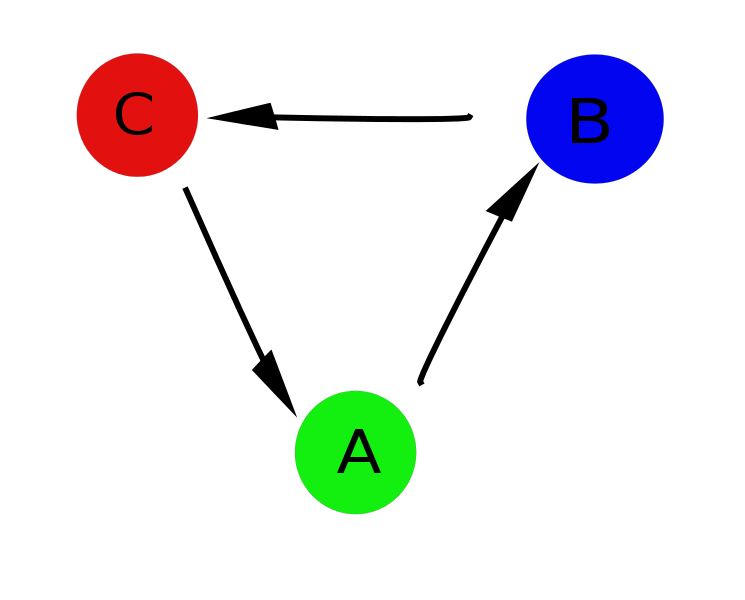
Вдогонку к посту о белках попробую рассказать о, казалось бы, такой несвязанной с биологией темой как сложные сети (complex networks).
Сложной сетью называют графы, обладающие нетривиальными топологическими свойствами. Под нетривиальными топологическим свойствами обычно имеется в виду то, что связи между узлами графа распределены по хитрому закону, что в свою очередь даёт на выходе различные кластерные структуры, хабы, уязвимые места и прочее.
Понятие сложной сети выросло из идеи отследить цитирования научных работ в 50-х годах прошлого века, и потихоньку разрослось, захватывая интернет, социальные сети, дорожные сети и даже многие области теоретической физики, вплоть до квантовой. Пионером сложных сетей был венгерский математик Пауль Эрдош (Paul Erdős), который опубликовал десятки статей по теории сетей и смежным проблемам. Любопытно, что в его честь в научном сообществе цитирования в шутку стали мерять числом Эрдоша. Это шуточная метрика, которая показывает длину связи между Эрдошем и другим автором в сети соавтора. То есть, если Василий Пупкин соавтор Альфреда Реньи, который в свою очередь является соавтором Эрдоша, то у Василия число Эрдоша равно двум (у Пауля и Альфреда ноль и единица соответсвенно).
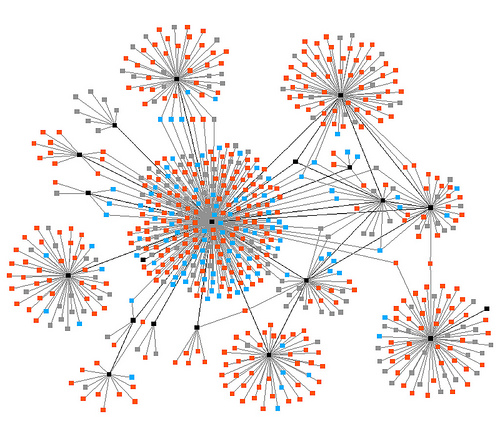
Одной из ключевых проблем (и, как следствие, свойств) в теории сложных сетей является задача разбиения сети на кластеры. Кластером называют массив узлов, которые связаны друг с другом сильнее чем с остальной сетью. Сейчас существуют десятки, если не сотни алгоритмов кластеризации, но у всех есть ограничения и недостатки: либо они слишком медленны, либо вычислительное время астрономически растет с количеством узлов, либо страдает точность в зависимости от условий начальной задачи. В данной статье будет использоваться gradient cluster алгоритм, суть которого в следующем: у каждого узла оставим только максимальную связь с другим узлом (исключив таким образом самосвязи), удалив все остальные. Таким образом сеть разобъется на подсети, которые и будут кластерами.
На верхней картинке кластеры легко найти и «на глазок», а на нижней?

Зачем это всё нужно? Дело в том, что белки под воздействием внешних факторов (температура, давление, ионы, вода etc) могут находится в различных состояниях (conformations), которые соответствуют различным биологическим функциям, не всегда полезным. Обычно состояния описывают неким параметром или несколькими параметрами (order parameter), такими как радиус инерции, количество водородных связей, расстояние между определенными атомами и т.д.
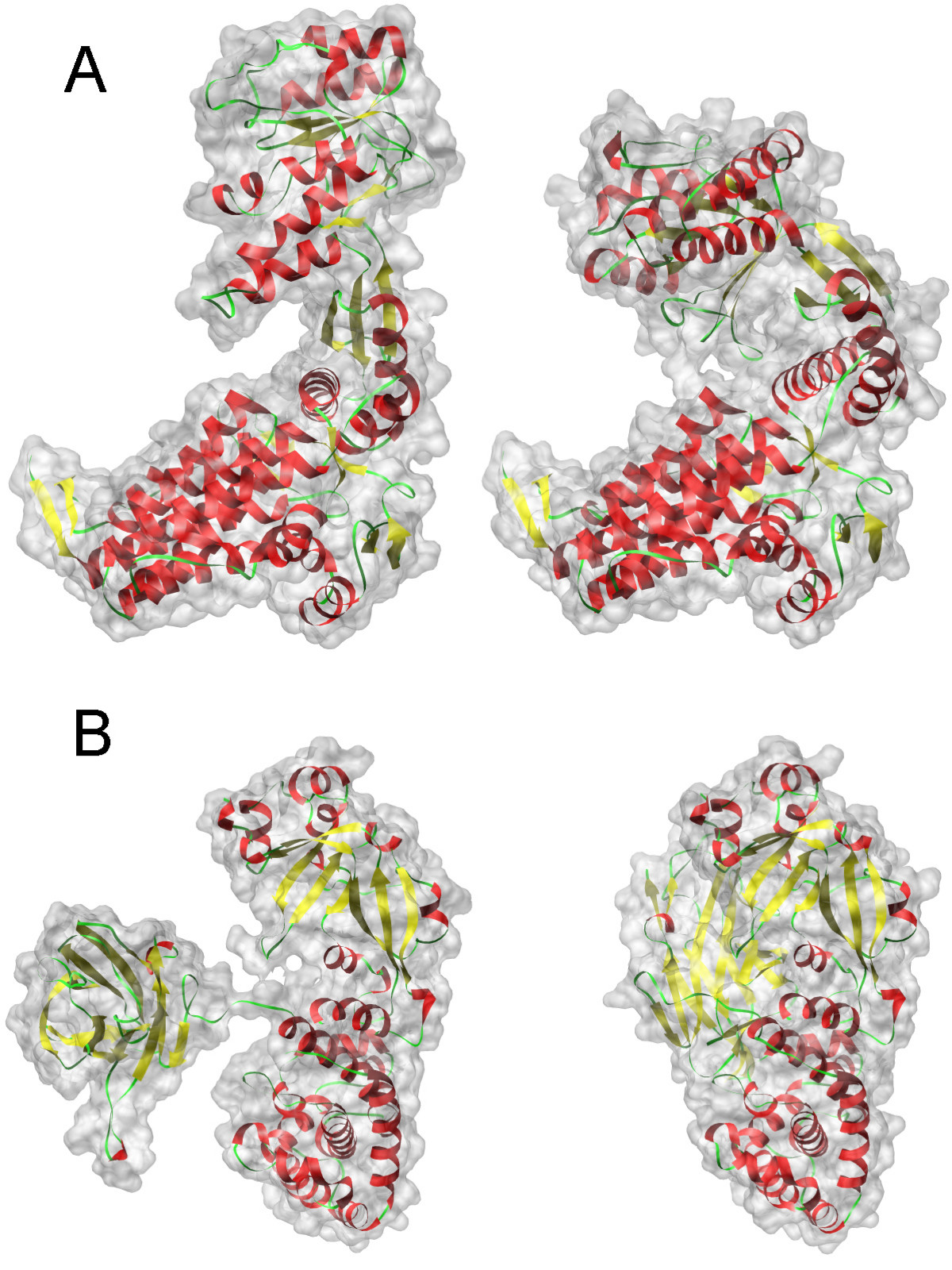
На картинке по два состояния двух разных белков. Функции в разных состояниях, соответственно, разные

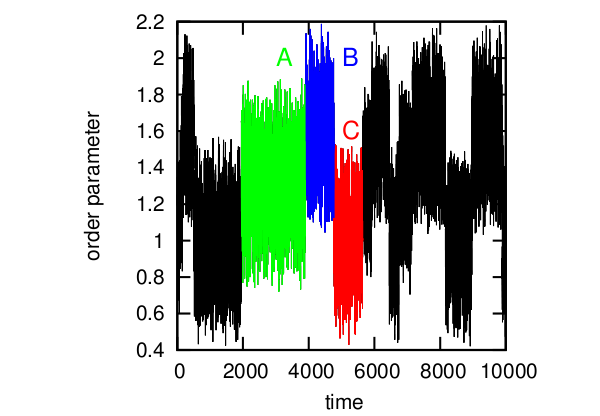
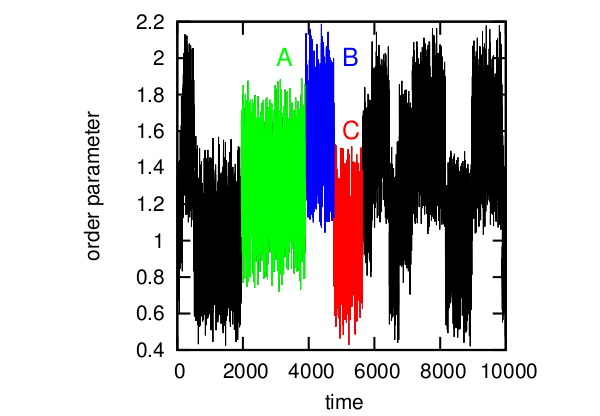
Рассмотрим простейший пример. Временной ряд условного order parameter для белка. Здесь можно выделить три состояния (A,B,C), которые соответствуют трем состояниям белка. Обычно в таких случаях используют формулу F=-kT log(P), где kT — константы, P — вероятность состояния и F — свободная энергия, и строят профиль свободной энергии, минимумы которого будут соответствовать разным структурам белка. И дальше вроде бы можно сказать, что система прыгает между несколькими энергетическими ямами, в зависимости от внешних факторов. Вроде бы всё хорошо.
Пример временного ряда.
Профиль свободной энергии.

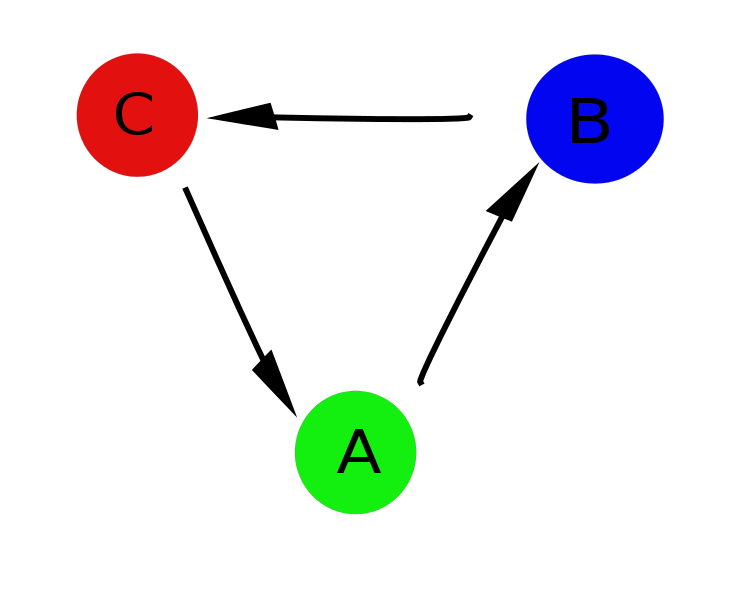
Но есть несколько проблем: первая, и самая очевидная — не всегда можно сказать какое значение параметра какому состоянию соответствует (например, при OP=1.4, возможны все три состояния), и полученный нами профиль немного искажает реальную картину. А во-вторых, дело в том, что на самом деле есть строго заданый цикл A->B->C, и переход из состояния A в состояние C напрямую невозможен и спроэцировав всё на одну ось в результате мы получили картину, довольно далёкую от реальности.
И здесь на помощь приходят сети. Можно задать соответствие между значением параметра порядка в каждый момент времени и узлом сети, а между двумя соседними по времени создать связь с весом, равным условной единице, и если во время анализа подобный момент будет повторен, соответственно увеличить её. Далее, как вы уже догадались, применяем описанный выше алгоритм кластеризации, и получаем картинку, которая реально описывает систему.
Немного теории
Сложной сетью называют графы, обладающие нетривиальными топологическими свойствами. Под нетривиальными топологическим свойствами обычно имеется в виду то, что связи между узлами графа распределены по хитрому закону, что в свою очередь даёт на выходе различные кластерные структуры, хабы, уязвимые места и прочее.
Понятие сложной сети выросло из идеи отследить цитирования научных работ в 50-х годах прошлого века, и потихоньку разрослось, захватывая интернет, социальные сети, дорожные сети и даже многие области теоретической физики, вплоть до квантовой. Пионером сложных сетей был венгерский математик Пауль Эрдош (Paul Erdős), который опубликовал десятки статей по теории сетей и смежным проблемам. Любопытно, что в его честь в научном сообществе цитирования в шутку стали мерять числом Эрдоша. Это шуточная метрика, которая показывает длину связи между Эрдошем и другим автором в сети соавтора. То есть, если Василий Пупкин соавтор Альфреда Реньи, который в свою очередь является соавтором Эрдоша, то у Василия число Эрдоша равно двум (у Пауля и Альфреда ноль и единица соответсвенно).
Одной из ключевых проблем (и, как следствие, свойств) в теории сложных сетей является задача разбиения сети на кластеры. Кластером называют массив узлов, которые связаны друг с другом сильнее чем с остальной сетью. Сейчас существуют десятки, если не сотни алгоритмов кластеризации, но у всех есть ограничения и недостатки: либо они слишком медленны, либо вычислительное время астрономически растет с количеством узлов, либо страдает точность в зависимости от условий начальной задачи. В данной статье будет использоваться gradient cluster алгоритм, суть которого в следующем: у каждого узла оставим только максимальную связь с другим узлом (исключив таким образом самосвязи), удалив все остальные. Таким образом сеть разобъется на подсети, которые и будут кластерами.
На верхней картинке кластеры легко найти и «на глазок», а на нижней?


Применение
Зачем это всё нужно? Дело в том, что белки под воздействием внешних факторов (температура, давление, ионы, вода etc) могут находится в различных состояниях (conformations), которые соответствуют различным биологическим функциям, не всегда полезным. Обычно состояния описывают неким параметром или несколькими параметрами (order parameter), такими как радиус инерции, количество водородных связей, расстояние между определенными атомами и т.д.
На картинке по два состояния двух разных белков. Функции в разных состояниях, соответственно, разные
Рассмотрим простейший пример. Временной ряд условного order parameter для белка. Здесь можно выделить три состояния (A,B,C), которые соответствуют трем состояниям белка. Обычно в таких случаях используют формулу F=-kT log(P), где kT — константы, P — вероятность состояния и F — свободная энергия, и строят профиль свободной энергии, минимумы которого будут соответствовать разным структурам белка. И дальше вроде бы можно сказать, что система прыгает между несколькими энергетическими ямами, в зависимости от внешних факторов. Вроде бы всё хорошо.
Пример временного ряда.
Профиль свободной энергии.
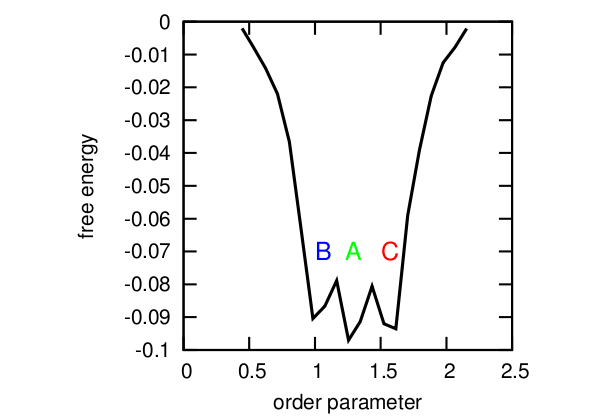
Но есть несколько проблем: первая, и самая очевидная — не всегда можно сказать какое значение параметра какому состоянию соответствует (например, при OP=1.4, возможны все три состояния), и полученный нами профиль немного искажает реальную картину. А во-вторых, дело в том, что на самом деле есть строго заданый цикл A->B->C, и переход из состояния A в состояние C напрямую невозможен и спроэцировав всё на одну ось в результате мы получили картину, довольно далёкую от реальности.
И здесь на помощь приходят сети. Можно задать соответствие между значением параметра порядка в каждый момент времени и узлом сети, а между двумя соседними по времени создать связь с весом, равным условной единице, и если во время анализа подобный момент будет повторен, соответственно увеличить её. Далее, как вы уже догадались, применяем описанный выше алгоритм кластеризации, и получаем картинку, которая реально описывает систему.