Перевод этой статьи уже есть на хабре, но он ужасен и содержит ложную информацию.
Приветствую, искатели приключений! Путешествуя по территории индексации MongoDB хотя бы некоторое время, вы, возможно, познакомились с таким правилом: если ваш запрос содержит сортировку/порядок (orderby) – добавьте сортируемое поле в конец индекса который используется для запроса.
Во многих случаях когда запрос содержит равенство (то есть поиск конкретного значения, например, {“name”: “Charlie”}) данная мантра бывает весьма полезной.
Запрос
Индекс
Такая комбинация будет не такой эффективной, как может показаться, не смотря на то, что индекс соответствует правилу. В этом запросе есть ловушка, в которую вы с легкостью попадете следуя общепринятому мнению.
Давайте разберемся что здесь не так и что делать в таких случаях. Но для начала, не смотря на то что этот пост не про основы индексации, освежим память по этой теме с помощью документации MongoDB:
“Индексируйте заранее”
Индексы заслуживают особого внимания в процессе дизайна. Исторически сложилось так что вопрос ответственность за эффективность доступа к данным ложится на администратора базы данных. Это провоцирует создание слоев оптимизации уже после дизайна, что документо-ориентируемая база может избежать.
“Индексируйте часто”
Индексированные запросы на порядок эффективнее обычных даже с небольшим количеством данных. Если неиндексированный запрос длится 10 секунд, тот же самый запрос может быть выполнен за 0 миллисекунд при использовании правильного индекса.
“Индексируйте полностью"
Запросы используют индексы слева направо. Индекс может быть использован только до тех пор пока запрос использует все поля и не пропускает ни одного.
“Индексируйте сортировку”
Если ваш запрос содержит сортировку или оператор orderby – добавьте сортируемое поле в индекс.
Команды
Вернемся к нашей проблеме. Держа в голове эти базовые знания, расхожее мнение гласит что для следующего запроса:
Необходимо создать следующий индекс:
Что если в большинстве запросов применяется диапазон вместо равенства? Как тут:
Здесь мы используем
Если вы заметили что такие запросы выполняются медленно, и вы помните основы о которых мы говорили, то запустите
Но забудьте о причинах медленной работы scanAndOrder; почему MongoDB сортирует результаты если мы уже добавили это поле в индекс? Ответ прост: мы не сделали этого.
Почему? Ответ кроется в структуре индекса который мы создали. В нашем примере документ с
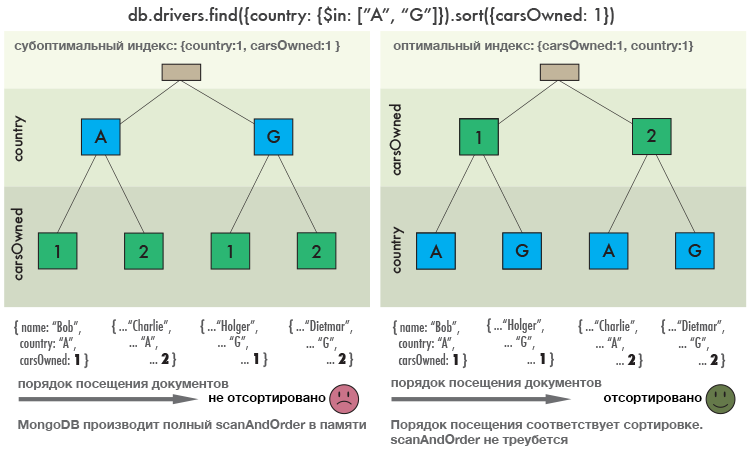
Схема слева иллюстрирует порядок посещения документов в соответствии с индексом который мы создали. Когда все документы, соответствующие запросу, найдены, их следует отсортировать. Схема справа показывает работу запроса с альтернативным индексом:
Порядок полей в индексе должен быть таким:
1. Сначала – поля, которые используются в запросе на точные значения.
2. Затем – сортируемые поля.
3. И в конце – поля, которые используются для поиска в диапазонах.
Идем ли мы на компромисс? Да. Запрос посетит большее количество документов чем технически необходимо, потому что посещения сортируемой части индекса произойдут перед применением оператора диапазонов. Помните эти простые правила, но имейте ввиду, что размеры ваших данных может приводить и к иным результатам.
Надеюсь это руководство окажется для вас полезным. Удачи, искатели приключений!
Искренне ваш,
Эрик из MongoLab.
Приветствую, искатели приключений! Путешествуя по территории индексации MongoDB хотя бы некоторое время, вы, возможно, познакомились с таким правилом: если ваш запрос содержит сортировку/порядок (orderby) – добавьте сортируемое поле в конец индекса который используется для запроса.
Во многих случаях когда запрос содержит равенство (то есть поиск конкретного значения, например, {“name”: “Charlie”}) данная мантра бывает весьма полезной.
Запрос
db.drivers.find({"country": {"$in": ["A", "G"]}}).sort({"carsOwned": 1})Индекс
{"country": 1, "carsOwned": 1}Такая комбинация будет не такой эффективной, как может показаться, не смотря на то, что индекс соответствует правилу. В этом запросе есть ловушка, в которую вы с легкостью попадете следуя общепринятому мнению.
Давайте разберемся что здесь не так и что делать в таких случаях. Но для начала, не смотря на то что этот пост не про основы индексации, освежим память по этой теме с помощью документации MongoDB:
“Индексируйте заранее”
Индексы заслуживают особого внимания в процессе дизайна. Исторически сложилось так что вопрос ответственность за эффективность доступа к данным ложится на администратора базы данных. Это провоцирует создание слоев оптимизации уже после дизайна, что документо-ориентируемая база может избежать.
“Индексируйте часто”
Индексированные запросы на порядок эффективнее обычных даже с небольшим количеством данных. Если неиндексированный запрос длится 10 секунд, тот же самый запрос может быть выполнен за 0 миллисекунд при использовании правильного индекса.
“Индексируйте полностью"
Запросы используют индексы слева направо. Индекс может быть использован только до тех пор пока запрос использует все поля и не пропускает ни одного.
“Индексируйте сортировку”
Если ваш запрос содержит сортировку или оператор orderby – добавьте сортируемое поле в индекс.
Команды
.explain() показывает использовался ли индекс (наряду с другой полезной информацией – прим. пер.),.ensureIndex() создает индекс,.getIndexes() или .getIndexKeys() выводит список индексов для коллекции.Вернемся к нашей проблеме. Держа в голове эти базовые знания, расхожее мнение гласит что для следующего запроса:
db.collection.find({“country”: “A”}).sort({“carsOwned”: 1})Необходимо создать следующий индекс:
db.collection.ensureIndex({"country": 1, "carsOwned": 1})Что если в большинстве запросов применяется диапазон вместо равенства? Как тут:
db.collection.find({"country": {"$in": ["A", "G"]}}).sort({"carsOwned": 1})Здесь мы используем
$in, но то же самое работает для $gt, $lt и т.д.Если вы заметили что такие запросы выполняются медленно, и вы помните основы о которых мы говорили, то запустите
.explain() и посмотрите какой индекс использовался. Но вы также увидите {scanAndOrder : true}, который означает что MongoDB произвела сортировку. Причина медленного выполнения запроса именно в этом: scanAndOrder – дорогая операция, потому что она сортирует документы в памяти. Ее нужно избегать при работе с большими массивами данных, она медленная и сильно нагружает процессор.Но забудьте о причинах медленной работы scanAndOrder; почему MongoDB сортирует результаты если мы уже добавили это поле в индекс? Ответ прост: мы не сделали этого.
Почему? Ответ кроется в структуре индекса который мы создали. В нашем примере документ с
{“country”: “A”} и документ с {“country”: “G”} отсортированы в индексе по ключу {“carsOwned”: 1}, но они отсортированы независимо друг от друга. Они не отсортированы вместе! 
Схема слева иллюстрирует порядок посещения документов в соответствии с индексом который мы создали. Когда все документы, соответствующие запросу, найдены, их следует отсортировать. Схема справа показывает работу запроса с альтернативным индексом:
{ “carsOwned”: 1, “country”: 1}. Переместив поле сортировки ближе к началу (влево) индекса мы создали сценарий в котором MongoDB посещает документы в том порядке, который нам требуется. Из этой эффективной хитрости следует простой набор правил для индексации:Порядок полей в индексе должен быть таким:
1. Сначала – поля, которые используются в запросе на точные значения.
2. Затем – сортируемые поля.
3. И в конце – поля, которые используются для поиска в диапазонах.
Идем ли мы на компромисс? Да. Запрос посетит большее количество документов чем технически необходимо, потому что посещения сортируемой части индекса произойдут перед применением оператора диапазонов. Помните эти простые правила, но имейте ввиду, что размеры ваших данных может приводить и к иным результатам.
Надеюсь это руководство окажется для вас полезным. Удачи, искатели приключений!
Искренне ваш,
Эрик из MongoLab.
