Уже не первый раз натыкаюсь на обсуждения вопросов о том, кто и как изучает новые технологии и о том, как справится с тем огромном потоком «нововведений», которые ежегодно появляются в индустрии ПО. Однажды я уже отвечал на этот вопрос на кывт-е, и после очередного вопроса решил оформить эти мысли более структурированным образом.
Если оглядеться вокруг, то может сложиться впечатление, что отрасль разработки ПО шагает такими громадными шагами, что угнаться за ней нет никакой возможности. И если рассматривать всю отрасль в целом, то действительно это так и есть. Как-то сразу вспоминается старина Брукс со своим «Мифическим человеко-месяцем», когда он в заключении к своей книге пишет о том, как изменилась индустрия ПО в середине 90-х по сравнению с 50-ми годами. В те далекие годы (да, 90-е тоже уже далеки, так что уж говорить за эпоху зарождения индустрии сорока годами ранее) можно было прочитать все журналы (!), компьютерной тематики, которые выходили в свет. Сейчас же ежемесячно появляется десятки книг только по одной из популярных технологий, а количество статей просто не поддается счету.
С одной стороны, это заставляет относиться к выбору источников информации более осознанным и благоразумным образом. И именно эта мысль побудила меня к формированию списка наиболее интересных книг по программированию в целом, и отдельно, наиболее значимых книг по языку C# и платформе .NET. Но помимо качественных источников информации (список книг хорошо было бы дополнить списком блогов, подкастов и видеоуроков) важным качеством любого программиста является еще структурирование и «повторное использование» полученных знаний.
По роду своей деятельности мы часто сталкиваемся с проблемами сложности. Мы привыкли бороться с ней самыми разными способами; мы создаем мелкие проверенные строительные блоки, на основе которых возводим крупные программные решения, мы абстрагируемся от несущественных деталей, пряча детали реализации за публичным интерфейсом классов или целых модулей, мы создаем иерархии классов для обобщения и повторного использования знаний и потраченных усилий.
А что, если попытаться провести параллели между общепринятыми практиками проектирования софта и нашими знаниями? Вот, например, декомпозиция задачи отлично применима, как в программировании, так и при обучении. Все мы прекрасно знаем, насколько легко сделать все сложно (простите за каламбур), если смешать в одном методе простенькую бизнес-логику и логику по работе с С-строками. Если методу требуется десяток более или менее простых операций со строками, то понять, что в нем происходит, будет очень сложно из-за всех этих strlen, strcpy, strcmp, strcat и многих других операций, в каждой из которых может крыться ошибка.
ПРИМЕЧАНИЕ
Принято считать, что главное достоинство инкапсуляции – это защита внутренней реализации класса от внешних клиентов; дескать, благодаря инкапсуляции, «поставщик услуг» можем изменить внутреннее поведение (или представление) не затронув при этом клиентов. Однако инкапсуляция — это игра не в одни ворота; помимо того, что класс сможет изменить свою реализацию, инкапсуляция позволяет разгрузить клиента от ненужных деталей реализации, делая его (клиента) жизнь намного проще.
Смешав в одном месте довольно простую логику вместе с плохо спроектированной абстракцией, мы получаем комбинаторный рост сложности, который взорвет мозг еще при написании кода, не говоря уже за его поддержку. То же самое можно заметить, например, при обсуждении некоторой задачи внутри команды, когда собеседник на тебя вываливает огромный объем информации, без большей части которой оба собеседника могли бы обойтись. При изучении чего-то нового эта же проблема проявляется даже более остро: onestepatatime – это любимый подход Джона Скита при описании возможностей языка C#, которым он успешно пользуется в своей книге “C# In Depth”, и именно этот подход делает его книгу простой для чтения и понимания.

Абстракции образуют иерархию (*)
(*) Это рисунок из книги Гради Буча «Объектно-ориентированный анализ и проектирование с примерами приложений».
Теперь давайте рассмотрим еще один аспект разработки, который можно напрямую использовать и при обучении. По словам Гради Буча – любая сложная система является иерархичной. Именно иерархия и модульность позволяют хоть как-то справляться с невероятной сложностью моделируемых систем. И если рассмотреть любую современную технологию, то можно заметить, что количество слоев в ней будет огромным, и что каждый из них строится на основе хорошо проверенных слоях нижнего уровня.
Давайте в качестве примера рассмотрим WCF.
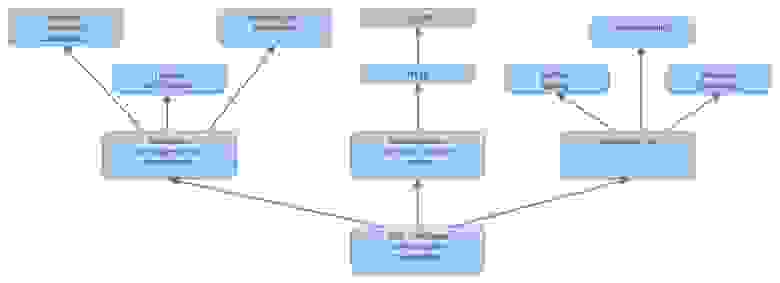
Ни одна современная технология не является сферическим конем, построенным в вакууме от базовых концепций или других подобных технологий. На самом деле, большинство из них, это всего лишь новая комбинация, хорошо проверенных и известных концепций, и WCF здесь – не исключение.
Современные технологии построения распределенных приложений довольно похожи. Все они строятся на основе проверенных паттернов, используют транспортные протоколы нижнего уровня и, в той или иной мере, борются с заблуждениями о распределенных приложениях (Fallacies of Distributed Computing).
Так, например, если у вас есть опыт работы с .NET Remoting-ом, то вы можете использовать его повторно при переходе на WCF: каждая из этих технологий является таким себе «слоеным» пирогом, с возможностью конфигурировать и настраивать самые разные уровни. В обеих технологиях мы можем использовать разные методы инстанцирования и конкурентности, настраивать безопасность и управлять сериализацией.
Знания низкоуровневых коммуникационных протоколов вы также сможете использовать повторно, поскольку рано или поздно в вашей системе начнутся проблемы, с которой не удастся разобраться без WireShark-а и анализа пакетов. Кроме того, многие проблемы или их решения могут быть заложены в самой природе транспортного протокола, и без этих знаний вы просто не сможете принять разумного решения: использовать ли в этой ситуации binding на основе протокола HTTP или TCP.
То же самое относится и к «сервисной» составляющей WCF. Сервисная архитектура – это отдельный аспект, который можно изучить за пределами WCF (например, используя веб-сервисы) и использовать его повторно уже в контексте новой технологии. Конечно, каждый из строительных блоков, на котором строится технология, может использоваться специфическим образом, но знание основополагающих принципов позволит разобраться в новой технологии на порядок легче.
ПРИМЕЧАНИЕ
Однажды я попробовал ответить на вопрос, «Что такое WCF?», стараясь воспользоваться приведенным здесь способом повторного использования знаний и максимально использовать аналогии с приемниками WCF, такими как .NET Remoting и веб-сервисы.
Помимо иерархичности и повторного использования низкоуровневых базовых блоков, мы можем воспользоваться еще одним механизмом ООП для борьбы со сложностью: обобщением и специализацией с помощью наследования.
Наследование – это одна из главных «визитных карточек» ООП и один из главных механизмов повторного использования, поэтому неудивительно, что именно им часто злоупотребляют. При проектировании ПО очень часто возникает проблема, под названием «преждевременным обобщением» (premature generalization), когда на слишком ранних этапах разработки вводятся базовые классы с определенным поведением, хотя еще не понятно, что именно является «общим» в данном конкретном случае. Так, например, весьма часто можно увидеть иерархию из 5 базовых классов для простого класса Customer, хотя на текущем этапе вовсе неясно, зачем это нужно.
ПРИМЕЧАНИЕ
Причины такого положения дел в проектировании ПО очень хорошо описал Бертран Мейер: «Произвольно или нет, но многие учебные презентации создают впечатление, что структуру наследования следует проектировать от наиболее общего (верхней ее части) к более специфическим частям (листьям). В частности, это происходит потому, что лучший способ описать существующую структуру – это идти от общего к частному, от фигур к замкнутым фигурам, затем к многоугольникам, прямоугольникам, квадратам. Но лучший способ описания структуры вовсе не означает, что он является и лучшим способом ее создания.
В идеальном мире, населенном совершенными людьми, мы бы сразу же обнаруживали правильные абстракции, выводили бы из них категории, затем их подкатегории и так далее. В реальном мире, однако, мы часто вначале обнаруживаем частный случай и лишь потом открываем общую абстракцию.»
Точно также, довольно типичной является ситуация, когда собеседник обобщает свои опыт и знания, полученные на одном проекте с одним языком программирования, на другие проекты и другие языки программирования. По сути, он обобщает эти знания в «базовые» классы своих знаний, хотя на данный момент у этих классов есть только один «наследник»:
Я: Я знаю, что множественное наследование – это фигня!
Он: Почему?
Я: Потому, что его нет в Java, а других языков я не знаю!
Довольно опрометчиво делать подобные выводы, если единственный язык, который я знаю – это Java. Скорее всего, я смогу сделать более правильные выводы и структурировать свои знания более осознанно, познакомившись хотя бы с несколькими языками, поддерживающими множественное наследование, такими как С++ и Eiffel.
Давайте, в качестве примера, рассмотрим несколько способов автоматического управления памяти и представим их в иерархической форме.

Автоматическое управление памятью является наиболее общим понятием, под который попадает несколько частных случаев. Так, например, можно выделить два наиболее типичных решения, основанных (1) на сборке мусора (garbage collection) и (2) на подсчете ссылок; при этом сборщики мусора могут использовать поколения (generations) или нет.
Каждое из решений обладает своими плюсами и минусами. Так, управление памятью на основе подсчета ссылок будет страдать от «кольцевых» зависимостей (когда объекта А содержит ссылку на объект B, тот содержит ссылку на объект C, а он опять ссылается на А), но при этом будет обеспечивать детерминированность очистки ресурсов. Сборщик мусора же решит проблему с циклическими ссылками, но расплачиваться за это придется отсутствием детерминированности освобождения ресурсов.
При изучении разных языков программирования, можно стараться запомнить, как именно реализовано автоматическое управление памятью в каждом из них, но после изучения нескольких языков эффективнее будет обобщить эти знания и использовать их повторно. Конечно, каждая платформа или язык программирования обладают своими особенностями, но знания основных механизмов управления памятью существенно сократят кривую обучения, ведь понять и запомнить придется лишь различия, а не весь механизм целиком. Именно поэтому «прагматики» Дэйв Томас и Энди Хант в своей книге «Программист-прагматик. Путь от подмастерья к мастеру» советовали изучать по одному языку программированию каждый год и знакомиться с другими платформами и операционными системами. Подобное расширение кругозора позволит шире смотреть на новые задачи, а также позволит обобщить и структурировать уже существующие знания.

Сколько бы «новых» технологий не выходило бы в свет, сколько бы новых уровней абстракции не изобретали, знание «основ» всегда будет полезным. Значительно проще понять несколько основополагающих принципов, вместо изучения сотни, казалось бы, несвязанных фактов. Знание низкоуровневых концепций можно использовать повторно, что значительно сократит время изучения «новых технологий», поскольку по большей части, они таковыми не являются. Кроме того, рано или поздно «абстракции дадут течь» и чтобы ее устранить, придется понять, как же она устроена внутри.
Если оглядеться вокруг, то может сложиться впечатление, что отрасль разработки ПО шагает такими громадными шагами, что угнаться за ней нет никакой возможности. И если рассматривать всю отрасль в целом, то действительно это так и есть. Как-то сразу вспоминается старина Брукс со своим «Мифическим человеко-месяцем», когда он в заключении к своей книге пишет о том, как изменилась индустрия ПО в середине 90-х по сравнению с 50-ми годами. В те далекие годы (да, 90-е тоже уже далеки, так что уж говорить за эпоху зарождения индустрии сорока годами ранее) можно было прочитать все журналы (!), компьютерной тематики, которые выходили в свет. Сейчас же ежемесячно появляется десятки книг только по одной из популярных технологий, а количество статей просто не поддается счету.
С одной стороны, это заставляет относиться к выбору источников информации более осознанным и благоразумным образом. И именно эта мысль побудила меня к формированию списка наиболее интересных книг по программированию в целом, и отдельно, наиболее значимых книг по языку C# и платформе .NET. Но помимо качественных источников информации (список книг хорошо было бы дополнить списком блогов, подкастов и видеоуроков) важным качеством любого программиста является еще структурирование и «повторное использование» полученных знаний.
По роду своей деятельности мы часто сталкиваемся с проблемами сложности. Мы привыкли бороться с ней самыми разными способами; мы создаем мелкие проверенные строительные блоки, на основе которых возводим крупные программные решения, мы абстрагируемся от несущественных деталей, пряча детали реализации за публичным интерфейсом классов или целых модулей, мы создаем иерархии классов для обобщения и повторного использования знаний и потраченных усилий.
А что, если попытаться провести параллели между общепринятыми практиками проектирования софта и нашими знаниями? Вот, например, декомпозиция задачи отлично применима, как в программировании, так и при обучении. Все мы прекрасно знаем, насколько легко сделать все сложно (простите за каламбур), если смешать в одном методе простенькую бизнес-логику и логику по работе с С-строками. Если методу требуется десяток более или менее простых операций со строками, то понять, что в нем происходит, будет очень сложно из-за всех этих strlen, strcpy, strcmp, strcat и многих других операций, в каждой из которых может крыться ошибка.
ПРИМЕЧАНИЕ
Принято считать, что главное достоинство инкапсуляции – это защита внутренней реализации класса от внешних клиентов; дескать, благодаря инкапсуляции, «поставщик услуг» можем изменить внутреннее поведение (или представление) не затронув при этом клиентов. Однако инкапсуляция — это игра не в одни ворота; помимо того, что класс сможет изменить свою реализацию, инкапсуляция позволяет разгрузить клиента от ненужных деталей реализации, делая его (клиента) жизнь намного проще.
Смешав в одном месте довольно простую логику вместе с плохо спроектированной абстракцией, мы получаем комбинаторный рост сложности, который взорвет мозг еще при написании кода, не говоря уже за его поддержку. То же самое можно заметить, например, при обсуждении некоторой задачи внутри команды, когда собеседник на тебя вываливает огромный объем информации, без большей части которой оба собеседника могли бы обойтись. При изучении чего-то нового эта же проблема проявляется даже более остро: onestepatatime – это любимый подход Джона Скита при описании возможностей языка C#, которым он успешно пользуется в своей книге “C# In Depth”, и именно этот подход делает его книгу простой для чтения и понимания.

Абстракции образуют иерархию (*)
(*) Это рисунок из книги Гради Буча «Объектно-ориентированный анализ и проектирование с примерами приложений».
Теперь давайте рассмотрим еще один аспект разработки, который можно напрямую использовать и при обучении. По словам Гради Буча – любая сложная система является иерархичной. Именно иерархия и модульность позволяют хоть как-то справляться с невероятной сложностью моделируемых систем. И если рассмотреть любую современную технологию, то можно заметить, что количество слоев в ней будет огромным, и что каждый из них строится на основе хорошо проверенных слоях нижнего уровня.
Повторное использование знание на примере WCF
Давайте в качестве примера рассмотрим WCF.

Ни одна современная технология не является сферическим конем, построенным в вакууме от базовых концепций или других подобных технологий. На самом деле, большинство из них, это всего лишь новая комбинация, хорошо проверенных и известных концепций, и WCF здесь – не исключение.
Современные технологии построения распределенных приложений довольно похожи. Все они строятся на основе проверенных паттернов, используют транспортные протоколы нижнего уровня и, в той или иной мере, борются с заблуждениями о распределенных приложениях (Fallacies of Distributed Computing).
Так, например, если у вас есть опыт работы с .NET Remoting-ом, то вы можете использовать его повторно при переходе на WCF: каждая из этих технологий является таким себе «слоеным» пирогом, с возможностью конфигурировать и настраивать самые разные уровни. В обеих технологиях мы можем использовать разные методы инстанцирования и конкурентности, настраивать безопасность и управлять сериализацией.
Знания низкоуровневых коммуникационных протоколов вы также сможете использовать повторно, поскольку рано или поздно в вашей системе начнутся проблемы, с которой не удастся разобраться без WireShark-а и анализа пакетов. Кроме того, многие проблемы или их решения могут быть заложены в самой природе транспортного протокола, и без этих знаний вы просто не сможете принять разумного решения: использовать ли в этой ситуации binding на основе протокола HTTP или TCP.
То же самое относится и к «сервисной» составляющей WCF. Сервисная архитектура – это отдельный аспект, который можно изучить за пределами WCF (например, используя веб-сервисы) и использовать его повторно уже в контексте новой технологии. Конечно, каждый из строительных блоков, на котором строится технология, может использоваться специфическим образом, но знание основополагающих принципов позволит разобраться в новой технологии на порядок легче.
ПРИМЕЧАНИЕ
Однажды я попробовал ответить на вопрос, «Что такое WCF?», стараясь воспользоваться приведенным здесь способом повторного использования знаний и максимально использовать аналогии с приемниками WCF, такими как .NET Remoting и веб-сервисы.
Обобщение знаний на примере автоматического управления памятью
Помимо иерархичности и повторного использования низкоуровневых базовых блоков, мы можем воспользоваться еще одним механизмом ООП для борьбы со сложностью: обобщением и специализацией с помощью наследования.
Наследование – это одна из главных «визитных карточек» ООП и один из главных механизмов повторного использования, поэтому неудивительно, что именно им часто злоупотребляют. При проектировании ПО очень часто возникает проблема, под названием «преждевременным обобщением» (premature generalization), когда на слишком ранних этапах разработки вводятся базовые классы с определенным поведением, хотя еще не понятно, что именно является «общим» в данном конкретном случае. Так, например, весьма часто можно увидеть иерархию из 5 базовых классов для простого класса Customer, хотя на текущем этапе вовсе неясно, зачем это нужно.
ПРИМЕЧАНИЕ
Причины такого положения дел в проектировании ПО очень хорошо описал Бертран Мейер: «Произвольно или нет, но многие учебные презентации создают впечатление, что структуру наследования следует проектировать от наиболее общего (верхней ее части) к более специфическим частям (листьям). В частности, это происходит потому, что лучший способ описать существующую структуру – это идти от общего к частному, от фигур к замкнутым фигурам, затем к многоугольникам, прямоугольникам, квадратам. Но лучший способ описания структуры вовсе не означает, что он является и лучшим способом ее создания.
В идеальном мире, населенном совершенными людьми, мы бы сразу же обнаруживали правильные абстракции, выводили бы из них категории, затем их подкатегории и так далее. В реальном мире, однако, мы часто вначале обнаруживаем частный случай и лишь потом открываем общую абстракцию.»
Точно также, довольно типичной является ситуация, когда собеседник обобщает свои опыт и знания, полученные на одном проекте с одним языком программирования, на другие проекты и другие языки программирования. По сути, он обобщает эти знания в «базовые» классы своих знаний, хотя на данный момент у этих классов есть только один «наследник»:
Я: Я знаю, что множественное наследование – это фигня!
Он: Почему?
Я: Потому, что его нет в Java, а других языков я не знаю!
Довольно опрометчиво делать подобные выводы, если единственный язык, который я знаю – это Java. Скорее всего, я смогу сделать более правильные выводы и структурировать свои знания более осознанно, познакомившись хотя бы с несколькими языками, поддерживающими множественное наследование, такими как С++ и Eiffel.
Давайте, в качестве примера, рассмотрим несколько способов автоматического управления памяти и представим их в иерархической форме.

Автоматическое управление памятью является наиболее общим понятием, под который попадает несколько частных случаев. Так, например, можно выделить два наиболее типичных решения, основанных (1) на сборке мусора (garbage collection) и (2) на подсчете ссылок; при этом сборщики мусора могут использовать поколения (generations) или нет.
Каждое из решений обладает своими плюсами и минусами. Так, управление памятью на основе подсчета ссылок будет страдать от «кольцевых» зависимостей (когда объекта А содержит ссылку на объект B, тот содержит ссылку на объект C, а он опять ссылается на А), но при этом будет обеспечивать детерминированность очистки ресурсов. Сборщик мусора же решит проблему с циклическими ссылками, но расплачиваться за это придется отсутствием детерминированности освобождения ресурсов.
При изучении разных языков программирования, можно стараться запомнить, как именно реализовано автоматическое управление памятью в каждом из них, но после изучения нескольких языков эффективнее будет обобщить эти знания и использовать их повторно. Конечно, каждая платформа или язык программирования обладают своими особенностями, но знания основных механизмов управления памятью существенно сократят кривую обучения, ведь понять и запомнить придется лишь различия, а не весь механизм целиком. Именно поэтому «прагматики» Дэйв Томас и Энди Хант в своей книге «Программист-прагматик. Путь от подмастерья к мастеру» советовали изучать по одному языку программированию каждый год и знакомиться с другими платформами и операционными системами. Подобное расширение кругозора позволит шире смотреть на новые задачи, а также позволит обобщить и структурировать уже существующие знания.
Заключение

Сколько бы «новых» технологий не выходило бы в свет, сколько бы новых уровней абстракции не изобретали, знание «основ» всегда будет полезным. Значительно проще понять несколько основополагающих принципов, вместо изучения сотни, казалось бы, несвязанных фактов. Знание низкоуровневых концепций можно использовать повторно, что значительно сократит время изучения «новых технологий», поскольку по большей части, они таковыми не являются. Кроме того, рано или поздно «абстракции дадут течь» и чтобы ее устранить, придется понять, как же она устроена внутри.
