Приветствую, уважаемые сообщники!
Эта статья — о том, как мы реализовали веб-кластер для новостного портала (с пиком посещений в 130 тысяч уникальных посетителей в день — это 7Тб траффика за 3 дня — выборы и 2 последующих. Сейчас в среднем кластер раздаёт 35-40 Тб траффика в месяц), о том, как по-разному понимают одинаковые задачи программисты и журналисты, о том, как можно достичь одной и той же цели, идя разными путями.
Она будет интересна тем, кто хочет построить легко масштабируемый географически распределённый веб-кластер, не вкладывая астрономических сумм в оборудование (а по меркам телевидения — будут вообще смешные суммы).
Я больше чем уверен, что маркетологи, толкающие убер-решения свежевыпущенных продуктов, имеющих в своём названии слова «масштабируемый веб-кластер» или «horizontal infinite scalable web cluster», меня возненавидят.
Я больше чем уверен, что конкуренты наших клиентов будут удивлены простотой решения, которое мы использовали.
Я не буду приводить банальных конфигов, которые можно найти в любом тоториале по настройке PHP, Nginx и Firebird (у последнего, строго говоря, и настраивать-то нечего — всё работает с пол-пинка «из коробки») и вообще буду рассказывать о сути решения, а не о том, какая из версий PHP лучше.
Опытным проектировщикам вряд ли будет интересно — они и так всё знают, а вот тем, кто только начинает путь на нелёгком поприще проектирования систем сложнее, чем «Hello, World!» наверняка будет что подчерпнуть — решение в боевом режиме уже скоро как 2 года, при этом никаких архитектурных проблем не возникало (хотя выход из строя сразу двух жёстких дисков на двух из трёх узлов был, но никто ничего не заметил — сайты чуть-чуть медленнее открывались, чем обычно).
Итак, пара слов, с чего всё начиналось. Жил-был сайтик группы независимых журналистов, которые очень мечтали стать настоящим телевидением (забегая вперёд, скажу, что у них это получилось — они создали своё, вполне успешное телевидение с «блэкджеком и шл...» — далее по тексту). Страна у нас маленькая, ничего страшного не происходит (и мы этому рады), но раз в 4 года у нас традиционно проходят выборы в Парламент.Который уже традиционно никак не избирает Президента. (Не бойтесь, политики тут не будет, это просто для общего понимания момента).
Разумеется, в период перед выборами и немного после все интернет СМИ очень сильно колбасит. Некоторые сайты не просто лежат, они валяются, некоторые переодически пытаются выдать хотя бы строчку текста, но проблема всеобщая и известная — сайты не справляются с наплывом посетителей. Я про обычные, текстовые сайты. А у наших клиентов сайт был необычный. Дело в том, что у них было и видео — новостные сюжеты, они производили 10 гигабайт в месяц — в то время, сейчас они создают такое количество видео в день. Ко всему прочему (это последнее упоминание политики, честное слово) эти журналисты не отличались особой лояльностью к власти. Говорили и писали что хотели.Совсем обнаглели, да? Мы всегда себя позиционируем как наёмников — клиент предлагает задачу, мы предлагаем её решение. Всё остальное нас не интересует, мы соблюдаем нейтралитет.
Перед нами была поставлена задача — предложить решение для новостных сайтов, которое позволит не просто выстоять при наплыве 50-100 тыс посетителей, но ещё было бы и географически разбросано по миру и управлялось измобильного бункера любой точки Вселенной планеты. Разумеется, географический разброс узлов кластера оставался за нами. В результате мы предложили следующую схему (художник из меня никакой, вы уж меня извините):
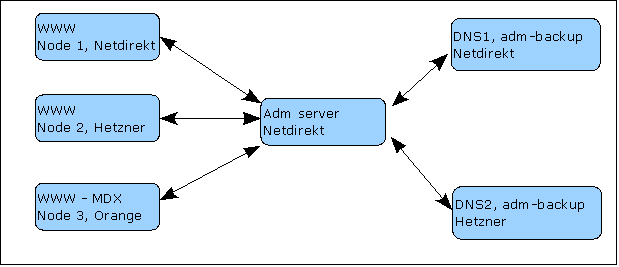
(Это упрощённая схема на ноябрь, в дальнейшем почти все сервера перенесли к Hetzner-у, так как у Netdirekt-a в то время постоянно колбасило канал. Сейчас у них с сетью ситуация обстоит намного лучше).
Обычные посетители видят один из 3-х серверов, при этом, мы сделали так, что «лёгкий» контент в виде текста и картинок все посетители из Молдовы тянули с одного их 3-х, а «тяжёлый» контент (видео) — тянули с сервера, расположенного у местного провайдера. Внешние посетители просто не видели молдавское зеркало и весь контент тянули с одного из немецких серверов.
Вот, что у нас получилось с посетителями в результате (каждая часть портала имеет свой счётчик):
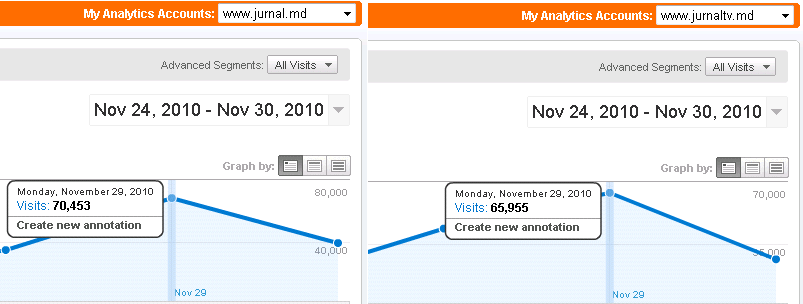
Эта схема позволяет сменить управляющий сервер в любой момент, сама проверяет доступность узлов кластера, легко масштабируется — в качестве резервного рассматривался и Amazon EC – более того, Amazon EC даже использовался некоторое время для видеостриминга (около 4-х месяцев), но из-за дороговизны траффика решено было всё-таки стриминг-ноды перенести к немецкому Hetzner-у.
Непосредственно за 2 недели до часа «Х» мы взяли резервные сервера и держали их наготове (но пользователи их не видели, так как держать активным сервер несколько дешевле, чем использовать его в боевом режиме — только из-за траффика).
Как это всё работает? Очень просто — молча и круглосуточно ;).
На управляющем сервере (как я уже упоминал, у портала 2 больших «раздела»: новости в виде текста с картинками и новости в виде текстового дайджеста и видео— де-факто используется 2 сервера, но для простоты я изобразил один) есть то, что обычно именуется системой управления контентом.
Основная задача этого сервера — позволять журналистам добавлять новости. Раз в определённое время (3-5 минут) стартует скрипт, который создаёт… offline-копию сайта. Разумеется, генерируются только страницы, которые были изменены или которые нуждаются в перестройке из-за кроссылок и зависимостей.
Это очень просто реализуется при помощи генераторов (sequense) и каскадных триггеров в Firebird — процедуре требуется внести изменения только в основную страницу сайта, а каскадные триггеры обновят все зависимости, пометив каждую страницу, которая нуждается в обновлении. Пометка выставляется не в виде флага 1/0, а в виде уникального номера, получаемого на основе генератора. Скрипт создания оффлайновой версии при старте узнаёт новое значение генератора, считывает значение этого генератора от своего предыдущего запуска и пересоздаёт все страницы в полученном диапазоне. При этом, так как мы используем транзакционный механизм Firebird – скрипту глубоко наплевать, какие изменения происходят во время его выполнения — т.е. у нас всегда создаётся целостная и непротиворечивая версия сайта, что бы при этом не делали репортёры.
Таким образом, у нас создаётся мастер-копия портала (ну или двух порталов, если угодно — текстового и видео). Скрипт (как и сама админка) написан на PHP и для работы с Firebird использует ADODB – так что его довольно-таки просто можно перестраивать по желанию заказчика*.
(* Но мы собираемся избавиться от ADODB в скором времени во всех наших будущих проектах — его универсальность только вредит, так как нормального механизма работы с БД, позволяющего использовать все особенности Firebird SQL сервера (впрочем, как и остальных) там не реализовано — к примеру, невозможно перехватывать исключения при выборке из селективных процедур, нет гибкого управления транзакциями и вообще, у этих классов слишком много ИИ — я предпочитаю самостоятельно решать, когда я хочу откатить тразакцию, а когда — подтвердить.)
Единственное, что пришлось менять в настройках Firebird – это значение размера кэша страниц БД — так как количество подключений к БД очень небольшое (редко когда более 50-60 одновременных подключений), то и количество страниц экспериментальным путём было увеличено до 2048 (мы используем Classic вариант, для архитектуры Super это значение спокойно можно увеличить в 10 раз, так как там общий кэш страниц. В грядущей версии Firebird 3.0 разработчики обещают одну SMP-friendly архитектуру с общим кэшем, так что для неё вполне можно будет использовать большие значения для настроек страничного кэша).
Затем, при помощи обычного rsync-а разница изменений раскидывается по зеркалам, которые из себя представляют обычные узлы для раздачи статики на основе Nginx. Я думаю, не требуется рассказывать, на что способен 4-хядерный сервер с 12 Гигабайтами оперативки при раздаче одной только статики? ;-)
При этом, 10% канала каждой ноды (это как раз 10 или 100 мегабит, в зависимости от конкретного подключения) зарезервировано для синхронизации. Синхронизация происходит в 2 этапа — сначала синхронизируется «тяжёлый» контент — картинки и видео, потом — текст (html/xml/js).
Иногда (при загруженных каналах от управляющего сервера к зеркалам) посетитель может увидеть маленькие несоответствия в виде негрузящихся картинок и/или видеороликов — так как используется round-robin DNS, то текст страницы пользователь может получить с одного зеркала, а ссылку на видео — с другого. Это не мешает порталу работать — текст есть всегда, а картинка или видео рано или поздно объявятся.
Так как на сайтах есть динамические формочки — например, подписка на рассылку новостей — то эти формочки обрабатываются отдельно выделенным сервером (он не изображён на схеме, но сути это не меняет). Даже если предположить, что все посетители одновременно ломанутся подписываться на новости и этот сервер «ляжет» — ничего страшного не случится — формы подгружаются в iframe и на доступности новостей отсутствие этих формочек никак не отражается.
Добавление нового узла происходит просто — сначала синхронизируется новое зеркало с основной копией (это происходит параллельно с обычным режимом работы синхронизатора), затем запись добавляется в DNS и… никто ничего не замечает.
Удаление ноды происходит проще — просто убирается запись из DNS. Добавление и удаление вполне поддаются автоматизации (именно так мы поступили с частью, которая отвечала за веб-стриминг около 1000 мегабитных потоков на Amazom EC), но если вы вдруг решитесь повторять подобное — советую сначала посчитать, сколько занимает первичная синхронизация данных (у нас это 2 Гигабайта для «лёгкой версии портала» и примерно 1 Терабайт для видео, хранится только несколько последних месяцев).
Именно поэтому динамическое добавление/удаление нод из пула запасных мы убрали через некоторое время работы проекта — слишком много занимает контент и слишком уж параноидальным получился скрипт — убирал ноды при каждой проблеме связи с ними.
Отдельно стоит упомянуть про подсчёты отображений новости. У меня сложилось впечатление, что любимое занятие у журналистов (помимо написаний/съёмок репортажей) — это мерянье количеством посетителей той или иной новости. Примерно литр крови и километр нервов нам пришлось потратить, чтобы убедить журналистскую братию в том, что не требуется выводить изменения счётчиков в реальном времени.
Программисты прекрасно понимают, что узнать, сколько человек в настоящий момент читают статью просто невозможно, можно только посчитать количество запросов статьи с сервера, для журналистов же это одинаковые понятия. :)
Для подсчёта просмотров мы связались с Кирилом Коринским (также известным, как catap), который любезно согласился добавить фичу подсчёта просмотров URL в свою ветку Nginx-а. Ну а дальше уже всё просто — все узлы переодически опрашиваются и счётчики страниц учитываются в свойствах самой страницы. Так как счётчики (т.е. сами значения) хранятся в отдельных файлах (сейчас это по одному файлу на новость, в скором времени мы планируем сделать группу счётчиков в одном файле, чтобы уменьшить количество самих файлов) — то при синхронизации передаётся не страницы сайта целиком, а только файл-счётчик. При большом количестве файлов это создаёт дополнительную нагрузку на дисковую подсистему — поэтому, при использовании такого же подхода сразу продумывайте о том, как разбить счётчики по группам — мы остановились на разбиении счётчиков по типам новостей и дате — файлы относительно маленькие и со временем они перестают меняться, так как старые новости никого практически не интересуют.
Вот вкратце, плюсы использованного нами решения:
Ну и парочка минусов, чтобы не всё казалось таким безоблачным:
И буквально маленькая щепотка опыта, которая позволит разнообразить пресную кашу будней.
Для хранения оффлайн-копии сайта мы используем файловую систему JFS. Она себя очень хорошо зарекомендовала и при работе с множеством мелких файлов и при работе с большими файлами (по моему опыту ещё только XFS может практически моментально удалить файл размером в 200-300Гб).
Так вот — по умолчанию файловая система монтировалась с параметрами по умолчанию. Но так как у нас со временем стало очень много файлов, дисковые операции стали немного подтормаживать. Так как время последнего доступа к файлу нам не требуется, я добавил опцию «noatime» к параметрам монтирования ФС. Вот что получилось — момент добавления, думаю, вы определите сами:

Кратко повторюсь — для стабильной работы в обычном режиме используется:
Узлы кластера разбросаны географически и находятся у разных провайдеров.
В случае ожидаемых событий, привлекающих большое количество посетителей — подключаются дополнительные сервера для раздачи контента.
В месяц потребляется около 40Тб траффика, общий объём контента — чуть более 1 Терабайта, видеоконтент хранится около 3-х месяцев.
Я с удовольствием отвечу на вопросы хабрасообщества.
Эта статья — о том, как мы реализовали веб-кластер для новостного портала (с пиком посещений в 130 тысяч уникальных посетителей в день — это 7Тб траффика за 3 дня — выборы и 2 последующих. Сейчас в среднем кластер раздаёт 35-40 Тб траффика в месяц), о том, как по-разному понимают одинаковые задачи программисты и журналисты, о том, как можно достичь одной и той же цели, идя разными путями.
Она будет интересна тем, кто хочет построить легко масштабируемый географически распределённый веб-кластер, не вкладывая астрономических сумм в оборудование (а по меркам телевидения — будут вообще смешные суммы).
Я больше чем уверен, что маркетологи, толкающие убер-решения свежевыпущенных продуктов, имеющих в своём названии слова «масштабируемый веб-кластер» или «horizontal infinite scalable web cluster», меня возненавидят.
Я больше чем уверен, что конкуренты наших клиентов будут удивлены простотой решения, которое мы использовали.
Я не буду приводить банальных конфигов, которые можно найти в любом тоториале по настройке PHP, Nginx и Firebird (у последнего, строго говоря, и настраивать-то нечего — всё работает с пол-пинка «из коробки») и вообще буду рассказывать о сути решения, а не о том, какая из версий PHP лучше.
Опытным проектировщикам вряд ли будет интересно — они и так всё знают, а вот тем, кто только начинает путь на нелёгком поприще проектирования систем сложнее, чем «Hello, World!» наверняка будет что подчерпнуть — решение в боевом режиме уже скоро как 2 года, при этом никаких архитектурных проблем не возникало (хотя выход из строя сразу двух жёстких дисков на двух из трёх узлов был, но никто ничего не заметил — сайты чуть-чуть медленнее открывались, чем обычно).
Итак, пара слов, с чего всё начиналось. Жил-был сайтик группы независимых журналистов, которые очень мечтали стать настоящим телевидением (забегая вперёд, скажу, что у них это получилось — они создали своё, вполне успешное телевидение с «блэкджеком и шл...» — далее по тексту). Страна у нас маленькая, ничего страшного не происходит (и мы этому рады), но раз в 4 года у нас традиционно проходят выборы в Парламент.
Разумеется, в период перед выборами и немного после все интернет СМИ очень сильно колбасит. Некоторые сайты не просто лежат, они валяются, некоторые переодически пытаются выдать хотя бы строчку текста, но проблема всеобщая и известная — сайты не справляются с наплывом посетителей. Я про обычные, текстовые сайты. А у наших клиентов сайт был необычный. Дело в том, что у них было и видео — новостные сюжеты, они производили 10 гигабайт в месяц — в то время, сейчас они создают такое количество видео в день. Ко всему прочему (это последнее упоминание политики, честное слово) эти журналисты не отличались особой лояльностью к власти. Говорили и писали что хотели.
Перед нами была поставлена задача — предложить решение для новостных сайтов, которое позволит не просто выстоять при наплыве 50-100 тыс посетителей, но ещё было бы и географически разбросано по миру и управлялось из
(Это упрощённая схема на ноябрь, в дальнейшем почти все сервера перенесли к Hetzner-у, так как у Netdirekt-a в то время постоянно колбасило канал. Сейчас у них с сетью ситуация обстоит намного лучше).
Обычные посетители видят один из 3-х серверов, при этом, мы сделали так, что «лёгкий» контент в виде текста и картинок все посетители из Молдовы тянули с одного их 3-х, а «тяжёлый» контент (видео) — тянули с сервера, расположенного у местного провайдера. Внешние посетители просто не видели молдавское зеркало и весь контент тянули с одного из немецких серверов.
Вот, что у нас получилось с посетителями в результате (каждая часть портала имеет свой счётчик):
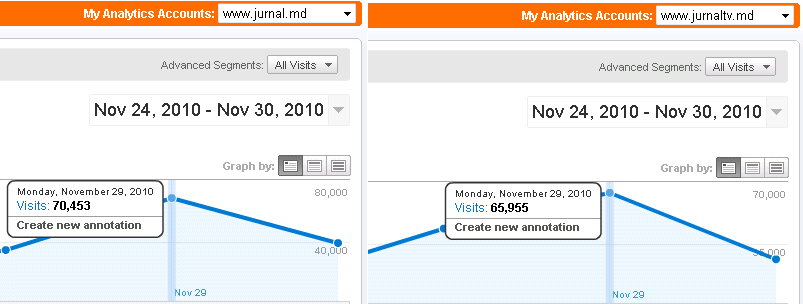
Эта схема позволяет сменить управляющий сервер в любой момент, сама проверяет доступность узлов кластера, легко масштабируется — в качестве резервного рассматривался и Amazon EC – более того, Amazon EC даже использовался некоторое время для видеостриминга (около 4-х месяцев), но из-за дороговизны траффика решено было всё-таки стриминг-ноды перенести к немецкому Hetzner-у.
Непосредственно за 2 недели до часа «Х» мы взяли резервные сервера и держали их наготове (но пользователи их не видели, так как держать активным сервер несколько дешевле, чем использовать его в боевом режиме — только из-за траффика).
Как это всё работает? Очень просто — молча и круглосуточно ;).
На управляющем сервере (как я уже упоминал, у портала 2 больших «раздела»: новости в виде текста с картинками и новости в виде текстового дайджеста и видео— де-факто используется 2 сервера, но для простоты я изобразил один) есть то, что обычно именуется системой управления контентом.
Основная задача этого сервера — позволять журналистам добавлять новости. Раз в определённое время (3-5 минут) стартует скрипт, который создаёт… offline-копию сайта. Разумеется, генерируются только страницы, которые были изменены или которые нуждаются в перестройке из-за кроссылок и зависимостей.
Это очень просто реализуется при помощи генераторов (sequense) и каскадных триггеров в Firebird — процедуре требуется внести изменения только в основную страницу сайта, а каскадные триггеры обновят все зависимости, пометив каждую страницу, которая нуждается в обновлении. Пометка выставляется не в виде флага 1/0, а в виде уникального номера, получаемого на основе генератора. Скрипт создания оффлайновой версии при старте узнаёт новое значение генератора, считывает значение этого генератора от своего предыдущего запуска и пересоздаёт все страницы в полученном диапазоне. При этом, так как мы используем транзакционный механизм Firebird – скрипту глубоко наплевать, какие изменения происходят во время его выполнения — т.е. у нас всегда создаётся целостная и непротиворечивая версия сайта, что бы при этом не делали репортёры.
Таким образом, у нас создаётся мастер-копия портала (ну или двух порталов, если угодно — текстового и видео). Скрипт (как и сама админка) написан на PHP и для работы с Firebird использует ADODB – так что его довольно-таки просто можно перестраивать по желанию заказчика*.
(* Но мы собираемся избавиться от ADODB в скором времени во всех наших будущих проектах — его универсальность только вредит, так как нормального механизма работы с БД, позволяющего использовать все особенности Firebird SQL сервера (впрочем, как и остальных) там не реализовано — к примеру, невозможно перехватывать исключения при выборке из селективных процедур, нет гибкого управления транзакциями и вообще, у этих классов слишком много ИИ — я предпочитаю самостоятельно решать, когда я хочу откатить тразакцию, а когда — подтвердить.)
Единственное, что пришлось менять в настройках Firebird – это значение размера кэша страниц БД — так как количество подключений к БД очень небольшое (редко когда более 50-60 одновременных подключений), то и количество страниц экспериментальным путём было увеличено до 2048 (мы используем Classic вариант, для архитектуры Super это значение спокойно можно увеличить в 10 раз, так как там общий кэш страниц. В грядущей версии Firebird 3.0 разработчики обещают одну SMP-friendly архитектуру с общим кэшем, так что для неё вполне можно будет использовать большие значения для настроек страничного кэша).
Затем, при помощи обычного rsync-а разница изменений раскидывается по зеркалам, которые из себя представляют обычные узлы для раздачи статики на основе Nginx. Я думаю, не требуется рассказывать, на что способен 4-хядерный сервер с 12 Гигабайтами оперативки при раздаче одной только статики? ;-)
При этом, 10% канала каждой ноды (это как раз 10 или 100 мегабит, в зависимости от конкретного подключения) зарезервировано для синхронизации. Синхронизация происходит в 2 этапа — сначала синхронизируется «тяжёлый» контент — картинки и видео, потом — текст (html/xml/js).
Иногда (при загруженных каналах от управляющего сервера к зеркалам) посетитель может увидеть маленькие несоответствия в виде негрузящихся картинок и/или видеороликов — так как используется round-robin DNS, то текст страницы пользователь может получить с одного зеркала, а ссылку на видео — с другого. Это не мешает порталу работать — текст есть всегда, а картинка или видео рано или поздно объявятся.
Так как на сайтах есть динамические формочки — например, подписка на рассылку новостей — то эти формочки обрабатываются отдельно выделенным сервером (он не изображён на схеме, но сути это не меняет). Даже если предположить, что все посетители одновременно ломанутся подписываться на новости и этот сервер «ляжет» — ничего страшного не случится — формы подгружаются в iframe и на доступности новостей отсутствие этих формочек никак не отражается.
Добавление нового узла происходит просто — сначала синхронизируется новое зеркало с основной копией (это происходит параллельно с обычным режимом работы синхронизатора), затем запись добавляется в DNS и… никто ничего не замечает.
Удаление ноды происходит проще — просто убирается запись из DNS. Добавление и удаление вполне поддаются автоматизации (именно так мы поступили с частью, которая отвечала за веб-стриминг около 1000 мегабитных потоков на Amazom EC), но если вы вдруг решитесь повторять подобное — советую сначала посчитать, сколько занимает первичная синхронизация данных (у нас это 2 Гигабайта для «лёгкой версии портала» и примерно 1 Терабайт для видео, хранится только несколько последних месяцев).
Именно поэтому динамическое добавление/удаление нод из пула запасных мы убрали через некоторое время работы проекта — слишком много занимает контент и слишком уж параноидальным получился скрипт — убирал ноды при каждой проблеме связи с ними.
Отдельно стоит упомянуть про подсчёты отображений новости. У меня сложилось впечатление, что любимое занятие у журналистов (помимо написаний/съёмок репортажей) — это мерянье количеством посетителей той или иной новости. Примерно литр крови и километр нервов нам пришлось потратить, чтобы убедить журналистскую братию в том, что не требуется выводить изменения счётчиков в реальном времени.
Программисты прекрасно понимают, что узнать, сколько человек в настоящий момент читают статью просто невозможно, можно только посчитать количество запросов статьи с сервера, для журналистов же это одинаковые понятия. :)
Для подсчёта просмотров мы связались с Кирилом Коринским (также известным, как catap), который любезно согласился добавить фичу подсчёта просмотров URL в свою ветку Nginx-а. Ну а дальше уже всё просто — все узлы переодически опрашиваются и счётчики страниц учитываются в свойствах самой страницы. Так как счётчики (т.е. сами значения) хранятся в отдельных файлах (сейчас это по одному файлу на новость, в скором времени мы планируем сделать группу счётчиков в одном файле, чтобы уменьшить количество самих файлов) — то при синхронизации передаётся не страницы сайта целиком, а только файл-счётчик. При большом количестве файлов это создаёт дополнительную нагрузку на дисковую подсистему — поэтому, при использовании такого же подхода сразу продумывайте о том, как разбить счётчики по группам — мы остановились на разбиении счётчиков по типам новостей и дате — файлы относительно маленькие и со временем они перестают меняться, так как старые новости никого практически не интересуют.
Вот вкратце, плюсы использованного нами решения:
- Использование статических сайтов в качестве узлов веб-кластера позволяет свести администрирование всего кластера к нескольким рутинным задачам — обновлению операционной системы узлов и оплате траффика. Этот же пункт позволяет раскидать географически узлы кластера, что вкупе с GEO-DNS может рассматриваться вообще как некоторый аналог сети доставки контента (CDN) — по сути это оно и есть.
- Использование транзакционного механизма БД и перенос логики в саму БД позволяет всегда иметь целостную и логически непротиворечивую версию сайта — впрочем, я бы очень удивился, если бы «срез» данных с сервера был бы логически нецелостным.
- Если ожидается наплыв посетителей — то простым увеличением узлов кластера можно легко с ним справиться. В нашем случае, полный ввод нового узла в строй занимал чуть более часа для текстовой части портала и около суток (нельзя впихнуть невпихуемое) для видео. Если смириться с частичной синхронизацией сайтов и остальное «доливать» в фоне — то ввод нового узла для видео также можно сократить до часа.
- Административный сервер можно сделать из любого из узлов (при необходимости) — достаточно просто развернуть бэкап базы (в сжатом виде около сотни мегабайт). Весь остальной контент уже есть.
Ну и парочка минусов, чтобы не всё казалось таким безоблачным:
- Решение не подходит для случаев, когда есть части сайта, которые по-разному должны видеть разные пользователи, т.е. когда по условию задачи страницы генерируются персонально для каждого пользователя. В нашем случае этого оказалось и ненужно.
- Счётчики посещений обновляются с отставанием примерно в полчаса-час. Терпимо, но вам придётся в этом долго убеждать клиента.
- Больше всего проблем доставляет синхронизация с местным зеркалом — наши провайдеры ещё не продают траффик по цене в 7 евро за Терабайт и если и предоставляют 100 честных Мегабит в мир — то по очень неадекватным ценам.
- Проектируйте менее параноидальную систему слежения за узлами кластера — наша оказалась слишком чувствительной, пришлось переводить добавление и удаление узлов в ручной режим.
И буквально маленькая щепотка опыта, которая позволит разнообразить пресную кашу будней.
Для хранения оффлайн-копии сайта мы используем файловую систему JFS. Она себя очень хорошо зарекомендовала и при работе с множеством мелких файлов и при работе с большими файлами (по моему опыту ещё только XFS может практически моментально удалить файл размером в 200-300Гб).
Так вот — по умолчанию файловая система монтировалась с параметрами по умолчанию. Но так как у нас со временем стало очень много файлов, дисковые операции стали немного подтормаживать. Так как время последнего доступа к файлу нам не требуется, я добавил опцию «noatime» к параметрам монтирования ФС. Вот что получилось — момент добавления, думаю, вы определите сами:
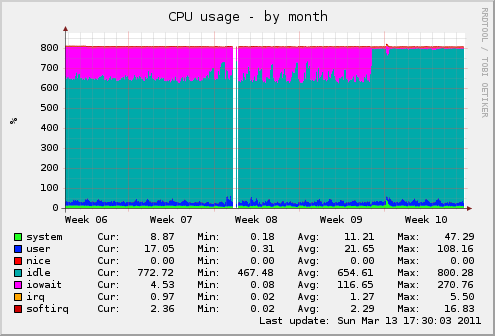
Кратко повторюсь — для стабильной работы в обычном режиме используется:
- 3 сервера для раздачи контента
- 2 сервера для «админки»
- 2 сервера для DNS и системы слежения за остальными серверами.
Узлы кластера разбросаны географически и находятся у разных провайдеров.
В случае ожидаемых событий, привлекающих большое количество посетителей — подключаются дополнительные сервера для раздачи контента.
В месяц потребляется около 40Тб траффика, общий объём контента — чуть более 1 Терабайта, видеоконтент хранится около 3-х месяцев.
Я с удовольствием отвечу на вопросы хабрасообщества.
