Comments 161
А вы пробовали ухо локтем чесать? Один знакомый заявил мне, что это возможно!)
Пробовал и вполне успешно!
Завидую, никогда не выходило ;-)
При должной гибкости и некоторой тренировке и не такое возможно. Правда практический смысл от этого такой же, как от этой статьи :)
На самом деле практический смысл есть. Мне иногда приходилось писать участки кода которые должны были выполнятся за строго определенное число тактов. Но вот засада — if если прямо, то 1 такт, а если направо то два. И выравнять порой сложно. Приходилось избавляться от if и делать «ветвление» хитрой математикой.
Ну вы же не сказали что надо чесать своё ухо своим же локтем :-)
Вы тоже попробовали это после прочтения комментария? ))
почесал…
Только что попробовал. Начальство удивленно покосилось, но все ок- получилось.
Нормальное исследование получилось. И вывод правильный, на мой взгляд.
Сколько человек сейчас попробовали почесать ухо локтем?
одна знакомая еще умеет бить пяткой в грудь. девочки не такое могут))
В Mathematica можно попробовать, примерный код:
теперь fact от отрицательных не будет срабатывать, все остальное считается, но это все же читерство, ведь есть ?Positive.
fact[0] := 1;
fact[n_?Positive] := n*fact[n - 1];теперь fact от отрицательных не будет срабатывать, все остальное считается, но это все же читерство, ведь есть ?Positive.
То, что:
f[0] :=
f[...] :=
f[...] :=
– это уже условные переходы.
f[0] :=
f[...] :=
f[...] :=
– это уже условные переходы.
Это вы тут видите условные переходы, а я вижу расширение определения функции на разные множества.
Это функциональный стиль задания, а не условные переходы.
Иными словами, мы задаем функцию на разных подмножествах области определения.
Тогда как в императивных языках if/else — именно условные переходы, так как связаны с порядком выполнения.
Так что логично ограничить условие задачи только императивными языками. Или потребовать отсутствия условных переходов уже в машинном коде.
Иными словами, мы задаем функцию на разных подмножествах области определения.
Тогда как в императивных языках if/else — именно условные переходы, так как связаны с порядком выполнения.
Так что логично ограничить условие задачи только императивными языками. Или потребовать отсутствия условных переходов уже в машинном коде.
Не совсем по теме, но немного похожие вещи:
If we had no if
If we had no proc
If we had no variables
If we had no if
If we had no proc
If we had no variables
Линейную программу, вычисляющую факториал, с использованием только логических и арифметических операций, написать невозможно. Для простоты положим, что в каждой строке может быть не более одной операции (ибо несколько операций можно легко разбить на несколько строк). Предположим также, что единственная изначально доступная константа — это «1» (любое другое число можно получить за конечное число строк).
Доказательство.
Пусть f(n, k) — самое большое число, вычислимое программой из k строк на входе n.
Лемма. Для любого k существует такое N_k, что f(n, k) <= n^(2^k) при всех n > N_k.
Доказательство (по индукции).
Для k = 1 — очевидно (разбор случаев: n*n, n*1, n+2, etc.).
Пусть доказано для k-1. Для k: после первых (k-1) строки в нашем распоряжении, по предположению индукции, есть число, не большее, чем n^(2^(k-1)) = x. Далее, опять разбор вариантов.
Поскольку n! растет быстрее, чем n^(2^k) для любого k, то, если наша программа состоит из K строк, при всех достаточно большин n она вычисляет число, меньшее n!..
Доказательство.
Пусть f(n, k) — самое большое число, вычислимое программой из k строк на входе n.
Лемма. Для любого k существует такое N_k, что f(n, k) <= n^(2^k) при всех n > N_k.
Доказательство (по индукции).
Для k = 1 — очевидно (разбор случаев: n*n, n*1, n+2, etc.).
Пусть доказано для k-1. Для k: после первых (k-1) строки в нашем распоряжении, по предположению индукции, есть число, не большее, чем n^(2^(k-1)) = x. Далее, опять разбор вариантов.
Поскольку n! растет быстрее, чем n^(2^k) для любого k, то, если наша программа состоит из K строк, при всех достаточно большин n она вычисляет число, меньшее n!..
Слишком уж сложно вы завернули :) Всё даже куда проще — для вычисления n! нужно O(n) операций, а в линейной программе число операций фиксировано. Заведомо найдётся число, для вычисления факториала которого потребуется больше, чем есть в программе. Вот если сказать, что n не превышает, скажем, 10, то ещё можно попробовать.
Если n не превышает C, то все просто:)
Например, если n может быть 1,2,3:
answer = (n-2)*(n-3)/(1-2)/(1-3)*1 + (n-1)*(n-3)/(2-1)/(2-3)*2 + (n-1)*(n-2)/(3-1)/(3-2)*6
А что для вычисления факториала необходимо O(n) операций — совсем неочевидно.
Например, если n может быть 1,2,3:
answer = (n-2)*(n-3)/(1-2)/(1-3)*1 + (n-1)*(n-3)/(2-1)/(2-3)*2 + (n-1)*(n-2)/(3-1)/(3-2)*6
А что для вычисления факториала необходимо O(n) операций — совсем неочевидно.
практически в любой задаче есть ограничения. Скажем, вычыслить n!.. 0<=n<=1000
поэтому в теории получается фиксированное количество операций. А если ограничений в задаче нету — тогда действительно невозможно
поэтому в теории получается фиксированное количество операций. А если ограничений в задаче нету — тогда действительно невозможно
Да легко. До этой вашей тысячи — по табличке, выше — по формуле Стирлинга, например. На больших аргументах она точна.
Относительная погрешность формули Стирлинга стремится к нулю. Абсолютная — к бесконечности.
Ну, во-первых, как уже здесь писали, абсолютная погрешность чисел Стирлинга стемится к бесконечности.
Во-вторых, я как раз к этому и веду, что при ограничениях можно как-то выкрутиться. Даже для тысячи, пускай не Вашим методом. А при их отсутствии всякие константы на размерность чего-либо теряют смысл.
Во-вторых, я как раз к этому и веду, что при ограничениях можно как-то выкрутиться. Даже для тысячи, пускай не Вашим методом. А при их отсутствии всякие константы на размерность чего-либо теряют смысл.
Упс… Я забыл про <<. С его помощью можно вычислить, например, 2^(n^2), что растет быстрее факториала.
Так что соображения по скорости роста не проходят.
Думаю, как доказать невыразимость факториала через арифметику, битовые операции и степень. Пока что не получается.
Так что соображения по скорости роста не проходят.
Думаю, как доказать невыразимость факториала через арифметику, битовые операции и степень. Пока что не получается.
В любом случае за конечное число шагов можно получить только конечное число. Для конкретной программы максимальное такое число можно оценить, а поскольку факториал — растущая функция, дело в шляпе. На самом деле без условий даже длинную арифметику реализовать не получится, куда уж тут факториалу.
Ну тогда и программу умножения двух чисел реализовать нельзя.
Предположим, что у нас не совсем компьютер фон Неймана, а нечто, больше похожее на RAM. То есть длинная арифметика дана «свыше».
Растущую функцию можно вычислить легко. Например, f(x) = x — растущая функция:)
Можно даже вычислить функцию, растущую быстрее факториала (см. выше).
Предположим, что у нас не совсем компьютер фон Неймана, а нечто, больше похожее на RAM. То есть длинная арифметика дана «свыше».
Растущую функцию можно вычислить легко. Например, f(x) = x — растущая функция:)
Можно даже вычислить функцию, растущую быстрее факториала (см. выше).
> Растущую функцию можно вычислить легко.
В оригинальном комменте предлагалось плясать от единицы. Я имел ввиду, что из неё сколь угодно большое число не построишь за конечное число операций.
В оригинальном комменте предлагалось плясать от единицы. Я имел ввиду, что из неё сколь угодно большое число не построишь за конечное число операций.
Оригинальный — это habrahabr.ru/blogs/crazydev/124878/#comment_4106402? В нем предлагалось плясать от единицы и входа.
Любую функцию. Потому что:
1) Внутри машины все является набором ноликов и единичек
2) Любоечисло набор бит можно отобразить в другое число другой набор бит с помощью арифметических и логический операций
3) Рекурсию-то никто не запрещал.
Вот вам ниже в доказательство пример сортировки массива без единной операции сравнения и без единного условного перехода:
habrahabr.ru/blogs/crazydev/124878/#comment_4111117
Могу, если сомневаетесь, «до кучи» еще запилить бинарный поиск без единного cmp/jcc.
P.S.: При всей кажущейся «бредовости» — автор статьи — просто молодец (сто плюсов ему в карму и тысячу счастливых лет жизни), побуждает пошевелить программистов давно неиспользованными извилинами в голове, не давая им заржаветь!
1) Внутри машины все является набором ноликов и единичек
2) Любое
3) Рекурсию-то никто не запрещал.
Вот вам ниже в доказательство пример сортировки массива без единной операции сравнения и без единного условного перехода:
habrahabr.ru/blogs/crazydev/124878/#comment_4111117
Могу, если сомневаетесь, «до кучи» еще запилить бинарный поиск без единного cmp/jcc.
P.S.: При всей кажущейся «бредовости» — автор статьи — просто молодец (сто плюсов ему в карму и тысячу счастливых лет жизни), побуждает пошевелить программистов давно неиспользованными извилинами в голове, не давая им заржаветь!
Если разрешена рекурсия с ленивыми вычислениями — то можно реализовать МТ и дальше вычислять что угодно. Как уже много раз говорилось в этом топике.
Мое рассуждение было для программ, выполняющихся последовательно — строки выполняются в том же порядке, в котором написаны, каждая — один и только один раз. Т.е. по сути вычисление по формуле.
Мое рассуждение было для программ, выполняющихся последовательно — строки выполняются в том же порядке, в котором написаны, каждая — один и только один раз. Т.е. по сути вычисление по формуле.
> Любой набор бит можно отобразить в другой набор бит с помощью арифметических и логический операций
Если вы имеете ввиду конечный набор бит, то да. Иначе, возникают вопросы вычислимости. Собственно, если ограничиться 32 битами, то функцию факториала (32 младших бита) можно вообще выписать аналитически без каких бы то ни было рекурсий.
Про реализацию ветвления через таблицу переходов и косвенную адресацию я понял. Собственно, это сродни тому, что я делал вначале (через хеш-таблицы), только выглядит уже не извращением, а практическим подходом.
Если вы имеете ввиду конечный набор бит, то да. Иначе, возникают вопросы вычислимости. Собственно, если ограничиться 32 битами, то функцию факториала (32 младших бита) можно вообще выписать аналитически без каких бы то ни было рекурсий.
Про реализацию ветвления через таблицу переходов и косвенную адресацию я понял. Собственно, это сродни тому, что я делал вначале (через хеш-таблицы), только выглядит уже не извращением, а практическим подходом.
Тогда, да, я неправильно рассуждал.
нет, я думаю для факториала решение
есть
поэтому некоторые класс таких задач уже можно решать подобным образом
есть
поэтому некоторые класс таких задач уже можно решать подобным образом
Это вы сейчас себя сами ограничили когда сказали «с использованием только логических и арифметических операций».
В этом топике рассматривалось существенно менее строгое ограничение: «без ветвлений».
А вот оно легко реализуется — условия заменяем на косвенную адресацию, циклы — на рекурсию.
В этом топике рассматривалось существенно менее строгое ограничение: «без ветвлений».
А вот оно легко реализуется — условия заменяем на косвенную адресацию, циклы — на рекурсию.
int fact(int n);
int fact1(int n)
{
return 1;
}
int factN(int n)
{
return fact(n - 1) * n;
}
typedef int (*fact_fn_t)(int);
fact_fn_t fact_fn[] = {fact1, factN};
int fact(int n)
{
int i = (bool)(n - 1);
return fact_fn[i](n);
}
int main(int argc, char* argv[])
{
cout << fact(5) << endl;
}def fac(n):
return not n or n * fac(n - 1)Эта программа нелинейна в том смысле, что выполнение идет непоследовательно (одна и та же строка может быть выполнена много раз).
Да, действительно, не обратил внимание на основное слово: «Линейно».
Зато это красиво )
Зато это красиво )
А еще это, если не ошибаюсь, не работает. Потому что это не С, и (not 0) — это True, а не 1. Так что 0! == True, при вычислении от больших аргументов — попытается умножить число на True, что вызовет исключение.
Если ошибаюсь — поправьте. Интерпретатора под рукой нет.
Если ошибаюсь — поправьте. Интерпретатора под рукой нет.
Да вроде всё ок:


Да, в питоне bool таки приводится к int при арифметических операциях. Жаль, я был о нем лучшего мнения…
А что в этом плохого? Мне кажется вполне логичным поведением и им часто пользуются для проверки переменной на равенство нулю и для проверки пустоты строки или списка и т.д.
А зачем для проверки пустоты приведение к int? «if l» вместо «if len(l) != 0» — действительно, писать удобно (хотя по мнению некоторых и непитонично). Но когда переменная будет то ли bool, то ли int — это ИМХО нехорошо.
А зачем для проверки пустоты приведение к int? «if l» вместо «if len(l) != 0» — действительно, писать удобно (хотя по мнению некоторых и непитонично).Оно и не приводится к int, оно приводится к логическому типу. К тому же, кроме «питоничности» и лучшей читаемости, вариант "
if l:" скорее всего ещё и быстрее.Но когда переменная будет то ли bool, то ли int — это ИМХО нехорошо.Добро пожаловать в язык с утиной типизацией ) Хотя вроде в любой момент понятно, какой тип имеет переменная и в чему он будет приведён: 0, "", [] — False, остальное — True
>Да, в питоне bool таки приводится к int при арифметических операциях
>А что в этом плохого? Мне кажется вполне логичным поведением
Да, быстрее. На треть примерно. Неприятно, честно говоря.
Конечно, переменная может в разное время иметь разный тип. Но мне кажется не слишком хорошим стилем то, что тип переменной в одном и том же месте зависит от того, что было раньше.
И приведение int к bool в условии — это одно. А конструкция вида True * 3 — это совсем другое.
>А что в этом плохого? Мне кажется вполне логичным поведением
Да, быстрее. На треть примерно. Неприятно, честно говоря.
Конечно, переменная может в разное время иметь разный тип. Но мне кажется не слишком хорошим стилем то, что тип переменной в одном и том же месте зависит от того, что было раньше.
И приведение int к bool в условии — это одно. А конструкция вида True * 3 — это совсем другое.
поскольку в реализации циклов условные операторы должны использоваться — то любую задачу, где количество итераций не константно, невозможно решить без условных операторов? (например тот же факториал)
Да, вы правы. Если не дать себе поблажку и не ограничить это число итераций сверху. Например, для всех чисел, больших 10 выводить «очень много».
Неа. Любой цикл можно превратить в рекурсию. Это особенно хорошо знают, например, xslt-кодеры, у которых циклов нет вообще. Так что от количества итераций не зависит никак. Остается только одна проблема — определить момент выхода, т.е. надо вернуть константу X, если текущий индекс = минимальному и Y в противном случае. Остатком от деления и простейшими арифметическими операциями это сделать не сложно.
Хм, а как вы собираетесь решать, входить или НЕ входить в рекурсию? Если программа линейна, то варианта только два: входить всегда или не входить никогда.
Ниже пример, когда рекурсивный вызов заменяется на одну из лямбд, либо продолжающую рекурсию, либо завершающую ее. Определение нужной лямбды осуществляется через арифметические операции и чтение из памяти по смещению (в данном случае массив).
int Rec(int n)
{
int a = -isPos(n);
return a&(n*Rec(n-1))+1-isPos(n);
}
isPos можно без ифов реализовать.
а так условных операторов вообще нету
да, действительно. можно использовать тот факт, что если
return (a&b);
и a равно нулю, то b не вычисляется. рекурсия спасает
return (a&b);
и a равно нулю, то b не вычисляется. рекурсия спасает
Запросто решается. Например, наспех сконструячил факториал на c# без условий.
ну если автор копал вглубь реализации встроенных хеш-таблиц, то Ваш код не подходит, так как все равно будет проверятся, чему равен индекс
Это обыкновенный массив, к которому обращение идет по числовому индексу. Никакой связи с хеш-таблицами нет. Кстати, и хеш-таблицы можно реализовать без условий. Исходя из того, что в основе своей хэш-таблицы — выборка из массива по индексу, полученном при помощи хэш-функции. Потом, правда, при наличии коллизий могут начать перебирать с условием, но всегда можно сделать второй хэш и т.п. А для строк можно вообще сделать ассоциативный словарь деревом и тоже будет без условий.
Насколько я понимаю, условный оператор скрыт в функции handlers. Где-то же должно решаться, брать из массива значение, или использовать x * Factorial(x — 1)?
да, я говорил об этом
Нет там никаких скрытых условных операторов. _handlers — это просто линейный массив функций. Скажем на ассемблере это могло бы выглядеть как «call [esi + смещение_в_массиве]». Здесь же не усматривается, что атомарная процессорная инструкция x86 «call» содержит завуалированную инструкцию «cmp» :)
А, прошу прощения, не разобрался с синтаксисом.
Безусловно, довольно остроумно. Но, мне кажется, в статье имелось в виду немного другое. «Нет инструкций, изменяющих направление программы» — это скорее значит, что команды выполняются в том же порядке, что и написаны. А у Вас все равно содержатся скачки.
Безусловно, довольно остроумно. Но, мне кажется, в статье имелось в виду немного другое. «Нет инструкций, изменяющих направление программы» — это скорее значит, что команды выполняются в том же порядке, что и написаны. А у Вас все равно содержатся скачки.
У меня осуществляется обыкновенный вызов функции. Но адрес функции определяется в зависимости от текущего состояния. В ассемблере я даже мог бы сделать совсем линейной, просто меняя смещения для JMP, которые скакали бы только вперед. Скажем так, убираем синтаксический сахар и возвращаемся к машине Тьюринга. Надеюсь ТС не хотел сказать, что мы отказываемся от возможностей машины Тьюринга ))
Программа для МТ целиком состоит из условных операторов:)
Поэтому, если мы хотим говорить о разрешимости задачи, ее надо уточнить. Если разрешить такого рода конструкции — то любую частично рекурсивную функцию можно вычислить таким образом — а значит, и любую вычислимую.
Поэтому, если мы хотим говорить о разрешимости задачи, ее надо уточнить. Если разрешить такого рода конструкции — то любую частично рекурсивную функцию можно вычислить таким образом — а значит, и любую вычислимую.
Переходы между состояниями в МТ можно делать с условиями, а можно и без :)
Опять же, если говорить процессорным языком, то МТ можно реализовать на ассемблере практически при помощи одних только MOV+JMP. Без CMP/JZ/JNZ и прочих условных переходов.
А вообще, все в итоге сводится к тому, что либо мы рассматриваем транзистор в CPU как условный оператор «если подан ток на базу, то...» :) Либо считаем, что любая задача может быть решена без применения условного оператора
Опять же, если говорить процессорным языком, то МТ можно реализовать на ассемблере практически при помощи одних только MOV+JMP. Без CMP/JZ/JNZ и прочих условных переходов.
А вообще, все в итоге сводится к тому, что либо мы рассматриваем транзистор в CPU как условный оператор «если подан ток на базу, то...» :) Либо считаем, что любая задача может быть решена без применения условного оператора
По определению, МТ задается множеством состояний, алфавитом и программой. Инструкции вида (состояние, символ) -> (состояние, символ, сдвиг) и есть условные операторы.
Но да, мы утыкаемся в вопрос, «что есть условные оператор».
Но да, мы утыкаемся в вопрос, «что есть условные оператор».
Определенно. И опять же, правила МТ можно рассматривать как условия «если состояние такое, а текущий символ эдакий, то...», а можно рассматривать как примитивную индексную операцию:
У меня не поворачивается язык сказать, что здесь использованы условные операторы :)
смещение_правила_в_таблице_правил = текущее_состояние*длина_алфавита + текущий_символ;
новое_состояние = правила[смещение_правила_в_таблице_правил][0];
новый_символ = правила[смещение_правила_в_таблице_правил][1];
движение = правила[смещение_правила_в_таблице_правил][2];
У меня не поворачивается язык сказать, что здесь использованы условные операторы :)
А у меня вполне поворачивается.
Я наконец придумал четкую формулировку.
То, что предлагает автор лучше называть не «вычислением без условных операторов», а «формулой».
Программа задает выход как некую функцию от входа. И автор приводит пример, когда эту функцию можно задать (бескванторной) формулой в арифметике. Факториал таким образом задать, по всей видимости, нельзя.
Я наконец придумал четкую формулировку.
То, что предлагает автор лучше называть не «вычислением без условных операторов», а «формулой».
Программа задает выход как некую функцию от входа. И автор приводит пример, когда эту функцию можно задать (бескванторной) формулой в арифметике. Факториал таким образом задать, по всей видимости, нельзя.
А можно еще и так.
Хм, даже самого заинтересовало. Вот не совсем честный, но красивый онлайнер на питоне:
Вообще, в питоне dict часто используется таким образом как альтернатива switch.
{"cake":"Yummy!!!"}.get(raw_input(), "The cake is a lie :(")Вообще, в питоне dict часто используется таким образом как альтернатива switch.
Да. самое главное забыл. Еще один онлайнер для Python 2.x:
print (lambda x:reduce(lambda x, y:x*y, [i for i in range(1, x)]))(raw_input()+1)
При нуле результат неправильный, но тогда код получается намного хуже =)
print (lambda x:reduce(lambda x, y:x*y, [i for i in range(1, x)]))(raw_input()+1)
При нуле результат неправильный, но тогда код получается намного хуже =)
<?php isCake(input) and print('Yummy, thanks!') or print('You are still lying to me!'); ?>так нельзя?
return «epic fail» в классе-родителе
return «win» в классе-потомке
чего тут может быть непонятного в такой реализации?..
return «win» в классе-потомке
чего тут может быть непонятного в такой реализации?..
Идея то безусловно прозрачна и ясна. А конкретную реализацию не предложите?
package ru.nullpointer.cake;
/**
*
* @author Alexander Yastrebov
*/
public class App {
public static void main(String[] args) throws Exception {
taste("pie");
taste("cake");
taste("cookie");
}
private static void taste(String s) {
Confectionery c = new Confectionery();
try {
s = Character.toUpperCase(s.charAt(0)) + s.substring(1);
Class clazz = Class.forName(App.class.getName() + "$" + s);
c = (Confectionery) clazz.newInstance();
} catch (Exception ex) {
}
c.taste();
}
static class Confectionery {
protected void taste() {
System.out.println("Not so tasty as I wish :(");
}
}
static class Cake extends Confectionery {
protected void taste() {
System.out.println("Mmm, very tasty!");
}
}
}
Имеет право на существование, хотя мне кажется, что это не совсем то на самом деле, так как в основном эта программа полагается скорее на механизм исключений. Если позволите, можно отбросить в вашем коде всё лишнее и написать просто
Идея с исключениями приходила мне в голову, но я её забраковал, как неуниверсальную. Да и это тоже в своём роде ветвление.
public class App {
public static void main(String[] args) {
taste("pie");
taste("cake");
taste("cookie");
}
private static void taste(String s) {
try {
s = Character.toUpperCase(s.charAt(0)) + s.substring(1);
Class.forName(App.class.getName() + "$" + s);
System.out.println("Mmm, very tasty!");
} catch (Exception ex) {
System.out.println("Not so tasty as I wish :(");
}
}
static class Cake { }
}
Идея с исключениями приходила мне в голову, но я её забраковал, как неуниверсальную. Да и это тоже в своём роде ветвление.
есть желающие отсортировать массив дробных чисел без условных операторов?
Один хрен все сводится к je или jne — а это уже условный переход, как не крути, без условий не написать программу на современной архитектуре.
Да нет, можно выжить и на jmp. Если нам надо передать управление адресу a, если x=0, и адресу b, если x=1, то можно засунуть a и b в массив c и делать jmp на адрес c[x]. Помнится, Кнут где-то даже рекомендует такую технику для оптимизации условных переходов.
Интересно, спасибо. Но все равно, если честно, не могу отделаться от ощущения что топик о том как заменить шило на мыло. Даже в приведенном вами примере мы эмулируем логику интегральной схемы (процессора) программно.
Осталось только заметить, что косвенный переход по адресу в таблице по сути условный переход (и вообще адресация памяти это выбор с условием):
если x равно 0, вернуть содержимое ячейки с номером 0
если x равно 1, вернуть содержимое ячейки с номером 1
и т.п.
если x равно 0, вернуть содержимое ячейки с номером 0
если x равно 1, вернуть содержимое ячейки с номером 1
и т.п.
Вот Пример, как можно сделать сортировку массива без применения cmp/jcc (вчера вечером развлекался после работы):
Как видно, все достаточно просто реализуется.
Другое дело, косвенные переходы «там где не надо» дают именно в данном конкретном случае неоправданный оверхед. (по скорости данная функция в своем таком виде я замерял примерно ~1.5 раза уступает квиксорту, в частности за счет этого неоправданного оверхеда а еще за счет неоптимизированной рекурсии (рекурсивно проще было сделать)).
Но во многих других случаях может получиться нехилый прирост к перфомансу за счет убраного бранчинга.
/* Вызов: extern void sort_array(uint32_t *arr,uint32_t N); */
.text
.globl sort_array
sort_array:
pushl %ebp
movl %esp, %ebp
pushl %edi
pushl %esi
pushl %ebx
pushl $31
pushl 12(%ebp)
pushl 8(%ebp)
call sort_array_asm_recursive
addl $12,%esp
popl %ebx
popl %esi
popl %edi
popl %ebp
ret
sort_array_asm_recursive:
movl 12(%esp),%ecx
movl 8(%esp),%eax
decl %eax
neg %eax
shrl $31,%eax
jmp *jump_tab3(,%eax,4)
go_sort_process:
movl 4(%esp),%ebx
xorl %eax,%eax
movl 8(%esp),%edx
decl %edx
go_sort_again:
movl %eax,%esi
subl %edx,%esi
shrl $31,%esi
jmp *jump_tab0(,%esi,4)
process_one:
movl (%ebx,%eax,4),%esi
shrl %cl,%esi
andl $1,%esi
shll $1,%esi
movl (%ebx,%edx,4),%edi
shrl %cl,%edi
andl $1,%edi
orl %edi,%esi
jmp *jump_tab1(,%esi,4)
sw_j0:
incl %eax
jmp go_sort_again
sw_j1:
incl %eax
decl %edx
jmp go_sort_again
sw_j2:
movl (%ebx,%eax,4),%esi
xchgl (%ebx,%edx,4),%esi
movl %esi,(%ebx,%eax,4)
incl %eax
decl %edx
jmp go_sort_again
sw_j3:
decl %edx
jmp go_sort_again
get_out_of_loop:
movl (%ebx,%eax,4),%esi
shrl %cl,%esi
andl $1,%esi
xorl $1,%esi
addl %esi,%eax
decl %ecx
movl %ecx,%esi
shrl $31,%esi
jmp *jump_tab2(,%esi,4)
recurs_go:
movl 8(%esp),%esi
subl %eax,%esi
leal (%ebx,%eax,4),%edi
pushl %ecx
pushl %esi
pushl %edi
pushl %ecx
pushl %eax
pushl %ebx
call sort_array_asm_recursive
addl $12,%esp
call sort_array_asm_recursive
addl $12,%esp
recurs_end:
ret
jmp recurs_end
.data
jump_tab0:
.long get_out_of_loop
.long process_one
jump_tab1:
.long sw_j0
.long sw_j1
.long sw_j2
.long sw_j3
jump_tab2:
.long recurs_go
.long recurs_end
jump_tab3:
.long recurs_end
.long go_sort_process
Как видно, все достаточно просто реализуется.
Другое дело, косвенные переходы «там где не надо» дают именно в данном конкретном случае неоправданный оверхед. (по скорости данная функция в своем таком виде я замерял примерно ~1.5 раза уступает квиксорту, в частности за счет этого неоправданного оверхеда а еще за счет неоптимизированной рекурсии (рекурсивно проще было сделать)).
Но во многих других случаях может получиться нехилый прирост к перфомансу за счет убраного бранчинга.
Ну, смотря что считать условными операторами. Например в массиве индексацию можно не считать условным оператором, поскольку при простой реализации она решается путем простых операций (в отличии от словарей)
И тогда можно использовать логику на массивах функций:
например тот-же факториал:
f[1] = \x, n -> f[n+1 / n] (x*n, n-1)
f[2] = \x, n -> print x
var k = read
f[1] (1,k)
И тогда можно использовать логику на массивах функций:
например тот-же факториал:
f[1] = \x, n -> f[n+1 / n] (x*n, n-1)
f[2] = \x, n -> print x
var k = read
f[1] (1,k)
Вообще, мне кажется, что функциональные языки могут обходиться без условных конструкций. А поскольку императивные и функциональные языки эквивалентны (в том смысле, что любую императивную программу можно заменить функциональной, и наоборот), то сразу можно сказать, что любую программу можно переписать без условных конструкций. И без while/for. И без изменяемых переменных.
И как они могут обходится без условных конструкций? Паттерн-матчинг не всесилен, а guards — это почти уже switch/case.
На самом деле в F# условные конструкции реализуются через паттерн-матчинг (см Expert F#, стр 38). Кроме того, if/then/else в F#--это выражение, в отличие от императивных языков (http://msdn.microsoft.com/en-us/library/dd233231.aspx).
паттерн-матчинг гораздо мощнее if-ов и всяких там switchcase-ов, что бы вы ни думали.
Все-таки паттерн-матчинг это тоже некая условная конструкция. А с возможностью написания без циклов и условных переменных я соглашусь.
Не претендую на оригинальность но
<?php
$word = 'cake';
$cake = 0;
$$word++;
$buff = array('The cake is a lie :(', 'Yummy!!!');
echo $buff[$cake];
В алгоритм не вьезжал (конец рабочего дня), но разве на уровне асма там не будет всяких сmp и jmp'ов? Как бы мы не писали высокоуровневый код, это самообман скорее всего :-)
А в языках с паттерн-матчингом паттерн-матчинг считается за условную конструкцию?
>>которая будет радоваться, если на вход ей подать, например, слово «печенька», и огорчаться в противном случае;
set_error_handler(function(){echo 'bad';die;});
$f = array(
'cake' => function(){echo 'good';}
);
//$input=trim(fread(fopen(«php://input», «r»), 10));
$input=$_GET['input'];
$f[$input]();
set_error_handler(function(){echo 'bad';die;});
$f = array(
'cake' => function(){echo 'good';}
);
//$input=trim(fread(fopen(«php://input», «r»), 10));
$input=$_GET['input'];
$f[$input]();
У меня только один вопрос — а зачем? В любом случае все библиотечные функции и классы реализованы с использованием условий, поэтому от них никак не уйти.
Тема интересная. Например, при выборе баннера в крутилке, используется несколько десятков сравнений (в худшем случае) для каждого баннера. В таком нагромождении условных операторов предсказатель ветвлений будет давать сбои, что приведёт к промахам при работе с кешом, что скажется на производительности… В общем, в этом смысл есть, но всё хорошо в меру…
для шейдеров в GLS именно, что надо без условных переходов и именно такие конструкции
факториал без условий, можно описать по формуле Стирлинга:
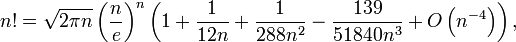
хотя наверняка при реализации корня или деления, или возведения в степень в библиотечных функциях будут использоваться условия. Но тем не менее можно и их заменить :))

хотя наверняка при реализации корня или деления, или возведения в степень в библиотечных функциях будут использоваться условия. Но тем не менее можно и их заменить :))
Можно попытаться «съесть» пирог из строки:
foreach (var trash in inString.Split(new[] {«cake»}, StringSplitOptions.RemoveEmptyEntries))
{
return «I can't eat that :(»;
}
return «Yummy!!!»;
хотя тут foreach — по сути if
foreach (var trash in inString.Split(new[] {«cake»}, StringSplitOptions.RemoveEmptyEntries))
{
return «I can't eat that :(»;
}
return «Yummy!!!»;
хотя тут foreach — по сути if
Доказано (Э. Дейкстра), что любая структура управления, а следовательно, и реализуемые алгоритмы, могут быть функционально эквивалентно представлены суперпозицией трех простых структур управления, имеющих один вход и один выход: последовательного выполнения, ветвления по условию и цикла с предусловием.
Так что, слишком долго обсуждаете.
Так что, слишком долго обсуждаете.
Забавно, много было решений на php, но так и не написали самое простое.
$word = "cake";
$results = array("The cake is a lie!", "Yummy!");
echo $results[$word];
Простите идиота.
Решение выше было верным) тоже с ассоциативным массивом и с обработкой ошибки) у меня хрень вышла, еще и накосячил)
Решение выше было верным) тоже с ассоциативным массивом и с обработкой ошибки) у меня хрень вышла, еще и накосячил)
Имеется ввиду вот это решение.
Способ № 482 на perl:
@yesno=('no', 'yes');
print $yesno[$ARGV[0]=~/cake/];
@yesno=('no', 'yes');
print $yesno[$ARGV[0]=~/cake/];
<?php
$emotions = array( $_GET['eat'] => ' :( '); // на что угодно переданное - плохая реакция
$emotions['cookie'] = 'thank you'; // а за печеньку спасибо
print $emotions[$_GET['eat']];
?>
Часто храню настройки скриптов в php массивах, в которых и узаю такие вот условия. На практике конечно юзаю if для проверки на существование элементов, в основном во избежании notice'ов.
тут было решение задачи сложения унарных чисел через цепи Маркова.
Видимо, и факториал можно.
Видимо, и факториал можно.
Вообще строго говоря в функциональном и логическом программировании нету if/else.
Для примера Пролог определение метапредиката if_then_else/3 без использования if (просто его нет в принципе нету :) ):
if_then_else(Condition, Then, Else) :- Condition, !, Then.
Для примера Пролог определение метапредиката if_then_else/3 без использования if (просто его нет в принципе нету :) ):
if_then_else(Condition, Then, Else) :- Condition, !, Then.
Превратить ненулевое число в 1 можно очень просто: (n | -n) >>> 31
Спасибо! Как говорится: век живи — век учись. Благодаря предоставленной Вами формуле, мне удалось немного реабилитироваться. Странно, что хабраобщество обошло вниманием столь полезный комментарий.
Кстати, у Вас небольшая опечатка — лишняя угловая скобка, но это сущие пустяки по сравнению с идеей.
Кстати, у Вас небольшая опечатка — лишняя угловая скобка, но это сущие пустяки по сравнению с идеей.
Превратить ненулевое 32-битное знаковое число в 1 можно предоставленым Вами способом
О, спасибо, запомню! Мне не удалось до такого додуматься.
А я прочитав заголовок думал что будет что-то о самомодификации кода, не угадал
Один знакомый заявил мне, что любая программа может быть написана без использования if/else.
Условие задачи не запрещает использовать операторы while и for. Поэтому извращаемся:
int res;
for( res = strcmp(input, "cake"); res == 0; )
{
puts("Yummy!!!");
// Здесь бы не помешал goto для избежания избыточной проверки,
// но раз уж объявили goto вредным - кушаем так.
break;
}
while( res != 0 )
{
puts("The cake is a lie :(");
break;
}
За такой код надо наказывать, но он без if/else.
На x86 ассемблере точно так же можно заменить cmp и jz/jnz на инструкцию loop. Пожалуй, это ещё больший изврат, чем вышеприведённый пример.
Более того:
System.out.println((char)(x*'s'));
^^ В библиотечных функциях никто так извращаться не будет. Посему без if/else программе не обойтись. Тут лишь можно поспорить на тему, является ли System.out частью программы или нет.
И наконец, даже на x86 ассемблере можно обойтись без cmp, jz/jnz. Я основательно забыл ассемблер, поэтому вместо кода предлагаю алгоритм.
0. Обнуляем регистр ebx
1. Устанавливаем esi на введённую строку
2. Устанавливаем edi на сравниваемый шаблон.
3. Загоняем в al код символа (для эстетов и любителей юникода ax или eax)
4. Вычитаем из al значение по адресу edi — соответственно изменяется флаг равенства и другие флаги.
5. Заносим регистр флагов в стек командой pushf
6. Берём значение из стека в регистр eax
7. Сдвигаем eax вправо, чтобы бит z попал в младший бит (я не помню, может быть он уже младший?)
8. Делаем «логическое И» регистра ax c единицей, чтобы сбросить все биты кроме младшего (после сдвига в него попал флаг z).
9. Инвертируем младший бит (нам нужно знать о несовпадении символов)
10. Делаем «логическое ИЛИ» с регистром ebx — в случае несовпадения в нём будет 1, иначе ноль.
11. Повторяем с шага 1 для каждого сравниваемого символа, но без цикла, чтобы не нарушить условие задачи. Иными словами — копипаста с шага 1.
12. В результате получаем в регистре ebx значение 0 при совпадении, или значение 1 при несовпадении.
13. Считаем разницу между переходом при совпадении строки и переходом при несовпадении.
14. Умножаем регистр ebx на разницу переходов, рассчитанную на предыдущем шаге.
15. Прибавляем к регистру ebx адрес перехода на ближайшую метку — в результате имеем адрес, соответствующий выполнению условия или адрес перехода при нарушении условия.
16. Я не помню, есть ли команда jmp [ebx], поэтому воспользуемся следующей последовательностью: push ebx; ret — кладём ebx на стек и «возвращаемся» на рассчитанный адрес.
Брр. ДА ВЕДЬ ЭТО ЖЕ ГНУСНОЕ ИЗВРАЩЕНИЕ! но без cmp и jz/jnz
упс. Простите, в пункте 11 копипаста с шага 3.
И ещё не помешает инкремент регистров esi и edi. Хотя, если склероз мне не изменяет, то можно писать и так:
mov al, [esi+1];
sub al, [edi+1]
и на каждой итерации ручками прописывать смещение относительно esi и edi. Ну это уже кто как привык.
И ещё не помешает инкремент регистров esi и edi. Хотя, если склероз мне не изменяет, то можно писать и так:
mov al, [esi+1];
sub al, [edi+1]
и на каждой итерации ручками прописывать смещение относительно esi и edi. Ну это уже кто как привык.
Хмм. Видать, люди не заценили «ассемблерный алгоритм». Что ж, признаю, что игра «pushf; pop ax» — не самый оптимальный вариант. apangin предложил гораздо более красивое решение.
Проверил этот пример в MSVC 2005 и gcc 4.1.2 — результат правильный.
Но что вы будете делать, если по условию надо ветвить код, а не подбирать строку?
Хотя… старые и добрые setjmp/longjmp никто не отменял. :)
#include "stdio.h"
static char * cake_message = "cake";
const char * match_message = "Yummy!!!";
const char * error_message = "The cake is a lie :(";
int test( char * str )
{
int result;
unsigned long * cake_ptr32, * arg_ptr32;
unsigned long diff;
char ch = str[4];
const char * result_message = match_message;
// Длина входящей строки не более 4-байт
result = (int) ((unsigned char) (str[4] | -str[4]) >> 7);
// Сравниваем слова как 32-х битные значения
cake_ptr32 = (unsigned long *) cake_message;
arg_ptr32 = (unsigned long *) str;
diff = *cake_ptr32 - *arg_ptr32;
result |= (int) (( diff | -diff ) >> 31);
result_message += result * (error_message - match_message);
puts(result_message);
return result;
}
int main(int argc, char * argv[])
{
test("on");
test("cake");
test("cakecake");
return 0;
}
* This source code was highlighted with Source Code Highlighter.Проверил этот пример в MSVC 2005 и gcc 4.1.2 — результат правильный.
Но что вы будете делать, если по условию надо ветвить код, а не подбирать строку?
Хотя… старые и добрые setjmp/longjmp никто не отменял. :)
Понаворатили решений одно красочней другого.
А между тем, задачка легко решается простейшей регуляркой :)
А между тем, задачка легко решается простейшей регуляркой :)
Мне кажется, для Java тут в самый раз подошло бы использование Reflection API.
Т.е., например, имеем классы Cake и Pie. Затем, получаем на вход слово и делаем как-то вот так:
try {
Class c = Class.forName(word);
…
} catch (Exception e) {
…
}
При использовании слов на русском языке, можно брать хэш (и нужным классам давать соотв. имена). Если допускаются пробелы и прочие спецсимволы — заменять их на подчеркивание. Ну или вообще использовать хэши в любом случае.
Т.е., например, имеем классы Cake и Pie. Затем, получаем на вход слово и делаем как-то вот так:
try {
Class c = Class.forName(word);
…
} catch (Exception e) {
…
}
При использовании слов на русском языке, можно брать хэш (и нужным классам давать соотв. имена). Если допускаются пробелы и прочие спецсимволы — заменять их на подчеркивание. Ну или вообще использовать хэши в любом случае.
Такое решение было предложено выше, см. habrahabr.ru/blogs/crazydev/124878/#comment_4106908
Да, пока завтракал, пришла в голову еще идея использовать enum'ы вот таким образом:
public enum Opts {
Cake {
@Override public String getResult() {
return «It's a cake!»;
}
},
Pie {
@Override public String getResult() {
return «It's a pie!»;
}
};
public abstract String getResult();
}
…
try {
String result = Opts.valueof(word).getResult();
}…
public enum Opts {
Cake {
@Override public String getResult() {
return «It's a cake!»;
}
},
Pie {
@Override public String getResult() {
return «It's a pie!»;
}
};
public abstract String getResult();
}
…
try {
String result = Opts.valueof(word).getResult();
}…
Наверно банально, я на Python так делаю ;))
x=3
y=4
result= x == y and x or 0
print result
возвращает 0 если x не равно Y и положительное число если равны
или как вариант
result= x == y and True or False
x=3
y=4
result= x == y and x or 0
print result
возвращает 0 если x не равно Y и положительное число если равны
или как вариант
result= x == y and True or False
Sign up to leave a comment.
Программирование без использования условных конструкций