Вводная часть:
Сам инструментарий называется NDEV. Чтоб получить необходимый код (его мало) и документацию (её много), надо зарегиться на сайте в «программе сотрудничества». Сайт:
dragonmobile.nuancemobiledeveloper.com/public/index.php
Это весь «геморрой», если клиентов вашего приложения менее полумиллиона и они пользуются сервисами менее 20 раз в день. Сразу после регистрации вы получите членство «Silver», которое позволит вам бесплатно пользоваться данными сервисами.
Разработчикам предлагается пошаговая инструкция по внедрению в свое приложение на iOS сервисов распознавания и синтеза речи:
Инструментарий (SDK) содержит в себе компоненты и клиента, и сервера. Диаграмма иллюстрирует их взаимодействие на верхнем уровне:

Комплект Dragon Mobile SDK состоит из различных примеров кода и шаблонов проектов, документации, а также программной платформы (фреймворка), упрощающей интеграцию речевых сервисов в любое приложение.
Платформа Speech Kit framework позволяет легко и быстро добавлять в приложения сервисы распознавания и синтеза (TTS, Text-to-Speech) речи. Данная платформа также обеспечивает доступ к компонентам обработки речи, находящимся на сервере, через асинхронные «чистые» сетевые API, сводя к минимуму накладные расходы и потребляемые ресурсы.
Платформа Speech Kit является полнофункциональным высокоуровневым «фреймворком», который автоматически управляет всеми низкоуровневыми сервисами.
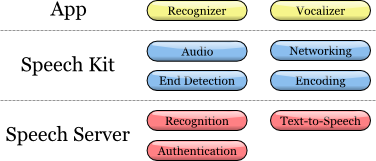
Архитектура Speech Kit
Основная часть
На прикладном уровне разработчику доступны два основных сервиса: распознавание и синтез речи из текста.
Платформа выполняет несколько согласованных процессов:
Осуществляет полное управление аудио системой для записи и воспроизведения
Сетевой компонент управляет подключениями к серверу и автоматически восстанавливает соединения с истекшим временем ожидания при каждом новом запросе
Детектор окончания речи определяет, когда пользователь закончил говорить, и при необходимости автоматически останавливает запись
Кодирующий компонент сжимает и распаковывает потоковую аудиозапись, снижая требования к полосе пропускания и уменьшая среднее время задержки.
Система серверов отвечает за большинство операций, входящих в цикл обработки речи. Процесс распознавания или синтеза речи выполняется целиком на сервере, обрабатывая или синтезируя аудио-поток. Кроме того, сервер осуществляет аутентификацию в соответствии с конфигурацией разработчика.
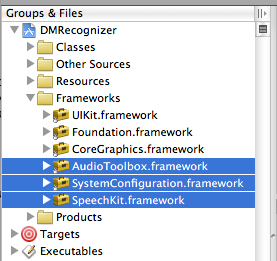
В данной конкретной статье мы сконцентрируем внимание на разработке для iOS. Фреймворк Speech Kit может использоваться точно также как любая стандартная программная платформа для iPhone, например Foundation или UIKit. Разница лишь в том, что Speech Kit – статический фреймворк, и целиком содержится в компиляции вашего приложения. Speech Kit непосредственно связан с некоторыми ключевыми операционными компонентами iPhone OS, которые необходимо включать в приложение как взаимозависимые, так, чтобы они были доступны во время работы приложения. Кроме Foundation вам необходимо добавить в Xcode-проект компоненты System Configuration и Audio Toolbox:
1. Начните с выбора программных платформ (Framework group) в рамках вашего проекта
2. Затем щелкните правой или командной кнопкой мыши «Платформы» (Frameworks) и в появившихся меню выберите: Добавить (Add) ‣Существующие Платформы (Existing frameworks)…
3. Наконец, выберите нужные фреймворки и нажмите кнопку Добавить (Add). Выбранные платформы отображаются в папке Фреймворки (Frameworks) (см. рис. выше).
Чтобы начать использование программной платформы SpeechKit, добавьте ее к своему новому или уже существующему проекту:
1. Откройте свой проект и выберите группу, в которой вы хотите чтобы находилась платформа Speech Kit, например: file:Frameworks.
2. В меню выберите Проект (Project) ‣ Добавить в проект( Add to Project)…
3. Далее найдите фреймворк «SpeechKit.framework», в который вы распаковали инструментарий Dragon Mobile SDK и выберите Добавить (Add).
4. Чтобы убедиться, что Speech Kit находится в вашем проекте и не ссылается на исходную локацию, выберите Копировать элементы (Copy items)… а затем Добавить (Add).
5. Как вы можете видеть, платформа Speech Kit добавлена в ваш проект, который вы можете расширить для доступа к публичным заголовкам (Public Headers).
Платформы, необходимые для Speech Kit
Фреймворк Speech Kit обеспечивает один заголовок верхнего уровня, который предоставляет доступ к полному интерфейсу программирования приложения (API), до классов и констант включительно. Вам необходимо импортировать заголовки Speech Kit во все исходные файлы, где собираетесь применять сервисы Speech Kit:
#import <SpeechKit/SpeechKit.h>
Теперь вы можете начать пользоваться сервисами распознавания и преобразования текста в речь (речевого синтеза).
Платформа Speech Kit является сетевым сервисом и нуждается в некоторых базовых настройках перед началом использования классов распознавания или синтеза речи.
Данная установка выполняет две основные операции:
Во-первых, она определяет и авторизует ваше приложение.
Во-вторых, — устанавливает соединение с речевым сервером, — это позволяет производить быстрые запросы на речевую обработку и, следовательно, повышает качество обслуживания пользователей.
Примечание
Указанное сетевое соединение требует авторизации учетных данных и настроек сервера, заданных разработчиком. Необходимые полномочия предоставляются с помощью портала Dragon Mobile SDK: dragonmobile.nuancemobiledeveloper.com.
Установка Kit Setup
Ключ приложения SpeechKitApplicationKey запрашивается программной платформой и должен быть установлен разработчиком. Ключ выполняет функцию пароля вашего приложения для серверов обработки речи и должен храниться в тайне для предотвращения неправомерного использования.
Ваши уникальные полномочия, включая ключ приложения (Application Key), предоставляющийся через портал разработчиков, предполагают внесение нескольких дополнительных строчек кода для установки данных прав. Таким образом, процесс сводится к копированию и вставке строк в исходном файле. Вам необходимо установить ваш ключ приложения до инициализации системы Speech Kit. Например, можно настроить ключ приложения следующим образом:
const unsigned char[] SpeechKitApplicationKey = {0x12, 0x34, ..., 0x89};
Установочный метод, setupWithID:host:port, содержит 3 параметра:
Идентификатор приложения
Адрес сервера
Порт
Параметр ID идентифицирует ваше приложение и используется в сочетании с вашим ключом приложения, обеспечивая авторизацию для доступа к речевым серверам.
Параметры хоста и порта задают речевой сервер, который может меняться от приложения к приложению. Таким образом, вам всегда следует использовать значения, заданные параметрами аутентификации.
Фреймворк настраивается на следующем примере:
[SpeechKit setupWithID:@«NMDPTRIAL_Acme20100604154233_aaea77bc5b900dc4005faae89f60a029214d450b»
host:@«10.0.0.100»
port:443];
Примечание
Метод setupWithID:host:port является методом класса и не генерирует объект (экземпляр). Этот метод предназначен для одноразового вызова за время работы приложения, он настраивает основное сетевое подключение. Это асинхронный метод, который выполняется в фоновом режиме, устанавливает соединение и выполняет авторизацию. Метод не сообщает об ошибке соединения/авторизации. Успех или провал выполнения данной установки становится известным с использованием классов SKRecognizer и SKVocalizer.
На данном этапе речевой сервер полностью сконфигурирован, и платформа начинает устанавливать соединение. Это соединение будет оставаться открытым в течение некоторого времени, выступая гарантией того, что последующие речевые запросы обрабатываются оперативно до тех пор, пока активно используются речевые сервисы. Если у соединения истекает время ожидания, оно прерывается, но будет восстановлено автоматически одновременно со следующим речевым запросом.
Приложение настроено и готово распознавать и синтезировать речь.
Распознавание речи
Технология распознавания позволяет пользователям диктовать вместо того, чтобы печатать там, где обычно требуется ввод текста. Распознаватель речи выдает список текстовых результатов. Он никак не привязан к какому-либо объекту пользовательского интерфейса (UI), поэтому отбор наиболее подходящего результата и выборка альтернативных результатов остается на усмотрение пользовательского интерфейса каждого приложения.

Процесс распознавания речи
Инициирование процесса распознавания
1. Перед использованием сервиса распознавания речи, убедитесь, что исходная платформа Speech Kit настроена вами с помощью метода setupWithID:host:port.
2. Затем создайте и инициализируйте объект SKRecognizer:
3. recognizer = [[SKRecognizer alloc] initWithType:SKSearchRecognizerType
4. detection:SKShortEndOfSpeechDetection
5. language:@«en_US»
6. delegate:self];
7. Метод initWithType:detection:language:delegate инициализирует распознаватель и запускает процесс распознавания речи.
Типовой параметр — NSString *, это одна из типовых констант распознавания, определяемых платформой Speech Kit и доступной через заголовок SKRecognizer.h. Nuance может предоставить вам другие значения для ваших уникальных потребностей распознавания, в этом случае вам понадобится добавить расширение NSString.
Параметр обнаружения задает модель «определение окончания речи» и должен соответствовать одному из типов SKEndOfSpeechDetection.
Языковой параметр определяет язык речи в виде строки в формате кода языка ISO 639, а затем нижнего подчеркивания “_”, после чего следует код страны в формате ISO 3166-1.
Примечание
Например английский язык, на котором говорят в США, имеет обозначение en_US. Обновленный список поддерживаемых языков для распознавания доступен на FAQ: dragonmobile.nuancemobiledeveloper.com/faq.php.
8. Делегат получает результат распознавания или сообщения об ошибке, как описано ниже.
Получение результатов распознавания
Для получения результатов распознавания, обратитесь к методу делегации recognizer:didFinishWithResults:
— (void)recognizer:(SKRecognizer *)recognizer didFinishWithResults:(SKRecognition *)results {
[recognizer autorelease];
// выполнить какие-либо действия по результатам
}
Метод делегации будет применяться только при успешном завершении процесса, список результатов будет содержать ноль или более результатов. Первый результат всегда может быть найден с помощью метода firstResult. Даже в отсутствие ошибки, может присутствовать совет (предложение) от речевого сервера, присутствующее в объекте результатов распознавания. Такой совет (предложение) должен быть представлен пользователю.
Обработка ошибок
Чтобы получать информацию о любых ошибках распознавания, используйте метод делегации recognizer:didFinishWithError:suggestion:. В случае ошибки будет вызван только этот метод; напротив, в случае успеха данный метод вызываться не будет. В дополнение к ошибке, как упоминалось в предыдущем разделе, в результате могут присутствовать или не присутствовать советы.
— (void)recognizer:(SKRecognizer *)recognizer didFinishWithError:(NSError *)error suggestion:(NSString *)suggestion {
[recognizer autorelease];
// информирование пользователя об ошибке и совет
}
Управление стадиями записи
Чтобы при желании получать информацию о том, когда распознаватель начинает или заканчивает запись аудио, воспользуйтесь методами делегации recognizerDidBeginRecording: и recognizerDidFinishRecording:. Так, может возникать задержка между инициализацией распознавания и фактическим началом записи, и сообщение recognizerDidBeginRecording: может сигнализировать пользователю, что система готова слушать.
— (void)recognizerDidBeginRecording:(SKRecognizer *)recognizer {
// Обновить UI чтобы указать, что система ведет запись
}
Сообщение recognizerDidFinishRecording: посылается до того, как речевой сервер заканчивает прием и обработку звукового файла, и, следовательно, до того, как становится доступен результат.
— (void)recognizerDidFinishRecording:(SKRecognizer *)recognizer {
// Обновить UI чтобы указать, что запись прекратилась, и речь еще обрабатывается
}
Данное сообщение посылается вне зависимости от наличия модели обнаружения конца записи. Сообщение посылается одинаково и по вызову метода stopRecording, и по сигналу обнаружения окончания записи.
Установка «звуковых иконок» (сигналов)
Кроме того, для воспроизведения звуковых сигналов до и после записи, а также после отмены сессии записи, могут использоваться «звуковые иконки». Вам необходимо создать объект SKEarcon и установить для него метод setEarcon:forType: платформы Speech Kit. Приведенный ниже пример демонстрирует, как устанавливаются «звуковые иконки» в приложении-примере
— (void)setEarcons {
// Воспроизводить «звуковые иконки»
SKEarcon* earconStart = [SKEarcon earconWithName:@«earcon_listening.wav»];
SKEarcon* earconStop = [SKEarcon earconWithName:@«earcon_done_listening.wav»];
SKEarcon* earconCancel = [SKEarcon earconWithName:@«earcon_cancel.wav»];
[SpeechKit setEarcon:earconStart forType:SKStartRecordingEarconType];
[SpeechKit setEarcon:earconStop forType:SKStopRecordingEarconType];
[SpeechKit setEarcon:earconCancel forType:SKCancelRecordingEarconType];
}
Когда вызывается блок кода уровнем выше,(после того, как вы настроили основную программную платформу Speech Kit с помощью метода setupWithID:host:port), перед началом процесса записи проигрывается аудиофайл earcon_listening.wav, и звучит аудиофайл earcon_done_listening.wav, когда запись завершена. В случае отказа от сессии записи для пользователя звучит аудиофайл earcon_cancel.wav". Метод``earconWithName: работает только для аудиофайлов, которые поддерживаются устройством.
Отображение уровня звука
В некоторых случаях, особенно при продолжительной диктовке, удобно снабжать пользователя визуальным отображением мощности звука его речи. Интерфейс звукозаписи поддерживает данную возможность при применении атрибута audioLevel, возвращающего относительный уровень мощности записанного звука в децибелах. Диапазон этого значения характеризуется плавающей точкой и находится в промежутке от 0.0 и -90.0 dB где 0.0 является самым высоким уровнем мощности, а -90.0 – нижней границей мощности звука. Этот атрибут должен быть доступен во время записи, в частности, в момент между получением сообщений recognizerDidBeginRecording: и recognizerDidFinishRecording:. В общем случае вам понадобится использовать метод таймера, например такой как performSelector:withObject:afterDelay: для регулярного отображения уровня мощности.
Преобразование текста в речь
Класс SKVocalizer предоставляет разработчикам сетевой интерфейс речевого синтеза.
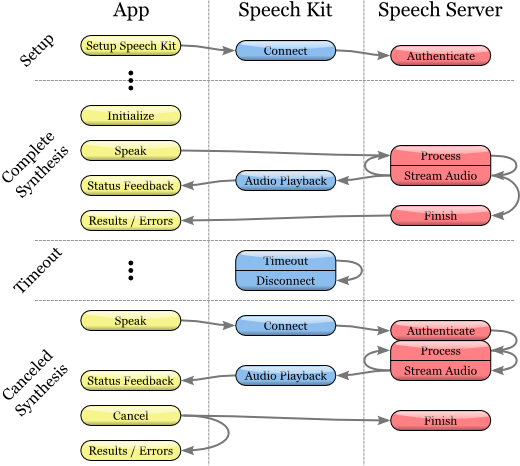
Процесс речевого синтеза
Инициализация процесса речевого синтеза
1. Перед началом использования сервиса синтеза речи убедитесь, что основная программная платформа настроена Speech Kit с помощью метода setupWithID:host:port.
2. Затем создайте и инициализируйте объект SKVocalizer для преобразования текста в речь:
3. vocalizer = [[SKVocalizer alloc] initWithLanguage:@«en_US»
4. delegate:self];
5.
1. Метод initWithLanguage:delegate: инициализирует сервис речевой синтез с языком по умолчанию.
Языковой параметр — NSString * который определяет язык в виде кода языка формата ISO 639, нижнего подчеркивания “_” и следующего за ними кода страны в формате ISO 3166-1. Например, английский язык, которым пользуются в США, имеет формат en_US. Каждый поддерживаемый язык имеет один или более уникальный голос, мужского или женского пола.
Примечание
Обновленный список поддерживаемых языков для речевого синтеза доступен на сайте: dragonmobile.nuancemobiledeveloper.com/faq.php. Список поддерживаемых языков будет обновляться при появлении поддержки нового языка(ов). Новые языки не обязательно будут требовать обновления существующего Dragon Mobile SDK.
Делегированный параметр определяет объект для получения от речевого синтезатора статусов и сообщений об ошибке.
2. Метод initWithLanguage:delegate: использует голос по умолчанию, выбранный Nuance. Чтобы выбрать другой голос, используйте метод initWithVoice:delegate: вместо предыдущего.
Голосовой параметр — NSString *, он определяет звуковую модель. Например, голос для великобританского английского по умолчанию – Samantha (Саманта).
Примечание
Обновленный список поддерживаемых голосов, сопоставленный с поддерживаемыми языками, размещен на сайте:
dragonmobile.nuancemobiledeveloper.com/faq.php.
5. Для начала процесса преобразования текста в речь вам необходимо использовать метод speakString: или speakMarkupString:. Эти методы отправляют запрашиваемую строку на речевой сервер и инициализируют потоковую обработку и воспроизведение аудио на устройстве.
6. [vocalizer speakString:@«Hello world.»]
Примечание
Метод speakMarkupString используется точно таким же образом, как метод speakString с той лишь разницей, что класс NSString * выполняется разметочным языком синтеза речи, предназначенным для описания синтезированной речи. Последние обсуждения разметочных языков синтеза речи выходит за рамки данного документа, однако вы можете ознакомиться с более подробной информацией по данной теме, предоставленной W3C, на www.w3.org/TR/speech-synthesis.
Речевой синтез является сетевым сервисом и, следовательно, упомянутые выше методы являются асинхронными, — в общем случае сообщение об ошибке не выводится моментально. Любые ошибки представляются в виде сообщений делегату.
Управление обратным откликом системы синтеза речи
Синтезированная речь не будет воспроизведена моментально. Скорее всего будет иметь место небольшая по времени задержка, во время которой на речевой сервис отправляется и перенаправляется обратно запрос. Опциональный делегационный метод vocalizer:willBeginSpeakingString: применяется для координации пользовательского интерфейса и имеет своей целью указать момент начала воспроизведения звука.
— (void)vocalizer:(SKVocalizer *)vocalizer willBeginSpeakingString:(NSString *)text {
// Обновить пользовательский интерфейс чтобы указать момент начала воспроизведения речи
}
Класс NSString * в сообщении выполняет роль ссылки на оригинальную строку, выполненную одним из методов: speakString или speakMarkupString, и может быть использован в ходе последовательного воспроизведения трека, когда сделаны соответствующие запросы на преобразование текста в речь.
По окончании воспроизведения речи посылается сообщение vocalizer:didFinishSpeakingString:withError. Это сообщение всегда отправляется как в случае успешного завершения процесса воспроизведения, так и в случае ошибки. В случае успешного завершения ошибка «зануляется».
— (void)vocalizer:(SKVocalizer *)vocalizer didFinishSpeakingString:(NSString *)text withError:(NSError *)error {
if (error) {
// Вывести для пользователя диалоговое окно ошибки
} else {
// Обновить пользовательский интерфейс, указать на завершение воспроизведения
}
}
После этих манипуляций вам остается только отладить соответствующий сервис и пользоваться.
Сам инструментарий называется NDEV. Чтоб получить необходимый код (его мало) и документацию (её много), надо зарегиться на сайте в «программе сотрудничества». Сайт:
dragonmobile.nuancemobiledeveloper.com/public/index.php
Это весь «геморрой», если клиентов вашего приложения менее полумиллиона и они пользуются сервисами менее 20 раз в день. Сразу после регистрации вы получите членство «Silver», которое позволит вам бесплатно пользоваться данными сервисами.
Разработчикам предлагается пошаговая инструкция по внедрению в свое приложение на iOS сервисов распознавания и синтеза речи:
Инструментарий (SDK) содержит в себе компоненты и клиента, и сервера. Диаграмма иллюстрирует их взаимодействие на верхнем уровне:
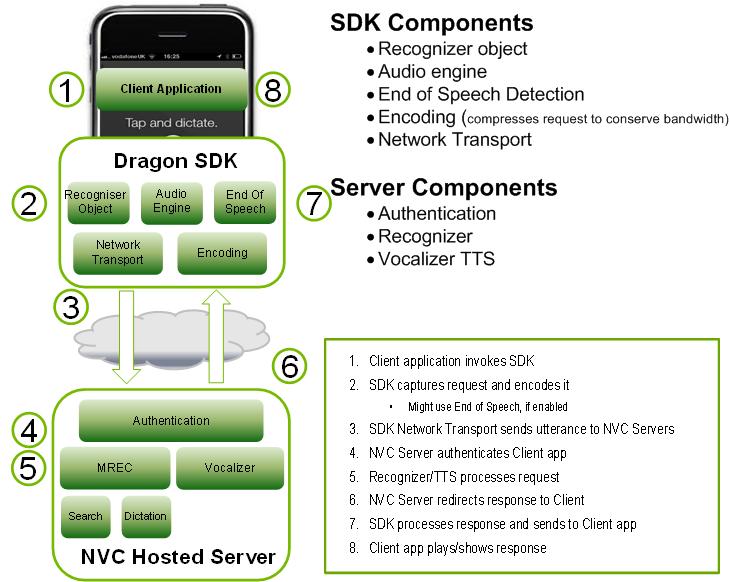
Комплект Dragon Mobile SDK состоит из различных примеров кода и шаблонов проектов, документации, а также программной платформы (фреймворка), упрощающей интеграцию речевых сервисов в любое приложение.
Платформа Speech Kit framework позволяет легко и быстро добавлять в приложения сервисы распознавания и синтеза (TTS, Text-to-Speech) речи. Данная платформа также обеспечивает доступ к компонентам обработки речи, находящимся на сервере, через асинхронные «чистые» сетевые API, сводя к минимуму накладные расходы и потребляемые ресурсы.
Платформа Speech Kit является полнофункциональным высокоуровневым «фреймворком», который автоматически управляет всеми низкоуровневыми сервисами.
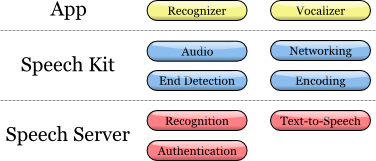
Архитектура Speech Kit
Основная часть
На прикладном уровне разработчику доступны два основных сервиса: распознавание и синтез речи из текста.
Платформа выполняет несколько согласованных процессов:
Осуществляет полное управление аудио системой для записи и воспроизведения
Сетевой компонент управляет подключениями к серверу и автоматически восстанавливает соединения с истекшим временем ожидания при каждом новом запросе
Детектор окончания речи определяет, когда пользователь закончил говорить, и при необходимости автоматически останавливает запись
Кодирующий компонент сжимает и распаковывает потоковую аудиозапись, снижая требования к полосе пропускания и уменьшая среднее время задержки.
Система серверов отвечает за большинство операций, входящих в цикл обработки речи. Процесс распознавания или синтеза речи выполняется целиком на сервере, обрабатывая или синтезируя аудио-поток. Кроме того, сервер осуществляет аутентификацию в соответствии с конфигурацией разработчика.
В данной конкретной статье мы сконцентрируем внимание на разработке для iOS. Фреймворк Speech Kit может использоваться точно также как любая стандартная программная платформа для iPhone, например Foundation или UIKit. Разница лишь в том, что Speech Kit – статический фреймворк, и целиком содержится в компиляции вашего приложения. Speech Kit непосредственно связан с некоторыми ключевыми операционными компонентами iPhone OS, которые необходимо включать в приложение как взаимозависимые, так, чтобы они были доступны во время работы приложения. Кроме Foundation вам необходимо добавить в Xcode-проект компоненты System Configuration и Audio Toolbox:
1. Начните с выбора программных платформ (Framework group) в рамках вашего проекта
2. Затем щелкните правой или командной кнопкой мыши «Платформы» (Frameworks) и в появившихся меню выберите: Добавить (Add) ‣Существующие Платформы (Existing frameworks)…
3. Наконец, выберите нужные фреймворки и нажмите кнопку Добавить (Add). Выбранные платформы отображаются в папке Фреймворки (Frameworks) (см. рис. выше).
Чтобы начать использование программной платформы SpeechKit, добавьте ее к своему новому или уже существующему проекту:
1. Откройте свой проект и выберите группу, в которой вы хотите чтобы находилась платформа Speech Kit, например: file:Frameworks.
2. В меню выберите Проект (Project) ‣ Добавить в проект( Add to Project)…
3. Далее найдите фреймворк «SpeechKit.framework», в который вы распаковали инструментарий Dragon Mobile SDK и выберите Добавить (Add).
4. Чтобы убедиться, что Speech Kit находится в вашем проекте и не ссылается на исходную локацию, выберите Копировать элементы (Copy items)… а затем Добавить (Add).
5. Как вы можете видеть, платформа Speech Kit добавлена в ваш проект, который вы можете расширить для доступа к публичным заголовкам (Public Headers).
Платформы, необходимые для Speech Kit
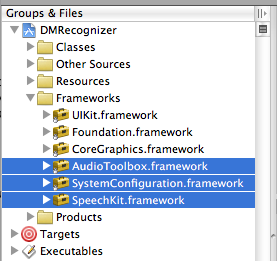
Фреймворк Speech Kit обеспечивает один заголовок верхнего уровня, который предоставляет доступ к полному интерфейсу программирования приложения (API), до классов и констант включительно. Вам необходимо импортировать заголовки Speech Kit во все исходные файлы, где собираетесь применять сервисы Speech Kit:
#import <SpeechKit/SpeechKit.h>
Теперь вы можете начать пользоваться сервисами распознавания и преобразования текста в речь (речевого синтеза).
Платформа Speech Kit является сетевым сервисом и нуждается в некоторых базовых настройках перед началом использования классов распознавания или синтеза речи.
Данная установка выполняет две основные операции:
Во-первых, она определяет и авторизует ваше приложение.
Во-вторых, — устанавливает соединение с речевым сервером, — это позволяет производить быстрые запросы на речевую обработку и, следовательно, повышает качество обслуживания пользователей.
Примечание
Указанное сетевое соединение требует авторизации учетных данных и настроек сервера, заданных разработчиком. Необходимые полномочия предоставляются с помощью портала Dragon Mobile SDK: dragonmobile.nuancemobiledeveloper.com.
Установка Kit Setup
Ключ приложения SpeechKitApplicationKey запрашивается программной платформой и должен быть установлен разработчиком. Ключ выполняет функцию пароля вашего приложения для серверов обработки речи и должен храниться в тайне для предотвращения неправомерного использования.
Ваши уникальные полномочия, включая ключ приложения (Application Key), предоставляющийся через портал разработчиков, предполагают внесение нескольких дополнительных строчек кода для установки данных прав. Таким образом, процесс сводится к копированию и вставке строк в исходном файле. Вам необходимо установить ваш ключ приложения до инициализации системы Speech Kit. Например, можно настроить ключ приложения следующим образом:
const unsigned char[] SpeechKitApplicationKey = {0x12, 0x34, ..., 0x89};
Установочный метод, setupWithID:host:port, содержит 3 параметра:
Идентификатор приложения
Адрес сервера
Порт
Параметр ID идентифицирует ваше приложение и используется в сочетании с вашим ключом приложения, обеспечивая авторизацию для доступа к речевым серверам.
Параметры хоста и порта задают речевой сервер, который может меняться от приложения к приложению. Таким образом, вам всегда следует использовать значения, заданные параметрами аутентификации.
Фреймворк настраивается на следующем примере:
[SpeechKit setupWithID:@«NMDPTRIAL_Acme20100604154233_aaea77bc5b900dc4005faae89f60a029214d450b»
host:@«10.0.0.100»
port:443];
Примечание
Метод setupWithID:host:port является методом класса и не генерирует объект (экземпляр). Этот метод предназначен для одноразового вызова за время работы приложения, он настраивает основное сетевое подключение. Это асинхронный метод, который выполняется в фоновом режиме, устанавливает соединение и выполняет авторизацию. Метод не сообщает об ошибке соединения/авторизации. Успех или провал выполнения данной установки становится известным с использованием классов SKRecognizer и SKVocalizer.
На данном этапе речевой сервер полностью сконфигурирован, и платформа начинает устанавливать соединение. Это соединение будет оставаться открытым в течение некоторого времени, выступая гарантией того, что последующие речевые запросы обрабатываются оперативно до тех пор, пока активно используются речевые сервисы. Если у соединения истекает время ожидания, оно прерывается, но будет восстановлено автоматически одновременно со следующим речевым запросом.
Приложение настроено и готово распознавать и синтезировать речь.
Распознавание речи
Технология распознавания позволяет пользователям диктовать вместо того, чтобы печатать там, где обычно требуется ввод текста. Распознаватель речи выдает список текстовых результатов. Он никак не привязан к какому-либо объекту пользовательского интерфейса (UI), поэтому отбор наиболее подходящего результата и выборка альтернативных результатов остается на усмотрение пользовательского интерфейса каждого приложения.
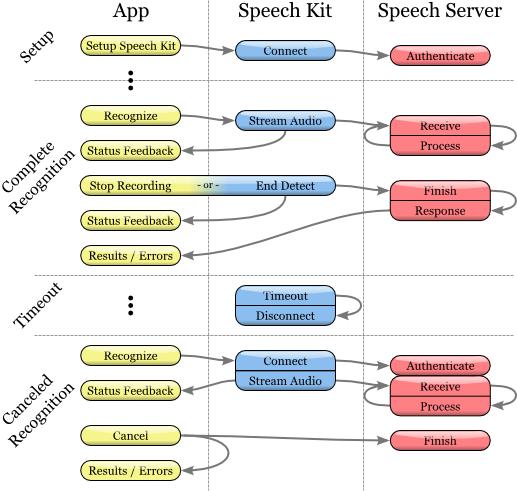
Процесс распознавания речи
Инициирование процесса распознавания
1. Перед использованием сервиса распознавания речи, убедитесь, что исходная платформа Speech Kit настроена вами с помощью метода setupWithID:host:port.
2. Затем создайте и инициализируйте объект SKRecognizer:
3. recognizer = [[SKRecognizer alloc] initWithType:SKSearchRecognizerType
4. detection:SKShortEndOfSpeechDetection
5. language:@«en_US»
6. delegate:self];
7. Метод initWithType:detection:language:delegate инициализирует распознаватель и запускает процесс распознавания речи.
Типовой параметр — NSString *, это одна из типовых констант распознавания, определяемых платформой Speech Kit и доступной через заголовок SKRecognizer.h. Nuance может предоставить вам другие значения для ваших уникальных потребностей распознавания, в этом случае вам понадобится добавить расширение NSString.
Параметр обнаружения задает модель «определение окончания речи» и должен соответствовать одному из типов SKEndOfSpeechDetection.
Языковой параметр определяет язык речи в виде строки в формате кода языка ISO 639, а затем нижнего подчеркивания “_”, после чего следует код страны в формате ISO 3166-1.
Примечание
Например английский язык, на котором говорят в США, имеет обозначение en_US. Обновленный список поддерживаемых языков для распознавания доступен на FAQ: dragonmobile.nuancemobiledeveloper.com/faq.php.
8. Делегат получает результат распознавания или сообщения об ошибке, как описано ниже.
Получение результатов распознавания
Для получения результатов распознавания, обратитесь к методу делегации recognizer:didFinishWithResults:
— (void)recognizer:(SKRecognizer *)recognizer didFinishWithResults:(SKRecognition *)results {
[recognizer autorelease];
// выполнить какие-либо действия по результатам
}
Метод делегации будет применяться только при успешном завершении процесса, список результатов будет содержать ноль или более результатов. Первый результат всегда может быть найден с помощью метода firstResult. Даже в отсутствие ошибки, может присутствовать совет (предложение) от речевого сервера, присутствующее в объекте результатов распознавания. Такой совет (предложение) должен быть представлен пользователю.
Обработка ошибок
Чтобы получать информацию о любых ошибках распознавания, используйте метод делегации recognizer:didFinishWithError:suggestion:. В случае ошибки будет вызван только этот метод; напротив, в случае успеха данный метод вызываться не будет. В дополнение к ошибке, как упоминалось в предыдущем разделе, в результате могут присутствовать или не присутствовать советы.
— (void)recognizer:(SKRecognizer *)recognizer didFinishWithError:(NSError *)error suggestion:(NSString *)suggestion {
[recognizer autorelease];
// информирование пользователя об ошибке и совет
}
Управление стадиями записи
Чтобы при желании получать информацию о том, когда распознаватель начинает или заканчивает запись аудио, воспользуйтесь методами делегации recognizerDidBeginRecording: и recognizerDidFinishRecording:. Так, может возникать задержка между инициализацией распознавания и фактическим началом записи, и сообщение recognizerDidBeginRecording: может сигнализировать пользователю, что система готова слушать.
— (void)recognizerDidBeginRecording:(SKRecognizer *)recognizer {
// Обновить UI чтобы указать, что система ведет запись
}
Сообщение recognizerDidFinishRecording: посылается до того, как речевой сервер заканчивает прием и обработку звукового файла, и, следовательно, до того, как становится доступен результат.
— (void)recognizerDidFinishRecording:(SKRecognizer *)recognizer {
// Обновить UI чтобы указать, что запись прекратилась, и речь еще обрабатывается
}
Данное сообщение посылается вне зависимости от наличия модели обнаружения конца записи. Сообщение посылается одинаково и по вызову метода stopRecording, и по сигналу обнаружения окончания записи.
Установка «звуковых иконок» (сигналов)
Кроме того, для воспроизведения звуковых сигналов до и после записи, а также после отмены сессии записи, могут использоваться «звуковые иконки». Вам необходимо создать объект SKEarcon и установить для него метод setEarcon:forType: платформы Speech Kit. Приведенный ниже пример демонстрирует, как устанавливаются «звуковые иконки» в приложении-примере
— (void)setEarcons {
// Воспроизводить «звуковые иконки»
SKEarcon* earconStart = [SKEarcon earconWithName:@«earcon_listening.wav»];
SKEarcon* earconStop = [SKEarcon earconWithName:@«earcon_done_listening.wav»];
SKEarcon* earconCancel = [SKEarcon earconWithName:@«earcon_cancel.wav»];
[SpeechKit setEarcon:earconStart forType:SKStartRecordingEarconType];
[SpeechKit setEarcon:earconStop forType:SKStopRecordingEarconType];
[SpeechKit setEarcon:earconCancel forType:SKCancelRecordingEarconType];
}
Когда вызывается блок кода уровнем выше,(после того, как вы настроили основную программную платформу Speech Kit с помощью метода setupWithID:host:port), перед началом процесса записи проигрывается аудиофайл earcon_listening.wav, и звучит аудиофайл earcon_done_listening.wav, когда запись завершена. В случае отказа от сессии записи для пользователя звучит аудиофайл earcon_cancel.wav". Метод``earconWithName: работает только для аудиофайлов, которые поддерживаются устройством.
Отображение уровня звука
В некоторых случаях, особенно при продолжительной диктовке, удобно снабжать пользователя визуальным отображением мощности звука его речи. Интерфейс звукозаписи поддерживает данную возможность при применении атрибута audioLevel, возвращающего относительный уровень мощности записанного звука в децибелах. Диапазон этого значения характеризуется плавающей точкой и находится в промежутке от 0.0 и -90.0 dB где 0.0 является самым высоким уровнем мощности, а -90.0 – нижней границей мощности звука. Этот атрибут должен быть доступен во время записи, в частности, в момент между получением сообщений recognizerDidBeginRecording: и recognizerDidFinishRecording:. В общем случае вам понадобится использовать метод таймера, например такой как performSelector:withObject:afterDelay: для регулярного отображения уровня мощности.
Преобразование текста в речь
Класс SKVocalizer предоставляет разработчикам сетевой интерфейс речевого синтеза.
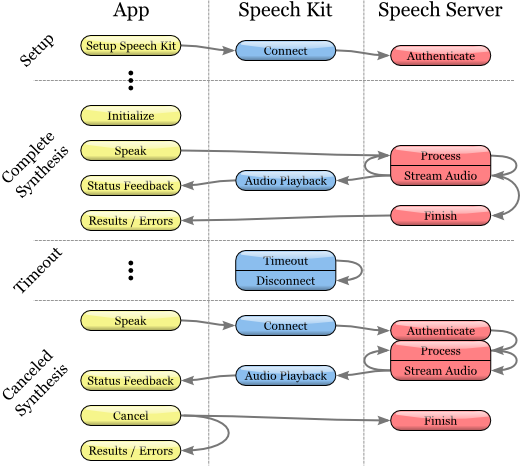
Процесс речевого синтеза
Инициализация процесса речевого синтеза
1. Перед началом использования сервиса синтеза речи убедитесь, что основная программная платформа настроена Speech Kit с помощью метода setupWithID:host:port.
2. Затем создайте и инициализируйте объект SKVocalizer для преобразования текста в речь:
3. vocalizer = [[SKVocalizer alloc] initWithLanguage:@«en_US»
4. delegate:self];
5.
1. Метод initWithLanguage:delegate: инициализирует сервис речевой синтез с языком по умолчанию.
Языковой параметр — NSString * который определяет язык в виде кода языка формата ISO 639, нижнего подчеркивания “_” и следующего за ними кода страны в формате ISO 3166-1. Например, английский язык, которым пользуются в США, имеет формат en_US. Каждый поддерживаемый язык имеет один или более уникальный голос, мужского или женского пола.
Примечание
Обновленный список поддерживаемых языков для речевого синтеза доступен на сайте: dragonmobile.nuancemobiledeveloper.com/faq.php. Список поддерживаемых языков будет обновляться при появлении поддержки нового языка(ов). Новые языки не обязательно будут требовать обновления существующего Dragon Mobile SDK.
Делегированный параметр определяет объект для получения от речевого синтезатора статусов и сообщений об ошибке.
2. Метод initWithLanguage:delegate: использует голос по умолчанию, выбранный Nuance. Чтобы выбрать другой голос, используйте метод initWithVoice:delegate: вместо предыдущего.
Голосовой параметр — NSString *, он определяет звуковую модель. Например, голос для великобританского английского по умолчанию – Samantha (Саманта).
Примечание
Обновленный список поддерживаемых голосов, сопоставленный с поддерживаемыми языками, размещен на сайте:
dragonmobile.nuancemobiledeveloper.com/faq.php.
5. Для начала процесса преобразования текста в речь вам необходимо использовать метод speakString: или speakMarkupString:. Эти методы отправляют запрашиваемую строку на речевой сервер и инициализируют потоковую обработку и воспроизведение аудио на устройстве.
6. [vocalizer speakString:@«Hello world.»]
Примечание
Метод speakMarkupString используется точно таким же образом, как метод speakString с той лишь разницей, что класс NSString * выполняется разметочным языком синтеза речи, предназначенным для описания синтезированной речи. Последние обсуждения разметочных языков синтеза речи выходит за рамки данного документа, однако вы можете ознакомиться с более подробной информацией по данной теме, предоставленной W3C, на www.w3.org/TR/speech-synthesis.
Речевой синтез является сетевым сервисом и, следовательно, упомянутые выше методы являются асинхронными, — в общем случае сообщение об ошибке не выводится моментально. Любые ошибки представляются в виде сообщений делегату.
Управление обратным откликом системы синтеза речи
Синтезированная речь не будет воспроизведена моментально. Скорее всего будет иметь место небольшая по времени задержка, во время которой на речевой сервис отправляется и перенаправляется обратно запрос. Опциональный делегационный метод vocalizer:willBeginSpeakingString: применяется для координации пользовательского интерфейса и имеет своей целью указать момент начала воспроизведения звука.
— (void)vocalizer:(SKVocalizer *)vocalizer willBeginSpeakingString:(NSString *)text {
// Обновить пользовательский интерфейс чтобы указать момент начала воспроизведения речи
}
Класс NSString * в сообщении выполняет роль ссылки на оригинальную строку, выполненную одним из методов: speakString или speakMarkupString, и может быть использован в ходе последовательного воспроизведения трека, когда сделаны соответствующие запросы на преобразование текста в речь.
По окончании воспроизведения речи посылается сообщение vocalizer:didFinishSpeakingString:withError. Это сообщение всегда отправляется как в случае успешного завершения процесса воспроизведения, так и в случае ошибки. В случае успешного завершения ошибка «зануляется».
— (void)vocalizer:(SKVocalizer *)vocalizer didFinishSpeakingString:(NSString *)text withError:(NSError *)error {
if (error) {
// Вывести для пользователя диалоговое окно ошибки
} else {
// Обновить пользовательский интерфейс, указать на завершение воспроизведения
}
}
После этих манипуляций вам остается только отладить соответствующий сервис и пользоваться.
