Comments 83
Спасибо, действительно понравилось! Только вот задачку с игроками не смог решить(
Мне кажется что 2я SQL задача неправильно поставлена:
так как Stepan и Svetlana делят 1е место, Vladimir и Valentin 2е, а Ivan 3е.
Если я не прав тогда, объясните мне что надо выводить если у 3х игроков будет 10, например.
так как Stepan и Svetlana делят 1е место, Vladimir и Valentin 2е, а Ivan 3е.
Если я не прав тогда, объясните мне что надо выводить если у 3х игроков будет 10, например.
Обычно в турнирах по, например, шахматам, используют именно подход, описанный мной в условии. И да, это реализоваь сложнее, чем выбор игроков с третим максимальным количеством очков.
Если у троих будет 10, то они делят с первого по третье место. Соответственно, для выборки по третьему месту нужно выводить всех троих.
Да несложная задача, решу на MySQL:
select Name from `test` where score=(SELECT score FROM `test` ORDER BY Score desc limit 3,1)Да уж. Задача «посложнее» на поверку оказалась попроще :) А я-то спросонья, когда ее придумывал, написал решение, заджоинив таблицу саму на себя.
Кстати, такое же решение прислал мне на почту Алексей Масленников:
Кстати, такое же решение прислал мне на почту Алексей Масленников:
SELECT * FROM `players` WHERE Score = (SELECT Score FROM `players` ORDER BY Score DESC LIMIT 2,1)Как-то так можно…
with scores as(
select 1 id, 'Ivan' name, 8 score from dual union all
select 2, 'Stepan', 10 from dual union all
select 3, 'Irina', 3 from dual union all
select 4, 'Vasily', 7 from dual union all
select 5, 'Vladimir', 9 from dual union all
select 6, 'Svetlana', 10 from dual union all
select 7, 'Valentin', 9 from dual union all
select 8, 'Bla', 0 from dual
)
select name
, score
, dense_rank() over(order by score desc) as PLACE
from scores
order by score descStepan 10 1 Svetlana 10 1 Valentin 9 2 Vladimir 9 2 Ivan 8 3 Vasily 7 4 Irina 3 5 Bla 0 6
промахнулся, предназначалось для #namespace.
Sql #2:
pastebin.com/1mKnEUNg
pastebin.com/1mKnEUNg
Это решает чуть-чуть другую задачу. Я ответил по этому поводу предыдущему комментатору.
ага, вон как. Понял.
Тогда вот так (если опять с условием задачи не протупил):
select *
from (
select name, score
-- минимальное место в группе (по очкам)
, min(place) keep(dense_rank first order by PLACE) over(partition by score) min_place
-- максимальное место в группе (по очкам)
, max(place) keep(dense_rank last order by PLACE) over(partition by score) max_place
from (
select name
, score
-- пронумеровываем результаты
, row_number() over(order by score desc) as PLACE
from scores
)
)
-- желаемое место между минимальным и максимальным в группе
where 3 between min_place and max_placeПочему тогда уж сразу и не написать
HAVING (dense_rank() over(order by score desc)) = 3
?
Увы, сейчас доступа к какой-нибудь базе нет :)
HAVING (dense_rank() over(order by score desc)) = 3
?
Увы, сейчас доступа к какой-нибудь базе нет :)
А число разве не является своим подчислом? Равно как любое множество является своим подмножеством.
Если делать так, как у вас (не является), то вот решение первой задачи.
Если делать так, как у вас (не является), то вот решение первой задачи.
import Data.List
dividedBy :: Int -> String -> Bool
dividedBy _ [] = False
dividedBy n b = case read b of
0 -> False
x -> n `mod` x == 0 && n /= x
dividers :: Int -> Int
dividers n = length . filter (dividedBy n). subsequences . show $ n
круто, а я и забыл про subsequences. Можно было всё сократить ещё на две строчки
Может быть, так и правда было бы логичнее. В любом случае, на решение задачи это не сильно влияет :)
Поздравляю с первым решением! А что это, простите, за язык такой?
Поздравляю с первым решением! А что это, простите, за язык такой?
Haskell.
Для полной работоспособности следует добавить функцию main:
main = putStrLn. show. dividers $ 101
Для полной работоспособности следует добавить функцию main:
main = putStrLn. show. dividers $ 101
> А что это, простите, за язык такой?
Позор, не узнать Haskell. :P
Позор, не узнать Haskell. :P
Вместо едкостей лучше бы решение на Lisp предоставили, — я помню, вы за этот язык можете кого угодно съесть.
(Надо чаще читать почту)
> я помню, вы за этот язык можете кого угодно съесть.
Нет, я не фанатик, просто считаю его (Common Lisp, в остальных новомодных лиспах вроде Clojure есть пара новых идей, но вырезаны почти все хорошие старые) лучшим языком для большинства задач. :] Есть никого не планирую.
> Вместо едкостей лучше бы решение на Lisp предоставили
Слишком поздно открыл топик о много прочитал готовых решений. Теперь всё что приходит в голову — построчные их переводы.
Впрочем, кое-что продемонстрировать можно.
Например, компайлер-макросы, позволяющие определять для своих функций способы оптимизации их вызова. Здесь примитивный вариант, но идея, думаю, ясна: sprunge.us/igBi?cl
Как нетрудно убедиться в SBCL с помощью DISASSEMBLE, последние две строчки при включённых оптимизациях заменяются на результат (в маш. коде для subseqs и t1 будет список и число соответственно). sprunge.us/ZPUR
Если же передать аргументом не константу или выключить оптимизации, то будет вызываться функция. sprunge.us/HeeY
> я помню, вы за этот язык можете кого угодно съесть.
Нет, я не фанатик, просто считаю его (Common Lisp, в остальных новомодных лиспах вроде Clojure есть пара новых идей, но вырезаны почти все хорошие старые) лучшим языком для большинства задач. :] Есть никого не планирую.
> Вместо едкостей лучше бы решение на Lisp предоставили
Слишком поздно открыл топик о много прочитал готовых решений. Теперь всё что приходит в голову — построчные их переводы.
Впрочем, кое-что продемонстрировать можно.
Например, компайлер-макросы, позволяющие определять для своих функций способы оптимизации их вызова. Здесь примитивный вариант, но идея, думаю, ясна: sprunge.us/igBi?cl
Как нетрудно убедиться в SBCL с помощью DISASSEMBLE, последние две строчки при включённых оптимизациях заменяются на результат (в маш. коде для subseqs и t1 будет список и число соответственно). sprunge.us/ZPUR
Если же передать аргументом не константу или выключить оптимизации, то будет вызываться функция. sprunge.us/HeeY
Решение второй задачи:
Вызов calcAll выводит рейтинг для участников по порядку:
[4, 1, 2, 1]
import Data.List
treeData = [
"0110",
"0000",
"0001",
"0000"
]
employeeSubs = elemIndices '1'
employees = map employeeSubs treeData
calcEmpl d n = foldr (\x -> (+) (calcEmpl d x)) 1 (d !! n)
calcAll = map (calcEmpl employees) [0..(length employees) - 1]
Вызов calcAll выводит рейтинг для участников по порядку:
[4, 1, 2, 1]
Неверно, попробуйте на 1919 — ваша программа выдает 5, хотя на самом деле ответ 2.
PS. Такая ошибка тут у многих
PS. Такая ошибка тут у многих
Хм, возможно, я не совсем ясно написал условие. Но в данном случае ответ действительно 4 (или 5, в зависимости от того, учитывается ли делимость на само себя), т.к. 1919 нацело делится на 1, 1, 19 и 19.
А условии специально приведен пример, где показывается, что каждый из повторяющихся множителей считается.
А условии специально приведен пример, где показывается, что каждый из повторяющихся множителей считается.
А, я пропустил этот момент :) Тогда ок
Стыдно признавать, но таки вы правы — программа ошибочна! Правда, в другом. :) Если посмотреть, что выдает функция subsequences на число 1919, увидим нелицеприятное:
["",«1»,«9»,«19»,«1»,«11»,«91»,«191»,«9»,«19»,«99»,«199»,«19»,«119»,«919»,«1919»]
Поясню справкой по функции:
То есть имеем лишнюю «19», которая вместе с 1, 19, 1, 19 составляет 5 элементов. Если добавить еще число как подчисло себя, то получится 6.
Пока думаю, как это исправить. :)
["",«1»,«9»,«19»,«1»,«11»,«91»,«191»,«9»,«19»,«99»,«199»,«19»,«119»,«919»,«1919»]
Поясню справкой по функции:
The subsequences function returns the list of all subsequences of the argument.
subsequences «abc» == ["",«a»,«b»,«ab»,«c»,«ac»,«bc»,«abc»]
То есть имеем лишнюю «19», которая вместе с 1, 19, 1, 19 составляет 5 элементов. Если добавить еще число как подчисло себя, то получится 6.
Пока думаю, как это исправить. :)
А я как раз думал почему же 19 3 раза получилось в вашем примере (я заменял вывод длины списка на вывод самого списка) :)
Но все равно, автор топика говорит что по условию нужно считать повторки. Хотя subsequences все равно придется заменить.
Кстати, я тоже искал такую функцию для перебора всех подстрок в питоновском itertools, и там её не оказалось :(
Кстати, я тоже искал такую функцию для перебора всех подстрок в питоновском itertools, и там её не оказалось :(
решение первой в лоб. Тормозное, но надеюсь не слишком длинное
subsets [] = [[]]
subsets (x:xs) = subsets xs ++ (map (x:) (subsets xs))
calculate :: Int -> [Int]
calculate n = (filter ((==0).mod n).map head.group.sort.map read.tail.init.subsets.show) n
main = (print.length.calculate) 1938
Кстати, у вас ошибка:
на самом деле 1,3,19,38.
subsets [] = [[]]
subsets (x:xs) = subsets xs ++ (map (x:) (subsets xs))
calculate :: Int -> [Int]
calculate n = (filter ((==0).mod n).map head.group.sort.map read.tail.init.subsets.show) n
main = (print.length.calculate) 1938
Кстати, у вас ошибка:
Без остатка 1938 делится на четыре из этих подчисел: 1, 3, 13 и 38.
на самом деле 1,3,19,38.
Чуть чуть упростил, получился однострочничек. Причём только в виде комбинаций функций.
Использовать
btw, язык — хаскель
dividers = length.((.(filter (/=0).map read.tail.init.subsequences.show)) =<< filter.((0 ==).).mod)Использовать
import Data.List
import Control.Monad.Instances
dividers = length.((.(filter (/=0).map read.tail.init.subsequences.show)) =<< filter.((0 ==).).mod)
main = print.dividers $ 1938btw, язык — хаскель
Я плохо понимаю этот ваш последний вариант. Он на число 1919 выдает 5, — и это, вроде бы, правильный результат, если учитывается число как подчисло самого себя. Если не учитывать, то должно быть 4. Не пойму, как сделано у вас среди этого мозголомного однострочника. :)
Кстати, функция subsequences нам подложила свинью. См. мой прошлый комментарий. :)
Первый ваш вариант выдает 2 на 1919, что неверно.
В общем, если ваш второй вариант работает как надо (даже несмотря на свинью с subsequences), то в этом вы победили. :)
Кстати, функция subsequences нам подложила свинью. См. мой прошлый комментарий. :)
Первый ваш вариант выдает 2 на 1919, что неверно.
В общем, если ваш второй вариант работает как надо (даже несмотря на свинью с subsequences), то в этом вы победили. :)
Неа, мой варинат не верен. Только сейчас понял.
Дело в том, что subsequences не подходит для разбиения. Поскольку он строит множество всех подмножеств а нужно считать только включения.
то есть в подчислах 1938 нет числа 13, которе даст subsequences.
из-за этого в примере с 1919 число 19 вылезает 3 раза (первая еденица даст два числа, последняя давт ещё одно 19). такие дела.
Дело в том, что subsequences не подходит для разбиения. Поскольку он строит множество всех подмножеств а нужно считать только включения.
то есть в подчислах 1938 нет числа 13, которе даст subsequences.
из-за этого в примере с 1919 число 19 вылезает 3 раза (первая еденица даст два числа, последняя давт ещё одно 19). такие дела.
В итоге пришлось сделать перебором вручную. Хотя явно менее красивый вариант
dividers n = let d = (length.show) n
in length [ subNumer | a<-[1..d], b<-[0..a-1], a-b/=d, let subNumer = div (mod n (10^a)) (10^b), subNumer /= 0, mod n subNumer == 0]import Control.Applicative
import Control.Monad.Instances
import Data.List
solve = length.tail.((filter.((==0).).mod)<*>(filter (>0).map (read .('0':)).(>>= tails).inits.show))
main = readLn >>= print . solve
В условии первой задачи очепятка, не 13, а 19.
Решение в лоб (C#, LinqPad):
Решение в лоб (C#, LinqPad):
var n = 1938;
var s = n.ToString();
var l = s.Length;
Enumerable.Range(0, l)
.SelectMany(x => Enumerable.Range(1, l - x).Select(i => int.Parse(s.Substring(x, i))))
.Where(i => i != n && n%i == 0)
.Dump();
Вторая задача в лоб, C#, LinqPad
var src = new[] { «0110», «0000», «0001», «0000» };
Func<int, int> getRating = null;
getRating = index => src[index].OfType().Select((c, i) => c == '1'? getRating(i): 0).Sum() + 1;
src.Select((s, i) => getRating(i)).Sum().Dump();
var src = new[] { «0110», «0000», «0001», «0000» };
Func<int, int> getRating = null;
getRating = index => src[index].OfType().Select((c, i) => c == '1'? getRating(i): 0).Sum() + 1;
src.Select((s, i) => getRating(i)).Sum().Dump();
1 задание:
как я вижу никто не использует регулярные выражения для решения этой задачи, хе-хе, получайте:
смысл всего вышенаписанного на Великом Языке Программирования Perl:
в цикле for строка бьётся на субстроки регулярным выражением, причём, благодаря тому что нужное количество символов принудительно НЕ СОВПАДАЕТ, перебор идёт по несколько нужных символов не друг за другом, а со смещением в один символ
и в конце каждое полученное значение проверяется на основном числе и выводиться количество делителей на которые число делится без остатка
как я вижу никто не использует регулярные выражения для решения этой задачи, хе-хе, получайте:
#!/usr/bin/env perl
use common::sense;
use re 'eval';
my $n = 1938;
my @to_check;
for (1..length($n)-1) {
$n =~ /.{$_}(?{ push @to_check,$& })(*FAIL)/;
}
say scalar grep { $n % $_ == 0 } @to_check;смысл всего вышенаписанного на Великом Языке Программирования Perl:
в цикле for строка бьётся на субстроки регулярным выражением, причём, благодаря тому что нужное количество символов принудительно НЕ СОВПАДАЕТ, перебор идёт по несколько нужных символов не друг за другом, а со смещением в один символ
и в конце каждое полученное значение проверяется на основном числе и выводиться количество делителей на которые число делится без остатка
4 задание:
select distinct a.id,a.name,a.score
from players a
left join (select distinct score from players) b on (a.score<b.score)
group by a.id,a.name,a.score
having count(b.score)=2
order by a.score desc;
если одинаковый результат у N игроков считать за N мест, то даже проще:
select distinct a.id,a.name,a.score
from players a
left join players b on (a.score<b.score)
group by a.id,a.name,a.score
having count(b.score)=2
order by a.score desc;Это неплохо, но не работает, если у трех участников Score равен 10. Тогда они делят места с 1 по 3, а ваш запрос ничего не возвращает.
Можно посчитать для каждого участника наивысшее место (число результатов, больше чем у него + 1) и низшее место (число результатов «перед ним» + число результатов, равных его). На третье место попадают все, у кого число 3 между двумя этими значениями.
select a.id, a.name
from @players a
cross join @players b
group by a.id, a.name
having 3 between
sum(case when (b.Score > a.Score) then 1 else 0 end) + 1
-- минимальное место
and (sum(case when (b.Score > a.Score) then 1 else 0 end) +
sum(case when (b.Score = a.Score) then 1 else 0 end))
-- максимальное место
Кстати, задача №3
select a.Id, a.CategoryId, a.Name from Books a
left join Books b on b.Id = a.Id and b.CategoryId = 2
where a.CategoryId = 1 and b.Id is nullЗадачка №1 на python:
n = 1938
s = str(n)
r = set()
for a in range(len(s)):
for b in range(len(s)-a):
num = int(s[a:a+b+1])
if not n % num:
r.add(num)
print len® - 1Только хотел написать на питоне. У тебя, кстати, деление на нуль не отлавливается.
Задача #1.
Вот в две строки ответ:
Знаю что некрасиво, но я не мастер в извращениях.
Задача #1.
Вот в две строки ответ:
n = "1938"
print len([i for i in range(len(n)-1) for j in range(len(n)-i) if int(n[j:j+i+1]) and int(n)%int(n[j:j+i+1])==0])
Знаю что некрасиво, но я не мастер в извращениях.
Ваше решение работает :)
Между прочим, в редакцию поступило письмо от Виктора, начинающего пайтониста:
Помогите Виктору :)
Между прочим, в редакцию поступило письмо от Виктора, начинающего пайтониста:
В программировании я новичок, могут быть ляпы, писал решение первой задачи на Python 2.7:
l = [str(1938)[i] for i in range(len(str(1938)))] res = 0 def sr(): m = '' for n in range(len©): m += c[n] if m != '': return int(m) else: return 0.1 for j in range(len(l)): for i in range(len(l)): c = l[i:j+1] if l != c and 1938%sr() == 0: res += 1 print res
Был бы очень признателен, если бы Вы указали узкие места и ошибки в коде. Пытаюсь научиться программировать, начал с Python.
Помогите Виктору :)
От новичка — новичку:
habrahabr.ru/post/204476/
Это насчёт всех range(len(x)) и прочих узкостей. К примеру:
>>for n in range(len©):
>>> m += c[n]
Меняется на
for n in c:
m += n
И ещё — константы всегда легче вывести в отдельную переменную.
>>> for char in str(1984):
… print char
…
1
9
8
4
Внезапно, строка — это список символов, и нет нужды делать [str(1938)[i] for i in range(len(str(1938)))] ;-) Зачем создавать массив, если строка — это сам по себе массив символов?
Нет проверки на деление на ноль, печалька =(
Это не всё, думаю, но углубиться не хватит времени =(
habrahabr.ru/post/204476/
Это насчёт всех range(len(x)) и прочих узкостей. К примеру:
>>for n in range(len©):
>>> m += c[n]
Меняется на
for n in c:
m += n
И ещё — константы всегда легче вывести в отдельную переменную.
>>> for char in str(1984):
… print char
…
1
9
8
4
Внезапно, строка — это список символов, и нет нужды делать [str(1938)[i] for i in range(len(str(1938)))] ;-) Зачем создавать массив, если строка — это сам по себе массив символов?
Нет проверки на деление на ноль, печалька =(
Это не всё, думаю, но углубиться не хватит времени =(
У меня получилось на 5 символов меньше :-D
a = '1938'
print len([1 for k in range(len(a)) for l in range(k+1,len(a)+1) if int(a[k:l]) if int(a)%int(a[k:l])==0])-1
Второй алгоритм на APL с циклом (неизящный):
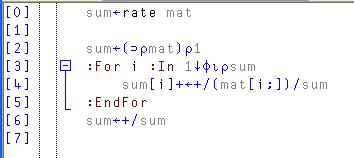
И его вывод:
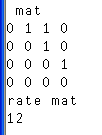

И его вывод:

Было бы совсем хорошо, если бы добавить к каждому заданию набор тестов.
Я тут что, первый рубист?
number = 1938.to_s
unpack_string = ""
number.length.times do |num|
unpack_string += "@#{num}aa*" unless num+1 == number.length
unpack_string += "@0a#{num}" unless num < 2
end
p (number.unpack(unpack_string) - ["0"]).find_all{|element|number.to_i%element.to_i==0}.count
Оригинальное решение 2-й SQL'ной задачи предложил хабрачитатель Юрий!
Если кто-нибудь захочет выслать ему инвайт, напишите мне личное сообщение.
SELECT GROUP_CONCAT(a.Name)
FROM players AS a
INNER JOIN players AS b
ON a.Score = b.Score
GROUP BY a.Score, b.Name
ORDER BY a.Score DESC
LIMIT 2,1;Если кто-нибудь захочет выслать ему инвайт, напишите мне личное сообщение.
Довольно оригинальное решение! Только как быть, если кроме имени надо будет вернуть другую информацию по игрокам?
Использовать еще одно отличное решение, предложенное хабрачитателем по имени Григорий Косьян :)
SELECT sg.name
FROM Players sg
INNER JOIN Players gr2
ON (sg.score <= gr2.score)
LEFT JOIN Players gr1
ON (sg.score < gr1.score)
GROUP BY sg.name
HAVING COUNT(DISTINCT gr1.name) < 3
AND 3 <= COUNT(DISTINCT gr2.name);В рамках ненормального программирования хабрачитатель Кирилл Зорин прислал решение первой алогритмической задачи на PL/SQL:
with
t as (select 1938 as num from dual),
tt as (select level lev, num from t connect by level <= length(to_char(num)))
select
count(
case when mod(t1.num, substr(to_char(t1.num), t1.lev, length(to_char(t1.num)) - t1.lev + 1 - t2.lev + 1)) = 0
then 1 end)
from
tt t1,
tt t2
where
t2.lev <= length(to_char(t1.num)) - t1.lev + 1
and substr(to_char(t1.num), t2.lev, length(to_char(t1.num)) - t1.lev + 1-t2.lev+1)!= t1.num
* This source code was highlighted with Source Code Highlighter.«T-SQL и не такое может!», — как бы отвечает хабрачитатель с ником Dr.Marazm.
declare @num as int, @i as int = 1, @j as int = 1
set @num = 1938
drop table #t
create table #t (a int)
while @i <= len(@num) begin
set @j = 1
while @j <= len(@num) begin
insert into #t (a)
select substring(cast(@num as varchar),@i,@j) a
set @j = @j + 1
end
set @i = @i + 1
end
select distinct *, @num % a from #t where @num % a = 0 and @num <> a
* This source code was highlighted with Source Code Highlighter.Наконец-то у меня есть учётка на Хабре и теперь я могу написать, что в моём решении нет никакого PL/SQL :)
MYSQL 2: SELECT group_concat(id, SEPARATOR ",") FROM players GROUP BY score ORDER BY score LIMIT 2,1
В случае с id, если нам нужны именно id игроков.
В случае с id, если нам нужны именно id игроков.
Алгоритмы. Задача №2, посложнее
Решение на javascript, не такое интересное, но работает во всех браузерах…
А вот если заюзить Array.prototype.reduce из ES5, то получается весьма интересно :) (работает в IE9, Chrome, Firefox, Opera)
Решение на javascript, не такое интересное, но работает во всех браузерах…
var data = [
"0110",
"0000",
"0001",
"0000"
];
function calc(row){
var res = 0;
return !!row.replace(/1/g, function(m, i){
res += calc(data[i]);
}) + res;
}
for (var i = 0, row, result = 0; row = data[i++];)
result += calc(row);
alert(result); // вывод результата, выдаст 8
А вот если заюзить Array.prototype.reduce из ES5, то получается весьма интересно :) (работает в IE9, Chrome, Firefox, Opera)
var data = [
"0110",
"0000",
"0001",
"0000"
];
alert(data.reduce(function calc(res, row){
return !!row.replace(/1/g, function(m, i){
res = calc(res, data[i]);
}) + res;
}, 0)); // выдаст 8
запутанное решение первой на PHP
function solve1($n)
{
$r = 0;
for ($i = $j = 0, $l = strlen($n); $i < $l; $i += ($j *= (++$j < $l — $i)) == 0)
if ($j+1 < $l && substr($n, $i, $j+1)) $r += (($n % substr($n, $i, $j+1))==0);
return $r;
}
function solve1($n)
{
$r = 0;
for ($i = $j = 0, $l = strlen($n); $i < $l; $i += ($j *= (++$j < $l — $i)) == 0)
if ($j+1 < $l && substr($n, $i, $j+1)) $r += (($n % substr($n, $i, $j+1))==0);
return $r;
}
Алгоритмы. Задача №1, разминочная
Решение на javascript. В целом, классическое решение, если опустить автоматическое приведение к типам.
Решение на javascript. В целом, классическое решение, если опустить автоматическое приведение к типам.
var num = String(1938);
var result = -1;
for (var e = num.length; e; e--)
for (var s = 0; s < e; s++)
result += num % num.substring(s, e) == 0;
alert(result);
1-я задача, рекурсивное решение.
<code class="python">n = 1938 r = lambda x, y: r(0, x) + r(x[1:], 0) if x else int(n % int(y) == 0 if int(y) else 0) + r(0, y[:-1]) if y else 0 print r(str(n), 0) - 1</code>
моя версия на php)
$num = 1938;
for($j=1; $j < strlen($num); $j++){
for($i=0; $i < strlen($num); $i++){
$array[] = substr($num,$i,$j);
}
}
$array = array_unique($array);
$count = 0;
foreach ($array as $value){
if(($num % $value) == 0){
$count++;
}
}
echo $count;
$num = 1938;
for($j=1; $j < strlen($num); $j++){
for($i=0; $i < strlen($num); $i++){
$array[] = substr($num,$i,$j);
}
}
$array = array_unique($array);
$count = 0;
foreach ($array as $value){
if(($num % $value) == 0){
$count++;
}
}
echo $count;
Более-менее стандартное, зато структурированное решение на C++ прислал хабрачитатель Евгений Дворянкин:
#include <iostream>
int GetRating(std::string *Data, int index)
{
int rate = 1;
for (int i =0; i<Data[index].size(); i++)
if(Data[index][i] == '1')
rate+=GetRating(Data, i);
return rate;
}
void main()
{
std::string srcData[]={"0110", "0000", "0001", "0000"};
int rate=0;
for(int i=0; i < (sizeof(srcData)/sizeof(srcData[0])) ; i++)
if(srcData[i]=="0000")
rate++;
else
rate+=GetRating(srcData,i);
std::cout << rate;
}А вот и рекурсивное решение на лиспе. Если точнее, на Racket.
Вызывать так:
(define (calc tbl)
(define (rating str)
(apply + 1
(map (λ (x) (rating (list-ref tbl (car x))))
(regexp-match-positions* "1" str))))
(apply + (map rating tbl)))
Вызывать так:
(calc '("0110" "0000" "0001" "0000"))
Sign up to leave a comment.
Праздничный биатлон