Это перевод и форма повествования от первого лица сохранена. Автор — Бен Бойтер, бакалавр информационных технологий в Университете Чарльза Стерта (CSU).

Большинство людей не в курсе, но моей диссертацией была программа для чтения текста с изображения. Я думал, что, если смогу получить высокий уровень распознавания, то это можно будет использовать для улучшения результатов поиска. Мой отличный советник доктор Гао Джунбин предложил мне написать диссертацию на эту тему. Наконец-то я нашел время написать эту статью и здесь я постараюсь рассказать о всем том, что узнал. Если бы только было что-то подобное, когда я только начинал…
Как я уже говорил, я пытался взять обычные изображения из интернета и извлекать из них текст для улучшения результатов поиска. Большинство моих идей было основано на методах взлома капчи. Как всем известно, капча — это те самые всех раздражающее штуки, вроде «Введите буквы, которые вы видите на изображении» на страницах регистрации или обратной связи.
Капча устроена так, что человек может прочитать текст без труда, в то время, как машина — нет (привет, reCaptcha!). На практике это никогда не работало, т. к. почти каждую капчу, которую размещали на сайте взламывали в течение нескольких месяцев.
У меня неплохо получалось — более 60% изображений было успешно разгадано из моей небольшой коллекции. Довольно неплохо, учитывая количество разнообразных изображений в интернете.
При своем исследовании я не нашел никаких материалов, которые помогли бы мне. Да, статьи есть, но в них опубликованы очень простые алгоритмы. На самом деле я нашел несколько нерабочих примеров на PHP и Perl, взял из них несколько фрагментов и получил неплохие результаты для очень простой капчи. Но ни один из них мне особо не помог, т. к. это было слишком просто. Я из тех людей, которые могут читать теорию, но ничего не понять без реальных примеров. А в большинстве статей писалось, что они не будут публиковать код, т. к. боятся, что его будут использовать в плохих целях. Лично я думаю, что капча – это пустая трата времени, т. к. ее довольно легко обойти, если знать как.
Собственно по причине отсутствия каких-то материалов, показывающих взлом капчи для начинающих я и написал эту статью.
Давайте начнем. Вот список того, что я собираюсь осветить в этой статье:
Все примеры написаны на Python 2.5 с использованием библиотеки PIL. Должно работать и в Python 2.6 (под Python 2.7.3 отлично запускается, прим. перев.).
Установите их в указанном выше порядке и вы готовы к запуску примеров.
В примерах я буду жестко задавать множество значений прямо в коде. У меня нет цели создать универсальный распознаватель капч, а только показать как это делается.
В основном капча является примером одностороннего преобразования. Вы можете легко взять набор символов и получить из него капчу, но не наоборот. Другая тонкость – она должна быть простая для чтения человеком, но не поддаваться машинному распознаванию. Капча может рассматриваться как простой тест типа «Вы человек?». В основном они реализуются как изображение с какими-то символами или словами.
Они используются для предотвращения спама на многих интернет-сайтах. Например, капчу можно найти на странице регистрации в Windows Live ID.
Вам показывают изображение, и, если вы действительно человек, то вам нужно ввести его текст в отдельное поле. Кажется неплохой идеей, которая может защитить вас от тысяч автоматических регистраций с целью спама или распространения виагры на вашем форуме? Проблема в том, что ИИ, а в частности методы распознавания изображений претерпели значительные изменения и становятся очень эффективными в определенных областях. OCR (оптическое распознавание символов) в наши дни является довольно точным и легко распознает печатный текст. Было принято решение добавить немного цвета и линий, чтобы затруднить работу компьютеру без каких-то неудобств для пользователей. Это своего рода гонка вооружений и как обычно на любую защиту придумывают более сильное оружие. Победить усиленную капчу сложнее, но все равно возможно. Плюс ко всему изображение должно оставаться довольно простым, чтобы не вызывать раздражение у обычных людей.
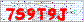
Это изображение является примером капчи, которую мы будем расшифровывать. Это реальная капча, которая размещена на реальном сайте.
Это довольно простая капча, которая состоит из символов одинакового цвета и размера на белом фоне с некоторым шумом (пиксели, цвета, линии). Вы думаете, что этот шум на заднем плане затруднит распознавание, но я покажу, как его легко удалить. Хоть это и не очень сильная капча, но она является хорошим примером для нашей программы.
Существует много методов для определения положения текста на изображении и его извлечения. С помощью Google вы можете найти тысячи статей, которые объясняют новые методы и алгоритмы для поиска текста.
Для этого примера я буду использовать извлечение цвета. Это довольно простая техника, с помощью которой я получил довольно неплохие результаты. Именно эту технику я использовал для своей диссертации.
Для наших примеров я буду использовать алгоритм многозначного разложения изображения. По сути, это означает, что мы сначала построим гистограмму цветов изображения. Это делается путем получения всех пикселей в изображении с группировкой по цвету, после чего производится подсчет по каждой группе. Если посмотреть на нашу тестовую капчу, то можно увидеть три основных цвета:
На Python это будет выглядеть очень просто.
Следующий код открывает изображение, преобразует его в GIF (облегчает нам работу, т. к. в нем всего 255 цветов) с печатает гистограмму цветов.
В итоге мы получим следующее:
Здесь мы видем количество пикселей каждого из 255 цветов в изображении. Вы можете увидеть, что белый (255, самый последний) встречается чаще всего. За ним идет красный (текст). Чтобы убедиться в этом, напишем небольшой скрипт:
И получаем такие данные:
Это список из 10 наиболее распространенных цветов в изображении. Как ожидалось, белый повторяется чаще всего. Затем идут серый и красный.
Как только мы получили эту информацию, мы создаем новые изображения, основанные на этих цветовых группах. Для каждого из наиболее распространенных цветов мы создаем новое бинарное изображение (из 2 цветов), где пиксели этого цвета заполняется черным, а все остальное белым.
Красный у нас стал третьем среди наиболее распространенных цветов и это означает, что мы хотим сохранить группу пикселей с цветом 220. Когда я экспериментировал я обнаружил, что цвет 227 довольно близок к 220, так что мы сохраним и эту группу пикселей. Приведенный ниже код открывает капчу, преобразует ее в GIF, создает новое изображение такого же размера с белым фоном, а затем обходит оригинальное изображение в поисках нужного нам цвета. Если он находит пиксель с нужным нам цветом, то он отмечает этот же пиксель на втором изображении черным цветом. Перед завершением работы второе изображение сохраняется.
Запуск этого фрагмента кода дает нам следующий результат.
На картинке вы можете увидеть, что у нас успешно получилось извлечь текст из фона. Чтобы автоматизировать этот процесс вы можете совместить первый и второй скрипт.
Слышу, как спрашиваете: «А что, если на капче текст написан разными цветами?». Да, наша техника все еще сможет работать. Предположите, что наиболее распространенный цвет – это цвет фона и тогда вы сможете найти цвета символов.
Таким образом, на данный момент мы успешно извлекли текст из изображения. Следующим шагом будет определение того, содержит ли изображение текст. Я пока не буду писать здесь код, т. к. это сделает понимание сложным, в то время как сам алгоритм довольно прост.
На выходе у вас будет набор границ символов. Тогда все, что вам нужно будет сделать – это сравнить их между собой и посмотреть, идут ли они последовательно. Если да, то вам выпал джек-пот и вы правильно определили символы, идущие рядом. Вы так же можете проверять размеры полученных областей или просто создавать новое изображение и показывать его (метод
В результате у нас получалось следующее:
Это позиции по горизонтали начала и конца каждого символа.
Распознавание изображений можно считать самым большим успехом современного ИИ, что позволило ему внедриться во все виды коммерческих приложений. Прекрасным примером этого являются почтовые индексы. На самом деле во многих странах они читаются автоматически, т. к. научить компьютер распознавать номера довольно простая задача. Это может быть не очевидно, но распознавание образов считается проблемой ИИ, хоть и очень узкоспециализированной.
Чуть ли ни первой вещью, с которой сталкиваются при знакомстве с ИИ в распознавании образов являются нейронные сети. Лично я никогда не имел успеха с нейронными сетями при распознавании символов. Я обычно обучаю его 3-4 символам, после чего точность падает так низко, что она была бы на порядок выше, отгадывай я символы случайным образом. Сначала это вызвало у меня легкую панику, т. к. это было тем самым недостающем звеном в моей диссертации. К счастью, недавно я прочитал статью о vector-space поисковых системах и посчитал их альтернативным методом классификации данных. В конце концов они оказались лучшем выбором, т. к.
Конечно, бесплатного сыра не бывает. Главный недостаток в скорости. Они могут быть намного медленнее нейронных сетей. Но я думаю, что их плюсы все же перевешивают этот недостаток.
Если хотите понять, как работает векторное пространство, то советую почитать Vector Space Search Engine Theory. Это лучшее, что я нашел для начинающих.
Я построил свое распознавание изображений на основе вышеупомянутого документа и это было первой вещью, которую я попробовал написать на любимом ЯП, который я в это время изучал. Прочитайте этот документ и как вы поймете его суть – возвращайтесь сюда.
Уже вернулись? Хорошо. Теперь мы должны запрограммировать наше векторное пространство. К счастью, это совсем не сложно. Приступим.
Это реализация векторного пространства на Python в 15 строк. По существу оно просто принимает 2 словаря и выдает число от 0 до 1, указывающее как они связаны. 0 означает, что они не связаны, а 1, что они идентичны.
Следующее, что нам нужно – это набор изображений, с которыми мы будем сравнивать наши символы. Нам нужно обучающее множество. Это множество может быть использовано для обучения любого рода ИИ, который мы будем использовать (нейронные сети и т. д.).
Используемые данные могут быть судьбоносными для успешности распознавания. Чем лучше данные, тем больше шансов на успех. Так как мы планируем распознавать конкретную капчу и уже можем извлечь из нее символы, то почему бы не использовать их в качестве обучающего множества?
Это я и сделал. Я скачал много сгенерированных капч и моя программа разбила их на буквы. Тогда я собрал полученные изображения в коллекции (группы). После нескольких попыток у меня было по крайней мере один пример каждого символа, которые генерировала капча. Добавление большего количества примеров повысит точность распознавания, но мне хватило и этого для подтверждения моей теории.
На выходе мы получаем набор изображений в этой же директории. Каждому из них присваивается уникальных хеш на случай, если вы будете обрабатывать несколько капч.
Вот результат этого кода для нашей тестовой капчи:
Вы сами решаете, как хранить эти изображения, но я просто поместил их в директории с тем же именем, что находится на изображении (символ или цифра).
Последний шаг. У нас есть извлекание текста, извлекание символов, техника распознавания и обучающее множество.
Мы получаем изображение капчи, выделяем текст, получаем символы, а затем сравниванием их с нашим обучающим множеством. Вы можете скачать окончательную программу с обучающим множеством и небольшим количеством капч по этой ссылке.
Здесь мы просто загружаем обучающее множество, чтобы иметь возможность сравнивать с ним:
А тут уже происходит все волшебство. Мы определяем, где находится каждый символ и проверяем его с помощью нашего векторного пространства. Затем сортируем результаты и печатаем их.
Теперь у нас есть все, что нужно и мы можем попробовать запустить нашу чудо-машину.
Входной файл –
Здесь мы видем предполагаемый символ и степень уверенности в том, что это действительно он (от 0 до 1).
Похоже, что у нас действительно все получилось!
На самом деле на тестовых капчах данный скрипт будет выдавать успешный результат примерно в 22% случаев (у меня получилось 28.5, прим. перев.).
Большинство неверных результатов приходится на неправильное распознаваине цифры «0» и буквы «О». Нет ничего неожиданного, т. к. даже люди их часто путают. У нас еще есть проблема с разбиванием на символы, но это можно решить просто проверив результат разбиения и найдя золотую середину.
Однако, даже с таким не очень совершенным алгоритмом мы можем разгадывать каждую пятую капчу за такое время, где человек не успел бы разгадать и одну.
Выполнение этого кода на Core 2 Duo E6550 дает следующие результаты:
От переводчика. У меня на Dual Core T4400 получились следующие результаты:
В нашем каталоге находится 48 капч, из чего следует, что на разгадывание одной уходит примерно 0.12 секунд. С нашими 22% процентами успешного разгадывания мы можем разгадывать около 432 000 капч в день и получать 95 040 правильных результатов. А если использовать многопоточность?
Вот и все. Надеюсь, что мой опыт будет использован вами в хороших целях. Я знаю, что вы можете использовать этот код во вред, но чтобы сделать действительно нечто опасное вы должны довольно сильно его изменить.
Для тех, кто пытается защитить себя капчей я могу сказать, что это вам не сильно поможет, т. к. их можно обойти программно или просто платить другим людям, которые будут разгадывать их вручную. Подумайте над другими способами защиты.

Большинство людей не в курсе, но моей диссертацией была программа для чтения текста с изображения. Я думал, что, если смогу получить высокий уровень распознавания, то это можно будет использовать для улучшения результатов поиска. Мой отличный советник доктор Гао Джунбин предложил мне написать диссертацию на эту тему. Наконец-то я нашел время написать эту статью и здесь я постараюсь рассказать о всем том, что узнал. Если бы только было что-то подобное, когда я только начинал…
Как я уже говорил, я пытался взять обычные изображения из интернета и извлекать из них текст для улучшения результатов поиска. Большинство моих идей было основано на методах взлома капчи. Как всем известно, капча — это те самые всех раздражающее штуки, вроде «Введите буквы, которые вы видите на изображении» на страницах регистрации или обратной связи.
Капча устроена так, что человек может прочитать текст без труда, в то время, как машина — нет (привет, reCaptcha!). На практике это никогда не работало, т. к. почти каждую капчу, которую размещали на сайте взламывали в течение нескольких месяцев.
У меня неплохо получалось — более 60% изображений было успешно разгадано из моей небольшой коллекции. Довольно неплохо, учитывая количество разнообразных изображений в интернете.
При своем исследовании я не нашел никаких материалов, которые помогли бы мне. Да, статьи есть, но в них опубликованы очень простые алгоритмы. На самом деле я нашел несколько нерабочих примеров на PHP и Perl, взял из них несколько фрагментов и получил неплохие результаты для очень простой капчи. Но ни один из них мне особо не помог, т. к. это было слишком просто. Я из тех людей, которые могут читать теорию, но ничего не понять без реальных примеров. А в большинстве статей писалось, что они не будут публиковать код, т. к. боятся, что его будут использовать в плохих целях. Лично я думаю, что капча – это пустая трата времени, т. к. ее довольно легко обойти, если знать как.
Собственно по причине отсутствия каких-то материалов, показывающих взлом капчи для начинающих я и написал эту статью.
Давайте начнем. Вот список того, что я собираюсь осветить в этой статье:
- Используемые технологии
- Что такое капча
- Как найти и извлечь текст из изображений
- Распознавание изображения с использованием ИИ
- Обучение
- Собираем все вместе
- Результаты и выводы
Используемые технологии
Все примеры написаны на Python 2.5 с использованием библиотеки PIL. Должно работать и в Python 2.6 (под Python 2.7.3 отлично запускается, прим. перев.).
- Python: www.python.org
- PIL: www.pythonware.com/products/pil
Установите их в указанном выше порядке и вы готовы к запуску примеров.
Отступление
В примерах я буду жестко задавать множество значений прямо в коде. У меня нет цели создать универсальный распознаватель капч, а только показать как это делается.
Капча, что это такое в конце концов?
В основном капча является примером одностороннего преобразования. Вы можете легко взять набор символов и получить из него капчу, но не наоборот. Другая тонкость – она должна быть простая для чтения человеком, но не поддаваться машинному распознаванию. Капча может рассматриваться как простой тест типа «Вы человек?». В основном они реализуются как изображение с какими-то символами или словами.
Они используются для предотвращения спама на многих интернет-сайтах. Например, капчу можно найти на странице регистрации в Windows Live ID.
Вам показывают изображение, и, если вы действительно человек, то вам нужно ввести его текст в отдельное поле. Кажется неплохой идеей, которая может защитить вас от тысяч автоматических регистраций с целью спама или распространения виагры на вашем форуме? Проблема в том, что ИИ, а в частности методы распознавания изображений претерпели значительные изменения и становятся очень эффективными в определенных областях. OCR (оптическое распознавание символов) в наши дни является довольно точным и легко распознает печатный текст. Было принято решение добавить немного цвета и линий, чтобы затруднить работу компьютеру без каких-то неудобств для пользователей. Это своего рода гонка вооружений и как обычно на любую защиту придумывают более сильное оружие. Победить усиленную капчу сложнее, но все равно возможно. Плюс ко всему изображение должно оставаться довольно простым, чтобы не вызывать раздражение у обычных людей.
Это изображение является примером капчи, которую мы будем расшифровывать. Это реальная капча, которая размещена на реальном сайте.
Это довольно простая капча, которая состоит из символов одинакового цвета и размера на белом фоне с некоторым шумом (пиксели, цвета, линии). Вы думаете, что этот шум на заднем плане затруднит распознавание, но я покажу, как его легко удалить. Хоть это и не очень сильная капча, но она является хорошим примером для нашей программы.
Как найти и извлечь текст из изображений
Существует много методов для определения положения текста на изображении и его извлечения. С помощью Google вы можете найти тысячи статей, которые объясняют новые методы и алгоритмы для поиска текста.
Для этого примера я буду использовать извлечение цвета. Это довольно простая техника, с помощью которой я получил довольно неплохие результаты. Именно эту технику я использовал для своей диссертации.
Для наших примеров я буду использовать алгоритм многозначного разложения изображения. По сути, это означает, что мы сначала построим гистограмму цветов изображения. Это делается путем получения всех пикселей в изображении с группировкой по цвету, после чего производится подсчет по каждой группе. Если посмотреть на нашу тестовую капчу, то можно увидеть три основных цвета:
- Белый (фон)
- Серый (шум)
- Красный (текст)
На Python это будет выглядеть очень просто.
Следующий код открывает изображение, преобразует его в GIF (облегчает нам работу, т. к. в нем всего 255 цветов) с печатает гистограмму цветов.
from PIL import Image
im = Image.open("captcha.gif")
im = im.convert("P")
print im.histogram()
В итоге мы получим следующее:
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0
, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0,
1, 0, 0, 2, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 2, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1,
0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 2, 1, 0, 0, 0, 2, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0
, 1, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0, 0, 1, 2, 0, 1, 0, 0, 1,
0, 2, 0, 0, 1, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 3, 1, 3, 3, 0,
0, 0, 0, 0, 0, 1, 0, 3, 2, 132, 1, 1, 0, 0, 0, 1, 2, 0, 0, 0, 0, 0, 0, 0, 15, 0
, 1, 0, 1, 0, 0, 8, 1, 0, 0, 0, 0, 1, 6, 0, 2, 0, 0, 0, 0, 18, 1, 1, 1, 1, 1, 2,
365, 115, 0, 1, 0, 0, 0, 135, 186, 0, 0, 1, 0, 0, 0, 116, 3, 0, 0, 0, 0, 0, 21,
1, 1, 0, 0, 0, 2, 10, 2, 0, 0, 0, 0, 2, 10, 0, 0, 0, 0, 1, 0, 625]
Здесь мы видем количество пикселей каждого из 255 цветов в изображении. Вы можете увидеть, что белый (255, самый последний) встречается чаще всего. За ним идет красный (текст). Чтобы убедиться в этом, напишем небольшой скрипт:
from PIL import Image
from operator import itemgetter
im = Image.open("captcha.gif")
im = im.convert("P")
his = im.histogram()
values = {}
for i in range(256):
values[i] = his[i]
for j,k in sorted(values.items(), key=itemgetter(1), reverse=True)[:10]:
print j,k
И получаем такие данные:
| Цвет | Количество пикселей |
|---|---|
| 255 | 625 |
| 212 | 365 |
| 220 | 186 |
| 219 | 135 |
| 169 | 132 |
| 227 | 116 |
| 213 | 115 |
| 234 | 21 |
| 205 | 18 |
| 184 | 15 |
Это список из 10 наиболее распространенных цветов в изображении. Как ожидалось, белый повторяется чаще всего. Затем идут серый и красный.
Как только мы получили эту информацию, мы создаем новые изображения, основанные на этих цветовых группах. Для каждого из наиболее распространенных цветов мы создаем новое бинарное изображение (из 2 цветов), где пиксели этого цвета заполняется черным, а все остальное белым.
Красный у нас стал третьем среди наиболее распространенных цветов и это означает, что мы хотим сохранить группу пикселей с цветом 220. Когда я экспериментировал я обнаружил, что цвет 227 довольно близок к 220, так что мы сохраним и эту группу пикселей. Приведенный ниже код открывает капчу, преобразует ее в GIF, создает новое изображение такого же размера с белым фоном, а затем обходит оригинальное изображение в поисках нужного нам цвета. Если он находит пиксель с нужным нам цветом, то он отмечает этот же пиксель на втором изображении черным цветом. Перед завершением работы второе изображение сохраняется.
from PIL import Image
im = Image.open("captcha.gif")
im = im.convert("P")
im2 = Image.new("P",im.size,255)
im = im.convert("P")
temp = {}
for x in range(im.size[1]):
for y in range(im.size[0]):
pix = im.getpixel((y,x))
temp[pix] = pix
if pix == 220 or pix == 227: # these are the numbers to get
im2.putpixel((y,x),0)
im2.save("output.gif")
Запуск этого фрагмента кода дает нам следующий результат.
| Оригинал | Результат |
|
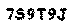 |
На картинке вы можете увидеть, что у нас успешно получилось извлечь текст из фона. Чтобы автоматизировать этот процесс вы можете совместить первый и второй скрипт.
Слышу, как спрашиваете: «А что, если на капче текст написан разными цветами?». Да, наша техника все еще сможет работать. Предположите, что наиболее распространенный цвет – это цвет фона и тогда вы сможете найти цвета символов.
Таким образом, на данный момент мы успешно извлекли текст из изображения. Следующим шагом будет определение того, содержит ли изображение текст. Я пока не буду писать здесь код, т. к. это сделает понимание сложным, в то время как сам алгоритм довольно прост.
for each binary image:
for each pixel in the binary image:
if the pixel is on:
if any pixel we have seen before is next to it:
add to the same set
else:
add to a new set
На выходе у вас будет набор границ символов. Тогда все, что вам нужно будет сделать – это сравнить их между собой и посмотреть, идут ли они последовательно. Если да, то вам выпал джек-пот и вы правильно определили символы, идущие рядом. Вы так же можете проверять размеры полученных областей или просто создавать новое изображение и показывать его (метод
show() у изображения), чтобы убедиться в точности алгоритма.from PIL import Image
im = Image.open("captcha.gif")
im = im.convert("P")
im2 = Image.new("P",im.size,255)
im = im.convert("P")
temp = {}
for x in range(im.size[1]):
for y in range(im.size[0]):
pix = im.getpixel((y,x))
temp[pix] = pix
if pix == 220 or pix == 227: # these are the numbers to get
im2.putpixel((y,x),0)
# new code starts here
inletter = False
foundletter=False
start = 0
end = 0
letters = []
for y in range(im2.size[0]): # slice across
for x in range(im2.size[1]): # slice down
pix = im2.getpixel((y,x))
if pix != 255:
inletter = True
if foundletter == False and inletter == True:
foundletter = True
start = y
if foundletter == True and inletter == False:
foundletter = False
end = y
letters.append((start,end))
inletter=False
print letters
В результате у нас получалось следующее:
[(6, 14), (15, 25), (27, 35), (37, 46), (48, 56), (57, 67)]
Это позиции по горизонтали начала и конца каждого символа.
ИИ и векторное пространство при распознавании образов
Распознавание изображений можно считать самым большим успехом современного ИИ, что позволило ему внедриться во все виды коммерческих приложений. Прекрасным примером этого являются почтовые индексы. На самом деле во многих странах они читаются автоматически, т. к. научить компьютер распознавать номера довольно простая задача. Это может быть не очевидно, но распознавание образов считается проблемой ИИ, хоть и очень узкоспециализированной.
Чуть ли ни первой вещью, с которой сталкиваются при знакомстве с ИИ в распознавании образов являются нейронные сети. Лично я никогда не имел успеха с нейронными сетями при распознавании символов. Я обычно обучаю его 3-4 символам, после чего точность падает так низко, что она была бы на порядок выше, отгадывай я символы случайным образом. Сначала это вызвало у меня легкую панику, т. к. это было тем самым недостающем звеном в моей диссертации. К счастью, недавно я прочитал статью о vector-space поисковых системах и посчитал их альтернативным методом классификации данных. В конце концов они оказались лучшем выбором, т. к.
- Они не требуют обширного изучения
- Вы можете добавлять/удалять неправильные данные и сразу видеть результат
- Их легче понять и запрограммировать
- Они обеспечивают классифицированные результаты, таким образом вы сможете видеть топ X совпадений
- Не можете что-то распознать? Добавьте это и вы сможете разпознать это моментально, даже если оно полностью отличается от чего-то замеченного ранее.
Конечно, бесплатного сыра не бывает. Главный недостаток в скорости. Они могут быть намного медленнее нейронных сетей. Но я думаю, что их плюсы все же перевешивают этот недостаток.
Если хотите понять, как работает векторное пространство, то советую почитать Vector Space Search Engine Theory. Это лучшее, что я нашел для начинающих.
Я построил свое распознавание изображений на основе вышеупомянутого документа и это было первой вещью, которую я попробовал написать на любимом ЯП, который я в это время изучал. Прочитайте этот документ и как вы поймете его суть – возвращайтесь сюда.
Уже вернулись? Хорошо. Теперь мы должны запрограммировать наше векторное пространство. К счастью, это совсем не сложно. Приступим.
import math
class VectorCompare:
def magnitude(self,concordance):
total = 0
for word,count in concordance.iteritems():
total += count ** 2
return math.sqrt(total)
def relation(self,concordance1, concordance2):
relevance = 0
topvalue = 0
for word, count in concordance1.iteritems():
if concordance2.has_key(word):
topvalue += count * concordance2[word]
return topvalue / (self.magnitude(concordance1) * self.magnitude(concordance2))
Это реализация векторного пространства на Python в 15 строк. По существу оно просто принимает 2 словаря и выдает число от 0 до 1, указывающее как они связаны. 0 означает, что они не связаны, а 1, что они идентичны.
Обучение
Следующее, что нам нужно – это набор изображений, с которыми мы будем сравнивать наши символы. Нам нужно обучающее множество. Это множество может быть использовано для обучения любого рода ИИ, который мы будем использовать (нейронные сети и т. д.).
Используемые данные могут быть судьбоносными для успешности распознавания. Чем лучше данные, тем больше шансов на успех. Так как мы планируем распознавать конкретную капчу и уже можем извлечь из нее символы, то почему бы не использовать их в качестве обучающего множества?
Это я и сделал. Я скачал много сгенерированных капч и моя программа разбила их на буквы. Тогда я собрал полученные изображения в коллекции (группы). После нескольких попыток у меня было по крайней мере один пример каждого символа, которые генерировала капча. Добавление большего количества примеров повысит точность распознавания, но мне хватило и этого для подтверждения моей теории.
from PIL import Image
import hashlib
import time
im = Image.open("captcha.gif")
im2 = Image.new("P",im.size,255)
im = im.convert("P")
temp = {}
print im.histogram()
for x in range(im.size[1]):
for y in range(im.size[0]):
pix = im.getpixel((y,x))
temp[pix] = pix
if pix == 220 or pix == 227: # these are the numbers to get
im2.putpixel((y,x),0)
inletter = False
foundletter=False
start = 0
end = 0
letters = []
for y in range(im2.size[0]): # slice across
for x in range(im2.size[1]): # slice down
pix = im2.getpixel((y,x))
if pix != 255:
inletter = True
if foundletter == False and inletter == True:
foundletter = True
start = y
if foundletter == True and inletter == False:
foundletter = False
end = y
letters.append((start,end))
inletter=False
# New code is here. We just extract each image and save it to disk with
# what is hopefully a unique name
count = 0
for letter in letters:
m = hashlib.md5()
im3 = im2.crop(( letter[0] , 0, letter[1],im2.size[1] ))
m.update("%s%s"%(time.time(),count))
im3.save("./%s.gif"%(m.hexdigest()))
count += 1
На выходе мы получаем набор изображений в этой же директории. Каждому из них присваивается уникальных хеш на случай, если вы будете обрабатывать несколько капч.
Вот результат этого кода для нашей тестовой капчи:
 |
 |
 |
 |
 |
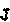 |
Вы сами решаете, как хранить эти изображения, но я просто поместил их в директории с тем же именем, что находится на изображении (символ или цифра).
Собираем все вместе
Последний шаг. У нас есть извлекание текста, извлекание символов, техника распознавания и обучающее множество.
Мы получаем изображение капчи, выделяем текст, получаем символы, а затем сравниванием их с нашим обучающим множеством. Вы можете скачать окончательную программу с обучающим множеством и небольшим количеством капч по этой ссылке.
Здесь мы просто загружаем обучающее множество, чтобы иметь возможность сравнивать с ним:
def buildvector(im):
d1 = {}
count = 0
for i in im.getdata():
d1[count] = i
count += 1
return d1
v = VectorCompare()
iconset =
['0','1','2','3','4','5','6','7','8','9','0','a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','
u','v','w','x','y','z']
imageset = []
for letter in iconset:
for img in os.listdir('./iconset/%s/'%(letter)):
temp = []
if img != "Thumbs.db":
temp.append(buildvector(Image.open("./iconset/%s/%s"%(letter,img))))
imageset.append({letter:temp})
А тут уже происходит все волшебство. Мы определяем, где находится каждый символ и проверяем его с помощью нашего векторного пространства. Затем сортируем результаты и печатаем их.
count = 0
for letter in letters:
m = hashlib.md5()
im3 = im2.crop(( letter[0] , 0, letter[1],im2.size[1] ))
guess = []
for image in imageset:
for x,y in image.iteritems():
if len(y) != 0:
guess.append( ( v.relation(y[0],buildvector(im3)),x) )
guess.sort(reverse=True)
print "",guess[0]
count += 1
Выводы
Теперь у нас есть все, что нужно и мы можем попробовать запустить нашу чудо-машину.
Входной файл –
captcha.gif. Ожидаемый результат: 7s9t9jpython crack.py
(0.96376811594202894, '7')
(0.96234028545977002, 's')
(0.9286884286888929, '9')
(0.98350370609844473, 't')
(0.96751165072506273, '9')
(0.96989711688772628, 'j')
Здесь мы видем предполагаемый символ и степень уверенности в том, что это действительно он (от 0 до 1).
Похоже, что у нас действительно все получилось!
На самом деле на тестовых капчах данный скрипт будет выдавать успешный результат примерно в 22% случаев (у меня получилось 28.5, прим. перев.).
python crack_test.py
Correct Guesses - 11.0
Wrong Guesses - 37.0
Percentage Correct - 22.9166666667
Percentage Wrong - 77.0833333333
Большинство неверных результатов приходится на неправильное распознаваине цифры «0» и буквы «О». Нет ничего неожиданного, т. к. даже люди их часто путают. У нас еще есть проблема с разбиванием на символы, но это можно решить просто проверив результат разбиения и найдя золотую середину.
Однако, даже с таким не очень совершенным алгоритмом мы можем разгадывать каждую пятую капчу за такое время, где человек не успел бы разгадать и одну.
Выполнение этого кода на Core 2 Duo E6550 дает следующие результаты:
real 0m5.750s
user 0m0.015s
sys 0m0.000s
От переводчика. У меня на Dual Core T4400 получились следующие результаты:
real 0m0.176s
user 0m0.160s
sys 0m0.012s
В нашем каталоге находится 48 капч, из чего следует, что на разгадывание одной уходит примерно 0.12 секунд. С нашими 22% процентами успешного разгадывания мы можем разгадывать около 432 000 капч в день и получать 95 040 правильных результатов. А если использовать многопоточность?
Вот и все. Надеюсь, что мой опыт будет использован вами в хороших целях. Я знаю, что вы можете использовать этот код во вред, но чтобы сделать действительно нечто опасное вы должны довольно сильно его изменить.
Для тех, кто пытается защитить себя капчей я могу сказать, что это вам не сильно поможет, т. к. их можно обойти программно или просто платить другим людям, которые будут разгадывать их вручную. Подумайте над другими способами защиты.
