Comments 258
Тег порадовал «смешались в кучу кони люди». Коль таки дела, спрошу и я. Вот на винде, я понимаю, в WinAPI функция мультиплексирования select — не масштабируемая, и на прикладном уровне дает сложность o(n), что в принципе может создавать проблемы для 10 000 и больше соединений (или все-же справляется?), ну а у linux в чём беда?
Я так понимаю, проблема не столько ОСи, сколько самих веб-серверов, которые могут просто не уметь обрабатывать такое количество соединений :)
Кто-то ещё пользуется селектом на винде? IOCP же.
Я пользуюсь, но судя по всему, больше не буду.
Кто-то еще пользуется виндой как серверной платформой?
не знаю к счастью или к сожалению, но у нас в конторе так исторически сложилось, что всё на MS. Я бы рад предложить перейти местами на nix (почтовик бесплатный на iredmail и прокся очень вписываются), но как только с шефом начинаем обсуждать, видим что пока проблем больше чем плюсов…
Так что коли вся сетка на Win, выбирать особенно не приходится… Хотя может время изменится для нас =)
Так что коли вся сетка на Win, выбирать особенно не приходится… Хотя может время изменится для нас =)
Select никто и не использует. На винде есть IOCP, на линуксе epoll, на FreeBSD и ее производных — kqueue. Это если рассматривать уровень системных вызовов.
и есть несколько различных либ, скрывающих детали конкретной ОС.
Если не требуется адового количества соединений, то можно и select.
Та ладно! Половина open source софта, весьма известных названий с которым я имел дело, вообще не знает каким именно чудом оно компилируется под винду. IOCP для них — черная магия. Пишут в лоб да как по-проще. И это еще в лучшем случае.
Под вынью не пробовал, но поговаривают 10к не тянет.
Вот на винде, я понимаю, в WinAPI функция мультиплексирования select — не масштабируемая, и на прикладном уровне дает сложность o(n), что в принципе может создавать проблемы для 10 000 и больше соединений (или все-же справляется?), ну а у linux в чём беда?
При всем моем уважении, select() была функцией мультиплексирования на винде лет двадцать назад. Последние лет… много используется GetQueuedCompletionStatus() которая волне себе способна держать до миллиона входящих TCP подключений, из них одновременно передающих данные ~ 10k.
Ну, наверное я немножко устарел. Года 2 назад писал веб-сервер, не помню что курил и читал, но альтернативы тогда не нашел. Сейчас сеть у меня сводится к QNetworkAccessManager, как бы печально это не звучало.
А при чем здесь винда? Это select сам по себе такой. Более того, оригинально он еще и битмаски использовал, что мешало ему работать с дескрипторами имеющими номер выше определенного (насколько я знаю apache делает кучу dup2 для перемещения несокетных дескрипторов «вверх» и сокетных — «вниз»). Вообще, история c10k в юниксах (включая wannabe — типа линукса) — это леденящий душу триллер.
А почему ожидалось, что Go порвет Erlang?
Во-первых, «C10k», почти наверняка, — проблема 10 тысяч соединений, а не тысячи.
Интересней было бы добавить сюда реализацию на каком-нибудь С (или хотя бы с использованием либы на С). Так, чисто для сравнения. Ну и перл с haskell'ом, чтоли.
Интересней было бы добавить сюда реализацию на каком-нибудь С (или хотя бы с использованием либы на С). Так, чисто для сравнения. Ну и перл с haskell'ом, чтоли.
Да, уже исправил на 10 000 :)
Хаскель в бенчмарке есть, а С и Перл можно добавить (Гитхаб же :) )
Хаскель в бенчмарке есть, а С и Перл можно добавить (Гитхаб же :) )
да, хаскел «не заметил»: задумался на середине ответа и дописал хаскелл уже позже ;)
Пойду попробую изобразить что-нибудь на перле аналогичное…
Пойду попробую изобразить что-нибудь на перле аналогичное…
Я исходники не смотрел, но судя по описанию действительно тест 1000 подключений происходит, так как при создании подлючения каждую миллисекунду = 10 секунд по 1000 подключений в секунду.
s/Латентность/Задержка/
довольно интересно. обязательно попробую у себя на сервере.
какая версия nodejs у вас использовалась?
какая версия nodejs у вас использовалась?
С Go в этом случае причина, насколько я понимаю, состоит в том, что по умолчанию «goroutine», которые используются в Go для реализации многопоточности, являются легковесными только до тех пор, пока им не понадобится делать какие-нибудь блокирующие операции, например чтение-запись в сокеты. Когда же goroutine требуется прочитать что-то из сокета, она превращается в обычный thread операционной системы, что должно весьма плохо сказываться на производительности, хотя коннект может действительно при этом идти быстро.
Все операции ввода-вывода и прочие системные вызовы в Go асинхронны хоть и имееют api который выглядит, как блокирующий. Единственный способ написать блокирующий код в Go — это долгие вычесления, которые обычно достаточно быстры благодаря компилируемой природе языка.
Кроме того горотуны не превращаються в обычные потоки в класическом понимании. Планировщик (scheduler) выполняет их в зависимости от того ждут ли они на результат асинхронной операции (любые системные вызовы или ожидание на ответ из канала), или же готовы к исполнению, на одном из реальных thread-ов, которые есть у него в пуле (на данный момент количесто таких потоков зависит от переменной среды GOMAXPROCS).
Так почему он себя так плохо показал? Выходит го не подходит для высоконагруженных проектов?
Ну конкретно у реализации вебсокетов модель немного другая, насколько я понимаю — они больше заточены под более-менее тяжелую обработку запросов, нежели на замену nginx. Ещё может быть вариант, что автор что-то не так намерял, ибо он, видимо, в 32-битной системе это тестировал.
То есть если поставить перед го приложением nginx то будет всё ок?
Попробуйте тот же Go только используя компилятор GCCGO. Обычно это дает ощютимый прирост производительности. На данный момент стандартная связка для Go значительно слабее оптимизирует чем GCC. Это скорей всего улучшиться в будующем, но сейчас удобней разрабатывать с стандартным компилятором, а в продакшн с GCCGO.
Кроме того библиотеки в Go достаточно свежы и возможно что-то и где-то можно оптимизировать. Если у вас есть идеи/пожелания — посылайте их golang-nuts или golang-dev рассылки и вас скорей всего выслушают, а если будет еще и какие-то изменения, которые очевидно улучшают производительность — с радостью их приймут.
Наверное самым слабым местом в Go сейчас являеться планировщик, который определенно будет улучшен в будующем (GOMAXPROCS — хак, а не решение всех проблем).
Кроме того библиотеки в Go достаточно свежы и возможно что-то и где-то можно оптимизировать. Если у вас есть идеи/пожелания — посылайте их golang-nuts или golang-dev рассылки и вас скорей всего выслушают, а если будет еще и какие-то изменения, которые очевидно улучшают производительность — с радостью их приймут.
Наверное самым слабым местом в Go сейчас являеться планировщик, который определенно будет улучшен в будующем (GOMAXPROCS — хак, а не решение всех проблем).
Я, честно говоря, тоже себе примерно так это и представлял, но видимо это не вся правда…
10к это было давно для обычных сокетов, сейчас для той же джавы 10к уже не проблема.
А веб сокеты что ли только подбираются к этому пределу? Или я что-то не так понял?
А веб сокеты что ли только подбираются к этому пределу? Или я что-то не так понял?
а зачем вебсокет… надо было tcp сокет делать
Тоже смотрел на результаты с недоумением. Также для питона не плохо было бы добавить результат по Tornado.
А лучше сразу для gevent
O_o
А сейчас там что?
А сейчас там что?
Там в ws4py старый gevent, а не 1чка, насколько я помню. 1чка на другой либе с кучой багфиксов и крэшфиксов.
Более того, насколько видно сравнение некорректно, т.к. процесс не параллелили.
Пускай запустят например даже gunicorn+gevent, это вполне возможно, с учетом использования wsgi.
Более того, насколько видно сравнение некорректно, т.к. процесс не параллелили.
Пускай запустят например даже gunicorn+gevent, это вполне возможно, с учетом использования wsgi.
gevent 1.0 еще не зарелизили, так что всё честно ^_^ Ну и сомневаюсь, что обновление до 1.0 хоть что-то существенно исправит.
wsgi в вебсокетах не используется, насколько мне известно.
Ну и, пожалуй, есть смысл сделать
wsgi в вебсокетах не используется, насколько мне известно.
Ну и, пожалуй, есть смысл сделать
erl -smp disable для эрланга и замерить как эрланг будет себя вести, если отключить расползание по процессорам.Исправит фундаментальные баги в libevent, который заменили на libev в gevent 1.
Ну значит тест не честный опять же.
Надо было переписать ws4py с мультифорком, чтобы у каждого хаба geventа была возможность заполнить все ядра. В эрланге это нативно.
Я это к чему. Мы держали 20000 соединений TCP постоянных на 2 серверах (по 5 тысяч соединений на сервер + mysql + memcache).
Если бы не проблема миддлвари можно было бы вешать и больше соединений.
Ну значит тест не честный опять же.
Надо было переписать ws4py с мультифорком, чтобы у каждого хаба geventа была возможность заполнить все ядра. В эрланге это нативно.
Я это к чему. Мы держали 20000 соединений TCP постоянных на 2 серверах (по 5 тысяч соединений на сервер + mysql + memcache).
Если бы не проблема миддлвари можно было бы вешать и больше соединений.
То что NodeJS и Python перестали работать — скорее всего уперлись в ограничения ОС (количество файл-хендлов) надо ОС подтюнить и должны заработать.
По ссылке ходили?
ulimit -n 999999NodeJS и Erlang нельзя сравнивать так в лоб.
В Erlang из коробки многопоточность. В то время как на NodeJS надо поизвращаться.
Сравнение Erlang и Node.js
В Erlang из коробки многопоточность. В то время как на NodeJS надо поизвращаться.
Сравнение Erlang и Node.js
Из описания непонятно, как рассчитывалось «Соединений» и с какой точностью. Может там до 10K одновременных далеко еще.
Кстати, автор там чего-то подрефакторил и будет повторно тестировать. Подождем.
Кстати, автор там чего-то подрефакторил и будет повторно тестировать. Подождем.
Табличка вообще не имеет смысла, поскольку задача решена только Erlang. Остальные просто выпадают из сравнения, как не решившие задачу. Смысла сравнивать по остальным параметрам нет. Если же идти на компромисс и учитывать только отработанные запросы, то не понятна средняя задержка у NodeJS в 42 секунды — не верю!
По поводу средних 42 секунд (если вы считаете, что это много).
Вполне объяснимая задержка – нода ковыряется на одномпроцессореядре (про cluster писали выше ), очередь сообщений копится, node не успевает всё обрабатывать, и поэтому «вжжжиииууу» © получается только на старте.
Грубо говоря, запустив ещё один node.js на другом ядре можно удвоить скорость, если есть ещё свободные ядра – будет +100500 к скорости такой вот синтетической «обработки» сообщений. На практике цифры конечно не такие радужные, ибо бизнес логика, mongo/mysql + гремучая смесь различных модулей из npm, которые поголовно версии ~0.x / ~0.0.x.
Как по мне, так на данный момент развития node, дешевле расширять ферму, докупать «облака» и запускать ещё процессы, чем допиливать каждый модуль до состяния «чак норрис+».
PS: А ещё оно при «правильном» обращении умеет течь, причём всем сразу. Но это уже руки.
Вполне объяснимая задержка – нода ковыряется на одном
Грубо говоря, запустив ещё один node.js на другом ядре можно удвоить скорость, если есть ещё свободные ядра – будет +100500 к скорости такой вот синтетической «обработки» сообщений. На практике цифры конечно не такие радужные, ибо бизнес логика, mongo/mysql + гремучая смесь различных модулей из npm, которые поголовно версии ~0.x / ~0.0.x.
Как по мне, так на данный момент развития node, дешевле расширять ферму, докупать «облака» и запускать ещё процессы, чем допиливать каждый модуль до состяния «чак норрис+».
PS: А ещё оно при «правильном» обращении умеет течь, причём всем сразу. Но это уже руки.
Кроме того, актуальность самой проблемы C10K мне кажется преувеличенной. Когда нагрузка вырастает до таких размеров, неизбежно начинается горизонтальное масштабирование по другим причинам. Хотя бы из-за надежности. Причем его можно начать уже с 1K и данной проблемой не париться.
Или я ошибаюсь?
Или я ошибаюсь?
Это концептуальная проблема. Она ценна не самом по себе, а для оценки системы в целом. В частности — когда именно пора делать горизонтальное масштабирование :).
Вебдевелопер?
Не всё так легко горизонтально масштабировать, есть приложения которые отлично справляются со своей задачей без горизонтального масштабирования и обслуживают по 10тысяч соединений.
Не всё так легко горизонтально масштабировать, есть приложения которые отлично справляются со своей задачей без горизонтального масштабирования и обслуживают по 10тысяч соединений.
Интересны ваши примеры. Я видел разные приложения, но с 10К — нет.
Ну если нужен пример того, что будет проблематично горизонтально масштабировать, то игровой сервер для игрушки типа wow с общим миром на 10к игроков.
А если просто сервера, обслуживающие 10ки тысяч полуактивных соединений, то это мессенджеры, системы мониторинга итд.
А если просто сервера, обслуживающие 10ки тысяч полуактивных соединений, то это мессенджеры, системы мониторинга итд.
Нужны реальные примеры. Теоретически-то я представляю. А вот в реальности как системы работают, это интересно.
Например из Яндекса или из другого highload проекта кто-нибудь сказал бы, по сколько соединений у них обслуживают фронт-енд сервера. И как они понимают, что пора добавлять. Сдается мне, что упираются узким местом становится совсем не количество соединений.
Например из Яндекса или из другого highload проекта кто-нибудь сказал бы, по сколько соединений у них обслуживают фронт-енд сервера. И как они понимают, что пора добавлять. Сдается мне, что упираются узким местом становится совсем не количество соединений.
UO сервер, далёкий 2003ий год на старом железе и тогда ещё на тормозном .net'е: «During our stress test we had over 9,000 users logged into UOGamers: Hybrid. We were still able to walk, talk and run around despite some small amounts of lag. The server held it's own with over 9,000 users logged in»
И сетевая часть там достаточно ужасно реализована.
И сетевая часть там достаточно ужасно реализована.
Если я не ошибаюсь, в ультиме, если не стоят посреди города в самой гуще общения с сервером будет очень. Даже очень мало. Помню я где-то в начале 2000-х играл в УО на модеме и всегда обходил стороной центр города, а вроде-бы в где-то в 2004-м, когда в Москве только начал появлятся выделенный интернет (со скоростью чуть большей, примерно в 4-8 раз, нежели модемная) у меня друзья держали свой сервер где по вечерам играли до 500-600-700 человек (точные цифры уже они наверное и сами не помнят).
Во время стресс теста лаги появились из-за недостаточной пропускной способности канала 1Gbit.
Ну допустим игры в социальных сетях, там несколько десятков тысяч конкрарентов это нормально. То чем занимался я, не было столь успешно и держало всего лишь до 4к на одной ноде (около 1к io бинарных пакетов в секунду), просто больше народу не приходило :(. Загрузка, я бы не сказал что была такая уж и большая, таски выполнялись достаточно быстро. В среднем по мс на таску (типа посадить дерево, собрать урожайчик) — не подскажу уже, но там счет был в миллисекундах.
Из достаточно популярных социалок, был перед глазами пример как 2 сервера обрабатывали до 27к+ конкарентов (соотношение по серверам примерно 3к1, io-пакетов в секунду примерно 3-4к), к сожалению что там и как дальше было — не в курсе, знаю что серверов стало чуточку больше как и пользователей.
Из достаточно популярных социалок, был перед глазами пример как 2 сервера обрабатывали до 27к+ конкарентов (соотношение по серверам примерно 3к1, io-пакетов в секунду примерно 3-4к), к сожалению что там и как дальше было — не в курсе, знаю что серверов стало чуточку больше как и пользователей.
Ещё кое-что вспомнилось по миллиону соединений :)
www.metabrew.com/article/a-million-user-comet-application-with-mochiweb-part-3
blog.whatsapp.com/index.php/2011/09/one-million/
www.metabrew.com/article/a-million-user-comet-application-with-mochiweb-part-3
blog.whatsapp.com/index.php/2011/09/one-million/
У нас («Мамба») сервера, которые обслуживают real-time штуки — соединение по amf-протоколу с флешкой и соединение через long polling/comet — держат порядка миллиона соединений каждый (или, во всяком случае, держали, когда я смотрел это последний раз). линукс, написаны на плюсах, особых проблем не наблюдается.
blog.whatsapp.com/index.php/2012/01/1-million-is-so-2011/ 2+ млн соединений
Представьте, надо Вам обработать 30к соединений.
Вот и вопрос: либо 4 (+1 для надежности) машины на Erlang, либо 10-20 машин на условом другом языке, который тянет только 1К.
Есть разница с точки зрения стоимости решения?
Вот и вопрос: либо 4 (+1 для надежности) машины на Erlang, либо 10-20 машин на условом другом языке, который тянет только 1К.
Есть разница с точки зрения стоимости решения?
Вот я к этому и клоню, к стоимости.
Если честно, 30К не представляю. :) Но давайте прикинем, теоретически. Сколько нужно памяти на одну сессию? Допустим 300 Кб; тогда на всех нужно 8.5 Гб. Это скромная оценка, при 64-разрядном приложении может и все 16 выйдет. Так же прикинем необходимую мощность CPU, I/O и других подсистем. А дальше прикинем, как выгоднее — распределить все эти пощности на 1-2 сервера или на 10-20? Если на 1-2, то наш выбор ограничивается «большими» серверами от известных вендоров. Их стоимость, стоимость поддержки и особенно стоимость компонентов для апгрейда вы, надеюсь, представляете. В случае же с 10-20 блейдами стоимость в расчете на один мегагерц CPU, гигабайт ОЗУ или гигабайт дискового пространства выйдет намного дешевле.
Кроме того, при дальнейшем масштабировании стоимость каждой дополнительной единицы мощности в первом случае будет возрастать, а во втором — оставаться такой же или даже падать.
Так что разница есть.
Если честно, 30К не представляю. :) Но давайте прикинем, теоретически. Сколько нужно памяти на одну сессию? Допустим 300 Кб; тогда на всех нужно 8.5 Гб. Это скромная оценка, при 64-разрядном приложении может и все 16 выйдет. Так же прикинем необходимую мощность CPU, I/O и других подсистем. А дальше прикинем, как выгоднее — распределить все эти пощности на 1-2 сервера или на 10-20? Если на 1-2, то наш выбор ограничивается «большими» серверами от известных вендоров. Их стоимость, стоимость поддержки и особенно стоимость компонентов для апгрейда вы, надеюсь, представляете. В случае же с 10-20 блейдами стоимость в расчете на один мегагерц CPU, гигабайт ОЗУ или гигабайт дискового пространства выйдет намного дешевле.
Кроме того, при дальнейшем масштабировании стоимость каждой дополнительной единицы мощности в первом случае будет возрастать, а во втором — оставаться такой же или даже падать.
Так что разница есть.
> Допустим 300 Кб; тогда на всех нужно 8.5 Гб
nginx: «10,000 inactive HTTP keep-alive connections take about 2.5M memory;»
nginx: «10,000 inactive HTTP keep-alive connections take about 2.5M memory;»
Это прекрасно, но мы же говорим о системе в целом, а не об одном Nginx.
Ну берём опять же игровой сервер, весь мир хранится в памяти, так что без разницы сколько у нас там соединений, всегда будем отъедать nM памяти. Возьмём опять же ультиму, с жутко переполненым миром и будет у нас ~1G на динамические сущности + ~1G на карту/статику.
Подключим к этому серверу 10,000 соединений, теперь наш сервер отъедает на 2,5M больше памяти.
Как от кол-ва соединений может взлететь расход памяти мне не особо понятно.
Предположим что к нам подключились какие-то мудаки, которые отправляют пакет максимально допустимой длины и висят недоотправив последний байт, мы изначально ограничили максимальный размер пакета в 64K, тогда конечно придётся к этим 10,000 соединениям прибавить ~625M.
Подключим к этому серверу 10,000 соединений, теперь наш сервер отъедает на 2,5M больше памяти.
Как от кол-ва соединений может взлететь расход памяти мне не особо понятно.
Предположим что к нам подключились какие-то мудаки, которые отправляют пакет максимально допустимой длины и висят недоотправив последний байт, мы изначально ограничили максимальный размер пакета в 64K, тогда конечно придётся к этим 10,000 соединениям прибавить ~625M.
> Как от кол-ва соединений может взлететь расход памяти мне не особо понятно.
Данные самой сессии где-то держать надо?
Данные самой сессии где-то держать надо?
typedef struct epoll_handler epoll_handler;
struct epoll_handler {
int (*fn)(epoll_handler*);
};
struct session {
int fd;
int events;
epoll_handler handler;
list timeouts_node; // intrusive list, 16B на 64бит
buf read_buf; // 24B на 64бит +- расход на недогруженые пакеты в пределах 64B
queue write_queue; // 16B на 64бит +- расход на пакеты для отправки
size_t write_offset;
int player_id;
}
+ затраты ОС
+ активация нескольких таймеров, связаных с залогинеными игроками.
От этого расход памяти особо не взлетит.
300Кб на одну сессию… в некоторых случаях жировато будет. Хотя в яве допустим 300кб — это смешные цифры, особенно если в хипе куча коллекций (там оверхед до 98% бывает, например ConcurrentHashMap с парой простых объектов из нескольих полей).
А так, у меня при 1к онлайне и ~1.5к юзеров в памяти (при кэше в виде SoftReference) хип отъедал до 2 гигов. Собственно по метру на пользователя. При использовании кэша с WeekReference цифры были немного другие, при той же тысячи, в хипе около 1.2-1.3 гига.
А так, у меня при 1к онлайне и ~1.5к юзеров в памяти (при кэше в виде SoftReference) хип отъедал до 2 гигов. Собственно по метру на пользователя. При использовании кэша с WeekReference цифры были немного другие, при той же тысячи, в хипе около 1.2-1.3 гига.
> Если честно, 30К не представляю. :)
Все определяется приложением и проектом. У меня сейчас в пиках до 25К.
> Но давайте прикинем, теоретически. Сколько нужно памяти на одну сессию?
Это сильно теоретически, все зависит от того, что делать.
В некоторых задачах на 1 коннект нужно меньше 1КБ.
Есть даже пример — комет-сервер на Erlang, держащий 1 миллион(!) подклключений. Это на одной машине! Если не путаю, там 64ГБ оперативы. Вобщем не такие страшные цифры на сегодняшний день. Типовая машина.
> Кроме того, при дальнейшем масштабировании стоимость каждой дополнительной единицы мощности в первом случае будет возрастать, а во втором — оставаться такой же или даже падать.
Разве я написал, что надо работать на 1 супермашине?
Ни в коем случае! Приложение должно эксплуатироваться минимум на 2 машинах, чтобы при сбое, оно могло продолжить работу. Даже пример привел: 3 рабочих сервера + 1 запасной.
Все определяется приложением и проектом. У меня сейчас в пиках до 25К.
> Но давайте прикинем, теоретически. Сколько нужно памяти на одну сессию?
Это сильно теоретически, все зависит от того, что делать.
В некоторых задачах на 1 коннект нужно меньше 1КБ.
Есть даже пример — комет-сервер на Erlang, держащий 1 миллион(!) подклключений. Это на одной машине! Если не путаю, там 64ГБ оперативы. Вобщем не такие страшные цифры на сегодняшний день. Типовая машина.
> Кроме того, при дальнейшем масштабировании стоимость каждой дополнительной единицы мощности в первом случае будет возрастать, а во втором — оставаться такой же или даже падать.
Разве я написал, что надо работать на 1 супермашине?
Ни в коем случае! Приложение должно эксплуатироваться минимум на 2 машинах, чтобы при сбое, оно могло продолжить работу. Даже пример привел: 3 рабочих сервера + 1 запасной.
UFO just landed and posted this here
1к — это все таки довольно мало. Хотя опять же, смотря для чего. Если взять к примеру геймдев, то 1к юзеров в мморпг на одной машине — много, особенно если они в одном месте. Для тех же социалок, 1к — раз плюнуть. Одной строчкой кода ставим ограничение на клиенте на действие, раз в три-четыре секунды + анимация этого всего и у нас поток запросов снижается в несколько раз (больше чем в три). Тут и 10к нормально живет и вторую машину не требует (если коечно постоянно в рсубд не лезть).
Очень странные результаты. Проверю вечером на сервере.
UFO just landed and posted this here
UFO just landed and posted this here
При том что эти сервера ещё и держали коннект с MySQL базой.
Это судьба.
UFO just landed and posted this here
> Вот я уже почти неделю штудирую все вдоль и поперек в поисках такого про Webmachine — как создать Restful API с его помощью.
Берется wiki.basho.com/Webmachine-Resource.html и потом любой проект с использованием webmachine, и смотрится в код :)
Ну и добро пожаловать в erlanger.ru/page/672/soobshhestvo (рассылка и чат)
Берется wiki.basho.com/Webmachine-Resource.html и потом любой проект с использованием webmachine, и смотрится в код :)
Ну и добро пожаловать в erlanger.ru/page/672/soobshhestvo (рассылка и чат)
Чтобы понять эрланг, нужно забыть все, что знаете о программировании на императивных языках.
Мои основные ошибки при изучении:
1. Пытался использовать эрланг как питон
2. Считал эрланг высокоуровневым.
Насчет второго: эрланг примерно столь же низкоуровневый, как и Си. Только он отражает работу совершенно другого процессора.
Ну, и начинать изучение эрланга с использования webmachine – примерно то же, что начинать изучать Ruby с рельс.
Мои основные ошибки при изучении:
1. Пытался использовать эрланг как питон
2. Считал эрланг высокоуровневым.
Насчет второго: эрланг примерно столь же низкоуровневый, как и Си. Только он отражает работу совершенно другого процессора.
Ну, и начинать изучение эрланга с использования webmachine – примерно то же, что начинать изучать Ruby с рельс.
> 7 500. При этом, здесь говорится, что node.js падает, грубо говоря, на 6 000 соединений.
Это числа одного порядка, чуть сильнее проц, чуть другие настройки ОС, немного более сложная обрабтка соединений, и одно превращается в другое. Вот если бы было 6К и 30К — это была бы ощутимая разница.
Это числа одного порядка, чуть сильнее проц, чуть другие настройки ОС, немного более сложная обрабтка соединений, и одно превращается в другое. Вот если бы было 6К и 30К — это была бы ощутимая разница.
На Гитхабе отображается интересная статистика используемых языков:
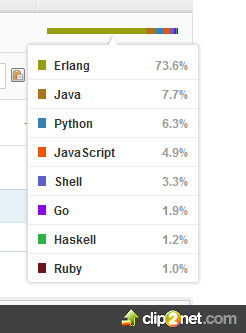

Судя по коду node.js работал всего лишь на одном ядре…
В этом, собственно, одна из проблем ноды — то что SMP надо устраивать ручками
Да я то в курсе… Щас просто понабегут нодахейтеры)
UFO just landed and posted this here
С тем же успехом можно сказать, что если надо запустить erlang на одном ядре — это надо устраивать ручками.
Для фреймворка, позиционирующего себя как для «building fast, scalable network applications.» отсутсвие smp — это не особенность, а недостаток
Именно поэтому
P.S. Я бы не тратил силы на критику проекта с версией 0.6.19 ;)
node cluster уже как полгода доступен. Попробую выжать вечером побольше RPS из этого бенчмарка.P.S. Я бы не тратил силы на критику проекта с версией 0.6.19 ;)
UFO just landed and posted this here
И ведь действительно используют. И на больших нагрузках. И они смогли написать модуль для кластеризации и довели его до включения в ядро. о том я и говорю, что на данный момент это в Node.js есть и незачем ссылаться на статьи годовалой давности м надежде подкрепить свою убеждённость что node.js чего-то не умеет :) Год назад у них на сайте совсем другой текст бы :)
Вот кстати, с кластером очень интересный эффект получили.
Запустили на нем приложение — без нагрузки 2 ядра загружены на 100%.
Запустили на нем приложение — без нагрузки 2 ядра загружены на 100%.
Не вижу как можно в ноде что-то выиграть от использования SMP, это же тупо запуск нескольких процессов. С тем же успехом можно и на NUMA гонять, у ерланга в этом плане более выигрышное положение.
могу ошибаться, но вроде собственно IO в Erlang работает в отдельном одном потоке. А уже обработчики могут расползаться по ядрам.
Ох, лол. В вики написано, что Tornado успешно преодолевает 10k.
Вики лучше не верить. Вон, node.js как бы тоже должен его преодолевать :)
Ну и про торнадо относительно старое: lionet.livejournal.com/42016.html
Ну и про торнадо относительно старое: lionet.livejournal.com/42016.html
Все зависит от архитектуры, изначально предполагается, что торнадо будет запускаться в несколько апстримов с балансировщиком.
Производительность отдельного воркера, имхо, достаточно зависимая и непоказательная величина, на которую влияет многое, но в основном количество блокирующих i/o операций в них (например, сделать запись в лог), так как сервер псевдоасинхронный.
Производительность отдельного воркера, имхо, достаточно зависимая и непоказательная величина, на которую влияет многое, но в основном количество блокирующих i/o операций в них (например, сделать запись в лог), так как сервер псевдоасинхронный.
Никому не кажется, что c10k уже основательно устарела? Вот 100k еще актуальна, а для 10k соединений достаточно взять любой удобный хотя бы jit'ируемый язык без сборщика мусора (как известно, эта дрянь обожает стартовать в самые неподходящие моменты), и дело в шляпе.
P. S. знаю о чем говорю, писал polling сервер, который не напрягаясь обслуживал 30k одновременных соединений в пике.
P. S. знаю о чем говорю, писал polling сервер, который не напрягаясь обслуживал 30k одновременных соединений в пике.
Да как бы пофиг на каком языке сделать accept 100k соединений, это не проблема. Большинство проблем с обслуживанием 100k соединений появляется от использования всяких libuv.
libuv
В смысле от библиотек, которые делают веб-разработку удобнее? Это для области «менее 500 запросов в секунду». Проблема c10k/c100k, как правило, либо нивелируется фронтендом, за которым живут десятки бакендов с этими «libuv», либо решается вручную с минимумом фреймворков и элементами тактодрочерства.
>В смысле от библиотек, которые делают веб-разработку удобнее?
>Проблема c10k/c100k, как правило, либо нивелируется фронтендом, за которым живут десятки бакендов с этими «libuv»
Ох уж эти веб-разработчики :)
Ну например Boost Asio делает разработку сетевых приложений удобнее, а вот libuv создаёт проблемы с масштабированием, что можно забыть про сотни тысяч соединений.
>Проблема c10k/c100k, как правило, либо нивелируется фронтендом, за которым живут десятки бакендов с этими «libuv»
Ох уж эти веб-разработчики :)
Ну например Boost Asio делает разработку сетевых приложений удобнее, а вот libuv создаёт проблемы с масштабированием, что можно забыть про сотни тысяч соединений.
А в чем заключаются проблемы libuv кстати?
всё завернули в proactor pattern из-за винды.
А на юниксах можно использовать reactor pattern и для обслуживания 100к тысяч полуактивных соединений не надо будет аллокэйтить 100к тысяч буфферов.
А на юниксах можно использовать reactor pattern и для обслуживания 100к тысяч полуактивных соединений не надо будет аллокэйтить 100к тысяч буфферов.
А не, сейчас глянул исходник, они в отличие от многих других библиотек, которые реализуют работу с сетью в винде/юниксах, пошли по более эффективному решению и сделали alloc_cb параметром read'а вместо готового буффера — это позволяет на юниксах делать этот alloc только когда в сокет что-то прилетело.
Хотя есть ещё куча претензий вроде отсутствия интерфейсов, которые используют readv, но это уже не так важно. Проблема с масштабированием на юниксах снимается :)
Хотя есть ещё куча претензий вроде отсутствия интерфейсов, которые используют readv, но это уже не так важно. Проблема с масштабированием на юниксах снимается :)
>libuv создаёт проблемы с масштабированием
а можно поподробнее?
а можно поподробнее?
Boost Asio
Зачем нужна эта громадина, когда есть libev/libevent или epoll/kqueue для любителей все делать своими руками?
В Erlang'е есть сборщик мусора. И?
Возможно, если бы его не было, среднее время соединения было бы значительно меньше секунды.
Ткните пожалуйста ссылкой на тест с Tornado?
Скажите, есть ли результаты для Tornado?
Пока нет. Если будут, будут тут: github.com/ericmoritz/wsdemo/blob/master/results.md
Pythin (ws4py)Who is mr. Pythin? :)
А есть результаты по EventMachine?
> Во время бенчмарка каждую миллисекунду запускается новый клиент.
Вот здесь основной затык. Реально пользователи не будут коннектиться каждую миллисекунду. Если создавать коннекшны с бОльшим интервалом, например втечении пяти-десяти минут, то количество коннекшнов будет гораздо больше.
Вот здесь основной затык. Реально пользователи не будут коннектиться каждую миллисекунду. Если создавать коннекшны с бОльшим интервалом, например втечении пяти-десяти минут, то количество коннекшнов будет гораздо больше.
UFO just landed and posted this here
Это да, только в данном случае мерялось скорей производительность создания коннекшнов, а не их работы. Создание коннекшна — тяжелая операция как для ОС, так и для платформы. Если создавать коннекшны неспеша, то Java, например, легко может держать и более 10к коннекшнов. Реальная проблема возникает при числе коннекшнов близком 32767.
> Реально пользователи не будут коннектиться каждую миллисекунду.
Вот тут большой вопрос.
Представьте, что у вас приложение рестартовало по какой-либо причине. Не важно: сетевой сбой, все клиенты отвалились, вы закрыли критическую уязвимость в коде и его нужно перезапустить и пр.
В этой ситуации как раз все клиенты будут ломиться одновременно. И может создасться ситуация, что приложение не сможет подняться, т.к. каждый раз будет падать в процессе запуска.
Итог: приложение может держать все коннекты, если они набираются не слишком быстро, но до первого чиха. А после: «Усе пропало, шеф» ©
Вот тут большой вопрос.
Представьте, что у вас приложение рестартовало по какой-либо причине. Не важно: сетевой сбой, все клиенты отвалились, вы закрыли критическую уязвимость в коде и его нужно перезапустить и пр.
В этой ситуации как раз все клиенты будут ломиться одновременно. И может создасться ситуация, что приложение не сможет подняться, т.к. каждый раз будет падать в процессе запуска.
Итог: приложение может держать все коннекты, если они набираются не слишком быстро, но до первого чиха. А после: «Усе пропало, шеф» ©
> Представьте, что у вас приложение рестартовало по какой-либо причине. Не важно: сетевой сбой, все клиенты отвалились, вы закрыли критическую уязвимость в коде и его нужно перезапустить и пр.
В этой ситуации как раз все клиенты будут ломиться одновременно.
Это напомнило, как в прошлом году (?) так упал Скайп. На винду приехало критическое обновление и огромное количество клиентов перезагрузилось, суперноды не выдержали возросшей нагрузки, сеть легла на два дня
В этой ситуации как раз все клиенты будут ломиться одновременно.
Это напомнило, как в прошлом году (?) так упал Скайп. На винду приехало критическое обновление и огромное количество клиентов перезагрузилось, суперноды не выдержали возросшей нагрузки, сеть легла на два дня
Я дописал сервер на Perl (повесил pull request) и погонял тесты у себя на машине. Что странно, цифры получаются совершенно иные:
РеализацияВремя на подсоединение (среднее)Задержка средняя)СообщенийСоединенийТаймаутов соединения
Erlang4.0083.595203259100000
Go2.2911.289204493100000
Perl2.2661.937204526100000
РеализацияВремя на подсоединение (среднее)Задержка средняя)СообщенийСоединенийТаймаутов соединения
Erlang4.0083.595203259100000
Go2.2911.289204493100000
Perl2.2661.937204526100000
Нда. Я так и думал, что table в комментариях не работает. Хоть бы из списка html-тегов в этом случае его удалили! :(
Тестировал 30 секунд а не 300, т.к. в текущей версии есть баг из-за которого при запуске на 60 и более секунд тест начинает жрать всю память и падает.
# Реализация Handshake Задержка Сообщений Соединений Таймаутов
# Erlang 4.008 3.595 203259 10000 0
# Go 2.291 1.289 204493 10000 0
# Perl 2.266 1.937 204526 10000 0
Тестировал 30 секунд а не 300, т.к. в текущей версии есть баг из-за которого при запуске на 60 и более секунд тест начинает жрать всю память и падает.
ЧТД.
Ну, не знаю, что ЧТД, показывает, что GC-шный VM-ный Erlang не намного хуже компилируемого Go ;) Правда, непонятно, почему задержка настколько выше
UFO just landed and posted this here
Спецификации железа указаны по ссылке. Использовались medium инстансы EC2.
Вы в код тестов заглядывали? Везде минимальная реализация вебсокет-сервера же!
Вот для Node github.com/ericmoritz/wsdemo/blob/master/competition/wsdemo.js
30 строчек всего, остальное — наиболее популярная WebSocket библиотека.
И где здесь можно ошибиться и проявить свое «неумение писать на чем-то кроме эрланга»? Как вы бы написали?
Вот для Node github.com/ericmoritz/wsdemo/blob/master/competition/wsdemo.js
30 строчек всего, остальное — наиболее популярная WebSocket библиотека.
И где здесь можно ошибиться и проявить свое «неумение писать на чем-то кроме эрланга»? Как вы бы написали?
UFO just landed and posted this here
Учитывая что многие держат свои продакшн сервера в облаках, не вижу смысла бенчмаркать на реальном железе, не там, где будет продакшн.
А IO если и перекособочивает, то для всех одинаково.
А IO если и перекособочивает, то для всех одинаково.
UFO just landed and posted this here
В облаках дорого, пока есть большая нагрузка, а как она прошла, опять дёшево. Такая ценовая политика всегда найдёт своего клиента.
И, я надеюсь, мы оба понимаем, что бенчмаркать надо в том же окружении, в котором потом будет продакшн. Как раз именно для того, чтобы бенчмарк выявил проблемы и окружения и используемых инструментов.
И, если ваш любимый инструмент вдруг показал себя в каком-то тесте, в каком-то окружении плохо, надо просто признать проблему. Да, здесь не работает. А не называть дибилами тех, кто его запустил. Иначе это уже баттхёрт.
И, я надеюсь, мы оба понимаем, что бенчмаркать надо в том же окружении, в котором потом будет продакшн. Как раз именно для того, чтобы бенчмарк выявил проблемы и окружения и используемых инструментов.
И, если ваш любимый инструмент вдруг показал себя в каком-то тесте, в каком-то окружении плохо, надо просто признать проблему. Да, здесь не работает. А не называть дибилами тех, кто его запустил. Иначе это уже баттхёрт.
А каким компилятором компилили на go? Стандартным или gcc?
А версию на libev + EV + AnyEvent можно?
Так оно через libev/EV и работает. IO::Stream это просто надстройка над EV для удобства.
Что касается AnyEvent, то мне не нравится сама идея такого модуля. Я несколько лет назад очень активно потестировал все перловские event-loop-ы, и выяснилось, что под высокой нагрузкой единственный модуль, который работает во-первых надёжно и во-вторых без утечек памяти — это EV. Так что выбор движка для event loop это серьёзный вопрос, и писать код который работает на «любом движке» — это круто в теории, а на практике я предпочитаю использовать только надёжные модули.
Что касается AnyEvent, то мне не нравится сама идея такого модуля. Я несколько лет назад очень активно потестировал все перловские event-loop-ы, и выяснилось, что под высокой нагрузкой единственный модуль, который работает во-первых надёжно и во-вторых без утечек памяти — это EV. Так что выбор движка для event loop это серьёзный вопрос, и писать код который работает на «любом движке» — это круто в теории, а на практике я предпочитаю использовать только надёжные модули.
Тогда код положи, пожалуйста, куда-нибудь. Я пока ставлю пакеты на ubuntu :)
Я-ж написал, что повесил pull request. Сам файл здесь.
Так AnyEvent же определяет EV и работает через него? Да и писал их один и тот же автор.
AnyEvent работает через Any Event. :) И хотя этим Any может оказаться и EV, но гарантий нет. Так что я предпочитаю работать через гарантированно надёжный EV, а не через какой повезёт Any.
SUPPORTED EVENT LOOPS/BACKENDS ^
The available backend classes are (every class has its own manpage):
Backends that are autoprobed when no other event loop can be found.
EV is the preferred backend when no other event loop seems to be in use. If EV is not installed, then AnyEvent will fall back to its own pure-perl implementation, which is available everywhere as it comes with AnyEvent itself.
Документация обнадёживает что будет выбран в первую очередь именно EV.
А мне интерфейс AnyEvent почему-то больше нравиться чем EV…
The available backend classes are (every class has its own manpage):
Backends that are autoprobed when no other event loop can be found.
EV is the preferred backend when no other event loop seems to be in use. If EV is not installed, then AnyEvent will fall back to its own pure-perl implementation, which is available everywhere as it comes with AnyEvent itself.
Документация обнадёживает что будет выбран в первую очередь именно EV.
А мне интерфейс AnyEvent почему-то больше нравиться чем EV…
Не подтверждаю твоих данных.
go/node/erlang отработало ок
haskell, perl и python жёстко таймаутит
ruby сказало buffer overflow позорно
go/node/erlang отработало ок
haskell, perl и python жёстко таймаутит
ruby сказало buffer overflow позорно
Почему, интересно, для хаскеля взяли Snap, а не Warp?
UFO just landed and posted this here
Ну да, ну да. Ведь у всех всегда под рукой есть готовое пустое железо для тестов.
UFO just landed and posted this here
> У тех, кто хочет получить вменяемые результаты, а не странную чуйню вроде «отзыв 20 секунд» — конечно есть. Такие дела.
Ну вперед, код выложен — проверяй и опровергай. Языком молоть может каждый.
> Уверен, там можно еще и до кода докопаться. Просто нет смысла смотреть при таком подходе.
А, ну понятно. Лишь бы язык почесать.
Ну вперед, код выложен — проверяй и опровергай. Языком молоть может каждый.
> Уверен, там можно еще и до кода докопаться. Просто нет смысла смотреть при таком подходе.
А, ну понятно. Лишь бы язык почесать.
UFO just landed and posted this here
Для идиотов на танках повторю: не нравится? Код в руки и вперед опровергать. Языком молоть каждый может
UFO just landed and posted this here
Еще раз повторю:
1. Свободное пустое железо для тестов под руками не у каждого валяется
2. Учитывая, сколько сервисов работает в облаках, тестирование в облаках тоже списывать со счетов глупо
3. Если есть пустое железо для тестов — вперед. Код на Гитхабе, проводите тесты, никто вас не останавливает. Молоть языком может каждый
4. Если не нравится код тестов, — вперед. Код на Гитхабе, предлагайте изменения, улучшайте тесты, никто вас не останавливает. Молоть языком может каждый
Но если вы способны только молоть языком, то увы.
1. Свободное пустое железо для тестов под руками не у каждого валяется
2. Учитывая, сколько сервисов работает в облаках, тестирование в облаках тоже списывать со счетов глупо
3. Если есть пустое железо для тестов — вперед. Код на Гитхабе, проводите тесты, никто вас не останавливает. Молоть языком может каждый
4. Если не нравится код тестов, — вперед. Код на Гитхабе, предлагайте изменения, улучшайте тесты, никто вас не останавливает. Молоть языком может каждый
Но если вы способны только молоть языком, то увы.
А вы-то проверяли перед тем как постить топик? ;)
То есть вы утверждаете, что Ноде и Питону мешает виртуалка? Почему же она Эрлангу не мешает справляться с задачей? Не находите логических нестыковок в своих претензиях?
UFO just landed and posted this here
А вы не думали, что человек хотел оттестировать именно результаты для «ксеновская виртуалка»? Учитывая, что сейчас все таи или иначе в облаках, это кажется весьма актуальным. К тому же, условия в плане виртуалки, у всех претендентов одинаковые.
P.S. Зачем так грубо отзываться о человеке, который приложил усилия и поделился своими результатами со всеми. Пусть они даже на ваш взгляд не верны, они все-равно пока куда весомей чем ваши доводы.
P.S. Зачем так грубо отзываться о человеке, который приложил усилия и поделился своими результатами со всеми. Пусть они даже на ваш взгляд не верны, они все-равно пока куда весомей чем ваши доводы.
Странно что нет «идеального» (наиболее близкого к ОС) кода на С или С++.
Так не очень понятно, хорошие эти числа или плохие.
Так не очень понятно, хорошие эти числа или плохие.
«Близкий к ОС код на С/C++» != идеальный. Потому что на том же Erlang'е 10 000 одновременных подсоединений можно легко обработать в 10 000 потоков, чего не сделаешь на C/C++.
Если у Сишника есть хоть какой-то опыт работы с сетью, то он никогда не будет усложнять себе жизнь и заниматься работой с сетевыми подключениями в тредах. Обработку риквестов, которые будут приходить от этих сокетов сишники могут выносить в треды, но не обслуживание соединений.
Вот пришло нам одновременно 100-1000-10000 реквестов. Выносим все в треды? ;)
Зависит от того над чем работаем. Если риквесты не требуют никакого IO, то здесь нет никаких проблем и мы можем поднимать кол-во тредов==кол-ву логических процессоров.
Если есть IO, то тут возникает выбор:
— если работа с легаси кодом, то придётся в тред пул загонять обработку риквестов
— если сишник ленив, то тоже в тред пул
— геморрой, с которым как-то справляются любители node.js'а, когда всё превращается в кашу из коллбэков
— protothreads — это набор макросов, нечто похожее на async в C#
— можно поэкспериментировать с gcc split stacks и получим легковесные треды вроде тех что в Go
Если есть IO, то тут возникает выбор:
— если работа с легаси кодом, то придётся в тред пул загонять обработку риквестов
— если сишник ленив, то тоже в тред пул
— геморрой, с которым как-то справляются любители node.js'а, когда всё превращается в кашу из коллбэков
— protothreads — это набор макросов, нечто похожее на async в C#
— можно поэкспериментировать с gcc split stacks и получим легковесные треды вроде тех что в Go
Ну, то есть приходим к следствию Армстронга ;)
В итоге такой код будет далеко не идеальным и далеко не близким к ОСи ;)
В итоге такой код будет далеко не идеальным и далеко не близким к ОСи ;)
Там же про распределённое программирование, а не про конкарренси.
В итоге код будет работать и выполнять свои задачи. Не все проблемы удачно вписываются под ерланг, тк можно в разы увеличить эффективность, используя другие механизмы для параллелизма в сложных системах.
В итоге код будет работать и выполнять свои задачи. Не все проблемы удачно вписываются под ерланг, тк можно в разы увеличить эффективность, используя другие механизмы для параллелизма в сложных системах.
Ну, распределенного не будет без параллельного :)
Представьте систему к которой подключено N клиентов, каждые 10мс происходит перерасчёт данных, данные сильно связаны между собой, на сях всё это хозяйство реализовано так:
Всё разбито на подзадачи, например: пересчитать положение объектов X, сделать действия Y которые зависят от положения объектов X, выполнить сложные действия, которые зависят от всех остальных задач итд. Дальше всё это естественно выстраивается в граф и планировщик начинает каждые 10мс запускать в тредах всё это хозяйство и уведомлять клиентов об изменениях на которые они подписаны. Увы, но на ерланге всё это превратится в нереально тормозное и корявое поделие.
Ерланг отлично справляется с тем для чего он был сделан, перекачивать данные из одного места в другое, но так же очень ужасен для громадного количества других задач.
Всё разбито на подзадачи, например: пересчитать положение объектов X, сделать действия Y которые зависят от положения объектов X, выполнить сложные действия, которые зависят от всех остальных задач итд. Дальше всё это естественно выстраивается в граф и планировщик начинает каждые 10мс запускать в тредах всё это хозяйство и уведомлять клиентов об изменениях на которые они подписаны. Увы, но на ерланге всё это превратится в нереально тормозное и корявое поделие.
Ерланг отлично справляется с тем для чего он был сделан, перекачивать данные из одного места в другое, но так же очень ужасен для громадного количества других задач.
Что за бредятина :) На Erlang'е это спокойно уложится в дерево супервизоров, а «планировщик» пишется в три с половиной строчки кода.
> Ерланг отлично справляется с тем для чего он был сделан, перекачивать данные из одного места в другое
Бгггг
> Ерланг отлично справляется с тем для чего он был сделан, перекачивать данные из одного места в другое
Бгггг
Да писал я на ерланге ещё лет 6 назад, достаточно хорошо знаю как он работает. То что я описал никоим образом не связано с супервизорами, на ерланге эта задача решалась бы совсем иначе, каждый объект в системе был бы актором и все друг друга бы пинали сообщениями, так раньше и было реализовано на Сях до того как не понадобилось добавить параллелизм для обработки больших объёмов данных(не уменьшения задержек). Потуги как-то ускорить всё это тупым обвешиванием блокировок и запуском внутри планировщика как в эрланге захлебнулись в блокировках и не дали нужного результата. В итоге отказались от таск параллелизма, а использовали дата параллелизм и граф задач, которые обходит эти данные.
Попытаться решить эту проблему таким же способом в ерланге, используя свой планировщик и несколько акторов с большими ets'ками/list'ами и прочим отсутствием нормальных структур данных превратятся в ещё больший ужас.
Попытаться решить эту проблему таким же способом в ерланге, используя свой планировщик и несколько акторов с большими ets'ками/list'ами и прочим отсутствием нормальных структур данных превратятся в ещё больший ужас.
> обработки больших объёмов данных
Вот ключевой момент, а не бредятина про то, как «граф задач будет тормозить на Эрланге».
Вот ключевой момент, а не бредятина про то, как «граф задач будет тормозить на Эрланге».
>> Ерланг отлично справляется с тем для чего он был сделан, перекачивать данные из одного места в другое
>Бгггг
>> обработки больших объёмов данных
>Вот ключевой момент
Ключевой момент в том что следствие Армстронга с его ерлангом, который реализуется модель акторов с таск параллелизмом работает только на определённом кругу задач, где не нужно обрабатывать данные, а гонять из одного конца в другой, например типичные веб приложения, где вся нагрузка на БД или мессенджеры.
>Бгггг
>> обработки больших объёмов данных
>Вот ключевой момент
Ключевой момент в том что следствие Армстронга с его ерлангом, который реализуется модель акторов с таск параллелизмом работает только на определённом кругу задач, где не нужно обрабатывать данные, а гонять из одного конца в другой, например типичные веб приложения, где вся нагрузка на БД или мессенджеры.
> Всё разбито на подзадачи, например: пересчитать положение объектов X, сделать действия Y которые зависят от положения объектов X, выполнить сложные действия, которые зависят от всех остальных задач итд. Дальше всё это естественно выстраивается в граф и планировщик начинает каждые 10мс запускать в тредах всё это хозяйство и уведомлять клиентов об изменениях на которые они подписаны. Увы, но на ерланге всё это превратится в нереально тормозное и корявое поделие.
Без уточнения «большие объемы данных» весь текст выше про «тормозное поделие» является бредом, потому что прекрасно ложится на Erlang.
Без уточнения «большие объемы данных» весь текст выше про «тормозное поделие» является бредом, потому что прекрасно ложится на Erlang.
>потому что прекрасно ложится на Erlang
Да, на ерланге можно написать свой планировщик, вместо тредов ОС использовать акторы и обходить этими акторами список задач, которые будут обрабатывать данные и использовать параллелизм. Но зачем тогда тут ерланг вообще? Если на Си это делается проще и работает на порядки быстрее.
Ерланг выигрывает там где идеально вписываются его акторы, иначе ерланг создаёт больше проблем чем решает.
Да, на ерланге можно написать свой планировщик, вместо тредов ОС использовать акторы и обходить этими акторами список задач, которые будут обрабатывать данные и использовать параллелизм. Но зачем тогда тут ерланг вообще? Если на Си это делается проще и работает на порядки быстрее.
Ерланг выигрывает там где идеально вписываются его акторы, иначе ерланг создаёт больше проблем чем решает.
Блин. Вы шутите или на полном серьезе?
Читаем: Всё разбито на подзадачи… всё это естественно выстраивается в граф и планировщик начинает каждые 10мс запускать в тредах… уведомлять клиентов об изменениях на которые они подписаны.
Не видеть здесь задачу, для которой Эрланг заточен идеально — это или вообще не знать языка, или быть очень жирным и толстым троллем.
Треды, уведомления, граф задач.
Процессы, сообщения, граф задач.
Но да, но да, надо рогом упереться в слово параллелизм, как если бы в эрланге все и всегда обязано обрабатываться параллельно.
Читаем: Всё разбито на подзадачи… всё это естественно выстраивается в граф и планировщик начинает каждые 10мс запускать в тредах… уведомлять клиентов об изменениях на которые они подписаны.
Не видеть здесь задачу, для которой Эрланг заточен идеально — это или вообще не знать языка, или быть очень жирным и толстым троллем.
Треды, уведомления, граф задач.
Процессы, сообщения, граф задач.
Но да, но да, надо рогом упереться в слово параллелизм, как если бы в эрланге все и всегда обязано обрабатываться параллельно.
>Но да, но да, надо рогом упереться в слово параллелизм
Нет, пускай у нас всё будет выполняться не параллельно, это как бы пофиг. Треды ОС тоже этого не гарантируют.
Планировщик стартует треды, внутри которых начинают исполняться задачи, тк мы определили все зависимости задач и во время параллельного запуска эти задачи не модифицируют данные друг друга, то нам не нужно использовать блокировки(основная проблема при таск параллелизме)
В ерланге такое можно даже не выдумывать, тк в случае с ерлангом всё будет тормознее чем если взять тупо акторов(Object_X), которые при изменении их позиции будут перекидываться сообщениями между собой, добавляться в акторы(Object_Area) и при изменении температуры так же плеваться сообщениями и всё будет работать, работать на порядки медленее чем то что можно сделать на Си.
Нет, пускай у нас всё будет выполняться не параллельно, это как бы пофиг. Треды ОС тоже этого не гарантируют.
struct Object_X {
PositionAndVelocity *pv;
float temperature;
}
struct Object_Area {
Rect r;
float temperature;
Array<Object_X> xs;
}
struct Data {
Array<PositionAndVelocity> object_x_pvs;
Array<Object_X> xs;
Array<Object_Area> areas;
}
task_update_positions(Data *d) {
for (p in d->pvs) {
update_position(p);
}
};
@ depends(task_update_positions)
task_update_area_temperatures(Data *d) {
for (a in d->areas) {
update_area_temperature(a);
}
}
@ depends(task_update_area_temperatures)
simulate(Data *d) {};
Планировщик стартует треды, внутри которых начинают исполняться задачи, тк мы определили все зависимости задач и во время параллельного запуска эти задачи не модифицируют данные друг друга, то нам не нужно использовать блокировки(основная проблема при таск параллелизме)
В ерланге такое можно даже не выдумывать, тк в случае с ерлангом всё будет тормознее чем если взять тупо акторов(Object_X), которые при изменении их позиции будут перекидываться сообщениями между собой, добавляться в акторы(Object_Area) и при изменении температуры так же плеваться сообщениями и всё будет работать, работать на порядки медленее чем то что можно сделать на Си.
Переведем на Erlang
> Планировщик стартует треды
Планировщик стартует процессы (причем в случае с supervision tree — со встроенными способами мониторинга за состоянием процесса и т.п.)
> тк мы определили все зависимости задач
тк мы определили все зависимости задач
> во время параллельного запуска эти задачи не модифицируют данные друг друга
во время параллельного запуска эти задачи не модифицируют данные друг друга
> взять тупо акторов(Object_X), которые при изменении их позиции будут перекидываться сообщениями между собой, добавляться в акторы(Object_Area) и при изменении температуры так же плеваться сообщениями
взять тупо gen_server'ов или просто процессов Object_X, которые при изменении их позиции будут перекидываться сообщениями между собой, добавляться в акторы(Object_Area) и при изменении температуры так же плеваться сообщениями
Но да, но да. Используя полностью терминологию Erlang'а, и описывая архитектуру, под которую Erlang заточен, мы продолжаем утверждать, что это в Erlang'е будет криво и тормознуто :))) Дададада, точно кривее и тормознутее, чем написанная на коленке точно такая же система на С (в полном сооответсвии с дополнением Армстронга), потому что в С/С++ все это придется изобретать с нуля (в худшем случае).
> Планировщик стартует треды
Планировщик стартует процессы (причем в случае с supervision tree — со встроенными способами мониторинга за состоянием процесса и т.п.)
> тк мы определили все зависимости задач
тк мы определили все зависимости задач
> во время параллельного запуска эти задачи не модифицируют данные друг друга
во время параллельного запуска эти задачи не модифицируют данные друг друга
> взять тупо акторов(Object_X), которые при изменении их позиции будут перекидываться сообщениями между собой, добавляться в акторы(Object_Area) и при изменении температуры так же плеваться сообщениями
взять тупо gen_server'ов или просто процессов Object_X, которые при изменении их позиции будут перекидываться сообщениями между собой, добавляться в акторы(Object_Area) и при изменении температуры так же плеваться сообщениями
Но да, но да. Используя полностью терминологию Erlang'а, и описывая архитектуру, под которую Erlang заточен, мы продолжаем утверждать, что это в Erlang'е будет криво и тормознуто :))) Дададада, точно кривее и тормознутее, чем написанная на коленке точно такая же система на С (в полном сооответсвии с дополнением Армстронга), потому что в С/С++ все это придется изобретать с нуля (в худшем случае).
Ну и продолжу:
> Да, на ерланге можно написать свой планировщик, вместо тредов ОС использовать акторы и обходить этими акторами список задач, которые будут обрабатывать данные и использовать параллелизм. Но зачем тогда тут ерланг вообще? Если на Си это делается проще и работает на порядки быстрее.
В C появились планировщики задач?
В С появились внятные способы запуска и мониторинга процессов/потоков?
В С появились сообщения для общения между этими потоками?
Или это все придется реализовывать ручками? (Ну или собирать по кусочкам из библиотек)
> Да, на ерланге можно написать свой планировщик, вместо тредов ОС использовать акторы и обходить этими акторами список задач, которые будут обрабатывать данные и использовать параллелизм. Но зачем тогда тут ерланг вообще? Если на Си это делается проще и работает на порядки быстрее.
В C появились планировщики задач?
В С появились внятные способы запуска и мониторинга процессов/потоков?
В С появились сообщения для общения между этими потоками?
Или это все придется реализовывать ручками? (Ну или собирать по кусочкам из библиотек)
>взять тупо gen_server'ов
это я как раз и описывал как делал бы на ерланге, поэтому такое сходство, тк от реализации того что описал выше нет никакого профита в ерланге.
и уж gen_server'ы с их оверхедом я бы не брал, еслиб было так критично по производительности.
>описывая архитектуру, под которую Erlang заточен
shared nothing actors ерланга != задачи, которые не модифицируют данные друг друга
единственный способ, с помощью которого мы можем как-то получить доступ к общим данным насколько помню — это только ets, иначе придётся перекидывать громадные массивы данных между акторами.
>В C появились планировщики задач?
планировщик задач так тяжело написать? В данном примере спокойно будет работать примитивный планировщик, без всяких task stealing'ов, которые реализованы в ерланге.
Если нужны более мощные, конфигурируемые планировщики, то всегда под рукой есть intel tbb.
>В С появились внятные способы запуска и мониторинга процессов/потоков?
если вы про аналог легковесных акторов, то не появилось, но в большинстве случаев не нужны все возможности акторов, а если прижмёт, то не так тяжело дописать какой-то функционал для protothreads или как-то иначе решить проблему. Но в задаче, которую я описывал выше — вообще не уместны акторы/protothreads итд.
>В С появились сообщения для общения между этими потоками?
Не всегда нужна какая-то богатая система для общения между потоками(например в задаче, которую я описывал выше — не нужна) или если вы опять про богатый функционал акторов, то в protothreads написан примитив, поверх которого легко добавить сообщения.
это я как раз и описывал как делал бы на ерланге, поэтому такое сходство, тк от реализации того что описал выше нет никакого профита в ерланге.
и уж gen_server'ы с их оверхедом я бы не брал, еслиб было так критично по производительности.
>описывая архитектуру, под которую Erlang заточен
shared nothing actors ерланга != задачи, которые не модифицируют данные друг друга
единственный способ, с помощью которого мы можем как-то получить доступ к общим данным насколько помню — это только ets, иначе придётся перекидывать громадные массивы данных между акторами.
>В C появились планировщики задач?
планировщик задач так тяжело написать? В данном примере спокойно будет работать примитивный планировщик, без всяких task stealing'ов, которые реализованы в ерланге.
Если нужны более мощные, конфигурируемые планировщики, то всегда под рукой есть intel tbb.
>В С появились внятные способы запуска и мониторинга процессов/потоков?
если вы про аналог легковесных акторов, то не появилось, но в большинстве случаев не нужны все возможности акторов, а если прижмёт, то не так тяжело дописать какой-то функционал для protothreads или как-то иначе решить проблему. Но в задаче, которую я описывал выше — вообще не уместны акторы/protothreads итд.
>В С появились сообщения для общения между этими потоками?
Не всегда нужна какая-то богатая система для общения между потоками(например в задаче, которую я описывал выше — не нужна) или если вы опять про богатый функционал акторов, то в protothreads написан примитив, поверх которого легко добавить сообщения.
Еще раз повторю. Опираясь только на это описание задачи:
эта задача идеально подходит для Эрланга.
Что тут спорить, я вообще не понимаю.
Но!
Если у нас появляется доп. условие, как-то: «большие объемы данных», то да, Erlang может не подойти.
Я это написал еще пять сообщений тому назад.
Вы мне начинаете рассказывать сказки про кривизну решения на Erlang'е, рассказывая какой-то бред про параллелизм, про толпу каких-то кубиков и наколенных решений в С, в то в время как проблема лежит не в параллелизме, не в акторах, не в оверхедах gen_server'ов, не в «сложных сообщениях» и т.п.
Всё разбито на подзадачи, например: пересчитать положение объектов X, сделать действия Y которые зависят от положения объектов X, выполнить сложные действия, которые зависят от всех остальных задач итд. Дальше всё это естественно выстраивается в граф и планировщик начинает каждые 10мс запускать в тредах всё это хозяйство и уведомлять клиентов об изменениях на которые они подписаны.
эта задача идеально подходит для Эрланга.
Что тут спорить, я вообще не понимаю.
Но!
Если у нас появляется доп. условие, как-то: «большие объемы данных», то да, Erlang может не подойти.
Я это написал еще пять сообщений тому назад.
Вы мне начинаете рассказывать сказки про кривизну решения на Erlang'е, рассказывая какой-то бред про параллелизм, про толпу каких-то кубиков и наколенных решений в С, в то в время как проблема лежит не в параллелизме, не в акторах, не в оверхедах gen_server'ов, не в «сложных сообщениях» и т.п.
>Я это написал еще пять сообщений тому назад.
Я просто подумал, что:
">> Ерланг отлично справляется с тем для чего он был сделан, перекачивать данные из одного места в другое
>Бгггг"
означает что ерланг отлично справляется с обработкой данных, а не только перекидыванием из одного места в другое.
>про толпу каких-то кубиков и наколенных решений в С
да, мужики из ерланга ограничиваются только OTP и никогда не используют сторонние решения. Что за идиоты придумали cpan, rubygems, pypi когда нужно использовать только стандартную библиотеку, а всё остальное — это какое-то наколенное решение, ведь планировщик, обмен сообщениями — это такие сложные вещи которые должны быть в стандартной либе, а ещё лучше в самом рантайме :)
>Вы мне начинаете рассказывать
Я лишь хотел привести пример, когда ерланговая модель акторов не справляется со своей задачей, раз уж вы заговорили о том как любая система в итоге реализует урезаный вариант ерланга с его распределённостью и параллелизмом.
Я просто подумал, что:
">> Ерланг отлично справляется с тем для чего он был сделан, перекачивать данные из одного места в другое
>Бгггг"
означает что ерланг отлично справляется с обработкой данных, а не только перекидыванием из одного места в другое.
>про толпу каких-то кубиков и наколенных решений в С
да, мужики из ерланга ограничиваются только OTP и никогда не используют сторонние решения. Что за идиоты придумали cpan, rubygems, pypi когда нужно использовать только стандартную библиотеку, а всё остальное — это какое-то наколенное решение, ведь планировщик, обмен сообщениями — это такие сложные вещи которые должны быть в стандартной либе, а ещё лучше в самом рантайме :)
>Вы мне начинаете рассказывать
Я лишь хотел привести пример, когда ерланговая модель акторов не справляется со своей задачей, раз уж вы заговорили о том как любая система в итоге реализует урезаный вариант ерланга с его распределённостью и параллелизмом.
> да, мужики из ерланга ограничиваются только OTP и никогда не используют сторонние решения.
Вы опять несете какую-то чушь. Я говорю о том, что «криво реализуемая фигня на Erlang'е», которую вы описываете, на Erlang'е уже давным давно реализована и является частью языка и библиотеки (граф. процессов, процессы, сообщения, callback'и и т.п.)
> Я лишь хотел привести пример, когда ерланговая модель акторов не справляется со своей задачей,
Ага-ага. Повторю в последний раз. Вы описали задачу, которая на Erlang ложится идеально. Единственное в этой задаче, что на Erlang не ложится — это большие данные.
Но вы то решили говорить не о них. Вы решили рассказать бредятину про то, как на эрлнаге сложно реализовать взаимодействие процессов :-\
Вы опять несете какую-то чушь. Я говорю о том, что «криво реализуемая фигня на Erlang'е», которую вы описываете, на Erlang'е уже давным давно реализована и является частью языка и библиотеки (граф. процессов, процессы, сообщения, callback'и и т.п.)
> Я лишь хотел привести пример, когда ерланговая модель акторов не справляется со своей задачей,
Ага-ага. Повторю в последний раз. Вы описали задачу, которая на Erlang ложится идеально. Единственное в этой задаче, что на Erlang не ложится — это большие данные.
Но вы то решили говорить не о них. Вы решили рассказать бредятину про то, как на эрлнаге сложно реализовать взаимодействие процессов :-\
>про толпу каких-то кубиков и наколенных решений в С
>Я говорю о том, что «криво реализуемая фигня на Erlang'е», которую вы описываете, на Erlang'е уже давным давно реализована и является частью языка и библиотеки
Так и я об этом написал :) О том что всё что уже реализовано в рантайме или стандартной либе — это труъ, а всё что в библиотеках, как например intel tbb, это для неудачников, которые не знают что в ерланг рантайме всё встроено :)
>Вы решили рассказать бредятину про то, как на эрлнаге сложно реализовать взаимодействие процессов
Ну вы же поняли, что я описывал что эрланг пригоден только для перекидывания данных из одного места в другое, а для обработки данных он как-то совсем не очень, если только под обработкой не понимается отрендерить шаблон и подставить в него какие-то данные ;)
А вообще всё началось с разрыва мозга про то что любая система, в которой нужна _конкарренси_ в итоге реализует какую-то часть ерланга, хотя там было написано про распределённую систему, но вы зачем-то потом добавили бредятину про параллелизм, который опять никоем местом не относился к теме :) На что я рассказал историю о том что особого профита от ерлангового параллелизма мы не можем получить, тк параллелизм штука сложная и то что подходит для решения одной задачи будет полным гавном для решения другой задачи.
>Я говорю о том, что «криво реализуемая фигня на Erlang'е», которую вы описываете, на Erlang'е уже давным давно реализована и является частью языка и библиотеки
Так и я об этом написал :) О том что всё что уже реализовано в рантайме или стандартной либе — это труъ, а всё что в библиотеках, как например intel tbb, это для неудачников, которые не знают что в ерланг рантайме всё встроено :)
>Вы решили рассказать бредятину про то, как на эрлнаге сложно реализовать взаимодействие процессов
Ну вы же поняли, что я описывал что эрланг пригоден только для перекидывания данных из одного места в другое, а для обработки данных он как-то совсем не очень, если только под обработкой не понимается отрендерить шаблон и подставить в него какие-то данные ;)
А вообще всё началось с разрыва мозга про то что любая система, в которой нужна _конкарренси_ в итоге реализует какую-то часть ерланга, хотя там было написано про распределённую систему, но вы зачем-то потом добавили бредятину про параллелизм, который опять никоем местом не относился к теме :) На что я рассказал историю о том что особого профита от ерлангового параллелизма мы не можем получить, тк параллелизм штука сложная и то что подходит для решения одной задачи будет полным гавном для решения другой задачи.
Можете протестировать github.com/kakserpom/phpdaemon?
Так и не смог запустить тест:
Огорчился.
./runtest results/java.dat 300 192.168.1.8 8000 10000
Running test with 10000 clients for 300 seconds
Data File: "results/java.dat"
escript: exception error: undefined function wsdemo_logger:new/1
in function runtest__escript__1339__771169__243679:main/1
in call from escript:run/2
in call from escript:start/1
in call from init:start_it/1
in call from init:start_em/1
Огорчился.
Две слабеньких ноды на одной клиент на другой сервер (ubuntu 12.04 64bit, Intel Core i5 M450 (1 core), 1GB)
Получился такой результат:
Получился такой результат:
erlang go python torna node.js
clients 2746 2851 2763 7002
handshakes 2744 2850 2761 2933
connection_timeouts 0 0 0 2728
messages_recv 555231 564177 519975 61927
handshake_time.median 75.666 13.107 162.254 2227.526
message_latency.median 447.559 486.75 2047.321 98011.552
crashes 0 0 0 0
Примерно одинаковые результаты получились из-за того что клиент уперся в ресурсы, добавил ему ядро и памяти:
Думаю что реализацию python tornado для этого теста можно неплохо улучшить, т.к. сейчас у него большой показатель «connection_timeouts», — сервер показывает очень много закрытий потоков, (видимо таймаут со стороны клиента) — а каждое закрытие вызывает исключение — с формированием полного tracaback и в консоль валиться «тонна» логов — это не такие уж и легкие блокирующие операции.
erlang go py_tornado node.js
clients 10000 10000 10000 10000
handshakes 4285 3989 4594 1926
connection_timeouts 5478 4531 5406 8074
messages_sent 1015680 993991 1280922 556111
messages_recv 713854 776522 293795 179100
handshake_time.median 1657.051 24.955 993.679 1945.153
message_latency.median 40455.355 32573.558 98749.899 96158.056
crashes 0 0 0 0Думаю что реализацию python tornado для этого теста можно неплохо улучшить, т.к. сейчас у него большой показатель «connection_timeouts», — сервер показывает очень много закрытий потоков, (видимо таймаут со стороны клиента) — а каждое закрытие вызывает исключение — с формированием полного tracaback и в консоль валиться «тонна» логов — это не такие уж и легкие блокирующие операции.
Вот тут blog.virtan.com/2012/07/million-rps-battle.html аналогичное тестирование между C/C++/Java/Erlang/NodeJS/Python/Perl. Результаты несколько отличаются.
вторая часть бенчмарка «вышла», к слову eric.themoritzfamily.com/websocket-demo-results-v2.html
Sign up to leave a comment.
C10k (Проблема 10000 соединений) на разных языках/платформах