Comments 118
Так это из-за Вас теперь сраная рекапча, которую раза с 5 получается угадать? Ну спасибо.
Если бы. Я начал писать пост уже где-то пол года назад, никак не хватало времени дописать. А тут, недавно зашел на сайт и увидел что уже рекапча стоит, поэтому и решил, что если уж и публиковать так сейчас.
У меня в памяти сразу всплыла история с предпредыдущей капчей Хабра. Автор тоже изложил алгоритм распознавания, после чего незамедлительно получил бан и капча была изменена. Ваше счастье, drozdVadym!
Хм, может это случилось когда еще действовала и кто то мог воспользоваться такой возможностью, а тут автор написал пост после того как ее уже заменили?!
П.с не слышал про эту историю.
П.с не слышал про эту историю.
Ссылка на лурк.
которую раза с 5 получается угадать?Если ее вообще возможно разгадать. Мне, например, сегодня хабр подсунул такую вот рекапчу:
Скрытый текст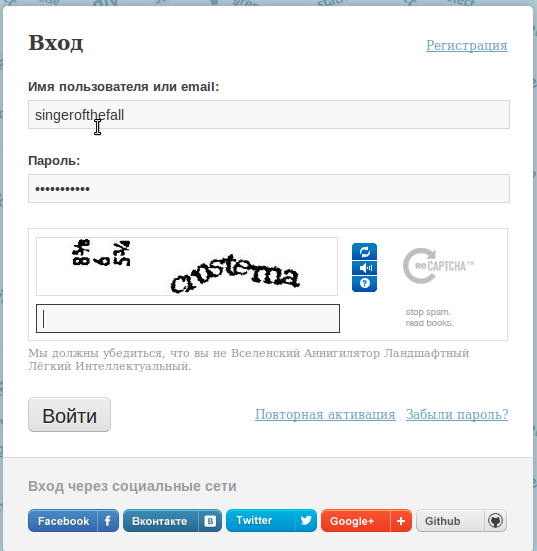

Не очень хорошо распознаются прописные r, n и m. Толи crnsterna толи cmstema. Первое слово не обязательно распознавать.
Не очень хорошо распознаются прописные r, n и m.
То есть дроби «восемь целых пять шестых» и «пять целых три (то ли шестых, то ли восьмых)», повернутые на 90 градусов, в качестве первого слова, вас не смущают?)
Первое слово не обязательно распознавать.Но ведь очень хочется!
А разве там не 'crostema'? =)
Первое слово не обязательно распознавать?..
Где Вы были раньше? :(
Где Вы были раньше? :(
В reCaptcha подсовывают слова из отсканированных книг. Одно слово, которое уже распознано, а второе — которое еще не распознано. По распознанному слову отсекают ботов, а распознавая нераспознанное слово, пользователь помогает оцифровывать книги. Так что да — вместо слова, которое невозможно распознать, можно написать что угодно.
Заметил, что если в слове на рекапче есть знак препинания, то это слово можно вообще не вводить.
Специально для Вас.

Одн из слов контрольное, второе — вы вводите что видите и помогаете распознавать книги
А где эти книги потом можно бесплатно получить?
Google Books…
А так же www.gutenberg.org
А так же www.gutenberg.org
Это еще что. Иногда, когда не можешь долго угадать, рекапча еще и издевается.
Скрытая картинка

Inglip has been summoned. It has begun.
Капчу поменяли после того, как мне в ЛС продемонстрировали слабую устойчивость текущей капчи — там был несколько другой алгоритм работы, но тем не менее, работал. Так что теперь рекапча, а входить на сайт по-прежнему удобней и быстрей всего через привязку аккаунта к социальным сетям.
UFO just landed and posted this here
Можно привязать к аккаунту социалку и через неё входить без всяких капч.
Люблю подобные статьи с точки зрения подходов к проблеме и её решению. Спасибо за старания :)
Этот алгоритм угадывает каптчи лучше чем я :(
UFO just landed and posted this here
Почему то на ваш комментарий вспомнилось )
P.S. хабр картинку съел почему то…
twipic2.s3.amazonaws.com/15763418/3_4003.jpg
P.S. хабр картинку съел почему то…
twipic2.s3.amazonaws.com/15763418/3_4003.jpg
{kind=link}
Если статья понравилась, в следующей могу подробно рассказать о основных подходах к распознаванию человеческого лица.
да! в карму плюсанул, за пост проголосовал, с тебя статья -)
А зачем вообще нужна капча на входе в хабр?
Может быть для того, чтобы было сложнее брутфорсить пароли? Тут все таки закрытая регистрация и увод аккаунта может быть даже выгоден с точки зрения финансов.
Чтобы нельзя было пройтись по всем пользователям на предмет паролей, угадывающихся с первой попытки.
UFO just landed and posted this here
Даешь взлом рекапчи, что бы на Хабр можно было зайти с 10-й попытки!
А если серьезно, то сколько времени заняла эта работа?
А если серьезно, то сколько времени заняла эта работа?
Изначально набросал алгоритм и код в Matlab где-то за 3 часа, но точность была 25-30%, много времени заняло ручное распознавание каптчи (честно, не засекал сколько). Потом начал оптимизировать, даже начал переписывать на C c использованием OpenCV, но закинул, в связи с дипломом и поступлением в магистратуру. Неделю назад вспомнил, что-то исправил, привел код к лучшему виду (хотя и сейчас он мне не особо нравиться) и опубликовал. Если считать суммарное количество времени на реализацию — где-то 20 часов.
О, а я когда-то через OpenCV это делал. Серый шум, кажется, убирался вот так 1 строчкой на Python'е:
Получалось примерно так:
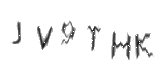
(Точной картинки сейчас нет, но выглядела она как-то так)
Потом по контурам легко находим символы и…
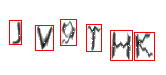
… и нейронная сеть рулит :-)

cv.Threshold(image, image, 100, 255, cv.CV_THRESH_OTSU)Получалось примерно так:

(Точной картинки сейчас нет, но выглядела она как-то так)
Потом по контурам легко находим символы и…

… и нейронная сеть рулит :-)

Вот никогда не понимал, зачем на капчах делают шум, который мешает пользователю, а для ботов никакой сложности не представляет. Гораздо лучше, по-моему, использовать противоположные эффекты и способности мозга к распознаванию образов обыкновенных знакомых слов.
Что-то вроде такого (свободная импровизация, без искажений букв):

Глазами это прочесть не составит труда. Прост ли будет алгоритм её распознавания?
Что-то вроде такого (свободная импровизация, без искажений букв):

Глазами это прочесть не составит труда. Прост ли будет алгоритм её распознавания?
Капча с искажениями генерируется автоматически, когда вы придумаете как сгенерировать то что у вас в примере — вы автоматически решите и обратную задачу :) А простые подходы вроде «нарисовать все буквы 1 раз и переставлять местами» взламываются и без всяких нейросетей.
То, что в примере генерируется элементарно:
1. Рисуем слово чёрным поверх серого фона, накладывая слегка искаженные буквы краями друг на друга.
2. Рисуем то же самое белым, со смещением на 2 пикселя вверх и влево.
3. Рисуем то же самое цветом фона, со смещением на 1 пиксель вверх и влево относительно п 1.
4. Добавляем случайные кляксы цветом фона, чтобы усложнить задачу поиска контуров.
Эту информацию можно как-то использовать для распознавания данного примера?
1. Рисуем слово чёрным поверх серого фона, накладывая слегка искаженные буквы краями друг на друга.
2. Рисуем то же самое белым, со смещением на 2 пикселя вверх и влево.
3. Рисуем то же самое цветом фона, со смещением на 1 пиксель вверх и влево относительно п 1.
4. Добавляем случайные кляксы цветом фона, чтобы усложнить задачу поиска контуров.
Эту информацию можно как-то использовать для распознавания данного примера?
Вот такую капчу расшифровать очень сложно будет. Надо подумать — и над использованием, и над алгоритмом. Спасибо!
UFO just landed and posted this here
Да, лучше несколько понятных слов, чем случайный набор букв. Угол тени определить легко, она тут для удобства восприятия. Дополнительный шрифт, на мой взгляд, слегка повысит стойкость, но осложнит задачу пользователю. Дополнительную стойкость, тоеоретически, можно получить искажением контура, вращением букв на небольшой угол и смещением их по вертикали. Так может быть сложнее выделить из неё отдельные буквы.
Есть ощущение, что без деформаций это разгадывается элементарным алгоритмом. Нужно просто брать буквы не во всю ширину.

На базе этого делаем шаблоны, потом простейший поиск этих шаблонов. Получается очень просто взломать.
Хотя сама идея классная, да.

На базе этого делаем шаблоны, потом простейший поиск этих шаблонов. Получается очень просто взломать.
Хотя сама идея классная, да.
Прокомментировать чуть подробнее код (в частности, интересна findSubRects) можете? А то сразу не получилось понять :)
когда количество найденных прямоугольников меньше чем нужно найти, мы делаем предположение, что некоторые символы склеены, потом с помощью сравнений площадей определяем необходимое количество прямоугольников, которое нужно найти на части изображения, и вызываем findSubRects .
В самой findSubRects делим картинку на нужное количество прямоугольников по заданным координатам.
Потом в каждом из полученных прямоугольников ищем наибольшую связанную область.
Код не инвариантен, и на самом деле дал не очень большой прирост качества распознавания.
Постараюсь потом прокомментировать все спорные участки кода, о обновлю листинг.
В самой findSubRects делим картинку на нужное количество прямоугольников по заданным координатам.
Потом в каждом из полученных прямоугольников ищем наибольшую связанную область.
Код не инвариантен, и на самом деле дал не очень большой прирост качества распознавания.
Постараюсь потом прокомментировать все спорные участки кода, о обновлю листинг.
«Как оказалось каптча не очень сложная и легко поддается взлому.» – чудесно!
Вообще капча — уходящий век. Есть масса способов отделить роботов от человека, просто капчу, видимо, проще всего прикрутить.
Есть масса способов отделить роботов от человека
А поподробней?

Галерею картинок придётся всё время обновлять, так что очень непрактично. Да и тупо выбирая картинки наугад каждый 84-й раз вы будете правильно опознавать котят.
Зачем же самим напрягаться? www.flickr.com/search/?q=kittens
Не, ну фотки там, конечно, прикольные, но не всегда понятно, где там котята.
О, вариант то хороший. Только вот я уже представляю, как мои родители с нулевым знанием английского будут искать какого-нибудь «розовато-лилового бурундучка». Да и самому как то попадалась капча, в которой требовалось найти (вроде) какой то определенный цветок, о котором я разве что только слышал.
У меня для вас и ваших пользователей бесплатное решение: напишите сверху «Выберите 3 картинки с котятами». И даже не благодарите.
Я люто ненавижу распознавать такие капчи, это хуже любого текста.
UFO just landed and posted this here
Все пропало — harthur.github.com/kittydar/
Тут надо статью писать. В паре предложений не уложиться.
> Как оказалось каптча не очень сложная и легко поддается взлому.
> Количество правильно распознанных каптч: 49.17 %
А если мой алгоритм объединить с вашей нейронной сетью, то получится отличный онлайн-OCR. Красивая тема :-)
Да, осталось придумать, кому и зачем нужна онлайн-OCRка…
> Количество правильно распознанных каптч: 49.17 %
А если мой алгоритм объединить с вашей нейронной сетью, то получится отличный онлайн-OCR. Красивая тема :-)
Да, осталось придумать, кому и зачем нужна онлайн-OCRка…
Альтернатива какому-нибудь antigate? Хотя, не думаю, что _онлайн_ OCR сейчас кого-нибудь заинтересует. И antigate и ваша онлайн OCR — оба будут иметь проблемы с производительностью (т.к. оба — сторонние сервисы), при этом antigate всегда будет распознавать лучше, т.к. там куча народу разгадывает картинки вручную за копейки. Для спама больше подходит распознавалка, работающая на той же машине, что и бот.
Альтернатива FineReader? Тоже нет, т.к. алгоритма распознавания однотипной капчи недостаточно для распознавания разных-разных документов.
Альтернатива FineReader? Тоже нет, т.к. алгоритма распознавания однотипной капчи недостаточно для распознавания разных-разных документов.
Есть же онлайн OCR-ка pixodrom. Но там кажется люди распознают.
а рекаптчу никто не пробовал распознавать нейронными сетями?
По мне так эту рекапчу только боты умеют хорошо разбирать. Был у меня сайт с рекапчей и она ни коим образом не помогла в борьбе с автоматическими регистрациями
А она ведь еще кое-где есть на Хабре! habrahabr.ru/info/advertising/workshops/
А что автор скажет про

Сами буквы без искажений, никаких поворотов, только искривление всего изображения. Разумеется, сетка для отладочных целей.
Сами буквы без искажений, никаких поворотов, только искривление всего изображения. Разумеется, сетка для отладочных целей.
Я понял, что там написано, только после очень вдумчивого разглядывания.
даже последний вариант, где линии гладкие?
Если бы добавить немного антиалиасинга, хотя бы x4 (а лучше x8, т.к. у вас довольно сильные искажения), то было бы уже лучше — как минимум в последнем варианте. Первый из трех вообще нечитаем, у второго нечитаемы отдельные буквы, если их «раздувает» так, что они превращаются в одно пятно.
Антиалиасинг — это дорого с точки зрения генерации. Когда насируют капчу, то могут легко положить сервер. Поэтому нужен быстрый алгоритм, который будет просто не только реализовать, но и исполнять.
Совсем недорого, если вы будете искажать не пиксельную карту, а векторное представление шрифта (и сетки, если захотите).
В самом простом случае, без применения сплайнов или кривых Безье, считайте, что буквы состоят из замкнутой цепи направленной отрезков, узловые точки которого вы определяете с высокой плотностью. Допустим, что при движении по часовой стрелке, область, ограниченная этими отрезками, заполняется цветом тела, а при движении против часовой стрелки — цветом фона, это даст вам возможность создавать дырки в буквах (например, в «б») и цифрах («8»).
Таким образом, перед построением капчи у вас должны быть в распоряжении несколько массивов узловых точек, с указанием направления (CW/CCW) для каждого из массивов. Координаты каждой точки, вне зависимости от принадлежности к какому-либо массиву, вы умножаете на ту же матричную функцию, что у вас использовалась для искажения оригинального изображения на попиксельной основе.
Затем скармливаете вашей графической библиотеке по очереди все полигоны с цветом тела, затем с цветом дырок. Можно, конечно, делать еще и occlusion mapping, но я не помню ни в кириллице, ни в латинице букв с двумя областями связности, одна из которых находилась бы в «дырке» от другой, так что это будет немного перебором.
Экономия будет значительной, даже с расходами на растеризацию полигонов — вам все-таки нужно умножать не каждый пиксель, а только узловые точки векторых букв. Пиксельное зашумление можно добавить в пост-обработке.
В самом простом случае, без применения сплайнов или кривых Безье, считайте, что буквы состоят из замкнутой цепи направленной отрезков, узловые точки которого вы определяете с высокой плотностью. Допустим, что при движении по часовой стрелке, область, ограниченная этими отрезками, заполняется цветом тела, а при движении против часовой стрелки — цветом фона, это даст вам возможность создавать дырки в буквах (например, в «б») и цифрах («8»).
Таким образом, перед построением капчи у вас должны быть в распоряжении несколько массивов узловых точек, с указанием направления (CW/CCW) для каждого из массивов. Координаты каждой точки, вне зависимости от принадлежности к какому-либо массиву, вы умножаете на ту же матричную функцию, что у вас использовалась для искажения оригинального изображения на попиксельной основе.
Затем скармливаете вашей графической библиотеке по очереди все полигоны с цветом тела, затем с цветом дырок. Можно, конечно, делать еще и occlusion mapping, но я не помню ни в кириллице, ни в латинице букв с двумя областями связности, одна из которых находилась бы в «дырке» от другой, так что это будет немного перебором.
Экономия будет значительной, даже с расходами на растеризацию полигонов — вам все-таки нужно умножать не каждый пиксель, а только узловые точки векторых букв. Пиксельное зашумление можно добавить в пост-обработке.
цепи направленной отрезков, узловые точки которого
«цепи направленных отрезков, узловые точки которых», конечно же. Не знаю, что на меня нашло.
Все заканчивается на «скармливаете вашей графической библиотеке» — лично я быстрых растеризаторов просто не знаю. И даже результат сравнительно быстрого Фритайпа лучше предварительно растеризировать. В принципе, перед растеризацией к глифу можно применить матрицу трансформаций, но этим мы получим набор шаблонов, который очень просто ломается. Пиксельный битмап же можно хранить в памяти, часть трансформаций проводить вообще через memmove (горизонтальные сдвиги) и переставление байт по заранее расчитанным трансформациям (найти в них повторы сложнее).
Если вы знаете быстрые растеризаторы — напишите, поиграюсь с бенчмарками (как раз пришла пора написать очередную ненужную говностатейку для поднятия кармочки)
Еще узкий момент — компрессия, сжимать в GIF достаточно дорого, у меня выходило порядка 3000 каптч в секунду (неоптимизированный кодер из Libavcodec, в принципе можно его обкромсать до сжатия битмапа, выкинуть подсчет палитры, формирование хидера и т.д., производительность должна быть выше). Сжатие в PNG по моему опыту менее эффективно для деформированнх цифирок, бенчмарков не делал. НО! В том же PNG я могу сделать 1-битный битмап без сжатия, т.е. просто к буферу-заголовку приклеить буфер с телом капчи. Никакого дефлейта вообще. Все просто летает, размер 1-битного рисунка небольшой и вполне приемлем. Но никакого антиалиасинга.
Только не надо писать «ой, да это ж хайлоад, у тебя должно быть 50 серверов». У меня не хайлоад, я просто не хочу позволить насильнику капчи сломать сервер. К примеру, надо обслужить множество запросов, в том числе от ботов (которых и фильтровать), а боты любят насиловать именно динамику, поэтому насилуют именно капчу.
Если вы знаете быстрые растеризаторы — напишите, поиграюсь с бенчмарками (как раз пришла пора написать очередную ненужную говностатейку для поднятия кармочки)
Еще узкий момент — компрессия, сжимать в GIF достаточно дорого, у меня выходило порядка 3000 каптч в секунду (неоптимизированный кодер из Libavcodec, в принципе можно его обкромсать до сжатия битмапа, выкинуть подсчет палитры, формирование хидера и т.д., производительность должна быть выше). Сжатие в PNG по моему опыту менее эффективно для деформированнх цифирок, бенчмарков не делал. НО! В том же PNG я могу сделать 1-битный битмап без сжатия, т.е. просто к буферу-заголовку приклеить буфер с телом капчи. Никакого дефлейта вообще. Все просто летает, размер 1-битного рисунка небольшой и вполне приемлем. Но никакого антиалиасинга.
Только не надо писать «ой, да это ж хайлоад, у тебя должно быть 50 серверов». У меня не хайлоад, я просто не хочу позволить насильнику капчи сломать сервер. К примеру, надо обслужить множество запросов, в том числе от ботов (которых и фильтровать), а боты любят насиловать именно динамику, поэтому насилуют именно капчу.
В случае векторных букв антиалиасинг не очень-то будет и нужен, нежатого однобитного битмапа вполне хватит. Вместо существующего растеризатора я бы вспомнил спектрум и сделал на Си свой велосипед — благо, только для отрезков с одним цветом заливки это совсем несложно.
Как сделаете — залейте на гитхаб :)
Линии рисовать несложно (однако с реализацией может быть множество нюансов), а проводить пермутацию байтов по шаблону — еще проще.
Да и скоростной растеризатор отрезков — это не та задача, которую я бы хотел решать (геометрию никогда не любил), а потом тюнить долгие месяцы.
Линии рисовать несложно (однако с реализацией может быть множество нюансов), а проводить пермутацию байтов по шаблону — еще проще.
Да и скоростной растеризатор отрезков — это не та задача, которую я бы хотел решать (геометрию никогда не любил), а потом тюнить долгие месяцы.
Challenge accepted.
{kind=link}
Ну как там дела? А то я вот такое придумал:

По-моему, тут анимация лишняя. Если наложить все кадры друг на друга, то неплохой эффект «дырявости» символов исчезнет (не пробывал, но кажется, что так). Можно выбрать любой кадр, и показывать только его: будет и надежнее, и быстрее (рендерить надо только одну картинку).
А что это за эффект вообще? Как определяется где рисовать символ, а где нет?
А что это за эффект вообще? Как определяется где рисовать символ, а где нет?
Ну тут и имелось в виду, что каждый кадр — отдельная капча. Не рендерить же портянку из 150 каптч друг на друге. Хотя вот скажем в habrahabr.ru/qa/32069/ вообще читать не умеют, даже когда на это прямо указал.
Эффект — банальная матрица свертки с рандомом + порог на выходе. Но что-то оно мне разонравилось уже, я вот с таким экспериментирую: rghost.net/42890070/image.png — самому страшно.
Эффект — банальная матрица свертки с рандомом + порог на выходе. Но что-то оно мне разонравилось уже, я вот с таким экспериментирую: rghost.net/42890070/image.png — самому страшно.
{kind=link}
Здесь удобнее использовать шрифты из библиотеки Hershey, которые рисуются множеством толстых линий. Обычными линиями, без сплайнов и кривых Безье.
Буква а

Надпись



А почему у вас в архиве из цифр только 3 4 6 9?
Sign up to leave a comment.
Взлом старой каптчи сайта Хабрахабр