 Как видно по дискуссиям на хабре, несколько десятков хабровчан прослушали курс ml-class.org Стэнфордского университета, который провел обаятельнейший профессор Andrew Ng. Я тоже с удовольствием прослушал этот курс. К сожалению, из лекций выпала очень интересная тема, заявленная в плане: комбинирование обучения с учителем и обучения без учителя. Как оказалось, профессор Ng опубликовал отличный курс по этой теме — Unsupervised Feature Learning and Deep Learning (спонтанное выделение признаков и глубокое обучение). Предлагаю краткий конспект этого курса, без строгого изложения и обилия формул. В оригинале все это есть.
Как видно по дискуссиям на хабре, несколько десятков хабровчан прослушали курс ml-class.org Стэнфордского университета, который провел обаятельнейший профессор Andrew Ng. Я тоже с удовольствием прослушал этот курс. К сожалению, из лекций выпала очень интересная тема, заявленная в плане: комбинирование обучения с учителем и обучения без учителя. Как оказалось, профессор Ng опубликовал отличный курс по этой теме — Unsupervised Feature Learning and Deep Learning (спонтанное выделение признаков и глубокое обучение). Предлагаю краткий конспект этого курса, без строгого изложения и обилия формул. В оригинале все это есть.Курсивом набраны мои врезки, которые не являются частью оригинального текста, но я не удержался и включил собственные комментарии и соображения. Прошу прощения у автора за то, что беззастенчиво использовал иллюстрации из оригинала. Также прошу прощения за прямой перевод некоторых терминов с английского (например, spatial autoencoder -> разреженный автоэнкодер). Мы Стэнфордцы плохо знаем русскую терминологию :)
Разреженный автоэнкодер
Наиболее часто используемые нейронные сети прямого распространения предназначены для обучения с учителем и используются, например, для классификации. Пример топологии такой нейронной сети приведен на рисунке:
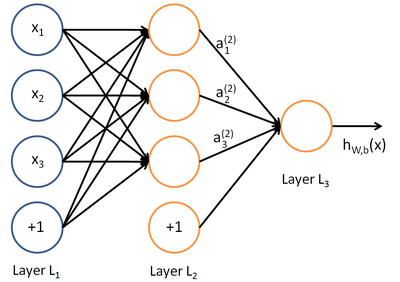
Обучение такой нейронной сети производится обычно методом обратного распространения ошибки таким образом, чтобы минимизировать среднеквадратическую ошибку отклика сети на обучающей выборке. Таким образом, обучающая выборка содержит пары векторов признаков (входные данные) и эталонных векторов (маркированные данные) {(x, y)}.
Теперь представим себе, что у нас нет маркированных данных – только набор векторов признаков {x}. Автоэнкодер представляет собой алгоритм обучения без учителя, который использует нейронную сеть и метод обратного распространения ошибки для того, чтобы добиться того, что входной вектор признаков вызывал отклик сети, равный входному вектору, т.е. y = x. Пример автоэнкодера:
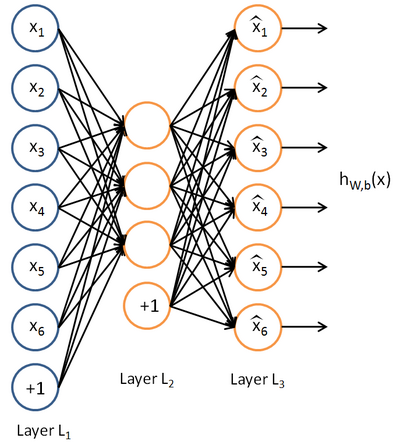
Автоэнкодер пытается построить функцию h(x) = x. Другими словами, пытается найти аппроксимацию такой функции, чтобы отклик нейронной сети приблизительно равнялся значению входных признаков. Для того, чтобы решение этой задачи было нетривиальным, на топологию сети накладываются особые условия:
• Количество нейронов скрытого слоя должно быть меньше, чем размерность входных данных (как на рисунке), или
• Активация нейронов скрытого слоя должна быть разреженной.
Первое ограничение позволяет получить сжатие данных при передаче входного сигнала на выход сети. Например, если входной вектор представляет собой набор уровней яркости изображения 10х10 пикселов (всего 100 признаков), а количество нейронов скрытого слоя 50, сеть вынужденно обучается компрессии изображения. Ведь требование h(x) = x означает, что исходя из уровней активации пятидесяти нейронов скрытого слоя выходной слой должен восстановить 100 пикселов исходного изображения. Такая компрессия возможна, если в данных есть скрытые взаимосвязи, корреляция признаков и вообще какая-то структура. В таком виде функционирование автоэнкодера очень напоминает метод анализа главных компонент (PCA) в том смысле, что понижается размерность входных данных.
Второе ограничение – требование разреженной активации нейронов скрытого слоя, — позволяет получить нетривиальные результаты даже когда количество нейронов скрытого слоя превышает размерность входных данных. Если описывать разреженность неформально, то будем считать нейрон активным, когда значение его функции передачи близко к 1. Если используется сигмоидная функция передачи, но для неактивного нейрона ее значение должно быть близко к 0 (для функции гиперболического тангенса – к -1). Разреженная активация – это когда количество неактивных нейронов в скрытом слое значительно превышает количество активных.
Если рассчитать значение p как среднее (по обучающей выборке) значение активации нейронов скрытого слоя, мы можем ввести в целевую функцию, используемую при градиентном обучении нейронной сети методом обратного распространения ошибок, дополнительный штрафной член. Формулы есть в оригинале лекций, а смысл штрафного коэффициента аналогичен методике регуляризации при вычислении коэффициентов регрессии: функция ошибки значительно возрастает, если величина p отличается от наперед заданного параметра разреженности. Например, мы можем потребовать, чтобы среднее значение активации по обучающей выборке равнялось 0.05.
Требование разреженной активации нейронов скрытого слоя имеет яркую биологическую аналогию. Автор оригинальной теории строения головного мозга Jeff Hawkins отмечает принципиальное значение тормозящих связей между нейронами (см. текст на русском языке Иерархическая темпоральная память (HTM) и ее кортикальные алгоритмы обучения). В головном мозге между нейронами, расположенными в одном слое имеется большое количество «горизонтальных связей». Хотя нейроны в коре мозга очень плотно связаны между собой, многочисленные тормозящие (ингибиторные) нейроны гарантируют, что одновременно будет активен только небольшой процент всех нейронов. То есть, получается, что информация представляется в мозге всегда только небольшим количеством активных нейронов из всех имеющихся там. Это, по-видимому, позволяет мозгу делать обобщения, например воспринимать изображение автомобиля в любом ракурсе именно как автомобиль.
Визуализация функций скрытого слоя
Обучив автоэнкодер на немаркированном наборе данных, можно попытаться визуализировать функции, аппроксимированные данным алгоритмом. Очень наглядна визуализация рассмотренного выше примера обучения энкодера на изображениях 10х10 пикселов. Зададимся вопросом: «Какая комбинация входных данных x вызовет максимальную активацию скрытого нейрона номер i ?» То есть, какой набор признаков входных данных ищет каждый из скрытых нейронов?
Нетривиальный ответ на этот вопрос содержится в лекции, а мы ограничимся иллюстрацией, которая получилась при визуализации функции сети со скрытым слоем размерностью 100 нейронов.

Каждый квадратный фрагмент представляет собой входное изображение x, которое максимально активирует один из скрытых нейронов. Поскольку соответствующая нейронная сеть была обучена на примерах естественных изображений (например, фрагментов фотографий природы), нейроны скрытого слоя самостоятельно изучили функции обнаружения контуров под разными углами!
По-моему, это очень впечалтяющий результат. Нейронная сеть самостоятельно, путем наблюдения большого количества разнообразных изображений, построила структуру, аналогичную биологическим структурам в мозгу человека и животных. Как видно из следующей иллюстрации из великой книги «От нейрона к мозгу» Дж. Николса и др., именно так устроены низшие зрительные отделы головного мозга:

На рисунке показаны ответы сложных клеток в полосатой коре кошки на зрительные раздражители. Клетка реагирует наилучшим образом (больше всего выходных импульсов) на вертикальную границу(см. первый фрагмент). Реакция на горизонтальную границу практически отсутствует (см. третий фрагмент). Сложная клетка в полосатой коре приблизительно соответствует нашему обученному нейрону в скрытом слое искусственной нейронной сети.
Вся совокупность нейронов скрытого слоя обучилась обнаруживать контуры (границы перепада яркости) под разными углами – точно так же, как и в биологическом мозге. На следующей иллюстрации из книги «От нейрона к мозгу» схематически показаны оси ориентации рецептивных полей нейронов по мере погружения вглубь коры мозга кошки. Подобные эксперименты помогли установить, что клетки со сходными свойствами у кошек и обезьян расположены в виде колонок, идущих под определенными углами к поверхности коры. Отдельные нейроны в колонке активируются при зрительном раздражении соответствующего участка поля зрения животного черной полосой на белом фоне, повернутой под определенным углом, специфичным для каждого нейрона в колонке.

Самообучение
Наиболее эффективный способ получить надежную систему машинного обучения – предоставить алгоритму обучения как можно больше данных. По опыту решения масштабных задач, происходит качественный переход, когда объем обучающей выборки превышает 1-10 млн. образцов. Можно попытаться добыть побольше маркированных данных для обучения с учителем, но это не всегда возможно (и рентабельно). Поэтому, использование немаркированных данных для самообучения нейронных сетей представляется многообещающим.
Немаркированные данные содержат меньше информации для обучения, чем маркированные. Зато объем доступных данных для обучения без учителя гораздо больше. Например, в задачах распознавания изображений доступно неограниченное количество цифровых фотографий в Интернете, и только ничтожный процент из них промаркирован.
В алгоритмах самообучения мы дадим нашей нейронной сети большое количество немаркированных данных, из которого сеть научится извлекать полезные признаки. Далее эти признаки могут использоваться для обучения конкретных классификаторов с помощью сравнительно небольших промаркированных обучающих выборок.
Изобразим первый этап самообучения в виде нейронной сети с 6 входами и тремя нейронами скрытого слоя. Выходы а этих нейронов будут являться обобщенными признаками, которые извлечены из немаркированных данных алгоритмом разреженного автоэнкодера.
Теперь можно обучить выходной слой нейронной сети, либо использовать логистическую регрессию, машину опорных векторов или алгоритм softmax для обучения классификации на основе выделенных признаков а. В качестве входных данных для этих традиционных алгоритмов будет использована промаркированная обучающая выборка xm. Возможны два варианта топологии сети самообучения:
• На вход традиционного классификатора (например, выходного слоя нейронной сети) подаются только признаки а;
• На вход традиционного классификатора (например, выходного слоя нейронной сети) подаются признаки а и входные признаки xm.
Далее в лекциях Ng рассматриваются многослойные сети и применение автоэнкодеров для их обучения.
