
Хочется продолжить свою предыдущую тему об алгоритмах сжатия. В этот раз я расскажу об алгоритме LZW и немного об его родственниках алгоритмах LZ77 и LZ78.
Алгоритм LZW
Алгоритм Лемпеля — Зива — Велча (Lempel-Ziv-Welch, LZW) — это универсальный алгоритм сжатия данных без потерь.
Непосредственным предшественником LZW явился алгоритм LZ78, опубликованный Абрахамом Лемпелем(Abraham Lempel) и Якобом Зивом (Jacob Ziv) в 1978 г. Этот алгоритм воспринимался как математическая абстракция до 1984 г., когда Терри Уэлч (Terry A. Welch) опубликовал свою работу с модифицированным алгоритмом, получившим в дальнейшем название LZW (Lempel-Ziv-Welch).
Описание
Процесс сжатия выглядит следующим образом. Последовательно считываются символы входного потока и происходит проверка, существует ли в созданной таблице строк такая строка. Если такая строка существует, считывается следующий символ, а если строка не существует, в поток заносится код для предыдущей найденной строки, строка заносится в таблицу, а поиск начинается снова.
Например, если сжимают байтовые данные (текст), то строк в таблице окажется 256 (от «0» до «255»). Если используется 10-битный код, то под коды для строк остаются значения в диапазоне от 256 до 1023. Новые строки формируют таблицу последовательно, т. е. можно считать индекс строки ее кодом.
Алгоритму декодирования на входе требуется только закодированный текст, поскольку он может воссоздать соответствующую таблицу преобразования непосредственно по закодированному тексту. Алгоритм генерирует однозначно декодируемый код за счет того, что каждый раз, когда генерируется новый код, новая строка добавляется в таблицу строк. LZW постоянно проверяет, является ли строка уже известной, и, если так, выводит существующий код без генерации нового. Таким образом, каждая строка будет храниться в единственном экземпляре и иметь свой уникальный номер. Следовательно, при дешифровании при получении нового кода генерируется новая строка, а при получении уже известного, строка ивлекается из словаря.
Псевдокод алгоритма
- Инициализация словаря всеми возможными односимвольными фразами. Инициализация входной фразы ω первым символом сообщения.
- Считать очередной символ K из кодируемого сообщения.
- Если КОНЕЦ_СООБЩЕНИЯ, то выдать код для ω, иначе:
- Если фраза ω(K) уже есть в словаре, присвоить входной фразе значение ω(K) и перейти к Шагу 2, иначе выдать код ω, добавить ω(K) в словарь, присвоить входной фразе значение K и перейти к Шагу 2.
- Конец
Пример
Просто по псевдокоду понять работу алгоритма не очень легко, поэтому рассмотрим Рассмотрим пример сжатия и декодирования изображения.
Сначала создадим начальный словарь единичных символов. В стандартной кодировке ASCII имеется 256 различных символов, поэтому, для того, чтобы все они были корректно закодированы (если нам неизвестно, какие символы будут присутствовать в исходном файле, а какие — нет), начальный размер кода будет равен 8 битам. Если нам заранее известно, что в исходном файле будет меньшее количество различных символов, то вполне разумно уменьшить количество бит. Чтобы инициализировать таблицу, мы установим соответствие кода 0 соответствующему символу с битовым кодом 00000000, тогда 1 соответствует символу с кодом 00000001, и т.д., до кода 255. На самом деле мы указали, что каждый код от 0 до 255 является корневым.
Больше в таблице не будет других кодов, обладающих этим свойством.
По мере роста словаря, размер групп должен расти, с тем, чтобы учесть новые элементы. 8-битные группы дают 256 возможных комбинации бит, поэтому, когда в словаре появится 256-е слово, алгоритм должен перейти к 9-битным группам. При появлении 512-ого слова произойдет переход к 10-битным группам, что дает возможность запоминать уже 1024 слова и т.д.
В нашем примере алгоритму заранее известно о том, что будет использоваться всего 5 различных символов, следовательно, для их хранения будет использоваться минимальное количество бит, позволяющее нам их запомнить, то есть 3 ( 8 различных комбинаций ).
Кодирование
Пусть мы сжимаем последовательность «abacabadabacabae».
- Шаг 1: Тогда, согласно изложенному выше алгоритму, мы добавим к изначально пустой строке “a” и проверим, есть ли строка “a” в таблице. Поскольку мы при инициализации занесли в таблицу все строки из одного символа, то строка “a” есть в таблице.
- Шаг 2: Далее мы читаем следующий символ «b» из входного потока и проверяем, есть ли строка “ab” в таблице. Такой строки в таблице пока нет.
- Добавляем в таблицу <5> “ab”. В поток: <0>;
- Шаг 3: “ba” — нет. В таблицу: <6> “ba”. В поток: <1>;
- Шаг 4: “ac” — нет. В таблицу: <7> “ac”. В поток: <0>;
- Шаг 5: “ca” — нет. В таблицу: <8> “ca”. В поток: <2>;
- Шаг 6: “ab” — есть в таблице; “aba” — нет. В таблицу: <9> “aba”. В поток: <5>;
- Шаг 7: “ad” — нет. В таблицу: <10> “ad”. В поток: <0>;
- Шаг 8: “da” — нет. В таблицу: <11> “da”. В поток: <3>;
- Шаг 9: “aba” — есть в таблице; “abac” — нет. В таблицу: <12> “abac”. В поток: <9>;
- Шаг 10: “ca” — есть в таблице; “cab” — нет. В таблицу: <13> “cab”. В поток: <8>;
- Шаг 11: “ba” — есть в таблице; “bae” — нет. В таблицу: <14> “bae”. В поток: <6>;
- Шаг 12: И, наконец последняя строка “e”, за ней идет конец сообщения, поэтому мы просто выводим в поток <4>.
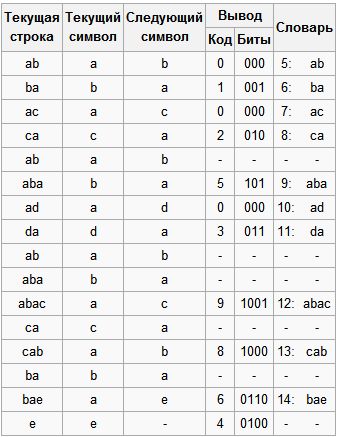
Итак, мы получаем закодированное сообщение «0 1 0 2 5 0 3 9 8 6 4», что на 11 бит короче.
Декодирование
Особенность LZW заключается в том, что для декомпрессии нам не надо сохранять таблицу строк в файл для распаковки. Алгоритм построен таким образом, что мы в состоянии восстановить таблицу строк, пользуясь только потоком кодов.
Теперь представим, что мы получили закодированное сообщение, приведённое выше, и нам нужно его декодировать. Прежде всего, нам нужно знать начальный словарь, а последующие записи словаря мы можем реконструировать уже на ходу, поскольку они являются просто конкатенацией предыдущих записей.

Дополнение
Для повышения степени сжатия изображений данным методом часто используется одна «хитрость» реализации этого алгоритма. Некоторые файлы, подвергаемые сжатию с помощью LZW, имеют часто встречающиеся цепочки одинаковых символов, например aaaaaa … или 30, 30, 30 … и т. п. Их непосредственное сжатие будет генерировать выходной код 0, 0, 5 и т.д. Спрашивается, можно ли в этом частном случае повысить степень сжатия?
Оказывается, это возможно, если оговорить некоторые действия:
Мы знаем, что для каждого кода надо добавлять в таблицу строку, состоящую из уже присутствующей там строки и символа, с которого начинается следующая строка в потоке.
- Итак, кодировщик заносит первую «а» в строку, ищет и находит «а» в словаре. Добавляет в строку следующую «а», находит, что «аа» нет в словаре. Тогда он добавляет запись <5>: «аа» в словарь и выводит метку <0> («а») в выходной поток.
- Далее строка инициализируется второй «а», то есть принимает вид «a?» вводится третья «а», строка вновь равна «аа», которая теперь имеется в словаре.
- Если появляется четвертая «а», то строка «aa?» равна «ааа», которой нет в словаре. Словарь пополняется этой строкой, а на выход идет метка <5> («aa»).
- После этого строка инициализируется третьей «а», и т.д. и т.п. Дальнейший процесс вполне ясен.
- В результате на выходе получаем последовательность 0, 5, 6 …, которая короче прямого кодирования стандартным методом LZW.
Можно показать, что такая последовательность будет корректно восстановлена. Декодировщик сначала читает первый код – это <0>, которому соответствует символ «a». Затем читает код <5>, но этого кода в его таблице нет. Но мы уже знаем, что такая ситуация возможна только в том случае, когда добавляемый символ равен первому символу только что считанной последовательности, то есть «a». Поэтому он добавит в свою таблицу строку «aa» с кодом <5>, а в выходной поток поместит «aa». И так может быть раскодирована вся цепочка кодов.
Мало того, описанное выше правило кодирования мы можем применять в общем случае не только к подряд идущим одинаковым символам, но и к последовательностям, у которых очередной добавляемый символ равен первому символу цепочки.
Достоинства и недостатки
+ Не требует вычисления вероятностей встречаемости символов или кодов.
+ Для декомпрессии не надо сохранять таблицу строк в файл для распаковки. Алгоритм построен таким образом, что мы в состоянии восстановить таблицу строк, пользуясь только потоком кодов.
+ Данный тип компрессии не вносит искажений в исходный графический файл, и подходит для сжатия растровых данных любого типа.
- Алгоритм не проводит анализ входных данных поэтому не оптимален.
Применение
Опубликование алгоритма LZW произвело большое впечатление на всех специалистов по сжатию информации. За этим последовало большое количество программ и приложений с различными вариантами этого метода.
Этот метод позволяет достичь одну из наилучших степеней сжатия среди других существующих методов сжатия графических данных, при полном отсутствии потерь или искажений в исходных файлах. В настоящее время испольуется в файлах формата TIFF, PDF, GIF, PostScript и других, а также отчасти во многих популярных программах сжатия данных (ZIP, ARJ, LHA).
Алгоритмы LZ77 и LZ78
LZ77 и LZ78 — алгоритмы сжатия без потерь, опубликованные в статьях Абрахама Лемпеля и Якоба Зива в 1977 и 1978 годах. Эти алгоритмы наиболее известны в семействе LZ*, которое включает в себя также LZW, LZSS, LZMA и другие алгоритмы. Оба алгоритма относятся к алгоритмам со словарным подходом. LZ77 использует, так называемое, «скользящее окно», что эквивалентно неявному использованию словарного подхода, впервые предложенного в LZ78.
Принцип работы LZ77
Основная идея алгоритма это замена повторного вхождения строки ссылкой на одну из предыдущих позиций вхождения. Для этого используют метод скользящего окна. Скользящее окно можно представить в виде динамической структуры данных, которая организована так, чтобы запоминать «сказанную» ранее информацию и предоставлять к ней доступ. Таким образом, сам процесс сжимающего кодирования согласно LZ77 напоминает написание программы, команды которой позволяют обращаться к элементам скользящего окна, и вместо значений сжимаемой последовательности вставлять ссылки на эти значения в скользящем окне. В стандартном алгоритме LZ77 совпадения строки кодируются парой:
- длина совпадения (match length)
- смещение (offset) или дистанция (distance)
Кодируемая пара трактуется именно как команда копирования символов из скользящего окна с определенной позиции, или дословно как: «Вернуться в словаре на значение смещения символов и скопировать значение длины символов, начиная с текущей позиции». Особенность данного алгоритма сжатия заключается в том, что использование кодируемой пары длина-смещение является не только приемлемым, но и эффективным в тех случаях, когда значение длины превышает значение смещения. Пример с командой копирования не совсем очевиден: «Вернуться на 1 символ назад в буфере и скопировать 7 символов, начиная с текущей позиции». Каким образом можно скопировать 7 символов из буфера, когда в настоящий момент в буфере находится только 1 символ? Однако следующая интерпретация кодирующей пары может прояснить ситуацию: каждые 7 последующих символов совпадают (эквивалентны) с 1 символом перед ними. Это означает, что каждый символ можно однозначно определить переместившись назад в буфере, даже если данный символ еще отсутствует в буфере на момент декодирования текущей пары длина-смещение.
Описание алгоритма
LZ77 использует скользящее по сообщению окно. Допустим, на текущей итерации окно зафиксировано. С правой стороны окна наращиваем подстроку, пока она есть в строке <скользящее окно + наращиваемая строка> и начинается в скользящем окне. Назовем наращиваемую строку буфером. После наращивания алгоритм выдает код состоящий из трех элементов:
- смещение в окне;
- длина буфера;
- последний символ буфера.
В конце итерации алгоритм сдвигает окно на длину равную длине буфера+1.
Пример kabababababz

Описание алгоритма LZ78
В отличие от LZ77, работающего с уже полученными данными, LZ78 ориентируется на данные, которые только будут получены (LZ78 не использует скользящее окно, он хранит словарь из уже просмотренных фраз). Алгоритм считывает символы сообщения до тех пор, пока накапливаемая подстрока входит целиком в одну из фраз словаря. Как только эта строка перестанет соответствовать хотя бы одной фразе словаря, алгоритм генерирует код, состоящий из индекса строки в словаре, которая до последнего введенного символа содержала входную строку, и символа, нарушившего совпадение. Затем в словарь добавляется введенная подстрока. Если словарь уже заполнен, то из него предварительно удаляют менее всех используемую в сравнениях фразу. Если в конце алгоритма мы не находим символ, нарушивший совпадения, то тогда мы выдаем код в виде (индекс строки в словаре без последнего символа, последний символ).
Пример kabababababz

