Microsoft Research опубликовало научную работу и видео, показывающие как работает алгоритм отслеживания тела в Kinect — это почти также изумительно, как и некоторые уже найденные ему применения.
Прорыв Kinect-у обеспечивают несколько составляющих. Его железо хорошо продумано и выполняет свои функции за приемлемую цену. Однако после того, как пройдет изумление от быстро измеряющего глубину железа, внимание неизбежно привлекает способ, которым он (Kinect) отслеживает тело человека. В данном случае героем выступает довольно классическая методика распознавания образов, но реализованная с изяществом.
Устройства, отслеживающие положение тела, уже были и ранее; но их большой проблемой является необходимость для пользователя становиться в эталонную позу, в которой алгоритм опознает его с помощью простого сопоставления. После этого используется следящий алгоритм, следующий за движениями тела. Основная идея: если у нас на первом кадре есть область, идентифицированная как рука, то на следующем кадре эта рука не может передвинуться очень далеко, и значит мы просто пытаемся идентифицировать близлежащие области.
Следящие алгоритмы хороши в теории, но на практике они дают сбои, если положение тела по какой-то причине потеряно; и совсем уж плохо они справляются с другими объектами, загораживающими отслеживаемого человека, даже на короткое время. Кроме того, отслеживание нескольких человек затруднено; и при такой «потере следа» восстановить его удается спустя довольно длительное время, если вообще удается.
Итак, что же ребята из Microsoft Research сделали с этой проблемой, что Kinect работает намного лучше?
Они вернулись к исходным принципам и решили построить систему распознавания тела, которая не зависит от слежения, а находит части тела, основываясь на локальном анализе каждого пиксела. Традиционное распознавание образов работает с помощью принимающей решения структуры, обученной на множестве образцов. Чтобы она работала, вы обычно предоставляете классификатор с большим количеством значений признаков, которые, как вы полагаете, содержат информацию, необходимую, для распознавания объекта. Во многих случаях задача выбора информативных признаков и есть самая сложная задача.
Признаки, которые были выбраны, могут удивить, так как они просты и далеко не очевидны в смысле информативности для идентификации частей тела. Все признаки получаются из простой формулы
f = d( x + u/d(x) ) — d( x + v/d(x) )
где u,v — пара векторов смещения, а d(x) — глубина пиксела, то есть расстояние от Kinect до точки, проецирующейся на x. Это весьма простой признак, по сути это просто разница в глубине двух пикселов, смещенных относительно исходного на u и v. (Варьируя u и v, получаем набор признаков. В самой работе (ссылка внизу) все гораздо понятнее. — Прим. перев.)
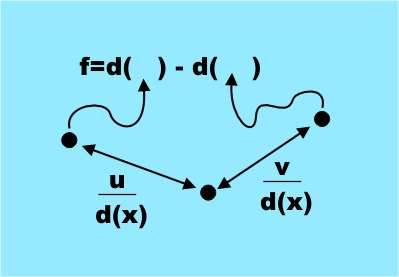
Единственное усложнение в том, что смещение нормировано глубиной исходного пиксела, то есть поделено на d(x). Это делает смещения независимыми от глубины и соотносит их с видимыми размерами тела.
Ясно, что эти признаки измеряют нечто, связанное с трехмерной формой области вокруг пиксела; но вот достаточно ли их, чтобы отличить, скажем, ногу от руки — это уже другой вопрос.
Следующий этап, выполненный командой — это обучение разновидности классификатора, называемого «лесом решений», то есть набора деревьев решений. Каждое дерево обучалось на наборе признаков на глубинных изображениях, которые заранее были привязаны к соответствующим частям тела. То есть деревья перестраивались до тех пор, пока они не стали выдавать правильную классификацию для определенной части тела на тестовом наборе изображений. Обучение лишь трех деревьев на 1 млн. изображений на 1000-ядерном кластере занимало около суток.
Обученные классификаторы выдают вероятность принадлежности пиксела к той или иной части тела; и следующая стадия алгоритма просто выбирает области с максимальной вероятностью для частей каждого типа. К примеру, область будет отнесена к категории 'нога', если «ножной» классификатор выдал максимум вероятности в этой области. Финальная стадия — это вычисление предполагаемого местоположения суставов относительно областей, опознанных как определенные части тела. На этой диаграмме максимумы вероятностей для различных частей тела обозначены цветными областями:
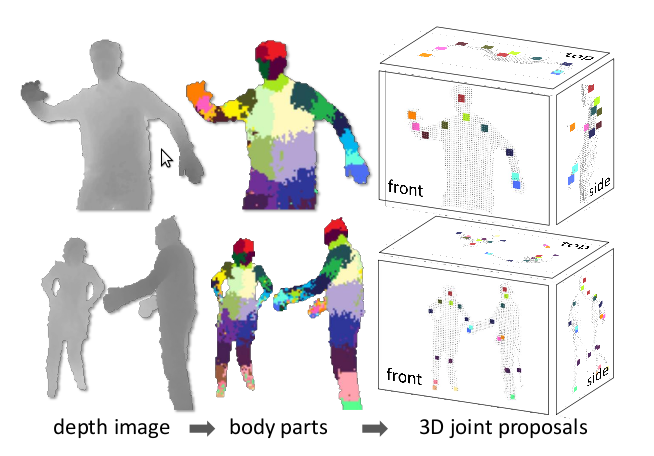
Заметим, что вычислить все это довольно просто, имея значения глубины хотя бы для трех пикселов и тут можно задействовать GPU. Поэтому система может обрабатывать 200 кадров в секунду и не требует начальной эталонной позы. Поскольку каждый кадр анализируется независимо, и нет слежения как такового, то нет и проблемы с потерей изображения тела; и можно обрабатывать несколько тел одновременно.
Теперь, когда вы немного понимаете, как это все работает, смотрим видео от Microsoft Research:
(альтернативный источник)
Kinect — значительное достижение и основан он на достаточно стандартном, классическом распознавании образов, но грамотно примененном. Также нужно принять во внимание доступность большой многоядерной вычислительной мощности, которая позволила сделать обучающее множество достаточно большим. Это одна из особенностей методик распознавания, что можно потратить века на обучение, но затем сама классификация может выполняться очень быстро. Возможно, мы вступаем в «золотой век», когда вычислительная мощь, необходимая для хорошей работы распознавания образов и машинного обучения, наконец сделает их практичными.
Собственно публикация (Pdf, 4.6 Мб)
P.S.
1. Это перевод. Так как всеобъемлющая мудрость Хабра не предусматривает такой мелочи, как изменение типа топика при первой публикации в песочницу, то он не оформлен должным образом.
Оригинал от Harry Fairhead с I Programmer.
2. Так как всеобъемлющая мудрость Хабра также не терпит спешки, то я уже было решил, что топик не прошел премодерацию и опубликовал его в другом месте. Так что если кто его там увидел, никому не говорите. Но знайте, что предназначался он для Хабра. :)
Прорыв Kinect-у обеспечивают несколько составляющих. Его железо хорошо продумано и выполняет свои функции за приемлемую цену. Однако после того, как пройдет изумление от быстро измеряющего глубину железа, внимание неизбежно привлекает способ, которым он (Kinect) отслеживает тело человека. В данном случае героем выступает довольно классическая методика распознавания образов, но реализованная с изяществом.
Устройства, отслеживающие положение тела, уже были и ранее; но их большой проблемой является необходимость для пользователя становиться в эталонную позу, в которой алгоритм опознает его с помощью простого сопоставления. После этого используется следящий алгоритм, следующий за движениями тела. Основная идея: если у нас на первом кадре есть область, идентифицированная как рука, то на следующем кадре эта рука не может передвинуться очень далеко, и значит мы просто пытаемся идентифицировать близлежащие области.
Следящие алгоритмы хороши в теории, но на практике они дают сбои, если положение тела по какой-то причине потеряно; и совсем уж плохо они справляются с другими объектами, загораживающими отслеживаемого человека, даже на короткое время. Кроме того, отслеживание нескольких человек затруднено; и при такой «потере следа» восстановить его удается спустя довольно длительное время, если вообще удается.
Итак, что же ребята из Microsoft Research сделали с этой проблемой, что Kinect работает намного лучше?
Они вернулись к исходным принципам и решили построить систему распознавания тела, которая не зависит от слежения, а находит части тела, основываясь на локальном анализе каждого пиксела. Традиционное распознавание образов работает с помощью принимающей решения структуры, обученной на множестве образцов. Чтобы она работала, вы обычно предоставляете классификатор с большим количеством значений признаков, которые, как вы полагаете, содержат информацию, необходимую, для распознавания объекта. Во многих случаях задача выбора информативных признаков и есть самая сложная задача.
Признаки, которые были выбраны, могут удивить, так как они просты и далеко не очевидны в смысле информативности для идентификации частей тела. Все признаки получаются из простой формулы
f = d( x + u/d(x) ) — d( x + v/d(x) )
где u,v — пара векторов смещения, а d(x) — глубина пиксела, то есть расстояние от Kinect до точки, проецирующейся на x. Это весьма простой признак, по сути это просто разница в глубине двух пикселов, смещенных относительно исходного на u и v. (Варьируя u и v, получаем набор признаков. В самой работе (ссылка внизу) все гораздо понятнее. — Прим. перев.)
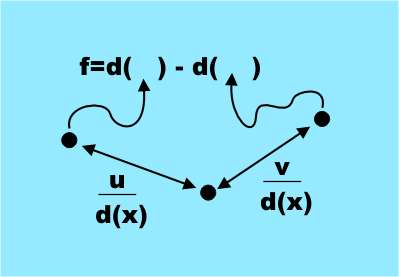
Единственное усложнение в том, что смещение нормировано глубиной исходного пиксела, то есть поделено на d(x). Это делает смещения независимыми от глубины и соотносит их с видимыми размерами тела.
Ясно, что эти признаки измеряют нечто, связанное с трехмерной формой области вокруг пиксела; но вот достаточно ли их, чтобы отличить, скажем, ногу от руки — это уже другой вопрос.
Следующий этап, выполненный командой — это обучение разновидности классификатора, называемого «лесом решений», то есть набора деревьев решений. Каждое дерево обучалось на наборе признаков на глубинных изображениях, которые заранее были привязаны к соответствующим частям тела. То есть деревья перестраивались до тех пор, пока они не стали выдавать правильную классификацию для определенной части тела на тестовом наборе изображений. Обучение лишь трех деревьев на 1 млн. изображений на 1000-ядерном кластере занимало около суток.
Обученные классификаторы выдают вероятность принадлежности пиксела к той или иной части тела; и следующая стадия алгоритма просто выбирает области с максимальной вероятностью для частей каждого типа. К примеру, область будет отнесена к категории 'нога', если «ножной» классификатор выдал максимум вероятности в этой области. Финальная стадия — это вычисление предполагаемого местоположения суставов относительно областей, опознанных как определенные части тела. На этой диаграмме максимумы вероятностей для различных частей тела обозначены цветными областями:
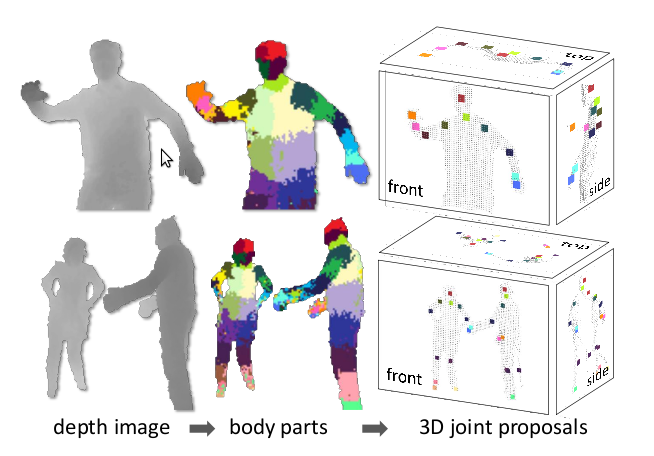
Заметим, что вычислить все это довольно просто, имея значения глубины хотя бы для трех пикселов и тут можно задействовать GPU. Поэтому система может обрабатывать 200 кадров в секунду и не требует начальной эталонной позы. Поскольку каждый кадр анализируется независимо, и нет слежения как такового, то нет и проблемы с потерей изображения тела; и можно обрабатывать несколько тел одновременно.
Теперь, когда вы немного понимаете, как это все работает, смотрим видео от Microsoft Research:
(альтернативный источник)
Kinect — значительное достижение и основан он на достаточно стандартном, классическом распознавании образов, но грамотно примененном. Также нужно принять во внимание доступность большой многоядерной вычислительной мощности, которая позволила сделать обучающее множество достаточно большим. Это одна из особенностей методик распознавания, что можно потратить века на обучение, но затем сама классификация может выполняться очень быстро. Возможно, мы вступаем в «золотой век», когда вычислительная мощь, необходимая для хорошей работы распознавания образов и машинного обучения, наконец сделает их практичными.
Собственно публикация (Pdf, 4.6 Мб)
P.S.
1. Это перевод. Так как всеобъемлющая мудрость Хабра не предусматривает такой мелочи, как изменение типа топика при первой публикации в песочницу, то он не оформлен должным образом.
Оригинал от Harry Fairhead с I Programmer.
2. Так как всеобъемлющая мудрость Хабра также не терпит спешки, то я уже было решил, что топик не прошел премодерацию и опубликовал его в другом месте. Так что если кто его там увидел, никому не говорите. Но знайте, что предназначался он для Хабра. :)
