилируются в классы. Парсинга yaml там быть не должно, т.к. вся конфигурация компилится в методы хардкодно инстанциирующие сервисы со всей конфигурацией:
То, что где-то там у вас трейс длинный, а где-то нет — если вы нативное расширение PHP используете, то его выполнение для дебаггера прозрачно. Если контроллер пустой, то временные затраты на логику инстанциирования сервисов достигает не 50%, а всех 80-90.
P.S. Большой трейс — это не плохо, это хорошо, т.к. в данном случае показывается хорошую декомпозицию.
protected function getDoctrine_Dbal_DefaultConnectionService()
{
return $this->services['doctrine.dbal.default_connection'] = $this->get('doctrine.dbal.connection_factory')->createConnection(array('dbname' => 'test', 'host' => '127.0.0.1', 'port' => NULL, 'user' => 'root', 'password' => '', 'charset' => 'UTF8', 'driver' => 'pdo_mysql', 'driverOptions' => array()), new \Doctrine\DBAL\Configuration(), new \Symfony\Bridge\Doctrine\ContainerAwareEventManager($this), array());
}
То, что где-то там у вас трейс длинный, а где-то нет — если вы нативное расширение PHP используете, то его выполнение для дебаггера прозрачно. Если контроллер пустой, то временные затраты на логику инстанциирования сервисов достигает не 50%, а всех 80-90.
P.S. Большой трейс — это не плохо, это хорошо, т.к. в данном случае показывается хорошую декомпозицию.
P.S. Большой трейс — это не плохо, это хорошо, т.к. в данном случае показывается хорошую декомпозицию.
Что за бред?
Конфиги не кешируются в Array(). Они компилируются в классы.
symfony.com/doc/master/reference/configuration/doctrine.html
Не знаю что да зачем и т.д. в конфигах по умолчанию в array
То, что где-то там у вас трейс длинный, а где-то нет — если вы нативное расширение PHP используете, то его выполнение для дебаггера прозрачно. Если контроллер пустой, то временные затраты на логику инстанциирования сервисов достигает не 50%, а всех 80-90.
Вы не на трейс смотрите а на время выполнения и сколько его занимает от всего проекта. И вообще тут трейс парсинга Yaml, а не инстанцирование сервисов.
Собирать в один файл не помогает в большинстве случаев. Правильно настроенный APC / Opcache это только замедляет.
При отсутствии кеширования APC — помогает.
Конечно, если мы говорим про абстрактное «подключение всех классов».
Почему бы при отсутсвии кеширования не установить и включить его? Или опять «а как же совместимость с shared хостингами без нормальной техподдержки»?
Вы строите свои оптимизации на тестах или только на предположениях, как это должно работать?
Вот сравнение, например: blgo.ru/blog/2013/08/07/autoload-req-pha/
Вот сравнение, например: blgo.ru/blog/2013/08/07/autoload-req-pha/
Из опыта скажу: пользователь который может запихнуть в plain-PHP конфиг логику — легко может забить на настройку DEV / PROD.
Можно узнать, а зачем ещё 1 framework, когда есть Yii и Symfony 2?
Ои оба покрывают всё множество извращенцем своими различиями в подходах к разработке веб-приложений.
Ои оба покрывают всё множество извращенцем своими различиями в подходах к разработке веб-приложений.
Так какие из идей уникальны?
Пардон, а в чем высший смысл deps.json? Разве просто composer.json (который, как я понимаю, в секции composer файла deps.json) не покрывает все нужды?
Там хранятся зависимости от assets библиотек — javascript, html, css библиотеки. Еще там хранятся зависимости к модулям фреймворка, но это еще под вопросом, возможно они будут хранится в composer.
Нууу, думаю, излишне городить лишнюю сущность, потенциально усложняющую и тормозящуюю систему, когда можно стандартным инструментом, который и так используется, задать местоположение для третьесторонних компонентов и, скажем, дернуть скрипт обновления ассетов в коллбеке, как это сделанно в Symfony с недавних (>= 2.3) пор. Там после «composer update» чистится кеш и обновляются ассеты.
Можно было бы просто воспользоваться bower-ом для управления assets-зависимости. Он удобнее и уже стал стандартным инструментом.
Далее заменить свой роутинг, i18n и другие компоненты на компоненты от symfony2, интегрировать Twig, убрать лишние шаги из ленивой загрузки классов, проверку кода перенести в build скрипт в CI (где ей и место) и будет yet-another-framework %)
Regenix позволяет интегрировать любые другие шаблонные движки. Скрипт build и так возможно запускать из CI. С таким же успехом можно заменить в любом другом фреймворке все на компоненты Symfony2.
Сифони тоже позволяет интегрировать любые шаблонизаторы. Более того, любые ORM, мэйлеры и т.п. В общем, за счёт конфигуратора и DI там можно внедрить, что хочешь, куда хочешь. Насколько знаю, единственное, что он не позволяет — так это использовать чужой http-kernel. В том смысле, что при использовании другого request-response ядра фреймворк уже не будет симфони.
Fabien Potencier о Symfony2: fabien.potencier.org/article/49/what-is-symfony2
Fabien Potencier о Symfony2: fabien.potencier.org/article/49/what-is-symfony2
yet-another? Symfony и получится.
Он тянет за собой Node.js (лишняя зависимость), слишком перемудрен на первый взгляд.
Assets которых нет в репозитарии можно держать в папке проекта и подключать их напрямую, используя относительный путь в шаблоне. Я точно не уверен, но кажется в Symfony просто указывается папка с assets. В Regenix если вы подключаете bootstrap, с ним автоматически тянется и jQuery, той версии, которая с ним совместима. Далее, когда вы подключаете bootstrap в шаблоне, подключать jQuery не нужно (т.к. это его зависимость), он подключается автоматически.
UFO just landed and posted this here
Не у всех есть лицензия на PhpStorm и не все ею пользуются. К тому же в IDE это все на уровне необязательных к исполнению подсказок. А так можно организовать проверку на стороне сервера интеграции, а это снижает риск возникновения ошибок и попадания в репозитарий «плохого» кода. Проверка во время открытия страницы сделана как полезное дополнение, для удобства разработчика.
UFO just landed and posted this here
Всегда будут противники коробочного решения. PHP-Parser (проект для парсинга php-кода) делает примерно тоже самое что и PHP_CodeSniffer. EAP работает не весь год.
UFO just landed and posted this here
Я не изучал досконально Laravel, поэтому ответить на вопрос не могу.
Приделать можно, но используя фреймворк вам делать этого не нужно, вам много чего приделывать в этом фреймворке не нужно. Когда есть большое количество решений одной проблемы, каждый приделывает что-то свое. Таким образом размывается единый стандарт пользования фреймворка. И получается, что каждый использует один и тот же фреймворк, но с разными инструментами.
Приделать можно, но используя фреймворк вам делать этого не нужно, вам много чего приделывать в этом фреймворке не нужно. Когда есть большое количество решений одной проблемы, каждый приделывает что-то свое. Таким образом размывается единый стандарт пользования фреймворка. И получается, что каждый использует один и тот же фреймворк, но с разными инструментами.
UFO just landed and posted this here
Я никого не призываю переходить на этот фреймворк. Скорее сейчас я больше заинтересован в людях, кому будет интересно вложить свой вклад в проект в качестве разработчиков фреймворка.
Но есть фреймворки, архитектура которых иная. Play framework для Java и Scala как пример. В начале статьи я писал, что ориентировался на этот фреймворк.
Это нормально. Некоторые фреймворки специально задумывались для этого (Symfony).
Но есть фреймворки, архитектура которых иная. Play framework для Java и Scala как пример. В начале статьи я писал, что ориентировался на этот фреймворк.
А где composer.json?
Как по мне то слишком много статики в ActiveRecord. Лучше бы разбить на классы.
Во вторых нет документации для методов классов и тд.
Router::reverse ( github.com/dim-s/regenix/blob/dev/framework/mvc/route/Router.php ) тихий ужас. Надо разбить на методы или хоть как-нибудь почистить, в методе не должно быть столько логики сразу, плохо для расширения.
Класс сканнер это конечно интересно (привет Кохана? ), но есть ли для этого продуманный кеш? а то на каждом запросе такие штуки делать дорого.
Стандарты, стандарты… То у вас есть пробел перед { то нет.
Глаза плачут кровью
Во вторых нет документации для методов классов и тд.
Router::reverse ( github.com/dim-s/regenix/blob/dev/framework/mvc/route/Router.php ) тихий ужас. Надо разбить на методы или хоть как-нибудь почистить, в методе не должно быть столько логики сразу, плохо для расширения.
Класс сканнер это конечно интересно (привет Кохана? ), но есть ли для этого продуманный кеш? а то на каждом запросе такие штуки делать дорого.
Стандарты, стандарты… То у вас есть пробел перед { то нет.
Глаза плачут кровью
Надеюсь что мой коммент не будет воспринят сильно агрессивно. Ни в коем случае не хочу обидеть автора, просто указать на несколько замечаний =)
ActiveRecord это вы имеете ввиду Propel ORM? Я думаю при желании логику работы с моделями можно выносить в отдельные классы-сервисы и подключать их через DI в контроллеры.
Конечно я осознавал, что делая что-то сложное, я теряю в производительности. Но я еще исходил из того, что если мне нужно писать что-то крупное и нагрузочное у меня для этого есть Java, а php можно использовать только как Frontend. Например для этих целей очень удобно использовать Apache Thrift.
На счет скобочек, проект в разработке и думать о скобочках нет времени. Форматирование исправляется подходящими инструментами за несколько минут. Говоря про стандарты, я меньше всего имел ввиду такие мелочи в code-style.
Конечно я осознавал, что делая что-то сложное, я теряю в производительности. Но я еще исходил из того, что если мне нужно писать что-то крупное и нагрузочное у меня для этого есть Java, а php можно использовать только как Frontend. Например для этих целей очень удобно использовать Apache Thrift.
На счет скобочек, проект в разработке и думать о скобочках нет времени. Форматирование исправляется подходящими инструментами за несколько минут. Говоря про стандарты, я меньше всего имел ввиду такие мелочи в code-style.
Я имел ввиду класс github.com/dim-s/regenix/blob/dev/framework/mvc/AbstractActiveRecord.php (кстати при чем он к папке mvc? )
Честно говоря не вижу большой надобности в фичах «Class Сканер», можно пример когда он был бы полезен?
Честно говоря не вижу большой надобности в фичах «Class Сканер», можно пример когда он был бы полезен?
Да все классы связанные с ActiveRecord устарели и не используются, их надо будет удалить. Они остались еще со времен, когда не планировалось внедрять стороннее решение по типу Propel.
Сканер полезен тем, что хранит мета-информацию о файлах, с помощью которой можно сделать удобную авто-регистрацию классов. Например, в проекте вы объявляете новый класс Тега для шаблонизатора. То что вы наследуете его от абстрактного класса тега, уже дает знать фреймворку, что вы хотите его использовать. Не нужно думать о том, где прописывать регистрацию этих тегов. Это один из примеров.
Сканер полезен тем, что хранит мета-информацию о файлах, с помощью которой можно сделать удобную авто-регистрацию классов. Например, в проекте вы объявляете новый класс Тега для шаблонизатора. То что вы наследуете его от абстрактного класса тега, уже дает знать фреймворку, что вы хотите его использовать. Не нужно думать о том, где прописывать регистрацию этих тегов. Это один из примеров.
Конечно я осознавал, что делая что-то сложное, я теряю в производительности. Но я еще исходил из того, что если мне нужно писать что-то крупное и нагрузочное у меня для этого есть Java, а php можно использовать только как Frontend.
Вот это особенно пугает.
Из-за модели работы PHP — рождаться и умирать, всегда будут проблемы с производительностью. Поэтому PHP сейчас подходит для средних и небольших проектов, для крупных нестандартных проектов есть более подходящие языки и архитектуры, моё субъективное мнение.
То есть Yahoo или Wikipedia — средние или небольшие?
Начитались про рождаться и умирать и туда же. При правильной настройке (быстро рождаться и правильно умирать) — это вполне можно считать плюсом.
Если выйдет более легковесный чем симфони (кнч с документацией и длительной поддержкой), то взял бы на вооружение нескольких проектов.
В мире PHP достаточно много известных фреймворков, однако многие из них не подходят нам по многим критериям.
Каждый хотя бы раз в жизни говорил это. К чему это приводит — через пару лет «О, а давайте перейдём на <имя фреймворка>!»
Regenix использует нестандартную модель загрузки классов, он не использует имена классов и их namespace для поиска их местоположения как сейчас принято делать в PHP. Class Scanner сканирует папки исходников на наличие в них классов. Что это означает? Для фреймворка есть понятия class paths (привет из Java), при добавлении нового источника классов (т.е. папки с исходниками), фреймворк производит сканирование и записывает всю найденную информацию о классах в кеш.
Composer позволяет генерировать автозагрузчик различными способами, в том числе так, как говорите вы: маппинг классов, маппинг неймспейсов, PSR-0.
Для примера возьмем использование несуществующего класса в use (вывод ошибок во фреймворке)
Привет, нормальные IDE.
Вот так, например, можно найти всех наследников класса за достаточно быстрое время (стоимость этой функции доли миллисекунды)
Зачем может понадобиться поиск наследников класса при выполнении программы — я вообще мало представляю.
Менеджер зависимостей для assets, модулей и зависимостей composer
Наличие папки «framework/lib» намекает на то, что даже если composer где-то в репозитории и есть, то composer'а в репозитории нет.
update: Оказалось, это врапперы. Тогда непонятно вынесение их в отдельную папку, а не размещение в папке тех компонентов, к которым они относятся.
namespace controllers;
class Clients extends Controller
Непонятен выбор стиля именования классов и неймспейсов.
Модели — реализованы с помощью стороннего проекта — Propel ORM
Это не модели, это сущности. M в MVC — это не про базы данных.
regenix\deps
regenix\exceptions
regenix\lang
regenix\libs
regenix\logger
Не очень понятна структура неймспейсов. Что-то сгруппировано по компоненту (logger), что-то по некоему third-party признаку (libs), где-то вообще решили не запариваться и кинули всё в кучу (lang).
Новый нестандартный MVC фреймворк для PHP
А в чём конкретно нестандартность? MVC, роутинг, ORM, конфиги, консоль, i18n, шаблонизатор. Разве что что-то там про ошибки. С другой стороны, до профайлеров «больших» фреймворков ещё очень далеко.
P.S. Как некая разработка и вклад в портфолио — ок. Но для публичного open-source релиза, имхо, сильно далеко. Да и смысла особого нет.
Частично ответы на ваши вопросы в статье, частично в комментариях.
Стиль именования классов и неймспейсов как в Java, пакеты все с маленькой буквы, классы с большой.
P.S. OpenSource для того и нужен, чтобы найти единомышленников еще до релиза и развивать проект. Многие известные Open-Source проекты до сих пор не имеют стабильных версий (т.е. нулевые версии.)
Стиль именования классов и неймспейсов как в Java, пакеты все с маленькой буквы, классы с большой.
P.S. OpenSource для того и нужен, чтобы найти единомышленников еще до релиза и развивать проект. Многие известные Open-Source проекты до сих пор не имеют стабильных версий (т.е. нулевые версии.)
0-версия — это не только нестабильность. Версия 0.9 — это чаще всего очень стабильный продукт. Смена мажорной версии — это чаще всего добавление серьёзных фич, или смена подхода в целом, или потеря обратной совместимости. В принципе, можно было бы 0 сменить на 1. Но зачем? Чтобы заставить пользователя продукта думать, что теперь надо всё заново тестировать?
С другой стороны, есть продукты, которые начинаются сразу с 1-х версий. Таким образом публичный релиз может выходить под, например, 3-й версией.
С другой стороны, есть продукты, которые начинаются сразу с 1-х версий. Таким образом публичный релиз может выходить под, например, 3-й версией.
Очень интересные ответы, было бы интересно услышать ваши мысли о PHPixie ( о котором мои посты) =)
Возможность блокировать использование супер-глобальных переменных ($_GET, $_POST, etc)
Стесняюсь спросить, но как вы предлагаете обрабатывать входящие параметры?
Для этого нужно использовать свойства и методы контроллеров, параметры $_GET можно получать через аргументы метода действия. Об этом можно почитать здесь: github.com/dim-s/regenix-documentation/blob/master/en/controllers.md#query-parameters
После обсуждений и критики в комментариях сделаны выводы, поэтому:
1. Классы будут разнесены по разным файлам (те что были объединены в один).
2. Анализатор для PSR-0 будет полностью следовать стандарту, а не частично
3. Будут исправлены недочеты в именах методов (all и т.п.)
4. Конфигурация composer возможно будет вынесена в отдельный файл composer.json
Если есть другие предложения пишите сюда: github.com/dim-s/regenix/issues
1. Классы будут разнесены по разным файлам (те что были объединены в один).
2. Анализатор для PSR-0 будет полностью следовать стандарту, а не частично
3. Будут исправлены недочеты в именах методов (all и т.п.)
4. Конфигурация composer возможно будет вынесена в отдельный файл composer.json
Если есть другие предложения пишите сюда: github.com/dim-s/regenix/issues
Конфиг компоузера надо обязательно выносить отдельно. К этому привыкли, не стоит устраивать людям проблемы с установкой доп. компонентов.
А в целом — хорошие выводы :)
А в целом — хорошие выводы :)
Хочу отметить тот факт, что работа проделана не малая и, почти, доведена до логической точки.
Да, возможно не все моменты вышли так как задумывал автор, или так как понравилось бы публике, однако Вы молодец что занимаетесь этим! Именно благодаря подобным проектам программисты и набираются опыта, и более детально понимают тонкие места реализации других проектов.
Желаю Вам развития и не забрасывать данную затею!
Да, возможно не все моменты вышли так как задумывал автор, или так как понравилось бы публике, однако Вы молодец что занимаетесь этим! Именно благодаря подобным проектам программисты и набираются опыта, и более детально понимают тонкие места реализации других проектов.
Желаю Вам развития и не забрасывать данную затею!
Sign up to leave a comment.
Regenix: Новый нестандартный MVC фреймворк для PHP