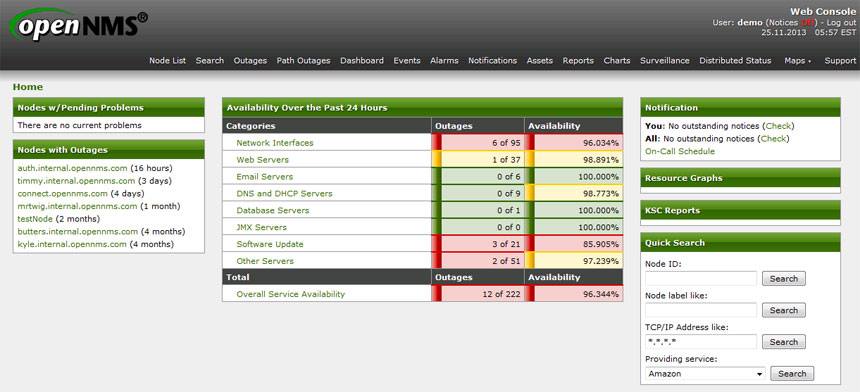
Ни в малейшей степени не желаю показаться непатриотичным, но исторически сложилось так, что при выборе корпоративной системы мониторинга сетевой инфраструктуры у нас на предприятии победила OpenNMS, сместив с этой должности бабушку Cacti и обогнав земляка-Zabbix. Сравнительный анализ Open Source систем мониторинга не входит в мои планы, поэтому просто в общих чертах расскажу об OpenNMS, благо на Хабре о ней не писали и вообще информации о ней немного.
Основная функция OpenNMS (Open Network Monitoring System) – мониторинг различных сервисов и внутренних систем сетевого и серверного оборудования. Для сбора информации используются так называемые «коллекторы», работающие по SNMP, HTTP, ИТДИТП протоколам. Отдельных серверных агентов у OpenNMS нет. Если информация окажется востребованной, то примеры реализаций «обёрток» я опишу в следующем материале в разделе «Юзкейсы». Не хочу больше повторять ошибок с публикацией гигантских простыней текста, в которых сложно разобраться как автору, так и читателям.
Краткая характеристика
OpenNMS динамично развивается, довольно неплохо документирована, но сообщество разрозненное, а конфигурирование в виде правки несметного количества XML файлов может многих отпугнуть. Система написана на Java с довесками на Perl и выпущено порядочное количество дистрибутивов под различные платформы. При желании её можно запустить на любой машине с Java SDK и сервером PostgreSQL.
A 1 GHz Pentium III (or equivalent processor) or better. A minimum of 256 MB of RAM, although 512 MB is strongly recommended.
Эти системные требования из официальной документации, мягко говоря, являются самыми минимальными и позволят именно что только запустить саму систему. Поэтому, позволю себе немного подкорректировать их: 64-битный CPU, 2 Gb RAM (это самый-самый минимум), высокопроизводительный жёсткий диск.
Прожорливость системы напрямую зависит от количества узлов, которые она будет мониторить. Система с более чем 1500 узлами и 5000 интерфейсами на них (VLAN'ы, порты, сервисы и т.п.) комфортно себя чувствует на Xeon E5520 c 12 Gb оперативки и SAS хардами. При этом под хранение rrd файлов отдан 2Gb tmpfs раздел. Запас по мощности выделен более чем двухкратный — это задел на рост сети и аппетитов системы в процессе обновления и развития.
Установка
Предварительно ставим
ntp, net-snmp, net-snmp-utils, postgresql, postgresql-server, perl. Базово настраиваем и запускаем все означенные сервисы. Затем устанавливаем JDK последней версии, скачав его с сайта Oracle, и наконец можно подключать репозиторий OpenNMS и ставить саму системуrpm -Uvh http://yum.opennms.org/repofiles/opennms-repo-stable-rhel6.noarch.rpm
yum install opennms iplike
Последний пакет – довесок к PostgreSQL от разработчиков OpenNMS в виде хранимой процедуры IPLIKE, помогающей работать с запросами по IP-адресам и адресам сетей, используя маски вроде
192.168.4-255.*, что активно используется в рамках самой системы.[!] Если имя хоста, на который ставится система, не резолвится на прописанных в resolv.conf DNS серверах, пропишите его в hosts. В противном случае, система не запустится. Также следует обратить внимание на первичную настройку PostgreSQL. После дефолтной установки сервера в
/var/lib/pgsql/data/pg_hba.conf в поставьте method trust всем трём local подключениям./opt/opennms/bin/runjava -S /usr/java/latest/bin/java
/opt/opennms/bin/install -dis
/etc/init.d/opennms start
После запуска система будет доступна по
hostname:8980. Отдельный веб-сервер устанавливать не обязательно – вебинтерфейс OpenNMS работает через Jetty сервер. Впрочем, при желании можно переконфигурировать сам Jetty, или на 80й порт повесить Nginx или apache с mod_proxy и делать proxy_pass на все запросы.При переустановке всей системы, следует дропнуть базу данных и удалить
/var/opennms. В противном случае возникнут коллизии с графиками и отчётами. Для полной переустановки делаем yum reinstall opennms и /opt/opennms/bin/install -dis, для частичной – только второе.Бывает так, что OpenNMS при запуске выдаёт сообщение
Started OpenNMS, but it has not finished starting up. Прежде всего, следует проверить, не допущена ли ошибка в конфигурации и все ли сервисы запущены (команда opennms -v status). И если все сервисы запущены, то у меня для вас плохие новости – OpenNMS не хватает ресурсов и она хочет послабления. Создаём файл $opennms/etc/opennms.conf с содержанием START_TIMEOUT=20. Число в параметре – это коэффициент, на который будет умножаться 5-секундный интервал проверки запущенности всех сервисов. По умолчанию этот параметр равен 10 и получается, что если за 50 секунд все сервисы не успеют отрапортовать об успешном запуске – будет возвращена ошибка. То есть START_TIMEOUT=20 это 100-секундное ожидание запуска всех систем.Интерфейс и настройка
Пожалуй, я пропущу часть с детальным описанием веб-интерфейса – в общих чертах система станет понятной через 10 минут прогулок по разделам, но стоит сразу отметить, что одной работой с веб-интерфейсом при конфигурировании системы не отделаться — придётся основательно покопаться в XML файлах.
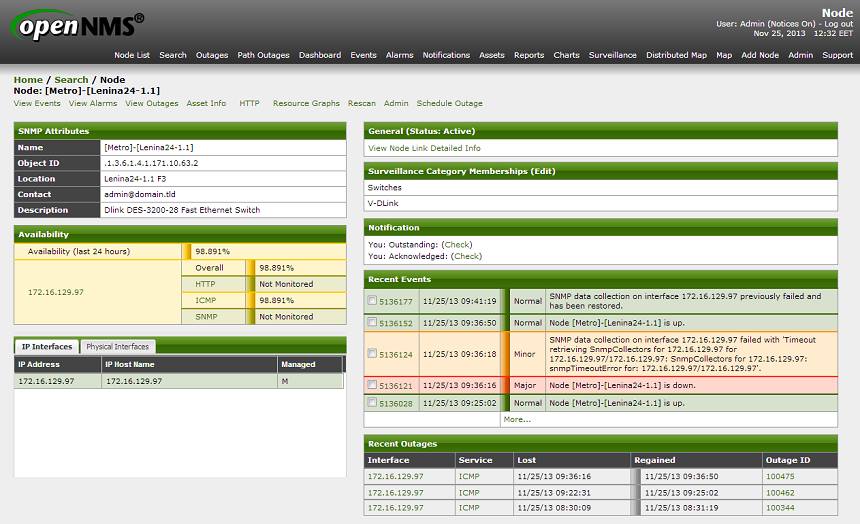
Так, например, добавить SNMP community для определенной подсети можно легко через веб-интерфейс в разделе
Admin → Configure SNMP by IP. Но просмотреть и отредактировать уже добавленные community можно только в соответствующем XML-файле. При этом диапазоны подсетей, за которыми нужно наблюдать (network discovery), можно полностью редактировать из веб-интерфейса.Поскольку редактировать конфигурационные файлы придётся много, я бы рекомендовал подключить любую привычную CVS, чтобы отслеживать изменения. Также я бы посоветовал выработать привычку после редактирования конфигурационного файла проверять его как
xmllint --noout filename.xml. И финальный штрих: изменения конфигурационных файлов применяются перезапуском демона opennms, что занимает порядочно времени.Внутренняя механика
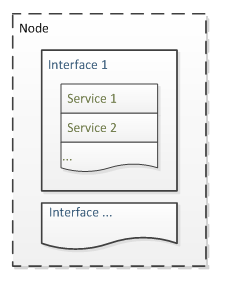 Основной единицей сбора данных является интерфейс, который под собой объединяет определенные сервисы. Все интерфейсы на одном устройстве группируются в ноду. Интерфейс не обязательно может быть сетевым – с точки зрения OpenNMS температурные датчики тоже являются интерфейсами. Начиная с версии 1.9, однотипные интерфейсы организуются в отдельные группы.
Основной единицей сбора данных является интерфейс, который под собой объединяет определенные сервисы. Все интерфейсы на одном устройстве группируются в ноду. Интерфейс не обязательно может быть сетевым – с точки зрения OpenNMS температурные датчики тоже являются интерфейсами. Начиная с версии 1.9, однотипные интерфейсы организуются в отдельные группы.При обнаружении нового интерфейса срабатывает событие
newSuspect, после чего система пытается обнаружить сервисы на этом интерфейсе, по цепочке найти другие интерфейсы на устройстве и сгруппировать полученную информацию в ноду. Получать данные о новых интерфейсах OpenNMS может автоматически (проводя поиск по заданным диапазонам с определенной периодичностью), вручную (вызывая perl скрипт) или по получению SNMP trap’а.# Вручную скормим системе сервер, на котором она сама и установлена:
perl /opt/opennms/bin/send-event.pl --interface 192.168.11.11 uei.opennms.org/internal/discovery/newSuspect
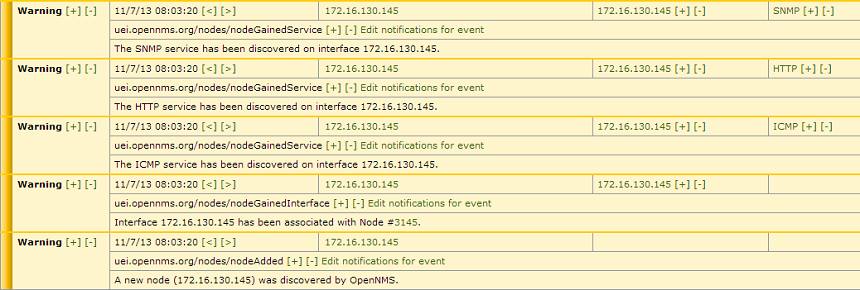
Теперь в Events → All Events можно наблюдать завораживающий процесс рождения новой ноды. Скорость её появления варьируется в зависимости от устройства и составляет от нескольких секунд до нескольких минут.
Отдельный интерес представляют собой Resource Graphs – графики системных ресурсов. После добавления новой ноды мы увидим только данные по умолчанию для каждого сервиса (например, время отклика ICMP и HTTP в случае наличия последнего). Однако, вполне можно расширить объём получаемой информации. Например, мы хотим снимать больше данных с другого сервера под управлением CentOS. Получать данные мы будем по SNMP, поэтому на целевом сервере устанавливаем net-snmp и редактируем
/etc/init.d/snmp/snmpd.conf# комментируем в начале конфига строки с com2sec, group, view и
# добавляем read-only комьюнити
rocommunity stat
# правим location и contact
syslocation Datacenter N1, Rack 2
syscontact admin@domain.tld
# описываем разделы для мониторинга
disk / 10000
disk /var 10000
# описываем предельные значения load average
load 12 14 14
Открываем 161 UDP порт в iptables, запускаем snmpd и заводим новое SNMP комьюнити в OpenNMS (Admin → Operations → Configure SNMP Community Names by IP). После этого можно открывать добавленную ноду и делать ей Rescan. После завершения сканирования, информации станет больше и графики станут предоставлять данные о дисковом пространстве, инодах и загрузке системы.
Перезагружать opennms при добавлении SNMP комьюнити через админку формально не требуется. Но иногда обновление этого файла или добавление новой discovery group подхватывается с большой задержкой и быстрее перезагрузить opennms, чем ждать, пока она очнётся самостоятельно.
Ещё немного внутренней механики
Разумеется, OpenNMS умеет сканировать сеть и определять появление новых устройств в сети. Процесс поиска настраивается в веб-интерфейсе в разделе Admin → Configure Discovery или в файле
$opennms/etc/discovery-configuration.xml. 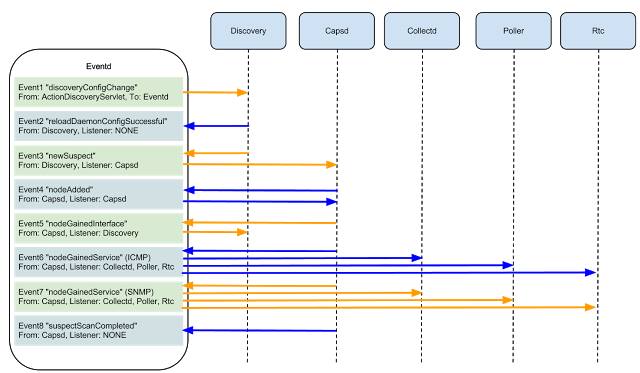
Изображение с сайта oopsmonk
Чуть детальнее остановимся на связях между сервисами в OpenNMS, запускающимися после обнаружения нового интерфейса и срабатывания newSuspect. Существует два сервиса, которые определяют наличие различных сервисов: capsd (capabilities daemon) и provisiond (provisioning daemon). По умолчанию они запускаются оба, и для меня остаётся загадкой, зачем это сделано. Ведь начиная с версии 1.8.0, capsd признан устаревшим, хотя при этом сохраняет высший приоритет по сравнению с provisiond.
Поэтому моя личная рекомендация — отключать capsd, перекладывая всю заботу об обнаружении сервисов на плечи provisiond. Работа с последним открывает доступ к условиям инициализации (provisioning requisitions), которые позволяют гибко настраивать определяемые сервисы, автоматически включать мониторинг нужных интерфейсов на узлах, сортировать узлы по категориям и т.п.
Непосредственно определением сервиса занимаются детекторы, являющиеся частью provisiond. Детекторы занимаются только обнаружением и регистрацией сервиса в рамках интерфейса, а сбором информации занимается pollerd. В ранних версиях системы сбором и обработкой данных занимались collectd и pollerd; первый собирал значения для графиков, а второй обрабатывал значения по запросу. Затем Collectd интегрировали в Pollerd и мороки с конфигурацией стало поменьше, хотя кое-где ещё можно наткнуться на оба понятия, что может вызвать определённую путаницу.
Замыкают цепочку обработки данных политики (policies), которые определяют правила, применяющиеся к нодам, попадающим под определенные условия инициализации. На данный момент доступны три: MatchingIpInterfacePolicy, MatchingSnmpInterfacePolicy, NodeCategorySettingPolicy. Их названия говорят сами за себя и применение политик позволяет управлять механиками получения информации с искомых интерфейсов. В качестве примеров:
- Применяя MatchingSnmpInterfacePolicy можно включать принудительный сбор информации с интерфейсов, имеющих в description определённое слово (например, [mon]).
- С помощью NodeCategorySettingPolicy отправлять все свитчи D-Link в отдельную категорию.
- С MatchingIpInterfacePolicy мы отключили сбор информации с 80 порта со всех коммутаторов, находящихся в одной подсети. График времени HTTP отклика в случае с коммутаторами не нужен — всегда есть ICMP ответ и данные с интерфейсов, в которых указано волшебное слово [mon]
Заключение
Стабильность. Единственный серьёзный глюк в системе был зарегистрирован во время «сбоя високосной секунды». И то, это пострадали системы баз данных, а не сама OpenNMS. В остальном, ни одного нарекания на стабильность за несколько лет работы.
Сложность. Система сложная и комплексная. Ею легко пользоваться с точки зрения саппорта — всё красиво, наглядно и есть даже клиент для айфона [x]. Но процесс настройки (особенно в первый раз) может легко сжечь уйму нервных клеток. Документация покрывает почти все базовые аспекты системы, но стоит отметить неприятную особенность — многие статьи содержат информацию для предыдущих версий. Логически причины этого вполне понятны: поддерживать актуальность для такой комплексной системы — задача не из простых. Но нашу жизнь это совсем не упрощает.
Гибкость. Разобравшись в системе, можно подключать свои события, трапы и модули для мониторинга. Если оборудование отдаёт какие-то параметры по SNMP или HTTP – его можно мониторить. Хранение данных в RRD позволяет гибко настраивать внешний вид графиков (которые по умолчанию не блещут красотой) в привычном RRDTool синтаксисе. Превышение пороговых значений обрабатывается в виде уведомлений и алармов. Внешние системы могут получать данные из OpenNMS по ReST или напрямую из базы.
Я не смогу ответить на вопросы «А почему не %systemname%?» и сознательно не стал на себя брать сравнительный анализ разных систем мониторинга — после продолжительной работы с одной системой и определенной привязки к её функционалу, непредвзятого обзора бы не получилось, а ресурсов такая работа отняла бы слишком много. На вопросы о самой системе отвечу с удовольствием, а если тема будет худо-бедно актуальной, то в продолжение этого ознакомительного материала можно будет написать примеры юзкейсов.
