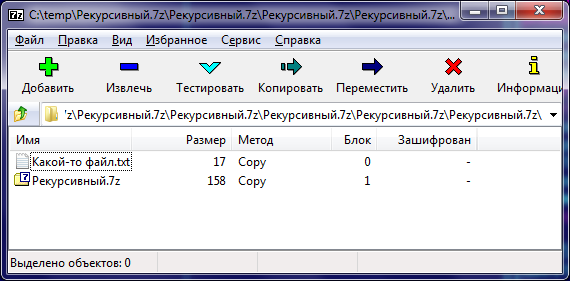
 Формат архивов 7-Zip довольно гибкий и позволяет, например, включать весь архив как один из файлов внутри самого архива, лишь немного считерив. Разберём формат на примере: создадим почти вручную архив с именем «Рекурсивный.7z», содержащий два файла: «Какой-то файл.txt» с содержимым «Hello, Habrahabr!» и «Рекурсивный.7z», копию самого себя.
Формат архивов 7-Zip довольно гибкий и позволяет, например, включать весь архив как один из файлов внутри самого архива, лишь немного считерив. Разберём формат на примере: создадим почти вручную архив с именем «Рекурсивный.7z», содержащий два файла: «Какой-то файл.txt» с содержимым «Hello, Habrahabr!» и «Рекурсивный.7z», копию самого себя.Краткая документация по формату входит в LZMA SDK. Архив начинается со следующей структуры размером 32 байта. Все позиции внутри архива кодируются как смещения относительно конца этой структуры.
сигнатура, 6 байт: { '7', 'z', 0xBC, 0xAF, 0x27, 0x1C };
версия формата, два байта { Major, Minor }, 7-Zip 9.20 пишет сюда { 0, 3 };
CRC следующих трёх полей, 4 байта;
смещение основного заголовка относительно конца этой структуры, 8 байт;
размер основного заголовка, 8 байт;
CRC основного заголовка, 4 байта.Далее следуют данные файлов без какой бы то ни было информации о самих файлах и о границах данных. Основной заголовок, который описывает всё содержимое архива, размещается в конце архива.
Основной заголовок может быть сам по себе упакован (а также зашифрован). Поскольку он содержит структурированные данные (типа имён файлов), коэффициент сжатия достаточно неплохой. Именно для возможности подобного сжатия вся информация о файлах в 7z собрана в одном заголовке и полностью отделена от сжатых данных файлов. Признак упакованности — первый байт основного заголовка: он должен быть равен 1 у неупакованного заголовка и 0x17 у упакованного. Для создания архива вручную мы не будем ничего сжимать.
Общая схема (распакованного) основного заголовка из документации:
{
ArchiveProperties
AdditionalStreams
{
PackInfo
{
PackPos
NumPackStreams
Sizes[NumPackStreams]
CRCs[NumPackStreams]
}
CodersInfo
{
NumFolders
Folders[NumFolders]
{
NumCoders
CodersInfo[NumCoders]
{
ID
NumInStreams;
NumOutStreams;
PropertiesSize
Properties[PropertiesSize]
}
NumBindPairs
BindPairsInfo[NumBindPairs]
{
InIndex;
OutIndex;
}
PackedIndices
}
UnPackSize[Folders][Folders.NumOutstreams]
CRCs[NumFolders]
}
SubStreamsInfo
{
NumUnPackStreamsInFolders[NumFolders];
UnPackSizes[]
CRCs[]
}
}
MainStreams
{
(Same as in AdditionalStreams)
}
FilesInfo
{
NumFiles
Properties[]
{
ID
Size
Data
}
}
}
Давайте разбираться по порядку, формируя попутно нужный заголовок. Первые 32 байта мы заполним в последнюю очередь (для них нужен готовый основной заголовок), следующие байты — данные, которые мы для простоты сжимать не будем:
00000020: 48 65 6C 6C 6F 2C 20 48 61 62 72 61 68 61 62 72 | Hello, Habrahabr
00000030: 21 | !
Записываем первый байт основного заголовка:
00000030: 01
ArchiveProperties — свойства для возможного расширения, сейчас не используются, 7-Zip никогда их не создаёт и молча пропускает при чтении.
AdditionalStreams и MainStreams описывают структуру сжатых данных. Первый байт в AdditionalStreams равен 0x03, первый байт в MainStreams равен 0x04, в остальном их структура идентична (кстати, точно такую же структуру имеет упакованный основной заголовок после первого байта 0x17).
MainStreams описывают данные файлов. AdditionalStreams позволяют вынести некоторые данные (например, собранные вместе имена файлов) отдельно и сжимать независимо от основного заголовка; 7-Zip не использует такую возможность при записи (в реальных архивах AdditionalStreams отсутствуют), но способен обрабатывать их при чтении.
Записываем первый байт MainStreams и идём вглубь:
00000030: 04
В 7-Zip преобразованиями данных занимаются кодировщики. У каждого кодировщика есть сколько-то входных потоков, сколько-то выходных потоков, свой собственный идентификатор и, возможно, какие-нибудь настройки. Большинство кодировщиков преобразуют один входной поток в один выходной поток: таковы, например, копирующий кодировщик {00} (он-то нам и нужен), LZMA-упаковщик {03, 01, 01}, AES-шифратор {06, 01, xx}, BZip2-упаковщик {04, 02, 02} (да, формат 7z вполне допускает алгоритмы, традиционно использующие другие форматы архивов). Пример кодировщика с несколькими выходными потоками: BCJ2 {03, 03, 01, 1B}. Машинный код x86 и x86-64 устроен так, что команды вызова процедуры (E8 xx xx xx xx) и прыжков (E9 xx xx xx xx — длинный безусловный, 0F 8y xx xx xx xx — длинный условный) кодируют адрес назначения как смещение относительно своего конца. Из-за этого просто так сжатие «не заметит», что разные вхождения E8 xx xx xx xx (с разными xx из-за относительности смещения) — на самом деле вызов одной и той же процедуры. BCJ2 преобразует назначения вызовов и прыжков в абсолютную форму и выдаёт 4 выходных потока: первый — обычные данные, второй — назначения вызовов, третий — назначения прыжков, четвёртый — битовый поток, который на каждое появление E8/E9/0F 8x сообщает, есть ли соответствующее закодированное назначение или это просто байт данных.
Формат 7z описывает самую общую ситуацию: входной поток кодируется произвольным числом каких-то кодировщиков, выходы с которых в свою очередь могут быть входами других кодировщиков и так далее. Первый блок PackInfo в информации о потоках описывает все финальные потоки, записанные в архив (все выходные потоки кодировщиков, не поданные на вход каким-то другим кодировщикам): байт 0x06, кодированное начало финальных потоков в файле (в виде смещения относительно конца первого заголовка, потоки следуют один за другим последовательно), кодированное число потоков, байт 0x09, размеры всех финальных потоков (по одному кодированному числу на каждый финальный поток), байт 0x00. Между размерами потоков и концом структуры может быть информация о CRC финальных потоков, но она обычно не используется, а CRC контролируется у распакованных данных.
Целые числа в 7z кодируются следующим образом: количество ведущих единиц в первом байте определяет количество дополнительных байт, прочие биты первого байта суть старшие биты числа, дополнительные байты определяют младшие байты числа в little-endian. Числа, меньшие 0x80, кодируются одним байтом, равным самому числу. Числа, занимающие все 8 байт, кодируются с помощью приписывания в начало байта 0xFF.
У нас будет два потока. Первый — для файла «Какой-то файл.txt», начинающийся со смещения 0 относительно конца первого заголовка. Второй — для архива, начинающийся с начала файла. Поскольку потоки следуют один за другим последовательно, размер первого потока придётся сделать равным 0 — 0x20 = 0xFFFFFFFFFFFFFFE0. Размер архива мы пока не знаем, оставим под него два байта. Итак, формируем блок PackInfo:
00000030: 06 00 02 09 FF E0 FF FF FF FF FF FF FF
00000040: ?? ?? 00
Второй блок CodersInfo описывает все использованные кодировщики с параметрами и связи между ними. Кодировщики объединены в группы по связям, между группами связей нет. Например, одна группа может состоять из одного LZMA-упаковщика, вторая — из связки BCJ2+(несколько разных LZMA). Блок CodersInfo начинается с байт 0x07 0x0B, после которых следует кодированное число групп, нулевой байт (ненулевой означал бы вынесение информации о группах в отдельный AdditionalStream), по одной структуре Folder на группу. Каждая группа начинается с числа кодировщиков в группе, затем следует описание каждого кодировщика. Первый байт описания кодировщика содержит размер идентификатора в младших 4 битах, следующий бит установлен, только если у кодировщика число входных каналов или число выходных каналов не равно единице, следующий бит установлен, если у кодировщика есть параметры. Далее следует идентификатор, далее число выходных и входных каналов (если либо то, либо другое отлично от единицы), далее размер параметров (если они есть) и сами параметры в виде массива байт. После всех кодировщиков идёт описание связей: номер выходного канала и номер входного канала, которые нужно связать. Каждый входной канал, кроме одного, должен быть выходом какого-нибудь декодера, поэтому число связей равно суммарному количеству входных каналов во всех кодировщиках минус 1. Наконец, если число выходных потоков больше одного, то описание группы заканчивается списком индексов несвязанных выходных потоков в том порядке, в котором они записаны в архиве. После описания папок идёт байт 0xC и размеры всех входных каналов, включая связанные, всех папок. Как и PackInfo, блок CodersInfo заканчивается байтом 0x00. Между размерами потоков и концом структуры может быть информация о CRC входных данных, которая обычно используется только для информации о потоках упакованного заголовка (CRC файлов хранятся в следующем блоке). CRC, если есть для всех потоков, хранится так: сначала ненулевой байт (признак того, что CRC определена для всех потоков; иначе дальше бы шёл битовый массив, указывающий, для каких потоков CRC определена), потом по 4 байта CRC на каждый поток.
Формируем блок CodersInfo, учитывая, что у нас один копирующий кодировщик в каждой из двух групп для двух потоков, и по-прежнему оставляя два байта под пока ещё неизвестный размер архива:
00000040: 07 0B 02 00 01 01 00 01 01 00 0C 11 ??
00000050: ?? 00
Третий блок SubStreamsInfo описывает файлы. В информации о потоках упакованного заголовка его нет, но в информации о потоках файлов он должен быть, возможно, без данных. 7-Zip сжимает не отдельные файлы, а блоки из нескольких файлов (непрерывные архивы; можно настроить ограничения на размер блока и на число файлов в блоке вплоть до одного файла, что фактически выключает непрерывные архивы, но по умолчанию непрерывность включена). Входные потоки в описании выше объединяют несколько файлов. Блок SubStreamsInfo описывает размеры (непустых) файлов в одном блоке. Он начинается с байта 0x08. Далее, возможно, следует байт 0x0D и число файлов в каждой группе; если их нет, то считается, что в каждой группе один файл. Затем, возможно, следует байт 0x09 и размеры отдельных файлов (кроме последнего в каждой группе — он вычисляется по размеру входного потока группы). Далее, возможно, следует байт 0x0A и CRC отдельных файлов, хранящиеся аналогично блоку CodersInfo. Завершается блок SubStreamsInfo, как и остальные, байтом 0x00. У нас два файла в архиве хранятся в разных потоках. Для простоты мы не будем записывать CRC в нашем архиве (это легко сделать для текстового файла, для архива нужно подгонять так, чтобы CRC, посчитанная по данным, включающим саму CRC, сошлась бы — пришлось бы выделять неиспользуемые байты и подгонять их). Поэтому блок SubStreamsInfo у нас не содержит данных:
00000050: 08 00
Завершаем информацию о потоках нулевым байтом и возвращаемся на уровень выше:
00000050: 00
FilesInfo, как нетрудно догадаться, содержит информацию о файлах внутри архива: имена, даты создания/изменения/доступа, атрибуты файлов. FilesInfo начинается с байта 0x05, следом идёт закодированное целое число, обозначающее число файлов, следом свойства (в некотором количестве). Каждое свойство начинается с ненулевого байта-идентификатора, после которого следует размер свойства (чтобы 7-Zip мог пропускать неизвестные свойства). Нулевой байт заканчивает FilesInfo. Имена файлов кодируются как свойство с типом 0x11, первый байт содержимого равен нулю (ненулевой байт означает, что всё дальнейшее содержимое свойства вынесено в отдельный AdditionalStream, индекс которого в общем массиве закодирован далее), дальше идут сами имена в UTF-16 с терминирующим нулём.
Даты и атрибуты мы для простоты заполнять не будем, а вот имена нужны. Заполняем блок FilesInfo:
00000050: 05 02 11 43 00 1A 04 30 04 3A 04 | .....К<а<к<
00000060: 3E 04 39 04 2D 00 42 04 3E 04 20 00 44 04 30 04 | о<й<-<т<о< <ф<а<
00000070: 39 04 3B 04 2E 00 74 00 78 00 74 00 00 00 20 04 | й<л<.<t<x<t<..Р<
00000080: 35 04 3A 04 43 04 40 04 41 04 38 04 32 04 3D 04 | е<к<у<р<с<и<в<н<
00000090: 4B 04 39 04 2E 00 37 00 7A 00 00 00 00 | ы<й<.<7<z<...
Осталось только завершить весь заголовок привычным уже нулевым байтом:
00000090: 00
Итак, размер всего файла 0x9E байт, теперь мы можем вернуться и записать на место вопросиков байты 80 9E, кодирующие число 0x9E. Осталось сформировать первый заголовок. Основной заголовок начинается с позиции 0x11 относительно конца первого заголовка и занимает 0x9E — 0x31 = 0x6D байт.
Теперь надо вычислить две CRC. Вручную считать CRC по 0x6D байтам довольно хлопотно, поэтому здесь прибегнем к помощи программ. Первая CRC, которую нам надо вычислить, — основной заголовок: байты с 0x31 до конца, его CRC равна 0x3F5E2977. Вторая CRC считается по трём последним полям первого заголовка, включая первую CRC: 11 00 00 00 00 00 00 00 6D 00 00 00 00 00 00 00 77 29 5E 3F. Она равна 0x6FA3DEA5. Наконец, соберём всё воедино и получим такой "Рекурсивный.7z":
00000000: 37 7a bc af 27 1c 00 03 a5 de a3 6f 11 00 00 00 |7z..'......o....|
00000010: 00 00 00 00 6d 00 00 00 00 00 00 00 77 29 5e 3f |....m.......w)^?|
00000020: 48 65 6c 6c 6f 2c 20 48 61 62 72 61 68 61 62 72 |Hello, Habrahabr|
00000030: 21 01 04 06 00 02 09 ff e0 ff ff ff ff ff ff ff |!...............|
00000040: 80 9e 00 07 0b 02 00 01 01 00 01 01 00 0c 11 80 |................|
00000050: 9e 00 08 00 00 05 02 11 43 00 1a 04 30 04 3a 04 |........C.К<а<к<|
00000060: 3e 04 39 04 2d 00 42 04 3e 04 20 00 44 04 30 04 |о<й<-<т<о< <ф<а<|
00000070: 39 04 3b 04 2e 00 74 00 78 00 74 00 00 00 20 04 |й<л<.<t<x<t<..Р<|
00000080: 35 04 3a 04 43 04 40 04 41 04 38 04 32 04 3d 04 |е<к<у<р<с<и<в<н<|
00000090: 4b 04 39 04 2e 00 37 00 7a 00 00 00 00 00 |ы<й<.<7<z<....|
