Comments 43
На работе сейчас пишу как раз ресурсоемкие приложения под специфические процессоры, часто приходится комбинировать как параллельное вычисление независимых команд (например, мои процессоры поддерживают одновременно 1 логическую операцию, 1 арифметическую и 2 операции с памятью), так и режим SIMD…
К чему это я, не знаю :)
К чему это я, не знаю :)
А может напишете, если будет свободное время, статью про микрооптимизацию (лучне правда про не сильно специфичные, а, например, arm, atom, core)? Лично мне было бы интересно почитать.
Я думал об этом, но знаю очень мало — только умею и только для определённого процессора :) Саму теорию не изучал — параллельно учусь на оптика, программирование выросло из хобби, когда пришел на работу знал почти только самое общее про программирование на С — даже не С++, а дали список ассемблерных команд с описанием процессора и сказали — оптимизируй :)
Могу на примере описать процедуру оптимизации, но у меня тут либо скучные — вычитание одного кадра из другого, либо специфичные — фильтрация изображения (честно говоря, я плохо понимаю, что он делает, только как)
Могу на примере описать процедуру оптимизации, но у меня тут либо скучные — вычитание одного кадра из другого, либо специфичные — фильтрация изображения (честно говоря, я плохо понимаю, что он делает, только как)
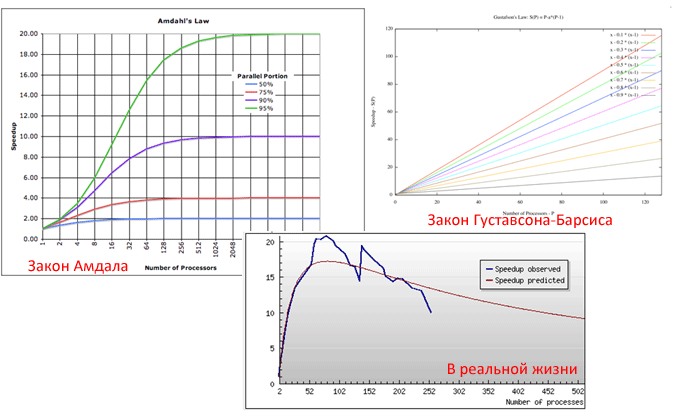
Самый быстрый в мире суперкомпьютер с тысячами процессоров и терабайтами памяти на нашей, вроде бы даже неплохо (75%!) параллелящейся задаче, меньше чем вдвое быстрее обычного настольного четырехядерника.
С этого места интересно по-подробнее.
По графику — 4-ядерник выполнит чуть более, чем в 2 раза данный код, суперкомпьютер — не более, чем в 4 раза, делим «чуть меньше 4» на «чуть больше 2», получаем меньше 2 :)
Но это для задачи, у которой 25% кода — последовательная :)
Но это для задачи, у которой 25% кода — последовательная :)
Принципиально однопоточный код увеличением количества процессоров/ядер ускорить нельзя. Никак, т.к. работает только одно ядро. Самый же быстрый на сегодняшний день суперкомп китайский Tianhe-1A построен на 14336 стандартных Intel Xeon и 7168 NVIDIA TESLA M2050. Тот же ксеон (один!) засовываем в настольный ящик, получаем практически такую же производительность (точнее — см. график)
А что это за задача, в которой последовательная часть составляет 25%? Ответ — сферическая задача в вакууме. Это я к тому, что на законе Амдала (1965 год) мир не остановился. Есть еще и законы Густавсона-Барсиса, метрика Карпа-Флатта и анализ изоэффективности (масштабируемости). Они дают другие, читай — оптимистичные оценки. И для многих задач — они более точно описывают ситуацию.
Эх, тема параллельных вычислений для меня не равнодушна… скоро будут 128, 256-ядерные процессоры… Нам нужно будет с ними что-то делать. Так что, спасибо, что подняли этот вопрос на Хабре!
Эх, тема параллельных вычислений для меня не равнодушна… скоро будут 128, 256-ядерные процессоры… Нам нужно будет с ними что-то делать. Так что, спасибо, что подняли этот вопрос на Хабре!
Да, но втиснуть их в обзор не получалось, потому ограничился Амдалом. Начальное понятие о принципиальных ограничениях он вполне дает.
Но вносит лишний пессимизм.
>Принципиально однопоточный код увеличением количества процессоров/ядер ускорить нельзя. Никак, т.к. работает только одно ядро.
Можно с помощью механизма предсказания вариантов.
Скажем:
Можно с помощью механизма предсказания вариантов.
Скажем:
Ну, про суперскалярность в статье есть.
Речь ведь шла по ускорению суперкомпа по сравнению с настольным жужжащим ящиком.
Там и там одни и те же суперскалярные процессоры, так что все-таки ускорить не получится.
Речь ведь шла по ускорению суперкомпа по сравнению с настольным жужжащим ящиком.
Там и там одни и те же суперскалярные процессоры, так что все-таки ускорить не получится.
Случайно отправилось предыдущее, прошу не обращать внимания.
Если под однопоточным кодом имеется ввиду тот, к которому не применим механизм предсказания ветвлений, то конечно его ускорить невозможно.
Если под однопоточным кодом имеется ввиду тот, к которому не применим механизм предсказания ветвлений, то конечно его ускорить невозможно.
Спасибо, было интересно почитать. Получается, в итоге все равно все упирается в скорость выполнения последовательного кода. 9 женщин за 1 месяц ребенка не родят :)
На самом деле, суперкомпьютеры не предназначены для решения маленьких задач, а с увеличением объемов данных последовательная часть как правило понижается. Таким образом можно добиться очень высокой эффективности. Так что суперкомпьютер — инструмент, и целесообразность его использования определяется для каждой конкретной задачи.
Статья написана сумбурно, желая покрыть сразу все, толком ни один аспект не описан как следует.
Статья написана сумбурно, желая покрыть сразу все, толком ни один аспект не описан как следует.
Насчет больших задач я в статье прямо написал
«Во многих алгоритмах время исполнения параллельного кода сильно зависит от количества обрабатываемых данных, а время исполнения последовательного кода — нет.
Потому «загоняя» на суперкомп большие объемы данных получаем хорошее ускорение.
Например перемножая матрицы 3*3 на суперкомпьютере мы вряд ли заметим разницу с обычным однопроцессорным вариантом, а вот умножение матриц, размером 1000*1000 уже будет вполне оправдано на многоядерной машине.»
«Статья написана сумбурно, желая покрыть сразу все, толком ни один аспект не описан как следует.»
Ну, здесь на каждый аспект можно написать отдельную статью и не одну. Полных обзоров я на русском языке не видел. Мне интересно было как раз сделать общий текст, чтоб видна была связь, эволюция и ограничения технологий и было бы возможно копать глубже там, где конкретно нужно.
«Во многих алгоритмах время исполнения параллельного кода сильно зависит от количества обрабатываемых данных, а время исполнения последовательного кода — нет.
Потому «загоняя» на суперкомп большие объемы данных получаем хорошее ускорение.
Например перемножая матрицы 3*3 на суперкомпьютере мы вряд ли заметим разницу с обычным однопроцессорным вариантом, а вот умножение матриц, размером 1000*1000 уже будет вполне оправдано на многоядерной машине.»
«Статья написана сумбурно, желая покрыть сразу все, толком ни один аспект не описан как следует.»
Ну, здесь на каждый аспект можно написать отдельную статью и не одну. Полных обзоров я на русском языке не видел. Мне интересно было как раз сделать общий текст, чтоб видна была связь, эволюция и ограничения технологий и было бы возможно копать глубже там, где конкретно нужно.
зато 81 женщины смогут за 9 месяцев родить 81 ребёнка… Что значит в среднем и значит «9 женщин 1 ребёнка за месяц».
В этом-то и смысл параллельных вычислений.
В этом-то и смысл параллельных вычислений.
> 3) Сложность, приводящая к принципиальной ненадежности
С точностью до наоборот. Во-первых, мультикомпьютеры проще, а не сложнее (да, состоят из большого числа частей, но более простых, чем в больших мультипроцессорах). Отказоустойчивость мультикомпьютеров обеспечить намного проще и дешевле (так как не нужно специального оборудования: отказал узел, ну и ничего, задачи на него больше пакетная система не назначает).
С точностью до наоборот. Во-первых, мультикомпьютеры проще, а не сложнее (да, состоят из большого числа частей, но более простых, чем в больших мультипроцессорах). Отказоустойчивость мультикомпьютеров обеспечить намного проще и дешевле (так как не нужно специального оборудования: отказал узел, ну и ничего, задачи на него больше пакетная система не назначает).
UFO just landed and posted this here
Все зависит, конечно, от свойств конкретной задачи. Но я бы грубо оценил ожидаемое ускорение от 10 до 30 раз. Причем, чем больше задача — тем больше и ускорение. В этом прелесть параллельных вычислений!
Сильно зависит еще от объема обрабатываемых данных и от возможности распараллелить по данным.
Можно посмотреть мою первую статью по OpenCL habrahabr.ru/blogs/hi/116579/ там я постарался про подводные камни написать.
Можно посмотреть мою первую статью по OpenCL habrahabr.ru/blogs/hi/116579/ там я постарался про подводные камни написать.
От GPU зависит. У нас на HD4850 в 11 раз быстрее, чем на четырёхядерном Athlon II X4.
Вообще-то предел по частоте наверняка еще не выбран. При обычном уменьшении техпроцесса AMD уже подобралась к номиналу 3,7 ГГц — отсюда рукой подать до 4,0, которые не удалось взять в 2004 «кукурузе». Intel тоже не месте не сидит. Продолжаются также исследования новых материалов, архитектур и т. д. для обхода этих проблем в чуть более отдаленной перспективе, имеются одиночные прототипы на сотни ГГц, так что хоронить этот параметр явно рановато. Другое дело темпы, с которыми это все развивается. Если уже сейчас можно тупо умножать ядра на проце, процы в машине, машины в сети и сети в мире — то для получения максимального результата разумно будет задействовать все эти направления, т. е. параллелизм на уровне компиляции, программирования, архитектуры приложений, диверсификацию железа, затронутую в данной статье на примере видеокарт, а также и распределенные вычисления, которые затронуты не были, но тоже являются перспективной темой для подобных задач. Наверняка существуют или появятся еще задачи (кроме привычной графики, физики, звука — возможно, что-нибудь из биоинформатики, что обозначится по мере ее дальнейшего развития), для которых оптимально будет проектировать специализированные процессоры в железе. Скорее всего, такой подход будет все шире применяться при приближении к молекулярным масштабам с заменой кремния на что-то другое. Если посмотреть еще дальше и сравнить вычислительную систему с самым продвинутым ее природным аналогом — человеческим мозгом — необходимо будет обеспечить будущие процессоры или их составляющие возможностью динамически настраивать соединения между собой в зависимости от задачи. Перспективы квантовых компьютеров и всяческие теоретические спекуляции пока оставим за бортом:).
Да, ждем графеновых или молибденитовых процессоров. Если получится, будет чуть проще, но все равно сложность уже не уменьшится т.к. выкидывать на помойку уже разработанные параллельные архитектуры никто не будет.
Просто процессоры в них заменят.
Просто процессоры в них заменят.
Насколько я помню, теоретический предел вообще — 10 ГГц, на практике до 6 ГГц разгоняли вроде.
Гораздо интереснее смотреть на другие типы процессоров — оптические те же, правда они как-то неуверенно исследуются…
Гораздо интереснее смотреть на другие типы процессоров — оптические те же, правда они как-то неуверенно исследуются…
Я еще про ПЛИС не писал, там тоже интересно очень, но слишком мало знаю, чтоб делиться.
Как курсовую сдам и если кармы хватит — напишу, я ими в НИВЦе МГУ занимаюсь.
На ПАВТ был интересный доклад про ПЛИС. Человек из Алмаз-Антей рассказывал, на таких схемах собрана логика нашего ПВО (С300 и компания)
Да, разработчики вот этой железки, которая стоит у нас, с удовольствием говорили, что «про большинство мы рассказать не можем, потому что воякам делали».
На самом деле, технологии позволяют уже сейчас 6 гигагерц получать на воздухе. У P4 некоторые блоки на такой частоте работали. Проблема только в том: а на кой они нужны? Сейчас основная проблема и бутылочное горлышко — это скорость доступа к памяти: ну будет процессор на своих 6 гигагерцах очень эффектно простаивать в ожидании данных, ну и кому оно такое надо, если вместо этого можно снизить энергопотребление?
Тупо умножать ядра на процессоре тоже нельзя. Опять же та же самая проблема: перегруженность шин данных.
То есть, основная польза от мультикомпьютеров — это как раз увеличение сумарной пропускной способности к функциональным блокам.
Тупо умножать ядра на процессоре тоже нельзя. Опять же та же самая проблема: перегруженность шин данных.
То есть, основная польза от мультикомпьютеров — это как раз увеличение сумарной пропускной способности к функциональным блокам.
Но тогда как работают те же 4 ядерные процессоры? Они обмениваются данными с памятью вчетверо сильнее, чем одноядерный той же частоты, который, по вашим данным, простаивает.
Да, начиная с пары четырехъядерных приходится городить NUMA, но до этого предела скорости памяти пока еще хватает.
Соответственно, для 6 гигагерцового одноядерника точно должно хватить.
Да, начиная с пары четырехъядерных приходится городить NUMA, но до этого предела скорости памяти пока еще хватает.
Соответственно, для 6 гигагерцового одноядерника точно должно хватить.
С чего это вдруг вчетверо сильнее? И в чём измеряется эта сила? Если речь о скорости, то Вы не правы. Четырёхкратное ускорение можно получить, если данные укладываются в кэши ядер, но при работе с большими массивами данных такого поведения кода добиться зачастую невозможно. Поэтому начинаются конфликты доступа к контроллерам памяти или к кэшу L3. И четырёхядерник, в среднем, эффективнее одноядерника той же архитектуры где-то в 2.5 раза.
Так что, пропускной способности памяти не хватает. Но проблема вот ещё в чём, когда работает 4 потока, то они могут более плотно загружать каналы доступа к памяти в сравнении с тем, когда работает один 6GHz процессор. У него сценарий будет примерно такой: хопа, надо посчитать вот эти данные, ок, щаз как посчитаю, ррРрррРРр(ждём данные из памяти)ррРРРрРрр(дождался)аз(посчитал), о, блин, теперь я знаю, что надо считать вот это, щаз посчитаю, рррРРррРРрРРрраз. То есть, зависимости по данным не позволяют одновременно много запросов посылать в контроллеры памяти. Поэтому такой процессор и будет долго простаивать. При чём, что на параллельных нагрузках, что на последовательных — без разницы. Поэтому, как бы, многоядерники тут выглядят лучше, они лучше загружают контроллеры памяти, простаивают меньше, и, как итог, работают энергоэффективнее, что важно.
Так что, пропускной способности памяти не хватает. Но проблема вот ещё в чём, когда работает 4 потока, то они могут более плотно загружать каналы доступа к памяти в сравнении с тем, когда работает один 6GHz процессор. У него сценарий будет примерно такой: хопа, надо посчитать вот эти данные, ок, щаз как посчитаю, ррРрррРРр(ждём данные из памяти)ррРРРрРрр(дождался)аз(посчитал), о, блин, теперь я знаю, что надо считать вот это, щаз посчитаю, рррРРррРРрРРрраз. То есть, зависимости по данным не позволяют одновременно много запросов посылать в контроллеры памяти. Поэтому такой процессор и будет долго простаивать. При чём, что на параллельных нагрузках, что на последовательных — без разницы. Поэтому, как бы, многоядерники тут выглядят лучше, они лучше загружают контроллеры памяти, простаивают меньше, и, как итог, работают энергоэффективнее, что важно.
По поводу GPGPU:
технология сильно совершенствуется, и сейчас нет больших проблем ускорить код который имеет большое количество ветвлений, а трансфер из памяти в видеопамять работает со скоростью прямого доступа к оперативной памяти (как более медленной). Вот как раз сегодня на тему написал:
habrahabr.ru/blogs/hi/119435/
технология сильно совершенствуется, и сейчас нет больших проблем ускорить код который имеет большое количество ветвлений, а трансфер из памяти в видеопамять работает со скоростью прямого доступа к оперативной памяти (как более медленной). Вот как раз сегодня на тему написал:
habrahabr.ru/blogs/hi/119435/
Насчет ветвлений очень спорный вопрос. У меня были совсем другие результаты на Fermi gts 450.
Но остальные аспекты очень интересны, спасибо за ссылку.
Но остальные аспекты очень интересны, спасибо за ссылку.
У Вас там слишком примитивные ветвления, которые очень хорошо укладываются в предикаты к инструкциям. Вот если бы там были блоки инструкций по 20, и если бы ещё вложенные ветвления, то вот где бы радость началась — таков опыт из реальной жизни на Fermi.
Есть еще эффект «пилы»: когда при использовании четного числа процессоров задача выполняется немного быстрее, чем если процессоров на 1 больше.
Sign up to leave a comment.
Высокопроизводительные вычисления: проблемы и решения