Comments 51
«скайрим» на 51-м месте среди частотных слов из комментариев Хабра? Хм. Уговорили, надо будет таки поиграть)
тотсамизнаетектоноимякоторогонельзяназыватьнахабрепотомучтотаккручеивообщебольшинствотакделаетпоэтомуябудуповторятьзавсеми
Хабраводка.
Поднимем рейтинг слова вместе!
Поднимем рейтинг слова вместе!
Не смотрели слова, которые есть в постах, но не в комментариях? Есть там что интересное?
Ну и можно ещё теги распарсить) Заодно узнать рейтинг тега «никто не читает теги» и т.д.
Ну и можно ещё теги распарсить) Заодно узнать рейтинг тега «никто не читает теги» и т.д.
Смотрел, там были всякие «переопределим» и «сконфигурируем» :). Позже, наверное, выложу.
Все, теперь они есть в комментариях.
А как вы решили задачу: есть 2 списка чего-то по популярности, нужно найти самое популярное из списка 1 при этом не популярное в списке 2 (и наоборот, соответственно)?
Я просто несколько раз сталкивался с подобной задачей в общем виде (например сравнение ассоциаций к двум словам на Sociation), находил несколько удовлетворяющих меня решений, но все они какие-то «нестопудовые» и мало математически обоснованы.
Или вы просто взяли какой-то порог, типа меньше 5-и употреблений, значит его нет?
Я просто несколько раз сталкивался с подобной задачей в общем виде (например сравнение ассоциаций к двум словам на Sociation), находил несколько удовлетворяющих меня решений, но все они какие-то «нестопудовые» и мало математически обоснованы.
Или вы просто взяли какой-то порог, типа меньше 5-и употреблений, значит его нет?
Да не, совсем по тупому — нет значит нет, есть значит есть.
Единственное более менее математическое, что приходит в голову — найти относительную частотность слова (ну или как это называется, в общем процент, который состовляют вхождения этого слова от всех слов) в постах и в комментах и отранжировать все слова по разнице этих частотностей.
С википедией и башем я это пробовал, там в начале списка вылезают просто слова разговорной речи, которых полно на баше и мало (но есть) в википедии.
Единственное более менее математическое, что приходит в голову — найти относительную частотность слова (ну или как это называется, в общем процент, который состовляют вхождения этого слова от всех слов) в постах и в комментах и отранжировать все слова по разнице этих частотностей.
С википедией и башем я это пробовал, там в начале списка вылезают просто слова разговорной речи, которых полно на баше и мало (но есть) в википедии.
Если сортировать по разнице, то в одном списке будут слова характерные только для 1-го или только для 2-го ресурса, и не характерные для обоих одновременно. И то, разница в данном случае — это неверно. Нам ведь важно во сколько раз слово популярнее, а не на сколько (например 20%-10% = 10%, 100%-90% = 10%, при этом в первом случае популярность выше в 2 раза, а во втором в 1.111...).
Я когда рассуждал, придумал такую простую визуализацию. 2 оси, по одной — популярность слова в первом списке, по второй — во втором. Пусть они нормированы [0:1], тогда слова около «точки» 1,1 — это максимально популярные общие для 2-х ресурсов слова, 1,0 — характерные для 1-го, и 0,1 для второго ресурса. Вроде всё просто, нужно только правильно поделить плоскость на 3 группы (например популярные слова Хабра, Лепры и обоих одновременно). Остаётся вопрос — как именно это сделать наиболее правильным образом :)
Я когда рассуждал, придумал такую простую визуализацию. 2 оси, по одной — популярность слова в первом списке, по второй — во втором. Пусть они нормированы [0:1], тогда слова около «точки» 1,1 — это максимально популярные общие для 2-х ресурсов слова, 1,0 — характерные для 1-го, и 0,1 для второго ресурса. Вроде всё просто, нужно только правильно поделить плоскость на 3 группы (например популярные слова Хабра, Лепры и обоих одновременно). Остаётся вопрос — как именно это сделать наиболее правильным образом :)
…
шикарно! sociation — это Ваш сайт?
Ну да, такое маленькое хобби :)
Нам ведь важно во сколько раз слово популярнее, а не на сколько
Вот совсем не уверен. Одно слово встретилось один раз, другое два раза. Ну да, второе популярней в два раза. При этом разница — с гулькин хрен, в пределах любых погрешностей. И другая ситуация — одно слово встретилась 10к раз, а другое 1к раз. Тут определённо первое слово намного популярней. Разница здесь, по-моему, лучше подходит, чем частное.
Хотя… Не знаю…
Вот совсем не уверен. Одно слово встретилось один раз, другое два раза. Ну да, второе популярней в два раза. При этом разница — с гулькин хрен, в пределах любых погрешностей. И другая ситуация — одно слово встретилась 10к раз, а другое 1к раз. Тут определённо первое слово намного популярней. Разница здесь, по-моему, лучше подходит, чем частное.
Хотя… Не знаю…
Тогда проще на абсолютных числах:
— 500 и 1000 упоминаний (разность — 500, в 2 раза популярнее)
— 100500 и 101000 (разность 500, отношение 1.0049, т.е. «почти одинаково»)
Насчёт 1 и 2 — чем меньше частота, тем больше погрешность. Но нас же низкочастотные слова вообще не очень интересуют?
Если вечером будете экспериментировать, скину позже несколько формул
— 500 и 1000 упоминаний (разность — 500, в 2 раза популярнее)
— 100500 и 101000 (разность 500, отношение 1.0049, т.е. «почти одинаково»)
Насчёт 1 и 2 — чем меньше частота, тем больше погрешность. Но нас же низкочастотные слова вообще не очень интересуют?
Если вечером будете экспериментировать, скину позже несколько формул
Впрочем это всё можно проверить. Отранжировать так и так и посмотреть, где результат лучше выглядит. Вечером, наверное, сделаю.
Вот тут можно посмотреть на js:
sociation.org/static/js/sociation/compare.js
Там основная функция принимает как аргумент функцию сравнения. Они идут ниже. Чем ниже тем новее и лучше :) Самый простой и эффективный пока — последний comporator11.
sociation.org/static/js/sociation/compare.js
Там основная функция принимает как аргумент функцию сравнения. Они идут ниже. Чем ниже тем новее и лучше :) Самый простой и эффективный пока — последний comporator11.
порнохабр 28
Похоже, я что-то пропустил.
Тут где-то на ресурсе, есть, наверное, самый популярный по добавлениям в избранное один большой комментарий, сожержащий большой список ссылок, к статье об блокировки или временной недоступности одного известного трекера. Вот мне кажется, что слово выше, относиться к нему, этому хорошему комментарию.
Причем непонятно, почему не давать сразу ссылку просто на www.tblop.com/
UFO just landed and posted this here
Хм… если просуммировать эти однокоренные слова, то выяснится что больше всего на хабре любят передергивать и противоречить.
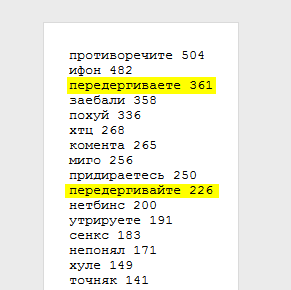

любовь здешних обитателей к созданию и употреблению «χ·слов», захотелось оценить масштабы явления.Поэтому одна из функций HabrAjax — это сокращать такие приставки до одной греческой буквы «хи».
UFO just landed and posted this here
Какое подозрительное совпадение в частотном словаре комментариев:
ахренеть 103
минуснули 103
!@#$%ы 103 (завуалировано)
ахренеть 103
минуснули 103
!@#$%ы 103 (завуалировано)
Как-то так должны выглядеть идеальные комментарии. Осторожно.
Минусаторы-холиварщики окститесь! Заебали оффтопить. Хуле утрируете?
Реквестую лосслесс жпг бубунты, правдо аеро! Ахренеть, миго непонял, ведроид пиратят, гнусмас похуй, хтц негодуе. Ахах, лучшеб ифон минуснули, пидорасы!
Яб нобелевку заплюсовал. Сраное иксбокс — совковая айрони. Спасибище, скайрим.
Ктож сусе линупс поубивал приватом?! Зачетно жжоте, ящитаю. Охх, опечаточка, слаку. Придираетесь? Огреб аккумом.
Бгг, передергивайте!
Реквестую лосслесс жпг бубунты, правдо аеро! Ахренеть, миго непонял, ведроид пиратят, гнусмас похуй, хтц негодуе. Ахах, лучшеб ифон минуснули, пидорасы!
Яб нобелевку заплюсовал. Сраное иксбокс — совковая айрони. Спасибище, скайрим.
Ктож сусе линупс поубивал приватом?! Зачетно жжоте, ящитаю. Охх, опечаточка, слаку. Придираетесь? Огреб аккумом.
Бгг, передергивайте!
Когда прочитал статью, придумал слово хабракадабра. Нашлась в списке.
Да, это очень интересная тема, когда-то ради прикола составлял общий частотный словарь и поименный для местного IRC, так в топе слов были исключительно короткие слова(2-3 буквы) и слабо зависели от человека.
И еще заметил что словарь каждый день пополнялся на 100-200 слов. В активные дни, когда происходили какие-то события поток новых слов увеличивался до 400 в день.
Примерно вот так распределились
НЕ 5414
И 4379
НА 2876
ТЫ 2100
ЭТО 1946
ЧТО 1719
НУ 1264
КАК 1215
ДА 1096
ПО 1071
ТАК 1040
ТО 967
ЕСТЬ 836
И 4379
НА 2876
ТЫ 2100
ЭТО 1946
ЧТО 1719
НУ 1264
КАК 1215
ДА 1096
ПО 1071
ТАК 1040
ТО 967
ЕСТЬ 836
И еще заметил что словарь каждый день пополнялся на 100-200 слов. В активные дни, когда происходили какие-то события поток новых слов увеличивался до 400 в день.
Sign up to leave a comment.
И снова закинул старик невод… (парсинг хабра, продолжение)