Предыстория
Не так давно, а именно 5 июня хабрачеловек по имени alan008 задал вопрос. Чтобы не заставлять ходить за подробностями, приведу его здесь:
Нужна помощь!
За несколько лет с разных трекеров (преимущественно c rutracker'а) разными клиентами (преимущественно uTorrent'ом) скачано много гигабайт разного полезного контента. Скачанные файлы впоследствии вручную перемещались с одного диска на другой, uTorrent их соответственно не видит. Многие .torrent файлы устарели сами по себе (например, велась раздача сериала путем добавления новых серий заменой .torrent файла).
Теперь сам вопрос: есть ли способ автоматически (не вручную) установить соответствие между имеющимися на компьютере .torrent файлами и содержимым, раскиданным по разным логическим дискам компьютера? Цель: удалить лишние (неактуальные) .torrent файлы, а для актуальных — поставить всё на раздачу. У кого какие идеи? :)
При необходимости (если это требуется) можно снова поместить все файлы данных в один каталог на одном логическом диске.
В обсуждениях сошлись на том, что если это и можно сделать, то только ручками. Мне же этот вопрос показался интересным, и после возвращения из отпуска я нашел время, чтобы в нем разобраться.
Потратив в общей сложности неделю на разбор формата .torrent-файла, поиск нормально работающей библиотеки для его парсинга, я приступил к написанию программы, которая позволит решить проблему затронутую в упомянутом вопросе.
Прежде чем начать, стоит отметить несколько моментов:
- Получилось много, но не все.
- По формату файла .torrent будут даны лишь необходимые пояснения.
- Людей, чувствительных к временами некачественному коду, прошу меня заранее простить — я знаю, что многое можно было написать лучше, оптимальнее и безглючнее.
Для тех, кому интересно, что из этого получилось, технические подробности и подводные камни — прошу под кат.
В данном случае имеется отличный способ решения — перекачать заново. Но мы же не ищем легких путей, да и предлагался такой вариант! Итак, будем решать задачу по сложному — не скачивать.
Приступая к написанию любой программы, необходимо сначала продумать хотябы базовый алгоритм ее работы. В нашем случае алгоритм, по сути, состоит из двух шагов:
- Найти и прочитать все .torrent-файлы;
- Найти в куче файлов тот, который соответствует описанному в .torrent, и переместить его в папку, соответствующую пути в .torrent.
Для реализации своей идеи, я использовал C#, однако для этого подойдет любой язык, на котором есть библиотеки для чтения файлов в формате bencode и реализована возможность считать SHA-1 хеш.
Ну что же, приступим к решению поставленной задачи.
Ищем торренты и читаем их
После того, как я разобрался с устройством .torrent-файлов, передо мной встал вопрос парсинга всего этого чуда. Прошерстив интернет по данному вопросу, я обнаружил несколько .NET-библиотек под это дело. Выбор свой я остановил на, более-менее понятной и работающей из коробки библиотеке BencodeLibrary, однако впоследствии пришлось ее немного дополнить под свои нужды, но об этом позже.
Начнем с самого простого момента — чтения .torrent.
Строение .torrent-файла довольно простое — он представляет из себя словарь в формате bencode. В данном словаре нас интересует только пара с ключом info — блок описания файлов. Этот тоже является словарем и содержит в себе информацию об имени файлов, их размере. Кроме того, как многим известно, торрент хеширует файлы не целиком, а по кускам определенной длины, которая зависит от размера этих файлов. Информация о размере этого куска также содержится в словаре info.
Для хранения информации из прочитанного файла будем использовать такой класс
Torrent:class Torrent
public class Torrent
{
public Torrent(string name, List<LostFile> files, int pieceLength, char[] hash, string fileName)
{
Name = name;
Files = files;
PieceLength = pieceLength;
Hash = hash;
FileName= fileName;
}
public string Name;
public int PieceLength;
public char[] Hash;
public List<LostFile> Files;
public string FileName;
...
}Здесь поля хранят следующую информацию:
*
Name — имя торрента (вообще говоря — имя папки или имя файла)*
Files — список файлов, которые нам надо будет в дальнейшем искать*
PieceLength — размер тех самых кусочков, хеш которых нам предстоит считать*
Hash — хеш строка всех файлов*
FileName — имя .torrent-файла на дискеТеперь стоит заострить внимание на строке хеша. Она составляется очень просто. Все файлы склеиваются в один (виртуально конечно) друг за другом, образуя при этом один БОЛЬШОООООООЙ воображаемый файл. В этом воображаемом файле берем кусок длины
PieceLength, считаем SHA1 хеш, кладем хеш в строку, берем следующий кусок, считаем хеш, дописываем к концу строки с хешем предыдущего куска. Т. е. это обычная конкатенация хешей всех кусков.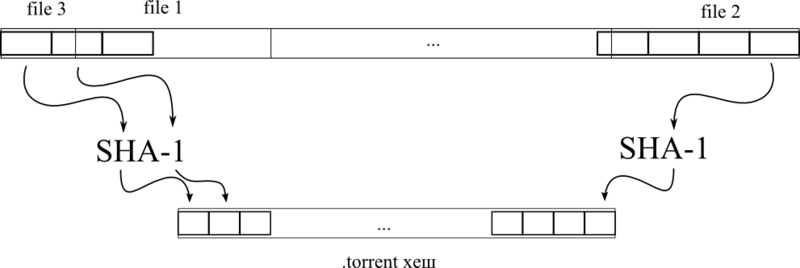
Как мог заметить внимательный читатель, файл внутри класса — это не просто файл, а особый тип данных, в котором файл описывается некой конструкцией типа
LostFile. Вот она:class LostFile
public class LostFile
{
public LostFile(string name, long length, long beginFrom)
{
Name = name;
Length = length;
BeginFrom = beginFrom;
}
public string Name;
public long Length;
public long BeginFrom;
. . .
}Здесь все просто: имя файла и его размер. Кроме того этот класс содержит еще одно поле —
BeginFrom. Оно описывает начало этого файла в том БОЛЛЬШОООООМ воображаемом файле. Он нужен, чтобы взять правильную часть файла для подсчета хеша — ведь длина файла очень редко кратна длине куска.
Подготовив структуры для хранения необходимой информации, можно приступать к их заполнению.
С помощью найденной на просторах интернета библиотеки BencodeLibrary мы читаем наш .torrent-файл и выкорчевываем из него блок info:
List<LostFile> files = new List<LostFile>(); // список файлов, понадобится позднее
BDict torrent = (BDict)BencodingUtils.DecodeFile(filename, Encoding.UTF8);
BDict fileInfo = (BDict)torrent["info"];
Далее из этого блока необходимо забрать данные об имени торрента, размере куска.
string name = ((BString)fileInfo["name"]).Value;
int pieceLength = (int)((BInt)fileInfo["piece length"]).Value;
С чтением хеша возникла проблема, решение которой мне не очень нравится, но оно работает. Дело в том, что по спецификации все строки в .torrent-файле должны быть в UFT8. Если читать хеш, который по спецификации записан в формате bencode-строки, как UTF8-строку, то возникнет проблема сравнения — хеши одинаковых кусков не совпадут. Читая же торрент в предлагаемой кодировке codepage-437, мы получим проблемы с русскими буквами в путях. Выход из такой ситуации, которая меня тормознула на два дня, я нашел не лучший, но работающий — читать два раза в разных кодировках.
torrent = (BDict)BencodingUtils.DecodeFile(filename, Encoding.GetEncoding(437));
char[] pieces = ((BString)((BDict)torrent["info"])["pieces"]).Value.ToCharArray();
В этом месте мы передаем в метод `BencodingUtils.DecodeFile` вторым параметром информацию о кодировке. Это как раз тот момент, когда пришлось добавлять один метод в библиотеку — изначально codepage-437 была вшита в код.
Мы добрались до самого интересного момента в этой части — чтение информации о файлах. Торрент файлы бывают двух типов. Эти типы различаются тем, сколько файлов в них описано. При описании только одного файла в .torrent пишется его имя и размер.
Сначала разберем .torrent с описанием одного файла.
long Length = ((BInt)fileInfo["length"]).Value;
files.Add(new LostFile(name, Length, 0)); // files - список файлов
Тут все просто — имя торрента совпадает с именем файла. В случае, когда файлов в раздаче много, то в поле name пишется имя папки, в которую их надо положить (на самом деле может быть что угодно, но почему-то все пишут имя папки в которой эти файлы лежали при создании). Кроме того появляется список files в котором содержится информация о каждом файле: путь к нему и размер. Если размер — просто целое число, то путь к файлу представляет собой список из строк (имен директорий), пройдя по которым мы увидим этот файл.
Такое лучше пояснять на примере. Для файлов
level_1\level_2_1\file_1.txt и level_1\level_2_2\file_2.txt, если мы захотим их раздавать, поле name будет содержать имя папки верхнего уровня ("level_1"), а список path для одного из файлов будет следующего вида: {"level_2_1", "file_1.txt"} и {"level_2_2", "file_2.txt"} для другого.Нам для .torrent с несколькими файлами надо путь до каждого файла собрать в одну строку. Кроме того, надо хранить начало каждого файла в том БОЛЬШООООМ (не забыли, правда же?!):
BList filesData = (BList)fileInfo["files"];
long begin = 0;
foreach (BDict file in filesData)
{
BList filePaths = (BList)file["path"];
long length = ((BInt)file["length"]).Value;
string fullPath = name;
foreach (BString partOfPath in filePaths)
{
fullPath += @"\" + partOfPath.Value;
}
files.Add(new LostFile(fullPath, length, begin)); // files - список файлов
begin += length;
}
Очень важно отметить, что порядок следования файлов в БОЛЬШОООООМ файле может быть любым, не обязательно по алфавиту или по размеру. Но порядок файлов в списке files будет точно таким же. Это ключевой момент для понимания принципа хеширования. Для примера, в ситуации, изображенной на первом рисунке, список файлов будет следующим:
{"file_3","file_1", ..., "file_2"}. Таким образом, считая хеш одного файла, мы знаем какой файл надо будет брать следующим.Когда мы все это дело прочитали и посчитали — давайте создадим и вернем экземпляр
Torrent:new Torrent(name, files, pieceLength, pieces, filename);
Собирая теперь все чтение и разбор .torrent-файла воедино, получаем:
ReadTorrent
static Torrent ReadTorrent(string filename)
{
List<LostFile> files = new List<LostFile>();
BDict torrent = (BDict)BencodingUtils.DecodeFile(filename);
BDict fileInfo = (BDict)torrent["info"];
string name = ((BString)fileInfo["name"]).Value;
int pieceLength = (int)((BInt)fileInfo["piece length"]).Value;
torrent = (BDict)BencodingUtils.DecodeFile(filename, Encoding.GetEncoding(437));
char[] pieces = ((BString)((BDict)torrent["info"])["pieces"]).Value.ToCharArray();
if (fileInfo.ContainsKey("files")) // Multifile torrent
{
BList filesData = (BList)fileInfo["files"];
long begin = 0;
foreach (BDict file in filesData)
{
BList filePaths = (BList)file["path"];
long length = ((BInt)file["length"]).Value;
string fullPath = name;
foreach (BString partOfPath in filePaths)
{
fullPath += @"\" + partOfPath.Value;
}
files.Add(new LostFile(fullPath, length, begin));
begin += length;
}
}
else // Singlefile torrent
{
long Length = ((BInt)fileInfo["length"]).Value;
files.Add(new LostFile(name, Length, 1));
}
return new Torrent(name, files, pieceLength, pieces, filename);
}
Теперь, когда у нас есть все необходимые данные, мы готовы к самому интересному — поиску наших файлов.
Ищем файлы
Мы вплотную подошли к реализации второго шага нашего алгоритма. Для этого будем использовать метод
FindFiles такого вида:void FindFiles(Torrent torrent, List<FileInfo> files, string destinationPath) {}
Здесь
files — список файлов, среди которых мы будем искать, destinationPath — путь до папки назначения, в которую будут помещаться найденные файлы.Для каждого файла в .torrent мы будем перебирать все файлы из кучи и их сверять. Так как проверка хеша довольно затратна, то надо сначала отсеять явно левые файлы. Ну посудите сами: если я качал дискографию в .mp3 и переместил ее, то явно не менял расширения файлов. Имя мог поменять, а вот расширение вряд ли.
FileInfo fileOnDisk = files[j];
if (fileOnDisk.Extension != Path.GetExtension(fileInTorrent.Name))
continue;
Также стоит проверять длину файла, но это уже сомнительно и иногда может давать ложные срабатывания. Только после того, как мы отсеяли по расширению явно левые файлы, можно приступать к проверке хеша.
if (!torrent.CheckHash(i, fileOnDisk))
continue;
После того как проверка завершена, и мы удостоверились в соответствии файла искомому — перемещаем его в папку назначения с правильным путем. Перед перемещением будем естественно проверять наличие директории, а также проверим есть ли уже такой файл или нет.
copyFile — переменная передаваемая с формы пользователем, ее назначение, я думаю, понятно всем.
FileInfo fileToMove = new FileInfo(destinationPath + @"\" + fileInTorrent.Name);
if (!Directory.Exists(fileToMove.DirectoryName))
Directory.CreateDirectory(fileToMove.DirectoryName);
if (!fileToMove.Exists)
{
// Перемещаем-копируем файл
if (copyFile)
File.Copy(fileOnDisk.FullName, fileToMove.FullName);
else
File.Move(fileOnDisk.FullName, fileToMove.FullName);
// Убираем из списка рассматириваемых
files.Remove(fileOnDisk);
// Убираем из описания торрента
torrent.Files.RemoveAt(i--);
break; //Больше искать файл в дереве не надо, можно переходить к следующему в torrent
}Есть в коде выше три важных для пояснения момента. Начну с двух последних — вот эти строки:
files.Remove(fileOnDisk);
torrent.Files.RemoveAt(i--);
Я посчитал вполне логичным убирать уже отсортированные файлы из рассмотрения, что позволит несколько сократить время выполнения поиска. Во второй строке есть конструкция
.RemoveAt(i--); так как из коллекции убирается текущий элемент, то указатель надо сдвинуть назад, чтобы на следующей итерации цикла брался следующий элемент, а не через один.Теперь про первый момент. Я знаю про наличие
foreach для списка, но его при использовании нельзя модифицировать этот спикок, то есть мы не сможем удалять уже ненужные более элементы. Итак, собирая все выше описанное в один метод, имеем: ReadTorrent
public static void FindFiles(Torrent torrent, List<FileInfo> files, string destinationPath, bool copyFile)
{
for (int i = 0; i < torrent.Files.Count; i++)// (LostFile fileInTorrent in torrent.Files)
{
LostFile fileInTorrent = torrent.Files[i];
for (int j = 0; j < files.Count; j++)
{
FileInfo fileOnDisk = files[j];
// Ищем файл с таким же разширением
if (fileOnDisk.Extension != Path.GetExtension(fileInTorrent.Name))
continue;
// Проверяем размер
if (fileOnDisk.Length != fileInTorrent.Length)
continue;
// Проверяем хэш
if (!torrent.CheckHash(i, fileOnDisk))
continue;
// Все проверки пройдены. перед нами искомый файл
// Перемещаем его
FileInfo fileToMove = new FileInfo(destinationPath + @"\" + fileInTorrent.Name);
if (!Directory.Exists(fileToMove.DirectoryName))
Directory.CreateDirectory(fileToMove.DirectoryName);
if (!fileToMove.Exists)
{
if (copyFile)
File.Copy(fileOnDisk.FullName, fileToMove.FullName);
else
File.Move(fileOnDisk.FullName, fileToMove.FullName);
// И убираем из списка рассматириваемых
files.Remove(fileOnDisk);
// Убираем из описания торрента
torrent.Files.RemoveAt(i--);
break;
}
}
}
}
Ну вот! Самое вкусное.
Проверка хеша
Как видно из кода выше, для проверки хеша мы передаем имя файла на диске и номер файла в списке файлов торрента. Это надо для того, чтобы не запускать поиск в списке файлов, а сразу взять его по номеру, раз он известен (еще одно "+1" циклу
for).public class Torrent
{
public string Name;
public int PieceLength;
public char[] Hash;
public List<LostFile> Files;
public string FileName;
public bool CheckHash(int index, FileInfo fileOnDisk) {}
}
Теперь приступим к реализации нашего метода проверки хеша. На данном этапе мы знаем номер в списке файлов торрента и путь до файла на диске
LostFile checkingFile = this.Files[index];
if (checkingFile.Length < this.PieceLength * 2 - 1)
return false;
В принципе, мы можем считать хеш любого файла, но давайте немного упростим себе задачу. Мы будем браться только за файлы, длина которых больше или равна
PieceLength * 2 - 1. Такое ограничение даст нам возможность вычленить хотя бы один кусок для проверки, полность находящийся в файле. У такого подхода есть несколько существенных плюсов:- Нет необходимости дополнительно искать на диске соседние файлы;
- Длина куска для хеширования очень редко превышает 2-4 МБ, что дает нам еще один плюс — с точки зрения производительности и времени, докачать такие файлы намного проще, чем искать их на диске.
На этом этапе мы подошли к самому сложному из всего, что нам надо было сделать — поиску нужного куска для проверки. Давайте немного отдалимся от программирования и обратимся к математике, сформулировав вспомогательную задачку.
Когда торрент-клиент проводит хеширование файлов, он считает хеш по порядку, однако бывает так, что нет одного или нескольких файлов. Тогда торрент-клиенту надо знать какой следующий кусок брать и откуда он будет начинаться в следующем имеющемся файле. Для вычисления двух этих цифр будем использовать следующий код, в котором переменная
firstChunkNumber содержит номер первого куска, который полностью содержится в данном файле, а bytesOverhead — количество байт от начала файла до начала этого куска. Для лучшего понимания этого момента взгляните на поясняющий рисунок после кода.long start = 0;
long firstChunkNumber = 0;
long bytesOveload = checkingFile.BeginFrom % this.PieceLength;
if (bytesOveload == 0) // Если кусок начинается с первого байта файла
{
start = checkingFile.BeginFrom;
firstChunkNumber = checkingFile.BeginFrom / this.PieceLength;
}
else
{
firstChunkNumber = checkingFile.BeginFrom / this.PieceLength + 1;
start = firstChunkNumber * this.PieceLength - checkingFile.BeginFrom;
}

Ответить на вопрос «Почему номер куска разный для случая, когда его начало совпадает с началом файла, и для случая, когда кусок лежит внутри?» предлагается самостоятельно.
Сейчас, зная номер куска мы должны взять его хеш из торрента с помощью такой конструкции:
char[] hashInTorrent = new char[20]; // 20 - длина хеша SHA1 в байтах
Array.Copy(this.Hash, firstChunkNumber * 20, hashInTorrent, 0, 20);
После этого, надо прочитать кусок из файла и посчитать его хеш:
char[] fileHash = new char[this.PieceLength];
using (BinaryReader fs = new BinaryReader(new FileStream(fileOnDisk.FullName, FileMode.Open)))
{
using (SHA1CryptoServiceProvider sha1 = new SHA1CryptoServiceProvider())
{
byte[] piece = new byte[this.PieceLength];
fs.BaseStream.Position = start;
fs.Read(piece, 0, this.PieceLength);
fileHash = Encoding.GetEncoding(437).GetString(sha1.ComputeHash(piece)).ToCharArray();
}
}
Ну и самое важное — его проверить. У меня, почему-то не захотел работать ни один из методов
Equals(), которые я смог найти, поэтому проверяем так:for (int i = 0; i < fileHash.Length; i++)
{
if (fileHash[i] != hashInTorrent[i])
return false;
}
Собирая воедино сие творение возбужденного мозга, получим метод следующего содержания:
CheckHash
public bool CheckHash(int index, FileInfo fileOnDisk)
{
LostFile checkingFile = this.Files[index];
if (checkingFile.Length < this.PieceLength * 2 - 1)
return false;
long start = 0;
long firstChunkNumber = 0;
long bytesOveload = checkingFile.BeginFrom % this.PieceLength;
if (bytesOveload == 0)
{
start = checkingFile.BeginFrom;
firstChunkNumber = checkingFile.BeginFrom / this.PieceLength;
}
else
{
firstChunkNumber = checkingFile.BeginFrom / this.PieceLength + 1;
start = firstChunkNumber * this.PieceLength - checkingFile.BeginFrom;
}
char[] hashInTorrent = new char[20];
Array.Copy(this.Hash, firstChunkNumber * 20, hashInTorrent, 0, 20);
char[] fileHash = new char[this.PieceLength];
using (BinaryReader fs = new BinaryReader(new FileStream(fileOnDisk.FullName, FileMode.Open)))
{
using (SHA1CryptoServiceProvider sha1 = new SHA1CryptoServiceProvider())
{
byte[] piece = new byte[this.PieceLength];
fs.BaseStream.Position = start;
fs.Read(piece, 0, this.PieceLength);
fileHash = Encoding.GetEncoding(437).GetString(sha1.ComputeHash(piece)).ToCharArray();
}
}
for (int i = 0; i < fileHash.Length; i++)
if (fileHash[i] != hashInTorrent[i])
return false;
return true;
}
На этой прекрасной ноте, рассказ о методах и алгоритмах заканчивается, и мы переходим к рассказу о реализации в реальной жизни данного творения. Вполне понятно, что данная задача мной решалась не для того, чтобы решить, а для того, чтобы реализовать. Поэтому привожу на суд общественности мое творение, которое реализует все то, о чем написано выше.
Программа
Программа написана, как уже упоминалось на C#. При работе не сильно прихотлива, требует только .NET 2.0. Есть однако одно ограничение на использование: торрент файлы и коллекцию лучше убрать из корня логического диска. Причина этого ограничения — использование при сканировании директорий параметра `SearchOption.AllDirectories`, что приводит к вылету при попытке прочитать закрытые директории типа корзины или `System Volume Information` (если знающие люди подскажут как это обойти, то буду весьма признателен). Для папки назначения особых ограничений естественно нет, главное чтобы влезло, и можно было в нее писать, иначе вылетит с ошибкой (не моделировал, но логично).
В процессе работы, после окончания обработки очередного файла, выводится результат — имя .torrent-файла на диске и количество обработанных файлов.
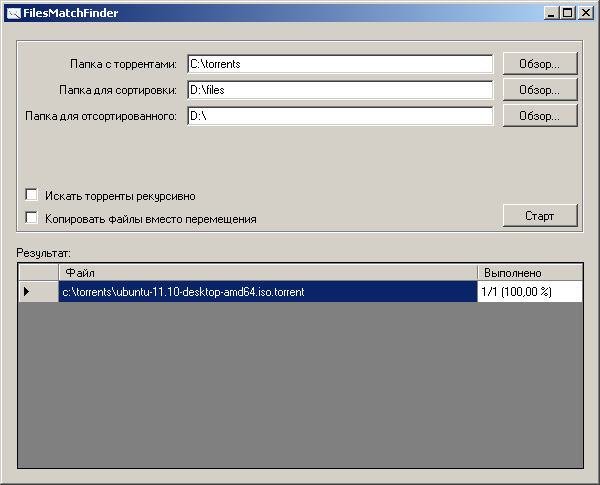
Чтобы запустить сканирование, необходимо выбрать три директории (с файлами .torrent, с файлами для сортировки и папку для отсортированного), по желанию указать две опции и запустить сканирование.
По поводу производительности. Она пока что низкая: обработка 10 больших torrent-файлов заняла около 5 минут.
Так как работает приложение в один поток, то во время выполнения интерфейс подвисает, но я над этим работаю. Также хочу напомнить, что файлы малого размера (меньше 2-х мегабайт) не будут перемещены по причине отсутствия возможности проверки хеша. Вполне вероятны ложные срабатывания из-за того, что проверяется только один кусок под номером
firstChunkNumber. Пока что проверять все куски слишком затратно, но в планах есть.Не ищите торренты рекурсивно, если они собраны в корне диска.
Копирование может занять много времени, поэтому интерфейс может подвиснуть — не пугайтесь.
Так как писалась эта программа 4fun, то качество кода там немного не то, которое хотелось бы, но у меня оно работает. Данная программа не тестировалась, исправлялись только очевидные ошибки, поэтому могут быть, да что скрывать-то, есть скрытые баги. ИСПОЛЬЗУЯ ДАННУЮ ПРОГРАММУ, ВЫ ИСПОЛЬЗУЕТЕ ЕЕ НА СВОЙ СТРАХ И РИСК.
Взять исходники можно на github. Распространяется по GPLv2. Там есть архив с исполняемым файлом. Для работы требуется библиотека Bencode Library, но не оригинальная, а модифицированная мною (есть у меня в репозитарии, подключена субмодулем).
Спасибо всем, кто проявил терпение и дочитал эту статью до конца. Рад услышать ваши вопросы, приветствуется всевозможная помощь в совершенствовании алгоритма и, в особенности, кода.
Источники: BitTorrentSpecification.
UPD1. По результатам обсуждения мне стало понятно, что правильней будет не ломать существующие коллекции выдергиванием файлов на раздачу, а наоборот — создавать хардлинки в нужном для раздачи месте на файлы внутри упорядоченных коллекций (фильмо и дискографий, например). В дальнейшем программа будет работать именно так.
UPD2. Если у тех, кто пользовался этой утилитой, есть еще какие-то пожелания по функционалу или баг репорты, то прошу оставлять их на github в issue-трекере.
