Comments 67
Сделайте вывод списком, и чтобы кнопки вперед, назад были прибиты (скачут вверх вниз в зависимости от текста)
Список фильмов без описаний? Если так, то зачем?
Хотя бы с рейтингом. Ну и вообще, листать, даже не зная, сколько записей в списке — странное занятие. К тому же, если я хочу найти какой-то определенный фильм, мне долго листать надо?
Список фильмов без описания, список фильмов с описаниями — никто вас не ограничивает. Лишь бы не по одному элементу.
мало информации, надо список с высокими полями, что б помещался постер, пару кадров, описание качества(+рейтинг imdb) и размер(HD рипы ведь могут быть и 11Гб и 25Гб) и что б можно было за пару секунд проставить галки на 20 фильмах, а не мотать каждую страницу где кроме маленького текстового блока ничего и нет
Ну хоть какой-то фильтр всё равно нужен.
Моя мечта — качать всё, что «комедия» -драма c рейтингом 8+ и год 2012+
Моя мечта — качать всё, что «комедия» -драма c рейтингом 8+ и год 2012+
Еще хорошо было бы получать RSS новых фильмов на вашем сервисе.
И видеть дату добавления фильма
Просто RSS новых фильмов? Зачем? Лента же будет эквивалентна ленте кинопоиска (только ссылки на мой сайт будут вести).
Думал, сделать RSS-ленту новых фильмов с возможностью подписки прямо из неё. Но тогда пустое/бессмысленное окно в браузере при подписке будет открываться.
Думал, сделать RSS-ленту новых фильмов с возможностью подписки прямо из неё. Но тогда пустое/бессмысленное окно в браузере при подписке будет открываться.
Вот именно затем. Перейдя на ваш сайт, я смогу подписаться, а на кинопоиске — нет. А у вас сейчас даже по названию фильм не найти.
Добавил RSS — http://kino2rss.appspot.com/rss. Пока в нем мало информации и кое-где отображаются None вместо значений, но как только в базу будут добавлены новые фильмы — для них все исправится. Надо бы, конечно, и старых фильмов данные поправить…
Кстати о kinobaza.tv: развитие проекта забросили в конец? Как оттуда «вытащить» просмотренные мною фильмы и оценки и импортировать куда-то?
Владельцы кинобазы есть на хабре, можно попробовать спросить у них — daeq3.
Вытащить просмотренные фильмы можно с помощью их API. Импортировать их куда-то — вопрос более сложный. Как-то я спрашивал у Кинопоиска как это сделать. Мне посоветовали посмотреть как сейчас работает их функционал и отправлять такие же GET-запросы.
Вытащить просмотренные фильмы можно с помощью их API. Импортировать их куда-то — вопрос более сложный. Как-то я спрашивал у Кинопоиска как это сделать. Мне посоветовали посмотреть как сейчас работает их функционал и отправлять такие же GET-запросы.
Есть же FlexGet…
По теме поста: kino2rss — ни скринов фильма, не ссылок. А на nnm-club можно итак зайти, а искать среди всего «киношлака» по описаниям интересное — не удобно.
все это хорошо, но все торренты киноновинок — это экранки с плохим качеством звука и смотреть их нет ни какого удовольствия.
У меня дети, так сильно балдеющие от серии «Ледникового периода», просмотрев (до премьеры) на качестве DVD «Ледниковый период 4» любительскую озвучку, отказались повторно просматривать и просят скачать хороший вариант.
У меня дети, так сильно балдеющие от серии «Ледникового периода», просмотрев (до премьеры) на качестве DVD «Ледниковый период 4» любительскую озвучку, отказались повторно просматривать и просят скачать хороший вариант.
я упорно жду два-три месяца и качаю с рутрекера фильмы с ужехорошей озвучкой и в приемлемом качестве.
Мой сервис — как раз для решения этой задачи, т.к. скачиваются лишь DVD-рипы или даже фильмы в HD-качестве. Т.е. сейчас я узнал о появлении интересного фильма (прочитав его описание), пометил, что хочу его посмотреть — как только фильм появится в хорошем качестве, он будет скачен автоматически (хотя с озвучкой тут всё сложнее, конечно).
Я так и не понял почему вход только через гугл…
Было бы хорошо иметь больший выбор а не только DVD или HD качество
Много проделанной работы и толком ни о чем…
1. Берите с кинопоиска не новинки, а новинки на DVD
2. Спарсить описание с кинопоиска минутная работа!
+ ко всему этому уже есть готовый апи. Могу поделиться в ЛС если есть желание переделать нормально ваш сервис.
1. Берите с кинопоиска не новинки, а новинки на DVD
2. Спарсить описание с кинопоиска минутная работа!
+ ко всему этому уже есть готовый апи. Могу поделиться в ЛС если есть желание переделать нормально ваш сервис.
Мне не понравилось.
Я совершенно не понял, как мне это может быть полезно.
Я совершенно не понял, как мне это может быть полезно.
А в чём разница по сравнению с подпиской на RSS ленту раздела «Экранки»? С полноценным описанием фильма. Тянуть все новинки — зачем? 70% из них невыносимое г…
Вот мониторинг за выходом новых серий сериалов или обновляемых раздач, считаю на много более полезным.
tvfedor.ru? правда, он для торрентс.ру
Пожалуй будет не совсем правильно пиариться в чужом топике, но blog.korphome.ru/torrentmonitor/
Добавил возможность мониторинга выхода новых серий сериалов — kino2rss.appspot.com/serials, тестирую…
Тянутся как раз не все новинки, а лишь те, что вы пометили (т.е. прочитали описание, решили, что этот фильм вам может понравится, отметили его).
Проблему с постерами можно решить используя например snoopy class'a, в свое время занимался грабежом кинопоиска для движка torrentpier.
Даа, с постерами проблема — вместо них заглушка отображается. snoopy class — это, как я понял, для PHP. У меня — Google App Engine (GAE) + python. В принципе, отправить те же заголовки, что и браузер, я, наверное, смогу. Хотя GAE в заголовки свой идентификатор вставляет, кинопоиск по нему может не отвечать на мои запросы. Но — совсем не хочется скачивать себе постеры.
Постеры добавил.
Осталось сделать сервис который будет за меня все эти новинки просматривать :)… ну или работать за меня пока я их просматриваю, это можно сделать даже в виде pro версии за деньги :)
Эх, упало из-за квот.
Ошибка
Traceback (most recent call last):
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/webapp/_webapp25.py", line 710, in __call__
handler.get(*groups)
File "/base/data/home/apps/s~kino2rss/1.361339873621337288/kino2rss.py", line 117, in get
movie_id = models.get_latest_movie_id()
File "/base/data/home/apps/s~kino2rss/1.361339873621337288/models.py", line 94, in get_latest_movie_id
movie = movies.get(keys_only = True)
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/query.py", line 1150, in get
return self.get_async(**q_options).get_result()
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/tasklets.py", line 323, in get_result
self.check_success()
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/tasklets.py", line 362, in _help_tasklet_along
value = gen.throw(exc.__class__, exc, tb)
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/query.py", line 1163, in _get_async
res = yield self.fetch_async(1, **q_options)
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/tasklets.py", line 362, in _help_tasklet_along
value = gen.throw(exc.__class__, exc, tb)
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/query.py", line 921, in _run_to_list
batch = yield rpc
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/tasklets.py", line 443, in _on_rpc_completion
result = rpc.get_result()
File "/base/python_runtime/python_lib/versions/1/google/appengine/api/apiproxy_stub_map.py", line 604, in get_result
return self.__get_result_hook(self)
File "/base/python_runtime/python_lib/versions/1/google/appengine/datastore/datastore_query.py", line 2452, in __query_result_hook
self._batch_shared.conn.check_rpc_success(rpc)
File "/base/python_runtime/python_lib/versions/1/google/appengine/datastore/datastore_rpc.py", line 1222, in check_rpc_success
rpc.check_success()
File "/base/python_runtime/python_lib/versions/1/google/appengine/api/apiproxy_stub_map.py", line 570, in check_success
self.__rpc.CheckSuccess()
File "/base/python_runtime/python_lib/versions/1/google/appengine/api/apiproxy_rpc.py", line 133, in CheckSuccess
raise self.exception
OverQuotaError: The API call datastore_v3.RunQuery() required more quota than is available.Сорри, не вам.
Эх, упало из-за квот.
Ошибка
Traceback (most recent call last):
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/webapp/_webapp25.py", line 710, in __call__
handler.get(*groups)
File "/base/data/home/apps/s~kino2rss/1.361339873621337288/kino2rss.py", line 117, in get
movie_id = models.get_latest_movie_id()
File "/base/data/home/apps/s~kino2rss/1.361339873621337288/models.py", line 94, in get_latest_movie_id
movie = movies.get(keys_only = True)
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/query.py", line 1150, in get
return self.get_async(**q_options).get_result()
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/tasklets.py", line 323, in get_result
self.check_success()
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/tasklets.py", line 362, in _help_tasklet_along
value = gen.throw(exc.__class__, exc, tb)
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/query.py", line 1163, in _get_async
res = yield self.fetch_async(1, **q_options)
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/tasklets.py", line 362, in _help_tasklet_along
value = gen.throw(exc.__class__, exc, tb)
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/query.py", line 921, in _run_to_list
batch = yield rpc
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/tasklets.py", line 443, in _on_rpc_completion
result = rpc.get_result()
File "/base/python_runtime/python_lib/versions/1/google/appengine/api/apiproxy_stub_map.py", line 604, in get_result
return self.__get_result_hook(self)
File "/base/python_runtime/python_lib/versions/1/google/appengine/datastore/datastore_query.py", line 2452, in __query_result_hook
self._batch_shared.conn.check_rpc_success(rpc)
File "/base/python_runtime/python_lib/versions/1/google/appengine/datastore/datastore_rpc.py", line 1222, in check_rpc_success
rpc.check_success()
File "/base/python_runtime/python_lib/versions/1/google/appengine/api/apiproxy_stub_map.py", line 570, in check_success
self.__rpc.CheckSuccess()
File "/base/python_runtime/python_lib/versions/1/google/appengine/api/apiproxy_rpc.py", line 133, in CheckSuccess
raise self.exception
OverQuotaError: The API call datastore_v3.RunQuery() required more quota than is available.А можно сделать не по одному фильму на странице, а сразу ленту? Так имхо удобнее, по отмечал всё что надо не переходя на другие страницы:

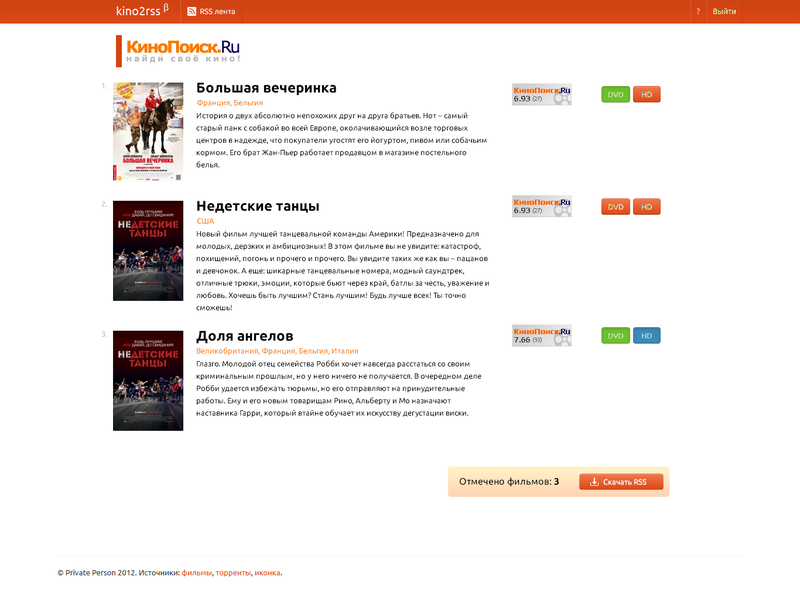
Я для себя писал парсер кинопоиска несколько для других целей. У меня есть там профиль и в нём заполнены любые актёры/актрисы/режиссёры. Каждую ночь (ну так что бы наверняка) скрипт обходит страницы этих людей, и смотрит — в каких фильмах они снимались/снимаются и загоняет их в базу. Просто любимых актёров/актрис/режиссёров очень много и самому следить кто где снялся или что снял — накладно, в итоге имею вывод в виде таблички, где отмечаю просмотренные в этом году фильмы, или смотрю что есть из старенького, что я ещё не смотрел, или что там в будущем ещё интересного выйдет.
как то вот так это выглядит hostingkartinok.com/show-image.php?id=ebb68a8893cbb293d725f893f5afa924
как то вот так это выглядит hostingkartinok.com/show-image.php?id=ebb68a8893cbb293d725f893f5afa924
Как у вас красиво отсортированы закладки в Safari )))
И рабочий стол наверное в порядке?
И рабочий стол наверное в порядке?
И рабочий стол чистый и 16k медиатека рассортирована, подписана и разложена и вообще все 6Тб барахла рассортированы, подписаны и разложены аккуратно по винтам и папочкам… люблю порядок :)
Я вам завидую белой завистью :)
мой

да, мне до вас ой как далеко :)))
pix.am/uEee/
ну тут наверное ещё просто сказывается наличие сервака на 8Тб и внешнего винта, а на минике и прошке у меня стоят маленькие ссд, чисто под систему и я на них ничего не храню
pix.am/uEee/
ну тут наверное ещё просто сказывается наличие сервака на 8Тб и внешнего винта, а на минике и прошке у меня стоят маленькие ссд, чисто под систему и я на них ничего не храню
Внешний на 1Тб+Капсула на 2Тб.
Серваков у меня штук 10 общим объемом более 30Тб.
Тут проблема в человеке, а не, как и где хранить данные. Я люблю, когда все под рукой. Если все со стола раскидать по папкам, то это потеря времени…
Серваков у меня штук 10 общим объемом более 30Тб.
Тут проблема в человеке, а не, как и где хранить данные. Я люблю, когда все под рукой. Если все со стола раскидать по папкам, то это потеря времени…
Просто дело в организации, у меня тоже всё под рукой и залезть куда то даже очень далеко — дело 5 секунд
pix.am/PDAz/
pix.am/PDAz/
Спасибо, удобно :)
простомтру новинок явно необходима обложка и список актеров
круто! а для актеров сделать просмотр фильмов с их участием и «любимые актеры»
что-то сломалось, указываю ссылку со своим ключем, а rss все равно пустая
Sign up to leave a comment.
Автоматическое скачивание киноновинок