Писал для коллег — программистов, далёких от предметной области, которые действительно, искренне не понимали, что такого сложного в базе данных. Они хотели хранить критические данные в простых файлах. Я задавал им каверзные вопросы о надёжности, скорости и одновременном доступе, они пытались «на ходу» придумать хитрые решения. В конце они трезво оценили требуемый объём кода и поняли, что им придётся написать свой маленький ORACLE или, хотя бы, MySQL. Затем я рассказал им, как были решены эти проблемы в DB ORACLE, их поразило изящество некоторых алгоритмов. Лекция понравилась, и я решил выложить её в открытый доступ.
Кто не хочет читать теорию – в конце пара ключевых моментов, которые должен знать каждый разработчик, работающий с ORACLE. Языком SQL он может и не владеть, но особенности COMMIT’а знать обязан.
Для DBA и прочих знатоков (в хорошем смысле) — материал сознательно максимально упрощён, за счёт этого есть некоторые неточности. Цель была – передать основные принципы неподготовленному человеку.
Вначале был файл и были таблицы с записями фиксированной длинны.
Всё просто – новые записи добавлялись в существующие «дырки» в середину файла вместо удалённых, если «дырок» нет – в конец.
Быстро, но много места приходится резервировать на всякий случай, для редких, уникальных данных. Так, один известный испанец имеет имя «Пабло Диего Хозе Франциско де Паула Хуан Непомукено Криспин Криспиано де ла Сантисима Тринидад Руиз и Пикассо» — соответственно, поле ФИО придётся делать с большим запасом.
И никаких длинных описаний или примечаний из нескольких предложений.

При добавлении таких строк в конец файла нет никаких проблем, а вот при вставке в середину файла взамен удалённых и изменении данных внутри строк (в описание товара добавили пару предложений) появляются проблемы. Решение давно придумано разработчиками файловых систем и менеджеров памяти – хранить данные блоками, когда данные «расползаются» по нескольким блокам – проводить дефрагментацию. Кроме того, ORACLE позволяет при создании блока оставлять там пустое пространство для будущих изменений, на случай, если длинна новой записи увеличится.
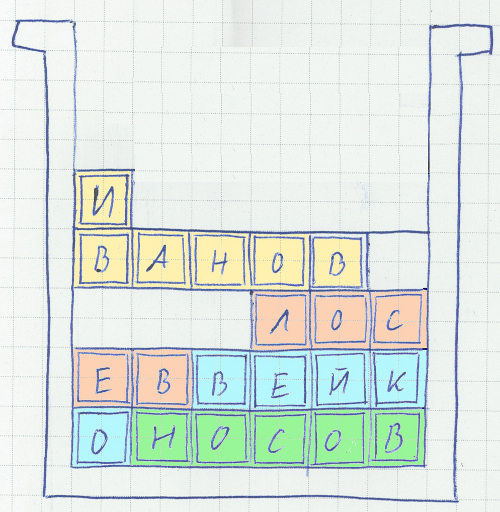
Когда добавили функционал – скорость сильно упала. На дефрагментацию уходит много ресурсов, её приходится ограничивать. В результате многие записи оказались «размазаны» по блокам, и, что самое плохое, эти блоки могут физически находиться в разных частях жёсткого диска. Очевидное решение — кэширование в буферном КЭШе — спасает ситуацию при чтении. При фиксации изменений все данные должны быть записаны на диск (когда речь идёт о критичных приложениях нельзя надеяться на UPS), причём желательно не один, а на несколько, для резервирования. Причём диски должны быть логическими, резервирование исключительно средствами RAID не подойдёт, ибо, в случае смерти контроллера на свалку может отправиться весь массив. А пользователи, кроме того, не желают дублировать файлы данных на сервере – серверные диски стоят очень дорого.

Выход был найден — создан – redo лог, лог повторного выполнения. После изменения данных в кэше в этот файл последовательно записываются все новые и измененные данные. Если выделить для этой задачи отдельный диск (а лучше несколько на разных контроллерах) – головка не будет прыгать, а скорость последовательной записи у дисков высокая. Обратим внимание на изящность решения – все изменения пишутся в лог сразу, не дожидаясь фиксации транзакции. COMMIT лишь проставляет ключевой маркер, что занимает доли секунды. В случае отката тразакции информация об изменениях по прежнему остаётся в лог файле, но завершается она меткой отката.
А как же файлы данных? Периодически запускается процесс, находящий в буфером кэше изменённые, так называемые «грязные» блоки и записывающий их на диск. За счёт «оптовой» обработки повышается скорость, и время реакции системы.
Чтобы размер логов повторного выполнения не увеличивался до бесконечности, используется ротация логов. ORACLE следит, чтобы при циклической смене лог файлов все «грязные» блоки попали в файлы данных.
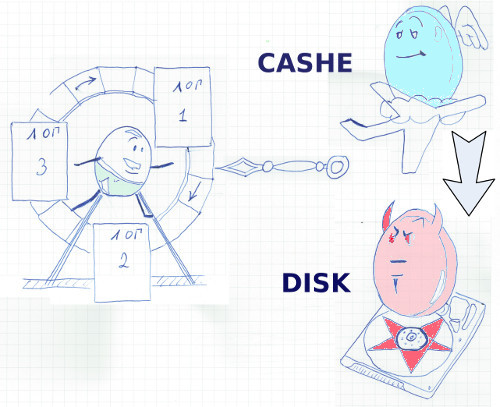
Из этой схемы вытекает неочевидная с первого взгляда особенность, поразившая меня в своё время до глубины души. Что делать с изменёнными блоками, которые не подтверждены COMMIT”ом, но уже не помещаются в буферный кэш? Писать изменения во временный файл? Нет, ORACLE пишет эти изменения сразу в фалы данных. Да, в системе, изначально ориентированной на повышенную надёжность файлы данных могут содержать неконсистентные, не зафиксированные COMMIT”ом данные, и это нормально, это часть рабочего процесса. Вместо этого СУБД делает резервную копию изменённых блоков в специальных UNDO файлах. Здесь этот резерв сохраняется до фиксации транзакции, и позволяет другим транзакциям читать данные во время того, как другая транзакция их меняет. Да, в ORACLE изменения не блокируют чтение. Это основы, но многие прикладные разработчики с удивлением узнают об этой особенности.
И – все UNDO изменения также записываются в лог повторного выполнения.
Таким образом, лог повторного выполнения содержит информацию обо всех добавленных данных, а также данные до и после изменения. Эти логии очень важны, только с помощью них можно привести фалы данных в корректное, согласованное состояние. ORACLE рекомендует дублировать логии повторного выполнения на разных дисках
Если перед циклической перезаписью следующего лог-файла повторного выполнения копировать его на другой носитель или сервер, можно получить следующие плюшки.
1. Простой бэкап – достаточно делать полную копию файлов данных, например, раз в сутки, а в остальное время лишь сохранять логи.
2. Резервный сервер – дальнейшее развитие идеи. Логи накатываются на копию БД, развёрнутой на резервном сервере, по мере их поступления. При наступлении часа Х обработка данных переключается на резервный сервер.
3. Запросы в прошлое – можно посмотреть данные таблицы, какие они были, например, полтора часа назад. И это можно делать на рабочей базе, не надо «поднимать» никаких резервных копий.
Возвращась к заголовку: что же произойдёт при внезапном отключении электричества? Ведь данные в файлах останутся в несогласованном состоянии? Ничего страшного.
Рассмотрим пример: после последней успешной записи в файл БД (время 1) система подтвердила 1 танзакцию (время 2), затем начала выполнять 2-ю, прямо во время записи в файл БД выключается питание (время 3).
Итак, сервер снова заработал. Система читает лог повторного выполнения с момента последней успешной записи на диск (со времени 1) и откатывает все изменения. Для этого в логе есть вся необходимая информация. Затем система последовательно повторяет все операции (накат). Находит метку COMMITа (сделанную во время 2) и выполняет фиксацию изменений. Затем продолжает накат. Доходит до конца лога повторного выполнения (на этой временной точке -3 — отключилось питание) и не находит метку COMMITа. Вновь выполнятся откат, но уже к точке (время 2).
Данные вновь в согласованном состоянии!
Да, вся эта информации полезна, но на что должны обратить внимание разработчики?
• Первый неочевидный момент — в отличие от других СУБД в ORACLE частый COMMIT вреден. При поступлении этой команды информация, пусть и в небольшом количестве, должна быть записана на диск. Этот процесс происходит максимально быстро, но если пытаться выполнять его после изменения каждой записи для 10 миллионной таблицы… Система сконструирована таким образом, чтобы делать COMMIT тогда, когда это необходимо с точки зрения бизнес-логики, а не чаще.
Отката же транзакции (ROLLBACK) нужно по мере сил избегать, как правило, врем на откат часто сравнимо со временем изменений. UPDATE выполнялся час, решили откатить, ROLLBACK тоже будет выполняться сравнимое время. А коммит бы «прошёл» за долю секуды.
• Второй момент, почему-то неочевидный для многих разработчиков — изменение данных никогда не блокируют чтение. Это нужно запомнить, а вообще реализация одновременного доступа к данным с точки зрения разработчика требует отдельной статьи.
• Третий момент – не бойтесь join’ов, это не ущербный MySQL. Правильно настроенная база позволит поддерживать и целостность данных, и производительность. HASH JOUN, MERGE JOIN, INDEX ORGANISED TABLES, настройка CARDINALITY, QUERY REWRITING и MATRIALISED VIEW UPDATE ON COMMIT позволят знающему админу добиться хорошей скорости. А вот поддерживать неконсистентную денормализованную систему в порядке через пару лет будет на порядок сложнее.
• И напоследок – используйте связанные переменные! Это позволит разом значительно, часто в несколько раз увеличить производительность и, как бесплатный бонус, избежать SQL!

Вывод – ORACLE создал надёжную СУБД, но, насколько она будет быстро работать, зависит от разработчиков. Неоптимальные решения заставят любой сервер просить пощады.
Кто не хочет читать теорию – в конце пара ключевых моментов, которые должен знать каждый разработчик, работающий с ORACLE. Языком SQL он может и не владеть, но особенности COMMIT’а знать обязан.
Для DBA и прочих знатоков (в хорошем смысле) — материал сознательно максимально упрощён, за счёт этого есть некоторые неточности. Цель была – передать основные принципы неподготовленному человеку.
Вначале был файл и были таблицы с записями фиксированной длинны.
Всё просто – новые записи добавлялись в существующие «дырки» в середину файла вместо удалённых, если «дырок» нет – в конец.
Быстро, но много места приходится резервировать на всякий случай, для редких, уникальных данных. Так, один известный испанец имеет имя «Пабло Диего Хозе Франциско де Паула Хуан Непомукено Криспин Криспиано де ла Сантисима Тринидад Руиз и Пикассо» — соответственно, поле ФИО придётся делать с большим запасом.
И никаких длинных описаний или примечаний из нескольких предложений.
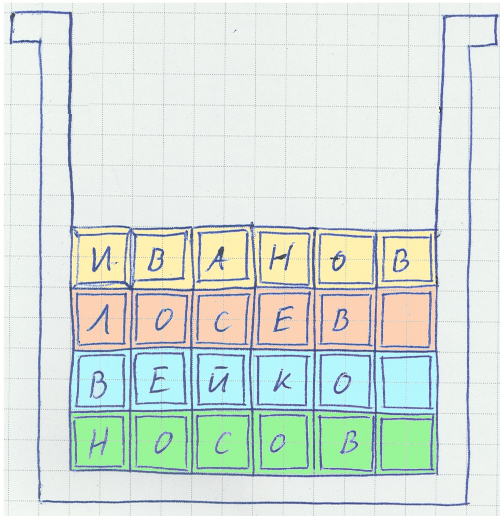
При добавлении таких строк в конец файла нет никаких проблем, а вот при вставке в середину файла взамен удалённых и изменении данных внутри строк (в описание товара добавили пару предложений) появляются проблемы. Решение давно придумано разработчиками файловых систем и менеджеров памяти – хранить данные блоками, когда данные «расползаются» по нескольким блокам – проводить дефрагментацию. Кроме того, ORACLE позволяет при создании блока оставлять там пустое пространство для будущих изменений, на случай, если длинна новой записи увеличится.
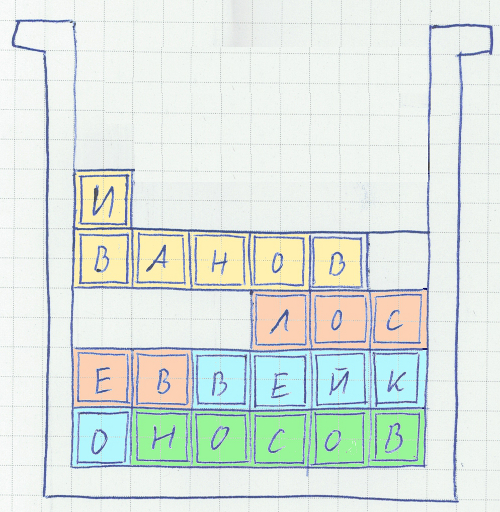
Когда добавили функционал – скорость сильно упала. На дефрагментацию уходит много ресурсов, её приходится ограничивать. В результате многие записи оказались «размазаны» по блокам, и, что самое плохое, эти блоки могут физически находиться в разных частях жёсткого диска. Очевидное решение — кэширование в буферном КЭШе — спасает ситуацию при чтении. При фиксации изменений все данные должны быть записаны на диск (когда речь идёт о критичных приложениях нельзя надеяться на UPS), причём желательно не один, а на несколько, для резервирования. Причём диски должны быть логическими, резервирование исключительно средствами RAID не подойдёт, ибо, в случае смерти контроллера на свалку может отправиться весь массив. А пользователи, кроме того, не желают дублировать файлы данных на сервере – серверные диски стоят очень дорого.
Выход был найден — создан – redo лог, лог повторного выполнения. После изменения данных в кэше в этот файл последовательно записываются все новые и измененные данные. Если выделить для этой задачи отдельный диск (а лучше несколько на разных контроллерах) – головка не будет прыгать, а скорость последовательной записи у дисков высокая. Обратим внимание на изящность решения – все изменения пишутся в лог сразу, не дожидаясь фиксации транзакции. COMMIT лишь проставляет ключевой маркер, что занимает доли секунды. В случае отката тразакции информация об изменениях по прежнему остаётся в лог файле, но завершается она меткой отката.
А как же файлы данных? Периодически запускается процесс, находящий в буфером кэше изменённые, так называемые «грязные» блоки и записывающий их на диск. За счёт «оптовой» обработки повышается скорость, и время реакции системы.
Чтобы размер логов повторного выполнения не увеличивался до бесконечности, используется ротация логов. ORACLE следит, чтобы при циклической смене лог файлов все «грязные» блоки попали в файлы данных.
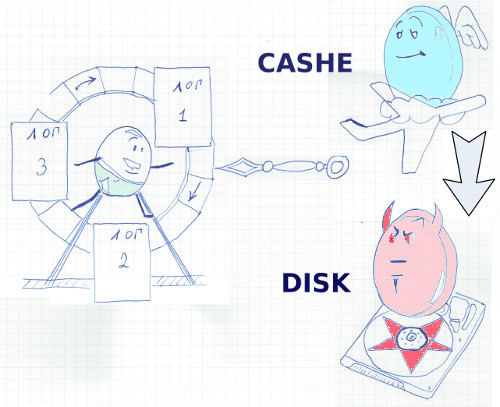
Из этой схемы вытекает неочевидная с первого взгляда особенность, поразившая меня в своё время до глубины души. Что делать с изменёнными блоками, которые не подтверждены COMMIT”ом, но уже не помещаются в буферный кэш? Писать изменения во временный файл? Нет, ORACLE пишет эти изменения сразу в фалы данных. Да, в системе, изначально ориентированной на повышенную надёжность файлы данных могут содержать неконсистентные, не зафиксированные COMMIT”ом данные, и это нормально, это часть рабочего процесса. Вместо этого СУБД делает резервную копию изменённых блоков в специальных UNDO файлах. Здесь этот резерв сохраняется до фиксации транзакции, и позволяет другим транзакциям читать данные во время того, как другая транзакция их меняет. Да, в ORACLE изменения не блокируют чтение. Это основы, но многие прикладные разработчики с удивлением узнают об этой особенности.
И – все UNDO изменения также записываются в лог повторного выполнения.
Таким образом, лог повторного выполнения содержит информацию обо всех добавленных данных, а также данные до и после изменения. Эти логии очень важны, только с помощью них можно привести фалы данных в корректное, согласованное состояние. ORACLE рекомендует дублировать логии повторного выполнения на разных дисках
Если перед циклической перезаписью следующего лог-файла повторного выполнения копировать его на другой носитель или сервер, можно получить следующие плюшки.
1. Простой бэкап – достаточно делать полную копию файлов данных, например, раз в сутки, а в остальное время лишь сохранять логи.
2. Резервный сервер – дальнейшее развитие идеи. Логи накатываются на копию БД, развёрнутой на резервном сервере, по мере их поступления. При наступлении часа Х обработка данных переключается на резервный сервер.
3. Запросы в прошлое – можно посмотреть данные таблицы, какие они были, например, полтора часа назад. И это можно делать на рабочей базе, не надо «поднимать» никаких резервных копий.
Возвращась к заголовку: что же произойдёт при внезапном отключении электричества? Ведь данные в файлах останутся в несогласованном состоянии? Ничего страшного.
Рассмотрим пример: после последней успешной записи в файл БД (время 1) система подтвердила 1 танзакцию (время 2), затем начала выполнять 2-ю, прямо во время записи в файл БД выключается питание (время 3).
Итак, сервер снова заработал. Система читает лог повторного выполнения с момента последней успешной записи на диск (со времени 1) и откатывает все изменения. Для этого в логе есть вся необходимая информация. Затем система последовательно повторяет все операции (накат). Находит метку COMMITа (сделанную во время 2) и выполняет фиксацию изменений. Затем продолжает накат. Доходит до конца лога повторного выполнения (на этой временной точке -3 — отключилось питание) и не находит метку COMMITа. Вновь выполнятся откат, но уже к точке (время 2).
Данные вновь в согласованном состоянии!
Да, вся эта информации полезна, но на что должны обратить внимание разработчики?
• Первый неочевидный момент — в отличие от других СУБД в ORACLE частый COMMIT вреден. При поступлении этой команды информация, пусть и в небольшом количестве, должна быть записана на диск. Этот процесс происходит максимально быстро, но если пытаться выполнять его после изменения каждой записи для 10 миллионной таблицы… Система сконструирована таким образом, чтобы делать COMMIT тогда, когда это необходимо с точки зрения бизнес-логики, а не чаще.
Отката же транзакции (ROLLBACK) нужно по мере сил избегать, как правило, врем на откат часто сравнимо со временем изменений. UPDATE выполнялся час, решили откатить, ROLLBACK тоже будет выполняться сравнимое время. А коммит бы «прошёл» за долю секуды.
• Второй момент, почему-то неочевидный для многих разработчиков — изменение данных никогда не блокируют чтение. Это нужно запомнить, а вообще реализация одновременного доступа к данным с точки зрения разработчика требует отдельной статьи.
• Третий момент – не бойтесь join’ов, это не ущербный MySQL. Правильно настроенная база позволит поддерживать и целостность данных, и производительность. HASH JOUN, MERGE JOIN, INDEX ORGANISED TABLES, настройка CARDINALITY, QUERY REWRITING и MATRIALISED VIEW UPDATE ON COMMIT позволят знающему админу добиться хорошей скорости. А вот поддерживать неконсистентную денормализованную систему в порядке через пару лет будет на порядок сложнее.
• И напоследок – используйте связанные переменные! Это позволит разом значительно, часто в несколько раз увеличить производительность и, как бесплатный бонус, избежать SQL!

Вывод – ORACLE создал надёжную СУБД, но, насколько она будет быстро работать, зависит от разработчиков. Неоптимальные решения заставят любой сервер просить пощады.
