Comments 29
Как раз занимаюсь вопросом практической безопасности (точнее, опасности) авторизации по голосу.
Спасибо за материал, очень ценно!
Спасибо за материал, очень ценно!

И никто не пошутит про «Добавочный — три шестьдесят две»? :)
Отлично, сам юзаю вайвлет и метод отпечатков, а до кохонена никак руки не доходили. Спасибо, относительно просто отписали).
Скажите, а кроме голоса, будет ли Ваш метод анализировать другие звуковые шаблоны (скажем машинные звуки, или хлопки/щелчки например)?
Я так понимаю, система никак не защищена от подделки в виде звучащего из динамика записанного голоса?
Если динамик будет выдавать голос на тех же частотах, что и оригинал, то никак.
ЕМНИП то спектаральная характеристика человеческого голоса гораздо шире, чем в спектральная характеристика частоп воспроизводимых динамиком. Чтобы добиться удовлетворительного результата, нужен оочень качественный динамик. Плюс учитывайте что микрофон вносит в искажения при усилении, соответственно усиление и так искаженного звука динамиком будет весьма отличаться от естесственного голоса. В принципе можно всем этим делом пренебречь и взять сферический динамик в вакууме, тогда xtelekom абсолютно прав и отличий не будет.
ЕМНИП то спектаральная характеристика человеческого голоса гораздо шире, чем в спектральная характеристика частоп воспроизводимых динамиком.
Стоп, как же это? Самая обычная звуковая система способна воспроизводить частоты от 50 Гц до 18 кГЦ, тогда как спектр человеческой речи лежит в пределах от 100 до 300 Гц. Или я чего-то не понял?
Я не правильно выразился. Хм, я имел ввиду то что спектры человеческого голоса, да и вообще звуков воспринимаемых человеком гораздо насыщенее нежели спектры воспроизводимые динамиками, пусть у них хоть от 6Гц до 25кГц. Плюс учитывайте тот момент что прежде чем воспроизвести необходимо этот сигнал закодировать. Хорошо, предположим что мы взяли один из популярных lossless форматов и воспроизводим закодированный звук с точностью до бита. Но, точность до бита позволяет добится вам максимальной отдачи при воспроизведение звука у когорого была качественная цифровая обработка с достаточным уровнем дискретизации. А если нет, то все это воспроизведение опять таки будет с искажениями. Проблема состоит в качественной оцифровке голоса, и выделении его составляющих из общего фона.
Идентификация по биометрикам — зло:
— Зачастую слабая защищенность от replay атак
— Нет возможности «сменить пароль» при его компрометации
— Зачастую слабая защищенность от replay атак
— Нет возможности «сменить пароль» при его компрометации
Поэтому я и забросил проект
Возможно вы в курсе, как же тогда лучше идентифицировать?
Я вижу единственный вариант «сильной» защиты голосом — если мы научились узнавать голос «вообще», то можно просить каждый раз произнести что-то другое. (совмещение каптчи и голосового распознавания).
Что именно делает фильтр шумоподавления, приведенный в начале статьи?
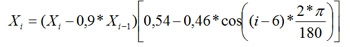
Обрезает высокие частоты? И откуда получены такие коэффициенты?
Т.к. если это фильтр на базе преобразования Фурье, то неплохо бы привести вывод этой формулы, а иначе совсем непонятно что это за зверь и где его можно применить

Обрезает высокие частоты? И откуда получены такие коэффициенты?
Т.к. если это фильтр на базе преобразования Фурье, то неплохо бы привести вывод этой формулы, а иначе совсем непонятно что это за зверь и где его можно применить
Там же написано «Входной дискретный звуковой сигнал обрабатывается фильтрами», до фурье еще дело не дошло, там другие фильтры. Коэффициенты подобраны методом научного тыка, не мной, нашел в литературе.
Как вы защищаетесь от записанного на диктофон голоса?
Биометрическая идентификация имеет свои ниши. К примеру, для автомобильных систем управляемых голосом, востребована идентификация, позволяющая системе выделять из голосов разных людей голос водителя и реагирующая только на него. Аналогично, игровая приставка должна различать голоса игроков и реагировать на них, к примеру изменением поведения их персонажей. Это примеры, в которых достаточно и не 100% идентификации.
Можно еще массово прослушивать телефоны и вылавливать голоса людей, которые находятся в розыске. Наверняка есть еще куча специфических примеров, так что всему свое место.
Можно еще массово прослушивать телефоны и вылавливать голоса людей, которые находятся в розыске. Наверняка есть еще куча специфических примеров, так что всему свое место.
Sign up to leave a comment.
Идентификация пользователя по голосу