Comments 32
Забыли упомянуть про Mercurial Queues и самый лучший DVCS GUI клиент «TortoiseHG».
Под Mac я очень доволен клиентом SourceTree. Хочу также добавить, что есть сервис BitBucket.org от Atlassian (не реклама, просто пользуюсь).
Пользовался долгое время на винде TortoiseHG. Мое мнение — он крайне убог, если сравнивать с tortoiseGit. Единственное его нормальное применение — смотреть историю.
Сейчас на маке использую SourceTree — дело обстоит чуть лучше с меркуриалом.
Но вообще гит мне по нраву больше (использую оба, и меркуриал даже больше), он проще, гибче.
Сейчас на маке использую SourceTree — дело обстоит чуть лучше с меркуриалом.
Но вообще гит мне по нраву больше (использую оба, и меркуриал даже больше), он проще, гибче.
Давно пользовались TortoiseHG? За последние пару лет он очень сильно изменился. Чего только стоит THg Workbench.
Пару месяцев назад использовал tortoiseGit и могу с уверенностью сказать что он убог против последней версии TortoiseHg.
Пару месяцев назад использовал tortoiseGit и могу с уверенностью сказать что он убог против последней версии TortoiseHg.
Последний раз плотно его использовал в ноябре. Осмотрю еще разок.
О, да. Hg Workbench — просто сказка, а не фича :) Я пробовал TortoiseGit — и этого там очень не хватало.
Возможность удобно коммитить только некоторые правки из одного файла — очень удобна. Просмотр истории, списка исправленных файлов и diff-ов в одном окне — чувствуется, что делалось с душой и для людей.

Возможность удобно коммитить только некоторые правки из одного файла — очень удобна. Просмотр истории, списка исправленных файлов и diff-ов в одном окне — чувствуется, что делалось с душой и для людей.

TortoiseGit для меня очень не удобен. Он не даёт возможности сделать (или удобно сделать) вещи, котоорые мне нужны регулярно: — нет возможности удобно закоммитить часть изменений в файле
— неудобно делать pull с rebase
— неудобная навигация по репозиториям
— нет возможности сделать interactive rebase
Я советую попробовать git extensions. Он всё это позволяет сделать. В частности там можно коммитить только некоторые правки из одного файла. Для сравнения, картинка окна git extensions:
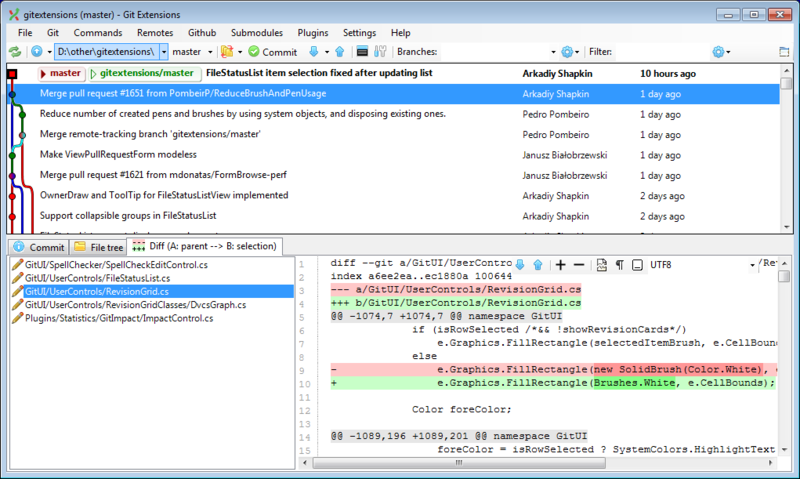
— неудобно делать pull с rebase
— неудобная навигация по репозиториям
— нет возможности сделать interactive rebase
Я советую попробовать git extensions. Он всё это позволяет сделать. В частности там можно коммитить только некоторые правки из одного файла. Для сравнения, картинка окна git extensions:

— нет возможности удобно закоммитить часть изменений в файле
— неудобно делать pull с rebase
— неудобная навигация по репозиториям
— нет возможности сделать interactive rebase
В последней версии tortoiseHg все эти недостатки исправно отсутствуют и фичи прекрасно работают.
Публикаций про преимущества DVCS систем в Сети вагон (тем не менее, спасибо за ещё одну, хорошие вводные материалы лишними не бывают). А вот кто бы сказал что-нибудь в пользу классических систем типа CVS и SVN? Многие, ведь, до сих пор ими пользуются, значит в каких то случаях они удобнее? Очень интересно в каких и чем.
Например в корпоративной разработке. Используя SVN (CVS уже можно не вспоминать, если и используют, то очень немногие) можно получить следующие преимущества:
1)гораздо больший шанс того, что в репозитории лежат актуальные результаты работы всех разработчиков. Если разрешить DCVS, то разработчиков сложнее контроллировать.
2)следствие из предыдущего пункта: хранение данных на едином сервере приводит к их большей надежности и сохранности. Если разработчик пару недель коммитил ревизии на своём ПК, и если что-то с этим ПК случится, то будут потеряны результаты работы за это время. Если коммитил в SVN, то всё ок, на таких серверах всегда есть RAID и бэкапы.
1)гораздо больший шанс того, что в репозитории лежат актуальные результаты работы всех разработчиков. Если разрешить DCVS, то разработчиков сложнее контроллировать.
2)следствие из предыдущего пункта: хранение данных на едином сервере приводит к их большей надежности и сохранности. Если разработчик пару недель коммитил ревизии на своём ПК, и если что-то с этим ПК случится, то будут потеряны результаты работы за это время. Если коммитил в SVN, то всё ок, на таких серверах всегда есть RAID и бэкапы.
1)гораздо больший шанс того, что в репозитории лежат актуальные результаты работы всех разработчиков. Если разрешить DCVS, то разработчиков сложнее контроллировать.
Не совсем понимаю, в чем тут отличие от DCVS? У нас в конторе например принято делать пуш по окончании выполнения задачи(пофиксил багу, заимплементил фичу, зарефакторил код), также часто девелоперы при работе в группах, синхронизируют друг с другом свои локальные репозитории, минуя центральный(дабы не ломать билд неотлаженным кодом). Вот и получается, что на центральном сервере всегда находятся актуальные результаты работы всех девелоперов. Контролировать тут несложно — пока нет коммита в центральном репо- нет результата работы.
Контроллировать можно, не спорю. Ещё несколько преимуществ которые были актуальны пару лет назад, но не уверен что они и по сей день действуют:
1) блокировки. Например, можно залочить отдельный файл и другие разработчики не смогут с ним ничего делать. В DCVS этого не видел.
2) проблемы со сквозной нумерацией. В SVN очень просто сделать автоматическое проставление номера версии в билде. В DCVS с этим был гемморой, не знаю как сейчас… То же самое, если нужна связка номеров версий с багтрекером или вики системой.
3) ну и самое главное, имхо, попробуте доказать менеджменту необходимость перехода отлаженной инфрастуктуры сотни разработчиков с SVN на DCVS, это всё может вылится в солидную копеечку…
1) блокировки. Например, можно залочить отдельный файл и другие разработчики не смогут с ним ничего делать. В DCVS этого не видел.
2) проблемы со сквозной нумерацией. В SVN очень просто сделать автоматическое проставление номера версии в билде. В DCVS с этим был гемморой, не знаю как сейчас… То же самое, если нужна связка номеров версий с багтрекером или вики системой.
3) ну и самое главное, имхо, попробуте доказать менеджменту необходимость перехода отлаженной инфрастуктуры сотни разработчиков с SVN на DCVS, это всё может вылится в солидную копеечку…
Ну пункт 3, наверное — основная причина, почему до сих пор используется SVN :)
Вместо нумерации Mercurial предлагает уникальные хэши для каждой ревизии, также механизмы тегов, закладок и веток очень удобны для навигации по репозиторию.
Вместо нумерации Mercurial предлагает уникальные хэши для каждой ревизии, также механизмы тегов, закладок и веток очень удобны для навигации по репозиторию.
1) С блокировками, действительно, есть сложности — это плохо вписывается в идеологию распределённых систем контроля версий. К — счастью, они нужны далеко не всегда. Для правки обычного текста программ они просто не нужны. Для ресурсов, наверное, полезны, но на практике у нас сложностей не возникало.
2) Мне кажется, что нумерация сборок — прерогатива систем непрерывной интеграции (bamboo, ...). Они с этой работой справляются очень хорошо, и по необходимости ставят метки сборки. Это тем более важно, если для сборки нужно несколько разных репозиториев. Обычно инструменты багтрекинга, непрерывной интеграции и системы контроля версий хороши работают друг с другом. Связка bamboo + JIRA + git работает очень хорошо и удобно. Любой из этих компонент можно заменить на свой любимый
3) У нас инициатива исходила от менеджмента — избавиться от зоопарка систем контроля версий. Мы радостно поддержали.
2) Мне кажется, что нумерация сборок — прерогатива систем непрерывной интеграции (bamboo, ...). Они с этой работой справляются очень хорошо, и по необходимости ставят метки сборки. Это тем более важно, если для сборки нужно несколько разных репозиториев. Обычно инструменты багтрекинга, непрерывной интеграции и системы контроля версий хороши работают друг с другом. Связка bamboo + JIRA + git работает очень хорошо и удобно. Любой из этих компонент можно заменить на свой любимый
3) У нас инициатива исходила от менеджмента — избавиться от зоопарка систем контроля версий. Мы радостно поддержали.
Не соглашусь по поводу большей сохранности. В DCVS у каждого разработчика полная копия всего репозитория. То есть сколько разработчиков, столько и бэкапов.
А я не главное хранилище имел ввиду :) В DCVS сотрудник может вытянуть себе свежую версию и работать над своей локальной задачей. Он может работать над задачей длительное время (неделю или больше), при этом делая коммиты только в свой локальный репозиторий. И при сбое в его ПК потеряются результаты работы только одного человека. Вроде пустяк, но задачи бывают разной степени важности и иногда потеря одной недели работы именно этого человека может дорого обойтись…
Ну так этот человек при желании может отсылать свою работу в отдельную ветку в центральном репозитории, а потом в итоге смержить это дело с основной. Это очень удобно реализовано, поэтому неудобств не должно вызывать.
В том то и дело, что «при желании». DCVS предлагает разработчикам много свободы, и не везде это приветствуется. Захочу — сделаю коммиты в главное хранилище, не захочу — не сделаю. Такие проблемы придется решать административным путем и в результате может получится та же централизованная система, но только реализованная на DCVS. А стоит ли?
Стоит, ради удобства разработчиков. Полноценный репозиторий на локальной машине — это очень комфортно.
Я у себя даже самые маленькие скрипты и программы, которые никогда не появятся на каком-то публичном сервере — и те держу под Mercurial. Подробная история всех правок, отслеживание изменений в рабочем каталоге и всего один каталог .hg в корне вместо кучи .svn и отсутствие необходимости в каком-либо ПО для сервера.
При этом если я надумаю что-то из этого вылить в паблик — я в любой момент могу это легко сделать. Причём совершенно не обязательно использовать для этого сервер Hg (как на BitBucket или Google Code). Можно просто сделать каталог на удалённой машине и залить туда репозиторий по SSH. А под Windows можно даже организовать центральный репозиторий по Самбе, просто создав репозиторий в расшаренном каталоге. То есть даже вариантов организации центрального репозитория несколько — от самого примитивного в виде каталога по Самбе до продвинутых с полноценным разделением прав и т.д. Что-то меня занесло по этому поводу :)
Гибкость — это круто! Вот это я хотел сказать.
Я у себя даже самые маленькие скрипты и программы, которые никогда не появятся на каком-то публичном сервере — и те держу под Mercurial. Подробная история всех правок, отслеживание изменений в рабочем каталоге и всего один каталог .hg в корне вместо кучи .svn и отсутствие необходимости в каком-либо ПО для сервера.
При этом если я надумаю что-то из этого вылить в паблик — я в любой момент могу это легко сделать. Причём совершенно не обязательно использовать для этого сервер Hg (как на BitBucket или Google Code). Можно просто сделать каталог на удалённой машине и залить туда репозиторий по SSH. А под Windows можно даже организовать центральный репозиторий по Самбе, просто создав репозиторий в расшаренном каталоге. То есть даже вариантов организации центрального репозитория несколько — от самого примитивного в виде каталога по Самбе до продвинутых с полноценным разделением прав и т.д. Что-то меня занесло по этому поводу :)
Гибкость — это круто! Вот это я хотел сказать.
Захочу — сделаю коммиты в главное хранилище, не захочу — не сделаю.
Скажите это тысячам девелоперов которые хостятся на gihub. Конечно, я не буду коммитить в опенсурс проект свои локальные доработки, если они никому не нужны, кроме меня. А если все ок, то без проблем сделаю Pull request.
При разработке коммерческого проекта такое исключено, иначе уволят вмиг.
Такие проблемы придется решать административным путем и в результате может получится та же централизованная система, но только реализованная на DCVS. А стоит ли?
Разве это проблема, поднять сервер hg и сказать чтоб все туда пушились по завершению работы? У нас именно так и произошло, 4 года — полет отличный.
2) проблемы со сквозной нумерацией. В SVN очень просто сделать автоматическое проставление номера версии в билде. В DCVS с этим был гемморой, не знаю как сейчас… То же самое, если нужна связка номеров версий с багтрекером или вики системой.
В локальном репозитории, в который не совершаются коммиты, интовый номер head ревизии будет совпадать с номером head удаленного, из которого был сделан клон. Тоесть, после синхронизации репозиториев билдсервера с центральным репо, номера head ревизий будут совпадать. Не очень очевидно, и красиво, но проблем не вызывает. Девелопер делает пуш, сразу же получает email нотификейшен о коммите, из письма копирует номерок(удаленного репо) и использует его на багтрекере. Или же можно зайти через hgweb и там его посмотреть.
Мне сложно представить хотя бы одно преимущество у централизированных SCM по сравнению с распределенными. DVCS позволяет организовать работу как с централизованной системой (но не наоборот), но при этом лишена многих ее недостатков и имеет большое количество плюсов.
Чем больше читаю про DVCS, тем больше уверен в том, что пока нет смысла слазить с SVN. Все эти плюсы — это возможности, которые нужны единицам и в действительности для монструозных проектов с тысячами девелоперов и сотнями мэйнтейнеров. Просто многих накрыло модой — та же история, что и с NoSQL. Нереляционные базы появились задолго до реляционных и банковский сектор на них как сидел, так и сидит, но ввиду новой моды все повально ломанулись переписывать свои бложики и домашнюю бухию под NoSQL в ожидании меганагрузок, а потом выкладывают все эти чудотворения на GitHub, чтобы потом на этих бложиках размещать пузомерки по коммитам.
Когда я единственный менеджер и мэйнтейнер проекта, я должен знать о каждом телодвижении каждого разработчика. Если у меня централизованная система и отлаженные механизмы взаимодействия разработчиков, я не вижу ни одного плюса со стороны DVCS, но вижу сразу гору минусов. И архитектура централизованной системы контроля версий ничуть не ограничивает меня в выделении подпроектов, закрытых групп и песочниц.
Из основных плюсов:
1. Полный контроль над происходящим — я вижу все коммиты по факту, а не когда разработчик вспомнит и отсинхрится с головой.
2. Полный централизованный бэкап всего репозитория (у меня раз в час) — я не переживаю за потерянную работу в случае проблем с железом или софтом.
3. Сквозная нумерация версий — никакого разброда и шатания с хэшами, тегами, алиасами и иже с ними. Простая и всем понятная автоматическая последовательная нумерация.
4. Расширенные настройки доступа — могу в групповом и/или индивидуальном порядке давать и забирать доступ с гранулярностью до единичного файла.
5. Интеграция с тикет-треккерами — все коммиты в реальном времени отслеживаются и привязываются к тикетам.
6. Стройный процесс разработки — один разработчик — одна задача. Ситуация, описанная как пример к shelve/unshelve — это вообще тихий ужас. Нашёл ошибку — создай тикет и иди дальше. У кого будет время, тот за неё возьмётся. Возможно это вообще не ошибка, а «особенность» и её не исправили пока т.к. тянет за собой что-то. В любом случае не мешай мух с котлетами. Если же считаешь что именно тебе жизненноважно её исправить именно сейчас (punk way) и в рамках отдельной ветки — делай отдельную ветку, исправляй там, сливай в ствол и накатывая слитые изменения себе, либо накатишь их при слиянии в ствол.
7. Ну и самое главное — основной принцип «что попало в VCS, остаётся в VCS» соблюдается для централизованных, но не соблюдается для распределённых VCS, и это самое вопиющее нарушение самой первоначальной идеи «хранить всю историю всех правок всех разработчиков всех версий в одном месте с возможностью сравнить любые две точки».
И если в Mercurial ещё прослеживается забота о пользователе, то в git я ни логики ни эргономики не наблюдаю. Усложнённая архитектура, раздутая система команд и раздутые мозги разработчиков, занятые борьбой с системой контроля версий, а не решением поставленных задач. Из часовой лекции Линуса, посвящённой переходу на git, можно было вынести только один тезис: «все, кто пользуются централизованными системами — лохи, а у меня вот, например, коммит ядра в 20К файлов занимает пару секунд» — за час этот аргумент был повторен столько раз, что складывается ощущение, что его кто-то сильно обидел, и он пошёл маме жаловаться. Может те обидели, кто не захотел халявную лицензию на Perforce продлять? Я ничего не имею против Линуса, он делает большое дело, как и многие из OSS сообщества, но эти выпады на SVN по-детски смешные. Если не можешь организовать команду и подготовить инфраструктуру — это не проблема инструментов.
Когда я единственный менеджер и мэйнтейнер проекта, я должен знать о каждом телодвижении каждого разработчика. Если у меня централизованная система и отлаженные механизмы взаимодействия разработчиков, я не вижу ни одного плюса со стороны DVCS, но вижу сразу гору минусов. И архитектура централизованной системы контроля версий ничуть не ограничивает меня в выделении подпроектов, закрытых групп и песочниц.
Из основных плюсов:
1. Полный контроль над происходящим — я вижу все коммиты по факту, а не когда разработчик вспомнит и отсинхрится с головой.
2. Полный централизованный бэкап всего репозитория (у меня раз в час) — я не переживаю за потерянную работу в случае проблем с железом или софтом.
3. Сквозная нумерация версий — никакого разброда и шатания с хэшами, тегами, алиасами и иже с ними. Простая и всем понятная автоматическая последовательная нумерация.
4. Расширенные настройки доступа — могу в групповом и/или индивидуальном порядке давать и забирать доступ с гранулярностью до единичного файла.
5. Интеграция с тикет-треккерами — все коммиты в реальном времени отслеживаются и привязываются к тикетам.
6. Стройный процесс разработки — один разработчик — одна задача. Ситуация, описанная как пример к shelve/unshelve — это вообще тихий ужас. Нашёл ошибку — создай тикет и иди дальше. У кого будет время, тот за неё возьмётся. Возможно это вообще не ошибка, а «особенность» и её не исправили пока т.к. тянет за собой что-то. В любом случае не мешай мух с котлетами. Если же считаешь что именно тебе жизненноважно её исправить именно сейчас (punk way) и в рамках отдельной ветки — делай отдельную ветку, исправляй там, сливай в ствол и накатывая слитые изменения себе, либо накатишь их при слиянии в ствол.
7. Ну и самое главное — основной принцип «что попало в VCS, остаётся в VCS» соблюдается для централизованных, но не соблюдается для распределённых VCS, и это самое вопиющее нарушение самой первоначальной идеи «хранить всю историю всех правок всех разработчиков всех версий в одном месте с возможностью сравнить любые две точки».
И если в Mercurial ещё прослеживается забота о пользователе, то в git я ни логики ни эргономики не наблюдаю. Усложнённая архитектура, раздутая система команд и раздутые мозги разработчиков, занятые борьбой с системой контроля версий, а не решением поставленных задач. Из часовой лекции Линуса, посвящённой переходу на git, можно было вынести только один тезис: «все, кто пользуются централизованными системами — лохи, а у меня вот, например, коммит ядра в 20К файлов занимает пару секунд» — за час этот аргумент был повторен столько раз, что складывается ощущение, что его кто-то сильно обидел, и он пошёл маме жаловаться. Может те обидели, кто не захотел халявную лицензию на Perforce продлять? Я ничего не имею против Линуса, он делает большое дело, как и многие из OSS сообщества, но эти выпады на SVN по-детски смешные. Если не можешь организовать команду и подготовить инфраструктуру — это не проблема инструментов.
UFO just landed and posted this here
я должен знать о каждом телодвижении каждого разработчика
Зачем?
1. Грамотное распределение нагрузки между разработчиками
2. Нужно вовремя замечать что кто-то упёрся лбом в какую-то мелочь и бьётся головой об стенку. Поднимаем вопрос и решаем проблему коллективно за несколько минут вместо многочасового копания кода и/или доки.
Не ограничивает вас. Администратора. Интересно, сколько ваших подчинённых уже работают с репозиторием из hgsubversion или git-svn?
Ни одного.
У каждого в репозитории есть рабочий каталог в котором он что хочет, то и ворочает, единственное что рекомендовано соблюдать определённые стандарты в структуре каталогов и коментариях к коду. Плюс по первой просьбе создаются песочницы для экспериментов.
1. Everything comes with a price. Зато коммититься в оффлайне можно.
А зачем? Кто сейчас работает в оффлайне? Когда у самого удалённого сотрудника канал 5 мегабит, у основной массы 20-100, ну и плюс есть офис с рабочими местами (он к стати тоже не один). Кто в коммандировке — с корпоративным ноутом и с 3G. В каком веке было актуально работать в оффлайне?
2. Полный (Mercurial) или частичный (git) бэкап репозитория у каждого разработчика. При нуле (0) усилий с каждой стороны. И да, я правильно понимаю, что разворачивание бэкапа отлажено?
Полный бэкап у каждого, целостность которого никто не гарантирует.
Естесственно отлажено, иначе какой смысл?
3. У Mercurial — локальная последовательная нумерация, у bazaar — сквозная последовательная нумерация коммитов.
никакого разброда и шатания с хэшами, тегами, алиасами и иже с ними
Всё в кучу. Может, вы просто не владеете матчастью? Ну так потрудитесь изучить вопрос предварительно, что ли.
Кто-то указывает в доке и комментах хэш, кто-то присваивает алиас и указывает его, кто-то тегирует — я это имел ввиду. Наличие множества вариантов выполнить одно и то же действие гарантирует что оно-таки будет выполнено множествами способов, что усложняет читаемость доки в т.ч.
4. Соболезнования. Однако это не фича VCS, а фича вебсервера (бонус от использования WebDAV) — под svnserve вы так не сделаете. Олсо mercurial.selenic.com/wiki/AclExtension (да, оно менее гранулярно, но тем не менее), олсо хуки в конце концов.
На самом деле это уже детали реализации, кто именно рулит доступ, главное что его можно рулить, а без этого корпоративная среда инструмент не примет. За AclExtension спасибо, гляну.
5. А что сказать-то хотели? Хуки для интеграции обычно пишутся на счёт «раз», «сделать номера тикетов ссылками на них» — не задача системы контроля версий, а стороннего софта, с которой тот успешно справляется.
То что при центральном репозитории все коммиты в реальном времени ложатся в тот-же redmine (который и с Mercurial и с git тоже работает, но не видит локальных репозиториев разработчиков) и по каждой задаче виден прогресс. Это особенно актуально когда какой-то разработчик зависит от частичного выполнения какой-либо задачи, или у него сходная и ему интересно по-раньше увидеть альтернативное, чтобы начать делать своё.
6. А контроль версий тут при чём?
При том что централизированные системы контроля версий автоматически выстраивают большую часть процесса без необходимости применения каких-либо админитсративных мер. В распределённых же слишком демократичная среда. Они хорошо подходят для крупных OSS проектов, но не очень для мелких и средних корпоративных (для крупных уже дело в куса, там админмашина любую VCS переварит).
7. В Mercurial так и есть.
т.е. Вы хотите сказать что в Mercurial я в центральном репозитории вижу содержимое всех автономных репозиториев всех разработчиков? А какой толк тогда от распределённости, кроме как работа в оффлайне? И как быть с rebase? Можно такого накоммитить что потом чёрт ногу сломит, но правда это уже более админ вопрос, чем технический, но всё-же нехорошо что для создания проблем уже приготовлены инструменты.
Кернел тащемта никогда не лежал в Perforce.
Перепутал с BitKeeper. Линус в своей речи хвалил и его и Perforce, а детали уже подзабылись. Но факт остаётся фактом: «In April 2005, however, efforts to reverse-engineer the BitKeeper system by Andrew Tridgell led BitMover, the company which maintained BitKeeper, to stop supporting the Linux development community.» т.е. фактически git был написан впопыхах и как замена коммерческого инструмента, не из-за того что инструмент не устраивает, а из-за того что платить не хочется.
Если не можешь организовать команду и подготовить инфраструктуру — это не проблема инструментов.
Вот слово в слово речь фанбоев Git.
Да, но в DVCS нужно ограничивать людей чтобы получить стройную систему, а любые ограничения психологически давят и регулярно нарушаются. В централизованных же системах ограничения уже есть из коробки, они архитектурные, и тут наоборот — мы выстраиваем модель так, чтобы дать разработчикам дополнительные возможности, и этот подход куда приятней людям и тут не стоит вопрос «нарушить или не нарушать», тут стоит «пользуемся удобствами или нет» — улавливаете разницу? Инструмент не решает изолированную проблему, он призван помогать решать круг задач, и я за тот, который решает эти задачи органичней.
1. Вижу связь с организацией процесса разработки, который может быть построен в DVCS таким образом, что различия останутся только в терминологии: push в центральный/интеграционный репозиторий vs. commit
2. Центральный/интеграционный репозиторий обязан бекапится (и бекапится) ответственными за это людьми
3. Думаю, что нумерация сборок — прерогатива системы Contionuous Integration. В этом случае система нумерации не играет большой роли, особенно когда в сборке участвуют несколько репозиториев.
5. Нужная вещь, с которой у всех современных VCS всё в порядке. Например, JIRA + git замечательно интегрируются
6. Опять же, описанное скорее особенность организации процесса разработки. VCS (svn/hg/git) это лишь инструмент, который позволяет позволяет не тратить особых усилий на его поддержку.
7. История опубликованная в центральном репозитории не меняется никогда.
> то в git я ни логики ни эргономики не наблюдаю
Уверен, опыт практического использования способен изменить эту точку зрения.
Базовое использование git тривиально такое же как и svn/hg. Продвинутая работа с ветками мне кажется даже проще в git, чем в hg, но это дело вкуса.
> 4. Расширенные настройки доступа — могу в групповом и/или индивидуальном порядке давать и забирать доступ с гранулярностью до единичного файла.
Это, действительно, интересно. Мы эту задачу решаем распределением прав доступа к веткам/репозиториям. В свою бытность работы с централизованными VCS делали также — не использовали ограничения прав на уровне файлов. Иногда сталкивались с проблемой случайных ошибочных прав доступа на уровне файлов.
2. Центральный/интеграционный репозиторий обязан бекапится (и бекапится) ответственными за это людьми
3. Думаю, что нумерация сборок — прерогатива системы Contionuous Integration. В этом случае система нумерации не играет большой роли, особенно когда в сборке участвуют несколько репозиториев.
5. Нужная вещь, с которой у всех современных VCS всё в порядке. Например, JIRA + git замечательно интегрируются
6. Опять же, описанное скорее особенность организации процесса разработки. VCS (svn/hg/git) это лишь инструмент, который позволяет позволяет не тратить особых усилий на его поддержку.
7. История опубликованная в центральном репозитории не меняется никогда.
> то в git я ни логики ни эргономики не наблюдаю
Уверен, опыт практического использования способен изменить эту точку зрения.
Базовое использование git тривиально такое же как и svn/hg. Продвинутая работа с ветками мне кажется даже проще в git, чем в hg, но это дело вкуса.
> 4. Расширенные настройки доступа — могу в групповом и/или индивидуальном порядке давать и забирать доступ с гранулярностью до единичного файла.
Это, действительно, интересно. Мы эту задачу решаем распределением прав доступа к веткам/репозиториям. В свою бытность работы с централизованными VCS делали также — не использовали ограничения прав на уровне файлов. Иногда сталкивались с проблемой случайных ошибочных прав доступа на уровне файлов.
3. Думаю, что нумерация сборок — прерогатива системы Contionuous Integration. В этом случае система нумерации не играет большой роли, особенно когда в сборке участвуют несколько репозиториев.
Не совсем то. Тут не номера сборок, а номера коммитов. Например: разработчик может работать над сложной и длинной задачей, но в этой задаче есть подзадача, которую в чистом виде выделять смысла нет, но от её исхода зависит реализация других задач. Так вот этот разработчик может сделать коммит, а в треккере написать: «в коммите #такой-то есть то что вы искали», или: «эта задача решалась на коммитах #а-#б» и все заинтересованные лица получат доступ к требуемой инфе раньше, а это ускоряе процесс. Ну и для указания ошибок в ходе разработки тоже удобней указывать номер коммита.
Понятно. У нас в таких случаях принято указывать номер ночной сборки, или ссылку на страницу сборки. Если дело срочное, то обычно указывается хеш коммита с упоминанием в какой ночной сборке этот коммит появится.
В целом соглашусь, что сплошная нумерация была бы приятным бонусом; здесь она «достигается» внешним образом через привязку к версии сборки.
В целом соглашусь, что сплошная нумерация была бы приятным бонусом; здесь она «достигается» внешним образом через привязку к версии сборки.
Sign up to leave a comment.
Переход на DVCS, Mercurial