Comments 108
и это материал на отдельную статью, а то и не одну.
Почитал бы с удовольствием!
Когда добавляете новые диски — надо руками править /etc/ceph/ceph.conf и раскладывать потом на все машины, после чего перезапускать всё?
Стоит отметить, что для сносной работы требуется 10GB сеть.
Consider starting with a 10Gbps network in your racks. Replicating 1TB of data across a 1Gbps network takes 3 hours, and 3TBs (a typical drive configuration) takes 9 hours. By contrast, with a 10Gbps network, the replication times would be 20 minutes and 1 hour respectively.
было бы так, если бы винт 3Тб реально мог сам работать со скоростью 10 Gbps. А там интерфейс по факту — 6 Gbps, а сам винт ещё медленнее.
Смотрите, обычно в один сервер ставят больше одно винта.
Вообще самое быстрое, что я видел на бытовых винтах и недорогом железе — это 280 мб/сек. Это синкался Software RAID10 на четыре SATA-диска 500 Гб на сервере начального уровня (с процом Xeon серии E3). Каждый из этих винтов способен выдать 140, а поскольку всего их было четыре — обе пары синкались параллельно — мы получили вдвое больше.
Это — немного больше гигабита, и это линейная запись, т.е. очень хорошая для винтов ситуация. При реальной работе такой скорости, конечно, не добиться, и весь этот RAID10 выдаст заведомо меньше гигабита.
Нахрена тут десять?
Это — немного больше гигабита, и это линейная запись, т.е. очень хорошая для винтов ситуация. При реальной работе такой скорости, конечно, не добиться, и весь этот RAID10 выдаст заведомо меньше гигабита.
Нахрена тут десять?
Как уже говорили, потому что винтов может быть десяток на одном хосте, вот и выходит что одновременно возможно копирование блоков с разных устройств.
+ я почти уверен что как таковыми файлами система не оперирует а оперирует блоками, поэтому работа идёт не с множеством файлов, а множеством блоков, ну и их объем не должен быть черезчур маленьким.
+ я почти уверен что как таковыми файлами система не оперирует а оперирует блоками, поэтому работа идёт не с множеством файлов, а множеством блоков, ну и их объем не должен быть черезчур маленьким.
Дополню.
Вот посмотрите на верхнюю строчку тут
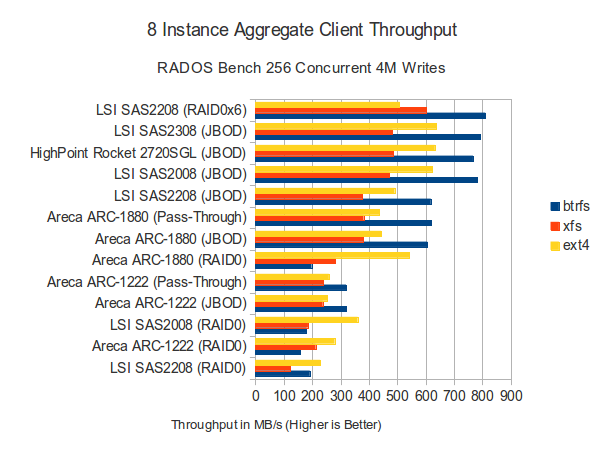
Тут взяли всего один контроллер, пробросили 6 SATA дисков и получили около 800MB/s. Это при блоке в 4MB и btrfs.
Давайте представим себе наиболее худшую ожидаемую аварию — пропадает такое количество дисков при такой утилизации хранилища, при которых является необходимым отреплицировать все существующие блоки всех серверов.
К примеру, при 12 3TB дисках на каждой ноде и уровне избыточности 2, это может означать необходимость отреплицировать 18 TB данных.
Вот посмотрите на верхнюю строчку тут

Тут взяли всего один контроллер, пробросили 6 SATA дисков и получили около 800MB/s. Это при блоке в 4MB и btrfs.
Давайте представим себе наиболее худшую ожидаемую аварию — пропадает такое количество дисков при такой утилизации хранилища, при которых является необходимым отреплицировать все существующие блоки всех серверов.
К примеру, при 12 3TB дисках на каждой ноде и уровне избыточности 2, это может означать необходимость отреплицировать 18 TB данных.
хочу сказать что это все про сферических коней. Если у вас будет нагрузка по 800МБ/с на запись регулярная на продакшене — вы никогда и ни за что не будете пользоваться подобными решениями. Вы купите Нетапп, МСА2000, поставите Нексенту, зарядите старвинд, на крайняк соберете RAID10/RAID6 на хорошем контроллере с BBU и все будет работать так же. И все будет работать без 10Г и если что-то пойдет не так, Вас лично точно не уволят =)
Массив RAID6 из 12 дисков на обычном 12 канальном Адаптеке легко выходит на 1,5-2ГБ в секунду по записи, что бы его прогрузить действительно нужна 10Г. Только вот задач такие встречаются крайне редко — может быть HD видео-монтаж?
Массив RAID6 из 12 дисков на обычном 12 канальном Адаптеке легко выходит на 1,5-2ГБ в секунду по записи, что бы его прогрузить действительно нужна 10Г. Только вот задач такие встречаются крайне редко — может быть HD видео-монтаж?
Смотрите, Ceph это полностью распределенное объектное хранилище. Наличие абстрактного уровня Группы Размещения (Placement Group) позволяет очень гибко обслуживать репликацию блоков. У хранилища нет SPF. Отказ диска, ноды или шкафа с нодами не приводит к даунтайму, при правильном проектировании даже просадки производительности не будет при восстановлении. Архитектура может содержать несколько десятков серверов. Масштабирование горизонтальное и полностью прозрачное.
собирается все здорово, но надо бы сделать лабу на 3-4 машины с 8 дисками на каждой, смонтировать том на ноду и погонять тестами скоростными по IOPS и миграции ВМ туда-сюда. и услышать отзывы публики почтненной которая хотя бы год юзала это на продакшене плотно.
по ходу пьесы подергать сетевые кабеля на машинах =) Хотите дадим машины для лабы, а вы отчет напишите полный?
по ходу пьесы подергать сетевые кабеля на машинах =) Хотите дадим машины для лабы, а вы отчет напишите полный?
я хочу! вот только не в москве…
Коллеги тестили, пытались положить туда нейм-ноду хадупа. Как только сеть начинала работать не идеально — ceph вставал колом.
Расскажи плз поподробнее, интересна архитектура которую вы собирали.
Подтверждаю. При маломальской нагрузке если перейти на другую ноду, образ виртуалки оказывается битым.
Как минимум, для применения в виртуализации еще сыро
Как минимум, для применения в виртуализации еще сыро
а вы образ держали в файлике на ceph или же непосредственно в rbd?
Уверен Вы про CephFS.
Для виртуализации замечательно подходит RBD, который можно использовать в продакшн.
Для виртуализации замечательно подходит RBD, который можно использовать в продакшн.
Кстати, вы не сможете пособить советом в каком направлении читать — хочется попробовать развернуть proxmox с rbd?
Это конечная цель, но даже если говорить о последовательном приближении: вот qemu поддерживает rbd как сторадж, как это запускать с rbd?
Это конечная цель, но даже если говорить о последовательном приближении: вот qemu поддерживает rbd как сторадж, как это запускать с rbd?
У меня пока еще не было возможности познакомится с Proxmox поближе, но думаю что можно начать с этого.
Отлично, если у меня железо с аппаратным раидом — стоит сделать там действительно массив и один OSD, или же пусть будет JBOD и куча OSD?
Всегда лучше пробовать несколько вариантов. Начните с проброса каждого диска через контроллер и включите на нем writeback, если батарейка живая.
Надо полагать, что вы про rbd говорили, cephfs прямо сильно зависит от тонких настроек под железо.
Вот здесь правильные цифры, мы их наблюдаем в продакшне. Ну не год, но полгода будет, да.
Вот rbd как раз позволяет гонять туда сюда образы, kvm например, с даунтаймами меньше секунды под нагрузкой.
Вот здесь правильные цифры, мы их наблюдаем в продакшне. Ну не год, но полгода будет, да.
Вот rbd как раз позволяет гонять туда сюда образы, kvm например, с даунтаймами меньше секунды под нагрузкой.
Вот странная ситуация, у нас у самих есть машины. Но вот совершенно погрязли в работе не очень интересной.
Вы случайно не можете увеличить кол-во времени в сутках? :) Я бы тогда точно поигрался и написал отчет.
Вы случайно не можете увеличить кол-во времени в сутках? :) Я бы тогда точно поигрался и написал отчет.
Это не про поиграться — это надо обязательно делать, если речь идет не про развлечения, а про работу и использование технологии для чего-то полезного. Как вообще себе можно представить использовать что-то не ознакомившись, как оно себя поведет под нагрузкой и в случае банального выпадения кабеля питания или сетевого провода?
потом кстати мне не очень понятна экономическая целесообразность таких решений — много старых серверов жрут электричество и занимают место в стойках, выгоднее сделать одну голову с репликацией и подцепить к ней JBOD на нужное количество дисков и идти пить пиво на сэкономленные деньги.
каждый активный сервер в хозяйстве — это примерно 200 баксов в месяц на его обслуживание в пересчете на электричество и зарплату админов, за год любая экономия просматривается насквозь.
потом кстати мне не очень понятна экономическая целесообразность таких решений — много старых серверов жрут электричество и занимают место в стойках, выгоднее сделать одну голову с репликацией и подцепить к ней JBOD на нужное количество дисков и идти пить пиво на сэкономленные деньги.
каждый активный сервер в хозяйстве — это примерно 200 баксов в месяц на его обслуживание в пересчете на электричество и зарплату админов, за год любая экономия просматривается насквозь.
Про поигратся — у меня работа как игра. Все, что новое и на тестирование для меня игра :)
Конечно, перед внедрением чего-то все тестируется, но для меня этам тестов — это игра!
Удачно положить с виду надежную систему или найти баги — это интересно!
Конечно, перед внедрением чего-то все тестируется, но для меня этам тестов — это игра!
Удачно положить с виду надежную систему или найти баги — это интересно!
Основные преимущества software defined storage, что пришли сразу в голову, я перечислил чуть выше.
По поводу экономики — при сравнение надо учитывать намного больше переменных чем только «электричество и зарплату админов», потому что архитектура объектного хранилища совершенно иная от стандартного подхода на голове + JBOD.
По поводу экономики — при сравнение надо учитывать намного больше переменных чем только «электричество и зарплату админов», потому что архитектура объектного хранилища совершенно иная от стандартного подхода на голове + JBOD.
А клиенту всё равно к какой ноде цепляться? И, возмжно стоит через днс раздавать ip сереов, тогда при вылете первой он не потеряет хранилище.
Но основной вопрос в другом, что у этой штуки с произвоительностью?
Как она себя будет вести, если скажем планово выключить хранилище.
Т.е. порядок выключения 1,2,3 (на третью что-то успели записать, после выключения 1). потом включаем 1,2 (пытаемся прочитать то, что записали на 3), потом уже включается 3.
Но основной вопрос в другом, что у этой штуки с произвоительностью?
Как она себя будет вести, если скажем планово выключить хранилище.
Т.е. порядок выключения 1,2,3 (на третью что-то успели записать, после выключения 1). потом включаем 1,2 (пытаемся прочитать то, что записали на 3), потом уже включается 3.
А клиенту всё равно к какой ноде цепляться? И, возмжно стоит через днс раздавать ip сереов, тогда при вылете первой он не потеряет хранилище.
Клиент «разговаривает» с тремя доступными демонами мониторинга mon.a, mon.b, mon.c.
Но основной вопрос в другом, что у этой штуки с произвоительностью?
Как она себя будет вести, если скажем планово выключить хранилище.
Т.е. порядок выключения 1,2,3 (на третью что-то успели записать, после выключения 1). потом включаем 1,2 (пытаемся прочитать то, что записали на 3), потом уже включается 3.
Все файлы размещаемые на Ceph FS разбиваются на блоки данных которые дублируются на разных физических дисках так, что бы оба дубликата одного и того же блока не попадали на диски одной ноды. В результате каждый блок данных будет случайно записан в двух экземплярах учитывая размещение физических дисков друг к другу. Хранилище не подтверждает команду записи блока данных до момента подтверждения записи от всех элементов участвующих в репликации этого блока.
Плановое выключение, как и аварийное при продуманном дизайне дисковой подсистемы, не приведет к потери каких либо данных.
с синхронностью-асинхронностью транзакций как дела обстоят?
Репликация обязательно синхронная. Неделю назад был Dev Summit. На нем был презентован блупринт для асинхронки wiki.ceph.com/01Planning/02Blueprints/Dumpling/RGW_Geo-Replication_and_Disaster_Recovery
mount -t ceph node01:6789:/ /mnt/cephfs -o name=admin,secretfile=/etc/ceph/admin.secret,noatime
Почему монтирование с одним монитором? Надо все указывать.
mon1,mon2,mon3:/ /mnt/cephfs
Иначе, если откажет монитор, клиент повешается, иногда вместе с ядром.
— не рекомендуется маунтить туда, где крутится сам osd
— mds в данном конкретном случае очень важная штука, ей надо подкрутить ресурсов, она при большом количестве файлов жрет их очень много.
— журнал лучше убрать подальше от всего хозяйства, он прямо и четко влияет на производительность.
— btrfs лучше, чем xfs, ext4 тоже можно, но она самая медленная )
— много чего еще из нюансов.
cephfs еще сырой и имеет много нюансов, не отраженных (либо неявно отраженных) в документации. Если эти нюансы не учитывать, то будет все стоять колом.
Мы для себя выбрали radosgw, полет отличный.
Да, монтировать можно не все, а в том числе и отдельные пулы. С бубном правда. Но работает.
Моя вина, недосмотрел. Поправил, спасибо!
И не только. Хочу написать об этом подробно позднее.
— не рекомендуется маунтить туда, где крутится сам osd
— mds в данном конкретном случае очень важная штука, ей надо подкрутить ресурсов, она при большом количестве файлов жрет их очень много.
— журнал лучше убрать подальше от всего хозяйства, он прямо и четко влияет на производительность.
— btrfs лучше, чем xfs, ext4 тоже можно, но она самая медленная )
— много чего еще из нюансов.
И не только. Хочу написать об этом подробно позднее.
Есть проблема у ceph'а определённая, в необходимости выделения сервера под метаданные.
собрать на трёх компах из 3х дисков можно, но эффективность будет ниже плинтуса.
собрать на трёх компах из 3х дисков можно, но эффективность будет ниже плинтуса.
Для тех кому уже для продакшена надо подобное и к тому же стабильное — посмотрите на MooseFS
Что там у moose случается при падении master server? Все операции записи/чтения обрываются?
Что в случае split-brain?
Что в случае split-brain?
Операции не обрываются, они «замирают» пока новый мастер не поднимится, подхватывается он автоматически, для клиентов это выглядит как временный фриз. Падение чанк-серверов вообще не заметно, как и дисков на них.
Сплин-брейна нет как такового, т.к. метасервер только один + сколько захотите металоггеров, которые при падении мастера можно превратить в мастера.
Музе не без минусов, и мастер-сервер без автофаиловера — его единственный минус мной обнаруженный.
Они у себя советуют использовать ucarp, что я нахожу неприемлемым.
У себя организовал ежесекундный мониторинг с проверкой как по живучести IP, так и на уровне работоспособности порта мастер-процесса.
Переключение металоггера в мастера происходит только если кроме фиксирования падения мастера, видны другие металоггеры и не пингуется IP мастера, что исключает сплин-брейн полностью. На мастере тоже мониторинг, который освобождает IP, если мастер-процесс не отвечает.
Посмотрите еще здесь начиная отсюда и вниз:
habrahabr.ru/post/178533/#comment_6196527
Сплин-брейна нет как такового, т.к. метасервер только один + сколько захотите металоггеров, которые при падении мастера можно превратить в мастера.
Музе не без минусов, и мастер-сервер без автофаиловера — его единственный минус мной обнаруженный.
Они у себя советуют использовать ucarp, что я нахожу неприемлемым.
У себя организовал ежесекундный мониторинг с проверкой как по живучести IP, так и на уровне работоспособности порта мастер-процесса.
Переключение металоггера в мастера происходит только если кроме фиксирования падения мастера, видны другие металоггеры и не пингуется IP мастера, что исключает сплин-брейн полностью. На мастере тоже мониторинг, который освобождает IP, если мастер-процесс не отвечает.
Посмотрите еще здесь начиная отсюда и вниз:
habrahabr.ru/post/178533/#comment_6196527
А ну да, отсутствие авто-выбора нового master сервера и связанные с этим костыли и проблемы split-brain.
Я смотрел на мусе, но из-за этого даже ставить не стал.
Проблема такая что часть металлгеров могут оказаться в разных кусках разделённой сети — появиться новый мастер и обратно уже не склеешь. Так?
Я смотрел на мусе, но из-за этого даже ставить не стал.
Проблема такая что часть металлгеров могут оказаться в разных кусках разделённой сети — появиться новый мастер и обратно уже не склеешь. Так?
Да, это костыль, как расплата за стабильность и надежность. И это единственный фактор для меня, который играет наивысшую степень — данные должны жить, быть доступными и не испорченными при любом катаклизме. Поэтому я не даже не ставил ceph, достаточно просто отзывы о надежности почитать.
Сплит-брейна не существует, это не гластер.
Насчет разделенно сети, всё не так — вторичный мастер прежде чем подняться должен проверить агентов на доступность на всех сегментах.
У меня проще — все сервера к одному свитчу подключены, нет разнесения по стойкам, поэтому достаточно просто другой металоггер проверить и убедиться что упал именно основной мастер.
Сплит-брейна не существует, это не гластер.
Насчет разделенно сети, всё не так — вторичный мастер прежде чем подняться должен проверить агентов на доступность на всех сегментах.
У меня проще — все сервера к одному свитчу подключены, нет разнесения по стойкам, поэтому достаточно просто другой металоггер проверить и убедиться что упал именно основной мастер.
Я так полагаю ты имеешь ввиду отзывы о CephFS?
Многие путаются между CephFS и собственно самим хранилищем Ceph (RADOS). Вот так выглядит «экосистема»:

Многие путаются между CephFS и собственно самим хранилищем Ceph (RADOS). Вот так выглядит «экосистема»:

да, отзывы именно о cephfs, а вглубь уже не интересно, если на этом уровне работает нестабильно.
Выглядит конечно ceph привлекательно, похож тот же музе, но говорят пока рано в продакшн. А музе работает уже у многих годами, недовольных не встречал, если есть голова на плечах (например не ставить goal=1, а потом сокрушаться куда же файлы пропали при вылете диска).
Выглядит конечно ceph привлекательно, похож тот же музе, но говорят пока рано в продакшн. А музе работает уже у многих годами, недовольных не встречал, если есть голова на плечах (например не ставить goal=1, а потом сокрушаться куда же файлы пропали при вылете диска).
У меня вопрос: я игрался с cephfs, был впечатлён скоростью на чтение, но крайне разочарован производительностью за запись. Точнее, с линейной скоростью проблем не было, а вот скорость random write просто убивала.
В моём случае я использовал 1 сервер с 8 OSD (каждый OSD на своём винте), плюс отдельные винты для mon и mds.
На выходе я получал производительность записи в файл — примерно половина производительности одного диска.
Это фича или я его готовить не умею?
В моём случае я использовал 1 сервер с 8 OSD (каждый OSD на своём винте), плюс отдельные винты для mon и mds.
На выходе я получал производительность записи в файл — примерно половина производительности одного диска.
Это фича или я его готовить не умею?
Я видел Ваши вопросы в рассылке ceph-users, Георгий.
Можно мне взглянуть на вашу песочницу, если она еще не снесена?
Можно мне взглянуть на вашу песочницу, если она еще не снесена?
[global] auth cluster required = cephx auth service required = cephx auth client required = cephx [osd] osd journal size = 1000 filestore xattr use omap = true [mon.a] host = lab mon addr = 8.8.8.8:6789 [osd.0] host = lab devs = /dev/sda osd mkfs type = xfs [osd.1] host = lab devs = /dev/sdb osd mkfs type = xfs [osd.2] host = lab devs = /dev/sdc osd mkfs type = xfs [osd.3] host = lab devs = /dev/sdd osd mkfs type = xfs [osd.4] host = lab devs = /dev/sde osd mkfs type = xfs [osd.5] host = lab devs = /dev/sdf osd mkfs type = xfs [osd.6] host = lab devs = /dev/sdg osd mkfs type = xfs [osd.7] host = lab devs = /dev/sdh osd mkfs type = xfs [mds.a] host = lab
/dev/sda on /var/lib/ceph/osd/ceph-0 type xfs (rw,relatime,attr2,inode64,noquota)
/dev/sdb on /var/lib/ceph/osd/ceph-1 type xfs (rw,relatime,attr2,inode64,noquota)
/dev/sdc on /var/lib/ceph/osd/ceph-2 type xfs (rw,relatime,attr2,inode64,noquota)
/dev/sdd on /var/lib/ceph/osd/ceph-3 type xfs (rw,relatime,attr2,inode64,noquota)
/dev/sde on /var/lib/ceph/osd/ceph-4 type xfs (rw,relatime,attr2,inode64,noquota)
/dev/sdf on /var/lib/ceph/osd/ceph-5 type xfs (rw,relatime,attr2,inode64,noquota)
/dev/sdg on /var/lib/ceph/osd/ceph-6 type xfs (rw,relatime,attr2,inode64,noquota)
/dev/sdh on /var/lib/ceph/osd/ceph-7 type xfs (rw,relatime,attr2,inode64,noquota)
/dev/sdy on /var/lib/ceph/mon type xfs (rw,relatime,attr2,inode64,noquota)
/dev/sdz on /var/lib/ceph/mds type xfs (rw,relatime,attr2,inode64,noquota)
На один сервер все ставить они вроде как не рекомендуют, или хотя бы в kvm. Журнал надо однозначно на ssd.
Плюс что-то надо сделать с mds, тоже на быстрый диск и много cpu, самое слабое звено. XFS заменить на btrfs.
С такими допущениями у нас проблем нет вроде со скоростью, все сопоставимо, есть проблемы с количеством файлов в этой штуке.
А какой релиз, кстати, для них вполне нормально даже в минорном релизе что-нибудь громадное пофиксить и допилить.
Почему relatime? noatime?
Плюс что-то надо сделать с mds, тоже на быстрый диск и много cpu, самое слабое звено. XFS заменить на btrfs.
С такими допущениями у нас проблем нет вроде со скоростью, все сопоставимо, есть проблемы с количеством файлов в этой штуке.
А какой релиз, кстати, для них вполне нормально даже в минорном релизе что-нибудь громадное пофиксить и допилить.
Почему relatime? noatime?
А эта FS принципиально умеет работать с shared storage? Ну есть у меня дисковая полка с FC подключением. Как-то тупо если я один виртуальный диск с полки с одним только узлом зацеплю, весь смысл от multipath теряется…
Простите, не осилил до конца вопрос.
Ceph работает с выделенными дисковыми ресурсами посредством файловой системы, в этом примере — xfs. То есть, на презентованом диске должна быть файловая система, а ниже может быть HBA с multipath на LUN дисковой полки.
Ceph работает с выделенными дисковыми ресурсами посредством файловой системы, в этом примере — xfs. То есть, на презентованом диске должна быть файловая система, а ниже может быть HBA с multipath на LUN дисковой полки.
разрешите я попытаюсь пояснить
вот у меня есть полка, подключенная по FC. Один и тот же том на полке видится по multipath на нескольких нодах одновременно. Я так например могу использовать cluster lvm — создал lv на одном сервере, на другом тоже его вижу.
Могу ли я запустить на разных серверах несколько ODS, подключенных к одному и тому же тому на полке? Как пример, это может быть полезно для отказоусточивости — я таким образом как бы расшариваю в сеть через rados то, что у меня было доступно только через FC и гарантирую, что даже при выходе из строя одного из ODS я буду иметь другую ноду, которая подключена к тому же самому стораджу.
вот у меня есть полка, подключенная по FC. Один и тот же том на полке видится по multipath на нескольких нодах одновременно. Я так например могу использовать cluster lvm — создал lv на одном сервере, на другом тоже его вижу.
Могу ли я запустить на разных серверах несколько ODS, подключенных к одному и тому же тому на полке? Как пример, это может быть полезно для отказоусточивости — я таким образом как бы расшариваю в сеть через rados то, что у меня было доступно только через FC и гарантирую, что даже при выходе из строя одного из ODS я буду иметь другую ноду, которая подключена к тому же самому стораджу.
Логика RADOS в том, что бы разбить данные на блоки и положить их на файловые системы дисковых ресурсов. Во время записи блоки можно продублировать столько раз сколько необходимо на разные физические диски учитывая размещение физических дисков друг к другу (ноды, шкафы). При правильной архитектуре мы можем прозрачно потерять не только диск, OSD демон, но и всю ноду или шкаф.
Если есть такие простаивающие ресурсы как дисковые полки, их можно попробовать разбить по одному LUN на каждую ноду. Специально закупать классическую СХД под Ceph нет никакого экономического смысла.
Если есть такие простаивающие ресурсы как дисковые полки, их можно попробовать разбить по одному LUN на каждую ноду. Специально закупать классическую СХД под Ceph нет никакого экономического смысла.
Резюмируя, не умеет. Более зрелые FS умеют, тот же GPFS, с дешевыми похоже никто не умеет. С glusterfs, например, та же фигня. OCFS2 умеет, но там максимум 32 ноды и они все должны быть подключены к полке.
Ваша идея уйти от обязательной репликации при падении OSD демона?
Именно. Это же демон упал, а не полка. А до полки у меня несколько путей через разные сервера. Как-то тупо кроме RAID50, например, еще и поверх делать репликацию.
Принимая во внимание то, что отказ демона (или его диска) и восстановление данных будут не заметны для клиента, применение RAID вместе с Ceph выйдет всегда сильно расточительно.
Вот-вот, почему бы ему не научиться мультипафингу, в том числе.
Потому что расточительно. Воспринимайте Ceph как RAID только с гранулярнорстью в объект при очень большом количестве дисков с построением карты иерархии/весов (учитывается размещение физических дисков друг к другу).
Вы же не делаете RAID поверж прицепленых дисков с полки где тоже сделали RAID?
Вы же не делаете RAID поверж прицепленых дисков с полки где тоже сделали RAID?
Я не очень понимаю куда вы клоните. Именно что Ceph как раз и провоцирует создать RAID (своими силами) поверх RAID с полки.
Может вы не достаточно ясно представляете себе инфраструктуру? Допустим у нас есть несколько дисковых полок, подключаемых по фибре. У них там довольно приличные скорости дискового обмена, гигабайты в секунду. Есть пяток серверов, отвечающих за нашу параллельную ФС. Т.е. они подключены фиброй к полкам, на них крутятся все демоны и прочее. И есть сотня-другая клиентов, которые цепляют к себе ФС с этих файловых серверов и собственно юзают. Одновременно. Так как все серверы хранения подключены ко всем полкам, потеря одного-двух серверов не должна вызвать отказ в работе дисковой подсистемы. В этом заключается с одной стороны возможность максимально использовать пропускную способность полок (разные запросы могут идти разными маршрутами), с другой — отказоустойчивость.
Так вот, Ceph в текущем виде предлагает выкинуть полки нафиг, воткнуть винты напрямую в серваки.
Может вы не достаточно ясно представляете себе инфраструктуру? Допустим у нас есть несколько дисковых полок, подключаемых по фибре. У них там довольно приличные скорости дискового обмена, гигабайты в секунду. Есть пяток серверов, отвечающих за нашу параллельную ФС. Т.е. они подключены фиброй к полкам, на них крутятся все демоны и прочее. И есть сотня-другая клиентов, которые цепляют к себе ФС с этих файловых серверов и собственно юзают. Одновременно. Так как все серверы хранения подключены ко всем полкам, потеря одного-двух серверов не должна вызвать отказ в работе дисковой подсистемы. В этом заключается с одной стороны возможность максимально использовать пропускную способность полок (разные запросы могут идти разными маршрутами), с другой — отказоустойчивость.
Так вот, Ceph в текущем виде предлагает выкинуть полки нафиг, воткнуть винты напрямую в серваки.
Вы себе решения типа Ceph просто недостаточно точно представляете. Не нужен FC, не нужны дорогие полки. Берёте 5 машин, подтыкаете по обычной SAS полке к каждой, поднимаете Ceph (ну или не Ceph, не суть важно). Более того, делать RAID совсем не надо, лучше от него не станет, а восстанавливать средствами софта получится скорее всего быстрее, чем RAID под нагрузкой соберётся (во всяком случае у нас совсем грустные цифры восстановления получались, скопировать рсинком пару терабайт по гигабитной сети на порядок быстрее). На случай вылета сервера или проблем с сетью у вас и так есть вторая (и даже третья) копия. А поломка SAS канала между дисками и сервером редкость редкая.
В чём вы видите профит при наличии нескольких серверов, раздающих данные с одной и той же полки?
В чём вы видите профит при наличии нескольких серверов, раздающих данные с одной и той же полки?
«Редкость редкая» != невозможная, а мультипаф решает ея
Надо понимать, что если уже есть полка, то надо ее использовать по-максимуму, тут цеф не подойдет. Он для тех, кто не хочет больше полок.
ceph решает это другими методами. Есть куча osd, на них лежат размазанные кусочки объектов в репликации ^2 (или как настроить).
osd вылетел — цеф автоматом сам восстановит данные от соседа. Если восстановить не сможет, значит у вас ошибка в архитектуре. Причем объекты размазываются псевдорандомно, не так, что
osd.0 это копия osd.1, а osd.2 — > osd.3. Файл, как видит его клиент, может быть размазан одновременно по 4 дискам. а может и по двум. Или по трем. Причем ceph все время мониторит доступность и скорость дисков и чуть-чего начнет рекавери сам.
Вероятность потери данных есть, для этого и придуманы уровни репликации. А если учесть, что osd — это простой блокдевайс с обычной файлухой, то какова вероятность того, что у вас что-то случится одновременно с двумя или тремя дисками с обычной файлухой так, что нельзя восстановить?
Если система сложная, то надо сначала продумать и настроить расположение сервисов, CRUSH-карту распределения объектов, веса хранилищ и уровни репликации для пулов.
ceph решает это другими методами. Есть куча osd, на них лежат размазанные кусочки объектов в репликации ^2 (или как настроить).
osd вылетел — цеф автоматом сам восстановит данные от соседа. Если восстановить не сможет, значит у вас ошибка в архитектуре. Причем объекты размазываются псевдорандомно, не так, что
osd.0 это копия osd.1, а osd.2 — > osd.3. Файл, как видит его клиент, может быть размазан одновременно по 4 дискам. а может и по двум. Или по трем. Причем ceph все время мониторит доступность и скорость дисков и чуть-чего начнет рекавери сам.
Вероятность потери данных есть, для этого и придуманы уровни репликации. А если учесть, что osd — это простой блокдевайс с обычной файлухой, то какова вероятность того, что у вас что-то случится одновременно с двумя или тремя дисками с обычной файлухой так, что нельзя восстановить?
Если система сложная, то надо сначала продумать и настроить расположение сервисов, CRUSH-карту распределения объектов, веса хранилищ и уровни репликации для пулов.
Профит в том, что полка может выжать допустим 1 ГБ/с, а у серверов сеть 1 Гбит/с. А с мультипафингом можно и больше выжать с инсталляции.
А еще профит в том, что полки и фибра у меня уже есть, а сервера под сотни дисков — надо покупать.
А еще профит в том, что полки и фибра у меня уже есть, а сервера под сотни дисков — надо покупать.
Чего выжать-то? Это скорость для клиента? Да лааадно. Файлуха столько не жмет никакая распределенная.
С полками другие проблемы — это гибкость и масштабируемость. Ну вот кончилось у вас место, дальше что? Или вам по пику два дня в месяц надо пережить на 100 гб больше, чем у вас есть?
Файлуха распределенная как-будто не глючит? ocfs2 да жесть же. gfs2? такая же. Весь кластер в коллтрейс — да легко ))
А если полка свалится? С проприетарным контроллером )) С вашей инфой что будет, пока эта полка по сервисам ездит 4 месяца?
С полками другие проблемы — это гибкость и масштабируемость. Ну вот кончилось у вас место, дальше что? Или вам по пику два дня в месяц надо пережить на 100 гб больше, чем у вас есть?
Файлуха распределенная как-будто не глючит? ocfs2 да жесть же. gfs2? такая же. Весь кластер в коллтрейс — да легко ))
А если полка свалится? С проприетарным контроллером )) С вашей инфой что будет, пока эта полка по сервисам ездит 4 месяца?
Вот в том и грусть-пичяль современности. Вроде и надо, а делать-то не чего :(
Ну у меня на работе, допустим, GPFS до 8 ГБ/с жмет. При 6 сотнях клиентов. Правда соединение InfiniBand.
Если у вас полка 4 месяца по сервисам ездит, меняйте системного интегратора что ли. Они по договору обычно менее чем за неделю заменяют железо.
Если у вас полка 4 месяца по сервисам ездит, меняйте системного интегратора что ли. Они по договору обычно менее чем за неделю заменяют железо.
Не пойму. 8 гигабайт в секунду скорость чего? Скорость чтения клиентом с дискового массива? О_о
Или это шина прокачивет? Тогда при чем тут GPFS?
Менее чем неделю — это круто. Будем менее, чем неделю стоять без данных ога.
Или это шина прокачивет? Тогда при чем тут GPFS?
Менее чем неделю — это круто. Будем менее, чем неделю стоять без данных ога.
Ceph всё также уныло дохнет если вырубить mds?
В 0.4 в лучшем случае все зависало минут на пять пока новый mds не выбран, а обычно просто обратно ноды не собирались ругаясь на разсинхронизацию. Починили?
В 0.4 в лучшем случае все зависало минут на пять пока новый mds не выбран, а обычно просто обратно ноды не собирались ругаясь на разсинхронизацию. Починили?
В препродакшн по-прежнему рекомендуют ставить не более одного mds.
Я пробовал то, о чем вы написали на версии 0.56.4 — задержка при создании/удалении файлов была, но измерялась секундами.
Я пробовал то, о чем вы написали на версии 0.56.4 — задержка при создании/удалении файлов была, но измерялась секундами.
Один mds? Fault tolerance говорите? Ну-ну…
Хотел бы попросить сделать еще такой тест с ядерным клиентом:
В несколько потоков пишите и читаете на ceph большие файлы (по гигу скажем) и мелкие, в этот момент делаете kill -9 mds-у.
Что на клиенте? Kernel panic не случается? Linux не зависает на несколько секунд на всех файловых операциях?
Хотел бы попросить сделать еще такой тест с ядерным клиентом:
В несколько потоков пишите и читаете на ceph большие файлы (по гигу скажем) и мелкие, в этот момент делаете kill -9 mds-у.
Что на клиенте? Kernel panic не случается? Linux не зависает на несколько секунд на всех файловых операциях?
Скажите, чем это лучше / хуже Хадупа?
Мы хотим уйти с хадупа, так как нам не нужен mapreduce и нужна POSIX совместимость.
Проще, сильно проще. Ну а вот сейчас поправьте меня, могу ошибаться.
Метаданные хадуп хранит на name-node, она одна, и все лежит в памяти. То есть количество файлов на файловой системе жестко ограничено размером памяти одной ноды с метаданными? Это — точка отказа и потенциальный bottleneck.
ceph скалируется по-всякому. Можно любое блочное устройство подцепить любого размера, все будет работать. Также у ceph есть и другие способы использования, помимо cephfs
— блочное устройство rbd. Эта штука давно в продакшн и везде впиливается. KVM умеет его как underlying, из софта — openstack, opennebula, proxmox, тот же hadoop.
— radosgw — почти полная совместимость с amazonS3 и swift.
То есть, имея свой кластер ceph, можно использовать его по-разному. И ничего ничему мешать не будет.
Метаданные хадуп хранит на name-node, она одна, и все лежит в памяти. То есть количество файлов на файловой системе жестко ограничено размером памяти одной ноды с метаданными? Это — точка отказа и потенциальный bottleneck.
ceph скалируется по-всякому. Можно любое блочное устройство подцепить любого размера, все будет работать. Также у ceph есть и другие способы использования, помимо cephfs
— блочное устройство rbd. Эта штука давно в продакшн и везде впиливается. KVM умеет его как underlying, из софта — openstack, opennebula, proxmox, тот же hadoop.
— radosgw — почти полная совместимость с amazonS3 и swift.
То есть, имея свой кластер ceph, можно использовать его по-разному. И ничего ничему мешать не будет.
В целом идея понятна.
Что касается Хадупа, там сейчас две NameNode, Active/Passive, они дублируют друг друга для минимизации single point of failure.
Метаданные — действительно должны влезать в память. Но, впринципе люди говорят, что хватает 150 байт на один файл.
Each file or directory or block occupies about 150 bytes in the namenode memory.
Что касается Хадупа, там сейчас две NameNode, Active/Passive, они дублируют друг друга для минимизации single point of failure.
Метаданные — действительно должны влезать в память. Но, впринципе люди говорят, что хватает 150 байт на один файл.
Each file or directory or block occupies about 150 bytes in the namenode memory.
Ну, то есть так и есть — основная проблема в том, что если памяти у name-node не хватит, то при избытке собственно места, мы ничего с ним сделать не сможем. Если мы говорим про петабайты и BIgData, то ceph умеет, а для hadoopfs — надо заморочиться )))
Другой вопрос, что cephfs еще сыровата, мягко говоря. Как бы не пришлось заморочиться еще больше )))))
Другой вопрос, что cephfs еще сыровата, мягко говоря. Как бы не пришлось заморочиться еще больше )))))
Добрый вечер!
Спасибо автору за ценный материал. Однако, смущает потеря половины пространства при стандартном уровне репликации. Гугление привело к манам по пулам ceph.com/docs/master/rados/operations/pools/. По ним создан пул erasure с erasure-code-k=5 и erasure-code-m=2. Через rados df пул отображается. Но пока использовать этот пул получилось только через блочное устройство в пуле. Все данные при монтировании через mount -t ceph..., как указано в статье, попадают в дефолтный пул data. Как заставить ceph использовать для данных не пул data, а новый erasure пул?
Спасибо автору за ценный материал. Однако, смущает потеря половины пространства при стандартном уровне репликации. Гугление привело к манам по пулам ceph.com/docs/master/rados/operations/pools/. По ним создан пул erasure с erasure-code-k=5 и erasure-code-m=2. Через rados df пул отображается. Но пока использовать этот пул получилось только через блочное устройство в пуле. Все данные при монтировании через mount -t ceph..., как указано в статье, попадают в дефолтный пул data. Как заставить ceph использовать для данных не пул data, а новый erasure пул?
Извини, только что заметил твой вопрос. Не знаю точно что делает erasure, но по поводу использования отличного от data пула для mds смотри тут
А как обстоят дела у Ceph FS с гео-репликацией (когда ноды разнесены по разным датацентрам)?
Насколько я знаю, пока никак. Кластер не может быть растянут на две автономные площадки, то есть если половинки развалятся, каждая будет жить сама по себе и никакой консистенции не будет. Как-то так.
Но, делать репликацию между двумя кластерами (они могут быть в разных датацентрах) для объектного доступа RadosGW уже возможно, но я не копал в эту сторону глубоко http://ceph.com/docs/master/radosgw/federated-config/.
Но, делать репликацию между двумя кластерами (они могут быть в разных датацентрах) для объектного доступа RadosGW уже возможно, но я не копал в эту сторону глубоко http://ceph.com/docs/master/radosgw/federated-config/.
У меня тут несколько вопрос накопилось:
— Правильно ли я понимаю, что CephFS можно монтировать r/w в нескольких местах одновременно?
— Читал, что если на ноде больше 8 osd, то прелесть журнала на ssd пропадает. Так ли это?
— В той же статье было написано, что больше 8 osd не желательно. Но тогда как-то не экномично выходит учитывая, что тут же рекомендация использовать 1:1 мапинг (osd:drive)
— Правда ли, что нода умирает если потерялся журнал?
Решаю между Ceph на 4 машинах (3 osd и 1 mds) и просто большим SAN'ом. Каждый OSD допустим имеет 24 диска. Ну или 12.
— Правильно ли я понимаю, что CephFS можно монтировать r/w в нескольких местах одновременно?
— Читал, что если на ноде больше 8 osd, то прелесть журнала на ssd пропадает. Так ли это?
— В той же статье было написано, что больше 8 osd не желательно. Но тогда как-то не экномично выходит учитывая, что тут же рекомендация использовать 1:1 мапинг (osd:drive)
— Правда ли, что нода умирает если потерялся журнал?
Решаю между Ceph на 4 машинах (3 osd и 1 mds) и просто большим SAN'ом. Каждый OSD допустим имеет 24 диска. Ну или 12.
Попытаюсь ответить, так как у меня CEPH в продакшене.
1 — Да можно.
2 — Зависит от того как вы выносите журнал на SSD, и от вашей сети. Если вы пилите один SSD под журнал на 8+ винтов — то пропадает уже при 5 винтах, так как суммарная скорость записи на 5 разных HDD и на один SSD сравнивается. Про сеть — если у вас сети данных и сети синхронизации разделены и скорость 1G по больше 5 OSD на один сервер не ставьте. Если же сети не разделены то в 2 раза меньше. Ну а если у вас 10G и lowlatency свитч то можно и побольше поставить.
3 — Если у вас хороший SATA контроллер, и быстрая сеть — можно и больше 8.
4 — Да, правда, нода умирает, но в процессе восстановления находит данные и актуализирует их.
PS: поделитесь ссылкой на статью.
1 — Да можно.
2 — Зависит от того как вы выносите журнал на SSD, и от вашей сети. Если вы пилите один SSD под журнал на 8+ винтов — то пропадает уже при 5 винтах, так как суммарная скорость записи на 5 разных HDD и на один SSD сравнивается. Про сеть — если у вас сети данных и сети синхронизации разделены и скорость 1G по больше 5 OSD на один сервер не ставьте. Если же сети не разделены то в 2 раза меньше. Ну а если у вас 10G и lowlatency свитч то можно и побольше поставить.
3 — Если у вас хороший SATA контроллер, и быстрая сеть — можно и больше 8.
4 — Да, правда, нода умирает, но в процессе восстановления находит данные и актуализирует их.
PS: поделитесь ссылкой на статью.
Понятно. Выходит при моем маштабе проще и дешевле большой тазик купить.
Вот статять: www.hastexo.com/resources/hints-and-kinks/solid-state-drives-and-ceph-osd-journals
Вот статять: www.hastexo.com/resources/hints-and-kinks/solid-state-drives-and-ceph-osd-journals
Ну не скажите, у меня собрано на очень старом железе и всё летает. Самое дорогое — винты.
Сервера HP Proliant DL320 G4 4GB RAM 2TB*2HDD
Коммутаторы D-link DGS3100-24TG
Суммарно 5 серверов, до 1000iops проблем не знаю.
Сервера HP Proliant DL320 G4 4GB RAM 2TB*2HDD
Коммутаторы D-link DGS3100-24TG
Суммарно 5 серверов, до 1000iops проблем не знаю.
Тоесть у вас 20ТБ до redundancy выходит?
Я то считал пачку тазиков на новых Dell R720 и R320 для mds. По FC или IB их цеплять между собой. В результате у меня вышло печально много. Дешевле выходит один R920. И брать MD1200 если место кончится. По-цене выходит так же, а администрировать проще.
Конечно если брать G4 я бы не доверил все одной ноде и размазал на несколько.
Я то считал пачку тазиков на новых Dell R720 и R320 для mds. По FC или IB их цеплять между собой. В результате у меня вышло печально много. Дешевле выходит один R920. И брать MD1200 если место кончится. По-цене выходит так же, а администрировать проще.
Конечно если брать G4 я бы не доверил все одной ноде и размазал на несколько.
Да, выходит 20TB.
G4 я не покупал, валялись, решил задействовать.
Далее — если вы купите один R920 то никакой отказоустойчивости у вас не будет. я бы на вашем месте взял несколько Dell R320 и размазал на них всю нагрузку. Например opennebula с этим бы прекрасно справилась.
Для MDS не нужен отдельный хост, с 0.7Х ветки их можно ставить на каждый хост. Активен будет один, а остальные «на подхвате», аналогично с mon. у меня на каждой ноде 2 OSD, MON, MDS.
G4 я не покупал, валялись, решил задействовать.
Далее — если вы купите один R920 то никакой отказоустойчивости у вас не будет. я бы на вашем месте взял несколько Dell R320 и размазал на них всю нагрузку. Например opennebula с этим бы прекрасно справилась.
Для MDS не нужен отдельный хост, с 0.7Х ветки их можно ставить на каждый хост. Активен будет один, а остальные «на подхвате», аналогично с mon. у меня на каждой ноде 2 OSD, MON, MDS.
Sign up to leave a comment.
Распределенная файловая система Ceph FS за 15 минут