Comments 14
Из статьи я уже было подумал, что TSQL оптимизатор настолько плох, что не умеет даже константы переводить в нужный тип до подстановки в запрос. Но быстрая проверка на запросах SELECT * FROM table WHERE id=1 и SELECT * FROM table WHERE id='1' показала, что это не так.
А вот, кстати, да. Тут надо будет покопать. Если выполнять пример из статьи — все будет как описано — Index Scan с неверным типом и Index Seek с правильным.
www.ozon.ru/context/detail/id/1895036/
Книга называется «Настройка SQL. Для профессионалов», а в реальности посвящена авторскому методу тюнинга sql-запросов не по наитию в стиле «так, напишем здесь where вместо join, а еще индекс добавим, и еще раз посмотрим план», а строго детерменированно: посмотрели план, построили схемку, основанную на числе записей и статистике, приказали оптимизатору выбрать именно этот хороший план.
И вот как раз одним из средств заставить оптимизатор убрать, например, использование лишнего индекса, и является использование неправильных типов данных, например
where concat(str,'')='value' для отключения индекса по строковому полю или
where mul(int,1) =100 для числового.
Книга называется «Настройка SQL. Для профессионалов», а в реальности посвящена авторскому методу тюнинга sql-запросов не по наитию в стиле «так, напишем здесь where вместо join, а еще индекс добавим, и еще раз посмотрим план», а строго детерменированно: посмотрели план, построили схемку, основанную на числе записей и статистике, приказали оптимизатору выбрать именно этот хороший план.
И вот как раз одним из средств заставить оптимизатор убрать, например, использование лишнего индекса, и является использование неправильных типов данных, например
where concat(str,'')='value' для отключения индекса по строковому полю или
where mul(int,1) =100 для числового.
Ага, нашел. Все зависит от приоритетов типов данных. Типы данных с более низким приоритетом, приводятся к типам с более высоким. В статье тип столбца nvarchar (практически самый низкий приоритет), соответственно он приводится к более высокому int'у. В вашем примере все тоже самое.
В примере с вьюхами запрос через вьюху и напрямую — разные. Потому что с вьюхами надо проверять что связанные записи есть, даже если данные из них не нужны. Интересно что сделает оптимизатор если навтыкать left join-ов?
Дак, как бы, в том и смысл, что когда пишем запрос вручную — мы не втыкаем лишние соединения, а когда «относимся ко вьюхам как к таблицам» и выбираем данные из вьюх — от них никуда не денешься.
Если навтыкать соединений — план будет точно такой же, как у запроса из вьюх, поскольку они все равно «разворачиваются» до запросов.
Или я вас не правильно понял?
Если навтыкать соединений — план будет точно такой же, как у запроса из вьюх, поскольку они все равно «разворачиваются» до запросов.
Или я вас не правильно понял?
Вьюхи — отличное средство абстракции и повторного использования кода. К тому же они, в отличии от тех же UDF и хранимок, отлично вписываются в реляционную модель. Учить людей сразу вот так их не использовать, потому что оптимизатор тупой — зло.
Через это я считаю что с этим примером надо бы получше разобраться. В данном случае запросы, очевидно, не идентичные. В примере в вьюхами базе надо убедиться что записи в связанных таблицах есть. В примере с таблицей этого не делается. Т.е. теоретически эти запросы могут вести себя по-разному. Можно попробовать во вьюхах сделать left join-ы, чтобы поставить примеры в одинаковое положение.
Дальше нужно еще посмотреть влияют ли в такой ситуации foreign keys — сможет ли оптимизатор допереть что если у него поля из связанных таблиц не нужны, и на них сделаны внешние ключи, то можно не ходить и не проверять наличие связанных записей.
Если это все, в случае конкретной базы, не прокатит — надо так и писать: аккуратнее в вьюхами, вот такую-то очевидную вещь оптимизатор не делает, потому-то и потому-то; советуем делать так-то. А не показывать что вьюхи — зло и рекомендовать плодить копипасту.
Через это я считаю что с этим примером надо бы получше разобраться. В данном случае запросы, очевидно, не идентичные. В примере в вьюхами базе надо убедиться что записи в связанных таблицах есть. В примере с таблицей этого не делается. Т.е. теоретически эти запросы могут вести себя по-разному. Можно попробовать во вьюхах сделать left join-ы, чтобы поставить примеры в одинаковое положение.
Дальше нужно еще посмотреть влияют ли в такой ситуации foreign keys — сможет ли оптимизатор допереть что если у него поля из связанных таблиц не нужны, и на них сделаны внешние ключи, то можно не ходить и не проверять наличие связанных записей.
Если это все, в случае конкретной базы, не прокатит — надо так и писать: аккуратнее в вьюхами, вот такую-то очевидную вещь оптимизатор не делает, потому-то и потому-то; советуем делать так-то. А не показывать что вьюхи — зло и рекомендовать плодить копипасту.
Тоже сразу подумал что последние запросы не идентичны. Тем более не принимается во внимание, что это могут быть индексированные представления, при этом если использовать «злые хинты» типа noexpand, то оптимизатор не будет разворачивать запрос и считать план, а сразу использует индексы.
То что вьюхи полезны — я не спорю и рассматривать нужно каждый случай отдельно. Вполне вероятно, что автор самой статьи тоже не против такого подхода.
Возможно, это моя вина, как переводчика, что я не смог этого передать — читая саму статью, у меня не возникало мыслей, что от представлений вообще надо отказываться. Сорри.
Теперь к примеру.
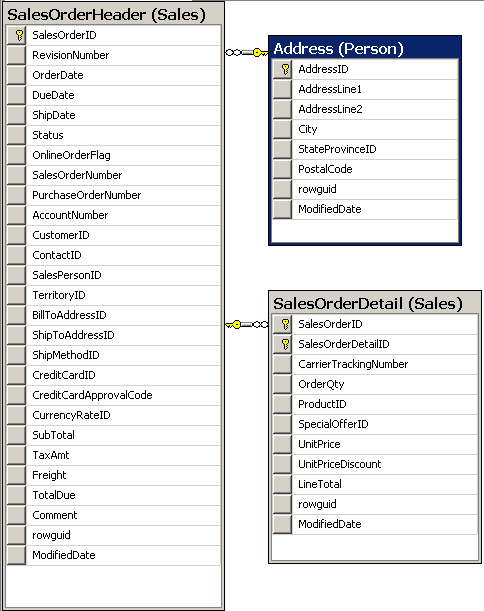
Вот диаграмма с этими таблицами — FK есть.
Теперь запросы:
Время выполнения 74 миллисекунды, 960 операций чтения.
Время выполнения 59 мс, 703 операции чтения
Вместо внутреннего, LEFT JOIN:
Время выполнения 70 мс, 931 операция чтения.
Скриншот с актуальными планами выполнения (они идут в том же порядке, как у меня перечислены запросы):
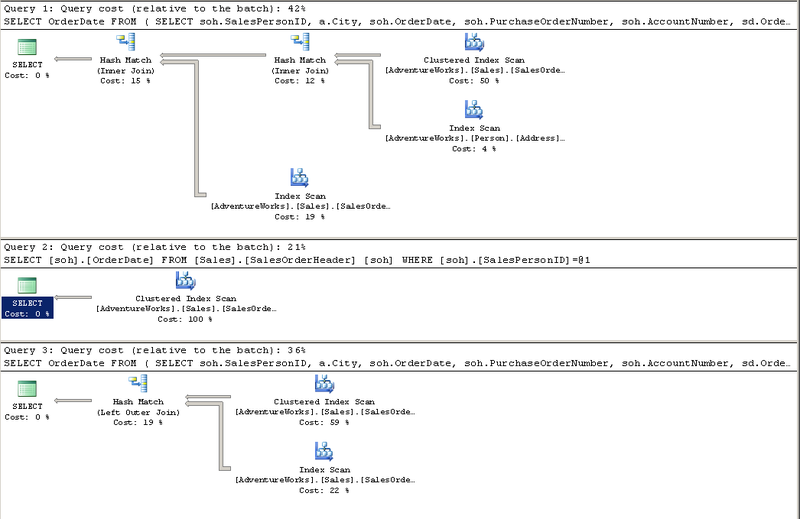
Не смотря на то, что выигрыш не настолько велик, как в оригинале, но он все равно есть. Мне кажется, что Грант (автор), поторопился с примером. Поскольку мне пришлось удалить данные из таблицы SalesOrderDetail — так, чтобы одной записи из SalesOrderHeader соответствовала одна запись из SalesOrderDeatil, иначе результаты запросов были разными.
Возможно, это моя вина, как переводчика, что я не смог этого передать — читая саму статью, у меня не возникало мыслей, что от представлений вообще надо отказываться. Сорри.
Теперь к примеру.
Вот диаграмма с этими таблицами — FK есть.

Теперь запросы:
SELECT OrderDate
FROM
(
SELECT soh.SalesPersonID,
a.City,
soh.OrderDate,
soh.PurchaseOrderNumber,
soh.AccountNumber,
sd.OrderQty,
sd.UnitPrice
FROM Sales.SalesOrderHeader AS soh
JOIN Person.Address AS a
ON soh.ShipToAddressID = a.AddressID
JOIN Sales.SalesOrderDetail AS sd
ON soh.SalesOrderID = sd.SalesOrderID
)temp
WHERE SalesPersonID=277
Время выполнения 74 миллисекунды, 960 операций чтения.
SELECT soh.OrderDate
FROM Sales.SalesOrderHeader AS soh
WHERE soh.SalesPersonID = 277 ;
Время выполнения 59 мс, 703 операции чтения
Вместо внутреннего, LEFT JOIN:
SELECT OrderDate
FROM
(
SELECT soh.SalesPersonID,
a.City,
soh.OrderDate,
soh.PurchaseOrderNumber,
soh.AccountNumber,
sd.OrderQty,
sd.UnitPrice
FROM Sales.SalesOrderHeader AS soh
LEFT JOIN Person.Address AS a
ON soh.ShipToAddressID = a.AddressID
LEFT JOIN Sales.SalesOrderDetail AS sd
ON soh.SalesOrderID = sd.SalesOrderID
)temp
WHERE SalesPersonID=277
Время выполнения 70 мс, 931 операция чтения.
Скриншот с актуальными планами выполнения (они идут в том же порядке, как у меня перечислены запросы):

Не смотря на то, что выигрыш не настолько велик, как в оригинале, но он все равно есть. Мне кажется, что Грант (автор), поторопился с примером. Поскольку мне пришлось удалить данные из таблицы SalesOrderDetail — так, чтобы одной записи из SalesOrderHeader соответствовала одна запись из SalesOrderDeatil, иначе результаты запросов были разными.
Как-то я прощелкал что там 1-ко-многим связь, а не 1-в-1. Тут никакие FK и left join-ы не помогут. Т.е. пример совсем какой-то плохой, т.к. сравниваются получается совершенно разные запросы.
А можешь еще плиз убрать sales order detail из последнего запроса? Это по-идее сделает запросы одинаковыми по смыслу.
В таком раскладе будет только одна связь многие-к-одному с Person.Address. Т.к. есть FK сервер по-идее будет знать что запись там точно есть. В результате план должен получиться по-идее такой же, как в запросе на одну табличку.
В таком раскладе будет только одна связь многие-к-одному с Person.Address. Т.к. есть FK сервер по-идее будет знать что запись там точно есть. В результате план должен получиться по-идее такой же, как в запросе на одну табличку.
Благодарю за понятное изложение. Основной смысл — не мудрить и смотреть план выполнения.
Sign up to leave a comment.
Семь смертных грехов программиста на T-SQL