Comments 37
Вопрос, зачем округлять рандомные значения до 3 знаков после запятой? Сколько точек не бери, в пределе вычислится не π, а площадь некоей многоугольной фигуры.
Это не округление. Дело в том, что рандомизатор выдает только целые числа. Поэтому, чтобы избежать только целых значений Х и Y, я сделал 3 знака после запятой. Можно и больше знаков сделать. Просто не вижу в этом смысла пока.
«Округлять» нельзя — в этом то и смысл Монте-Карло. С помощью округления точки могут попасть лишь на пересечении линий, которые отстают друг от друга на растояние dx — которое в Вашем случае равно 0.001. А теперь представьте себе вырожденный случай, когда в квадрате не ~100000 таких пересечений, а например лишь 4 либо 9 — и станет понятно к чему приводит округление… Чем больше знаков после запятой — тем точнее результат — при условии, что генератор действительно случайный:)
Мы с Вами знаем, что любая программа использует совсем даже не случайный генератор. Поэтому я хочу заняться этой темой. Не посоветуете какой-нибудь хороший генератор псевдослучайных чисел?
34

Если вы работаете под линуксом, посмотрите на разницу между /dev/random и /dev/urandom, в любом случае потребуется «прогрев».
В Windows XP генератор псевдослучайный чисел мягко говоря безобразный, в Висте и 7ке лучше. Почитайте про CryptoAPI и, в частности, CryptGenRandom.
В Windows XP генератор псевдослучайный чисел мягко говоря безобразный, в Висте и 7ке лучше. Почитайте про CryptoAPI и, в частности, CryptGenRandom.
Так вот зачем Intel встраивает аппаратный генератор случайных чисел! Чтобы skobeltsyn смог точно вычислить площадь многоугольника близкого к дуге окружности. На самом деле подлинность случайности при выборе точек в данном алгоритме не важна.
есть хороший генератор на основе LPtau последовательностей
Не хватает колонок с погрешностями.
Согласен, но чем больше я беру радиус, тем меньше будет погрешность от округления. Заковыка в поиске оптимального размера фигур и количества точек. То есть, когда я беру радиус 100 точек, то число пи получается порядка 3.18… не слишком удачный результат. Но чем больше круг(от 1000 и более), тем точнее становится расчёт. Минус метода заключается в том, что я не контролирую точность из-за того, что генератор псевдослучайный.
это задача школьной программы. Зачем писать об этом на Хабре?
Задачка интересная. Почему бы её и не вспомнить?
Я полагаю, что вы бы могли рассказать не столько и не только о вычислении числа Пи, сколько о применении метода Монте-Карло для решения различных геометрических задач.
Я только начал заниматься этим вопросом. В перспективе вычисление этим методом диффузии веществ в микропористых средах. Решение геометрических задач методом Монте-Карло — это очень известная тема, о которой, считаю, можно не упоминать.
Решение геометрических задач методом Монте-Карло — это очень известная тема, о которой, считаю, можно не упоминать
А вот вычисление числа Пи — это тайные знания масонов, да?
Решение геометрических задач — это более-менее реальный способ применения метода Монте-Карло, в отличие от вычисления числа Пи (которое, по сути, лишь является примитивной иллюстрацией самого алгоритма).
Это и есть решение геометрической задачаи. Если разобраться повнимательнее в алгоритме вычисления пи, то можно сразу заметить, что тут вычисляется площадь круга методом Монте-Карло. И по идее она же должна делиться на площадь квадрата. Так что косяк в алгоритме детектед. И он и не в разрядности, и не в генераторе.
Простите, возможно я не совсем точно выразился. Я имел в виду то, что одно дело — «научить» хабраюзеров находить площадь круга, а другое — рассказать, как же методом Монте-Карло вычислять, например, многомерные интегралы или находить корни системы линейных алгебраических уравнений.
Вас же минусуют не только за, как вы выразились, «косяк в алгоритме», но и за то, что вы нас недооцениваете :).
Вас же минусуют не только за, как вы выразились, «косяк в алгоритме», но и за то, что вы нас недооцениваете :).
UFO just landed and posted this here
И всё ради этого?
Заодно приделал вихрь Мерсенна, который для метода Монте-Карло и создавался.
#include <boost/random/normal_distribution.hpp>
#include <boost/random/mersenne_twister.hpp>
bool inCircle(double x, double y) {
return x*x + y*y < 1;
}
double secretFunction(size_t n) {
boost::uniform_01<boost::mt19937> gen((boost::mt19937()));
size_t inside = 0;
for (size_t i = 0; i < n; i++)
inside += inCircle(gen(), gen());
return 4.0 * inside / n;
}Заодно приделал вихрь Мерсенна, который для метода Монте-Карло и создавался.
Скажите, а какая точность у вашей реализации алгоритма?
Как уже было сказано выше, никого не интересует таблица с полученными значениями, ибо рандом по определению. Я прогнал по 20 раз для каждого значения n от 1 до 20 миллионов (итого 400 замеров).
Наверняка я что-то накосячил со статистикой, но вот что получилось (все графики в зависимости от числа миллионов случайных точек):
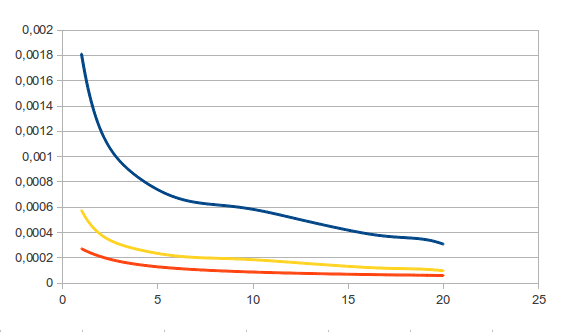
Синяя линяя — стандартное отклонение.
Желтая линия — стандартное отклонение / pi.
Красная линия — предполагаемое отклонение. Вот тут я мог напутать. По моим подсчётам это (4/pi-1)/sqrt(n). По другим источникам — 1/sqrt(n). Что общего в формулах — так это то, что погрешность от double-арифметики при N < 2^32 всегда будет всегда намного меньше погрешности метода Монте-Карло.
Наверняка я что-то накосячил со статистикой, но вот что получилось (все графики в зависимости от числа миллионов случайных точек):

Синяя линяя — стандартное отклонение.
Желтая линия — стандартное отклонение / pi.
Красная линия — предполагаемое отклонение. Вот тут я мог напутать. По моим подсчётам это (4/pi-1)/sqrt(n). По другим источникам — 1/sqrt(n). Что общего в формулах — так это то, что погрешность от double-арифметики при N < 2^32 всегда будет всегда намного меньше погрешности метода Монте-Карло.
Sign up to leave a comment.
Вычисление числа Пи методом Монте-Карло