Comments 103
Да вы круты! :) Спасибо за подборку модулей и описание проблем и решений.
используя MongoDB можно в принципе обходится и без мемкэша. При наличии достаточного количества памяти конечно.
Разница в скорости работы с мемкешем и без на данном проекте довольно существенная. Хотя это сильно зависит от конфигурации сервера и самих запросов.
Видимо Cher имел ввиду, что кэшировать данные можно в ту же самую монгу
Всё же memcached даёт замечательную возможность автоматического удаления данных, когда у них заканчивается срок годности. В MongoDd придётся это отслеживать руками. Мне кажется, что пусть лучше каждое приложение будет занято своими обязанностями.
В MongoDd придётся это отслеживать рукамиА вот и неправда. В mongoDB для данных можно задавать как время жизни, так и максимальный размер коллекции.
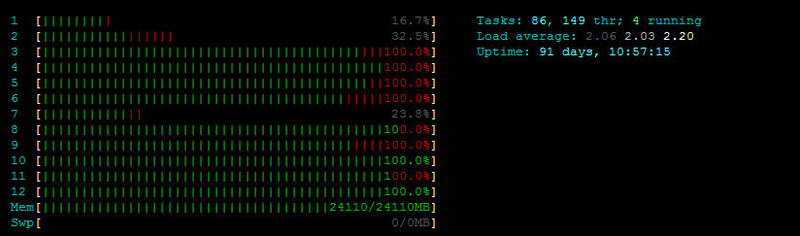
После публикации статьи кто-то начал очень интенсивно тестировать сайт на нагрузку. Тест идёт уже где-то полтора часа. htop показывает приблизительно такую картину:
 .
.
Большинство запросов заворачивается с ошибкой 503, т.к. в Nginx прописаны ограничения на количество запросов и одновременных соединений с IP-адреса. В это время у всех остальных сайт отображается корректно.
 .
.Большинство запросов заворачивается с ошибкой 503, т.к. в Nginx прописаны ограничения на количество запросов и одновременных соединений с IP-адреса. В это время у всех остальных сайт отображается корректно.
кстати, как такие ограничения задать подскажите?
Вот 2 модуля Nginx, которые я использовал для этого:
wiki.nginx.org/HttpLimitZoneModule
wiki.nginx.org/HttpLimitReqModule
wiki.nginx.org/HttpLimitZoneModule
wiki.nginx.org/HttpLimitReqModule
Контроллер, при необходимости, вызывает методы модели, которые получают данные из MongoDb или Memcached. Когда все данные для ответа готовы, контроллер даёт команду шаблонизатору на формирование страницы и отправляет сгенерированный html пользователю.
Если не секрет, при ожидании подготовки данных, используется только async?
А как реализованы запросы к MongoDB? Интересен исходный код.
Пример получения данных для страницы «обсуждаемые»:
var hub = require('hub');
/* Тут инициализируются другие объекты нужные модулю, убрал для краткости */
var collection = new hub.mongodb.Collection(hub.mongodbClient, 'message');
/* Тут расположены остальные методы этой модели */
module.exports.findDiscussed = function(page, cb) {
collection.find({isPublished: true, type: 0, replies: {$ne: 0}}, function(err, cursor) {
cursor.sort({replyDt: -1}).limit(hub.config.app.perPage).skip(page * hub.config.app.perPage);
cursor.toArray(function(err, messages) {
cb(err, messages);
});
});
};
/* И тут тоже */
Я, наверно, схвачу ещё пару минусов, но не могу не задать один вопрос: вы вообще код пишете, или только модули в кучу собираете?
p.s. за подборку-то да, спасибо, но статья же должна быть не о том.
p.p.s. я так реагирую на это, потому что сам пишу проект на Node.js. Использую ровно 2 сторонних (не своих) модуля — шаблонизатор и коннектор к БД.
p.s. за подборку-то да, спасибо, но статья же должна быть не о том.
p.p.s. я так реагирую на это, потому что сам пишу проект на Node.js. Использую ровно 2 сторонних (не своих) модуля — шаблонизатор и коннектор к БД.
Среди тех модулей, что я привёл выше, что по вашему лишнее? Я не люблю изобретать велосипеды, только в крайнем случае. Вот вы говорите, что используете только шаблонизатор и коннектор к БД. А такие рутинные вещи, как поддержка сессий, разбор multipart-запросов для вычленения из них файлов, удобную работу с куками (они же в нативном виде приходят просто массивом заголовков), роутинг. Вы это с нуля сами пишите? Я не вижу в этом смысла. Я не в коем случае не предлагаю безумно собирать всё подряд и использовать это. Перед тем, как что-либо подключить к проекту я внимательно изучаю его исходный код, чтобы понять как оно работает и не будет ли оно где-то фейлить. Но писать что-то, что уже написано до вас и возможно написано лучше чем вы сможете написать за ограниченное время — смысла не вижу. Лучше сосредоточиться на логике приложения и обеспечить его стабильную работу. Как ни крути — используя сторонние модули это выйдет сделать гораздо быстрее.
Промахнулся, написал ответ комментарием к посту
Разработка приложений — это не «написал и забыл», на мой взгляд. А поддержка кода проще, когда надо поддерживать свой код, а не десятки сторонних модулей. Ну и, ниже я написал, что является лишним в принципе. Если насчёт oauth и twitter можно поспорить, что это будут велосипеды, то остальное — это использование велосипедов других авторов.
Как раз таки модульная архитектура позволяет прощу управлять приложением. У популярных модулей сотни а у некоторых и тысячи пользователей. Ошибка в такой разработке локализуется и справляется гораздо быстрее, т.к. код постоянно исследуют и улучшают множество разработчиков. По сути — это бесплатный труд. Остаётся только сказать им спасибо и помогать по возможности. От этого выигрывают все.
Та же ситуация. Использую около 5-7 модулей, но причина другая — хотел (и всё ещё хочу) попробовать многое реализовать сам. Не совсем понял зачем вам hub. Я для этого использую globals. Проблемы засорения глобального пространства не наблюдаю, так как точно знаю что и почему я там храню. Все маловажные но повсюду нужные функцию расширяю в объект $ (jQuery). В модулях использую что-то подобное классам из prototype, так намного проще понимать и развивать код. В довершении ко всему пользуюсь node-sync, вместо async (но полагаю что для средних и крупных проектов это может быть фатальным).
Я для этого использую globals.Зачем???
jQueryв node.js? Кажется, я чего-то не понимаю в этом мире.
1. Удобно. Вы можете предложить что-то удобнее? require хороший механизм, но я использую его только для сторонних модулей. Свои личные принципы построения приложений на js я выработал ещё до знакомства с nodejs, и пока не вижу никаких причин от них отказываться.
2. К jQuery я привык, в этой библиотеке есть масса привычных мне функций. А также я использую её для парсинга HTML. Старые добрые методы для манипуляции с DOM уже не раз пригодились мне в nodejs. Учитывая что я могу применить их и для какого-либо XML документа, полагаю вопрос отпадает само по себе.
2. К jQuery я привык, в этой библиотеке есть масса привычных мне функций. А также я использую её для парсинга HTML. Старые добрые методы для манипуляции с DOM уже не раз пригодились мне в nodejs. Учитывая что я могу применить их и для какого-либо XML документа, полагаю вопрос отпадает само по себе.
Мне религия не позволяет использовать globals. node-sync разработка конечно очень интересная и выглядит красиво. Но она использует fiber'ы. А это по сути потоки. Тут можно скатиться в крайности. Типа заворачивать обработку каждого реквеста в свой fiber. Они не будут блокировать друг друга, но внутри мы получим тот же пхп без преимущества асинхронного IO. Либо моно заворачивать в fiber'ы куски внутри одного реквеста, тогда получается что для каждого запроса будет стартовать несколько потоков. И на большом количестве запросов я не уверен, что это будет работать стабильно. Без тестов на реальном приложении в условиях хотябы приближенным к реальным я побоюсь использовать такой подход, каким бы красивым он не казался.
Не вижу никакой разницы между использование globals и hub с точки зрения религии. Вы делаете ровным счётом тоже самое, но в пределах одного объекта. Однако вам приходится по всюду таскать require и писать лишние hub. На мой взгляд, это премудрости :) Бог идеального кода не простит вам такие грехи.
Касательно sync-а согласен с вами. Моя ситуация позволяет использовать мне их без риска, в виду специфики задачи. Очень жду большой разгромной, или полной обожания статьи, которая расставила бы все точки над i.
Касательно sync-а согласен с вами. Моя ситуация позволяет использовать мне их без риска, в виду специфики задачи. Очень жду большой разгромной, или полной обожания статьи, которая расставила бы все точки над i.
что у вас <= что лучше/проще (+бонус)
async <= habrahabr.ru/blogs/javascript/137818/
node-oauth <= легко пишется (даёт опыт)
node-twitter <= легко пишется (даёт опыт)
http-get <= http.get
daemon.node <= init script
form <= regexp
configjs <= {}
localejs <= {}
hub <= правильная структура приложения (даёт опыт)
connect-response <= http + шаблонизатор
async <= habrahabr.ru/blogs/javascript/137818/
node-oauth <= легко пишется (даёт опыт)
node-twitter <= легко пишется (даёт опыт)
http-get <= http.get
daemon.node <= init script
form <= regexp
configjs <= {}
localejs <= {}
hub <= правильная структура приложения (даёт опыт)
connect-response <= http + шаблонизатор
1. form <= regexp. В корне не согласен. Я полагаю речь идёт об удобном и лёгком в использовании автоматизированном инструменте, который позволяет проверять формы, наглядно выводить ошибки связывая их с нужными полями. Сам написал для этого велосипед и он получился весьма большим. Да в нём повсюду используются регулярки, но без него для каждой формы пришлось бы писать свой новый велосипед, которые очень сложно поддрживать. Чем больше мне приходится работать со сложными и не очень формами, тем больше я прихожу к выводу, что без мощного и удобного инструмента это нелепая трата времени.
2. localejs <= {}. Аналогично. Я полагаю, что надо привыкать сразу к удобным инструментам, которые сделают за тебя всю работу и будут удобны людям, переводящим сайт.
3. async <=… Не зря же та статья вызвала столько споров. Получается огромный малочитаемый код, который не решил никаких проблем. ИМХО.
2. localejs <= {}. Аналогично. Я полагаю, что надо привыкать сразу к удобным инструментам, которые сделают за тебя всю работу и будут удобны людям, переводящим сайт.
3. async <=… Не зря же та статья вызвала столько споров. Получается огромный малочитаемый код, который не решил никаких проблем. ИМХО.
1. А разве «каждую новую форму» не надо валидировать по своему? Если нет — то и проблем нет, а если да — то зачем велосипед, который делает сразу всё?
2. Чем хэш неудобен? Самое наглядное и простое решение. Для крупных проектов, естественно, нужна какая-то своя система, учитывающая особенности проекта, но тут-то речь о небольших (по функциональности\команде разработчиков) сервисах.
3. Код, как раз-таки, самый читаемый, не надо разбираться в синтаксисе сторонних модулей, не надо извращаться, что-то придумывая. В node.js же специально всё сделано асинхронным, зачем что-то с этим делать?
2. Чем хэш неудобен? Самое наглядное и простое решение. Для крупных проектов, естественно, нужна какая-то своя система, учитывающая особенности проекта, но тут-то речь о небольших (по функциональности\команде разработчиков) сервисах.
3. Код, как раз-таки, самый читаемый, не надо разбираться в синтаксисе сторонних модулей, не надо извращаться, что-то придумывая. В node.js же специально всё сделано асинхронным, зачем что-то с этим делать?
1. Ну макс. добавить новый фильтр, которые наверняка потом пригодится в дальнейшем
2. А чем он удобен? Ведь в {} нужно же ещё погрузить нужные данные, а тех что не хватает взять из языка по умолчанию. Думаю что такого рода тонкостей может быть много. Все эти хеши (а по сути только их я до сего момента и использовал\ую) никогда не казались мне удобными для решения проблем локализации.
3. Лапша вначале поста гораздо более читаемая, нежели та же самая лапша но по вертикали. Честно говоря, она даже хуже. Что касается изврата, чем в большие дебри языка я ухожу, тем больше мне кажется, что именно для этого он и создан. Превосходный пластилин, позволяющий вылепить много удобных и полезных конструкций, решений. Что касается асинхронности, в этом плане сильно не хватает цивилизованных современных решений вроде волокон. Я их по крайней мере использую, но не уверен что сгодится для крупных проектов, видимо нужно ждать пока «устаканится». Если бы передо мной стал выбор писать как написано в той статье или писать на другом языке, я бы выбрал второе не задумываясь.
ИМХО
2. А чем он удобен? Ведь в {} нужно же ещё погрузить нужные данные, а тех что не хватает взять из языка по умолчанию. Думаю что такого рода тонкостей может быть много. Все эти хеши (а по сути только их я до сего момента и использовал\ую) никогда не казались мне удобными для решения проблем локализации.
3. Лапша вначале поста гораздо более читаемая, нежели та же самая лапша но по вертикали. Честно говоря, она даже хуже. Что касается изврата, чем в большие дебри языка я ухожу, тем больше мне кажется, что именно для этого он и создан. Превосходный пластилин, позволяющий вылепить много удобных и полезных конструкций, решений. Что касается асинхронности, в этом плане сильно не хватает цивилизованных современных решений вроде волокон. Я их по крайней мере использую, но не уверен что сгодится для крупных проектов, видимо нужно ждать пока «устаканится». Если бы передо мной стал выбор писать как написано в той статье или писать на другом языке, я бы выбрал второе не задумываясь.
ИМХО
2. Что значит «погрузить»? Сразу в хэше всё и хранить. Можно хэш выделить в отдельный модуль, в котором ничего другого не будет.
text = dictionary['ru'][textKey] || dictionary['en'][textKey];
3. Вопрос в том, насколько разработчик понимает язык и как у него дела с логикой.
тех что не хватает взять из языка по умолчанию
text = dictionary['ru'][textKey] || dictionary['en'][textKey];
3. Вопрос в том, насколько разработчик понимает язык и как у него дела с логикой.
2. Такое сгодится только в самых простых ситуациях.
3. Именно поэтому и расплодилось разных решений, потому что с логикой хорошо у многих и люди стремятся к удобному. JS к этому располагает.
3. Именно поэтому и расплодилось разных решений, потому что с логикой хорошо у многих и люди стремятся к удобному. JS к этому располагает.
2. см выше:
3. Как я себе это представляю:
а) разработчик учит язык — пытается писать всё сам.
б) разработчик что-то умеет — берёт модули, склеивает их своим кодом
в) разработчик осознал, что он не просто кодер — выкидывает всё лишнее, понимает что он использует и зачем
г) сюда я ещё не добрался, но предполагаю, что всё развивается по спирали.
Для крупных проектов, естественно, нужна какая-то своя система, учитывающая особенности проекта, но тут-то речь о небольших (по функциональности\команде разработчиков) сервисах.
3. Как я себе это представляю:
а) разработчик учит язык — пытается писать всё сам.
б) разработчик что-то умеет — берёт модули, склеивает их своим кодом
в) разработчик осознал, что он не просто кодер — выкидывает всё лишнее, понимает что он использует и зачем
г) сюда я ещё не добрался, но предполагаю, что всё развивается по спирали.
2. не обязательно для крупных, даже для мелких. Железобетонные языковые-конфиги годятся только для самых элементарных ситуаций, которые, как минимум, подразумевают что править их будут люди знакомые с {}-разметкой и обладающие доступом, к примеру, к FTP.
3. Я вижу это так:
а) разработчик постигает АЗЫ языка.
б) разработчик начинает понимать суть языка и как на нём писать.
в) разработчик знает язык и делает с ним всё, что пожелает.
г) разработчик знает язык как свои 5 пальцев
При этом использование сторонних модулей, упрощение и усложнение кода никак не относятся к данному списку, так как могут сопровождать каждый из пунктов. Они вообще никак не связаны со знанием языка, только задача определяет их.
3. Я вижу это так:
а) разработчик постигает АЗЫ языка.
б) разработчик начинает понимать суть языка и как на нём писать.
в) разработчик знает язык и делает с ним всё, что пожелает.
г) разработчик знает язык как свои 5 пальцев
При этом использование сторонних модулей, упрощение и усложнение кода никак не относятся к данному списку, так как могут сопровождать каждый из пунктов. Они вообще никак не связаны со знанием языка, только задача определяет их.
Тут есть, что обсудить. Эти утверждения очень субъективны. Я про <=.
Начну с того, что вобще всё пишется относительно легко, когда знаешь как оно работает. Но это не является поводом писать это самому.
async делает разработку более удобной. Если я знаю как он работает и могу написать аналог это не значит что я должен этим заниматься. В статье на которую вы сослались приведена техника распаралеливания довольно похожая на работу async в далёком приближении. Если это начать развивать получится тоже самое.
Но зачем этим заниматься если я могу подключить async и писать код вроде:
Если он настолько удобен и не ухудшает производительность, в чём проблема?
node-oauth и node-twitter — написание собственных полезно будет только для понимания принципа работы (читать — развития). Потом обязательно будет столкновение с проблемами различия поведения разных сервисов и написание костылей, которые в этих библиотеках уже учтены. Для опыта полезно, для разработки приложения — нет. Если не хватает функционала лучше внести исправление в библиотеку и отправить pull request (ну или развивать свой форк) — пользы для всех будет больше.
http-get. Да пишется это довольно просто. А когда дойдём до определния в ответе gzip-сжатия и следованию за редиректами — получим свой http-get. Зачем?
daemon.node. Тут согласен. Можно использовать strat-stop-daemon и подобные утилиты. Но иногда это бывает не так удобно, как дописать 2-3 строки в приложение. Тут зависит от ситуации.
form — категорически не согласен. Это никак не просто regexp. И тем более не <=. Имея в одном месте довольно простое описание правил для ожидаемого объекта мы передаём обработчику сырые данные и на выходе получаем либо список ошибок либо 100% валидные данные, которым мы можем доверять. Такой подход сокращает тучу проверок в коде контроллера.
configjs и lacalejs — да это {}. Но не просто {}, а с функционалом для решения рутинных операций. Да оно пишется просто. Да — ничего не стоит самому написать эти 50 строк кода. Я один раз написал их так, как мне кажется это удобно использовать, оформил их в модуль и теперь могу использовать их везде просто подключением этого модуля. Мне не нужно хранить его в репозитории проекта. Если я захочу расширить функционал я сделаю это в одном месте и все проекты, где подключен этот модуль смогут просто обновиться при помощи npm и получить доступ к новому функционалу. Разве не круто? Или копипаст наше всё?
hub — правильная структура приложения? С удовольствием почитаю о том, как вы видите правильную структуру приложения. А конкретнее следующие моменты: доступ к конфигурации приложения из любой его точки (контроллеры, модель, фильтры (выполняемые до или после контроллеров), таски. Доступ к пулу заранее открытых соединений с кешем и базой данных из любой модели. Доступ к мультиязычным строкам из контроллеров и шаблонов. И т.д.
connect-response — да это шаблонизатор и методы работы с куками + рутинные операции для формирования ответов (заголовки, коды, редиректы и т.п.). Просто это нужно на всех web-проектах, я не вижу причины не оформлять это в удобный модуль.
Начну с того, что вобще всё пишется относительно легко, когда знаешь как оно работает. Но это не является поводом писать это самому.
async делает разработку более удобной. Если я знаю как он работает и могу написать аналог это не значит что я должен этим заниматься. В статье на которую вы сослались приведена техника распаралеливания довольно похожая на работу async в далёком приближении. Если это начать развивать получится тоже самое.
Но зачем этим заниматься если я могу подключить async и писать код вроде:
async.parallel({
questions: function(cb) { messageModel.findByTag(tag, page, getQuestions(res, cb)); },
info: function(cb) { messageModel.countByTag(tag, getInfo(req, page, cb)); }
}, function(err, results) {
/* Тут я имею в переменной results 2 поля questions и info с готовыми данными или в err ошибку произошедшую во время выполнения */
});Если он настолько удобен и не ухудшает производительность, в чём проблема?
node-oauth и node-twitter — написание собственных полезно будет только для понимания принципа работы (читать — развития). Потом обязательно будет столкновение с проблемами различия поведения разных сервисов и написание костылей, которые в этих библиотеках уже учтены. Для опыта полезно, для разработки приложения — нет. Если не хватает функционала лучше внести исправление в библиотеку и отправить pull request (ну или развивать свой форк) — пользы для всех будет больше.
http-get. Да пишется это довольно просто. А когда дойдём до определния в ответе gzip-сжатия и следованию за редиректами — получим свой http-get. Зачем?
daemon.node. Тут согласен. Можно использовать strat-stop-daemon и подобные утилиты. Но иногда это бывает не так удобно, как дописать 2-3 строки в приложение. Тут зависит от ситуации.
form — категорически не согласен. Это никак не просто regexp. И тем более не <=. Имея в одном месте довольно простое описание правил для ожидаемого объекта мы передаём обработчику сырые данные и на выходе получаем либо список ошибок либо 100% валидные данные, которым мы можем доверять. Такой подход сокращает тучу проверок в коде контроллера.
configjs и lacalejs — да это {}. Но не просто {}, а с функционалом для решения рутинных операций. Да оно пишется просто. Да — ничего не стоит самому написать эти 50 строк кода. Я один раз написал их так, как мне кажется это удобно использовать, оформил их в модуль и теперь могу использовать их везде просто подключением этого модуля. Мне не нужно хранить его в репозитории проекта. Если я захочу расширить функционал я сделаю это в одном месте и все проекты, где подключен этот модуль смогут просто обновиться при помощи npm и получить доступ к новому функционалу. Разве не круто? Или копипаст наше всё?
hub — правильная структура приложения? С удовольствием почитаю о том, как вы видите правильную структуру приложения. А конкретнее следующие моменты: доступ к конфигурации приложения из любой его точки (контроллеры, модель, фильтры (выполняемые до или после контроллеров), таски. Доступ к пулу заранее открытых соединений с кешем и базой данных из любой модели. Доступ к мультиязычным строкам из контроллеров и шаблонов. И т.д.
connect-response — да это шаблонизатор и методы работы с куками + рутинные операции для формирования ответов (заголовки, коды, редиректы и т.п.). Просто это нужно на всех web-проектах, я не вижу причины не оформлять это в удобный модуль.
Резюмирую: вы — за использование велосипедов (не важно, что они написаны не вами), я — за минимализм в коде.
Так без этого когда приложение работать не будет. Вы получается пишите тот же велосипед сами, а я за использование велосипедов которые собирают много людей (которые умеют хорошо их собирать). У вас растёт код приложения — у меня количество require. Во втором случае поддерживать придётся гораздо меньше кода.
UFO just landed and posted this here
Кстати, вы не ответили про роутинг, разбор заголовков, разбор multipart-запросов, поддержку сессий. В нативном Node.JS этого нет и кода это занимает прилично (хоршоая реализация). Как вы делаете это без connect и ему подобных модулей?
В чём проблема с роутингом?
Разбор заголовков — они же уже разобранные приходят, в хэше.
Multipart-запросы пока не делал в своих проектах, так что ничего не скажу. Но с теорией знаком, не сложнее, чем oauth-протокол использовать.
Поддержка сессий — а куки чем не вариант?
Разбор заголовков — они же уже разобранные приходят, в хэше.
Multipart-запросы пока не делал в своих проектах, так что ничего не скажу. Но с теорией знаком, не сложнее, чем oauth-протокол использовать.
Поддержка сессий — а куки чем не вариант?
Да нет проблем никаких. Просто это большая пачка кода, которая нужна в каждом проекте и не меняется от проекта к проекту и она уже хорошо реализована другими разработчиками. В чём проблема использовать её? Я не говорю что это сложно сделать. Я говорю что этого делать не нужно. Исключение — саморазвитие. Либо когда вы знаете что напишете решение лучше существующего и опубликуете его и станете мейнстримом в этой области. Писать код самому только ради того что вы можете написать его сам — это неправильно. Я так считаю. Это тоже самое если не использовать наборы готовых классов на Java, .NET или C++, которыми пользуются все. И с крутым видом говорить: «только Native, только хардкор».
Я не вижу там никакой большой пачки кода. Для своих проектов у меня есть «заготовка», в которой это всё есть, но это даже не модуль или фреймворк, а именно заготовка, шаблон проекта.
Работает так (упрощённо): myFunctions[pagename](params). Вот и весь роутинг, если я правильно понял, о чём вы.
Смысл не в том, чтоб «писать самому», а в минимализме кода, отсутствии лишних частей и отсутствии незнакомых вам частей кода.
Работает так (упрощённо): myFunctions[pagename](params). Вот и весь роутинг, если я правильно понял, о чём вы.
Смысл не в том, чтоб «писать самому», а в минимализме кода, отсутствии лишних частей и отсутствии незнакомых вам частей кода.
Под роутингом я имею ввиду следующее:
У нас есть шаблон url типа:
/news/:category/:year/full/:id
К серверу поступают запросы с различными url и методами GET, POST.
Нам нужно:
1. Быстро сматчить урл запроса с шаблонами урлов и понять какой из них пришёл.
2. Вычленить из этого урла переменные, на основе шаблона урла и передать их в параметры запроса
3. Найти метод контроллера, который отвечает за выполнение этого урла и передать ему управление.
В при помощи connect и hub я сделаю это так:
У нас есть шаблон url типа:
/news/:category/:year/full/:id
К серверу поступают запросы с различными url и методами GET, POST.
Нам нужно:
1. Быстро сматчить урл запроса с шаблонами урлов и понять какой из них пришёл.
2. Вычленить из этого урла переменные, на основе шаблона урла и передать их в параметры запроса
3. Найти метод контроллера, который отвечает за выполнение этого урла и передать ему управление.
В при помощи connect и hub я сделаю это так:
hub.router.app('/news/:category/:year/full/:id', function(req, res, next) {
// Сюда будет передано управление для обработки нашего урл.
// В req.params.id будет id новости. Соответственно и другие параметры там же.
});У меня сделано так (упрощённо):
А дальше уже в зависимости от функции. Ну и всякие данные передаются не в урле, а get- или post- параметрами. В урле — только страница\подстраница.
Т.е., в вашем варианте это было бы:
Или, если конкретная новость:
actions = url.split('/');
myFunctions(actions[0]);А дальше уже в зависимости от функции. Ну и всякие данные передаются не в урле, а get- или post- параметрами. В урле — только страница\подстраница.
Т.е., в вашем варианте это было бы:
/news/<category>?year=<year> либо /news?category=<category>&year=<year>Или, если конкретная новость:
/news/<news_id>Такой подход большой проект превратит в кошмар. Есть печальный опыт.
Никаких отличий от вашего варианта, за исключением меньшего количества кода и отсутствия лишних модулей.
Ну-ну. Если вы не видите тут никаких отличий, то мне дальше нечего сказать. Когда-нибудь поймёте. Я тоже когда-то так писал.
Ну раз единственный аргумент, который у вас остался, это «сперва добейся», мне тоже дальше сказать нечего.
Я что-то не особо понял назначения hub. Во-первых, правильная организация проекта с иерархией логики и инкапсуляцией ее частей исключает расшаривание ресурсов между частями приложения. Вам скорее всего следует пересмотреть архитектуру приложения.
Во-врорых, чем вас не устраивает использование
Во-врорых, чем вас не устраивает использование
global?Было бы очень интересно почитать о построении структуры приложений, учитывая специфику node.js без использования таких вещей как hub. И при этом без серьёзного усложнения его структуры и увеличения количества кода. Можно конечно написать самому или взять готовую реализацию DI, но я пока слабо представляю как сделать это на JavaScript красиво и так, чтобы это реально принесло профит. Если поделитесь интересными ссылками на эту тему — будет клёво.
Про globals — я слышал за их использование температура котла в аду x2 =)
Про globals — я слышал за их использование температура котла в аду x2 =)
globals аналог window в браузере. Разработчики Prototype.js автоматически попадут в ад? О боже, они ведь ещё и .prototype-ы базовых объектов переписали, на кол их! На самом деле весь вопрос заключается в подходе. Нет никакого единственно верного решения.
С браузером сравнивать некорректно. Там в принципе нет другого способа начать инициализацию. Т.е. в любом случае будет хотябы одна глобальная переменная. А поскольку такие библиоткеи как Prototype и JQuery разрабатываются разными командами у них просто нет выбора, кроме как объявить эту переменную своей. Клиентский код использует другие подходы, там другие приоритеты и задачи и сложившиеся обстоятельства (окружение его использования). В серверных языках прибегать к globals очень плохой тон. Что будет если разработчик какого-либо модуля захочет использовать globals и он совпадёт с вашим?
Сравнение вполне корректно. Проблема может возникнуть только если код написан как скрипт. Кучка функций в перемешку с кодом, как, увы, написаны многие модули, в том числе и хорошие, для nodeJS. На мой взгляд удобный код должен строится на схеме подобной этой (сгодится и более простая):
Всё окружение для определённого экземпляра находится в нём самом и никому не мешает. Всё что он желает сделать глобальным — он делает глобальным. Но для этого должны быть веские основания и это должно вписываться в концепцию системы (конкретной системы, а не npm).
>> Что будет если разработчик какого-либо модуля захочет использовать globals и он совпадёт с вашим?
Не представляю себе, как может возникнуть такая ситуация. Такое возможно только если другой разработчик никак не связан с вашим проектом (т.е. модуль не для конкретной системы, и значит обязан предоставляться через require) или нарушены всякие разумные принципы построения системы.
Я представляю себе сайт только как целостный движок, который оперирует контроллерами, моделями и представлением. Это жёстко-связанная конструкция, которые живёт по своим правилам. Т.е. я вижу framework, а не кучку js-файлов внутри которых свой собственный бардак. Более простой пример: сайт — ПО, а то что предоставляет npm — плагины к нему.
classes.Some = new Class();
classes.Some.prototype =
{
_init: function(){},
...
}
// где угодно
var some_var = new classes.Some();
Всё окружение для определённого экземпляра находится в нём самом и никому не мешает. Всё что он желает сделать глобальным — он делает глобальным. Но для этого должны быть веские основания и это должно вписываться в концепцию системы (конкретной системы, а не npm).
>> Что будет если разработчик какого-либо модуля захочет использовать globals и он совпадёт с вашим?
Не представляю себе, как может возникнуть такая ситуация. Такое возможно только если другой разработчик никак не связан с вашим проектом (т.е. модуль не для конкретной системы, и значит обязан предоставляться через require) или нарушены всякие разумные принципы построения системы.
Я представляю себе сайт только как целостный движок, который оперирует контроллерами, моделями и представлением. Это жёстко-связанная конструкция, которые живёт по своим правилам. Т.е. я вижу framework, а не кучку js-файлов внутри которых свой собственный бардак. Более простой пример: сайт — ПО, а то что предоставляет npm — плагины к нему.
Ваш пример кода показывает то, чего в клиентском JS нет. Там нет нативной возможнсти подключить файл так, чтобы он не оказался в глобальном пространстве. В вашем случае появляется глобальная переменная classes. Можно конечно реализовать аналог require (а скорее всего таких реализаций уже много), который будет получать код файла в виде текста и при помощи eval() превращать его в JS объект. Тогда он не попадёт в глобальное пространство. Но тут мы сталкиваемся с тем, а где же будет расположен сам модуль загрузчик? Да! В глобальном пространстве. И пока между всеми разработчиками не будет договорённости о поддержки этого самого загрузчика — все будут использовать глобально пространство в браузере. А договорённость может придти только с появлением во всех браузерах и в стандарте этого самого загрузчика.
В node.js этот загрузчик есть, поэтому использование глобального пространства там поддаётся правилам других серверных языков программирования. В которых это считает плохим тоном.
Не вижу связи с привязкой фреймворка к сайту. Фреймворк загоняет в рамки. Вам придётся писать код так, как это придумал разработчик фреймворка. Использование отдельных модулей этих рамок не ставит. Можно писать код так как нравится вам или как принято у вас в компании пользуясь при этом благами цивилизации (огромным количеством хороших модулей).
В node.js этот загрузчик есть, поэтому использование глобального пространства там поддаётся правилам других серверных языков программирования. В которых это считает плохим тоном.
Не вижу связи с привязкой фреймворка к сайту. Фреймворк загоняет в рамки. Вам придётся писать код так, как это придумал разработчик фреймворка. Использование отдельных модулей этих рамок не ставит. Можно писать код так как нравится вам или как принято у вас в компании пользуясь при этом благами цивилизации (огромным количеством хороших модулей).
Опишите задачу, когда вам необходимо что-то глобальное (т.е., используемое в двух различных модулях).
Я чуть выше писал:
С удовольствием почитаю о том, как вы видите правильную структуру приложения. А конкретнее следующие моменты: доступ к конфигурации приложения из любой его точки (контроллеры, модель, фильтры (выполняемые до или после контроллеров), таски. Доступ к пулу заранее открытых соединений с кешем и базой данных из любой модели. Доступ к мультиязычным строкам из контроллеров и шаблонов. И т.д.
Зачем доступ к конфигурации где-либо, кроме стартового модуля? (ну, опционально, стартовый + воркеры).
Доступ к мультиязычности должен быть только в том месте, где происходит шаблонизация.
Доступ к мультиязычности должен быть только в том месте, где происходит шаблонизация.
1. В контроллере я запрашиваю вывод страницы вопросов. Мне нужно знать сколько вопросов на странице (это указывается в конфигурации). Как получить туда доступ о вашему?
2. В форме происходит ошибка. Текст ошибки — мультиязычная строка. Форма описна в отдельном модуле (все тексты ошибок — там). Как получить доступ к локали оттуда?
3. Шаблонизатор работает в закрытом адресном пространстве. Он не может посмотреть никуда кроме своей области видимости (тех данных что ему передали) и Globals. Как он получит доступ к локали?
Ну эти примеры ещё можно с упрощением сказать что мы просто подключим через require нужный файл. Мы это уже обсуждали выше. У нас разные мнения на этот счёт.
А вот дальше:
4. При создании инициализации приложения я настроил пул соединения с БД и кешем. Как мне использовать его, в любом файле модели по вашему?
5. Как получить доступ к пулу кеша из фильтров, которые вобще выполняются вне контроллера (всегда для каждого запроса).
Вы отвечаете только на часть вопросов и мне приходится их повторять. Надеюсь что вы это не специально, но больше повторяться я не буду.
2. В форме происходит ошибка. Текст ошибки — мультиязычная строка. Форма описна в отдельном модуле (все тексты ошибок — там). Как получить доступ к локали оттуда?
3. Шаблонизатор работает в закрытом адресном пространстве. Он не может посмотреть никуда кроме своей области видимости (тех данных что ему передали) и Globals. Как он получит доступ к локали?
Ну эти примеры ещё можно с упрощением сказать что мы просто подключим через require нужный файл. Мы это уже обсуждали выше. У нас разные мнения на этот счёт.
А вот дальше:
4. При создании инициализации приложения я настроил пул соединения с БД и кешем. Как мне использовать его, в любом файле модели по вашему?
5. Как получить доступ к пулу кеша из фильтров, которые вобще выполняются вне контроллера (всегда для каждого запроса).
Вы отвечаете только на часть вопросов и мне приходится их повторять. Надеюсь что вы это не специально, но больше повторяться я не буду.
Про require вы ошиблись.
1. Вывод страницы вопросов вызывается функцией, в которую аргументом передаётся нужный параметр. В чём проблема?
2. Формирование шаблона с кодом ошибки и тексты должны находиться в одном месте. Тексты вообще, в идеале, не должны быть нигде, кроме шаблонов и модуля мультиязычности (если он есть).
3. Ему и не надо ничего знать, кроме самих шаблонов и данных для генерации шаблонов.
4. А его не надо использовать нигде, кроме модуля, в котором описаны все запросы к БД.
5. Не понял задачу, что за фильтры такие?
1. Вывод страницы вопросов вызывается функцией, в которую аргументом передаётся нужный параметр. В чём проблема?
2. Формирование шаблона с кодом ошибки и тексты должны находиться в одном месте. Тексты вообще, в идеале, не должны быть нигде, кроме шаблонов и модуля мультиязычности (если он есть).
3. Ему и не надо ничего знать, кроме самих шаблонов и данных для генерации шаблонов.
4. А его не надо использовать нигде, кроме модуля, в котором описаны все запросы к БД.
5. Не понял задачу, что за фильтры такие?
1. Да функция вызывается с аргументом — количеством вопросов. Это количество лежит в конфиге (вдруг я завтра захочу не 10 а 15 выводить). Как мне получить доступ к этому конфигу из контроллера чтобы полчить этот аргумент и передать его функции?
2. В моём случае текст ошибки вобще не приявязан к какому либо шаблону. Добавление вопроса происходит через AJAX на любой странице сайта. И ошибка выводится во flash-сообщение наверху. Она относится к форме, аточнее к полю формы в котором может возникнуть. Держать гдето все ошибки вместе — бред. Если я захочу поменять логику разора формы я не хочу гдето в другом месте менять тексты ошибок или добавлять/удалять их. Я для этого и делал form, чтобы всё это было логично объединено в одном месте.
3. На странице есть строка, к примеру заголовок. Я захотел открыть английскую версию. Точно такую же только английскую. Вы предлагаете делать вторую пачку шаблонов? Намного проще в месте строки подставить ссылку на переменную, в которой в зависимости от текущей локали будет находится нужная строка. Ато если языков будет 5. И мне захочется изменить дизайн, то привет изменение 5 пачек шаблонов? Нет уж, так не пойдёт.
4. У вас один модуль где описаны все запросы к БД? У меня даже на таком маленьком проекте их 4. На большьших их десятки. Иначе это будут тысячи строк кода и вобще это противоречит MVC. Одна модель — один класс. В каждой модели нужен доступ к БД.
5. К примеру на каждой странице у меня есть теги. Я не делаю их вывод в каждом контроллере. Есть некая функция, которая добавляется в цепочку вызвовов и пеперед или после выполнения контрооллера она вызывается и меняет/добавлет данные на страницу в соответствии со своей логикой. Таких функций может быть несколько.
2. В моём случае текст ошибки вобще не приявязан к какому либо шаблону. Добавление вопроса происходит через AJAX на любой странице сайта. И ошибка выводится во flash-сообщение наверху. Она относится к форме, аточнее к полю формы в котором может возникнуть. Держать гдето все ошибки вместе — бред. Если я захочу поменять логику разора формы я не хочу гдето в другом месте менять тексты ошибок или добавлять/удалять их. Я для этого и делал form, чтобы всё это было логично объединено в одном месте.
3. На странице есть строка, к примеру заголовок. Я захотел открыть английскую версию. Точно такую же только английскую. Вы предлагаете делать вторую пачку шаблонов? Намного проще в месте строки подставить ссылку на переменную, в которой в зависимости от текущей локали будет находится нужная строка. Ато если языков будет 5. И мне захочется изменить дизайн, то привет изменение 5 пачек шаблонов? Нет уж, так не пойдёт.
4. У вас один модуль где описаны все запросы к БД? У меня даже на таком маленьком проекте их 4. На большьших их десятки. Иначе это будут тысячи строк кода и вобще это противоречит MVC. Одна модель — один класс. В каждой модели нужен доступ к БД.
5. К примеру на каждой странице у меня есть теги. Я не делаю их вывод в каждом контроллере. Есть некая функция, которая добавляется в цепочку вызвовов и пеперед или после выполнения контрооллера она вызывается и меняет/добавлет данные на страницу в соответствии со своей логикой. Таких функций может быть несколько.
1. Конфиг подключается 1 раз — в контроллер. Из контроллера вызываются все необходимые «высокоуровневые» функции. Если где-то в недрах такой функции нужен параметр из конфига — он передаётся аргументом из контроллера.
2. Значит, текст ошибки — это отдельный шаблон. Либо передаётся параметром в шаблон при генерации. Все ошибки как раз-таки очень удобно держать в одном месте. Если у вас мультиязычное приложение — тексты ошщибок должны лежать в хэше с переводами и прокидываться оттуда в шаблон. Хэш должен подключаться там же, где вызывается генерация шаблонов.
3. Зачем? У вас есть шаблон, в который вы прокидываете нужные строки из хэша переводов. Не надо никакого доступа никуда.
4. Да, один. Точнее, предполагается что он один на каждую используемую в проекте БД. В моих проектах БД одна, соотвественно, и модуль один. Зачем больше-то? Это ведь только собрание разных обращений к БД, очень удобно, когда оно всё в одном месте.
5. Всё равно не понял. Есть одна функция, которая генерит тэги. Есть один модуль, в котором происходит генерация страниц. При генерации дёргается функция с нужными параметрами (если они есть).
2. Значит, текст ошибки — это отдельный шаблон. Либо передаётся параметром в шаблон при генерации. Все ошибки как раз-таки очень удобно держать в одном месте. Если у вас мультиязычное приложение — тексты ошщибок должны лежать в хэше с переводами и прокидываться оттуда в шаблон. Хэш должен подключаться там же, где вызывается генерация шаблонов.
3. Зачем? У вас есть шаблон, в который вы прокидываете нужные строки из хэша переводов. Не надо никакого доступа никуда.
4. Да, один. Точнее, предполагается что он один на каждую используемую в проекте БД. В моих проектах БД одна, соотвественно, и модуль один. Зачем больше-то? Это ведь только собрание разных обращений к БД, очень удобно, когда оно всё в одном месте.
5. Всё равно не понял. Есть одна функция, которая генерит тэги. Есть один модуль, в котором происходит генерация страниц. При генерации дёргается функция с нужными параметрами (если они есть).
не туда ответил случайно вот: habrahabr.ru/blogs/nodejs/138629/#comment_4630212
1. Контроллер не 1. Их много. На каждый логический раздел сайта по контроллеру.
2. Текст ошибки — шаблон? Это всё усложняет. Посмотрите пример в form. Там всё лакончино и в одном логически разумном месте а не сгруппировано по типу. Когда количество текстов ошибок будет приближаться к сотне — взвоете добавлять их в одно место. Поэтому локализатор даёт возможность делить локаль на файлы, а hub получать доступ к нужной части локали.
3. Тут да. В шаблон прокидывается сслыка на текущую локаль и он берёт оттуда данные.
4. Вы имеете ввиду библиотеку в которой реализованы функции query и подобные ей, в которую из контроллера передаются запросы? О_о Я говорю про модели. Это модули которые соержат в себе методы вида findDiscussedQuestions, findUnansweredQuestion, а уже эти методы обращаются БД, следовательно ссылка на бд нужна в каждой из моделей. Контроллер ничего не знает о тексте запроса, как и куда он отсылается и как кешируется.
5. Один модуль где для генерации страниц? Видимо мы разговариваем о разных WEB-приложениях.
Я вас не очень понимаю. Вы пробовали использовать фреймворки на других языках? Symfony/Yui на PHP? Spring и т.п. на Java? ASP на .NET? Там такой подход не должен вызывать вопросов. Везде примерно одинаково сделано я тут не америку открываю. Просто где-то болше ООП, где-то меньше суть похожа.
2. Текст ошибки — шаблон? Это всё усложняет. Посмотрите пример в form. Там всё лакончино и в одном логически разумном месте а не сгруппировано по типу. Когда количество текстов ошибок будет приближаться к сотне — взвоете добавлять их в одно место. Поэтому локализатор даёт возможность делить локаль на файлы, а hub получать доступ к нужной части локали.
3. Тут да. В шаблон прокидывается сслыка на текущую локаль и он берёт оттуда данные.
4. Вы имеете ввиду библиотеку в которой реализованы функции query и подобные ей, в которую из контроллера передаются запросы? О_о Я говорю про модели. Это модули которые соержат в себе методы вида findDiscussedQuestions, findUnansweredQuestion, а уже эти методы обращаются БД, следовательно ссылка на бд нужна в каждой из моделей. Контроллер ничего не знает о тексте запроса, как и куда он отсылается и как кешируется.
5. Один модуль где для генерации страниц? Видимо мы разговариваем о разных WEB-приложениях.
Я вас не очень понимаю. Вы пробовали использовать фреймворки на других языках? Symfony/Yui на PHP? Spring и т.п. на Java? ASP на .NET? Там такой подход не должен вызывать вопросов. Везде примерно одинаково сделано я тут не америку открываю. Просто где-то болше ООП, где-то меньше суть похожа.
Промахнулся. Это ответ на вот этот комментарий: habrahabr.ru/blogs/nodejs/138629/#comment_4629998
Когда количество текстов ошибок будет приближаться к сотне
А вам не кажется, что в проекте что-то не так, если там сотня разных сообщений об ошибках?
4. Я не понял что вы думаете что я имею ввиду. Есть модуль с запросами к БД — findDiscussedQuestions, findUnansweredQuestion и т.п. В этом модуле БД и подключается, и используется.
5. Генерация всех шаблонов всего приложения должна быть в одном месте. А вот подготовка данных для этой генерации — раскидана по «тематическим» модулям. Контроллер дёргает функцию, которая собирает данные, что-то с ними делает и возвращает это контроллеру. Дальше контроллер дёргает генерацию нужного шаблона с этими данными.
Не кажется. Это нормальная ситуация, при этом я бы не сзказал что проект должен быть огромным для этого.
4. Такой модуль не один! Модуль для вопросов. Модуль для тегов. Модуль для пользователей. Это только в моём малюсеньком проектике. На деле их десятки То о чём говорите вы это интерфейс к БД, это не модель.
4. Такой модуль не один! Модуль для вопросов. Модуль для тегов. Модуль для пользователей. Это только в моём малюсеньком проектике. На деле их десятки То о чём говорите вы это интерфейс к БД, это не модель.
Интерфейс к БД — это как раз сторонний модуль. А я говорю про часть кода, которая отвечает за алгоритмы вашей программы, связанные с получением, записью данных из\в БД и, частично, их обработкой. В моём подходе он должен быть один на каждую используемую БД.
Ну и я не про другие языки говорю, а про Javascript в общем и node.js в частности.
Просто меня удивляет, что у вас вызывают сомнения очевидные вещи, которые давно успешно применяются во многих популярных фреймворках, на многих языках.
Не «вещи во фреймворках», а сами фреймворки. Про это давным давно сказано в поговорках «из пушки по воробьям», «гвозди микроскопом» и т.п.
Странное сравнение. Если использовать фреймворк для создание web-приложений для создания web-приложения это как гвозди молотком. Гвозди микроскопом это если писать web-приложение на ASM к примеру. Или ещё какой-нибудь подобный хардкор. Бывают плохие фреймворки, бывают хорошие. У вас какое-то предвзятое отношение ко всем. Без разбора. При таком подходе если я сам себе напишу фреймворк я его получается по вашему не могу использовать т.к. он уже по определению плох, что он фреймворк.
Вот! Десять раз согласен. Более того, отказываться от фреймворка — это и есть пушка по воробьям. Полчаса придётся пушку двигать чтобы прицел поправить, ежели воробей сдвинется.
Нсли вы напишете фреймворк под конкретный проект, или возьмёте из какого-то фреймворка только тот код, что вам нужен в конкретном проекте — это будет то что надо.
Внезапное огромное спасибо за htop, не знал про такое счастье существует.
игра для социальной сети Node.JS + MongoDB около 10 млн запросов в сутки. Node.Js работает клево, есть свои минусы но в целом очень удобно.
Трудно с утечкой памяти бороться :)
Трудно с утечкой памяти бороться :)
В node.js утечки могут быть только при ошибках в коде (вашем либо в используемых модулях). Посмотрите весь код внимательно. Места объявления переменных, циклы, рекурсивные функции и т.п.
Я знаю что делать нужно =) я написал что не удобно это делать =)
habrastorage.org/storage2/a80/27b/670/a8027b670d127de3610638e6512c8a4a.jpg
хабрахабр картинку не хочет показывать :(
habrastorage.org/storage2/a80/27b/670/a8027b670d127de3610638e6512c8a4a.jpg
{kind=link}
хабрахабр картинку не хочет показывать :(
занятно. Т.е. около 115 запросов в секунду. А в пике сколько? Какого плана запросы? долгоживущие или простой http запрос-ответ?
Спасибо за разжевывание!
А сударь Norlin не пойму почему агрессирует…
А сударь Norlin не пойму почему агрессирует…
Апплодирую стоя…
UFO just landed and posted this here
form.filter(form.Filter.trim) это и есть sanitize. Можно использовать как встроенные фильтры node-validator, так и свои собственные, написанные в формате node-validator.
var form = require('form');
// Свой фильтр в формате node-validator
filterToUpperCase = function() {
this.modify(this.str.toUpperCase());
return this.wrap(this.str);
};
var fields = {
name: [
form.filter(form.Filter.trim), // Применяем встроенный в node-validator фильтр trim
form.filter(filterToUpperCase), // Применяем свой фильтр
form.validator(form.Validator.notEmpty, 'Empty name'),
form.validator(form.Validator.is, /[0-9]+/, 'Bad name')
],
text: [
form.filter(form.Filter.trim),
form.validator(form.Validator.notEmpty, 'Empty text'),
form.validator(form.Validator.len, 30, 1000, 'Bad text length')
]
};
var textForm = form.create(fields);
textForm.process({'text' : 'some short text', 'name': ''}, function(error, data) {
console.log(error);
console.log(data);
});
UFO just landed and posted this here
Аналогично: form.filter(form.Filter.xss)
Со sql injection, вообще-то, борются эскепингом во время работы с базой (с разными базами разными способами), а не универсальной фильтрацией на уровне валидации форм. Да и с XSS большинство предпочитает справляться на выходе, а не при сохранении данных в базу.
Sign up to leave a comment.
Разработка WEB-проекта на Node.JS: Часть 2