В продолжение первого урока по изучению азов RabbitMQ публикую перевод второго урока с официального сайта. Все примеры, как и ранее, на python, но по-прежнему их можно реализовать на большинстве популярных ЯП.
Очереди задач
В первом уроке мы написали две программы: одна отправляла сообщения, вторая их принимала. В этом уроке мы создадим очередь, которая будет использоваться для распределения ресурсоемких задач между несколькими подписчиками.
Основная цель такой очереди ‒ не начинать выполнение задачи прямо сейчас и не ждать, пока оно завершится. Вместо этого задачи откладываются. Каждое сообщение соответствует одной задаче. Программа-обработчик, работающая в фоновом режиме, примет задачу на обработку, и через какое-то время она будет выполнена. При запуске нескольких обработчиков задачи будут разделены между ними.
Такой принцип работы особенно полезен для применения в веб-приложениях, где невозможно обработать ресурсоемкую задачу во время HTTP-запроса.
Подготовка
В предыдущем уроке мы отсылали сообщение с текстом «Hello World!». А сейчас мы будем посылать сообщения, соответствующие ресурсоемким задачам. Мы не будем выполнять реальные задачи, такие как изменение размера изображения или рендеринг pdf файла, давайте просто сделаем заглушку, используя функцию time.sleep(). Сложность задачи будет определяться количеством точек в строке сообщения. Каждая точка будет “выполняться” одну секунду. Например, задача с сообщением «Hello...» будет выполняться 3 секунды.
Мы немного изменим код программы send.py из предыдущего примера, чтобы было возможно отправлять произвольные сообщения из командной строки. Эта программа будет отправлять сообщения в нашу очередь, планируя выполнение новых задач. Назовем ее new_task.py:
import sys
message = ' '.join(sys.argv[1:]) or "Hello World!"
channel.basic_publish(exchange='',
routing_key='hello',
body=message)
print " [x] Sent %r" % (message,)
Программа receive.py из предыдущего примера также должна быть изменена: необходимо симулировать выполнение полезной работы, по секунде на каждую точку текста сообщения. Программа будет получать сообщение из очереди и выполнять задачу. Назовем ее worker.py:
import time
def callback(ch, method, properties, body):
print " [x] Received %r" % (body,)
time.sleep( body.count('.') )
print " [x] Done"
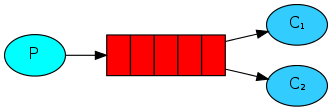
Циклическое распределение
Одно из преимуществ использования очереди задач ‒ возможность выполнять работу параллельно несколькими программами. Если мы не успеваем выполнять все поступающие задачи, то можем просто прибавить количество обработчиков.
Для начала давайте запустим сразу две программы worker.py. Обе они будут получать сообщения из очереди, но как именно? Сейчас увидим.
Вам необходимо открыть три окна терминала. В двух из них будет запущена программа worker.py. Это будут два подписчика ‒ C1 и C2.
shell1$ python worker.py
[*] Waiting for messages. To exit press CTRL+C
shell2$ python worker.py
[*] Waiting for messages. To exit press CTRL+C
В третьем окне мы будем публиковать новые задачи. После того как подписчики запущены, можно отправлять любое количество сообщений:
shell3$ python new_task.py First message.
shell3$ python new_task.py Second message..
shell3$ python new_task.py Third message...
shell3$ python new_task.py Fourth message....
shell3$ python new_task.py Fifth message.....
Давайте посмотрим, что было доставлено подписчикам:
shell1$ python worker.py
[*] Waiting for messages. To exit press CTRL+C
[x] Received 'First message.'
[x] Received 'Third message...'
[x] Received 'Fifth message.....'
shell2$ python worker.py
[*] Waiting for messages. To exit press CTRL+C
[x] Received 'Second message..'
[x] Received 'Fourth message....'
По умолчанию, RabbitMQ будет передавать каждое новое сообщение следующему подписчику. Таким образом, все подписчики получат одинаковое количество сообщений. Такой способ распределения сообщений называется циклический [алгоритм round-robin]. Попробуйте то же самое с тремя или более подписчиками.
Подтверждение сообщений
Выполнение этих задач занимает несколько секунд. Возможно, Вы уже задались вопросом, что будет, если обработчик начал выполнение задачи, но неожиданно прекратил работу, выполнив ее лишь частично. В текущей реализации наших программ сообщение удаляется, как только RabbitMQ доставил его подписчику. Поэтому, если Вы остановите обработчик во время работы, задача не будет выполнена, а сообщение будет утеряно. Также будут утеряны доставленные сообщения, обработка которых еще не была начата.
Но мы не хотим терять какие-либо задачи. Нам нужно, чтобы в случае аварийного выхода одного обработчика сообщение передавалось другому.
Чтобы мы могли быть уверенны в отсутствии потерянных сообщений, RabbitMQ поддерживает подтверждение сообщений. Подтверждение (ack) отправляется подписчиком для информирования RabbitMQ о том, что полученное сообщение было обработано и RabbitMQ может его удалить.
Если подписчик прекратил работу и не отправил подтверждение, RabbitMQ поймет, что сообщение не было обработано, и передаст его другому подписчику. Так Вы можете быть уверены, что ни одно сообщение не будет потеряно, даже если выполнение программы-обработчика неожиданно прекратилось.
Для обработки сообщений отсутствует тайм-аут. RabbitMQ передаст их другому подписчику только если соединение с первым будет закрыто, поэтому нет никаких ограничений на время обработки сообщения.
По умолчанию используется ручное подтверждение сообщений. В предыдущем примере мы принудительно включили автоматическое подтверждение сообщений, указав no_ack=True. Теперь мы уберем этот флаг и будем отправлять подтверждение из обработчика сразу после выполнения задачи.
def callback(ch, method, properties, body):
print " [x] Received %r" % (body,)
time.sleep( body.count('.') )
print " [x] Done"
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(callback,
queue='hello')
Теперь, даже если Вы остановите обработчика, нажав Ctrl+C во время обработки сообщения, ничто не будет утеряно. После остановки обработчика RabbitMQ заново передаст неподтвержденные сообщения.
Не забывайте подтверждать сообщения
Иногда разработчики забывают добавить в код basic_ack. Последствия этой небольшой ошибки могут быть существенными. Сообщение будет заново передано только тогда, когда программа-обработчик будет остановлена, но RabbitMQ будет потреблять все больше и больше памяти, т.к. не будет удалять неподтвержденные сообщения.
Для отладки такого рода ошибок Вы можете использовать rabbitmqctl для вывода на экран поля messages_unacknowledged (неподтвержденные сообщения):
$ sudo rabbitmqctl list_queues name messages_ready messages_unacknowledged
Listing queues ...
hello 0 0
...done.
[или воспользоваться более удобным скриптом мониторинга, который я приводил в первой части]
Устойчивость сообщений
Мы разобрались, как не потерять задачи, если подписчик неожиданно прекратил работу. Но задачи будут утеряны, если прекратит работу сервер RabbitMQ.
По умолчанию при остановке или падении сервера RabbitMQ все очереди и сообщения теряются, но это поведение можно изменить. Для того чтобы сообщения оставались в очереди после перезапуска сервера, необходимо сделать как очереди, так и сообщения устойчивыми.
Сначала убедимся, что не будет потеряна очередь. Для этого необходимо объявить ее, как устойчивую (durable):
channel.queue_declare(queue='hello', durable=True)
Хотя эта команда сама по себе правильная, сейчас она не будет работать, потому что очередь hello уже объявлена, как неустойчивая. RabbitMQ не позволяет переопределить параметры для уже существующей очереди и вернет ошибку при попытке это сделать. Но есть простой обходной путь ‒ давайте объявим очередь с другим именем, например, task_queue:
channel.queue_declare(queue='task_queue', durable=True)
Этот код необходимо исправить и для программы-поставщика, и для программы-подписчика.
Так мы можем быть уверены, что очередь task_queue не будет потеряна при перезапуске сервера RabbitMQ. Теперь необходимо пометить сообщения, как устойчивые. Для этого нужно передать свойство delivery_mode со значением 2:
channel.basic_publish(exchange='',
routing_key="task_queue",
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # make message persistent
))
Замечание по поводу устойчивости сообщений
Пометка сообщения, как устойчивого, не дает гарантии, что сообщение не будет утеряно. Не смотря на то, что это и заставляет RabbitMQ сохранять сообщение на диск, есть небольшой промежуток времени, когда RabbitMQ подтвердил принятие сообщения, но еще не записал его. Также RabbitMQ не делает fsync(2) для каждого сообщения, поэтому какие-то из них могут быть сохранены в кеш, но еще не записаны на диск. Гарантия устойчивости сообщений не полная, но ее более чем достаточно для нашей очереди задач. Если Вам требуется более высокая надежность, Вы можете оборачивать операции в транзакции.
Равномерное распределение сообщений
Вы, возможно, заметили, что распределение сообщений все еще работает не так, как нам нужно. Например, при работе двух подписчиков, если все нечетные сообщения содержат сложные задачи [требуют много времени на выполнение], а четные ‒ простые, то первый обработчик будет постоянно занят, а второй большую часть времени будет свободен. Но RabbitMQ об этом ничего не знает и все-равно будет передавать сообщения подписчикам по очереди.
Так происходит, потому что RabbitMQ распределяет сообщения в тот момент, когда они попадают в очередь, и не учитывает количество неподтвержденных сообщений у подписчиков. RabbitMQ просто отправляет каждое n-ое сообщение n-ому подписчику.
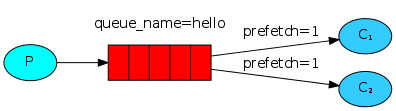
Для того чтобы изменить такое поведение, мы можем использовать метод basic_qos с опцией prefetch_count=1. Это заставит RabbitMQ не отдавать подписчику единовременно более одного сообщения. Другими словами, подписчик не получит новое сообщение, до тех пор пока не обработает и не подтвердит предыдущее. RabbitMQ передаст сообщение первому освободившемуся подписчику.
channel.basic_qos(prefetch_count=1)
Замечание по поводу размера очереди
Если все подписчики заняты, то размер очереди может увеличиваться. Следует обращать на это внимание и, возможно, увеличить количество подписчиков.
Ну а теперь все вместе
Полный код программы new_task.py:
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
message = ' '.join(sys.argv[1:]) or "Hello World!"
channel.basic_publish(exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # make message persistent
))
print " [x] Sent %r" % (message,)
connection.close()
Полный код программы worker.py:
#!/usr/bin/env python
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
print ' [*] Waiting for messages. To exit press CTRL+C'
def callback(ch, method, properties, body):
print " [x] Received %r" % (body,)
time.sleep( body.count('.') )
print " [x] Done"
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback,
queue='task_queue')
channel.start_consuming()
Используя подтверждение сообщений и prefetch_count, вы можете создать очередь задач. Настройка устойчивости позволит задачам сохраняться даже после перезапуска сервера RabbitMQ.
В третьем уроке мы разберем, как можно отправить одно сообщение нескольким подписчикам.
