Весь поисковый индекс Google размещается в RAM памяти уже как минимум 5 лет. Почему бы не попробовать сделать то же самое и с поисковым индексом для Lucene?
В последнее время, оперативная память стала весьма недорога, поэтому для высоконагруженных ресурсов, вполне резонно ожидать серьезного улучшения производительности за счет размещения поискового индекса целиком в оперативной памяти.
Очевидный вопрос – не попробовать ли нам загрузить весь индекс, в предоставляемый Lucene класс
К сожалению, этот класс известен тем, что создает очень серьезную нагрузку на сборщик мусора (GC): каждый файл представляется в виде списка из фрагментов типа
Несмотря на указанные проблемы с классом
Недавно я узнал про Java виртуальную машину Zing, разработанную компанией Azul, которая обеспечивают работу сборщика мусора без пауз, даже для очень больших объемов heap. Т.е. теоретически, большая нагрузка на память, порождаемая классом
По умолчанию, утилиты из комплекта luceneutil измеряют среднее время отклика, отбрасывая при этом, крайне интересные экстремальные значения. Делается это по причине того, что эти утилиты предназначены для тестирования алгоритмов и эффективности, внесенных в них изменений, специально игнорируя случайные отклонения, внесенные посторонними задержками на уровне операционной системы, дисковой подсистемы, сборщика мусора и т.д.
Но для реальных поисковых приложений, что действительно имеет значение, так это полное время отклика для всех поисковых запросов. Поиск, это по своей сути интерактивный процесс: пользователь сидит и ждет, когда к нему вернется результат поиска, и только затем кликает по ссылкам. Если даже 1% запросов занимает много времени, то это уже является серьезной проблемой! Пользователи нетерпеливы, и очень быстро переходят к конкурентам.
Поэтому я доработал lucenutil, чтобы выделить в отдельный модуль нагрузочный клиент (sendTasks.py), который сохраняет время отклика для всех запросов; а также скрипты (loadGraph.py и responseTimeGraph.py) для построения графиков времени отклика. Также был доработан непосредственно запускающий скрипт responseTimeTests.py для исполнения серии тестов, с возрастающей нагрузкой (запросов/сек), автоматически останавливающий тестирование, когда нагрузка начинает превышать производительность сервера. Как приятное дополнение, такой подход позволяет измерять реальную производительность сервера, а не экстраполировать ее из усредненных показателей.
Для наиболее правильного моделирования времени посылки реальных запросов, клиент посылает их в соответствии с распределением Пуассона. Тестирующий скрипт работает в один поток, и если мы посылаем запросы со скоростью 200 запросов в секунду, а сервер по какой-то причине замирал на 5 секунд, то очередь запросов вырастет до 1000. К сожалению, очень много нагрузочных тестов ведут себя иначе, и заводят отдельный клиентский поток, для каждого эмулируемого клиента.
Клиент работает (через ssh) на отдельной машине, что является важным моментом, потому как сервер Lucene (а не только JVM), периодически проседает по производительности (например, происходит swap), что может тормозить работу нагрузочного клиента и, таким образом, исказить результаты. В идеале, клиент работает на выделенной машине, и не испытывает никаких пауз. Дополнительно, на клиенте отключается сборщик мусора Python, для устранения его негативного влияния.
Для тестирования Zing, я проиндексировал полную базу англоязычной Википедии по состоянию на 2.05.2012, имеющую объем 28.78 Гб простого текста, представляющего 33.3 миллиона документов, размером около 1Кб, включая встроенные поля и векторы терминов. Благодаря этому, я могу подсвечивать результаты, используя класс
Каждый тест исполнялся в течении часа, из учета исключались первые 5 минут, необходимые для разогрева. Максимальный объем heap составил 140 Гб (
Я протестировал различные уровни нагрузки (запросов/сек), начиная с 50 (минимальная) и до 275 (очень большая), а затем построил графики, иллюстрирующие перцентили времени отклика, для различных конфигураций. Используемый по умолчанию, параллельный Oracle GC вел себя ужасно медленно (Десятки секунд для очистки памяти) поэтому я даже не включил его в результирующий отчет. Новый коллектор G1 оказался еще более медленным как на скорости запуска (потребовалось 6 часов чтобы загрузить индекс в
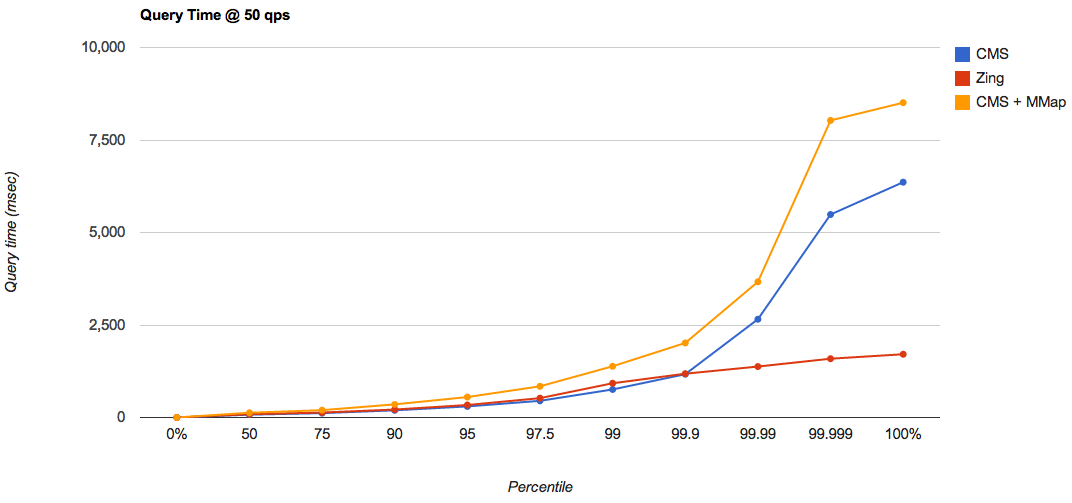
На минимальной нагрузке (50 запросов/сек), Zing продемонстрировал хорошую работу, обеспечивая минимальное время отклика, даже для худших случаев, тогда как CMS продемонстрировал достаточно долгое время отклика достаточно большом количестве случаев, даже при использовании
Чтобы оценить предел насыщаемости каждой из конфигураций, я построил график иллюстрирующий время отклика для 99% случаев, и для разных уровней нагрузки:
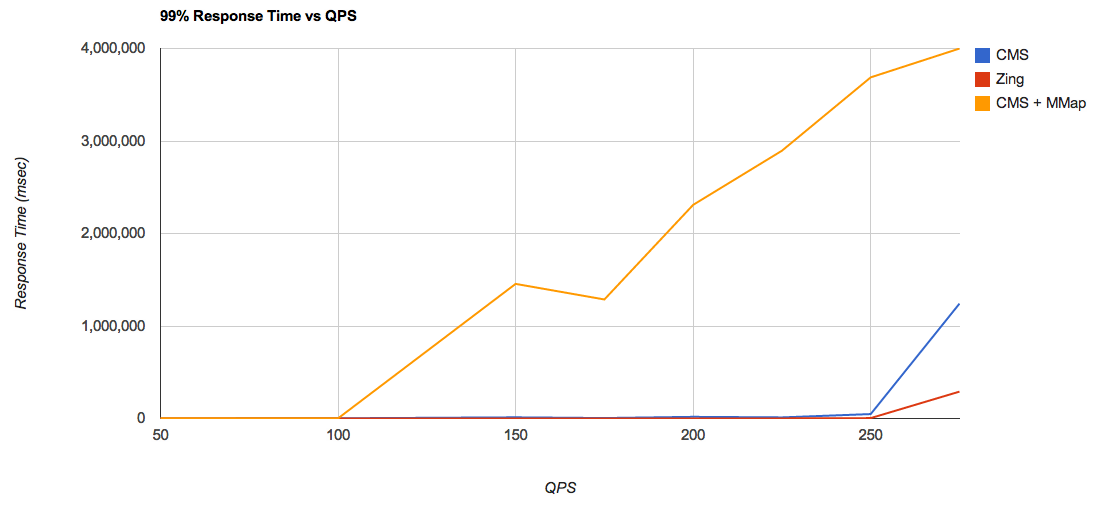
Из этого графика можно сделать вывод, что для связки
Построим тот же самый график, но уже без результатов для
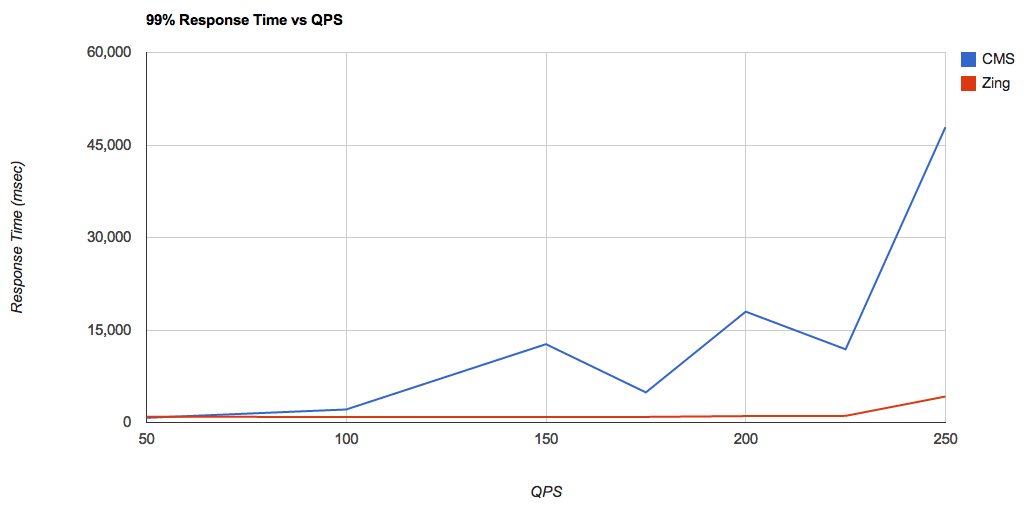
Для перцентиля 99%, показатели Zing остаются стабильными, тогда как CMS начинает демонстрировать долгое время отклика, начиная с нагрузки в 100 запросов/сек. Посмотрим на показатели при нагрузке в 225 запросов/сек, наиболее близкой к пределу насыщения и при использовании
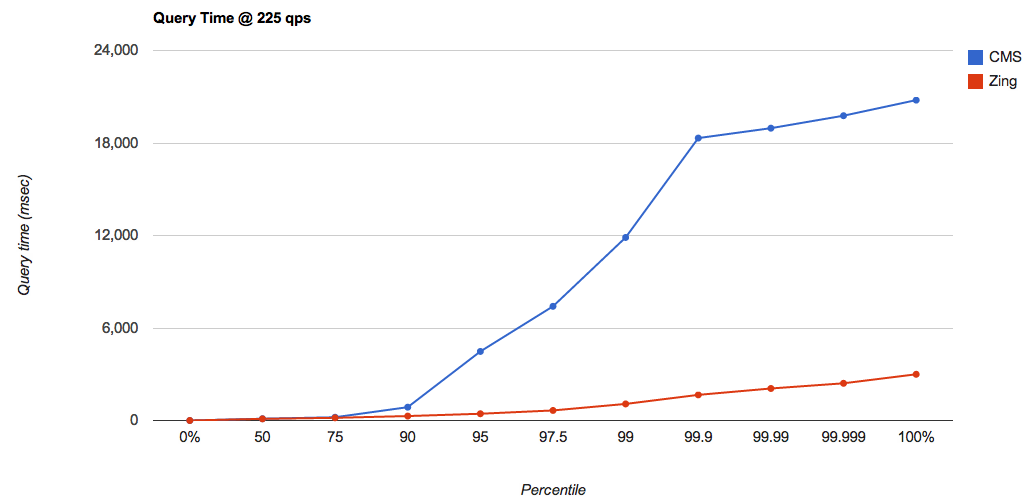
Время, потраченное на паузы, здесь уже существенно больше, чем при нагрузке в 50 запросов/сек: Уже начиная с перцентиля в 95%, время отклика становится слишком большим: 4479 мсек и более.
Приведенные тесты демонстрируют, что при использовании сборщика мусора Zing, достигается очень малое время отклика, даже на экстремальных нагрузках, когда приложению выделен heap размером в 140Гб, а индекс Lucene имеет объем 78 Гб и полностью загружен в
Что особенно интересно, Azul недавно анонсировал доступность JVM Zing для open-source разработчиков, для использования ее в целях разработки и тестирования.
В последнее время, оперативная память стала весьма недорога, поэтому для высоконагруженных ресурсов, вполне резонно ожидать серьезного улучшения производительности за счет размещения поискового индекса целиком в оперативной памяти.
Очевидный вопрос – не попробовать ли нам загрузить весь индекс, в предоставляемый Lucene класс
RAMDirectory?К сожалению, этот класс известен тем, что создает очень серьезную нагрузку на сборщик мусора (GC): каждый файл представляется в виде списка из фрагментов типа
byte[1024]. Так же, он содержит ненужные механизмы синхронизации: если приложение обновляет индекс (т.е. не только ищет), отдельно проблемой встает вопрос того, как сохранить внесенные в RAMDirectory изменения обратно на диск. Время старта также существенно замедляется, за счет необходимости первоначальной загрузки индекса в память. Столкнувшись с этим списком проблем, разработчики Lucene часто рекомендуют использовать RAMDirectory только для небольших индексов или в целях тестирования, а в остальных случаях полагаться на механизмы управления памятью операционной системы, и обращаться к ней при помощи класса MMapDirectory. Несмотря на указанные проблемы с классом
RAMDirectory, разработчики ведут работу по его улучшению, а многие пользователи уже сейчас используют его в своих проектах.Недавно я узнал про Java виртуальную машину Zing, разработанную компанией Azul, которая обеспечивают работу сборщика мусора без пауз, даже для очень больших объемов heap. Т.е. теоретически, большая нагрузка на память, порождаемая классом
RAMDirectory не будет являться проблемой для Zing. Давайте же проверим это! Но для начала сделаем небольшое пояснение насчет того, насколько важно проводить тестирование времени отклика для всех запросов, а не измерять среднюю температуру по больнице.Перцентили для времени отклика поискового запроса
По умолчанию, утилиты из комплекта luceneutil измеряют среднее время отклика, отбрасывая при этом, крайне интересные экстремальные значения. Делается это по причине того, что эти утилиты предназначены для тестирования алгоритмов и эффективности, внесенных в них изменений, специально игнорируя случайные отклонения, внесенные посторонними задержками на уровне операционной системы, дисковой подсистемы, сборщика мусора и т.д.
Но для реальных поисковых приложений, что действительно имеет значение, так это полное время отклика для всех поисковых запросов. Поиск, это по своей сути интерактивный процесс: пользователь сидит и ждет, когда к нему вернется результат поиска, и только затем кликает по ссылкам. Если даже 1% запросов занимает много времени, то это уже является серьезной проблемой! Пользователи нетерпеливы, и очень быстро переходят к конкурентам.
Поэтому я доработал lucenutil, чтобы выделить в отдельный модуль нагрузочный клиент (sendTasks.py), который сохраняет время отклика для всех запросов; а также скрипты (loadGraph.py и responseTimeGraph.py) для построения графиков времени отклика. Также был доработан непосредственно запускающий скрипт responseTimeTests.py для исполнения серии тестов, с возрастающей нагрузкой (запросов/сек), автоматически останавливающий тестирование, когда нагрузка начинает превышать производительность сервера. Как приятное дополнение, такой подход позволяет измерять реальную производительность сервера, а не экстраполировать ее из усредненных показателей.
Для наиболее правильного моделирования времени посылки реальных запросов, клиент посылает их в соответствии с распределением Пуассона. Тестирующий скрипт работает в один поток, и если мы посылаем запросы со скоростью 200 запросов в секунду, а сервер по какой-то причине замирал на 5 секунд, то очередь запросов вырастет до 1000. К сожалению, очень много нагрузочных тестов ведут себя иначе, и заводят отдельный клиентский поток, для каждого эмулируемого клиента.
Клиент работает (через ssh) на отдельной машине, что является важным моментом, потому как сервер Lucene (а не только JVM), периодически проседает по производительности (например, происходит swap), что может тормозить работу нагрузочного клиента и, таким образом, исказить результаты. В идеале, клиент работает на выделенной машине, и не испытывает никаких пауз. Дополнительно, на клиенте отключается сборщик мусора Python, для устранения его негативного влияния.
Тестируем на Википедии
Для тестирования Zing, я проиндексировал полную базу англоязычной Википедии по состоянию на 2.05.2012, имеющую объем 28.78 Гб простого текста, представляющего 33.3 миллиона документов, размером около 1Кб, включая встроенные поля и векторы терминов. Благодаря этому, я могу подсвечивать результаты, используя класс
FastVectorHighlighter. В результате, получился индекс объемом 78 Гб. Для каждого теста, сервер загружает полный индекс в RAMDirectory, после чего, клиент посылает запросы из списка 500-та наиболее тяжелых (наиболее часто встречающиеся в документах термины). В то же самое время, сервер производит переиндексацию документов (updateDocument) со скоростью примерно 100 документов в секунду (~100 Кб/сек).Каждый тест исполнялся в течении часа, из учета исключались первые 5 минут, необходимые для разогрева. Максимальный объем heap составил 140 Гб (
-Xmx 140G). Для получения базового уровня производительности, я также протестировал MMapDirectory, с максимальным объемом heap 4 Гб. Машина имеет 32 процессорных ядра (64 с включенным hyper-threading) и 512 Гб RAM, сервер сконфигурирован на работу в 40 потоков. Я протестировал различные уровни нагрузки (запросов/сек), начиная с 50 (минимальная) и до 275 (очень большая), а затем построил графики, иллюстрирующие перцентили времени отклика, для различных конфигураций. Используемый по умолчанию, параллельный Oracle GC вел себя ужасно медленно (Десятки секунд для очистки памяти) поэтому я даже не включил его в результирующий отчет. Новый коллектор G1 оказался еще более медленным как на скорости запуска (потребовалось 6 часов чтобы загрузить индекс в
RAMDirectory, в отличии от 900 секунд, при использовании конкурентного коллектора CMS), а во время работы, запросы испытывали задержки более чем в 100 секунд, поэтому его результаты я тоже не включил в отчет (Это оказалось сюрпризом так как G1 позиционируется для работы с большими heap). Таким образом, я протестировал три конфигурации: CMS, с его настройками по умолчанию и использованием класса MMapDirectory, как базисный уровень, а так же CMS и Zing, с использованием класса RAMDirectory.На минимальной нагрузке (50 запросов/сек), Zing продемонстрировал хорошую работу, обеспечивая минимальное время отклика, даже для худших случаев, тогда как CMS продемонстрировал достаточно долгое время отклика достаточно большом количестве случаев, даже при использовании
MMapDirectory:
Чтобы оценить предел насыщаемости каждой из конфигураций, я построил график иллюстрирующий время отклика для 99% случаев, и для разных уровней нагрузки:
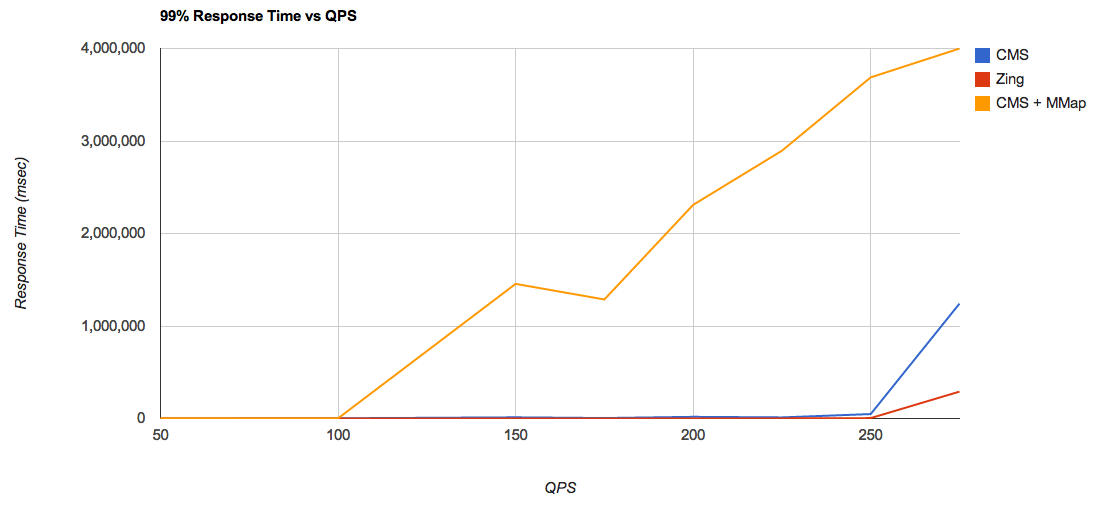
Из этого графика можно сделать вывод, что для связки
CMS + MMap, пиковая производительность приходится на уровень где-то между 100 и 150 запросов/сек, Тогда как, при использовании RAMDirectory, этот пик приходится на уровень где-то между 225 и 250 запросов/сек. Это потрясающий прирост производительности! Этот результат тем более интересен тем, что если измерять усредненное время отклика, то разница в производительности между RAMDirectory и MMapDirectory далеко не так заметна. Построим тот же самый график, но уже без результатов для
CMS + MMapDirectory а так же, уберем результаты для нагрузки в 275 запросов/сек (так как она явно выходит за пределы возможности нашего оборудования):
Для перцентиля 99%, показатели Zing остаются стабильными, тогда как CMS начинает демонстрировать долгое время отклика, начиная с нагрузки в 100 запросов/сек. Посмотрим на показатели при нагрузке в 225 запросов/сек, наиболее близкой к пределу насыщения и при использовании
RAMDirectory совместно с CMS и Zing:
Время, потраченное на паузы, здесь уже существенно больше, чем при нагрузке в 50 запросов/сек: Уже начиная с перцентиля в 95%, время отклика становится слишком большим: 4479 мсек и более.
Zing работает!
Приведенные тесты демонстрируют, что при использовании сборщика мусора Zing, достигается очень малое время отклика, даже на экстремальных нагрузках, когда приложению выделен heap размером в 140Гб, а индекс Lucene имеет объем 78 Гб и полностью загружен в
RAMDirectory. Более того, производительность приложения, измеряемая в количестве запросов в секунду, также существенно увеличивается (примерно в два раза в рассмотренном примере), а так же позволяет спокойно использовать RAMDirectory даже для больших индексов, если они работают под управлением Zing.Что особенно интересно, Azul недавно анонсировал доступность JVM Zing для open-source разработчиков, для использования ее в целях разработки и тестирования.
